中国企业“走出去”的技术进步效应影响因素
——基于修正的多指标面板数据模糊聚类
2022-04-12陈晔婷刘洪颖
陈晔婷,刘洪颖
(云南师范大学 经济与管理学院, 云南 昆明 650500)
一、 引言
在经济全球化背景下, 通过对外直接投资渠道获取的国外研发资本能够显著提升一国的创新绩效,特别是对于发展中国家更能起到缩短研发周期、节约研发成本的目的。 企业通过对外直接投资能够提升具有比较优势的产品和技术的市场发展潜力,参考国外在技术层面和企业管理层面的经验发展,并结合企业自身特点提升综合市场竞争力。 发展中国家企业的研究和发展(R&D)活动在全国经济增长和发展中越来越重要,而世界经济的全球化为促进知识创造活动提供了更多机会。
虽然“一带一路”倡议推动着中国企业对外直接投资的发展,但从目前的发展状况来说,中国企业对外直接投资发展历程较短,当前仍处于摸索建设初级阶段,在发展规模、资本积累、技术研发和创新、人才培养等方面处于弱势领域。 此外,目前“走出去”的企业中虽然不乏通过对外直接投资成功推动企业创新的企业,如联想成功并购IBM 的PC 业务,海尔集团在海外建立了8 个研发中心,北汽成功收购瑞典萨博汽车的知识产权等。 这些企业通过并购和绿地投资等方式,使自己在技术、产品等方面有了较大提高,快速增强了海外影响力和竞争力。然而不得不承认,有很多企业“走出去”却没能实现提高研发实力的目的。 如TCL 作为海外投资的先行者,但创新绩效没有得到显著的提升。 “走出去”是趋势和诉求,但没有达到预期目标的企业也比比皆是。 在这种背景下,我们应当尽可能从企业内部挖掘影响技术进步效应的因素,避免更多的企业盲目“走出去”,促使适合的企业更好地“走出去”,这也有助于中国对外直接投资取得更好的经济成效。
学者们对知识转移现象的影响因素进行了较为广泛的研究,最早对企业所处的外部环境作为主要的影响因素。 李梅[1]通过中国省际数据实证检验了对外直接投资的逆向技术溢出效应。 结果表明,对外直接投资的逆向技术溢出存在明显的地区差异,并存在门槛效应。 并从经济发展、技术差距、金融发展和对外开放程度等方面测算了引发积极逆向技术溢出效应的门限水平。尹东东[2]在此基础上进一步检验了表征各因素对逆向技术溢出效应的影响,结果发现国内经济发展水平、对外开放程度、基础设施、金融发展规模对于OFDI 逆向技术溢出效应的实现起到了积极的促进作用。 随后学者们研究影响因素的重点逐渐从外部环境转向了企业本身,目前的研究主要从企业母公司自身特征出发。沙文兵[3]通过实证研究发现自主研发投入水平的不同会导致对外直接投资逆向技术溢出的吸收程度不同。 李梅[4]考虑了企业的管理者背景,认为企业高管政治紧密,则逆向技术溢出越显著,高管政治联系正向调节技术溢出对创新的影响。林莎[5]从进入东道国的战略出发,认为跨国并购和绿地投资两种不同对外投资方式在绩效上呈现出差异性。 Piperopoulos[6]以对外直接投资的目标国家为研究对象,认为对外直接投资对中国企业创新绩效有正向影响,当目标国为发达国家时,该作用更为显著。Hsu[7]从对外直接投资经验的视角, 考察研发国际化对创新的作用, 将国际化经验作为调节变量来考虑。Nair[8]认为子公司所处的网络、知识复杂性以及东道国的竞争指数都会影响跨国公司的知识转移。 通过对文献的梳理发现,学界对企业对外直接投资与创新绩效的影响因素研究还并不完善,虽然已经有学者从母公司异质性特征的视角,如企业的研发投入、所在行业、社会资源等,也有学者从子公司进入东道国的模式出发,以并购或者绿地投资作为研究视角进行初步的探讨。
通过对文献的梳理还发现,影响创新绩效的企业特征因素往往被直接用作“走出去”企业技术进步效应的控制变量,对控制变量也缺乏进一步的分析,这显然存在着不足。 由于跨国投资的难度加大,对企业自身也提出了更高的要求。虽然目前越来越多的企业试图通过对外直接投资的方式学习和获取境外的先进技术,但失败的企业数量是不容小觑的。除了外部环境因素,每个企业的特征各不相同,探讨企业特征对技术进步的影响有助于帮助企业进行对外直接投资决策。 基于上述论述,本文意图从企业的特征入手,对企业面板数据进行实证分析。由于现有论文中大多采用回归的方法,将文中要测算的变量常被用作控制变量。 也就是说,学者们普遍认为企业的规模、企业成立时间等基本特征对“走出去”企业的技术进步效应有正向影响,为了对这种固有思维进行验证,本文采用聚类的方法对数据进行挖掘。 但是,目前面板数据聚类方法的研究还相对欠缺,面板数据的主要作用仍然是对数据的基本形式进行刻画,在不同领域不同分析方法中,仍然以研究数据的因变量模型为主要内容[9]。
朱建平[10]最早对面板数据做了统计描述,用面板数据的聚类分析进行实证检验证明方法的有效性,某种意义上为后续学者进行研究奠定了一定的理论基础。 二维截面数据聚类分析的理论基础已经很成熟,因此,一般面板数据聚类个体间的相似度问题是将基本的聚类分析用于面板数据时唯一需要考虑的问题。 部分学者也正是这样进行实证检验的。 李因果[11]认为在经济管理问题中,必须考虑根据研究对象构建相似的共识进行测度,根据面板数据的特性提出了反映面板数据样本间绝对量差异、增速差异、波动性差异的距离统计量,之后结合改进的距离公式给出了面板数据ward 聚类法的聚类步骤。 李峥[12]定义了包含三个维度的“欧式时空距离”,在此基础上对面板数据进行聚类分析,将数据进行分类,再利用面板数据的变系数模型进行实证检验。 刘兵[13]则考虑了时间序列的特征,研究了具有水平趋势、非水平趋势、线性趋势的面板数据,以样品指标序列的趋势特征来设置统计量,但论文中还未探讨其他形式时间序列的聚类问题。
基于上述论述,本文利用wind 数据库中上市公司的财务报表数据与商务部发布的《对外直接投资名录》进行匹配,结合修正的多指标面板数据模糊聚类方法验证“走出去”企业技术进步效应的内在影响因素。 主要贡献体现在两个方面:一是从企业内部特征的视角发现,与被广泛认同的企业特征不同,并不是企业规模越大,成立时间越长,就会通过对外直接投资提高创新能力,反而是与“蹬羚企业”具有相似特征的中小规模企业更能在对外直接投资过程中获取技术;二是在方法上修正面板数据的聚类方法,由于面板数据的聚类方法(灰色关联度、降维)相对欠缺并存在聚类方法复杂、不便于使用、聚类数无法评价等问题,因此提出一种多指标面板数据的模糊聚类及评价方法。 该方法能够有效地对多指标面板数据进行聚类。
二、研究设计
当前针对多指标面板数据的聚类方法,主要集中在一些学者将传统的灰色关联分析方法进行改良,并应用在面板数据相似性的分析上。 刘震[14]在其研究的基础上,将面板数据在三维空间的数据点看作网格状结构的节点,将网格拆分,从而构建了灰色网格的关联度模型。 吴利丰[15]则基于面板数据的凸性构建了三维灰色凸关联度、指标随时间变化的速度和指标发展的协调水平。 钱吴永[16]将灰色关联度的应用范围由一维向量拓展到二维矩阵。 多指标面板数据聚类分析的最大困难在于其数据结构的特殊性,其聚类分析理论的构建实际上是传统多元分析方法应用拓展到高维数据的重要突破。
目前,许多学者在聚类时用预处理的手段对多指标面板数据进行降维。 徐华锋[17]等通过数据线性组合的方式对数据进行降维,之后采用动态聚类的方法对投影向量进行了聚类。 任娟[18]通过因子分析的方式达到降维的目的,又依据Fisher 的最优分割法提出了多指标面板数据的有序聚类方法。 王双英[19]将面板数据的指标分为因变量指标与自变量指标进行降维,再利用自组织竞争神经网络进行聚类。
通过上述文献梳理发现,基于灰色关联度进行聚类分析的过程是非常复杂的,并且降维数据会造成数据源的不完整。 本文针对上述问题,提出一种易于实现的、快速的、能够自评价的多指标面板数据聚类方法。
(一)模型设计
常见面板数据的存储方式是按照样本进行划分,每个样本内部形成“时间-指标”矩阵。 也就是每个样本一张表,该表每一列为一期,每一行为一个指标。 这种方式的存储是对面板数据最直观的表达方式,结构简单、直观,便于研究者对样本进行数据分析[20-21]。
但是,这种存储方式不易于聚类分析。 面板数据聚类分析的目的是发现样本之间的相似性,因此每个样本应该对应着该样本的特征向量。 面板数据难于聚类的主要原因就在于特征向量不易表达。 如果直接使用面板数据是无法进行表达的,当前采用最多、最易于实现的方式是将面板数据表示为如表1 所示的面板数据二维表示法。 每一行代表一个样本,每一列可以作为样本的特征向量,通过这种变换每一行就能够作为该样本的特征向量,从而进行聚类。

表1 面板数据二维表示法
其中,Dij(t)表示第i 个样本的第j 个指标在第t 期的值,i∈[1,N],j∈[1,m],t∈[1,n]。 将样本按照时间进行对齐的方式就能够对每个样本的特征进行刻画,从而进行聚类分析。
若将样本数据使用一个矩阵△x∈RN×M进行表达,则△x(k,l)与Dij(t)具有如下关系:

其中,k∈[1,N], l∈[1,M]。
特征向量间的相似性主要通过向量间距离进行计算。 常用的计算距离方法包括欧氏距离、曼哈顿距离、余弦距离等。 这些距离应用场景不同,各有利弊,其中应用最广泛的是余弦距离。 本文也使用余弦距离计算两个特征向量间的相似性:

其中,‖Vx(i)‖和‖Vx(j)‖分别为向量Vx(i)和Vx(j)的范数,为归一化向量。
为了有效地发现样本之间的相似性,首先利用一种典型的模糊聚类方法——模糊C 均值聚类算法FCM(Fuzzy C-Means)[22]来确定样板数据的聚类中心与隶属度矩阵。 该隶属度矩阵和聚类中心为下一节的划分和确定奠定了基础,具体的获取方法叙述如下。
算法1:隶属度矩阵与聚类中心获取算法。
步骤一:输入由事件构建所得特征矩阵△x,其中第i 行即为该条事件的特征向量△x(i);
步骤二:对于活动数C(2≤C≤N),当满足阈值ε 或者达到最大迭代次数K 时迭代停止,记录下取C 时所对应的隶属度矩阵和聚类中心;
步骤三:输出所有聚类数C 所构建的隶属度矩阵集合MU和聚类中心集合Center[22]。
定义1(Hpal 熵)[23]:

定义2(平均模糊熵):给定聚类数为C,通过算法1 求得的对应隶属度矩阵为U,则平均模糊熵定义为

其中,μij表示样本j 属于第i 类的程度。
通过定义2 可知,针对不同C 的平均模糊熵H(C)也不同,在所有的聚类数C(2≤C≤N)中,存在一个聚类数m 使得平均模糊熵H(m)达到最小值,此时所对应的聚类数m 即为最佳聚类结果,对应的隶属度矩阵和聚类中心分别记为Um 和CTm。 具体如算法2 所示[24]。
算法2:聚类结果确定及结果关联。
步骤一: 根据聚类数C 和相应的隶属度矩阵UC 依次计算每个聚类数C 所对应的模糊熵,得到模糊熵集合Entropy={entropy1,…,entropyC};
步骤二:对模糊熵集合归一化,得到归一化的模糊熵集合Entropy′={entropy1/e1-1/c,…,entropyC/e1-1/c};
步骤三:得到Ci=argminentropyi′及Ci所对应的聚类中心Centeri、隶属度矩阵Ui;
步骤四:根据隶属度阈值δ,聚类中心Centeri、隶属度矩阵Ui得到当前每个样本的聚类集合也就是聚类结果A,以及A 与各个样本的关联关系集R;
步骤五:输出聚类结果A以及A 与各个样本的关联关系集R。
(二)模型优势
多指标面板数据不仅能够用于表达包含时间维度与空间维度的横截面数据,还是一种重要的数据结构。 这种数据结构与当前聚类方法所采用的特征向量二维矩阵稍有不同,所以本文考虑通过对面板数据稍加变换即可作为企业的特征向量来表征企业。 该方式从数据结构的层面与当前面板数据复杂的表达方式不同。 在方法层面,本文主要通过FCM 聚类对多指标面板数据进行聚类。 已有的面板数据聚类往往是硬化分(例如朱建平[10]和李因果[11]采用的层次聚类方法),由于模糊聚类得到的样本属于各个类别的不确定性程度,表达了样本类属性的中介性,即建立起样本对于类别的不确定性描述,更能客观地反映实际事物。 同时,本文提出一种基于模糊熵的聚类评价方法, 通过计算每种聚类结果对应的熵值来评判聚类结果的优劣,从而确定聚类数。
三、 实证分析
(一)数据来源及说明
本文采用研发效率作为企业技术进步效应的替代变量。 先通过将《对外直接投资名录》和wind 数据库进行匹配,将对外直接投资时长超过10 年并且基本信息公布较为全面(主要是研发投入的数据)的企业筛选出来,其次对这些企业的研发效率逐个计算(研发效率的计算公式:RDratioti=Pti/RD(t-1)i,其中创新投入指标为R&D 经费,专利申请量P 是衡量技术创新产出的一个重要指标。 考虑到研发产出的滞后性,产出比投入滞后一期),保留研发效率呈上升趋势的企业共11 家,这些企业组成A 组数据。 另外一组由进行对外直接投资时间较短的企业组成,由于大部分企业是在2014 年左右才开始进行对外直接投资的,这些企业“走出去”的时间较短,研发效率的趋势并不稳定,因此随机从这些企业中抽取了报表中财务数据较为全面的企业共39 家,这些公司包括四川长虹电器股份有限公司、孚日集团股份有限公司、云南白药集团股份有限公司等,这些企业组成一个组,设为B 组。 A 组中企业数量有11 个,B 组中企业数量有39 个。 通过企业特征变量将这两个组的企业放在一起并进行模糊聚类,进行模糊聚类的企业成为C 组,观察C 组的聚类结果。 如果B 组中有企业能够和A 组企业聚在一起,说明这些企业具有相似性。 那么B 组企业在未来也有随着对外直接投资的进程,研发效率显著提升的可能性。 分析这些企业的特征,为企业进行对外直接投资决策提供可能的参考。 通过梳理已有文献,总结可能影响研发效率的因素,并且考虑到数据的可获取性,最终选择考察的指标包括:资本密集度(固定资产/员工数)、企业规模(从业人员对数)、资本流动性(流动资本-流动负债)/总资产、企业年龄(被调查年份-创办年份+1)、是否研发、资本劳动比、是否高新技术企业,时间周期从2011—2017 年,共7 期。
实验步骤设计为六步:a.对样本数据Data 进行预处理;b.将数据转化为二维特征矩阵;c.利用FCM 方法获得聚类数和聚类中心;d.通过本文提出的基于Hpal 熵的方法遍历聚类数,计算每种聚类数下的模糊熵;e.记录模糊熵值最小时的分布;f.多次重复实验步骤c、d、e,取多次重复且出现次数最多的聚类数为最终结果。
因为FCM 聚类每次聚类的结果可能不同,所以我们在实验方案中考虑通过多次计算(本实验计算50 次)选取多次中出现最频繁的聚类结果为最终结果。
(二)实验结果与分析
通过实验得到的结果如图1、图2 和图3 所示。 其中图1 为聚类数从1 变化到39 对应的平均模糊熵的变化情况。 从图1 中可以看出,当聚类数为7 时,对应的平均模糊熵达到最小值0.24,因此实验数据对应的聚类数为7。在该聚类数下,每个样本所属的聚类编号(从1 到7,共7 类)如图2 所示,每类包含的样本数统计结果如图3 所示。 从图2、图3 可以发现:第一类包含的样本数最多达到12 个;第3 类和第5 类包含的样本数最少,均只有1 个。

图1 平均模糊熵随聚类数变化

图2 聚类结果下每个样本所属类别

图3 聚类结果下各个聚类类别包含样本统计
通过聚类企业分类的结果如图4 所示。 第一类样本包括四川长虹电器股份有限公司、浙江新安化工集团股份有限公司、江苏银河电子股份有限公司、济南轻骑摩托车股份有限公司、株洲时代新材料科技股份有限公司、云南白药集团股份有限公司、博深工具股份有限公司、江苏联发纺织股份有限公司、深圳市大族激光科技股份有限公司、重庆华邦制药股份有限公司、北京福星晓程电子科技股份有限公司、歌尔声学股份有限公司(共12 家);第二类样本包括:浙江久立特材科技股份有限公司、阳光电源股份有限公司、中国南玻集团股份有限公司、新疆金风科技股份有限公司、四川海特高新技术股份有限公司(共5 家);第三类样本包括苏州胜利精密制造科技股份有限公司(共1 家);第四类样本包括广西柳工集团有限公司、亚普汽车部件股份有限公司、中信重工机械股份有限公司、浙江万丰奥威汽轮股份有限公司、中国长城计算机深圳股份有限公司、京东方科技集团股份有限公司、江苏金智科技股份有限公司(共7家);第五类样本包括双钱集团股份有限公司(共1 家);第六类样本包括江西铜业股份有限公司、杭州海康威视数字技术股份有限公司、孚日集团股份有限公司、金发科技股份有限公司、贵州钢绳股份有限公司(共5 家);第七类样本包括:潍柴动力股份有限公司、烟台冰轮股份有限公司、建研科技股份有限公司、浙江正泰电器股份有限公司、上海电气集团股份有限公司、北汽福田汽车股份有限公司、江汉石油钻头股份有限公司、武汉高德红外股份有限公司(共8 家)。

图4 企业分类结果
图4 展示了每类企业都有哪些家。 第一类企业共有12 家,第二类企业共有5 家,第四类企业共7 家,第六类企业共5 家,第七类企业共8 家,共有5 个组。 第三类和第五类各有1 家企业,因此不再考虑。 每一组企业的具体特征均值如表2 至表6 所示。
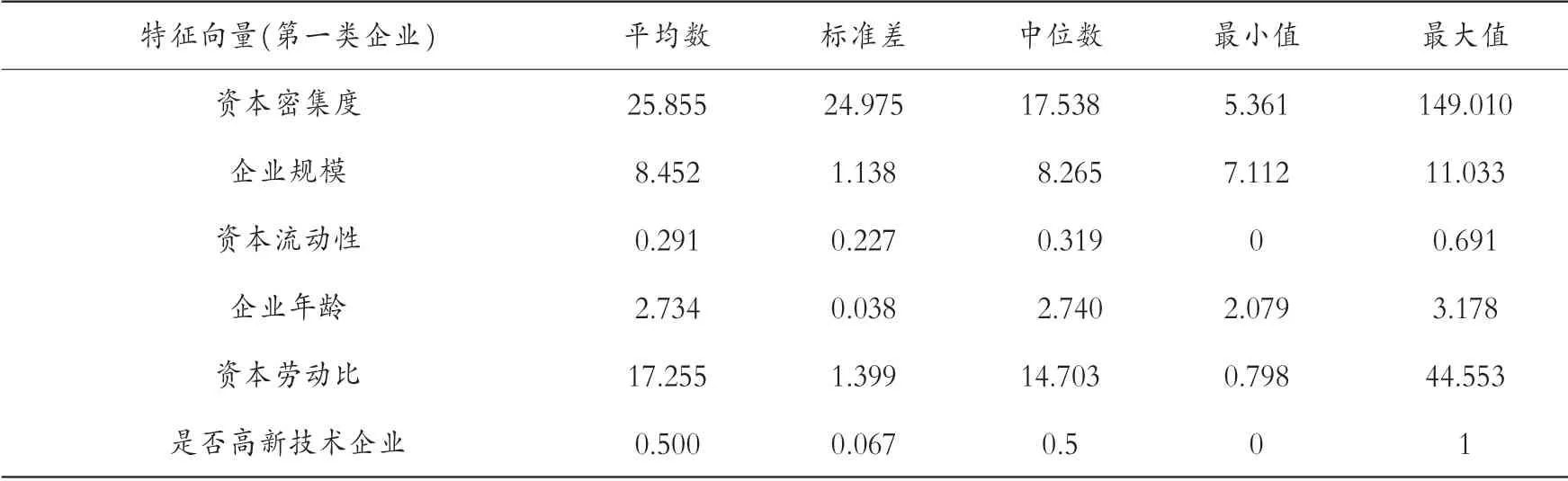
表2 第一组企业的描述性分析

表6 第七组企业的描述性分析

表3 第二组企业的描述性分析
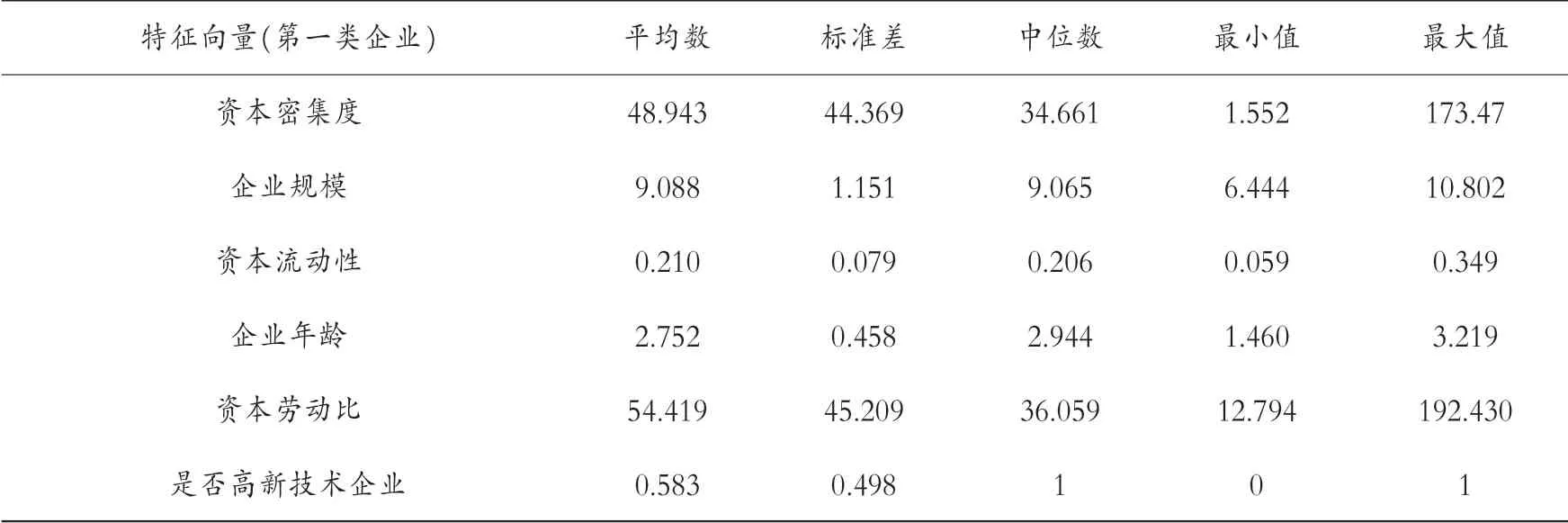
表4 第四组企业的描述性分析
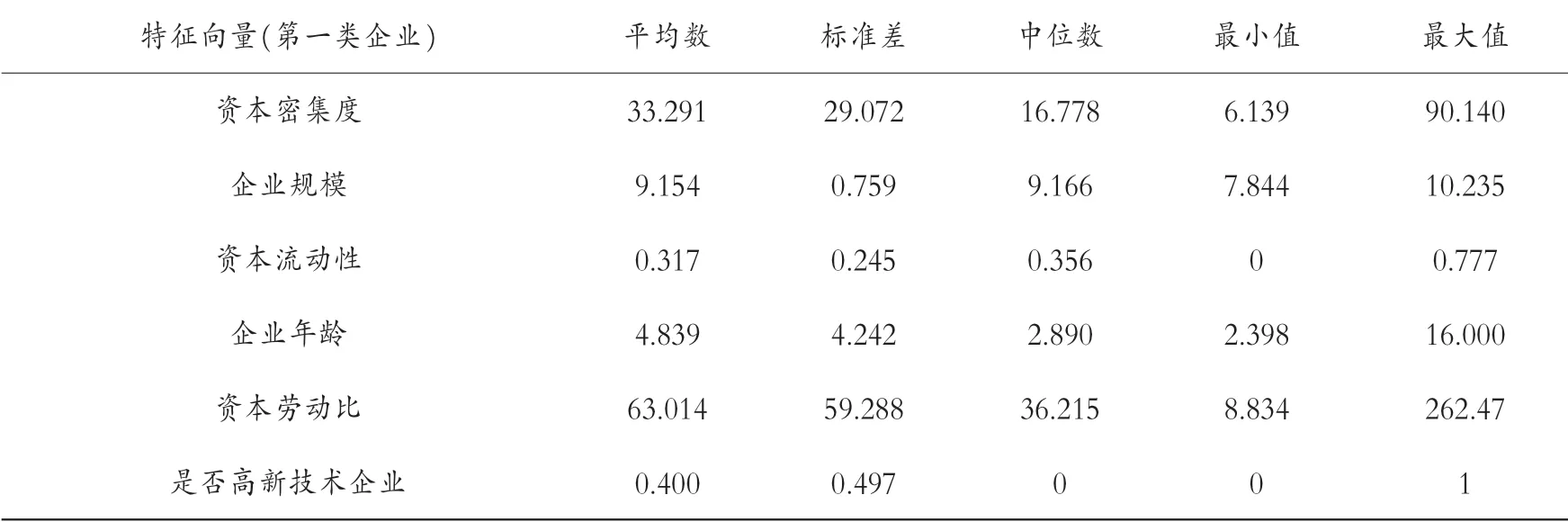
表5 第六组企业的描述性分析
几组数据中平均数都大于标准差,表示数据中没有极端值,并且将各组的特征分别进行排序。 资本密集度:第二组(66.474)>第四组(48.943)>第六组(33.291)>第七组(26.966)>第一组(25.855)。 企业规模:第六组(9.154)>第四组(9.088)>第七组(8.874)>第一组(8.452)>第二组(8.126)。 资产流动性:第六组(0.317)>第一组(0.291)>第七组(0.257)>第四组(0.210)>第二组(0.185)。 企业年龄:第六组(4.839)>第四组(2.752)>第一组(2.734)>第二组(2.716)>第七组(2.639)。 资本劳动比:第六组(63.014)>第四组(54.419)>第七组(31.943)>第二组(26.366)>第一组(17.255)。 是否高新技术企业:第二组(0.750)>第四组(0.583)>第一组(0.500)>第六组(0.400)>第七组(0.259)。 再次聚类,可以发现具有哪些特征的企业能够与长期进行对外直接投资的企业聚在一类。
(三)发现与结论
进行对外直接投资的企业达到十年及以上的,企业数据完整且研发效率呈增长趋势的企业分别是:深圳远望谷信息技术股份有限公司、深圳信隆实业股份有限公司、国光电器股份有限公司、宁波韵升股份有限公司、浙江海亮股份有限公司、横店东磁集团股份有限公司、杭州士兰微电子股份有限公司、江苏恒瑞医药股份有限公司、中国软件与技术服务股份有限公司、威海华东数控股份有限公司、青岛金王应用化学股份有限公司。 影响研发效率的企业特征如表7 所示。
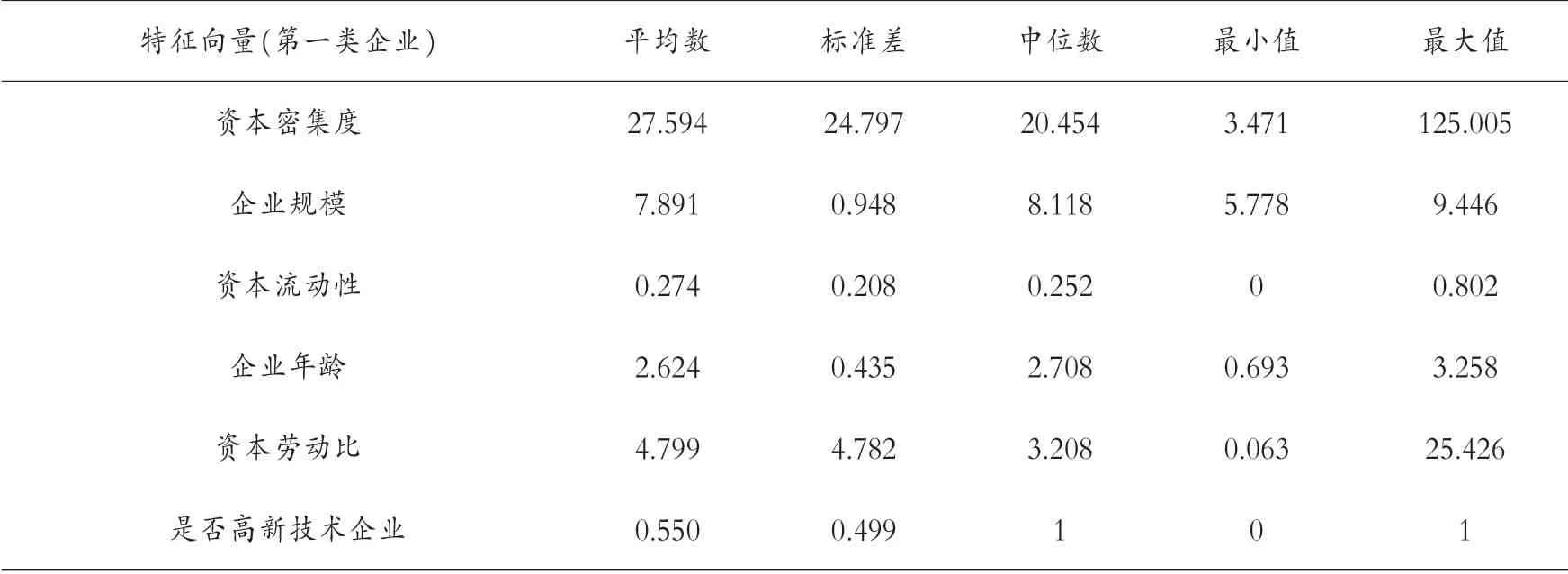
表7 影响研发效率的企业特征的描述性分析
将这11 家企业影响研发效率的特征与前文提到的39 家企业合在一起共50 家企业进行聚类,聚类结果如图5 所示。50 家企业共聚成两类,其中前11 家企业有10 家都在同一个类别中(类2),说明这10 家企业的特征都具有相似性。 因此推断在企业进行对外直接投资的过程中,技术进步显著的企业可能拥有表6 中描述的那些特征。 类2 中其余的企业共11 家,分别是歌尔声学股份有限公司、苏州胜利精密制造科技股份有限公司、双钱集团股份有限公司、四川海特高新科技股份有限公司、江苏联发纺织股份有限公司、中信重工机械股份有限公司、新疆金风科技股份有限公司、中国南玻集团股份有限公司、阳光电源股份有限公司、浙江久立特材料科技股份有限公司、浙江新安化工集团股份有限公司。 这些企业能与前面10 家企业聚为一类,说明他们的企业特征具有相似性;而将这些企业的研发效率进行测算,发现这些企业确实在对外直接投资期间研发效率呈增长态势。

图5 两组企业聚合分类结果
将上述11 家企业与分组企业对照发现, 第二类样本的5 家企业全都涵盖在这11 家之中。 这类企业的特点是规模较其他组的企业小,资产流动性较低,企业也比较年轻,但都是高新技术企业并且资本密集度明显高于其他组企业。 除了第二类的5 家企业,第一类有3 家、第四类有1 家,第三类有1 家和第五类有1 家也都在第二类分组里。 这些企业的影响因素特征的描述性分析如表8 所示。
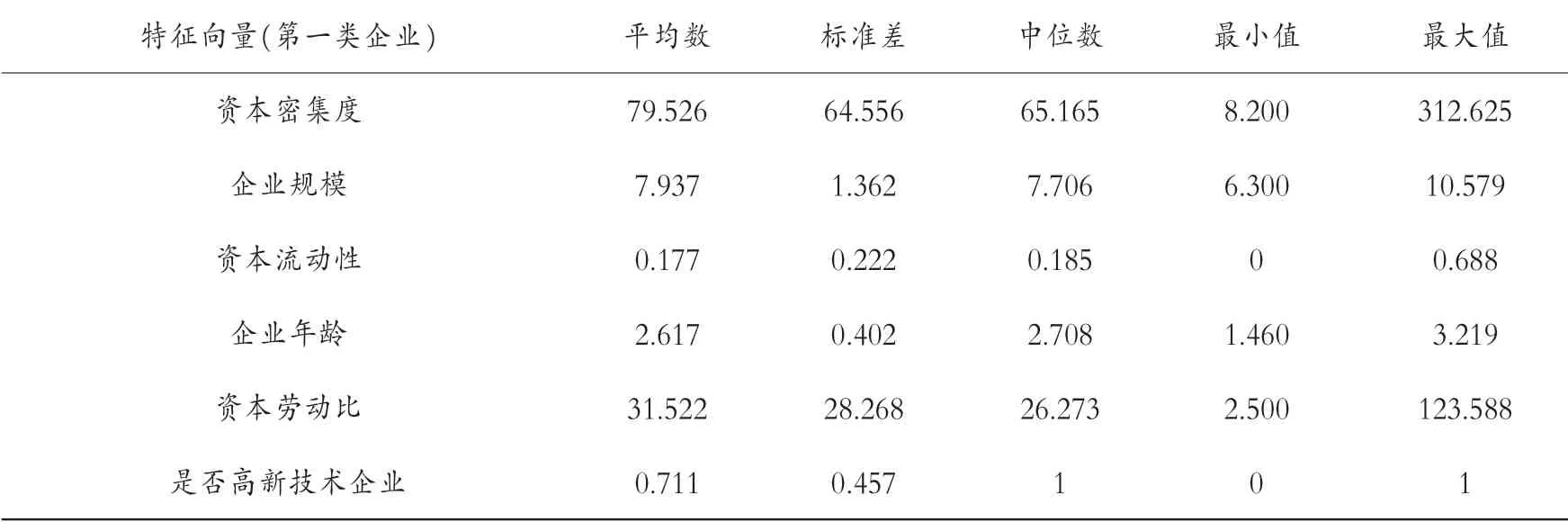
表8 企业影响因素特征的描述性分析
与第二类数据的特征相似,这11 家企业的平均资本密集度更高,企业规模更小也更为年轻,并且同样是高新技术企业较多。 因而可以得出这样的结论,对于近期进行对外直接投资或者未来将要进行对外直接的企业,并不是全部的制造业都可以通过对外直接投资方式提高创新能力,而具有如下特征的企业更能够通过对外直接投资行为实现技术进步:年轻的高新技术企业、规模相对较小且资本密集度远超出普通制造业的企业。
四、结语
在经济全球化的今天,国家与国家之间竞争的核心就是生产力的竞争。 新形势下如何有效提升科技进步对经济增长的贡献率成为一个值得研究和深思的问题[25]。 在当前开放经济条件下,如何有效发挥企业对外直接投资渠道从而提升创新绩效,对于作为世界第二大对外直接投资国的中国企业而言,形成自身竞争优势具有重要的现实意义。 关于制造业“走出去”的技术进步效应的影响因素,学者们已经展开了较为广泛的讨论,关注的重点也逐渐从外部环境的影响转移到企业自身,但由于方法的限制等原因,企业的特征因素往往得不到深入的挖掘。基于此,本文提出一种多指标面板数据的模糊聚类及评价方法。该方法首先将多指标面板数据从三维横截面数据转化为二维特征矩阵表示方式,其次利用改进的FCM 方法对特征向量进行聚类,再次提出一种基于Hpal 熵的模糊聚类自评价方法,最后通过遍历聚类数并计算当前聚类模糊熵进而确定最终聚类结果。 在此方法的基础上,将近期进行对外直接投资企业和已经对外直接投资超过10 年的企业面板数据分别进行多次聚类, 用以分析什么样的企业特征能够在长期的对外直接投资中实现研发效率的提升。 结果发现,近期进行对外直接投资的39 家企业中,有11 家企业与能够提高研发效率的企业聚为一类。 这些企业的特征包括:成立时间并不长,员工人数不多并且多为高技术企业。 这些企业由于资本密集度较高,因此资本流动性较低。
我国企业进行对外直接投资之前,除了进行海外市场的调研,了解海外高端技术行情以外,还应从企业自身的特征出发,考虑是否适合进行“技术获取型”的对外直接投资。 研究结果显示,高新技术企业进行对外直接投资相比于普通的制造业企业,更易于通过对外直接投资的方式提高创新能力。 对于普通的制造业企业来说,通过对外直接投资的方式直接提高创新能力的结果并不是很理想,因此普通的制造业企业应先拉近与高端技术的距离,逐渐提升自己的学习能力,然后再向更尖端的技术靠拢,这样才能将研发资金更有效地加以利用并有利于培养自身的核心竞争力。 在此之前可以考虑其他的途径提高自身的创新能力而不是跟风走出国门。 此外,结果显示,并不是成立时间较长的规模较大的企业能够通过对外直接投资来提高创新能力,反而是成立时间不长、规模也不大但资本密集度高的企业能够在技术获取型的对外直接投资中脱颖而出。 可能的原因是技术的提高除了需要大量研发资金和研发人员的投入外,更需要企业自身的设备作为支撑。 特别是中美贸易战之后,发达国家对中国的技术封锁越发严格(如华为被无理制裁),中国企业特别是高新技术企业通过对外直接投资的方式直接获取显性知识变得愈发困难。 在这种背景下,企业可以通过与海外子公司以及海外技术人员沟通交流来获取有益于创新的隐性知识,进而转化为显性知识来提高创新能力。 由于直接将专利和新产品反哺母国企业的趋势变缓了,因此只有结合自身的高端机械设备并结合发达国家的经验及技能,才能有效地通过“走出去”的方式提高中国企业的技术水平。 此外,年轻的企业可能更注重产品的创新研发,因此鼓励年轻的、规模不大但资本密集度高的高新技术企业“走出去”,就能够在未来获得更为显著的技术进步效应。
