基于多尺度特征解码网络的RGB显著性目标检测
2022-04-14李颖,宋甜,王静
李 颖,宋 甜,王 静
(四川大学电子信息学院,成都 610065)
0 引言
显著性目标检测(SOD)能够模拟人类选择性的分辨出视觉中最重要目标的机制,识别并提取出图像中最显著的目标。它是由各种领域中广泛的对象级应用驱动的,比如视觉跟踪、图像理解、图像字幕等。
SOD历史相对较短,主要分为非深度学习和深度学习模型。早期的非深度学习SOD模型大多基于低级的手工特征,且依赖于图片特性(颜色对比、背景先验等)启发,无法实现端到端的训练。随着深度学习的蓬勃发展,SOD逐渐从传统方法发展到深度学习方法,性能得到极大提升。最早的深度SOD模型对图像的每个处理单元提取深度特征,然后训练多层感知机(MLP)分类器进行显著性评分预测,这种方法不能很好地捕获关键的空间信息。随着全卷积神经网络的发展,Liu等利用CNN可以提取包含低级局部细节和高级全局语义的多层次特征的特性,开发了基于VGG网络的深度SOD模型,该模型通过使用循环层逐步组合较浅的特征来细化粗糙的显著性地图。Zhang等利用编码器-解码器体系结构来设计网络,通过学习解码器的不确定性,产生分辨率更高的预测。总结起来,这些模型主要分为单流网络模型、多流网络模型、U型侧融合网络模型等。
Lin等开发的U型网络因为能利用多层特征进行侧融合,恢复图片的语义信息被广泛关注。因此,目前主流的显著性目标检测方法大部分采用U型的编解码网络结构。许多方法直接将编码器和解码器通过简单的相加或相乘的操作进行级联,提取的特征尺度单一,这忽略了不同层级和尺度特征对最终预测图的影响,导致最终的预测图缺失上下文语义信息。一些方法为了提取深层特征增加了U型网络的深度,虽然可以提取深层特征,但随着特征金字塔深度的增加局部信息也会严重损失。此外,由于接受域的限制,单尺度卷积核难以捕获大小变化的对象的上下文信息。为了解决这个问题,Chen等在其网络中直接配置了一个巨大的空间金字塔池模块(ASPP)。然而,当使用一个膨胀率较大的卷积时,由于内核下的信息严重缺乏相关性,这可能不利于细微图像结构的辨别。
基于以上的问题,为了充分利用语义和细节信息,本文设计了一种简单而有效的多尺度特征解码网络,通过在编码和解码模块之间增加精炼过渡层和注意力机制,给各层次特征的通道和空间信息分配不同权重,以恢复图片的细节,增强显著性信息。此外,在网络的顶部增加感受野增强模块,通过空洞卷积扩大感受野、残差连接保留原始信息,可以定位深层特征中不同尺度信息,获取更精确的显著性目标。最后将不同层的多尺度信息进行聚合,提取出最终的显著图。在主流的6个显著性目标检测数据集上对比,表明本文的方法优于同类方法。
1 网络结构
1.1 模型引入
整个网络包含编码和解码两个部分,具体如下:
(1)编码网络。VGG-16预训练骨干网络,包含13个卷积层、5个最大池化层、2个全连接层。与其他显著性目标检测类似,为了保留最后一层卷积层的细节信息,本文丢弃了所有全连接层和最后一层池化层,使其成为全卷积神经网络。
(2)解码网络。包含四部分:①精炼过渡层(Refining Transition Layer):将编码器输出的多尺度特征~减少通道数以实现精炼化。②双注意力模块(Dual Attention Module)。从通道和空间上对精炼过渡层输出的特征~赋予不同权重,筛选出有用的语义信息。③感受野增强模块(Receptive Field Enhancement Mod⁃ule)。扩大感受野,从深层特征定位多尺度信息。④特征融合流(Feature Aggregation Stream)。将不同尺度的解码信息进行融合,生成显著图(prediction)。
1.2 多尺度特征解码模块
现有的一些RGB显著性目标检测在编码和解码模块之间直接通过相加或相乘连接,没有充分利用图片语义和细节信息。一些方法在U型网络的特征融合过程中设计复杂的网络结构将信息从高层次流向低层次以补充细节,这虽然可以引入有价值的人类先验信息,但会导致训练过程变复杂,网络结构缺乏通用性。
为了充分利用语义和细节信息,本文设计了一种多尺度特征解码模块,首先用精炼过渡层的3×3卷积降低编码器输出特征~的维度,以实现特征的精炼化打磨;然后在多尺度特征的输出引入双注意力模块,在通道和空间上还原编码器的细节信息;最后使用特征融合流将多尺度特征融合。
(1)双注意力模块(DAM)。由于特征经过编码器和精炼过渡层后会损失细节信息,直接对特征进行融合效果不佳,为了提高网络对特征图中空间和通道上信息的利用能力,使解码器更加关注显著性区域,受[11]启发,引入了一种简单而有效的双注意力模块,此模块在本文提出的多尺度特征解码网络中起到核心作用,可以与任何深度卷积主干结合来优化网络特征。如图2所示。

图1 多尺度特征解码网络
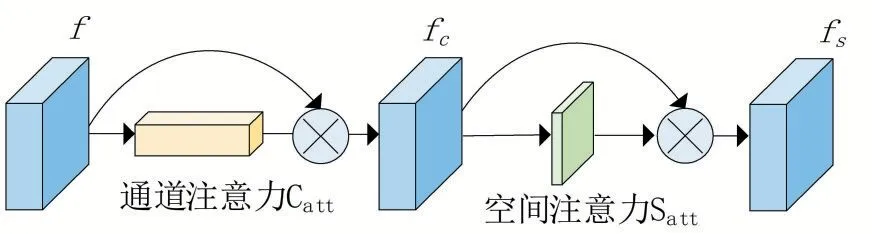
图2 双注意力模块
双注意力模块包含了一个连续的通道注意力操作和一个空间注意力操作,定义的公式为:
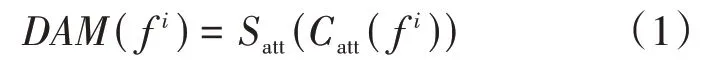
其中f 表示第(=1,2,3,4,5)分支的特征,表示通道注意力操作,表示空间注意力操作。通道注意力操作先用全局最大池化聚合特征图的空间信息,然后将此特征送入感知机以产生特征;空间注意力操作是将输入的特征在通道轴上全局最大池化,然后经过7×7卷积。两个操作最后一步都是将处理后特征经过Sigmoid函数后与原始输入特征相乘,公式详解为:

其中,表示两层感知机,是对每个特征图全局最大池化的操作,⊗表示有维度扩展的相乘操作,是卷积操作,是对特征图上沿着通道轴每个点的全局最大池化操作,表示Sigmoid操作。
(2)特征融合流(FAS)。对多尺度特征进行融合,生成最终的显著图。具体操作是采用膨胀率为1的3×3卷积块对输入特征通道进行降维,可以提取出特征中有效信息,然后将经过上采样操作后的高层次特征与低层次特征逐级融合。定义如下:

其中D是输出的解码模块,是特征融合流,是基于双线性插值的上采样操作。
1.3 感受野增强模块
在显著性目标检测中,由于不同层次特征对最终预测效果的影响不同,深层特征具有更高层次的语义信息,可以为解码器贡献更多的上下文指导,为了提升网络的鲁棒性,可以对深层特征的多尺度信息进行整合。常用的方式有空间金字塔池算法(ASPP)。该方法采用多个平行的空洞卷积层,具有不同的扩张速率,虽然可以不增加网络参数的同时生成高分辨率特征图,但随着膨胀率的扩大,连续空洞卷积时的稀疏性会导致采样点之间的关联太弱,无法提取稳定的特征。Inception网络采用不同尺度的卷积核获取多尺度特征,虽然可以获得不同感受野,但不同的卷积核的采样中心位置固定,输出的特征会更关注靠近中心部分的信息,这会失去对不同视野的分辨能力,造成最终的显著图分割不均匀。
基于以上问题,为了获取不同视野的多尺度特征。受RFB(Receptive Field Block)启发,人类视觉系统中不同的感受野应该具备不同的离心率,可以将Inception结构与空洞卷积结合,在扩大感受野的同时模拟人类视觉系统,获取不同离心率的多尺度信息。因此,在RFB基础上,本文改进了一个多分支结构的感受野增强模块(RFEM),该模块包含了两部分:多尺度特征提取的分支和残差连接分支,可以在扩大感受野的同时,保留原始特征信息。模块的结构如图3所示,对4个分支操作:先用1×1卷积操作对4个分支降维,然后对第(=2,3,4)分支进行1×(2-1)和( )2-1×1的卷积操作(膨胀率为1),接着对第(=2,3,4)分支进行3×3卷积操作(膨胀率为2-1),然后将四个分支的特征进行拼接(concat),对拼接后的特征进行1×1卷积操作降维。整个过程的1×1卷积能减少网络参数量,可以更好的进行跨通道信息融合,不同膨胀率的空洞卷积是为了扩大感受野,获取多尺度特征,定位全局显著信息。最后的残差连接将拼接后的特征与原始特征相加,以修补局部细节信息。整个模块的公式定义为:
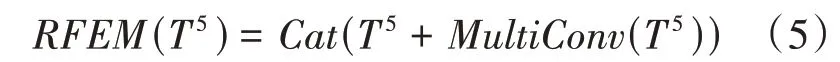
其中()表示4个支路的卷积操作,细节如图3。

图3 RFEM模块
2 实验相关设置
2.1 实验数据集
本文的训练集为DUTS-TR,测试集使用了六个常用的基准数据集,包括DUT-OMRON(5168),DUTS-TE(5019),HKU-IS(4447),ECSSD(1000),PASCAL-S(850),SOD(300)。这些图片包含结构复杂的前景目标、多个前景目标、大型前景目标和低对比度目标等具有挑战性的场景。
2.2 评价指标
为了综合评估显著图的质量,采用平均绝对误差(mean absolute error,MAE),S-measure(structural measure),F-measure来评估预测图和Ground Truth标注图的误差。
(1)MAE。平均绝对误差,表示预测显著性图和Ground Truth标注图的平均像素差。定义如下:

其中,和分别是显著图和对应的Ground Truth标注图。(,)和(,)分别是图像高度、宽度和像素坐标。
(2)F-measure。用来综合评估回归率和准确率,定义如下:

其中,和分别是平均准确率和平均召回率,设置为0.3。
(3)S-measure。用来评估预测的显著图与Ground Truth标注图的结构相似度。定义如下:

其中,S为区域感知相似度,S为目标感知相似度,设置为0.5。
2.3 实验细节
本文的模型基于Pytorch框架实现,在一台实验室配备的GTX 1080 Ti GPU(11 GB内存)上进行网络的训练和测试。在训练阶段,为了避免过拟合,采用了数据增强技术,包括对比度、饱和度变化、随机亮度、随机水平翻转。采用随机梯度下降(SGD)优化器。冲量值、权重衰减和学习率分别设置为0.9、0.0005和0.001。训练时批次大小batch-size为4,在经过40个ep⁃och后训练收敛,整个过程大概需要7小时。
2.4 损失函数
本文采用二分类交叉熵损失函数(Binary Cross-Entropy Loss)对的显著图进行全监督训练。定义如下:
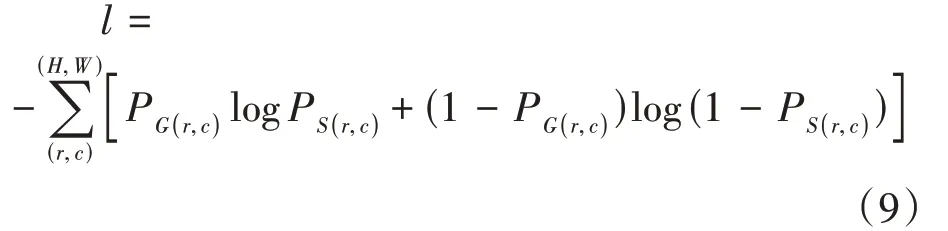
其中,和分别是显著图和对应的Ground Truth标注图。(,)和(,)是图像高度、宽度和像素坐标。P和P是显著图和标注图的像素值。
3 实验结果
3.1 消融实验
为了证明多尺度特征解码模块和感受野增强模块的有效性,本文在4个主流数据集上进行了消融实验。Baseline为包含VGG-16骨干网络、精炼过渡层和特征融合流的基础网络。1号实验表示对Baseline网络进行训练和评估,2号实验是双注意力模块(DAM)加在Baseline上训练评估,3号实验是将感受野增强模块(RFEM)加在Baseline上进行评估,4号实验是将DAM和RFEM都添加在Baseline上训练评估。实验结果如表1—表2所示。
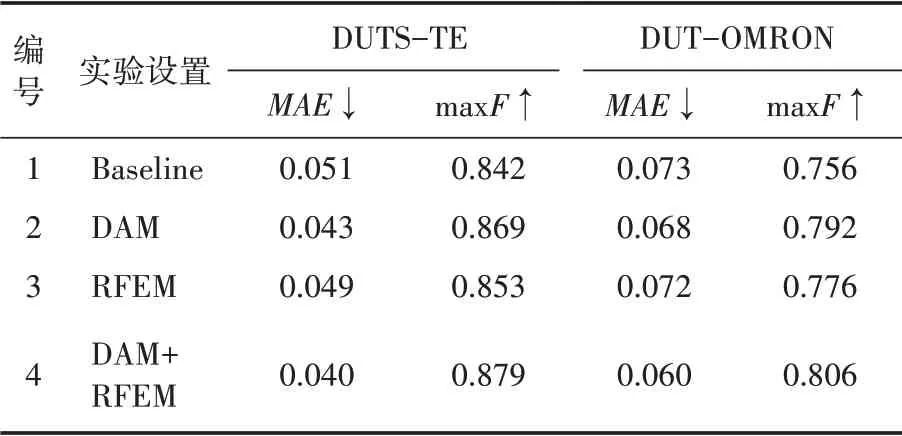
表1 DUTS-TE和DUT-OMRON数据集的消融实验

表2 ECSSD和PASCAL-S数据集的消融实验
从表中可以看出,在2号实验中,四个数据集的优化了0.005~0.011,max最多提升了4.7%。在3号实验中,四个数据集的优化了0.002~0.011,max最多提升了2.6%。在4号实验中,可以看出网络性能进一步提升,值在四个数据集上对于Baseline优化了0.01~0.013,max值提升了2.8%~6.6%。这证明各模块的有效性。
3.2 与其他方法对比
将本文方法与其他基于VGG骨干网络的方法在测试集上进行比较,结果如表3和表4所示。从表中可以看到,除了在DUT-OMRON数据集的和S值以外,本文方法在其他5个数据集上的评估指标都显著优于最先进的AF⁃Net。其中值都优化了0.003~0.007;max和S最多提升了2.0%和1.9%。除了SOD数据集的和S值,本文方法也显著优于较先进的PiCANet。
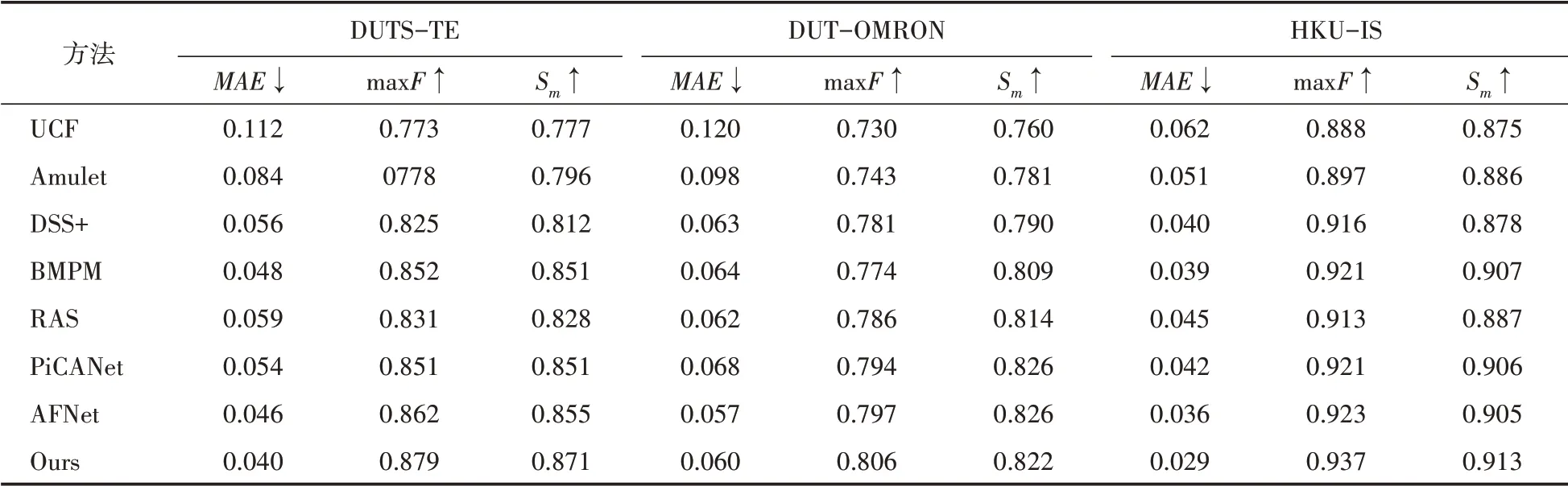
表3 本文方法与其他方法在DUTS-TE,DUT-OMRON,HKU-IS对比

表4 本文方法与其他方法在ECSSD,PASCAL-S,SOD对比
本文与其他方法的显著图进行了可视化对比,从图4中可以看出,本文的多尺度特征解码网络可以处理不同类型的目标,并产生较准确的结果。第1行是当目标前景被杂草和树枝挡住时,本文的方法能清晰分割出目标整体轮廓。第2行是目标在图片的边界时的场景,可以看到依然能正确分割整个目标。第3、4行是针对多个目标的场景,可以看到所有显著性目标都被分割,边缘也比较清晰,而别的方法可能有遗漏甚至识别出其他不相关物体。第5行是目标与背景界限不清时的场景,本文的方法精度虽然不高,但能基本识别出目标在水面上的形状,其他方法要么识别不完整,要么将倒影也识别出来。

图4 本文与其他方法的可视化对比
4 结语
本文提出了一种基于VGG-16全卷积神经网络的多尺度特征解码显著性目标检测模型。首先通过使用精炼过渡层和注意力机制对编码器输出信息进行精细打磨,增强编码与解码网络之间的信息交换,然后通过感受野增强模块,在保留局部采样点相关性的同时扩大深层特征的感受野,增强全局语义信息,最后结合多尺度特征融合流将不同层次特征进行融合输出结果。
通过实验对比分析,分别验证了多尺度特征解码模块和感受野增强模块的有效性。此外,将本文的方法在主流数据集上与其他先进的RGB SOD方法进行了定性和定量的对比,结果证实本文的方法能生成更精确的显著图。
