基于Mixup 数据增强的LSTM-FCN 时间序列分类
2022-04-15王天刘兆英张婷刘博文李玉鑑
王天,刘兆英,张婷,刘博文,李玉鑑,2
1. 北京工业大学 信息学部,北京 100124
2. 桂林电子科技大学 人工智能研究院,广西 桂林 541004
时间序列是用按时间顺序排列的变量来表示事件的序列[1]。时间序列数据广泛地存在于生产生活中,例如股票的走向趋势、商品价格的变化波动、患者的心电图或者脑电波活动情况等等。分析时序数据对指导人们生产生活具有重大意义,例如医生通过观察病人的心电图判断其是否患病;经济学家观测股票分析其走向趋势。在这些时间序列分析问题中,时间序列分类(time series classification,TSC)[2]是一项比较重要且具有挑战性的任务。
目前深度学习已经在计算机视觉以及自然语言处理等多个领域得到极大的发展,基于神经网络的时间序列分类也取得了一定的进展。例如,Wang 等[3]提出了全卷积网络(fully convolutional network,FCN)和ResNet 模型,实现了端到端的训练过程,避免了复杂的特征工程。金海波[4]针对传统Shapelets 算法时间复杂度高的问题,提出一种快速发现算法,完成了算法的并行化。张国豪等[5]提出了一种结合卷积神经网络(convolutional neural networks,CNN) 和双向门控循环单元(gate recurrent unit,GRU)的模型结构,用于提取时间序列数据的卷积特征和时序特征,该模型利用了2 种特征信息完成了对时序数据的分类。胡紫音等[6]利用注意力机制在多元时序数据中进行特征选择,解决了高维数据特征提取问题。王会青等[7]利用反向传播神经网络提取时间序列特征用朴素贝叶斯分类,解决了有限数据集的分类问题。Iwana 等[8]提出5 种原型选择算法,并利用动态时间归整(dynamic time warping,DTW)[9]计算序列与原型之间的局部距离特征作为CNN 的输入,充分探索了局部距离特征的分类潜力。姜逸凡等[10]利用孪生网络衡量序列之间的相似性进行分类。Karim 等[11]尝试将长短时记忆网络(long short-term memory,LSTM)和全卷积网络结合提出了LSTM-FCN模型,该模型同时提取时间序列的局部特征和长期依赖关系,在多个数据集上取得了优于FCN、ResNet 等模型的结果。
以上对时间序列分类的研究中,几乎都是从模型的角度出发,通过设计不同的模型,提取高质量的特征,进而提高准确率,而鲜少从数据的角度出发。实际上许多应用中的标记数据存在局限性[12],例如数据量小、类别不平衡等,进而影响了模型的分类性能。
数据增强作为深度学习中常用的技术手段,可以通过扩充数据集提高模型性能[13-14],并在图像处理等领域得到了广泛的使用。然而类似的方法却不能很好地应用到时序数据[15],例如添加随机噪声[16]、随机形变[16]等增强方法。Forestier 等[17]提出的加权动态时间弯曲重心平均算法(weighted DTW barycenter averaging,wDBA),该算法以加权方式计算平均序列生成新样本,按照权重分配方式分为全平均[17](average all,AA)、选择平均[17](average selected,AS)和距离选择平均[17](average selected with distance,ASD)3 种方法。该算法虽然可以生成无限多样本,但是计算量较大,不适用于长序列。
Mixup[18]作为一种简单有效的数据增强方法,已经在图像分类中得到广泛的应用。为此,本文将Mixup 引用到时间序列数据中,并结合LSTM-FCN,提出Mixup 数据增强的LSTM-FCN算法。该算法首先使用Mixup 方法增强原始时间序列数据,得到新的增强数据;然后使用增强后的数据训练LSTM-FCN,并进行分类。
本文的主要贡献包括2 个方面:1)提出了一种Mixup 数据增强的LSTM-FCN 的时间序列分类算法,将Mixup 数据增强方法应用于时间序列数据;2)验证了Mixup 数据增强对时间序列分类的性能影响,在30 个UCR 数据集上的实验表明,Mixup 数据增强的LSTM-FCN 可以提高模型的分类准确率。
1 LSTM-FCN 模型
图1 给出了LSTM-FCN 模型的结构。从图1可以看出,该模型由2 个分支组成,分别为时序卷积分支和长短时记忆分支。其中,时序卷积分支采用了全卷积网络模型,该部分包含3 个卷积块,每一块都由一个一维卷积层、块归一化和ReLU 激活函数组成,最后一层由全局平均池化取代全连接层以减少模型参数;长短时记忆分支使用了一层LSTM 网络,同时加入Dropout 缓解模型的过拟合情况。最后拼接2 个分支的输出,并使用Softmax 对得到的特征进行分类。

图1 LSTM-FCN 结构
2 基于Mixup 数据增强的LSTMFCN 的时间序列分类
本节首先介绍提出的算法整体框架,然后详细介绍Mixup 数据增强算法,最后给出算法的完整训练过程。
2.1 算法整体流程
本文提出的基于Mixup 数据增强的LSTMFCN 时间序列分类算法包含2 部分:Mixup 数据增强和LSTM-FCN 分类模型,图2 给出了其整体流程图。具体来说,Mixup 在训练阶段首先对批量数据及其独热(one-hot)编码形式的标签进行混合,生成新的增强数据;然后将增强数据作为LSTM-FCN 的输入,训练LSTM-FCN 并输出分类结果。训练过程中使用混合标签计算交叉熵损失而不用原始标签。混合之后的标签以概率的形式表达了样本的类别,使得模型在预测结果时得到更平滑的估计。模型训练完成后,它已经学习到了良好的区分边界,在测试阶段将不再需要Mixup部分。

图2 模型框架
2.2 Mixup 数据增强
Mixup[18]是一种基于邻域风险原则的数据增强方法,该算法利用线性插值的方式对2 个样本和标签进行混合,一定程度上扩展了训练数据的分布空间,从而使模型的泛化能力得到提高。

Dmixup将作为一个迷你块用来训练模型。
Mixup 方法的主要思想是将经验狄拉克分布

Mixup 以经验邻域风险为原则优化网络模型参数,可以提高模型的不确定性估计能力,增强模型的泛化能力。
2.3 模型训练算法训练过程

模型训练算法给出了Mixup 数据增强的LSTM-FCN 的训练过程。具体来说,在训练过程中,每一步都会产生一个随机数,并对该批次数据使用Mixup 计算得到增强后的样本。经过多次迭代后,间接上增加了数据的多样性,丰富了数据分布。
3 实验结果与分析
本文实验在Windows10 环境下完成,CPU 为
Intel(R) Core(TM) i5-8300H CPU @ 2.30 GHz,GPU 为NVIDIA GeForce GTX 1050 Ti,代 码使用Pytorch 编写,使用分类准确率(Accuracy)Raccuracy和平均排名(Average rank)Raverage[20]来评估模型的性能。
3.1 数据集
本文使用UCRArchive2018[21]中的30 个数据集进行实验分析以验证本文算法的有效性。表1给出了这30 个数据集的基本信息,包括训练集和测试集样本个数、类别和长度。图3 给出了2 个数据集的示例样本,不同线段表示不同的类别。

表1 数据集信息

图3 数据集样本示例
3.2 参数设置
实验中,LSTM-FCN 的时序卷积分支的3 个卷积层采取了He 初始化,3 个卷积核大小分别为7×1、5 ×1和 3 ×1,数量分别为128、256和128。LSTM的隐含状态个数固定为8。优化器使用Adam 算法,学习率设置为0.001。训练过程中采取学习率衰减策略,当损失函数在30 个迭代次数内没有下降时,将学习率减小为原来的0.9 倍,直到学习率为0.000 1。迷你块大小设置为16,每个数据集训练2 000 次。数据集的 α参数设置如表2。

表2 Mixup 参数设置
3.3 本文方法与LSTM-FCN 在时间序列分类上的性能比较
本文在UCR 的30 个数据集上进行了对比实验,表3 给出了本文方法与LSTM-FCN 模型3 次训练结果的平均分类准确率,加粗数值表示最优结果。训练时间比表示本文方法训练模型花费时间与训练LSTM-FCN 花费时间的比值。

表3 本文方法和LSTM-FCN 结果
从 表3 可 以 看 出:1)使 用Mixup 增 强的LSTM-FCN 在26 个数据集上取得了不低于LSTM-FCN 的 平 均 分 类 准 确 率。 其 中,在CinCECGTorso 数 据 集 上,Mixup 增 强 的LSTMFCN 取得了91.50% 的分类准确率,与LSTMFCN 的结果相比,提高了4.79%,提升效果最为明显。2)Mixup 方法在小数据集(数量小于200)上的提升效果比较明显。例如,在ArrowHead、BeetleFly、Herring 以及Wine 等12 个数据集的准确率提升在1% 以上。3)所有数据集的训练时间比都在1 左右。这说明使用Mixup 数据增强后训练模型所花费的代价几乎与LSTM-FCN 相同,但使用Mixup 后模型取得了更好的分类准确率。
综合以上分析,Mixup 增强方法可以应用于时间序列数据中,并有效提高模型的分类性能,尤其适用于小样本的时间序列数据,这是因为小样本数据分布一般较为稀疏,不能充分反应真实数据的分布情况,但经过Mixup 方法生成增强数据后,可以填充原始数据中空白的分布空间,使模型更好地估计区分边界。
3.4 不同数据增强方法比较
为验证Mixup 的有效性,本节将其与wDBA[17]的3 种 方法(AA[17]、AS[17]和ASD[17]) 进 行比较。本文分别使用这4 种数据增强方法对数据增强,然后使用增强的数据训练LSTM-FCN 并测试。表4 给出了不同方法的结果,图4 展示了不同方法的可视化结果。
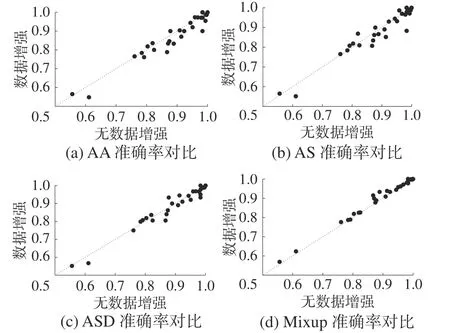
图4 不同数据增强方法的效果比较
1)从图4(d)可以看出,使用Mixup 后,多数数据集的准确率得到提升,从图4(a)、(b)、(c)中可以发现,AA、AS、ASD 方法虽然在一些数据集上提高了准确率,但还有一部分数据集准确率出现下降的情况。这说明Mixup 是一种更加通用的数据增强方法。
2)从 表4 可 以 看出:使 用Mixup 增 强的LSTM-FCN 在26 个数据集上取得了不低于LSTM-FCN 的结果,而AA、AS 和ASD 方法分别在第9、10 和13 这3 个数据集上取得了不低于LSTM-FCN 的 结 果;同 时,Mixup 分 别 在 第20、21 和22 这3 个数据集上取得了优于AA、AS 和ASD 方法的结果。 与其他3 种方法相比,Mixup 方法的平均准确率分别提升了2.49%、1.86%和1.57%,而且Mixup 方法取得了最高的平均 准 确 率90.28%; 另 外,Mixup 方 法 取 得了1.800 的最高平均排名,高于LSTM-FCN 的3.067,AA 的3.750,AS 的3.033 和ASD 的3.350。

表4 数据增强方法准确率比较 %
综合以上分析,不同的数据增强方法有助于提高模型的分类性能;此外,Mixup 方法取得了高于其他3 种数据增强方法的结果,这表明Mixup方法更适合于时间序列分类。
3.5 模型参数影响
本小节探索超参数 α对准确率的影响。选取10 个数据集,使用多个 α值{0.1, 0.2, 0.4, 0.8, 1.0,2.0, 4.0, 8.0}训练模型,观察其对分类性能的影响,结果如图5 所示。从图5 可以看出:
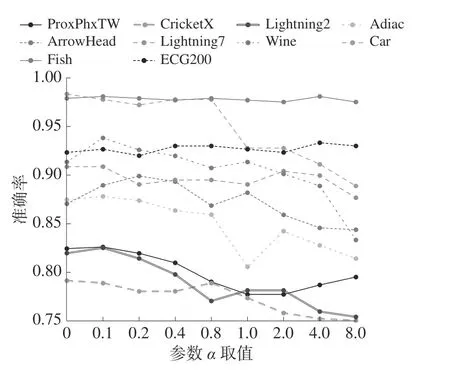
图5 不同 α值对准确率的影响
1)当 α增大时准确率整体上呈现下降的趋势。这是因为当 α变大时,数据的混合程度变强,导致合成数据的类别信息表达模糊,模型不能从其中提取到有效特征进行分类。
2)有5 个数据集在α=0.1 时取得了最优结果,例如,Adiac、Lightning2、Wine 等;此外,对于某些数据集,例如Fish 和ECG200,不同 α值对其影响较小,准确率没有表现出明显的变化;还有,在一些小数据集中可以看到较为明显的效果提升,例如Wine(数量57)和ArrowHead(数量36)。
总体来说,不同数据集对 α值的适应情况不同,本文还未能探索出自适应的方法确定 α的值,这是未来一个可能的研究方向。但是,大部分时序数据集在 α取0.1 时取得了最好的分类准确率,因此,本文推荐设置 α=0.1 为默认取值。
4 结论
本文使用数据增强方法改善分类效果,提出基于Mixup 和LSTM-FCN 的时间序列分类模型。首先使用Mixup 对原始数据进行增强,然后使用增强后的数据训练LSTM-FCN 网络,并进行分类。实验结果表明:
1)Mixup 可以应用于时序数据,并有效提高LSTM-FCN 的分类准确率;
2)与wDBA 方法相比,Mixup 具有明显优势;
3)Mixup 的性能受参数的影响,不同的参数会得到不同的性能。
未来将依据时间序列的特征,对Mixup 方法进行改进,使其更好地应用于时间序列数据,以进一步提高模型的性能。
