基于注意力和标签自适应的跨域行人重识别①
2022-04-08陈思文吴怀宇
陈思文 吴怀宇 陈 洋
(武汉科技大学机器人与智能系统研究院 武汉430081)
0 引言
近年来,随着社会公共安全的需要,监控摄像头大量普及,随之而来的是庞大的视频监控数据,通过人工观察不同监控视频来查找指定行人需要耗费大量的人力物力,因此,基于跨摄像头的行人身份重识别成为视频分析工作中一个重要的研究课题。目前,大量的行人重识别方法[1-4]都是基于深度学习模型来实现的,旨在通过在目标场景下大量的带标签数据进行有监督训练,获得在目标场景下行人外观特征的最佳视觉表示,从而实现对行人身份的有效识别。
然而,当模型在没有训练过的目标场景中应用时,其性能会出现大幅度下跌,这是因为不同场景下的拍摄视角、相机参数、光照环境以及图片质量等因素的不同,导致行人数据分布在域间存在巨大差异。例如,公开数据集Market-1501[5]采集的行人图像分辨率较高、光照条件好、色彩鲜明,而DukeMTMCreID[6]采集的行人图像分辨率较低、色彩相对较暗、背景复杂,这种显著的图像差异导致了同一模型在两个不同数据集上性能的巨大落差。
为增强行人重识别模型在跨域任务中的性能,文献[7]提出了源域相机到目标域相机的图像转换方法。该方法不直接在源域和目标域之间进行图像样式转换,而是将每一个相机看成是一个独立的子域,利用StarGAN[8]的多域图像到图像的转换方法,生成带有源域身份关联的目标相机域样式的图像,通过在生成的带有身份关联的图像上学习目标域行人身份特征表示。但这种方法生成的图像并不能完全替代真实的图像,可能导致生成的图像细节不利于行人重识别任务。文献[9]通过KMeans 对目标数据集进行样本聚类,然后选择离聚类中心较近的样本来训练模型,但是该方法需要目标数据集的类别数量。文献[10]使用了最大均值差异(maximum mean discrepancy,MMD)来寻找域不变特征空间表示,以此提高模型在目标域上的性能。文献[11]结合源域的有标签数据和目标域的无标签数据,提出了基于生成对抗网络架构的无监督域自适应方法,该方法通过无监督的方式学习从一个域到另一个域的映射关系。但是,这些方法仅考虑了源域和目标域之间的差异,而没有考虑源域与目标域之间的相关性。
为充分挖掘源域数据集与目标域数据集之间的相关性,进一步提高模型在跨域问题上的性能,本文提出了融合标签自适应和注意力机制的跨域行人重识别方法。通过引入注意力机制和BNNeck 模块改进模型,以提取行人更深层次的域不变语义特征,从而提高模型在不同数据集上的相关性表达能力。同时提出了无监督标签自适应方法(unsupervised label adaptation,ULA),利用不同数据集之间的相关性,挖掘出目标域数据集上的可用数据对模型进行微调,从而进一步提高模型在跨域行人重识别任务上的性能。
1 方法设计
1.1 系统框架
提出的融合注意力机制和标签自适应的跨域行人重识别系统架构如图1 所示,主要分为3 个部分,即基于注意力机制的行人重识别模型、无监督标签自适应以及基于知识蒸馏(knowledge distillation,KD)的参数更新。在训练期间,完全标注的源域数据集{Xs,L(Xs)}被用来预训练基于注意力机制的行人重识别模型,提出的无监督标签自适应方法在没有任何标注的目标域数据集Xt上通过选择可信度高的样本来微调中间模型,接着通过知识蒸馏的方法将中间模型参数加权并更新到原模型中,使原模型在获得新知识的同时,不至于出现对旧知识的灾难性遗忘。随着更多的样本不断加入到模型的训练中,模型在目标数据集中的性能将逐步得到提升。其中,Xs和Xt分别表示源域和目标域的图像,L(Xs)表示源域图像的身份,源域数据集中任意行人xs,i与其身份标签ls,i相对应。

图1 基于注意力和无监督标签自适应的跨域行人重识别系统框架
具体来说,首先,在行人重识别模型的不同深度特征层中嵌入注意力机制和BNNeck 模块,注意力机制可以提高模型在不同尺度特征图上对通道和空间的感知能力,从而学到更深层次的域不变语义特征,增强模型在不同数据集上的特征表示能力;而BNNeck 模块通过在三元组损失和标签分类损失之间加入批归一化层,可以有效抑制标签分类损失对三元组损失的影响,使最终得到的特征分布更能满足相同身份相互靠近、不同身份互相远离的特性。其次,由于源域与目标域数据集之间的相关性,模型在目标域数据集上有一定的特征表示能力,因此提出标签自适应方法,通过在目标数据集上提取行人特征,构建行人特征库,再选择出行人特征库中分布稠密且形状任意的样本簇,并为其分配伪标签,从而可以获得目标数据集中一部分可信度高的样本数据。接着,通过中心损失,在选择的样本数据上学习相同行人在不同摄像头下的共性特征作为身份区分特征模板,对行人与身份区分特征模板的相似度比对,将标签信息自适应扩展至满足阈值的行人上,形成新的数据集。最后,通过知识蒸馏的方法,在保留旧知识不会出现灾难性遗忘的同时,学习新数据集上的知识,逐步改善模型在目标数据集上的性能。随着模型性能的改善,更多的样本数据将通过标签自适应方法添加到模型的训练中,从而进一步提高模型在目标数据集中的性能。
1.2 基于注意力机制的行人重识别网络
现有研究已经表明单域行人重识别模型在跨域问题上表现较差,受文献[4]启发,本文通过引入融合通道注意力和空间注意力机制的注意力模块和BNNeck[12]模块对常用的基线模型(Resnet50[13])进行改进,以提高模型在跨数据集任务上的初始性能,从而进一步挖掘源域和目标域数据集之间的相关性。如图2 所示,常用的Resnet50 网络主要由5 个模块组成,分别是其中,Conv1 模块的卷积核大小为7 ×7,卷积步长为2,以使用较大的感受野对原图像进行下采样,得到长宽均为原始图像1/2的特征图,然后再经过最大池化层进一步对图像进行下采样处理模块则通过残差网络结构提取图像的深度特征,避免了随着网络层数的加深会出现梯度消失的问题。
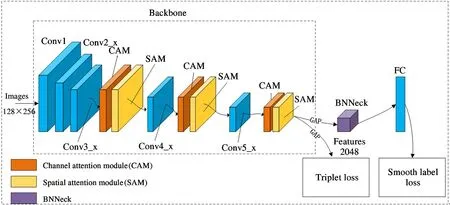
图2 基于注意力机制的行人重识别网络结构图
1.3 无监督标签自适应
针对目标域上没有任何标签的数据,受文献[9,14]在无标签数据集中使用聚类算法选择样本微调模型成功案例的启发,提出无监督标签自适应方法,充分利用源域数据集和目标域数据集之间的相关性,使用在源域数据集上预训练的模型提取目标域数据集的行人特征,将分布稠密的样本簇的共性特征作为身份区分模板,通过计算与共性特征的相似度,将标签信息扩展至目标数据集中,从而选择出目标域数据集上最可信的样本来微调模型,以提高模型在目标域数据集上的性能,如图3 所示。

图3 无监督标签自适应方法示意图
具体来说,首先使用欧式距离来描述目标域数据集行人特征之间的分布关系为dist(x(i),x(j)),再通过基于密度的聚类方法,对于每一个目标域数据集上的样本xj∈Xt,计算其ε-邻域中包含的所有距离dist(x(i),x(j))不大于ε的样本,如式(1)所示,从而选择出目标域数据集中分布稠密的样本形成样本簇。一般而言,分布稠密的样本属于同一身份的可能性较大。

其中,Nε(x(j))表示特征x(j)周围小于ε距离的所有样本,x(i)和x(j)分别表示目标数据集中第i个样本和第j个样本,dist(x(i),x(j))表示目标数据集中第i个样本和第j个样本之间的欧氏距离,ε表示2 个样本之间的密度阈值,这里ε取值1.0。
其次将每一个样本簇视为独立类别的行人样本,选择一定数量的样本簇作为基础类别,并为其分配伪标签,样本簇中的每一个样本共享相同的伪标签,从而形成在目标域上带伪标签的数据集。为了能够在算法执行过程中不断将标签自适应扩展至新的数据上,通过中心损失[14],如式(2)所示,最小化样本簇中行人到其共性特征的距离,以此学习目标域数据集下每一类样本簇的共性特征Ct来作为身份区分特征模板。

其中,LCommon表示每一类样本簇到其共性特征的距离,B表示样本簇和共性特征的数量,fj,t表示目标数据集样本簇上的第j类样本特征,cj,t表示目标数据集上第j类样本的共性特征。
最后,对于每一个新的来自目标域数据集的行人xi,t∈Xt,通过相似度距离度量,如式(3)所示,计算xi,t与每一个身份区分特征模板Ct的相似度θ(xi,t,cj),将相似度θ(xi,t,cj)大于设定阈值的样本视为可信样本,为其分配与模板相同的伪标签并加入到模型的训练中。
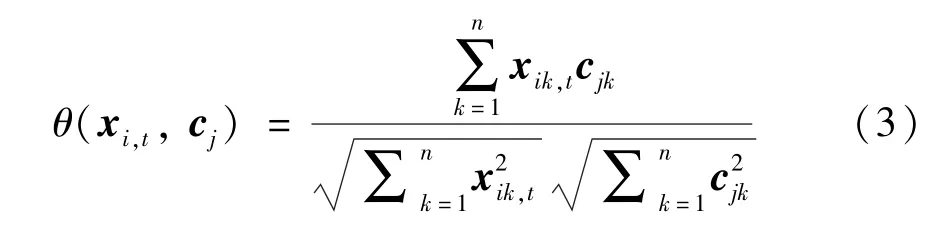
其中,θ(xi,t,cj)表示目标数据集上的行人xi,t与第j个身份区分特征模板cj的相似度。如果相似度θ(xi,t,cj)大于0.8,则判定该行人与模板身份一致,为该行人分配伪标签并添加至数据集中用来微调模型。xik,t和cjk分别表示目标数据集上的行人xi,t与身份区分特征模板cj在k-维度上的特征值,n表示特征维度。
1.4 基于知识蒸馏的参数更新
由于标签自适应方法依赖于模型在目标数据集下的初始性能,为了保证在目标数据集上样本选择的准确性和一致性,在适应到新场景的过程中不仅要学习新的知识,也要保留之前获得的知识。基于这样的考虑,借鉴一种新的知识蒸馏方法[15],通过采用这种基于知识蒸馏的策略,使模型不仅能够适应到目标域数据集下,同时也能保留在源域数据集上的性能。
如图1 所示,通过一个在带伪标签的目标数据集上微调的中间模型和在源域数据集中的预训练模型,将微调好的中间模型参数通过式(4)来逐步完成原模型权重参数的更新。

其中,Wtarget表示原模型的权重参数,Wintermediate表示中间模型的权重参数,μ表示蒸馏因子。通过改变μ值来平衡旧知识的遗忘和新知识的学习速率。
1.5 损失函数
为提高模型在目标数据集上的性能,通过联合平滑标签损失(smooth label loss)[16]和三元组损失(triplet loss)[17]来优化模型。对于平滑标签损失,根据模型的预测得分和图像标签,使用式(5)计算平滑标签损失。

其中,y表示真实标签,i表示第i个类别,pi表示标签预测得分,N表示训练集中的总类别数,ε是一个常数,用来鼓励模型不去相信标签是正确的,在这里ε值为0.1。对于三元组损失,选择每个批次内相同身份最远的距离dp和不同身份之间最近的距离dn的样本形成三元组损失,并通过式(6)计算三元组损失:
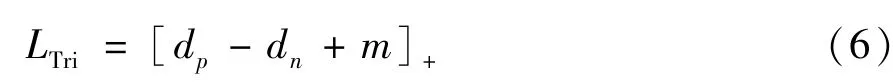
其中,m表示距离裕度,运算符[z]+表示取z和0的集合中的最大值,在这里m取值为0.3。最后,总损失可以用式(7)表示。

其中,β取值为0.0035,表示共性特征在学习过程中所占的比重。
2 实验数据与结果分析
2.1 数据集介绍
为了验证方法的有效性,在2 个大型的公开行人数据集Market-1501 和DukeMTMC-reID 上评估了本文提出的方法。
Market-1501 数据集包含来自6 个摄像机的1501 个身份的32 668 张图像。其中,751 个身份的12 936 幅图像用于训练,750 个身份的19 732 幅图像用于测试。
DukeMTMC-reID 数据集是从8 个摄像机收集的大规模re-ID 数据集。其中,702 个身份的16 522幅图像用于训练,另外702 个身份的图像用于测试。
2.2 性能评估指标
在行人重识别任务中,常用的性能评估指标有首位命中率(Rank-1)和平均精度均值(mAP)。其中,Rank-1 为首次预测正确的概率,mAP的定义如式(8)所示。

其中,Q表示查询集的数量,AP由式(9)定义。

其中,k表示预测图像的排名,如果预测排名为k的图片与查询图片是同一ID,则rel(k)为1,否则rel(k)为0,而p(k)被定义为
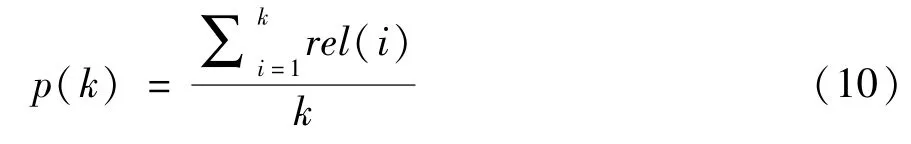
2.3 实施细节
实验环境如下:Windows 10的操作系统,深度学习框架为Pytorch1.6.0,编程语言版本为Python。
对于行人重识别模型,本实验使用Resnet 50 作为主干网络(Baseline),在x输出上分别添加了通道注意力模块和空间注意力模块,并在最后的全局池化层和全连接层之间添加了BNNeck 模块,输入图像的大小调整为128×256 像素,输出维度为2048的特征向量。对于模型的预训练,本实验使用了随机擦除[18]、色彩抖动、随机裁剪以及用于训练的随机水平镜像等数据增强方法。采用Adam 优化器,批处理大小设置为64,学习率从3.5 ×10-5开始,每50 个epoch 衰减为原来的0.1 倍,训练120 个周期。针对模型的微调,设置密度聚类阈值ε为1.0,相似度阈值为0.8,每5 个epoch 使用知识蒸馏方法对原模型进行一次参数更新,并对无标签的目标数据集使用无监督标签自适应方法(ULA)以获得新的训练数据,微调学习率为1 ×10-7,训练80 个周期。
2.4 实验结果
2.4.1 无监督标签自适应性能分析
实验分别以Market-1501 和DukeMTMC-reID 作为无标注的测试数据集,验证无监督标签自适应(ULA)在不同设定类别数量下对模型在跨域任务上性能的影响,对比结果如表1 所示。首先将Resnet50 作为基础网络(Baseline),并在此基础上添加了注意力机制模块和BNNeck 模块得到基于注意力机制的行人重识别模型(CSAM-ReID)。从表中可以看出,与基础网络(Baseline)相比,CSAM-ReID 在Market-1501 数据集上mAP提升了5.6%,Rank-1 提升了4.6%;在DukeMTMC-reID 数据集上mAP提升了8.4%,Rank-1 提升了11.1%。其次在CSAM-ReID基础上,使用ULA 在无标签的目标数据集中选择高质量样本以微调模型,表1 中展示了不同预设类别数量ULA 方法的实验结果。当预设类别数量为750时,在Market1501 数据集上mAP达到了32.0%,Rank-1 达到了48.2%;在DukeMTMC-reID 数据集上mAP达到了35.1%,Rank-1 达到了54.7%。实验结果表明,改进的CSAM-ReID 模型可以有效提升模型在目标域数据集上的初始性能,而标签自适应方法通过选择无标签的目标数据集上可信度高的样本微调模型,大大改善了行人重识别模型在目标数据集上的行人外观特征表示性能。
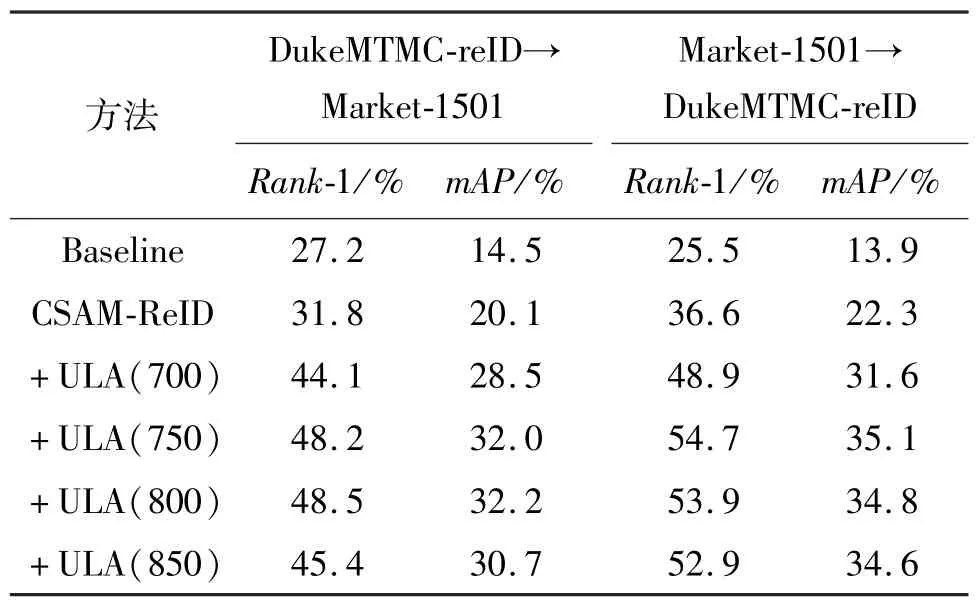
表1 不同预设类别数量的ULA 方法对模型在目标数据集上性能的影响
2.4.2 知识蒸馏性能分析
为验证基于知识蒸馏的参数更新方法在平衡旧知识的遗忘和新知识的学习任务中的有效性,在CSAM-ReID 模型和ULA的基础上分别使用不同的知识蒸馏因子,实验结果如表2 所示。可以看出,当知识蒸馏因子μ为0.5 时,相比于CSAM-ReID +ULA(750),在Market-1501 数据集上mAP提高1.1%,Rank-1 提高了0.4%;在DukeMTMC-reID 上mAP提高了1.0%,Rank-1 提高了1.8%。实验结果表明,添加知识蒸馏的参数更新策略有助于模型对旧知识的保留,保证了在目标数据集上样本选择的准确性和一致性,从而提高了模型在目标数据集上的性能。
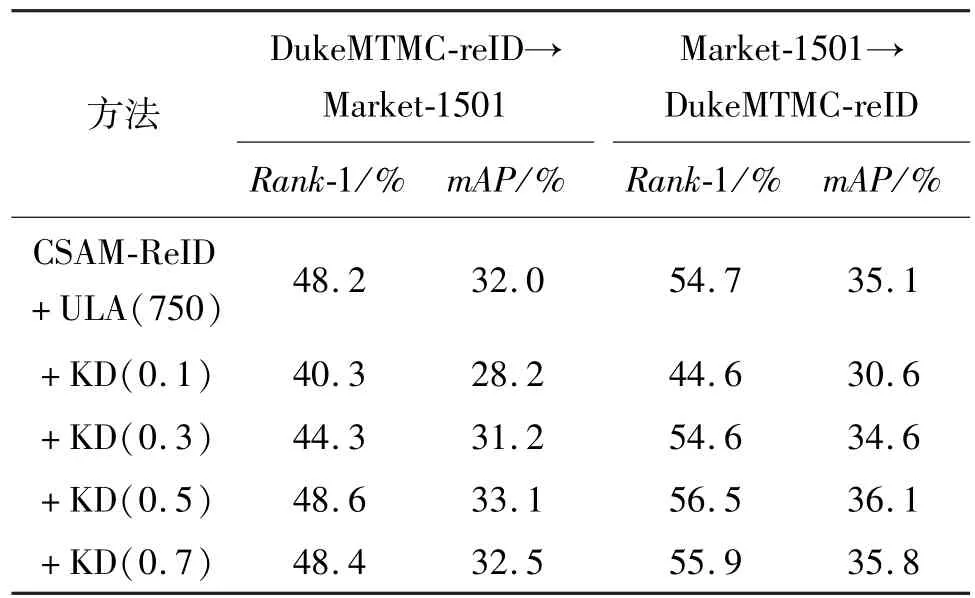
表2 不同知识蒸馏因子对模型在目标数据集上性能的影响
2.4.3 所提方法与前沿算法的实验数据对比
如表3 所示,所提算法与Market-1501 和Duke-MTMC-reID 数据集上的6 种最新的跨域行人重识别方法进行比较,分别是基于聚类的方法PUL[9],基于属性共同训练的方法TJ-AIDL[19]、基于图像转换的方法IPGAN[7]、PTGAN[20]、SPGAN[21]以及基于域鉴别网络和域自适应的DDNDA[22]。从实验结果可以看出,所提方法在Market-1501 数据集上Rank-1为48.6%,mAP为33.1%,在DukeMTMC-reID 上的Rank-1 为56.5%,mAP为36.1%,相比于基于图像转换方法IPGAN,在Market-1501 和DukeMTMCreID 数据集上,其mAP分别提高了6.1%和8.1%。

表3 所提方法与其他先进算法的性能对比
2.5 训练过程可视化
为了分析训练过程中标签自适应方法选择的样本和目标数据集上行人特征分布的变化,在训练期间随机选择DukeMTMC-reID 数据集上6 个带伪标签的行人和8 位不同身份的行人分别对其样本选择过程和特征分布变化过程进行可视化,特征分布和样本选择结果分别如图4 和图5 所示。从图4 中可以观察到,随着训练数的增加,在特征空间中相同身份的行人相互靠近,不同身份的行人彼此远离,从而提高模型对不同身份的行人辨别能力。同时,每一次对模型进行参数更新并使用标签自适应方法后都有大量的新样本加入到训练数据中。从图5 中可以看出,由于直接将模型应用在目标域数据集上其性能会较差,因此刚开始选择的样本都是在同一摄像头下姿态相似的行人,随着模型在目标域数据集下性能的改善,越来越多的样本通过标签自适应被关联了伪标签,加入到模型的进一步微调中。
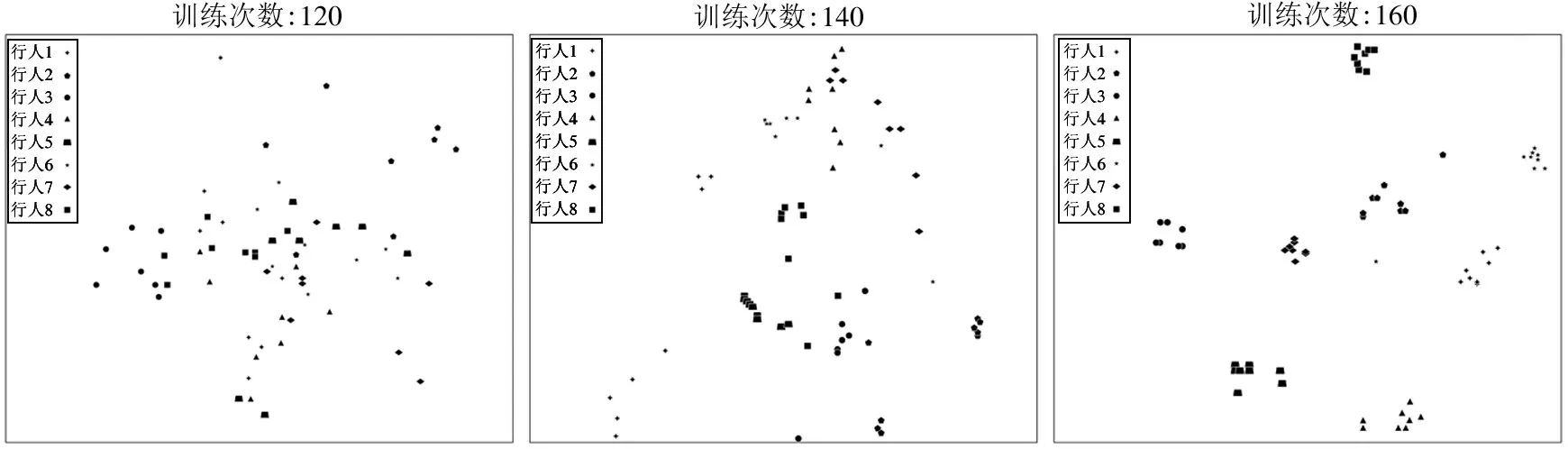
图4 在训练过程中样本在特征空间中的分布变化图

图5 在训练过程中通过标签自适应选择样本的过程
图6(a)和(b)分别展示了模型在DukeMTMCreID 数据集上不同阶段的损失函数和性能指标的曲线变化。从图6(a)可以看到,每5 个epoch 损失函数都会陡然升高。这是因为通过标签自适应加入了新的样本,随着模型的不断训练,损失函数逐渐接近最小值,达到平稳状态,此时模型的性能是最优的。从图6(b)可以看到,模型在epoch 为160 时性能指标达到最高,随着模型的继续迭代,模型的性能开始显示下降的趋势。这是因为在连续迭代的过程中,先前选择的错误样本逐渐累积,模型接收了大量错误的样本训练而导致的。

图6 在DukeMTMC-reID 数据集上训练的损失函数和性能指标变化曲线图
3 结论
本文提出了一种基于注意力机制和标签自适应的跨域行人重识别方法。通过在不同深度特征层嵌入注意力机制和BNNeck 模块可有效提高行人重识别模型在跨域任务中的初始性能,进而提高行人重识别模型对源域数据集和没有任何标签的目标域数据集之间相关性的表达能力。无监督标签自适应方法可以充分挖掘没有任何标签的目标域数据集上的可用数据,并将标签信息扩展至新的数据上。基于知识蒸馏的方法可以使模型在学习新的知识的同时保留旧知识,保证样本选择的一致性和准确性,从而提高模型的稳定性。实验结果表明,所提方法能有效提高行人重识别模型在跨域任务中的性能。
