基于多特征融合及Transformer 的人体跌倒动作检测算法
2022-04-15刘文龙陈春雨
刘文龙,陈春雨
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
当前,人工智能和高性能计算设备的迅速发展,为大规模深度神经网络的训练和部署提供了可行性保障。动作识别作为计算机视觉的研究方向之一,在各个领域具有良好的应用前景。在医疗领域,可以通过动作识别来判断病人的状态,减轻病房看护者的负担。病人一旦发生摔倒等行为可以通过动作识别来进行判断,并提醒看护人员进行及时救助[1]。在安防领域,可以利用动作识别实现对打架斗殴等违法犯罪行为进行识别并记录,为刑事案件的侦破提供有利帮助[2]。在监考任务中,可以通过行为识别来判断应试者是否存在扭头、转身以及东张西望等作弊行为[3]。可见动作识别在现实场景中具有重要的应用价值。传统的视频动作行为识别常常通过人工肉眼观察来完成,耗费了大量的人力和时间,长期工作还会对视力造成损伤,这项任务被计算机取代是大势所趋。基于深度学习的动作检测方法相对于传统方法可以实现无人化、智能化[4]。
陈永彬等[5]采用了OpenPose 网络提取人体关键点信息,并融合了场景的语义信息,通过判断头部以下关键点的下移量进行判断是否存在摔倒行为。乌民雨等[6]采用了包含长短期记忆(long short-term memory, LSTM)的双流的网络结构,2个流分别输入RGB 图片和光流图片。刘峰等[7]通过目标检测器检测到运动的行人,对行人提取了头部运动特征,通过深度森林算法对特征进行分类,来判断行人是否发生摔倒行为。魏振刚等[8]通过对视频中的人物的前景提取得到目标,对前景目标进行形态学处理得到了最小外接矩形,通过分析外接矩形的宽高比筛选出可能存在跌倒行为的样本,再运用统计学方法对异常目标绘制椭圆边界作为特征进行分类,判断是否发生跌倒行为。Tran 等[9]提出了3D 卷积(3D convolution,C3D)方法,可以通过训练学习,简单有效地对动作的时空特征进行提取,这项方法常用于对动作进行分类,但单独的C3D 方法无法完成对执行动作的目标进行空间定位,对此本文吸收了C3D 方法可以提取时空特征的思想,实现了跌倒动作的时空定位。
1 网络结构
得益于GPU 性能的高速发展,大规模神经网络的训练及部署成为了可能。动作识别作为计算机视觉领域的重要研究分支,可以通过深度学习方法来解决;动作的定位可以通过借鉴目标检测的方法,采用边界框的回归来实现。对于动作的分类不仅需要空间特征信息,还需要时间维度上的特征信息,因为动作是连贯的,所以必须通过一定的手段来提取时间维度上的特征。因此本文借鉴了YOLOv3 目标检测网络[10]和双流网络[11]的设计思想。
1.1 动作识别网络整体结构
本文提出的网络整体结构如图1 所示。
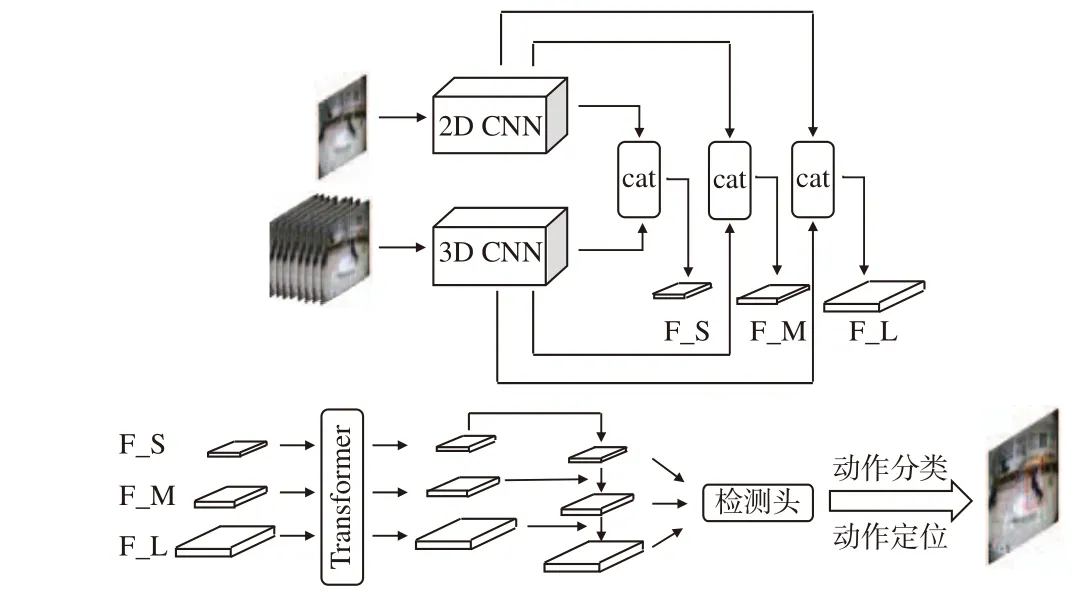
图1 整体网络结构
本文设计了可以实现动作识别与定位的算法,通过在2D 卷积神经网络(convolutional neural network, CNN)并联了一路3D 卷积神经网络(3D CNN)用于提取时间维度特征,并通过通道融合机制对空间维度特征和时间维度特征在通道维度上进行拼接(cat)。为了提高模型对小目标的检测能力,本算法采用特征金字塔结构,对骨干网络提取3 个不同尺度的特征(分别为F_S、F_M、F_L),提升对小目标的检测能力,对这3 个尺度的特征采用Transformer 结构进行深层次特征融合,提取语义信息。最终经过分类网络和回归网络进行动作分类和动作定位。
1.1.1 特征提取网络
由于动作具有连续性,几乎不能通过单张图片来进行判断动作类型,所以必须获得动作的连续信息,也就是时间维度上的特征。这种时间维度上的特征采用3D 卷积来进行提取,他的计算过程可以通过图2 来表示。图2 中h3D、w3D和l分别为特征图空间维度的高度、空间维度的宽度、时间维度的长度,k3D为卷积核空间维度的宽度和高度,d为卷积核时间维度的长度。

图2 3D 卷积计算示意
3D 卷积的输入是由视频拆分出来的一系列连续的图片帧。本文中采用的是连续的16 帧图片,将其组成一个五维张量,并由B表示批次大小、C表示图片通道数目、N表示图片数目、W表示图片的宽度、H表示图片的高度。3D 卷积的卷积核包含3 个维度,可以在图2 中的长方体数据中的3 个方向滑动,最终堆叠到同一个输出,这样就可以提取多个相邻图片之间的特征。本文采用的3D 卷积网络为3D ResNet101[12]。
图3 所示的是2D 卷积示意图,图中h2D,w2D分别代表特征图空间维度的高度和宽度。k2D代表卷积核空间维度的宽度和高度。在3D 卷积输入的多个连续图片序列中抽取最后一帧作为关键帧,将其输入到2D 卷积网络中。2D 卷积的卷积核包含2 个维度,可以在图3 中的长方形数据中的2 个方向进行滑动,得到特征图,提取输入图像空间上的信息。本文采用ResNeXt101 作为2D 网络,该网络具有良好的特征提取能力。
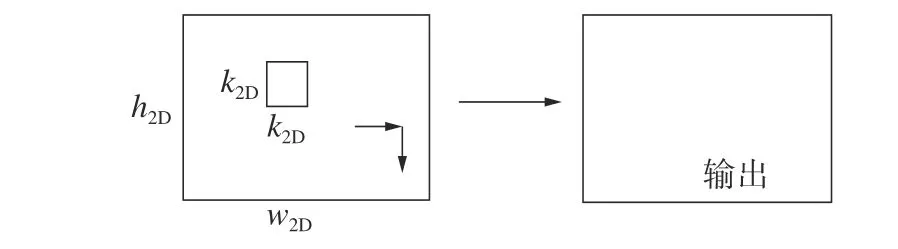
图3 2D 卷积计算示意
1.1.2 特征金字塔Transformer 结构
为了更好地提取语义特征,提升模型对动作的专注度,本文采用了Transformer 结构。Transformer最早应用于自然语言处理任务中,因其优秀的表现被迁移到计算机视觉中[13]。而本文则将其应用到动作检测任务中,将其作为注意力机制与传统注意力机制进行对比。本文应用的Transformer结构如图4 所示。

图4 特征金字塔Transformer 结构
本文对特征提取网络的3 个预测特征层构成的特征金字塔使用了Transformer 结构,Transformer结构可以使得特征可以跨空间和尺度进行交互。文中应用的特征金字塔Transformer 包含了3 个子模块,分别是自我特征交互模块、自顶而下特征交互模块和自底而上特征交互模块。经过该结构输出的特征图与输入特征图尺寸相同,但蕴含了丰富的上下文信息。加权后的Q经 过 3×3卷 积与通过 3×3卷积进行下采样的V相加,相加后的结果经过 3×3卷积运算后得到输出特征图。计算过程如式(5):



如图4 所示的网络结构图,3 个不同尺度的预测特征层在经过上文所述的3 种模块之后得到的特征图,按照尺寸大小进行重新排列,再将原始预测特征层与排列后的特征图在通道维度进行拼接,经过卷积得到与原始预测特征层尺寸相同的特征图。可以看到,输出的特征图与输入特征图相比,增加了空间和尺度信息的交互,包含了更为丰富的语义信息。
1.2 数据处理及损失函数
本文考虑到小目标检测的问题,采用了YOLOv3 算法的检测方案。通过K-means 算法对数据集的边界框大小进行统计,最终聚类出9 个预选框。选取3 个预测特征层,在3 个尺度上对目标进行检测,每个预测特征层对应3 个聚类出来的预选框。在经过Transformer 和卷积之后,最终的每个预测特征层通道为 3×(A+5)。其中:3 为该预测特征层预选框的数目;A为数据集中动作类别数目;每个预选框对应A+5个参数,5 为边界框的中心坐标和边界框的宽高回归所需要的4 个参数和1 个置信度参数。
损失函数共包括3 部分,分别是边界框回归损失、分类损失和置信度损失。其中边界框回归损失采用完整交并比(complete intersection-overunion,CIoU) 损失函数[15],分类和置信度损失采用Focal Loss 损失函数[16]。由于YOLOv3 的正样本负样本存在严重的不均衡问题,大量的负样本大部分为简单易于区分的负样本,会造成对真样本的淹没,影响检测效果,针对样本不均衡问题,本文采用式(6)作为分类和置信度损失函数。

边界框回归损失函数通常采用L2 范数损失函数,由于L2 范数损失函数不能很好地反应预测框与真实位置的重合程度,所以在本文中采用了CIoU 损失函数,它能够很好地反应预测框与真实位置的重叠程度,并具有尺度不变性,还充分考虑了预测框与真实位置的中心距离、预测框的长宽比等因素,比L2 范数损失函数具有更大的优势。图5 为CIoU 函数计算所需参数示意图。其中绿色矩形框为目标的真实边界框,它的宽高分别为wgt和hgt;黑色方框为网络预测的边界框,它的宽高分别为wp和hp;d为真实框和预测框的中心距离,c为真实框与预测框的最小外接矩形的对角距离。

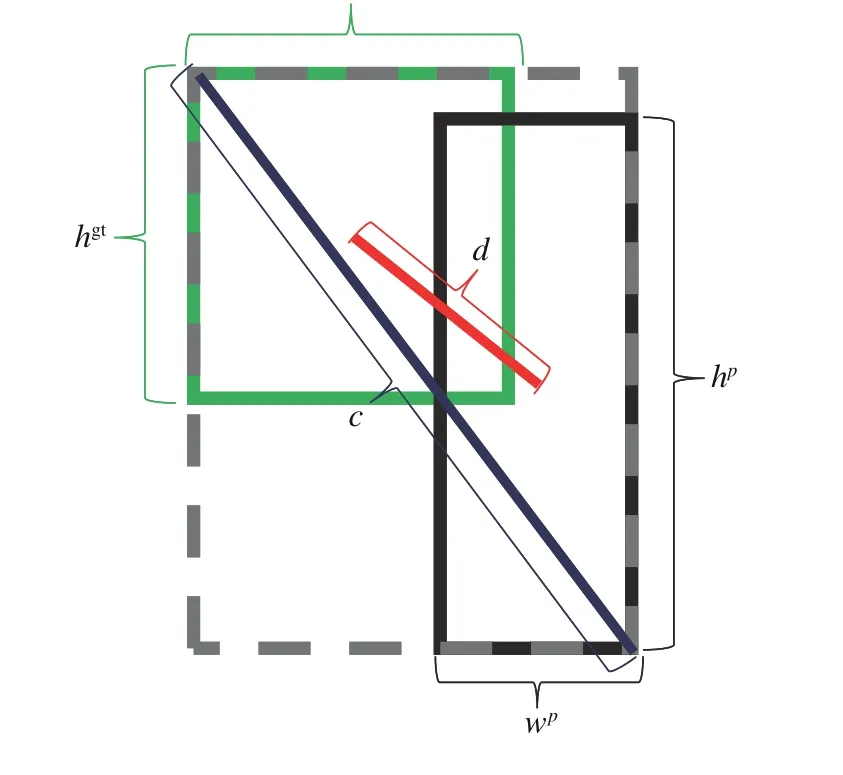
图5 CIoU 函数计算所需参数示意
2 实验
2.1 跌倒动作数据集
目前,跌倒动作的公开数据集数目不多,很少有提供跌倒动作的人物边界框数据。本文从Muticam 数据集中选取部分视频,共包含6 个场景,每个场景由8 个摄像头在不同角度进行拍摄,分辨率为320 ×240。对拍摄的视频进行了分帧处理,并进行了手工标注,一共标记了7 083 张图片。其中6 373 张图片作为训练集,710 张图片作为验证集和测试集。每次输入到网络进行训练和推理的图片数据均来自于同一个摄像头,8 个摄像头的数据最终都会独立地被送入网络进行训练和推理。
2.2 跌倒动作识别实验
2.2.1 实验环境与训练策略
本文中所有实验的硬件平台均在Ubuntu 18.04 操 作 系 统 下,GPU 采 用Nvidia RTX2080Ti,GPU 显存大小为11 GB,CPU 采用I7-8700K,内存大小为32 GB。软件环境如下:深度学习框架为Pytorch-1.7.1、CUDA 版本为10.1。
每次实验训练集迭代训练10 次,一次训练输入到网络的样本数目为2,共计训练31 870 次。基本学习率(Rlearning)为0.002,学习率的动态变化如图6 所示,其中包含了2 种策略:对于前1 000 次训练采用线性预热;预热完成后采用余弦衰减策略直到训练结束。优化器采用带有动量参数的随机梯度下降算法。
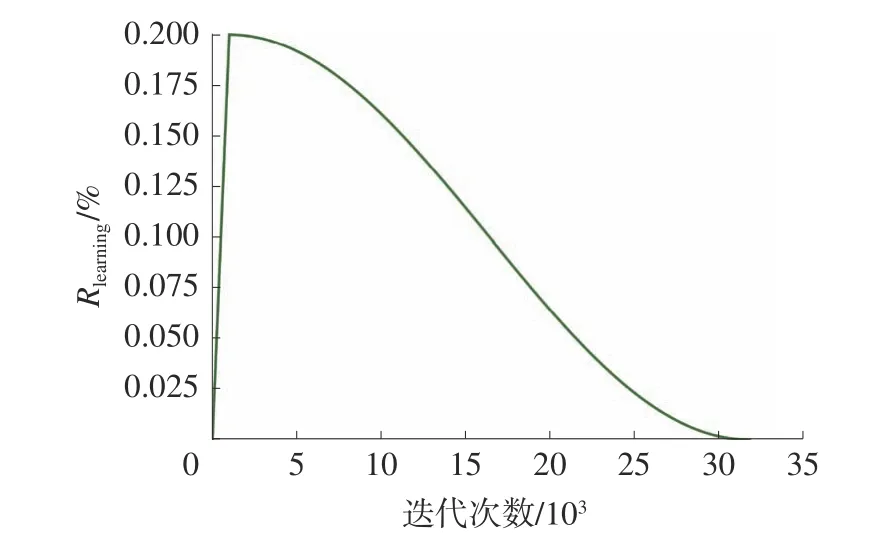
图6 学习率变化曲线
2.2.2 预选框的设置
本文的算法需要预先设定好预选框,合适的预选框设定可以加速模型的收敛。预选框的设定原则是尽可能与数据集中的目标宽高相似,所以需要对数据集进行分析。由于本文采用了3 个尺度的预测特征层,每个预测特征层对应3 个预选框,所以一共需要设置9 个预选框。预选框通过K-means 算法得到。图7 中黄色的圆点代表数据集中的目标的宽高信息,其中横坐标为目标的宽度像素值,纵坐标为目标的高度像素值,其余颜色的9 个点为聚类中心,红色的3 个聚类中心是设置在特征金字塔网络输出的最大尺寸特征图上的预选框,绿色的3 个聚类中心是设置在特征金字塔网络输出的中等尺寸特征图上的预选框,蓝色的3 个聚类中心是设置在特征金字塔网络输出的最小尺寸特征图上的预选框。因为特征金字塔网络中尺寸相对较大的特征图用于更好地预测小目标,尺寸相对较小的特征图用于预测相对较大的目标,这里通过对聚类中心面积的大小进行排序将这9 个预选框分配给特征金字塔网络的3 个特征层。

图7 聚类算法设定预选框
2.2.3 骨干网路结构有效性实验
该部分实验旨在判断不同的骨干网络结构对检测精度的影响,从而确定最佳的网络结构。对比实验中除了骨干网络的结构不同外其余的参数均相同,该部分的注意力机制均采用了特征金字塔Transformer,输入图像像素尺寸均为320 ×256,3D 卷积神经网络均输入连续16 张图片,采用IoU 阈值为0.5 的均值平均精度(mean average precision,mAP)δmAP作为评价指标。
对比单独使用2D 网络、单独使用3D 网络、同时使用2D 和3D 网络的实验精度结果,从表1数据可以看出,同时使用2D 和3D 网络具有最好的mAP 精度。
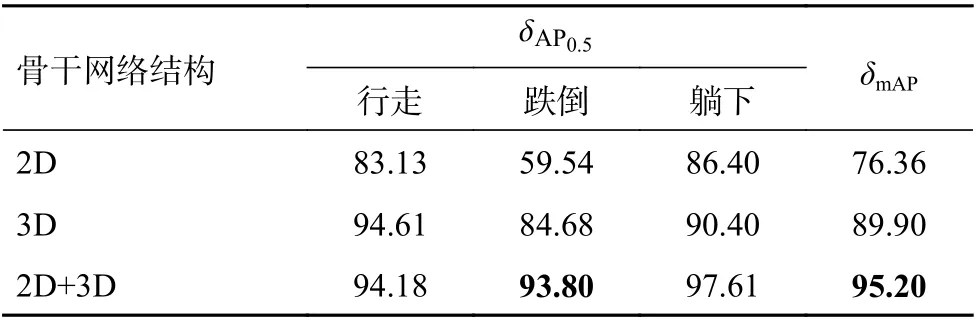
表1 不同网络结构实验精度结果 %
分析发现,单独使用2D 网络,无法提取时间维度上的特征。从跌倒这个动作中来看,这个动作无法从单个图片中确定,所以单独使用2D 网络得到该动作的AP 指标相比于其余2 组对比实验的实验结果低了很多;单独使用3D 网络相比于单独使用2D 网络的实验结果平均精度(average precision,AP)值δAP提 升 很 大,但 与 同 时 使用2D 和3D 网络的mAP 精度上还是有一定差距。这是因为3D 网络注重于提取时间维度的特征而缺乏空间维度的特征,从而导致边界框的定位不准。可以看出,同时使用2D 和3D 网络在动作时空定位任务上具有充分的有效性。
2.2.4 3D 网络图片输入数目实验
在2.2.3 节中对3D 网络用于跌倒动作检测的有效性进行了验证,由于动作具有连续性的特点,人类无法通过一帧图片判定一个动作的类别,同理计算机也如此。但是观察一个动作时间的或长或短,会对动作类别的预测产生影响。对于算法来说就是网络一次性该输入多少张连续图片这一问题值得深入探究。对此本文算法的3D 网络部分,作者通过实验进行了探究,发现输入图片数目为16 时具有最好的效果。分析其原因是因为当输入图片数目较少时,时间维度上提取的特征没有经过长时间的建模,包含的时间特征不够全面;而输入相对较多的图片时,很多动作持续时间较短,输入的图片序列中包含了其他动作的特征,造成网络学习混乱,效果也不佳。表2 为3D 网络一次性输入不同数目的图片时所对应的mAP 结果。
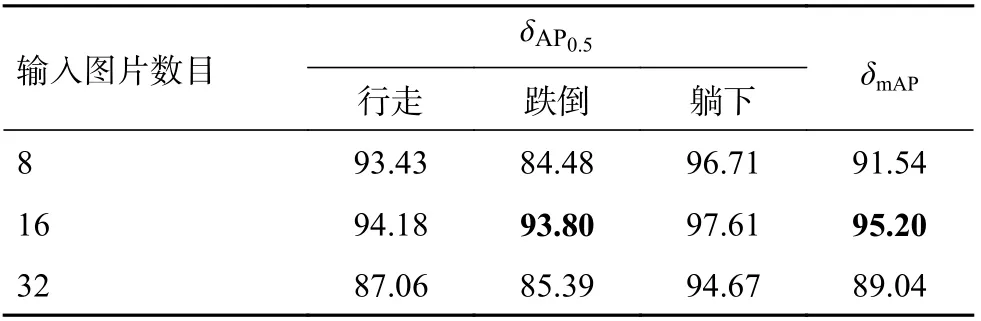
表2 3D 网络输入不同图片数目实验精度结果 %
2.2.5 Transformer 有效性实验
本文对骨干网络获得的特征采用了通道拼接的方法进行特征融合,融合后的2D 和3D 特征缺乏深层次的融合交互,本文为解决这个问题使用了Transformer 结构作为注意力机制,该结构应用在特征金字塔之后,可以融合不同预测特征层的特征,达到了特征跨空间、时间、尺度融合的目的。这部分实验将本文算法同通道注意力机制算法(Cam)和空间注意力算法(Sam)进行对比。表3的结果表明特征金字塔Transformer 结构对检测性能具有很大的提升。

表3 特征金字塔Transformer 结构有效性实验 %
3 结论
针对跌倒动作检测任务,本文提出了一种基于多特征融合及Transformer 结构的时空定位检测架构,通过Transformer 结构深度融合2D 和3D 网络提取的空间和时间维度以及不同尺度的特征,并通过一系列的对比实验证明了本文算法的有效性。本文算法相比于C3D 等算法不仅完成了动作的分类还实现了动作的时空定位。与仅使用2D 卷积网络相比,mAP 提升了14.84%;与仅使用3D 卷积网络相比,mAP 提升5.3%。加入Transformer 结构相比于传统注意力机制mAP 最少提升了1.44%,可见将本方法应用于跌倒动作的时空定位,具有相当大的理论和经济价值。
