基于XGBoost模型的地铁列车运行状态仿真方法
2022-04-11门元昊刘晓双秦枭喃罗森林
门元昊 吴 亮 刘晓双 秦枭喃 罗森林
(1. 北京理工大学信息系统及安全对抗实验中心, 100081, 北京; 2. 通号城市轨道交通技术有限公司, 100081, 北京∥第一作者, 硕士研究生)
列车运行状态仿真即通过建立真实运行环境的近似模型,模拟地铁列车在ATC(列车自动控制)系统下的运行表现,可结合电子地图实现列车位置、速度的估计反馈,是测试列车控制系统的重要工具。仿真的目的是为ATC系统的研究提供模拟试验平台。由于ATC在设计、开发、测试等各个环节所需投入的时间长且系统不断更新迭代,在其研制过程中持续地在真实的生产环境中进行开发与调试是不现实的,因此,通常需要先建立列车运行状态的仿真模型,在仿真模型上开展相关系统的研发工作。目前,针对列车运行状态的仿真仍以传统的物理模型或改进的物理模型为主[1-3],这些方法均对列车的受力及运动学模型进行了简化与近似,且面对不同的列车与线路环境时,需对照真实的运行数据采用人工方式来调整模型参数,存在着列车适配性差、仿真误差大等问题,难以高效、准确地模拟ATC在真实环境中的实际表现,不利于系统的评估与改进。
针对上述问题,基于机器学习的理论与方法,本文通过挖掘列车在目标环境下的运行表现,结合特征工程提高算法对ATC系统延时等特性的学习能力,基于XGBoost(极端梯度提升)算法建立具备更好适应性与准确性的列车运行状态仿真模型,为ATC系统的研发提供基础技术支撑。
1 现有的列车运行状态仿真方法概述
现有的列车运行状态仿真系统一般以物理模型为基础,结合人工或求解式的参数调整方法,实现列车控制输出与实际表现间函数关系的拟合,进而对加速度、速度、位置等描述列车运行状态的属性进行估计与仿真,常采用包括单质点模型、多质点模型、绳体模型等描述方法拟合列车的动力学表现。文献[4]提出了一种针对高速列车运行的仿真方法,使用绳体模型对列车进行动力学建模,能够较好地模拟出列车质量分布均衡、动力分布分散的特点,准确模拟列车运行状态,但由于不同列车的质量与动力分布特点差异较大等原因,该方法难以适配不同型号的列车和复杂运行的线路。
综上,随着仿真技术的不断发展,基于物理模型的方法对输出动力的作用效果进行估算的准确性在持续提升,但仍缺乏适应ATC系统输出延时、适配不同列车性能特点的能力。因此,引入机器学习理论,研发可自动化利用真实运行数据,构建可准确拟合控制命令与列车表现间复杂函数关系的仿真模型,以提高对列车运行状态的仿真能力。
2 基于XGBoost算法的列车运行状态仿真方法
2.1 算法原理
本文提出一种基于XGBoost集成学习算法的列车运行状态仿真方法,其原理如图1所示。该方法基于真实的运行数据,首先针对列车运行过程中在不同速度、坡度及轨道状态等条件下施加相同的牵引/制动级位所产生不同加速度的作用效果,以及特定列车具有独特且伴有一定随机性的系统延时等问题,采用特征工程扩展优化原始数据维度,筛选并建立轨道信息、速度状态以及级位序列的特征子集,合并构成新的特征空间;在此基础上,利用XGBoost算法,学习任意采样时刻不同状态下控制命令(包括历史命令信息)与实际加速度间的关系,从而实现对下1个采样时刻列车运行状态(借由速度、位置进行描述)的估计。由此建立可与ATC在电子地图辅助下进行交互反馈的列车运行状态仿真模型。

图1 基于XGBoost模型的地铁列车运行状态仿真方法原理Fig.1 Principle of metro train running state simulation method based on XGBoost model
2.2 特征工程
训练数据的样本质量与特征空间是决定机器学习效果的关键要素之一,因此首先对原始数据中存在的不完整数据(如采样遗漏等)、异常值(如日志错误等)进行清洗,提取出完整的站间运行数据,然后针对列车运行状态仿真任务,采用特征工程方法引导机器学习算法准确挖掘目标函数关系。
列车运行状态仿真模型的核心任务是:观察当前采样时刻的轨道坡度、列车速度、控制级位等数据,基于隐含了列车运动模型、控制延时特性、级位作用表现等信息的作用效果估计模型,预测列车在下1个采样时刻的速度表现。因此,特征空间应包含轨道信息、速度状态和级位序列,而训练标签可通过计算采样时刻间的列车速度变化获取。
综上,为建立可面向不同列车和不同线路环境、训练成本低、特征空间具有一定地铁环境数据普适性的列车运行状态仿真模型,挖掘列车运动模型、控制延时特性、级位作用的表现特征,本文所述方法将当前时刻的坡度数据、速度信息、历史级位作为特征空间的主要组成。设t时刻列车的运行特征为xt={et,vt,lt},其中:et为t时刻列车所处位置的坡度;vt为t时刻列车运行速度;lt为t时刻列车输出的级位序列{lt,0,lt,1,…,lt,k},lt,k为t-k时刻列车运行系统输出的级位。依据目标列车的经验最大延时周期数,将k设为11,历史时刻不足的采样点则实施补零操作。同时,将列车t+1时刻与t时刻的速度差at(即t时刻的加速度)设为样本标签。最终构建出13维的特征向量及1维的样本标签,由此可依照有监督学习方法进行后续的模型训练及验证。
2.3 模型构建
利用预处理后的数据集训练XGBoost模型,以实现对采样点列车瞬时加速度的估计。XGBoost算法是文献[5]提出的一种可扩展的端到端基于树的Boosting(提升方法)家族算法,可通过构建多个弱学习器,将这些弱学习器组合形成强学习器。通常选取决策树等子模型作为此算法的弱分类器。XGBoost算法因其优异的泛化性能被广泛应用于有监督学习领域,适合用于列车运行状态的仿真任务,相比GBDT(梯度提升决策树)方法,XGBoost算法在代价函数中加入了正则项,可有效控制模型的复杂度,同时支持多线程训练。采用XGBoost算法后模型的计算速度更快,可满足不同规模列车的运行数据仿真要求。
在模型训练中,XGBoost算法利用坡度数据、速度信息、历史级位等参数自适应地挖掘列车行驶过程中的加速度表现和控制延时特点,以有效模拟列车在ATC系统下的真实运行表现。与基于列车输出级位和加速度间的对应关系表(以下简称“加速度表”)的传统物理模型相比,XGBoost算法能够适应性地降低因环境因素干扰或列车实际参数与出厂参数不完全匹配等问题引发的仿真误差。XGBoost算法的基本原理如下:
对于样本集N={(x1,y1),(x2,y2),…,(xn,yn)},训练优化函数参数空间F,使得全局上目标函数O(F)最小。目标函数可表示为:
O(F)=l(F)+Ω(F)
(1)
式中:
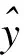
Ω(F)——正则化项,用以约束F的复杂性,控制模型的复杂度。
XGBoost算法采用同Boosting算法家族一致的残差修正思想。针对每个样本,将现有估计与真实标签间的残差作为即将加入的新弱学习器的训练标签,由此可得到加入第t棵树后的估计结果为:
(2)
式中:
xi——模型输入的第i条样本数据;
fi(xi)、ft(xi)——分别为第i棵树和第t棵树的分类结果;
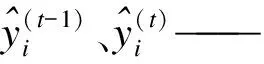
将损失函数和正则化项代入式(1)目标函数中,可得第t次迭代时的目标函数为:
(3)
式中:
n——样本数量;
yi——第i条样本数据对应的真实标签;
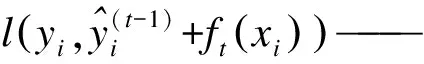
Ω(ft)——正则化项,用以约束第t棵树ft的复杂性,控制模型的复杂度。
对目标函数中的损失函数项进行二阶泰勒展开,并代入单个弱学习器的函数式与模型复杂度的函数式表达,能够得到展开的目标函数如下:
(4)
式中:
T——叶子节点的个数;
wj——叶子节点权重;
K——构建树的总棵数;
γ、λ——均为调整参数,用以防止过拟合;
Gj——损失函数一阶偏导的累加值之和;
Hj——损失函数二阶偏导的累加值之和。
基于式(4)可计算每个叶子节点的最优权重和模型最小损失,从而在迭代过程中使用贪婪算法逐步训练K棵树,以组成具备强估计能力的集成模型。
2.4 状态仿真
地铁列车在运行过程中会依据地图信息和当前运行数据不断切换其行车状态,并输出相应的制动级位或牵引级位。在使用物理模型仿真时,常常会依据列车出厂时提供的加速度表和级位传输延时信息来预测计算当前时刻列车的加速度。具体的计算流程为:首先将列车系统输出的级位依次存到级位盒中,然后依据列车延时表获得当前作用在列车上的级位,接着根据加速度表和当前的列车速度找到对应的理论加速度,最后依据式(5)更新下1个周期的列车速度,并依据式(6)更新该周期内列车行驶距离。
vt+1=vt+atT0
(5)
(6)
式中:
vt——t时刻的列车速度;
T0——列车运行的1个周期时长;
st——t到t+1时刻内列车的运行距离。
由于列车型号的不一致使得在模拟仿真过程中需要不断地更换参数,所以难以用一套固定的模型参数实现准确的模拟仿真。此外,由于环境因素的干扰,使得列车在实际行驶过程出现与出厂参数不符的偏差。
综上,本文采用上述基于XGBoost算法构建的列车速度估计模型,替换传统物理模型的加速度计算模块。仿真时先对列车的线路信息及状态进行初始化,并进行与训练数据一致的特征工程处理;然后将采样点输入至XGBoost模型中,获得当前时刻的列车加速度,同理依据式(5)~(6)更新列车的速度和行驶距离;接着利用地图信息、ATC系统输出更新的坡度信息和级位序列。上述步骤依次迭代进行,直到列车到站停车。最后,将列车在线路上的运行仿真数据进行记录,并分析其仿真效果。
3 基于XGBoost算法的列车运行状态仿真试验
3.1 试验目的
为验证基于XGBoost算法的列车运行状态仿真方法的有效性,本文对3列来自某地铁线路的真实列车数据进行学习及仿真测试,并与基于性能参数表的物理模型仿真方法进行比较。数据特征参数的具体说明如表1所示。
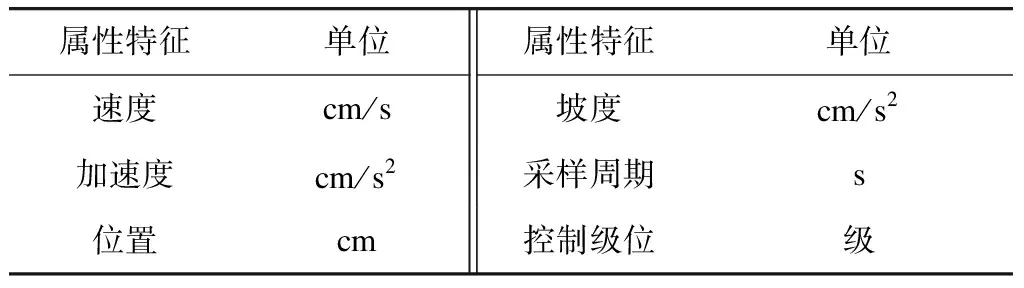
表1 模型中采用的列车特征参数及其单位
3.2 评价方法
采用每个采样周期内加速度的均方根误差R和每站速度曲线误差百分比E两个指标,其计算式如式(7)、式(8)所示。R和E的值越小,表示模型的准确性越高,与实际列车运行情况的符合程度越高,即仿真效果越好。
(7)
(8)
式中:
N——数据集中的数据总条数;
ai——列车的实际加速度;

m——线路上的数据采样数;
vj——j时刻列车的实际速度;

3.3 试验过程
首先对原始数据进行清洗,对加速度异常、缺失的数据点进行删减处理,然后依据算法原理中的特征工程方法逐条完成特征空间的建立。接着预留1个车站的数据(该站不参与模型训练)并用作单站列车运行速度曲线仿真,以验证模型的实用性。将其余站点的采样数据按照7∶2∶1的比例分别拆分至训练集、验证集和测试集内。
在进行列车运行状态仿真模型训练时,首先将训练集输入至XGBoost模型中,并用验证集进行超参数调整,最后使用测试集对仿真模型的性能进行分析评价。此外,将基于XGBoost模型的仿真结果与基于列车性能参数表物理模型得到的仿真结果进行对比。
基于验证集的表现,确定试验中采用的XGBoost模型超参数如下:最大树深度为8,学习率为0.6,基分类器数量为500。在实用性检测时,将基于XGBoost算法的仿真模型应用到没参加模型训练的预留站上并进行模拟仿真,将预留站列车的实际运行速度、基于XGBoost模型得到的仿真速度、基于物理模型得到的仿真速度进行对比。
3.4 试验结果分析
参与试验的3列车的编号为T1、T2、T3,数据量分别为460 511条、795 88条、472 68条。将基于物理模型得到的仿真结果与基于XGBoost模型得到的结果进行对比,如表2所示。从表2中可以看出,与基于物理模型得到的结果相比,基于XGBoost模型的列车运行状态仿真模型的R和E在多列车上的测试结果均较低,且在不同列车上的仿真性能表现更为稳定,这说明了基于XGBoost模型的仿真方法具有良好的环境适应性,能与不同的列车车型相匹配。

表2 基于物理模型和基于XGBoost模型的仿真结果对比
将预留站列车的实际运行速度、基于XGBoost模型得到的仿真速度、基于物理模型得到的仿真速度进行对比,得到的结果如图2所示。从图2可以看出,基于物理模型得到的仿真速度在模拟控制级位变换较为频繁,且在复杂的目标速度调整(采样周期为(200~400)×0.2 s)及巡航速度控制(采样周期为(400~1 300)×0.2 s)阶段均难以实现准确的速度估计,从而影响了整个车站的仿真效果。而基于XGBoost模型得到的仿真速度曲线则与列车的实际运行曲线更为贴合。
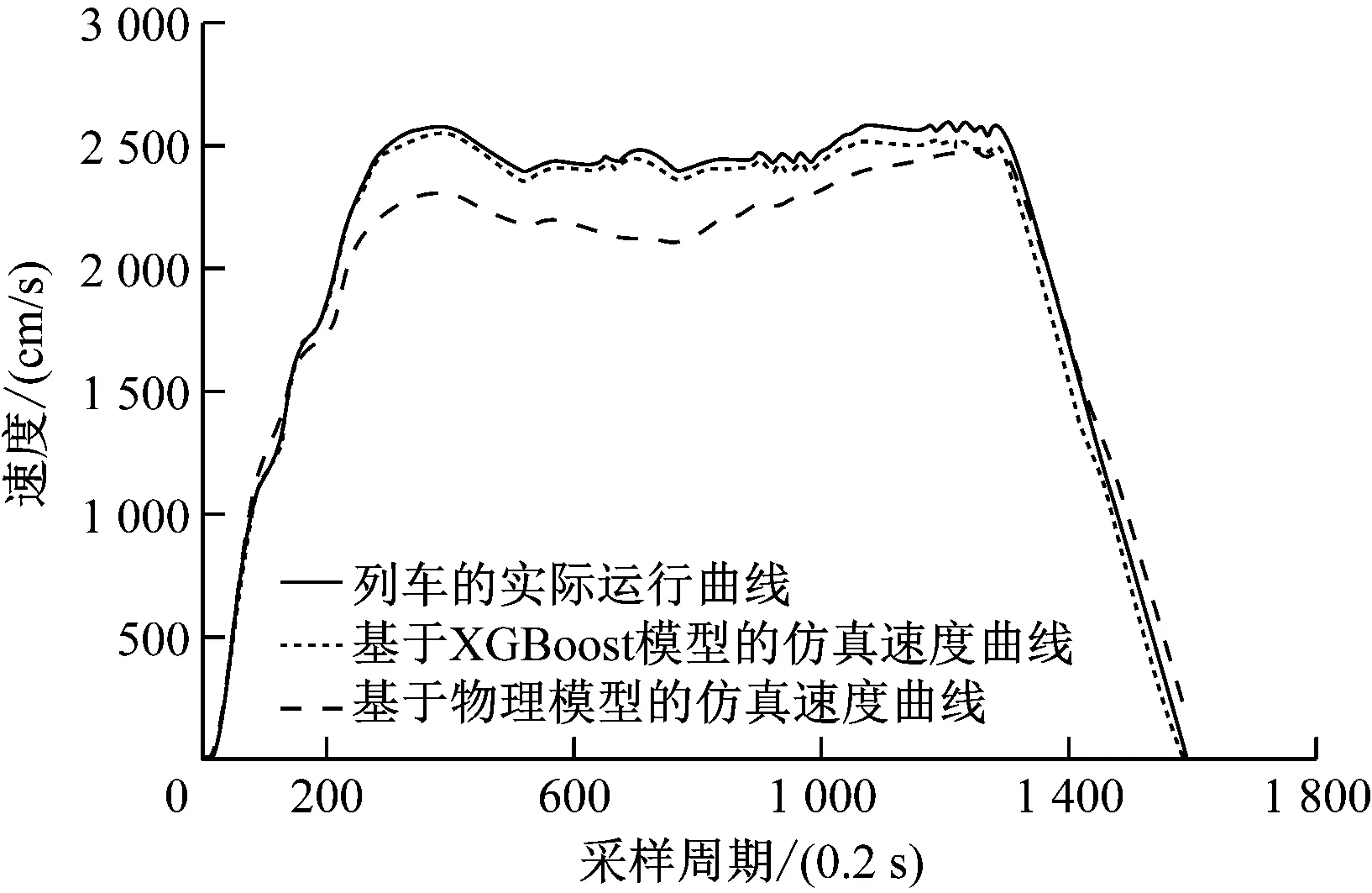
图2 3种不同测试工况下列车在单站运行时的 速度曲线仿真对比
综上可知,本文提出的基于XGBoost的列车运行速度仿真模型构建方法可从实际运行数据中有效挖掘列车运动模型、控制延时特性、级位作用表现等特征并加以利用,进而建立列车运行状态的仿真模型。该模型具有良好的环境适应性,能与不同的列车车型相匹配,可生成与实际情况接近的列车运行速度曲线,较为准确地实现对地铁列车运行状态的仿真。
4 结语
列车运行状态仿真是研发与优化ATC的重要工具,具备自动化适应能力与高精度仿真性能的状态仿真模型将助力轨道交通自动化技术的不断发展。本文提出的基于XGBoost模型的仿真方法可从实际运行数据中有效挖掘列车运动模型、控制延时特性、级位作用表现等特征,实现对ATC系统输出与实际作用效果间复杂函数关系的学习,进而建立具备一定适应性且模拟精度较高的列车运行状态仿真模型。试验采用真实数据验证了使用该方法所建立的仿真模型的有效性,且该方法适用于针对不同列车车型的运行状态仿真场景。未来应进一步结合其他先进的序列数据建模方法,不断改进、优化该模型的训练效果,为列车自动运行技术的发展提供更可靠、有效的技术支撑。
