一种基于情感特征表示的跨语言文本情感分析模型
2022-04-12徐月梅施灵雨蔡连侨
徐月梅,施灵雨,蔡连侨
(北京外国语大学 信息科学技术学院,北京 100089)
0 引言
随着国际化进程的加快和中国实力的逐渐增强,中国的新闻事件日益受到关注,不同国家的媒体平台会根据各自的立场进行报道。例如,YouTube上一条关于武汉新冠疫情爆发伊始的视频,有如下评论: “It is so terrible(英语)”“Le virus se propage à Wuhan(法语,意为病毒在武汉传播)”、以及“怖すぎる(日语,意为太可怕了)”。分析这些多语言评论文本的情感倾向对于精准把握国际舆论走向十分重要。
情感分析通过挖掘文本中的主观性信息来判断其情感倾向,例如,对某个事件的立场是褒扬还是贬损。现有情感分析主要采用监督学习的方法,需要借助大量已标注的文本对情感分析模型进行训练,进而实现对未标注文本的情感预测。然而,有标注的情感语料很难获得,尤其是非英语语言的情感语料。现有的情感分析研究在英语语言下积累了丰富的情感资源,例如,标注语料、情感词典等;而在其他语言中的情感分析研究相对较少,情感语料资源匮乏。跨语言情感分析(Cross-Lingual Sentiment Analysis, CLSA)旨在利用某一种语言(源语言)的情感资源来协助其他语言(目标语言)进行相应的情感分析。源语言一般为具有丰富情感资源的语言,例如,英语;目标语言则为情感资源较为匮乏的语种,例如,法语、德语、日语等。跨语言情感分析通过构建不同语言之间的知识关联以实现资源共享,能够解决大部分非英语语种所面临的情感资源匮乏的问题,因此成为近年来的研究热点。
现有跨语言情感分析的方法按照技术路线的不同可以分为三类: 基于机器翻译、基于平行语料库以及基于深度学习的方法。
基于机器翻译是跨语言情感分析研究的传统方法[1-4],其核心思想是采用机器翻译系统构建语言之间的联系,通过将已标注的源语言文本翻译为目标语言文本,以此作为训练数据,对目标语言的未标注语料进行情感分析和预测。这类方法思路简单,容易实现,但会受到机器翻译质量的影响。例如,真实在线评论“He cannot oppose that suggestion more(他百分百反对这个建议)”,由机器翻译得到的中文文本是“他不能再反对这个建议”,意思正好相反。
基于平行语料库的方法主要通过平行语料集学习源语言和目标语言在相同空间上的文本表示来进行跨语言情感分析。例如,Zhou等人[5]利用部分标记的平行语料形成跨语言情感分类子空间的学习框架。然而,对于大部分语言,高质量、大规模的平行语料仍难以获得,使得这类方法在不同的语种中开展研究时受到限制。
与基于机器翻译和基于平行语料库的方法不同,基于深度学习的跨语言情感分析为了减少对机器翻译系统和平行语料库的依赖,借助深度学习算法强大的特征自动提取能力和丰富的表示能力,将不同语言文本投影到同一个词向量表示空间后,再进行情感分析。这种方法主要基于Mikolov等人[6]提出的理论,即不同语言下同一语义的单词呈相同的分布结构,因此将不同语言文本投影到同一语义空间后,相同语义的单词距离接近。例如,英语和中文的单词映射到同一语义空间后,“猫”和“cat”靠在一起,“狗”和“dog”靠在一起。
现有基于深度学习的跨语言情感分析非常依赖于文本的单词向量表示(Word Embedding)。单词是语言构成的基本单元,识别不同语言的单词并用统一的方式表示出来,对于基于深度学习的跨语言情感分析尤为重要。大部分现有工作[7-8]为了减少随机词向量表示对跨语言情感分析的影响,采用Word2Vec模型[9]得到源语言和目标语言的词向量表示。现有实验结果表明,相比于随机初始化或者基于Word2Vec的源/目标语言词向量表示,借助预训练好的双语词嵌入(Bilingual Word Embedding, BWE)词典能够大大提升跨语言情感分析的效果[7]。比较遗憾的是高质量的BWE词典较难获得,尤其是对于大部分缺少标注语料的语言。因此,为了获得高质量的BWE词典并且减少在BWE词典生成过程中对目标语言标注数据的依赖,相关工作[10-12]研究无监督的BWE词典生成,借助大量无标注的目标语言数据生成BWE词典,取得了较好的效果。然而,Søgaard等人[13]指出,基于无监督的BWE词典生成方法对于语言对的选择非常敏感,仅仅依靠无监督的学习方法在某些语言对(如英语-日语)上难以得到高质量的BWE词典,仍然需要借助目标语言的监督信息,例如,少量的双语种子词典等。
本文提出一种基于情感特征表示的跨语言情感分析模型,尝试解决不同语言对的BWE词典较难获得的问题,不依赖于目标语言的标注数据,而是通过引入源语言具备的丰富的情感监督信息获得情感感知的词向量表示,从源语言的角度获得兼顾语义信息和情感特征信息的词向量表示,改进现有基于Word2Vec词向量表示的跨语言情感分析方法仅体现文本语义信息而忽略了单词之间情感关联的问题,有效提升跨语言情感分析的性能。
实验以英语作为源语言,分别将3种数据集上的6种不同语言(汉语、法语、德语、日语、韩语和泰语)作为目标语言进行测试。与机器翻译方法、不采用情感特征表示的跨语言情感分析方法相比,该模型能够分别提高跨语言情感分类预测性能约9.3%和8.7%。
1 相关工作
跨语言情感分析研究旨在借助丰富的源语言情感分析资源帮助目标语言开展情感分析工作,最早可追溯到2004年Yan等人[14]首次探索性地通过机器翻译来解决跨语言情感分析问题。
诸多研究表明,通过跨语言情感分析能够将英语语言下积累的研究成果在其他语言情境下推广应用。例如,万小军[1]利用英语有标注的情感分类数据,通过机器翻译实现中文文本的情感分类预测。余传明等人[8]以亚马逊的产品评论为例实现从英语到汉语和日语文本的情感分类预测。Vulic等人[15]通过跨语言词向量实现英语和荷兰语的相互检索。跨语言情感分析已成为情感分析领域的一个重要研究方向。
跨语言情感分析研究的难点在于目标语言情感资源的匮乏以及不同语言之间情感表达无直接关联[16],因此早期的跨语言情感分析主要采用机器翻译来建立不同语言间的关联,利用机器翻译系统直接将源语言语料翻译成目标语言,在此基础上进行情感分析任务。Carmen Benea等人[17]利用机器翻译获得目标语言的标注文本,然后利用有限的目标语言标注数据去训练情感分类器。万小军[2]首先实现从目标语言到源语言的机器翻译转换,再训练情感分类模型进行分类;在此基础上又提出了半监督的协同学习框架,进一步利用目标语言的无标注语料来大大提升系统性能。虽然通过机器翻译来构建跨语言间的情感分析联系已足够成熟,但仍避免不了机器翻译失误对文本情感带来的约10%的扭曲或反转现象[18]。
为了克服机器翻译质量对跨语言情感分析的影响,相关工作利用双语词典、平行语料库获得一致空间上的文本表示后再进行跨语言的情感分类。例如,Barnes等人[19]利用双语词典获取投影矩阵,将源语言和目标语言分别映射到共享空间。Zhou等人[5]利用部分标记的平行语料库形成跨语言情感分类子空间的学习框架。Turney等人[20]基于情感词对在语料中的共现频率来判断词的情感极性。对于基于双语词典的跨语言情感分析,关键在于如何构建高质量的双语情感词典。Wan等人[21]采用机器翻译将英文情感词典翻译成中文,但存在一词多义或者多词一义的问题,导致中英词条数量不对等。此外,双语词典和平行语料双语资源很难获取,仅在部分语言对之间建成较完备的双语资源。
近年来,深度学习快速发展,在自然语言处理的各类任务上取得了不错的成果,研究者们尝试将深度学习技术应用于跨语言情感分析,以减少对机器翻译和平行语料库的依赖。
基于深度学习中的生成对抗网络(Generative Adversarial Network, GAN)或者改进生成对抗网络(如对抗自动编码器)的跨语言情感分析方法[14]被分别提出。这些工作[7-8,12]通过生成-对抗模式进行迭代训练,得到目标语言和源语言在相同语义特征空间的词向量表示,实验表明,基于生成对抗网络的方法在跨语言情感分析上具有明显优势,性能优于基于机器翻译的跨语言情感分析方法。然而,基于生成对抗网络的跨语言情感分析[7-8,12]需要借助BWE词典,对于缺少BWE的语言对只能采用单语言下的随机词向量或者Word2Vec等词向量模型,大大限制了基于深度学习的跨语言情感分析模型的性能。因此,近年来相关工作开始研究跨语言的词向量表示(Cross Language Word Embedding, CLWE)以获得不同语言对的BWE词典,尤其是研究无监督的CLWE生成[10-12]。例如,Meng Zhang等人[10]提出一种无监督的基于对抗学习算法的双语词向量表示生成算法,以便获得更好的词向量表示,为下游的跨语言任务服务。Søgaard等人[13]研究发现,基于无监督的BWE词典生成方法对于语言对的选择非常敏感。对于部分语言对,依靠完全无监督的CLWE难以得到高质量的BWE词典。
本文的研究沿袭基于生成对抗网络的跨语言情感分析框架,在此基础上提出基于词向量情感特征表示的跨语言文本情感分析模型,通过引入情感感知的源语言词向量表示,使得源语言的词向量表示兼顾语义和情感特征信息,在基于深度学习的跨语言情感分析中关注到更多与情感分析任务相关的特征,提高跨语言情感分类性能。
2 情感感知的跨语言情感分析模型
图1描述了情感感知的跨语言情感分析模型的构建流程,主要包括3个模块: 情感感知的源语言词向量表示、基于生成对抗网络的跨语言联合特征提取以及情感分类预测模块。
模型的基本思路是: 首先引入源语言的情感监督信息,获得情感感知的源语言词向量表示,目标语言的词向量表示则通过随机初始化或者采用Word2Vec获得。然后,基于源语言情感感知的词向量表示,利用生成对抗网络获得目标语言与源语言在同一特征空间的联合特征表示。最后,输入上述两 步获得的源语言和目标语言的联合特征表示,基于已标注的源语言文本语料对情感分类器进行训练,预测目标语言文本的情感倾向。

图 1 跨语言情感分析模型构建流程图
给定源语言的标注文档用S={s1,s2,...sN}表示,N为文档的个数,sk表示S中的第k个文档。S中文档的情感标注用Y={y1,y2,...yN}表示,yk=1表示文档sk的情感极性为积极,yk=-1则表示情感极性为消极。目标语言的待预测情感文档用D={d1,d2,...,dN′}表示,N′为目标语言文档的个数,dk表示D中的第k个文档。跨语言情感分析需要解决的问题是利用源语言的已标注文本集合S和Y,预测目标语言文档集合D中的情感极性。
2.1 源语言情感感知的词向量表示
本文借助源语言的情感词典和已标注的源语言文本分别作为单词级别(word-level)以及文档级别(document-level)的情感监督信息,获得源语言情感感知的词向量表示。
给定文档sk={xk1,xk2,...,xkn},xki表示文档sk中的第i个单词,eki为单词xki的词向量表示,eki∈RM,M是词向量的维度。
根据S中所有单词构成的词汇表,构造一个词嵌入矩阵V∈RC×M,V中的每一行是一个单词的词向量表示,则C等于词汇表中单词的个数。利用正态分布初始化V中每一个单词的词向量表示。
2.1.1 单词级别情感监督
本文使用源语言的情感词典作为单词级别的情感监督信息训练单词的词向量表示。对于S中每篇文档的每个单词x,通过查表V得到其词向量表示e后,将e输入到单词级别的Softmax层,预测单词的情感倾向,得到单词的情感倾向分布p(c|e),如式(1)所示。
其中,θw和bw分别表示词语级别Softmax层的权重值和偏置值,c∈{1,-1}表示单词的情感极性,1表示正向,-1表示负向。


(2)

2.1.2 文档级别情感监督
使用已标注的源语言标注文本作为文档级别的情感监督信息。给定文档S,通过查表V得到所有单词的词向量表示,令se表示文档S的向量表示。定义se等于S中所有单词的词向量的均值,如式(3)所示。
其中,|s|表示文档S中单词的个数。将S的向量表示se输入到文档级别的Softmax层,根据向量表示se预测文档的情感倾向概率,得到文档S的情感分布值p(c|se),如式(4)所示。
其中,θd和bd分别表示文档级别Softmax层的权重值和偏置值。
用平均交叉熵作为损失函数,衡量文档的情感分布预测值和文档的真实情感标注之间的距离,如式(5)所示。

2.1.3 联合单词级别和文档级别的表示学习
单词的词向量表示应同时考虑单词级别和文档级别的情感信息。因此,定义总的损失函数为单词级别和文档级别损失函数的和,如式(6)所示。
其中,α∈[0,1]为折中系数,调整fword和fdoc对总的损失函数的影响。当α=0时,单词的词向量表示仅考虑文档语境的情感信息,α越大则考虑单词语境的情感信息越多,在3.5.1节将测试分析不同α值对跨语言情感分析性能的影响。
2.2 源语言和目标语言的词向量空间转换
源语言和目标语言的词向量空间转换旨在根据已知源语言的词向量表示得到目标语言在同一语义空间的文本向量表示,这一过程非常适合用生成对抗网络实现[24]。具体而言,主要包括生成器G和语言鉴别器D两个模块。
生成器G的目的是进行特征提取和词向量空间转换,使生成的目标语言词向量分布接近于源语言的词向量分布。设源语言的词向量es服从分布ps,目标语言的词向量ed服从分布pd。生成器G通过学习一个映射函数g:M→M,使得g(ed)的分布尽可能接近于源语言的分布。
生成器的目标是为了最小化源语言词向量分布和目标语言词向量分布之间的JS散度距离[22],文中用Wasserstein距离代替JS散度距离计算,主要考虑其在超参数选择上性能更稳定。因此,生成器利用Wasserstein 距离衡量源语言词向量分布ps和目标语言词向量分布pd之间的距离,目标是最小化Wasserstein(ps,pd)。语言鉴别器D是一个二元分类器,将g(ed)作为输入,输出判别其是来自于目标语言或者源语言。
G和D都是反向传播的神经网络,通过生成对抗训练互相博弈学习、反复迭代梯度更新,利用Adam进行优化。如果一个训练好的鉴别器D对于G转换得到的词向量分布无法判断是来自于目标语言或者源语言,说明生成器G实现了从目标语言词向量空间到源语言词向量空间的转换,迭代结束。
使用交叉熵损失函数定义生成器和鉴别器的损失函数。生成器的损失函数如式(7)所示。
其中,D(g(ed))表示鉴别器将生成器转换后的词向量判别为源语言的概率。
鉴别器的目标是区别源语言向量和目标语言向量的转换,其损失函数如式(8)所示。
本文采用深度平均网络(Deep Averaging Network,DAN)和CNN分别作为语言生成器G,相比于CNN,DAN具有更快的收敛时间[7]。语言鉴别器D则选择隐藏层数量为1的多层感知机。
2.3 跨语言情感判别
基于源语言和目标语言在同一语义空间的词向量表示,利用源语言的已标注文本对情感分类器进行训练后,输入在同一语义空间表示的目标语言文本,判别输出其情感极性。

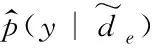
在跨语言情感分析中,目标语言的词向量空间转换以及情感极性判别作为统一的整体,在训练过程中,同时将情感分类器的判别结果和语言鉴别器D的判别结果反馈给语言生成器G,优化目标语言的特征语义提取。使用超参数λ来平衡二者的影响,因此,语言生成器G的损失函数定义如式(10)所示。
3 实验结果
为了验证所提基于情感特征表示的跨语言情感分析模型(Senti_Aware model)以不同语言为目标进行跨语言情感分析的性能,实验将已标注的英语文本作为源语言,分别选取了6种不同的语言作为目标语言进行测试,并与5种对比算法进行比较。5种对比算法分别是:
(1)单语言下的情感预测上限方法(以下简称Upper): 在目标语言(汉语、法语、德语、日语、韩语和泰语)中使用该语言标注好的文档数据作为情感分类模型的输入,然后将训练好的情感分类模型直接用于预测在该目标语言下的未标注文档。Upper方法中选择支持向量机(Support Vector Machine, SVM)模型作为分类模型。SVM在情感分类中表现优异,优于朴素贝叶斯、随机森林等算法[23]。
(2)机器翻译: 通过谷歌机器翻译引擎将目标语言翻译成源语言文本,利用已标注的源语言语料作为训练集对SVM情感分类器模型进行训练,再对翻译后的源语言文本进行预测。
(3)Bi_W2V Model: 与Senti_Aware model采用相同的跨语言联合特征提取模块和情感分类预测模块,参数设置亦相同;但没有使用情感感知的源语言词向量表示,而是用Word2Vec获得源语言和目标语言的向量表示。
(4)Bi_random Model: 与Bi_W2V model采用相同的模型和参数设置,但是使用随机生成的源语言和目标语言的词向量表示替代Word2Vec词向量表示。
(5)CLCDSA模型: Feng等人提出的一个基于Encoder-Decoder的无监督跨语言跨领域情感分析(Cross Lingual Cross Domain Sentiment Analysis, CLCDSA)模型[24],利用有标注的源语言数据和大量无标注的目标语言数据,对跨语言同领域或者跨语言跨领域的文本情感进行预测。实验中,CLCDSA采用与所提模型相同的数据集,数据集中所有文本作为同一个领域输入,不再细分数据的领域(例如属于DVD、书籍或音乐)。实验参数设置与文献[27]相同: 语言模型采用AWD-LSTM模型[24],每层的隐藏单元数为1 150,dropout rate=0.5,语言鉴别器采用1个3层的多层感知机,每层有400个隐藏单元,训练的迭代数为20 000个steps,每个词向量的维度为200。
3.1 实验数据集
考虑到没有一个现有的数据集能够提供5种语言以上的跨语言情感评测数据,因此实验选取了3个数据集,包括6种不同的目标语言,能够测试所提模型在不同数据集、不同语言上的泛化性能。这也是首次在跨语言情感分析研究中选择5种以上的语言进行实验评测。
其中,源语言和目标语言中的汉语、日语、法语和德语的数据来源于亚马逊网站的产品评论多语种数据集[25],每种语言包括12 000条标注的数据,分别是1星、2星、4星和5星的产品评分,星值越大表示评分越高。实验中将3星以下的数据标注为负向评论,将3星以上的数据标注为正向评论。
韩语数据集的选取参考文献[26],来源为韩国影评网站NAVER的用户评论,一共包含20万条评论的数据,已标注为正向或负向情感。为了与汉语、日语、法语和德语的数据测试规模保持一致,选取12 000条韩语数据作为跨语言预测数据。
泰语数据集的选取参考文献[27],主要为用户产品服务评论,一共包含26 737条评论,已标注为正向、负向和中性情感极性。其中,正负向评论共11 601条,经过数据预处理、分词后选取长度大于 1的数据,一共10 000条作为泰语跨语言预测数据。每个语种的数据集参数如表1所示。

表1 实验数据集参数
英语源语言采用已标注数据中的6 000条作为训练数据,6 000条作为测试数据;所提模型不需要对目标语言的标注数据进行训练,因此目标语言的标注数据仅作为验证跨语言情感分析的性能使用,汉语、日语、法语、德语和韩语采用12 000条数据作为待预测数据,泰语使用10 000条数据作为待预测数据。英语、日语、法语和德语还包括了大量无标注数据,这些未标注的数据和已标注的数据一起作为CLCDSA模型的输入,训练得到英语、日语、法语和德语的二进制编码文件,而对于汉语、韩语和泰语的二进制编码文件则是通过采用规模相对较小的有标注数据,将标注去掉后作为CLCDSA模型所需的目标语言无标注数据进行训练,得到汉语、韩语和泰语的二进制编码文件。
在进行跨语言情感分析前,需要对数据进行预处理。统一去除实验数据集文本中的标点及特殊符号。对于中文文本,采用jieba分词器进行分词,使用百度停用词表去除停用词;对于日语文本,采用MeCab分词系统,在调用Python接口时引入sys模块和MeCab模块,在-Owakati模式(无词性标注)下进行分词。对于泰语文本,使用泰语自然语言处理库PyThaiNlp进行分词。数据集中的法语、德语和韩语的文本,单词之间已由空格分开,无需进一步分词。
3.2 实验参数设置
实验的主要参数设置如表2所示。词嵌入向量的维度最小等于50、最大等于200;Batch_size(批量大小)为50;Epoch(训练次数)等于30;学习率为 5×10-4。超参数λ设置为0.01,相比于语言鉴别器的结果,情感分类器的判别结果对语言生成器而言影响更大一些。

表2 实验主要参数设置
3.3 实验评价指标
采用准确率(Accuracy)和F1值(F1-measure)作为情感分类预测的评价指标。对于情感预测二分类问题,混淆矩阵如表3所示。
其中,TP表示文档的实际情感标签为积极,模

表3 二分类混淆矩阵
型预测的结果为积极的个数;FP表示文档的实际标签为消极,模型预测的结果为积极的个数;FN表示文档的实际标签为积极,模型却预测为消极的个数;TN表示文档的实际标签为消极,模型预测的结果也是消极的个数。
根据表3,准确率的计算如(11)所示。
精确率和召回率的计算如(12)所示。
F1值作为精确率和召回率的综合评价指标,计算如(13)所示。
3.4 实验结果分析
表4展示了以英语为源语言,汉语、法语、德语、日语、韩语和泰语作为目标语言的跨语言情感分类预测结果。表4中,每个目标语言最优的预测准确率和F1值用加粗表示,次优数值用下划线表示。表4实验中,所提模型设置词向量的维度为50维,α取值为0.8,分别采用DAN和CNN作为源语言和目标语言联合特征提取的语言生成器。后续章节将讨论词向量维度大小、α取值以及是否采用预训练好的BWE词典作为联合特征提取器对于实验结果的影响。
不同跨语言对之间的情感预测性能会受到数据集大小、数据本身质量以及数据预处理程度的影响。例如,有的语言数据集本身的情感倾向表达比较明显,有助于情感预测;而有的语言数据集情感倾向表达比较隐晦,不利于情感预测。这一点体现在Upper方法应用在不同语言上的情感预测性能各不相同。在进行跨语言情感预测时,既要进行纵向对比,即在同一种语言中对比不同算法的跨语言预测性能,分析不同算法的性能优劣;又要进行横向对比,分析同一个算法在不同语言中的跨语言预测性能。
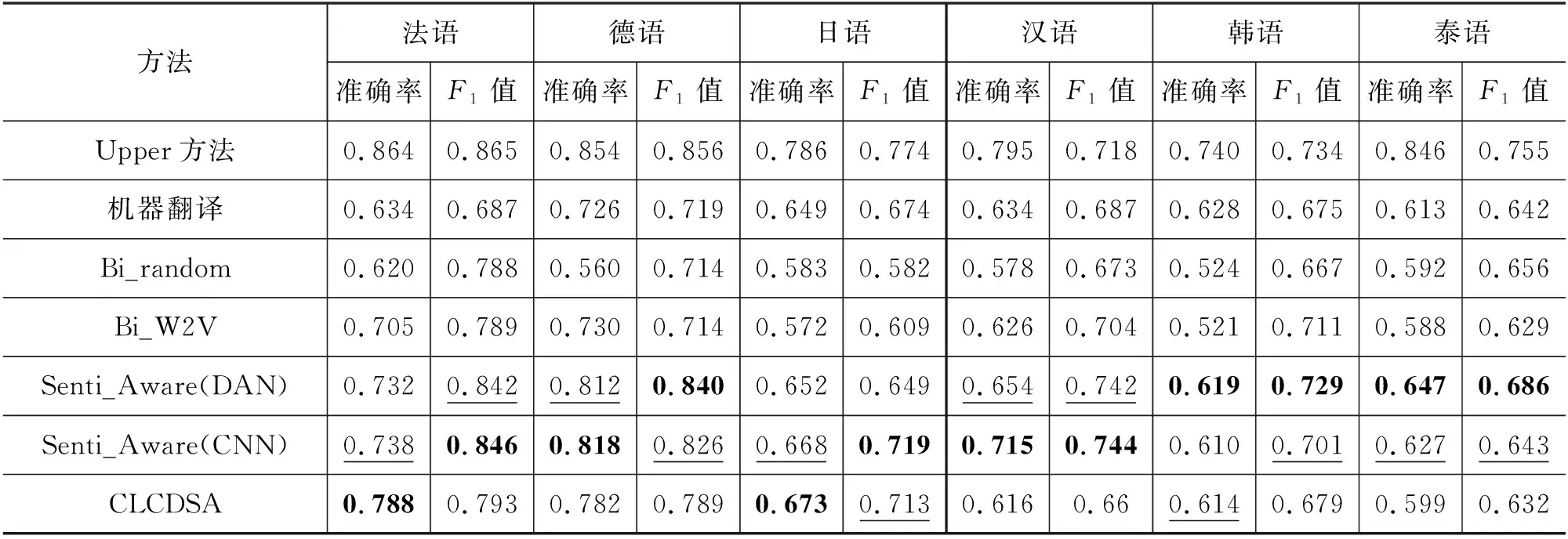
表4 以英语为源语言,法语、德语、日语、汉语、韩语和泰语为目标语言的跨语言情感预测
表4的实验结果表明,所提模型在汉语、法语、德语、日语、韩语和泰语6种不同语言上的跨语言情感分类的性能都优于基于机器翻译、Bi_random和Bi_W2V方法,验证了基于情感特征表示的跨语言文本情感分析方法的有效性。Upper方法提供了模型能达到的跨语言情感预测分类性能的上限值。可以看到,所提模型Senti_Aware(DAN)在德语上准确率和F1值分别为0.812和0.840,接近于Upper方法的0.854和0.856。
从不同语种比较,当法语、德语作为目标语言时,情感特征表示的优势更明显。在法语实验中Senti_Aware(CNN)准确率提升至0.738,F1值提高至0.846;在德语中准确率和F1值则分别为0.818和0.826。在数据处理过程相同、参数条件不变情况下,纵向比较不同方法在不同语言上的性能,发现跨语言情感分类模型在德语数据集上表现最好,主要与不同语言之间的距离有关。英语与德语同属日耳曼语族,虽然英语在词汇上较法语接近,但在语法和语音上与德语更接近,因此在英语-德语语言对的跨语言情感分类中性能最好,符合实验预期。
分析Word2Vec词向量生成对跨语言情感预测的影响。对比Bi_random和Bi_W2V在不同语言上的性能发现,Bi_W2V相比Bi_random并没有明显的性能提升,说明相比于随机生成得到的词向量表示,采用Word2Vec对源语言和目标语言分别生成独立的词向量空间对跨语言情感分类预测提升不明显,更重要的是如何将两个独立的词向量空间映射到同一语义空间。这也进一步印证了在跨语言情感分析中,通过深度学习模型实现两种语言的词向量特征空间学习、迁移是非常重要的一步。
基于机器翻译方法的性能在法语、德语和汉语上的跨语言情感预测性能甚至低于Bi_W2V算法。由于现有的翻译引擎API接口不能支持多于 5 000 字的文本翻译,实验过程对机器翻译方法的实现需要将数据集切分成几个部分,分开翻译再合并,耗费了大量的翻译、数据整理时间;性能上却没有 Bi_W2V 简单采用Word2Vec生成词向量后进行跨语言情感提取和预测的性能好。侧面说明,相比于基于机器翻译的跨语言情感预测,基于深度学习的方法优势明显,是跨语言情感分析未来的发展方向。
CLCDSA方法在不同目标语言上的跨语言情感预测性能差别较大,在法语、德语和日语的性能相比其他三种目标语言性能更为突出,而在汉语上的性能最差(相比较其他算法)。除了上述分析中以英语为源语言,与目标语言法语和德语更为接近以外(日语和英语的距离并不接近,可以看到和法语和德语相比,日语的效果明显较低),主要原因在于: 法语、德语和日语数据集包括了大量的无标注数据(表1),而数据集中的汉语、韩语和泰语则没有提供无标注数据,实验中只能将对应语言的有标注数据去掉作为CLCDSA模型的无标注数据进行输入。在汉语、韩语和泰语中,又以汉语的标注数据最少,只有12 000条。实验结果确证了CLCDSA方法的结论,即利用目标语言大量的无标注数据学习单词语义,有助于提高跨语言的情感预测。当缺少标注数据时,CLCDSA的性能明显下降。此外,实验中曾将Chen等人[7]使用的数据集作为CLCDSA的中文无标注数据,发现对性能提升不大,主要原因在于酒店的用户评论数据和亚马逊数据集有一定区别,对于目标待预测文本的语义学习帮助不大。
CLCDSA在法语和日语上得到了最好的情感预测准确率,分别为0.788和0.673,高于所提模型Senti_Aware(CNN)的0.738和0.668。但从6种不同的目标语言上看,所提模型在不同语言、不同数据集上的泛化性能更突出。在同样的亚马逊数据集上,所提模型在德语和汉语上的预测准确率和F1值均优于CLCDSA;在跨语言跨数据集时,即以亚马逊用户评论的英文数据集为数据源,预测目标语言为韩语的电影评论数据集和目标语言为泰语的产品数据集,Senti_Aware(DAN)相比CLCDSA具有明显优势。此发现与文献[24]中的结论吻合: CLCDSA在跨语言跨领域的情感预测性能低于在跨语言同领域中的性能。
对比分析不同的特征提取网络对所提模型的影响。实验中分别利用DAN和CNN作为特征提取网络,发现改变特征提取网络,Senti_Aware的性能有波动但基本稳定。相较于其他对比算法,Senti_Aware(DAN)和Senti_Aware(CNN)仍有明显优势,表明本文模型在跨语言情感分析任务中的有效性。实验结果表明,特征网络为CNN时的平均准确率略高一些,将特征提取网络从DAN改变为CNN后,模型的准确率可提升0.6%~1%。在训练过程中,DAN的收敛速度更快,CNN则相对速度较慢。例如,在型号为Tesla V100、显存大小为31 GB的GPU服务器上跑相同的数据集和相同的实验设置,以泰语的数据集文本预测为例,基于DAN特征提取网络的Senti_Aware需要时间约6分11秒,而基于CNN特征提取网络的Senti_Aware需要时间约12分3秒,CLCDSA模型则需要42分50秒。
横向对比跨语言情感预测模型在不同语言上的情感预测性能发现: 当法语、德语作为目标语言时,跨语言情感预测性能更接近于Upper方法在单语言下的预测性能,明显优于以日语、汉语、韩语和泰语为目标语言时的性能。以Senti_Aware(DAN)为例,所提模型在法语和德语上的预测准确率分别为0.732和0.812,而在其他目标语言上的预测准确率都低于0.68,主要原因在于以英语为源语言时,英语-汉语、英语-德语跨语言对之间的语法、语义差别较小,而英语-汉语、英语-韩语和英语-泰语中这些语言对之间的距离较大。实验结果从侧面说明,进行跨语言情感分析应从语言本身出发,针对目标语言选择距离较近的源语言,提高跨语言情感分析的性能。
综上所述,本文模型在不同语种、不同数据集实验中具有较强鲁棒性,取得较好的分类效果,证明融合情感特征表示有助于跨语言情感分析。
3.5 影响跨语言情感分析的因素分析
本节讨论影响跨语言情感分析模型的因素,主要讨论不同α值、词向量维度和是否采用预训练好的BWE词典对模型的影响。以德语为目标语言进行分析,在其他几个语言上的对比分析结果类似,因篇幅关系不一一列举。
3.5.1 α值对跨语言情感分析的影响
在融合情感语义的词嵌入训练过程中,α值大小会对词嵌入的表示能力有影响。由于在德语数据集上分类效果表现最好,故选用德语数据集探究不同α值的影响,步长为0.1,实验结果如图2所示。

图2 不同α值对于跨语言情感分类的影响
从图2可以看出,α为0.1时分类准确率可达到0.794,此时文档级别的情感信息权重最大;当α值逐渐增大,分类准确率逐渐下降;当α值为0.5时准确率最低,此时单词级别和文档级别的情感信息权重相同。当α值继续增大,代表单词级别的情感信息权重超过文档级别情感信息,此时分类准确率有所提升,并在α值为0.9时达到最高准确率0.812。实验结果表明,单词级别与文档级别的情感信息均有较好的独立监督效果,但当二者权重接近时,情感信息利用率下降,从而影响词嵌入表示效果,进而导致跨语言情感分类准确率下降。
3.5.2 词向量维度对跨语言情感分析的影响
词向量的维度大小对单词语义的表示能力有一定影响,因此本节实验分别将词向量维度设置为50维、100维、150维、200维,探究词向量维度对跨语言情感分析的影响。实验仍选用德语数据集,特征提取网络选择DAN,实验结果如表5所示。
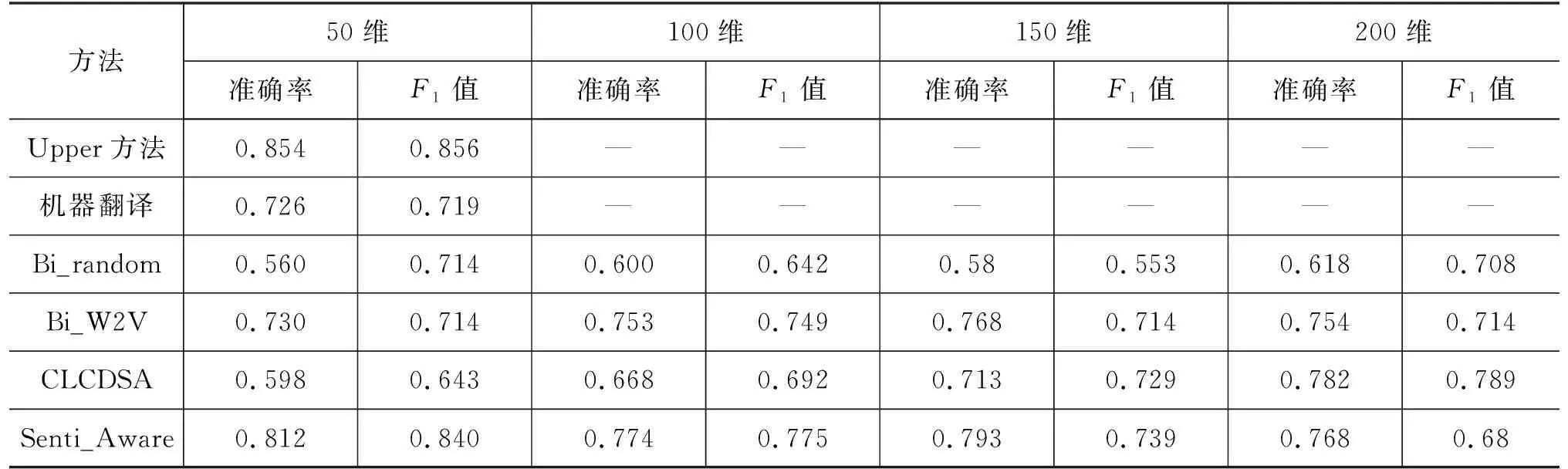
表5 词向量维度对跨语言情感分析的影响
从实验结果可以看出,在跨语言情感分类任务中随着词向量维度的升高,仅采用随机词嵌入的Bi_random 方法在词向量维度为200维时分类准确率也能达到0.618,F1值为0.708,且提升最为明显。说明对于随机初始化文本向量的Bi_random方法,词向量维度较大时,表征的信息更多、效果更好。
当采用Bi_W2V方法时,增大词向量维度,准确率有小幅度提升,当词向量为100维时Bi_W2V方法获得最高F1值0.749,词向量为150维时获得最高准确率0.768,而当词向量维度进一步增大到200维时,准确率和F1值反而有所下降。
对于Senti_Aware方法,改变词向量维度大小对于分类准确率提升不明显,在维度为50维时已经能很好融合情感语义信息,最高准确率达到0.812,F1值达到0.840,具有很好的稳定性。
对于CLCDSA方法,词向量维度等于200时性能最好。随着向量维度的降低,性能有所下降。下降的原因主要是Encoder-Decoder模型的参数随着向量维度的下降而降低: 在词向量维度等于200时,模型的参数个数是1 333万个;当词向量维度等于50时,模型的参数个数降到72万个。
3.5.3 BWE对跨语言情感分析的影响
本节讨论BWE双语词嵌入词典对跨语言情感分析的影响。相关工作指出,相比于随机初始化的词向量表示或Word2Vec词向量表示,借助预训练的BWE词典获得源/目标语言的词向量表示能够大大提升跨语言情感分析的效果[8]。
为了分析BWE对跨语言情感分析的影响,使用预训练好的BWE词向量表示(以下简称Bi_BWE方法)替代基于情感特征表示的词向量(即本文所提Senti_Aware方法)进行对比实验。两种方法采用完全相同的实验参数和设置,以DAN为特征提取网络,α值取0.9。考虑到不同语言对的BWE词典较难获得,在实验测试的6种目标语言中,仅有英语-汉语、英语-法语和英语-德语具有预训练好的BWE词典,因此本节的对比实验以汉语、法语和德语为例进行。
实验中,英语-汉语BWE词典来源于Zou等人的工作[28],一共包含了199 870个中英文单词的词向量表示;英语-法语和英语-德语的BWE词典则来自于广泛使用的MUSE双语词嵌入词典集。MUSE双语词典(1)通过对各种语言的维基百科数据词条进行预训练得到,涵盖了30种不同的语言,主要以欧盟国家的语言为主。,各包含40万个双语单词的词向量表示,其中,英语、法语和德语各有20万个单词。实验结果如表6所示。
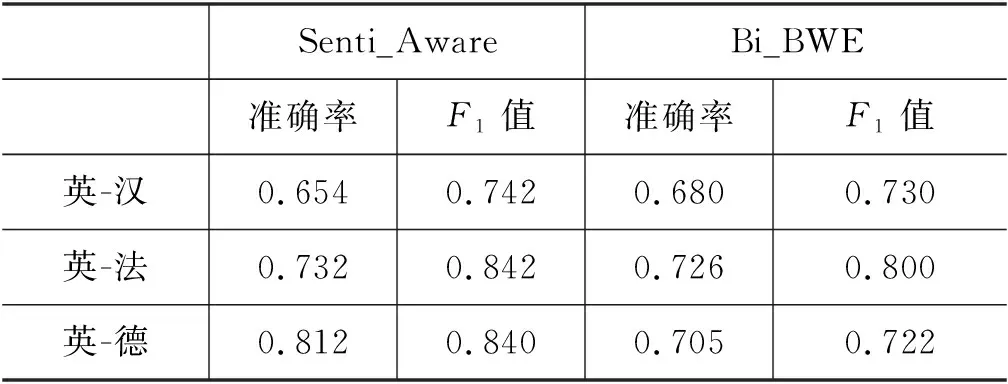
表6 不同BWE词典跨语言情感预测性能对比
分析表6的结果发现,Senti_Aware与Bi_BWE相比仍具有一定优势,二者在汉语上性能相当,相比Bi_BWE,Seni_Aware模型在法语上略有提升,在德语上表现出明显优势。此外,对比表4的实验结果,我们发现Bi_BWE的性能在不同语言上都明显优于Bi_random的随机词向量表示,但与Bi_W2V相比性能提升不大。分析原因主要如下:
第一,英语-汉语的BWE词典是基于中英文用户评论数据训练得到的,所采用的训练数据集与实验数据集比较贴近,能够较好地表示实验数据集中单词的词向量,因此在汉语上性能提升较大;而英-法和英-德的BWE词典是基于维基百科的数据词条训练得到的,词典大而全,但是在语义表达上并不贴合实验的用户评论数据集,在性能上不如直接采用Word2Vec基于实验数据集生成得到的词向量表示。
第二,Senti_Aware在德语上的跨语言情感预测性能提升最大,明显优于法语。从Bi_BWE的结果看德语和法语的性能相当。除了上述分析的英语-德语之间的语义距离较英语-法语更近,另一主要原因在于实验数据集中德语用于训练目标语言的词向量表示的数据约为31万条,而法语的数据量则约为5万条(表1),数据量越多越有利于生成得到更好的词向量表示,有助于下游的情感预测任务。
综上实验结果表明,采用BWE词典能够提升跨语言情感分析性能,所采用的BWE词典的语义应与预测的数据集语义表示比较接近,才能有效提高跨语言情感预测的性能。
3.6 单词词向量表示的可视化分析
为了从语言学和语义角度分析基于源语言情感特征的词向量表示相比Word2Vec更能兼顾单词语义和情感特征信息,本节利用可视化方法对比Senti_Aware和Word2Vec模型所获得的词向量表示。
通过Word2Vec或Senti_Aware得到的单词词向量表示都是50维的高维向量,无法在二维平面进行可视化,因此实验中采用主成分分析(Principal Component Analysis,PCA)方法对实验中获得的词向量表示进行降维,最后在二维平面输出。PCA常被用于高维数据的降维,提取高维数据的主要特征分量后映射到低维平面输出[29]。

图3 Word2Vec和Senti_Aware词向量表示示例一

图4 Word2Vec和Senti_Aware词向量表示示例二
图3和图4分别展示了两组单词在Word2Vec和Senti_Aware词向量表示下的二维平面可视化输出。为了能够清楚看到可视化的表示结果,实验选取了少量几个单词作为示例。图中的每一个点代表一个单词的高维词向量在PCA降维后的二维平面嵌入结果,两个点的词向量表示越接近,则在二维平面越靠近。Word2Vec的词向量表示结果在图的左边;Senti_Aware词向量表示的结果在图的右边。
图3中为一组单词“good”、“delicious”、“hate”、“bad”、“exciting”、“happy”、“beautiful”在二维平面的可视化结果。这组单词的情感极性比较明显,可以看到Senti_Aware的词向量表示兼顾了单词的情感特征信息,能够区分情感极性不同的单词。例如,情感极性负面的单词“hate”和“bad”比较靠近,而“good”和“delicious”则聚集在一起。对比Word2Vec的词向量表示,单词“happy”、“bad”和“beautiful”聚集在一起,无法有效区分单词的情感极性。
在图3的基础上,增加几个语义较为接近的单词: “dog”、“cat”和“bird”,而随机去掉几个单词,可视化结果如图4所示。可以看到,Word2Vec模型在语义表征上更有优势,能够将语义相近的单词“dog”、“cat”和“bird”聚集在一起,但是单词“hate”和“exciting”则仍重叠在一起。而Senti_Aware的词向量表示则仍能明显区分单词的情感极性,“hate”作为情感极性为消极的单词,与其他单词有明显的语义距离。
4 结论
本文提出一种基于词向量情感特征表示的跨语言文本情感分析方法,在缺乏BWE词典的情况下实现从英语到其他目标语言的跨语言情感极性预测,解决了在基于深度学习的跨语言情感分析中BWE词典较难获得的问题。所提方法在跨语言情感分析模型中引入源语言的情感监督信息以获得源语言情感感知的词向量表示,使得词向量表示能兼顾语义信息和情感特征信息,从而提高情感预测的性能。实验以英语已标注的文本数据为源语言,分别在6种目标语言(汉语、法语、德语、日语、韩语和泰语)的未标注文本上进行情感极性预测。
实验表明,所提模型在6种语言上均有较好表现,优于基于机器翻译、基于Word2Vec和采用BWE双语词嵌入词典的跨语言情感预测方法。所提模型在德语上的跨语言情感分类性能最好,达到0.812,接近于在德语单语言下的情感预测性能。本文还分析了影响跨语言情感分析模型的不同因素,实验发现: ①单词级别与文档级别的情感信息均有较好的独立监督效果,能够提升模型的性能;②选择不同的特征提取网络如DAN和CNN对模型的性能带来0.6%~1%的影响,从模型预测准确率和收敛速度上看,DAN的总体表现较好;③高维词向量对于所提模型的分类准确率提升作用不明显,在维度为50维时已经能很好融合情感语义信息;④采用BWE双语词典有助于跨语言情感预测,然而不同语言对的BWE词典较难获得,本文方法能够在缺少BWE词典的情况下实现跨语言情感极性预测。
