大数据背景下服装品牌知识挖掘研究
2022-04-14杨丽丽刘静伟
杨丽丽,刘静伟
(西安工程大学 服装与艺术设计学院,陕西 西安 710048)
大数据时代产生了海量的数据,但是数据类型多元异构、网页发布不规范等因素导致数据价值密度低,信息造价昂贵。大数据分析和数据挖掘是基于统计分析学的从数据中获取知识的一种研究方法,在互联网、金融、医疗等多个行业都有很好的发展与应用。语料库分析法在国外已有三十年以上的研究历史,目前服装领域内多使用学术文献作为研究语料库进行行业信息发现和预测,缺乏对其他行业数据的探索与使用;为了提高服装行业对开源数据的利用率,构建行业语料库、通过合理的数据分析工具对行业数据进行知识挖掘,对行业知识工程的建设具有重要的实践意义。
1 服装品牌研究语料库构建
1.1 数据渠道选择
为保证语料库中服装品牌数据的多样性和全面性需对采集渠道进行评估筛选,最终确定的数据源类型如下:
(1)服装专业平台和品牌网站:如WGSN、POP 流行趋势平台,中国时尚网、中国报告大厅等网站。
(2)学术资源平台:CNKI 数据库。
(3)通用知识网站:如百度百科知识库。
1.2 研究样本选择
进行品牌调研,围绕“服装品牌排行”检索知名度较高、数据信息分布较多的服装品牌。共选择了60 个服装品牌,主要可分为以下几种类型。
(1)国际奢侈品牌。如阿玛尼、巴宝莉等共32 个。
(2)国内具有一定创建历史与知名度的服装品牌。如劲霸、七匹狼等共10 个中国品牌。
(3)潮牌与户外品牌。如LARGE、SUPREME、户外品牌始祖鸟、哥伦比亚等共18 个。
1.3 数据采集与整理
网络爬虫是进行大数据收集的主要技术手段。采集过程以爬虫(后裔采集器)采集为主,人工采集为辅。
通用类数据平台结构简单,先用采集器进行数据爬取,再对结果进行人工筛选降重,以减少数据噪音;专业类平台,如WGSN、POP,CNKI 有权限限制,平台结构复杂,采集过程主要依赖人工。
采集过程中总结出如下数据分布特点:
通用网络平台如百度百科、品牌、服装网,数据重复率高类型单一;学术平台的数据语料,类型丰富但噪音大。通用网络上国际服装品牌的数据量和信息价值多于国内的服装品牌,学术平台数据则呈现相反趋势。奢侈等级越高,其受众群体小,数据缺乏,如定制类品牌Brioni。
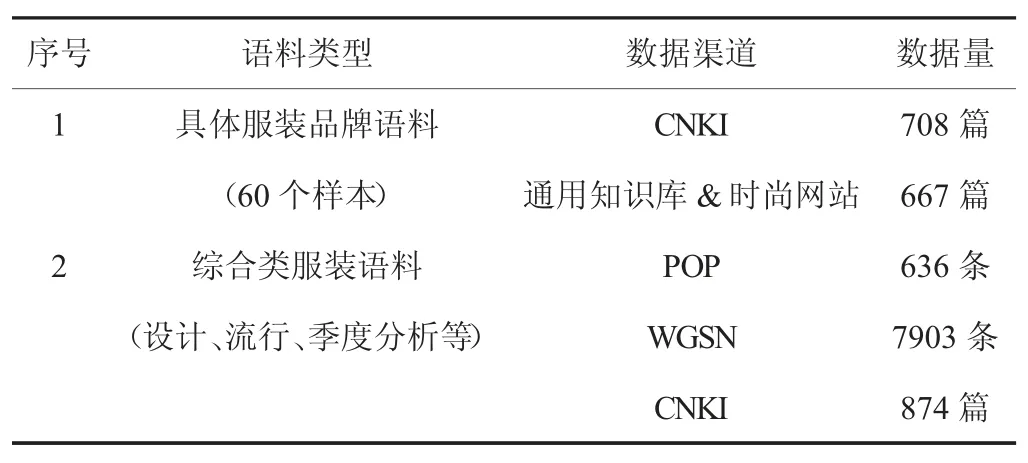
表1 采集数据统计Tab.1 Data collection statistics
2 服装品牌数据挖掘
2.1 数据预处理
数据研究过程使用的是定量内容分析和数据挖掘软件KH Coder,该软件有特征抽取、语义共现、文本聚类、主题分析等功能,适用于大量型非结构化文本的分析。为提高数据挖掘的效率和质量,数据预处理步骤如下:
(1)数据集成与格式规范:数据格式整理为单个CSV/Excel表格或批量TXT 文本。以品牌为例,每一个品牌数据合并在一个TXT 文档里,以品牌名称和定义的序号命名,汇总在文件夹下。CSV 文件中,第一列为分析数据,第二列第三列可设置外部变量。
(2)词类筛选与定义:选择跟分析目的相关的词性,排除无意义词汇对数据结果的影响。一般主要选择名词、专业用词、形容词、标签。
(3)编码规则编写:KH 编码器可以自定义编码规则,执行编码。如“*博柏利Burberry|博宝利/巴宝莉”表示只要出现这些词汇则认为该文档与品牌“博柏利”有关,借助编码可协助品牌语料识别。
2.2 关键词共现网络分析
语义网络是全局性的数据结构观察方法。在KH coder 设置不同的分析系数与变量因素,执行共现网络分析可发现隐形关联,从不同的角度进行数据特征挖掘,发现语料库的数据特征和隐藏的知识结构。
共现分析是按照关键词在每篇文章中的共同出现的情况生成的语义网络。设置参数时将共现网络设置为无向网,共现结果(图1~图3)中圈的大小代表频次,颜色代表聚类情况。
语义网络呈现的共现关系可以是词汇与外部变量之间的。
以图1 为例,该图是以品牌语料作为分析文本,以“品牌名称”作为外部变量,基于语义相似度计算的语义网络。品牌间由特征词关联起来形成不同的远近关系,其关联与人工划分的品牌类型相符;由品牌的共现相似性可对竞争关系展开知识推理。
语义网络呈现的共现关系也可以是词汇与词汇之间的。
图2 是没有设置外部变量,由服装综合性语料分析后展开的语义网络,可借此知道文本中存在较多的信息类型。由图可知,分析文本中包含较多的“市场”“色彩”“元素”“造型”“图案”等信息类型。
图3 是以“雅格狮丹”的品牌语料为分析文本导出的语义网络。雅格狮丹是英国伦敦的御用皇家品牌,战争期间为军队设计的防水大衣是品牌的经典设计。在共现结果中,与雅格狮丹品牌相关的关键词和信息点在语义网络中都有明显表现。通过语义网络,可观察到每个品牌的数据特征词;得到基于大数据文本的“品牌数据画像”。
语义网络中的共现词汇在一定程度上体现了数据的主题,可挖掘语料库的行业信息,实现行业的知识发现。
2.3 集群聚类与KWIC 检索
通过聚类分析和KWIC 检索可在词汇语境下进行数据的分析观察。
集群就是把相似的个体(样本语料)归于一群。通过集群聚类,可以得到不同场景的文本集群,并可得到不同集群下的特征词汇表(表2,表3)。
Jaccard 数值越高证明该词在这一集群中的权重越大。如表2 所示,由特征词可知该集群的文本语料与“颜色”密切相关;如表3 所示,该集群的语料与户外运动密切相关。以此为依据可进行语料分类和行业术语抽取。
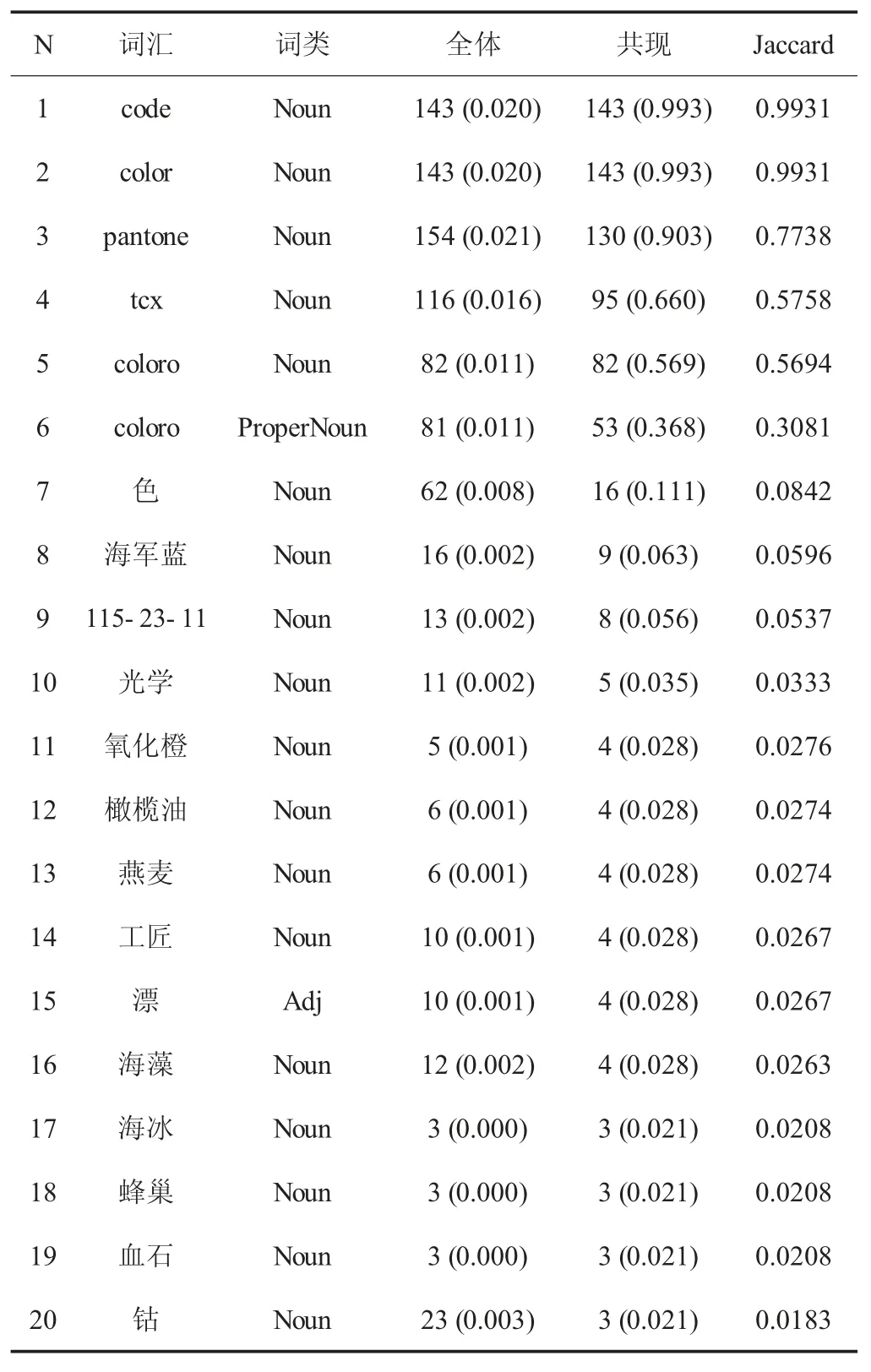
表2 特征词汇集群示例(部分)Tab.2 example ofcharacteristic vocabulary cluster(part)
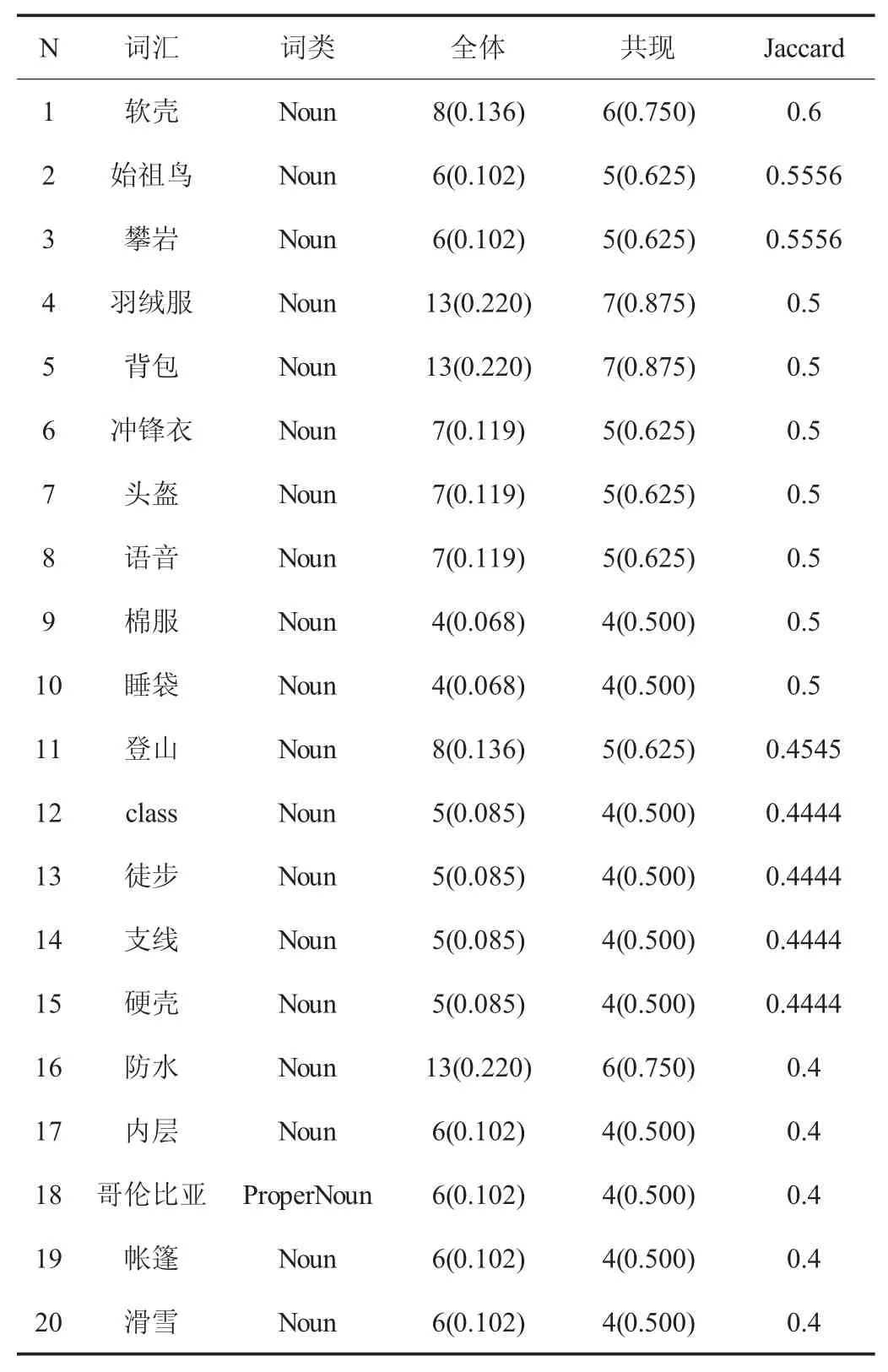
表3 特征词汇集群示例(部分)Tab.3 example ofcharacteristic vocabulary cluster(part)
KWIC 检索也是基于语义相似度计算的统计分析,可输入关键词(研究对象)直接查询该词的上下文语境。分数越高意味着在分析样本中该词与风格搭配越频繁。
由上述结果可知,在KH coder 中执行集群聚类可对文本语料进行分类;借助集群聚类和KWIC 检索还可获取特征词汇,“品牌”“颜色”“单品”“图案”、“面料”“风格”“功能”“场景”等服装行业的知识信息都可借此进行聚类、提炼。
3 结论
文章借助爬虫技术和文本挖掘工具,对60 个服装品牌进行了数据采集与语料库构建,发现了不同服装品牌的数据分布特征。在语料库基础上进行数据挖掘,从不同角度绘制了语料文本的语义网络,并获取了基于语料库的服装品牌知识集群。结果表明,运用大数据技术在服装品牌开源数据上进行知识抽取具备科学性和可行性。实验结果对知识工程建设者或数据分析人员具有一定的借鉴或参考价值。
