基于先验信息和一维数据聚类的专家赋权方法
2022-04-13易平涛王士烨李伟伟董乾坤
易平涛, 王士烨, 李伟伟, 王 露, 董乾坤
(东北大学 工商管理学院,辽宁 沈阳 110167)
0 引言
综合评价通常基于多指标体系结构,对被评价对象进行客观、公正、合理的全面评价[1,2]。多属性群体评价作为综合评价的一个重要分支,在经济、社会、管理、科技等诸多领域被广泛应用。面对日益复杂的评价问题,通过群体评价汇集多位专家的知识、经验等解决复杂评价问题,是诸多专家学者研究的一个重要方向。截止到目前,国内外学者针对群体评价的问题展开了持续讨论并取得了丰盛的成果。如,李贵清等[3]根据语言评价标准提出的大规模群体评价方法;董庆兴等[4]从双重反馈的视角出发,对语言型动态群体评价问题提出了解决方案;张发明等[5]从网络视角出发,对动态交互式的群体评价进行了信息集结的探索,并有效地集结群体意见;Sujit Das等[6]提出了一种利用中性软矩阵(NSM)和专家相对权重来求解群体决策问题(GDM)的算法;Soumava Boral等[7]提出一种新的混合多准则群决策方法。
合理确定专家权重是多属性群体评价需要解决的重要问题。目前,有学者对该问题从不同方面展开了深入讨论。如,何立华等[8]根据聚类的思想,从类内和类间两个视角刻画专家权重;王新鑫等[9]提出专家对应准则扩充犹豫模糊集,利用扩充后的矩阵计算出专家权重;金飞飞等[10]构建专家之间信任关系模型,以此度量专家权重;刘业政等[11]在已知专家主观权重的基础上,提出一种权重自适应调整的方法;冯源等[12]依据平均差概念和修改后的平均差系数公式,对专家权重从局部到整体逐次进行微调整;王俊英等[13]从TOPSIS法和灰色关联度出发,提出了专家权重自适应调整算法;Xu[14]通过最小化个体区间和集体区间模糊偏好关系的偏差,构建二次规划模型确定专家权重;Yue[15]通过投影法度量专家权重;刘安英等[16]利用语言标度确定专家的后验权重;周宇峰等[17,18]通过对信息自身逻辑一致性和群体相容性程度的判断,基于专家判断信息可信度进行后验权重的确定,并综合先验和后验信息来对专家进行赋权。
本文在上述研究基础上,针对多属性群体评价中专家权重的确定问题,基于文献[19]中的数据聚类思想及信息集结方法、文献[20]中时间权向量的求解思路,给出了一种专家权重确定方法,该方法同时兼顾专家先验权重和后验权重。
本文的创新之处在于以下几点:
(1)提出了一种确定专家先验权重的方法,根据专家的先验信息(即专家的历史评价数据),利用专家历史评价活动中的序值相关系数,计算出本次评价活动的预测值,从而确定出专家先验权重。
(2)提出了一种确定专家后验权重的方法,基于群体共识视角,对各专家所给出的后验信息(即在当前评价活动中专家提供的信息)进行一维数据聚类,结合不同分组情况下出现的概率,进而确定专家后验权重。最后将两种权重组合实现专家赋权。
本文对于专家赋权的方法充分考虑了历史信息和当下信息,相比传统专家赋权方法仅考虑当下信息有更好的适用性和灵活性。但本文所提供的方法对于使用者提出了更高的要求,如何为方法使用者提供更为科学合理的参照标准,是本文下一步重要的研究方向。
1 问题描述与条件假设
设被评价对象集合为O={o1,o2,…,on},被评价对象综合评价值集合为Y={y1,y2,…,yn},评价指标集合为U={u1,u2,…,um},评价指标权重集合为Ω={ω1,ω2,…,ωm},评价专家集合为E={e1,e2,…,ek},专家权重集合为A={A1,A2,…,Ak},专家的权重由各专家的先验信息和后验信息确定。xijq表示专家eq对于被评价对象oi关于评价指标uj的赋值,其中i=1,2,…,n;j=1,2,…,m;q=1,2,…,k。不失一般性,令m,n,k≥3,由xijq组成的评价信息矩阵如表1所示。

表1 评价专家给出的指标信息
为了更准确地说明问题,现给出3个假设:
(1)参评者均为本次评价活动专业相关领域的专家;
(2)仅收集参评专家专业相关领域的历史评价信息;
(3)各位专家的判断具有一定的稳定性。
2 方法与基本原理
2.1 专家先验权重的确定
k位专家对问题作出评价,但因各个专家的知识结构、经验、能力、专业水平等的不同,这些因素在一定程度上会导致专家评价水平的差异。本文期望通过专家在以往评价活动中的历史数据判断专家评价水平,这些数据均属于先验信息,因此,由这类信息确定的专家权重称为先验权重。
确定先验权重的基本思路:首先对评价者q(q=1,2,…,k)在tb(b=1,2,…,v)时期内的评价活动中所给出的方案的评价结论与该方案最终的评价结论进行一致性程度的分析(这里,本文考虑信息采集的经济性与简便性,选择序值信息作为度量依据,在宽松的分析环境中一定程度上也保证了度量的准确性),由此可以度量出每个评价者在各个时期内进行评价活动的准确性;然后基于k组序值相关系数,结合指数平滑法[21,22],计算出k位评价者在本次评价活动中对方案正确排序准确性的预测度量。最后对k位评价者在本次评价活动中序值相关系数的预测度量进行归一化处理,得到k位评价者的先验权重。
基于上述关于专家先验权重的确定思路,下面给出确定专家先验权重的具体过程:
1)收集专家eq的历史评价信息,如表2所示。

表2 专家eq的历史评价信息
2)计算专家eq的历史序值相关系数
因序值具有等级变量的性质,本文采用斯皮尔曼等级相关系数[1],对评价者在t时期内进行的评价活动进行序值之间的相关系数计算。历史序值相关系数的基本公式为:
(1)
式中d表示两个序值之间的差值,j表示等级个数,r越高表明两个序值之间的一致性程度越高。
3)运用指数平滑法计算专家eq在本次评价活动中的序值相关系数(因序值相关系数没有明显的趋势变化,故选用一次指数平滑法)。一次指数平滑法的平滑公式为:
(2)
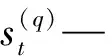


α—平滑系数,其取值范围[0,1]。
预测度量计算公式为:
(3)


平滑系数α的取值对于指数平滑法的预测效果有重要的影响,现有的研究和应用中,确定α值的方法一般为以下两种:
①经验估算和试算法[21,22]。α越接近于1,远期实际值对本期平滑值影响程度的下降越迅速;反之,越缓慢。一般来说,时间序列波动越小,α取小值;时间序列波动越大,α相应地取大值。根据这种经验,对α进行不同的取值,反复试算,最后选择试算过程中误差最小的平滑系数α作为最优的值。
②规划求解[22]。将目标函数设置为真实值与预测值差值的平方和,对其进行最小化求解,便可以较快的速度进行α系数的优选。
本文为保证预测效果和计算过程的简洁性,选用规划求解的方式来确定α值。
对于(一次指数)平滑序值相关系数初始值的确定,我们一般根据时间序列号t的大小来确定,若t≥15,则以第一期的序值相关系数作为初始值,若t<15,则以前三期的序值相关系数的绝对平均值作为初始值[21]。
4)确定专家先验权重,公式如下:
(4)
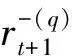
2.2 基于群体共识视角的专家后验权重的确定
在评价过程中,由于专家自身知识结构、权威度等因素的影响,各位专家所做判断信息的可信度会有所差异。根据专家给出的指标信息可信度,进而确定专家权重,一种可行思路是基于群体共识视角,对专家给出的指标信息进行聚类分组度量。本文将基于该思路确定的专家权重称为后验权重。
评价活动中,各位评价者给出各个方案的指标信息,从各位评价者的指标信息中抽取出Z{G11,G12,…,G1m;G21,G22,…,G2m;…;Gn1,Gn2,…,Gnm;Z=n·m}个一维数据集(一维数轴上若干数据点的集合)。Gnm表示方案on在指标xm下,k位专家给出的指标评价信息集。


定义3[1]对Gij={xij1,xij2,…,xijk}中数据由大到小进行排序,得到有序组gij={bij1,bij2,…,bijk},bijq(i=1,2,…,n;j=1,2,…,m;q=1,2,…,k)为Gij中第q大元素,称{Δd|Δd=bijq-bij(q+1),q=1,2,…,k-1}为Gij的有序增量集,Δd为Gij的有序增量。


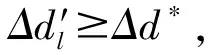
(5)

(6)
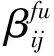
(7)

(8)

从h次分组中和Z个一维数据集中,抽取出专家eq对应的指标信息被赋予的比重和,即
(9)
由此计算相应的专家后验权重为
(10)
基于上述关于专家后验权重的确定思路,给出确定专家后验权重的具体过程:
1)根据定义1,从各评价者的指标信息中,抽取出Z个一维数据集;
2)对Gij={xij1,xij2,…,xijk}按定义3求得Gij的有序增量集;
3)依据定义4,求得有序组η;
4)根据定义5,求出有序组η的极差;
5)求出总的分组次数h和每一次分组中的数据群;
6)依据式(5)计算出数据集Gij中不同分组情况出现的概率;
7)根据式(6)计算出数据集Gij在第f次分组中第u个数据组中的指标信息个数占总体的比重;
8)根据式(7)计算出数据集Gij在第f次分组中第u个数据组中的指标信息xijq被赋予的比重;
9)根据式(8)得出数据集Gij中,第f次分组出现的概率情况下,每一个指标信息xijq被赋予的比重;
10)根据式(9)从h次分组和Z个一维数据集中,计算出专家eq的比重和;
11)根据式(10),进行归一化处理,求出各专家的后验权重。
2.3 专家权重的确定
在本次评价活动中,考虑专家先验信息和后验信息的专家权重为
(11)
其中0≤φ≤1,且φ的取值越大,说明在本次评价活动中越关注专家的先验信息;φ的取值越小,说明在本次评价活动中越关注专家的后验信息。
3 应用算例
某风险投资公司对4个拟投资的初创企业(o1,o2,o3,o4)进行评估,为此邀请了行业内10名专家对它们从商业模式u1、市场洞察力u2、产品潜力u3、团队能力u4总计4个方面进行评价,评价方式采用打分制,分数越高,表示越优,打分范围为1~10分。
3.1 专家先验权重的确定
计算10位专家的序值相关系数,囿于篇幅,此处仅列出专家e1的历史评价信息。假设整理信息可得专家e1相关历史评价活动进行了6次,具体步骤如下:
1)专家e1的历史评价信息见表3所示:

表3 评价专家e1的历史评价信息
2)依据式(1)可得e1在6次评价活动中序值相关系数,如表4所示。

表4 评价专家e1的历史评价序值相关系数
4)选取合适的α值:通过规划求解,计算出最优的α值为0.0623。
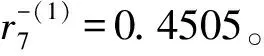
3.2 基于群体共识视角的专家后验权重的确定
所有的指标信息均由各位专家根据自己的知识、经验等给出相应的分值(考虑到所有指标均为极大型指标且量纲一致,不对决策矩阵的进行规范化处理),相应评价矩阵信息如表5所示。

表5 专家e1~e10的指标信息
囿于篇幅,此处仅展示数据集G11的运算。
1)从10位专家的指标信息中,抽取出一维数据集G11={2.2,6.7,2.7,5.3,6.0,4.4,8.4,6.3,7.2,6.9};
2)根据定义3对G11中的指标信息按照从大到小的顺序进行排列,排列后的数据集为g11={8.4,7.2,6.9,6.7,6.3,5.3,4.4,2.7,2.2}。并求得g11的有序增量集Δd={Δ1=1.2,Δ2=0.3,Δ3=0.2,Δ4=0.4,Δ5=0.3,Δ6=0.7,Δ7=0.9,Δ8=1.7,Δ9=0.5};




8)根据式(7)计算出数据集G11第f次分组下每一个数据组中的指标信息x11q被赋予的比重:f=1时,Δd*∈(0.2,0.3]:
其余分组情况以此类推;
9)根据式(8)计算出数据集G11中,第f次分组出现的概率情况下,每一个指标信息x11q被赋予的比重,f=1时,Δd*∈(0.2,0.3]:
其余分组情况以此类推;
10)根据式(9)从7次分组和16个一维数据集中,计算出专家eq的比重和:
Bq=(5.5878,6.9763,5.3845,6.3678,6.1429,
6.2181,6.6279,5.7412,6.4134,7.3793)
11)根据式(10)进行归一化处理,求出各专家的后验权重:
Aq″=(0.0889,0.1110,0.0857,0.1013,0.0978,
0.0990,0.1055,0.0914,0.1021,0.1174)
3.3 专家权重的确定
根据式(11)计算10位专家的权重。实际应用过程中,若更倾向于先验信息,则对φ赋予较大的值;若更倾向于后验信息,则对φ赋予较小的值,本次计算φ取0.5,计算结果见表10。

表6 10位专家的权重
在计算中可以看出,因知识结构、经验、能力、专业水平等的不同,以及受不确定性因素的影响,专家们在问题的分析及评判上存在差异,进而在群体评价中各位专家的权重也存在差异。
对φ从0到1以0.01的步长取值,可以发现专家1、3、4、5、6、8、9的权重呈上升趋势,专家2、7、10的权重呈下降趋势。当φ=0时表示仅考虑后验信息;当φ=1时表示仅考虑先验信息。对φ在不同情况下取值,求解对应的10位专家权重的误差平方和(实际应用过程中,可根据具体情况选用其它度量离散程度的方法),具体见图1。通过求解专家权重误差平方和,可为评价活动的实施者对专家赋权提供参考。若决策者倾向于专家之间的差异性,则选择专家权重误差平方和较大时对应的φ值,反之,选择专家权重误差平方和较小时对应的φ值。

图1 专家权重误差平方和散点图
3.4 不同方法的比较研究
应用文献[23]中提出的离差最大化的决策者权重确定方法,经计算得到的专家权重为:
A1=0.0782;A2=0.1267;A3=0.1194;
A4=0.1190;A5=0.0828;A6=0.1101;
A7=0.0988;A8=0.1112;A9=0.0973;A10=0.0565
应用线性加权计算各初创企业的综合评价值分别为
y1=6.2707;y2=6.1465;y3=6.1227;y4=5.5073
因此,各初创企业的排序结果是:o1≻o2≻o3≻o4。
在保证指标权重与上述方法一致的前提下,利用本文提出的专家权重确定方法(φ取0.5),可得各初创企业的综合评价值为
y1=6.2033;y2=6.1377;y3=6.0352;y4=5.5320
对应的排序结果是:o1≻o2≻o3≻o4。经过比较发现,本文提供的方法与文献[23]中所提方法排序结果是一致的,表明本文所提出的专家权重确定方法的合理性以及适用性,可在评价信息为精确值时的场景中作进一步应用。本文通过对φ值的选取,既考虑到历史评价信息,又兼顾到当下评价信息,将两种客观权重进行组合赋权,得到比较科学合理的专家权重。φ取值的大小,充分考虑了方法使用者对于先验信息和后验信息的偏好,基于专家权重误差平方和,进一步为方法使用者针对评价专家差异性的偏好选择提供了参考。相比文献[24]中将主客观权重进行组合的方式,本文中专家先验权重和后验权重的确定均以一定的客观数据信息为依据,进一步减少了主观因素的影响。
4 结语
本文根据现有确定专家权重的研究,以及一维数据聚类等思想,给出了确定专家先验权重和后验权重的方法:
(1)根据专家以往参与群体评价的历史信息,给出了一种确定专家先验权重的方法。为专家赋权的过程中,充分考虑各位专家的历史评价信息,利用现有统计方法预测下一次专家评价活动的准确度,以此给出相应权重。本文先验权重的求解方法,相比传统的打分制确定权重的方式,减少了一定的随机性,对先验信息的利用更加公正合理。
(2)结合一维数据聚类的思想,给出了一种确定专家后验权重的方法。考虑专家对各个方案在各个指标之下的理解程度,基于群体共识视角进行聚类分析,将分组以概率的形式展现,保证了参评专家信息的完整性,避免了信息缺失。相比传统的剔除异常值的求解思路,更大程度地保证了评价活动中信息的完备性。
最后,本文通过一个算例说明了这两种确定专家权重方法的合理性和有效性。在未来的研究工作中,可以尝试将后验权重的求解思路拓展至指标权重的求解方法和评价信息为不确定值时的评价情景中。
