知识堆叠降噪自编码器
2022-04-14刘国梁余建波
刘国梁 余建波
知识的表述和推理一直是人工智能的热点话题,其中知识所代表的是数据特征与标签间存在的一般规律.在人工智能发展早期,符号规则用来表述知识并进行推理,研究者企图通过这种方式来以人类的思维模式解释机器的结论,而在这一过程中的规则定义为知识[1].符号形式的优点在于可以通过推导对知识进行验证,并且其规则推导过程都是可以理解的.
在大数据时代,以连接主义为核心的神经网络相较于符号系统具有更好的适应性.其中,深度学习[2]凭借其良好的特征学习性能近些年已经在各个领域得到了广泛应用.通过深度学习得到的深度网络即为具有深度结构的神经网络.在深度神经网络领域,Hinton等[3-4]基于深度置信网络(Deep belief network,DBN)提出非监督贪心逐层训练算法,为解决深层结构优化难题提供了解决办法,并进一步提出了堆叠自动编码器(Stacked auto encoder,SAE).Lecun等[5]提出了卷积神经网络(Convolutional neural network,CNN),利用空间相对关系以减少参数数目来提高反向传播算法的训练效果,在图像识别方面应用前景广阔.此外,深度学习还出现了一些变形结构,如堆叠降噪自编码器(Stacked denoising auto encoder,SDAE)[6].深度网络凭借其强大的学习能力广泛地应用于各个领域,但同时也据有不可忽视的 “黑箱问题”[7],即人类不能通过了解网络内部的结构和数值特性来得到数据特征和数据标签之间的关系,这一问题从根本上限制了深度神经网络的发展.
近年来,一些研究者开始探究如何将符号系统和神经网络相结合,其中一部分人希望通过符号规则所表示的逻辑关系来解释网络内部的结构和数值特性,另一部分希望将人类已知的知识通过符号系统传入神经网络以提高网络性能.Gallant[8]最先提出了一种使用IF-THEN 规则解释推理结论的神经网络专家系统.其后Towell等[7]提出基于知识的人工神经网络(Knowledge-based artificial neural network,KBANN),利用MofN 规则实现对神经网络的知识抽取和插入,通过这种方式解释网络并增强网络性能.Garcez等[9]在KBANN 的基础上提出了 CILP (Connectionist inductive learning and logic programming)系统,该系统将逻辑规则应用到初始化网络过程中,使网络可以更好地学习数据和知识.Fernando等[10]在KBANN 的基础上提出了INSS (Incremental neuro-symbolic system)系统,成功利用包含实数的分类规则初始化人工神经网络.Setiono[11]在前人的基础上从标准的三层前馈神经网络中抽取了IF-THEN 规则,该抽取算法最大的亮点在于将隐藏节点的激活值离散化.袁静等[12]尝试利用符号逻辑语言描述神经网络,并通过激活强度从理论上帮助规则进行推导.钱大群等[13]根据神经网络节点的输出值建立约束并生成规则.这种规则被用来解释神经网络的行为.黎明等[14]将模糊规则与神经网络相结合以提高模型的模式识别能力.在深度学习上更进一步的研究中,Penning等[15]提出神经符号认知代理模型(Neural-symbolic cognitive agent,NSCA),试图将时间符号知识规则与RTRBM (Recurrent temporal restricted Boltzmann machine)结合实现在线学习.Odense等[16]将受限玻尔兹曼机(Restricted Boltzmann machine,RBM)与MofN 规则相结合.深度置信网络(DBN)是由RBM 堆叠形成的,而这一研究的意义则在于这是对DBN 网络进行模块化解释的主要基础,也是对神经网络与符号结合的一种新思考.Tran等[17]在NSCA 的基础上将置信度规则与DBN 相结合,实现知识的抽取和插入.Li等[18]通过将符号系统与神经网络相结合形成神经符号系统,将符号主义与连接主义的优点集成,形成新的推理学习模型.Garcez等[19]提出了神经符号计算的概念,其中知识以符号的形式表示,而学习和推理由神经元计算.通过这种方式将神经网络的鲁棒学习和有效推理与符号的可解释性相结合.论文从知识的表示、提取、推理和学习方面进行讨论,并分别对基于规则、基于公式和基于嵌入的神经符号计算方法进行了论述.但是,上文所提到的知识提取与插入方法通常在浅层神经网络模型实施,对于深度神经网络模型的知识提取与插入有待深入展开.
本文提出了一种新的深度神经网络模型 ——知识堆叠降噪自编码器 (Knowledge-based stacked denoising autoencoder,KBSDAE),实现了符号系统与深度SDAE之间的有效集成,解决了深度神经网络的知识发现,特征提取与网络可视化问题.本文的主要贡献如下:1)提出了一种新的深度知识神经网络KBSDAE 模型,显著地提高了特征学习及模式识别性能;2)提出了一种从深度网络发现知识的方法,实现了深度网络可解释的目的;3)有效地将符号规则与分类规则相结合,获得了一种具有高推导性能的规则系统.最后采用各类标杆数据验证了本文所提出方法的有效性与可应用性.
1 堆叠降噪自编码器
自编码器(Autoencoders,AE)是基于神经网络的特征表达网络,由输入层 (x)、隐藏层 (h)和输出层 (y)构成,是深度学习的典型模型之一[6].它通过编码和解码运算重构输入数据,使得重构误差最小.通过这种方式得到输入数据的隐藏层表达,以达到特征提取的目的.因为学习过程中不存在数据标签,但是又以输入数据作为重构目标,所以认定该模型为自监督学习过程.
自编码器的编码阶段是输入层x到隐藏层h的过程,具体表示为
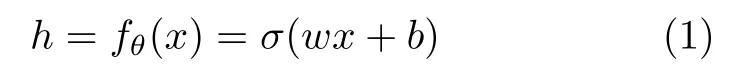
其中,σ是Sigmoid 非线性激活函数:σ(x)=1/(1+e-x),参数集合θ={w,b}.解码阶段是隐藏层h重构输出层y的过程,具体表示为

其中,σ′是Sigmoid 非线性激活函数,参数集合θ′={w′,b′}.
通过最小化重构误差函数L(x,y)=‖x-y‖2来逐步地调整网络内部的参数θ,θ′,优化方式选择随机梯度下降法.最优参数表示为

降噪自编码器(Denoising auto-encoder,DAE)是基于AE 的一种变形,通过噪声污染训练输入数据以增加网络的鲁棒性,防止过拟合[7].从图1 可以看到DAE 的训练过程,首先利用随机函数以一定的概率p将原训练数据x中的一些单元置零得到被污染的数据;通过编码和解码对进行重构;最后调整网络参数θ,θ′.在利用受污染的数据学习后,网络可以具有更好的鲁棒性.可以说,DAE 相较于传统的AE 具有更强的泛化能力.
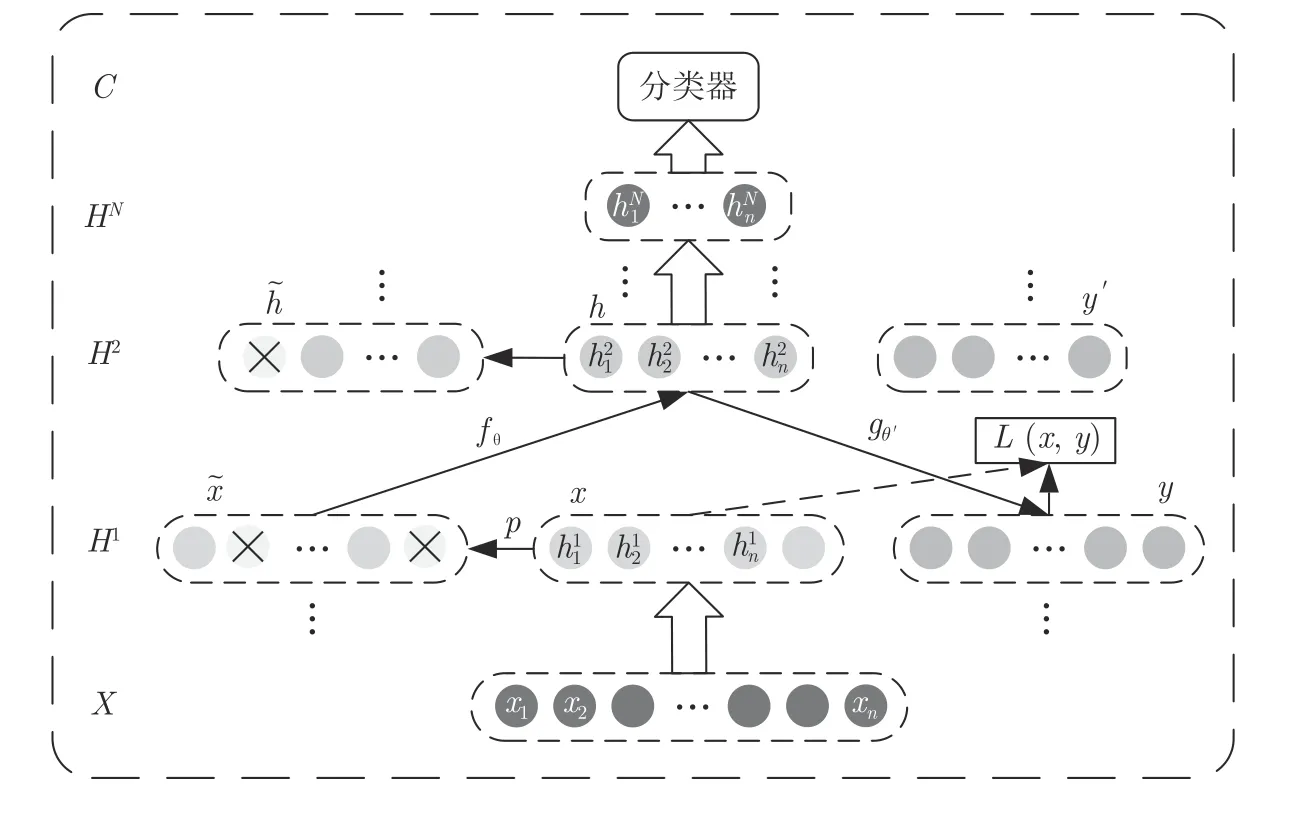
图1 堆叠降噪自编码器工作原理示意图Fig.1 Stacked denoising auroencoder working principle diagram
将若干个DAE 堆叠起来,就可以形成SDAE,如图1 所示.每一个DAE 都以前一个DAE 的隐藏层输出作为原始输入数据,添加噪声后利用被污染的数据进行训练.其训练过程首先是逐个DAE 贪婪训练,最后通过BP 算法[20]微调整个网络以获得最佳网络模型.
本文提出的KBSDAE 实现了深度网络知识抽取和插入目的,形成的KBSDAE 系统如图2 所示.下面将阐述知识抽取和插入的详细过程.

图2 KBSDAE 模型结构图Fig.2 KBSDAE model structure diagram
2 规则抽取与推理
本文提出的规则集是由置信度符号规则和分类规则合并而成的,两种形式规则的合成有助于规则集具有更高的可理解性和推理精度.对两种规则集分别建立了相应的规则抽取算法,并且面向规则推理过程中两者形式不同的问题,建立了一套基于惩罚逻辑[21]的完整推理算法.
2.1 混合规则
符号规则方面,传统逻辑符号规则有很多种表达形式,但是它们在复杂问题上的逻辑推理能力较弱.为了能描述深度神经网络,本文选择了一种数值和符号相结合的规则 ——置信度规则.这种规则存在以下特性:规则节点与网络神经元一一对应;规则节点间的逻辑关系是从网络中拓扑而出;规则置信值是对网络权值进行拟合得出的;即便面对复杂的大型规则结构也可以进行有效的数学推理.这些特性赋予符号规则两种能力:1)符号规则的结构与网络基本相同且元素一一对应,网络内部的逻辑关系可以被迁移到规则上作为一种网络内部关系的表现;2)规则可以作为深度神经网络的一种简化表示,具备一定的网络能力.所以符号规则的运行其实是对神经网络行为的一种简化模仿,而这种模仿过程是人类所能理解的.
置信度规则是一个符合充要条件的等式c:h ↔x1∧···∧xn,其中c属于实数类型,定义为置信值;h和xi(i∈[1,n])为假设命题,这种符号规则形式与文献[16]中的规则相似,但由于面向的网络不同,规则符号的意义也不同.本文定义具体的置信度符号规则为
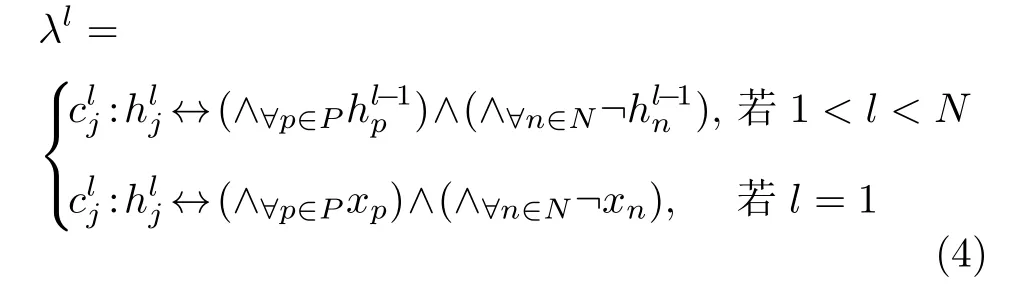
该规则可解释为:当x1,···,xn命题成立时,h命题也成立的置信值为c,反之亦成立.其中,是符号规则标签,解释为第l层第j个符号规则;代表DAE 中第l个隐藏层中第j个神经元;xi(i∈[1,n])代表DAE 输入层中第i个神经元,P和N分别代表对产生积极和消极影响的输入层神经元集合.根据表达式可以看出,符号规则的整体结构和堆叠的自编码器具有相似的堆叠嵌套结构,可以最大化复现网络结构.
分类规则的解释逻辑是对网络分类过程的一种模仿,由数值和逻辑符号组成.这种规则是从功能上对神经网络分类层的模仿,通过数值和符号定义不同类别的不同区间可以最大限度的对网络分类过程进行模仿和解释.同时,由于分类规则组成元素与置信度符号规则相同,故两者可以进行有效结合.具体的规则形式表示为

其中,ϕ是规则的标签,BN表示从置信度符号规则集中推导输出的可信值集,VN代表对应的实数集,y为类值标签,可以被赋值为某一类cl.该规则的解释为:当符号规则集输出的BN符合相应的条件时,可以判定这组数据属于某一类cl.
两种规则的合并即为本文提出的混合逻辑规则Rmix
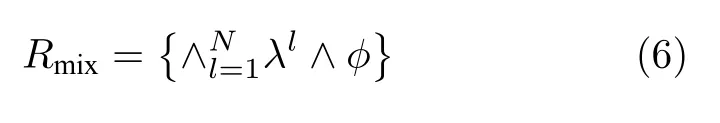
可以看出,它是由堆叠的多层置信度符号规则和分类规则混合而成.
2.2 符号规则抽取
符号规则抽取目标是每一个自编码器的编码阶段[17],抽取过程的核心原理是将规则置信度cjsj最大化拟合权重值wj.根据DAE 基本原理,其输入数据x到隐含表示h的映射表示为

根据式(7)提出新的函数,同样可以将数据x映射到隐藏层空间中
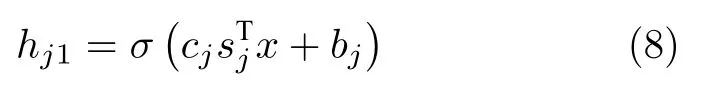
其中,cj是连续实数,sj∈{1,0,-1}是对wj的符号项表示,可以理解为sij=sign(wij).当xi或¬xi在规则j中时,sij分别等于1 或 -1,其余情况下sij等于0.对比式(7)和式(8)可以看出,二式的形式和元素基本相同.为了使hj1可以有效地代表隐藏层空间,需要找到合适的cj和sj,使hj1近似于hj.本文通过最小化wj与cj×sj之间的欧氏距离实现拟合过程
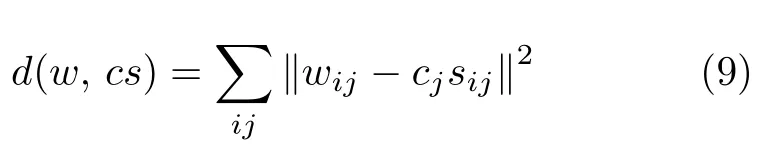
在提取cj的过程中,对式(8)进行求导并令其等于零,即∑

经过数学推导,最终可以得到cj的表达式为

进一步对式(9)分析,可得

可知,如果想要欧氏距离最小,需要在sij=1或sij=0的情况下.进一步,如果一个元素对应的欧氏距离只有在sij=0 的情况下最小,那么可以判定该元素xi不应该出现在规则hj中.即
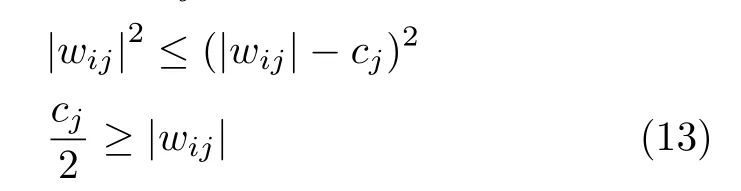
可知,当 2|wij|≤cj时,对应的元素不应出现在规则中.通过式(11)和式(13)可以得到一种具有强连接关系和判定系数的符号规则集,能够更加紧凑地描述DAE 网络.
根据上述分析,从DAE 网络中抽取置信度符号规则的具体算法DAE_CRE 可参考文献[17]的规则抽取算法.SDAE 是由DAE 编码网络堆叠而成的,只需将DAE_CRE算法迭代运行,就能抽取出SDAE 编码器部分的置信度符号规则集.同时,通过上述方法得到的规则集具有堆叠嵌套结构,这有助于规则集的推理性.
2.3 分类规则抽取
置信度符号规则可以表示SDAE 的堆叠编码器部分,但是在分类层的表示上存在较大的信息损失[17].为了更加准确地解释SDAE,本文运用数据挖掘领域分类规则的相关知识,从统计意义上解释分类层.为了与之前的符号规则保持一致性,分类规则的基本形式也是IF-THEN.
利用遗传算法(Genetic algorithm,GA)[22]挖掘符号规则推导出的置信值与分类标签之间的关系是分类规则抽取算法的核心思想.在实验中发现,从符号规则中推导出的置信度集合存在数据间差异过小的问题.这使得一般的GA 编码方式得到的规则性能较低.针对上述问题,本文改进了Yu等[23]的编码方式,使分类规则性能提高的同时让规则更加紧凑简单.算法基因的构成如表1 所示,每一个基因由状态判别量(Active,Act)、符号判别量(Distinguished symbol,DS)、具体数值(Value,V)三个元素组成.N个这样的基因按照特征的顺序组成了染色体,N为特征数量.

表1 遗传算法基因编码示意表Table 1 Genetic algorithm gene coding schematic
本文选用的GA 算法适应度函数是较为普遍的规则质量评估函数:

其中,TP表示被判断为正样本,实际上也是正样本;FN表示被判断为负样本,实际上也是负样本;TN表示被判断为负样本,但实际上是正样本;FP表示被判断为正样本,但实际上是负样本.(TP/(TP+FN))和 (TN/(FP+TN))分别表示每条规则对该类别的敏感度和特异性.通过这个适应度函数,可以得到对每一个分类都具有高敏感度和特异性的规则.
2.4 规则推理
由于符号规则与分类规则的表现形式不同,需要特定的推导方法才能使混合规则集具有可推导性,抽取的规则集的意义才能显现.本文提出的推导方法(Rule-INF)分成两个部分:符号规则部分和分类规则部分.符号规则的推导借鉴了文献[21]中惩罚逻辑的思想并加以改善.通过置信度值的数值特性,符号规则的推导突破了二值的限制,可以用于推导大量的连续性数据.分类规则的推导将符号规则输出的置信值与规则一一对照,寻找出符合条件的规则并进行分类.具体的推导算法如算法1 所示.
算法 1.Rule-INF 算法


3 KBSDAE
本节将讨论如何利用混合规则集Rmix初始化并训练KBSDAE,这种初始化过程可以看作是一种迁移学习,即在网络创建的初始阶段就赋予深度网络有效的知识.通过这种方式得到的KBSDAE网络具有更快的收敛速度和更高的识别精度.混合规则包含符号规则和分类规则,它们分别对应初始化KBSDAE 的编码部分和分类器部分,本节将分别讨论初始化KBSDAE 不同训练阶段的方法.
3.1 DAE 学习阶段
基于Tran等[17]的符号规则与DBN 相结合的思想,本文首先筛选出置信度较高的分类规则束,其次利用符号规则初始化DAE 网络,最后利用特殊的参数更新策略完成训练.
符号规则束筛选算法Rule-Screen 基于符号规则的置信度运行.由于规则结构具有迭代嵌套特性,可以看作一种类似树状结构,所以将规则集分割为规则束以作为筛选目标.每个规则束的置信度值通过推导算法得到,最终选取置信度较高的规则用于初始化网络.具体的算法流程如算法2 所示,将第1 层符号规则集的置信度值作为输入在符号规则集中进行推导,并最终筛选出置信度高的n个规则束.通过这种方法将规则集中最可信的规则用于网络初始化,在不造成信息过度损失的情况下简化初始化过程.在本文中,规则筛选率为1/n=0.3,该参数的选取依据参照文献[24].实验发现,利用算法2 得到的规则束囊括了各层符号规则中的高置信度规则,这从另一个方面证明了算法的有效性.
算法 2.Rule-Screen 算法


由于符号规则的结构与DAE 的编码阶段基本相同,本文将规则中的元素和置信度值分别初始化为对应网络中的神经元和连接权重,并且在网络训练过程中抑制被初始化参数的更新,使知识得以保留.具体训练步骤如下.
步骤 1.建立一个SDAE,其结构和抽取规则的原网络相同.对每一个规则cj:hj↔x1∧···∧xn,hj&x1∧···∧xn分别对应目标网络的隐藏层神经元以及输入层神经元集.注意,这些神经元集的排列位置应与原网络位置相同.
步骤 2.确定在hj与x1···xn之间的连接权重.如果输入神经元对应规则中的xp,那么s=1;反之,则s=-1.其余的与hj没有关联以及隐藏层与输出层之间的权重设为较小的随机值.神经元偏差设为随机值.
步骤 3.利用BP 算法训练DAE,其中被规则初始化的连接权重不被更新.为了保证代入的规则在训练过程中与网络较好嵌合,利用随机数对隐藏层神经元输出进行二值化处理:随机生成一个数值为0-1 的随机数R,如果hj>R,那么hj=1;反之,则hj=0.
步骤 4.自上而下地对每一个DAE 重复执行步骤1~3,直到编码部分训练完成.
3.2 Fine-tuning 阶段
分类规则的结构形式与SDAE 的分类层结构不同,不能直接进行初始化过程.本文将KBANN[7]的相关知识融入到KBSDAE 的分类层中,训练过程如图3 所示.但是本文所定义的分类规则包含实数集和符号集,而只针对符号规则的KBANN 方法在这里并不能完全适用.为了将分类规则中的实数知识初始化入网络中,本文借鉴了Fernando等[10]提出的INSS 系统思想,利用实数型规则初始化网络.

图3 KBSDAE 的Fine-tuning 阶段示意图Fig.3 Fine-tuning diagram of KBSDAE
初始化分类层的核心步骤是,利用分类规则在分类层和DAEs 中间新增加一个隐藏层,定义为lN+1.对每一个规则基本元素对应网络中DAEs 部分最后一个隐藏层的神经元,VnN对应新建隐藏层lN+1中的神经元,类标签值clj对应分类层神经元.具体的权值和偏置值初始化方法如图4所示.图4 以一条分类规则为例,展示了这条规则初始化网络的全过程,其中P代表连向该单元的神经元数目,w和C分别代表分类规则的灵敏度和可信度.为了更清晰地表达,图4 省略了大部分连接线.本文中定义Weight2=1.需要注意的是,为了提高被初始化网络的泛化性,微调过程中在新隐藏层lN+1和编码阶段顶层lN分别新加25 个神经元,这种操作在KBANN[7]中被证明是有效的.

图4 分类规则初始化网络算法示意图Fig.4 Classification rule initialize network algorithm diagram
4 实验与结果分析
4.1 规则有效性验证
为验证抽取知识的有效性.利用数据关系已知的简单数据训练自编码器,并从编码过程中抽取知识.如果抽取出规则所代表的知识与已知数据关系相符,那么可以证明从网络中抽取特征间知识的有效性.本文利用具有异或关系的数据对自编码器AE 进行训练,并从编码过程中抽取符号规则集.该实验的目的在于验证从不同规模的AE 提取出的符号规则是否也具有异或特性.输入数据具有三个维度x,y,z,它们具有z↔x ⊕y关系的同时还具有x ↔y ⊕z和y↔x ⊕z关系.通过训练让DAE 学习异或关系.
从不同DAE 中提取的部分符号规则如表2 所示.其中与输入数据关系相符的规则具有较大的置信度,反之只具有很小的置信度,并且从不同规模网络中抽取出的规则都基本符合数据关系.这证实了本文所提出的符号规则体系可以有效拓扑并抽取出网络中的知识.尽管抽取过程存在一定的信息损失,但是依旧可以很好地表示DAE 的编码过程.

表2 部分DAE 符号规则抽取结果Table 2 DAE symbol rule extraction result
为了验证符号规则是否也能够像DAE 一样提取特征,本文利用三种特征维度较高且数据特征与标签间的关系不明显的数据集分别对不同规模的DAEs 进行训练并抽取规则.一般情况下,相较于原始数据,经过DAE 编码后输出的数据具有更低的维度,而利用这种低纬度数据训练的支持向量机(Suppprt vector machine,SVM)一般具有更好的分类结果.如果相应置信度符号规则对输入的原始数据经过推导后所输出的低纬度数据也可以提升SVM 的分类结果,那么可以证明从DAE 中提取出来的规则具备同样的特征提取能力.
利用DAE 无监督训练后输出的降维数据和对应规则推导得到的置信值集合分别对SVM 进行训练并测试分类性能,其中SVM 选用线性核函数.数据集包含MNIST 手写数字数据集、HAR 人体活动识别数据集、数据集的图像中每个像素有256 (0~255)灰度级,将这些图像归一化到区间[0,1].MNIST 数据集包含 60 000 个训练数据和10 000个测试数据集.为了提高训练效率,本文首先选取10 000个训练数据和2 000 个验证数据训练初始网络.之后选取分类效果最好的初始网络并利用完整的60 000个数据进行训练.最后再利用10 000 个测试数据进行测试.HAR 数据包含由智能手机收集的561 维特征以及对应的6 种人物动作,有8 239 个训练数据集和2 060 个测试数据集.训练模型的参数:DAE 的学习率为0.01~1 之间,噪声率在0.2~0.5 之间.SVM 的惩罚系数在0.01~1 之间.
利用SVM 对不同数据进行10 折交叉训练的结果如表3 所示.相较于原始数据,经过DAEs 或对应符号规则提取特征的低维数据具有更好的可分性.虽然规则的特征提取能力和相应DAEs 之间存在差距,但是从某种意义上讲,DAEs 中抽取的规则可以在一定程度上代表DAEs,故规则也具有稳定降维的能力.
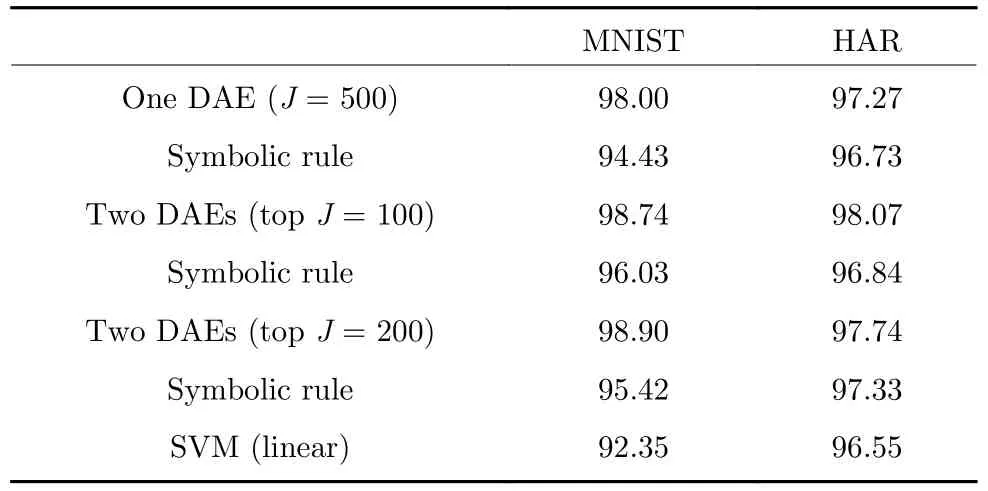
表3 复杂数据集降维后SVM 10 折交叉分类结果(%)Table 3 Ten-fold cross-classification results of dimensionally reduced complex data on SVM (%)
4.2 混合规则可推导解释性验证
为了验证混合规则的可推导性和可解释性,利用DNA promoter[25]数据集训练网络并抽取规则.该数据集普遍应用于验证网络-符号系统,数据集具有106 例数据,分成53 个激活项数据和53 个不激活项数据,每一例数据由DNA 的-50~7 位置上的染色体状态组成(A,T,G,C).将染色体状态进行one-hot 编码以方便网络学习,如:A=(1,0,0,0),T=(0,1,0,0)等.经过数据处理,原数据变为228 维数据.随机选取86 例训练数据,20 例预测数据.首先利用数据分别训练5 个单层SDAE,网络规模为228-3-2 (即:单层SDAE 的输入神经元个数为228 (输入数据为228 维数据),SDAE 的隐层神经元个数为3,输出层神经元个数为2 (根据分类数确定,此处为激活项与不激活项两类)),两个训练阶段的学习率分别为0.01和1,DAE 训练阶段噪声率为0.1.这些网络在测试集上的平均识别精度为90%,而对应抽取出的规则在测试集上的平均推导识别精度为91.52%.具体的分类规则如表4 所示,可以看出本文提出的混合规则具有较高的推导判别性能.

表4 基于DNA promoter 的分类规则明细表(%)Table 4 Classification rule schedule based on DNA promoter (%)
在模型的可解释方面,本文所提出模型的核心思想为符号与网络相结合,而规则就是对网络的一种模拟和解释.接下来我们将尝试利用规则对网络进行解释并验证.基于DNA promoter 数据集的模型规则如表3和表4 所示.表5 包含了3 个隐藏神经元所对应的部分规则以及DNA promoter 数据集固有的基本规则,其中 “[]”表示为任意碱基都成立;“T (A)”表示T 或A 在该位置出现都算假设成立.以为例解释网络行为:如果输入数据在规则片段1 对应位置的碱基排列为 “TTG (Tor A)C”;在规则片段2 对应位置的碱基排列为 “(Tor A)AAAGC”;在规则片段3 对应位置的碱基排列为“AATAA”,那么DAE 的隐藏层神经元h2的输出值则尽可能大.根据表4 的分类规则,如果h2和h3足够大,就将这一数据定义为 “promoter”.上述的过程为规则推导的过程,也在一定意义上解释了神经网络内部的运行机理.为了验证这种解释是否正确,将抽取出的规则与数据的固有基本规则进行对比,可以发现基本规则与生成规则所对应的地方基本相符,这也验证了利用规则抽取网络内部知识的有效性.
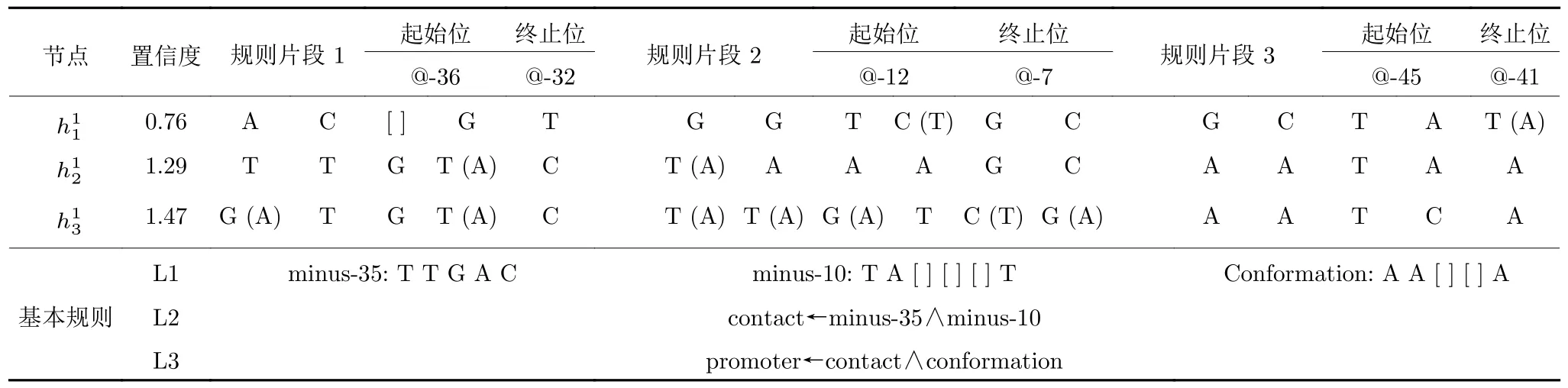
表5 基于DNA promote 数据集的部分符号规则明细Table 5 Partial symbol rule details based on DNA promote
对比规则和标准网络在相同测试数据下的推导精度,以验证规则的高精度推导能力和稳定性.根据不同训练数据量,分别连续训练20 个标准单层DAE 网络并从中抽取规则.利用20 例测试数据分别对每一个网络和其对应的规则进行精度测试,结果如图5 所示.图中横坐标表示标准网络在测试集上的预测精度,纵坐标表示规则在测试集上的推导精度.可以看出,测试结果大部分都落在对角线周围,这证明规则推导精度和对应的标准网络大体相当,且具有较高稳定性.即便训练数据量发生变化,推导精度也不会发生突变.

图5 SDAE和对应混合规则DNA promoter 的识别率对比(%)Fig.5 Comparison of DNA promoter recognition rate between SDAE and corresponding blending rules (%)
4.3 标准数据集验证
KBSDAE 在构建过程中创造性地同时利用两种不同类型的规则进行网络确定与权重参数初始化,其网络结构以及训练方法都与传统SDAE 有所不同.因此,本文采用UCI 数据库[26]中的经典标准数据(如表6 所示)对KBSDAE 的分类性能进行测试,并与其他典型分类器进行比较.
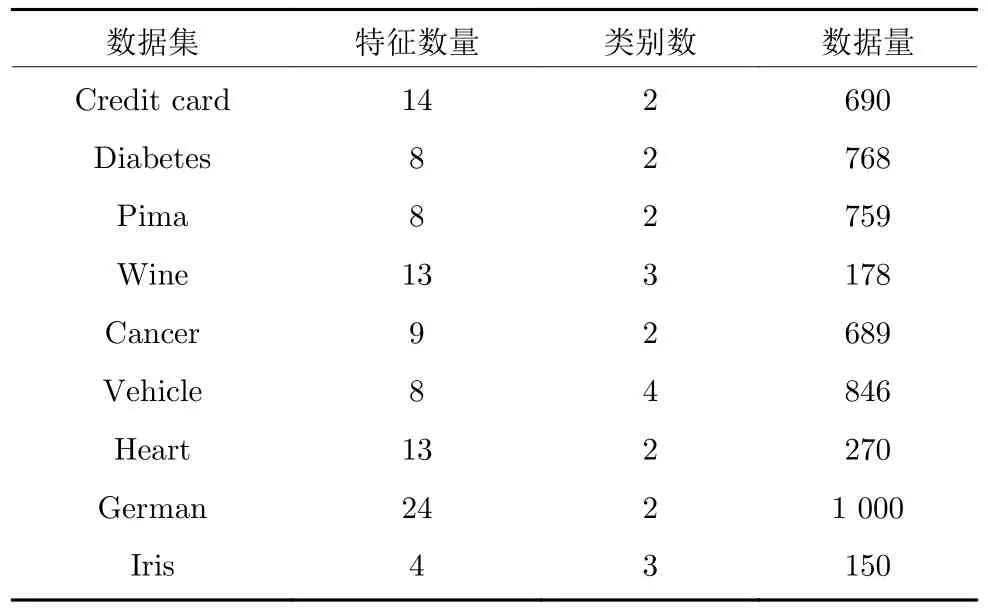
表6 UCI 数据集信息Table 6 UCI dataset information
KBSDAE 的网络结构为两个DAE 堆叠(第1个DAE 隐藏层神经元数稍大于输入特征数,第2个DAE 隐藏层神经元数稍小于输入特征数),外加一层由分类规则初始化出的隐藏层lN+1,该层神经元数根据分类规则变化,最后堆叠一个Softmax 分类层.两个训练阶段的学习率在0~0.01 之间,噪声率在0.01~0.3 之间.DAE 迭代训练200 次,Finetuning 阶段迭代50 次,其余分类器的迭代次数与之相似.对比的网络有DBN,网络结构为两个RBM 堆叠,其结构与KBSDAE 相似,两个训练阶段学习率在0.1~1 之间,RBM 训练阶段的动量为0.05~0.3;Sym-DBN 模型来自于文献[17],是一种符号规则和DBN 相结合的模型,其网络结构与DBN 相同,两阶段学习率在0.01~0.2 之间,RBM训练阶段的动量为0.05~0.3.SDAE 为两层DAE堆叠而成,网络结构与参数和KBSDAE 相同.INSS-KBANN[10]中的规则由GA 算法直接从训练数据集中挖掘,包含一个隐藏层,学习率在0.1~1 之间,迭代训练200 次.BPNN 模型结构与KBSDAE相同,学习率在0.1~1 之间,迭代训练300 次.
如表7 所示,其中所有识别器的测试结果都是经过5 折交叉[27]后得到.在实验过程中,将数据随机等分成5 份,其中4 份作为训练数据,另外一份作为测试数据.实验连续进行5 次,保证每一份数据都成为过测试集和训练集.实验结果证明,KBSDAE的分类性能相较于传统的机器学习分类器有较为明显的提升.特别地,KBSDAE 明显优于SDAE,这说明符号规则与分类规则融合的SDAE设计方法显著提高了其特征学习与识别性能.
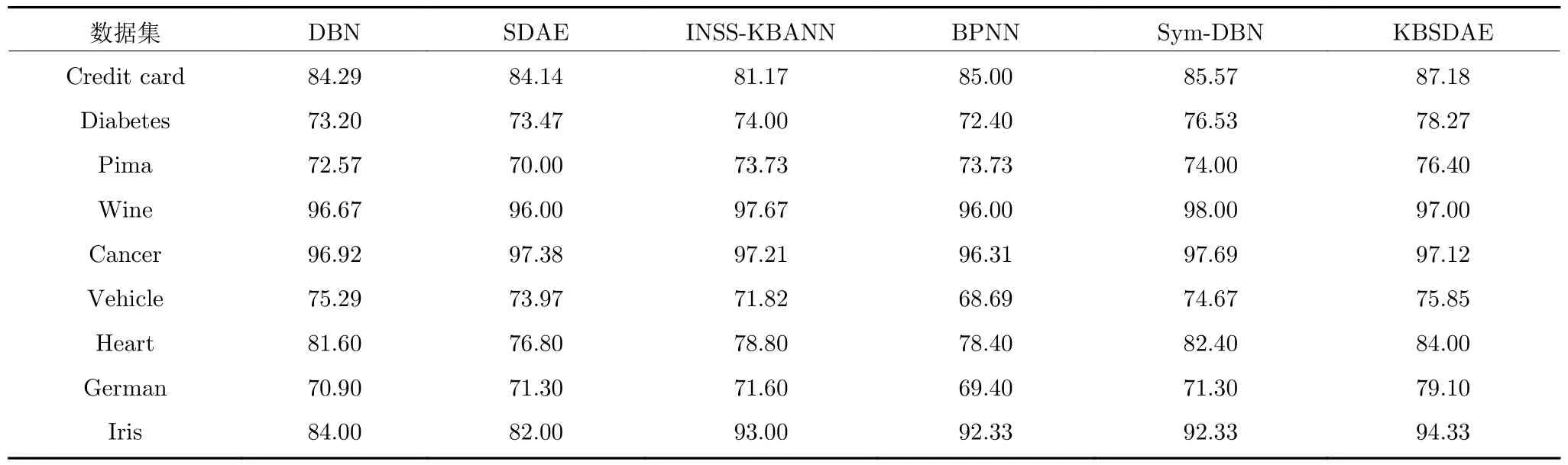
表7 UCI 数据集信息 (%)Table 7 UCI dataset information (%)
知识代入过程中对网络的影响在于初始化阶段.网络的初始化对网络的训练过程具有较大的影响[7].为了验证利用知识初始化网络是否可以带来积极影响,本文利用 HAR 数据集建立KBSDAE 网络,并记录了KBSDAE 在无监督训练和微调阶段的均方误差(Mean square error,MSE)变化.MSE 可以很好地描述网络在训练过程中的分类性能变化.从图6 可以看出,无论是在无监督还是在微调阶段,KBSDAE 的MSE相较于规模相同的SDAE 都具有更低的起点、更快的收敛速度和更低的收敛区间.这证明了利用知识初始化网络所带来的积极影响,进一步证明了本文提出方法的有效性.
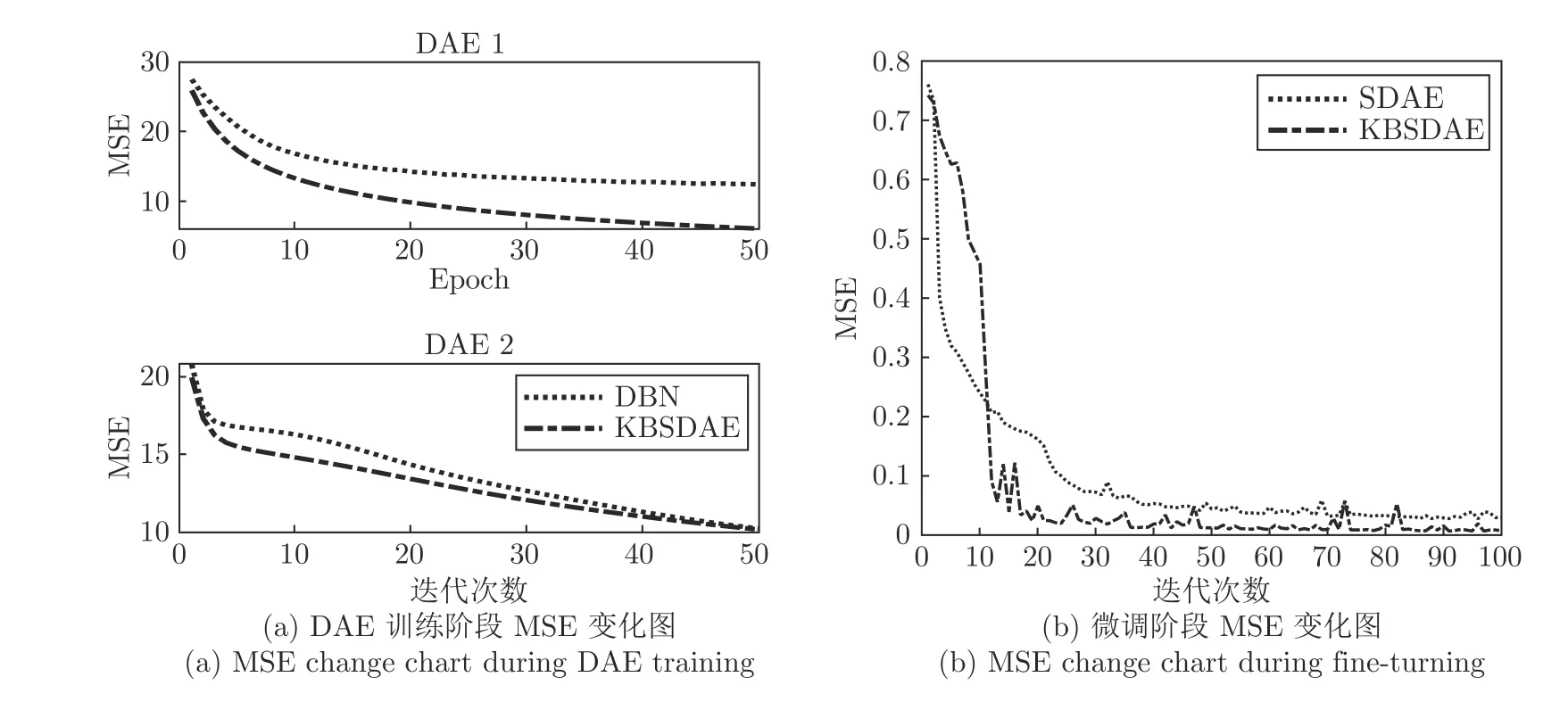
图6 KBSDAE和SDAE 在HAR 数据集上训练过程的均方误差变化对比Fig.6 Comparison of mean square error of KBSDAE and SDAE training process on HAR dataset
为了进一步验证KBSDAE 模型在处理复杂分类问题时能否有效进行分类,选取了两种标准数据集:USPS 手写数据集以及HAR 数据集[28].对比了SDAE和KBSDAE 的类识别性能.具体的实验数据如表8 所示.从表中可以看出,在结构参数基本相同的情况下,KBSDAE 与SDAE 的分类情况类似,故认定KBSDAE 不存在类识别不平衡问题.值得注意的是,文献[27]利用改进的支持向量机处理HAR 数据集的分类问题,识别精度最高仅达到89.3%,而KBSDAE 可以达到98.5%的识别精度.
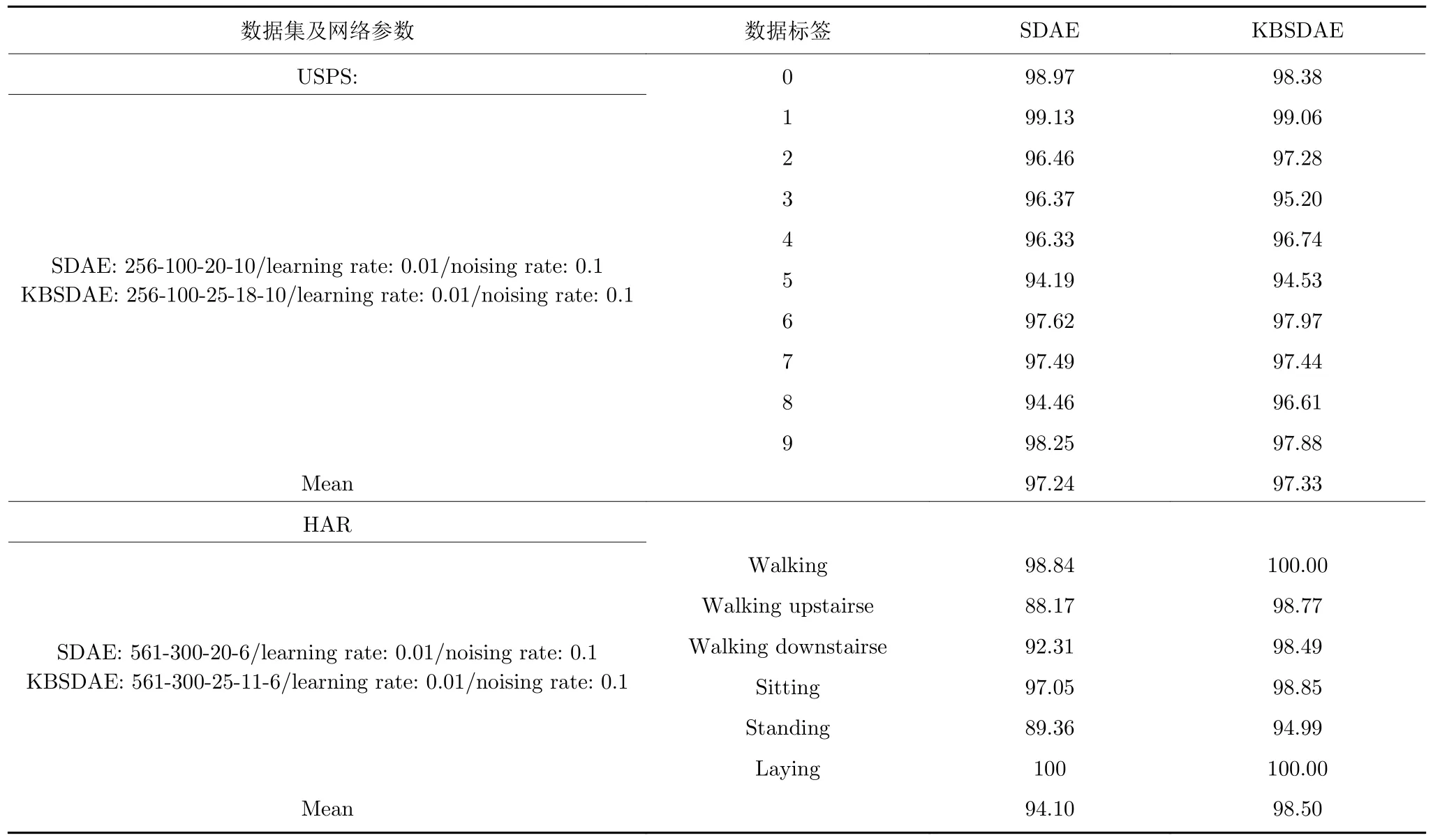
表8 复杂数据集分类结果对比(%)Table 8 Classification results of comparison on complex datasets (%)
为了验证KBSDAE 在复杂数据集上的分类性能是否足够优越.本文选取了目前较为主流的一维分类器和符号神经模型在USPS和HAR 数据集上进行分类结果横向对比.结果如表9 所示,其中所有结果都是5 折交叉后得到的.可以看出,KBSDAE相较于其他分类模型具有更好的分类效果.
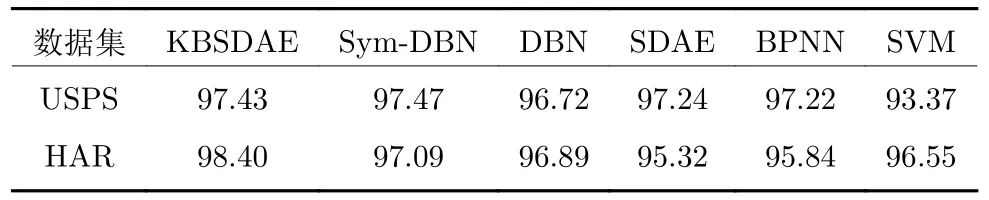
表9 复杂数据集5 折交叉分类结果对比(%)Table 9 Comparison of five-fold cross-classification results on complex datasets (%)
4.4 灵敏度分析
为了验证规则中的知识是否能赋予网络一定的分类性能以及KBSDAE 对数据的敏感度,对比了不同训练数据量下网络模型的预测精度.本文利用DNA promoter 数据分别训练SDAE和KBSDAE.训练数据量从10 开始逐渐递增.训练后的网络利用20 个测试数据进行识别性能测试,结果如图7所示,在训练数据量很小的情况下,KBSDAE 依旧具有高识别精度,这是由于知识代入网络的结果.并且,随着训练数据量的增加KBSDAE 识别精度也稳定高于传统SDAE.
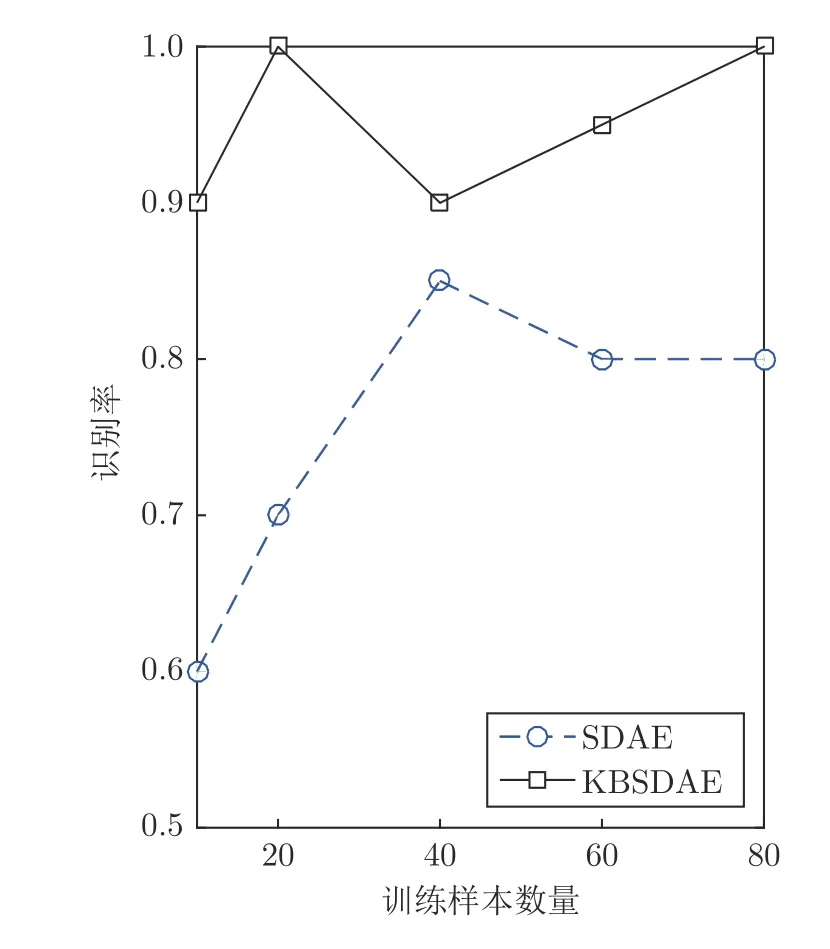
图7 不同DNA promoter 数据量训练的SDAE 与KBSDAE 分类性能对比Fig.7 Comparison of classification performance between SDAE and KBSDAE trained by different DNA promoter data
为进一步验证知识代入网络的过程是否有效,对比了KBSDAE和SDAE 在不进行Fine-tuning和只进行几步Fine-tuning 后的测试精度.利用DNA promoter 数据集分别建立了结构和训练参数相同的SDAE和KBSDAE,其中两个训练阶段的学习率分别为0.01和1,DAE 训练阶段噪声率为0.1.实验结果如图8 所示,可以看到KBSDAE 在不进行Fine-tuning 的情况下仍具有80%的测试精度,与SDAE 的51%测试精度相比提升明显,这进一步证明了利用规则将知识代入网络中的方法是有效的.经过前几步Fine-tuning 后的KBSDAE 测试精度普遍高于SDAE,证明了将知识代入网络可以显著提高网络的分类性能.
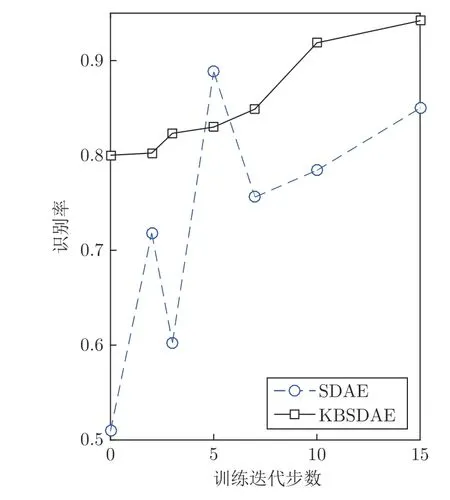
图8 不同Fine-tuning 训练步数的SDAE 与KBSDAE 分类性能对比Fig.8 Comparison of SDAE and KBSDAE classification performance of different fine-tuning training steps
5 结束语
面对深度神经网络的 “黑箱问题”,本文提出了一套全新的知识表达规则系统,尝试解释并强化深度神经网络.该系统可以对SDAE 网络进行简单表示并从SDAE 中抽取和插入知识.通过这套系统,可以理解到网络内部的知识并建立性能更加强大的KBSDAE.规则系统创新性的将符号类型和数值类型的规则进行有机结合,使得这种混合规则具有较高的推导性能和可理解性,在网络规模愈加复杂的当下这种规则形式不失为一条具有研究价值的路径.实验证明,混合规则系统可以有效表示网络并提取网络知识,具有高推导精度和稳定性.利用规则初始化后的KBSDAE 相较于传统SDAE 具有更快的收敛速度,更高的预测精度和数据灵敏度.下一步可以将规则与深度网络可视化相结合以提升对网络的解释能力.可以尝试解释更复杂和庞大的网络,如卷积神经网络.
