基于拉曼光谱荧光背景的痕量原油泄漏检测方法
2022-04-08童宗歌陈夕松胡云云
童宗歌,陈夕松,王 鹏,胡云云
(1.东南大学自动化学院,南京 210096;2.南京富岛信息工程有限公司)
炼化企业常采用原油与常压蒸馏塔侧线的轻质油进行换热,经常存在原油换热器内漏问题,特别是近年来我国加工的高硫高酸等原油日益增多[1],因腐蚀换热管道导致原油污染侧线轻质油的现象更加严重。一般来说,不同轻质油侧线产品根据其性质以及用途的不同,对于泄漏原油含量的容忍度也不一样,例如相较于常二线馏分,石脑油对原油含量要求更低,原油质量分数甚至达10 μg/g以下。
轻质油中原油检测限越低,检测速度越快,意味着可以越早地发现换热装置损坏并及时维护,促进炼化企业安全生产。现有的原油泄漏监测技术主要包括人工化验法和光谱学分析法。人工化验法虽然精确,但速度慢,不能及时发现泄漏并维护。常用的光谱学检测方法有近红外光谱法和拉曼光谱法,近红外光谱对于痕量原油的检测限为mg/g级,而此时油品杂质已经可以通过色泽明显分辨。拉曼光谱基于拉曼散射效应,通过记录拉曼散射光频移可以得到和近红外光谱类似的结构信息[2]。拉曼散射效应往往伴随着荧光效应,拉曼光谱同时记录着拉曼信号和荧光信号,而荧光信号的强度远超拉曼信号。在拉曼光谱检测过程中,荧光信号往往被视为背景噪声,需要使用物理方法、化学方法以及计算机算法消除拉曼谱图中的荧光信号[3]。因此,本研究利用原油中重组分荧光效应显著的特点[4],实现拉曼信号分析轻质油组分的同时利用荧光信号进行痕量级别原油泄漏检测。
荧光信号强度和痕量原油含量高度相关,使用偏最小二乘法建立相应的预测模型。建模使用的数据通常为经过预处理的原始光谱数据,光谱数据的波数点通常为数千个,高维数据会影响模型的运算复杂度和收敛速率。此外,全波段光谱除了荧光信息也包含大量的噪声,而荧光信息在波长上的分布并不均匀,由此导致偏最小二乘法的预测值偏移。炼化企业对于不同的侧线产物中混入痕量原油的容忍度不同,对于换热器维护的警报限也是因厂而异,因此,模型应当满足对不同区间痕量原油的监测并最大程度提升模型的预测精度。本研究在偏最小二乘法的基础上使用3种特征提取优化算法,即遗传算法、随机蛙跳算法和竞争自适应重加权采样算法,对拉曼光谱的谱段信息进行提取,优化模型的预测性能,以满足炼化企业对痕量原油检测指标的要求。
1 实验与数据采集
1.1 仪 器
本试验使用上海如海光电科技有限公司生产的拉曼光谱仪,型号为SEED3000PLUS。该仪器包括光谱分析仪本体、785 nm拉曼探头及光纤(RPB-785-1.5T-FS)、785 nm激光发射器以及拉曼信号增强支架(SH-L-EN)。
1.2 试验方案
采用中国石化某企业3种常压蒸馏塔塔顶石脑油与9种性质不同的原油进行调合,原油质量分数为100 μg/g,所得混合油样品的拉曼光谱趋势相近,谱峰位置相同,区别在于不同原油的拉曼谱峰强度不同。因此,针对痕量原油检测,采用一种石脑油调配一种原油可以反映不同石脑油和不同原油组合的扫谱结果。
根据上述试验结果选择一组具有代表性的石脑油和原油进行调合。由于不同炼化企业以及不同侧线产物对于痕量原油的检测要求不同,为了覆盖不同的检测范围以及最大程度验证拉曼光谱的检测性能,配制原油质量分数分别为1,2,3,4,5,10,20,30,40,50,60,70,80,90,100 μg/g的原油与石脑油混合油样品,其中每个原油含量配6组样品,共计90个混合油样品。使用拉曼光谱仪扫描90个样品波数范围为50~3 260 cm-1的拉曼光谱,试验条件为:室温,功率350 W,积分时间90 ms,平均采样次数10次。将90个混合油样品的拉曼光谱采用Savitzky-Golay 3次11点卷积平滑算法进行平滑处理,处理后的光谱如图1所示。

图1 混合油样品经过平滑处理的拉曼光谱
1.3 数据集划分与处理
在光谱分析过程中,将数据集划分为校正集和测试集,校正集用于建立标准预测模型,测试集用于检测模型的泛化能力。数据集的划分对模型性能具有决定性影响,因此划分中应尽量保证数据选取的随机性和代表性。
本试验数据是人工调合油品的离散拉曼光谱数据,由于调合油品按照15个固定原油含量配制,而拉曼光谱强度与痕量原油含量呈正相关关系,所得光谱数据具有相对固定的分布。因此在进行数据集划分时,为保证测试集分布均匀,按照以下方式采集测试集:①将数据集按照15个痕量原油含量分组,每组具有6个相同痕量原油含量的拉曼光谱数据;②在每组数据中随机抽取1个数据加入测试集,测试集由15个代表不同痕量原油含量的光谱数据组成。
对数据集进行主成分(PCA)降维,得到第一主成分的贡献率为93.25%,第二主成分的贡献率为1.12%,足以代表数据集的关键信息。PCA降维下校正集与测试集二维分布见图2。由图2可知,测试集数据分布均匀。

图2 PCA降维下校正集与测试集二维分布●—校正集; —测试集
2 结果与讨论
2.1 偏最小二乘法建模
偏最小二乘法是主成分回归、典型相关分析与多元线性回归的有机结合。该方法使用已知训练集的油品光谱阵和性质阵计算出光谱采样波数点与油品性质的线性关系,进而对待测油品性质进行预测。偏最小二乘法吸取了主成分回归降维提取关键信息的优点,同时加强了光谱阵和性质阵之间的联系,从而保证获得最佳的校正模型[5]。
使用偏最小二乘法对全波数段建模,根据其建模标准,75个数据建模时主成分个数不得超过12个。因此,主成分数取1~12之间的整数,交叉验证采用5折交叉验证法,计算使用不同主元数的交叉验证均方根误差(RMSECV),最终选择5个主成分。
2.2 基于遗传算法的谱段优化结果
遗传算法是一种随机全局搜索优化方法,它模拟了自然选择和遗传中发生的复制、交叉和变异等现象。从初始种群出发,通过随机选择、交叉和变异操作,产生一群更适合环境的个体,使群体进化到搜索空间中越来越好的区域,通过不断繁衍进化,最后收敛到一群最适应环境的个体,从而求得问题的优化解[6]。根据遗传算法的机理,染色体的基因过多不利于模型收敛,因此将光谱中波数50~3 260 cm-1的波段划分成8个波数点一组的小区间,共计256个区间。初始种群个体数设置为200个,迭代次数设置为200次,染色体交叉概率为0.8,考虑到收敛速率和模型精度,将染色体基因变异概率设置为0.5,每个染色体可能变异的基因个数为50个。作为算子的偏最小二乘法回归模型的主成分数为5,验证方法为 5折交叉验证法。基于遗传算法对谱段进行优化,统计每次迭代最优个体基因,并根据每组基因出现的次数进行降序排列;对特征变量从前到后进行区间合并,并统计不同数量的波数段建模的RMSECV,结果如图3所示。由图3可知,该模型在前63个区间合并的光谱谱段建模的RMSECV最小,因此将该谱段光谱作为最优谱段,共有504个波数点。

图3 基于遗传算法的谱段优化结果
2.3 基于随机蛙跳算法的谱段优化结果
随机蛙跳算法结合了随机搜索和适者生存的思想,根据预设的随机策略更新搜索子集,并统计每次迭代搜索到的最优子集选择的谱段,最后根据谱段出现的概率确定最终选取的谱段范围[7]。将拉曼光谱中的每个波数点均作为特征变量,由于样本个体的特征变量有2 048个,搜索空间很大,因此需要很高的迭代次数以保证该方法能够收敛预测性能良好的谱段,综合考虑预测精度和计算成本,并经过试验求证,最终将迭代次数设置为10 000次,初始训练集的变量数设置为10。基于随机蛙跳算法对谱段进行优化,得到迭代10 000次各特征变量出现的频率,根据频率对特征变量进行降序排列;对特征变量从前到后进行区间合并,并统计不同数量的特征变量对模型预测能力的影响,结果见图4。其中,作为算子的偏最小二乘法回归模型的主成分数为5,验证方法为 5折交叉验证法。由图4可知,该模型的RMSECV随着合并区间的扩张先变小后增大。即随着合并区间的扩张,模型的预测性能提高;但当扩张到第93个波数点之后,继续扩张给模型引入了噪声,模型的预测性能下降。因此,选择排序后的前93个波数点作为最优谱段。最优谱段波数点分布如图5所示。由图5可知,所选波数点集中在拉曼波峰附近。

图4 基于随机蛙跳算法的谱段优化结果

图5 基于随机蛙跳算法的最优谱段波数点分布 —拉曼光谱; ■—被选择的波数点
2.4 基于竞争自适应重加权采样算法的谱段优化结果
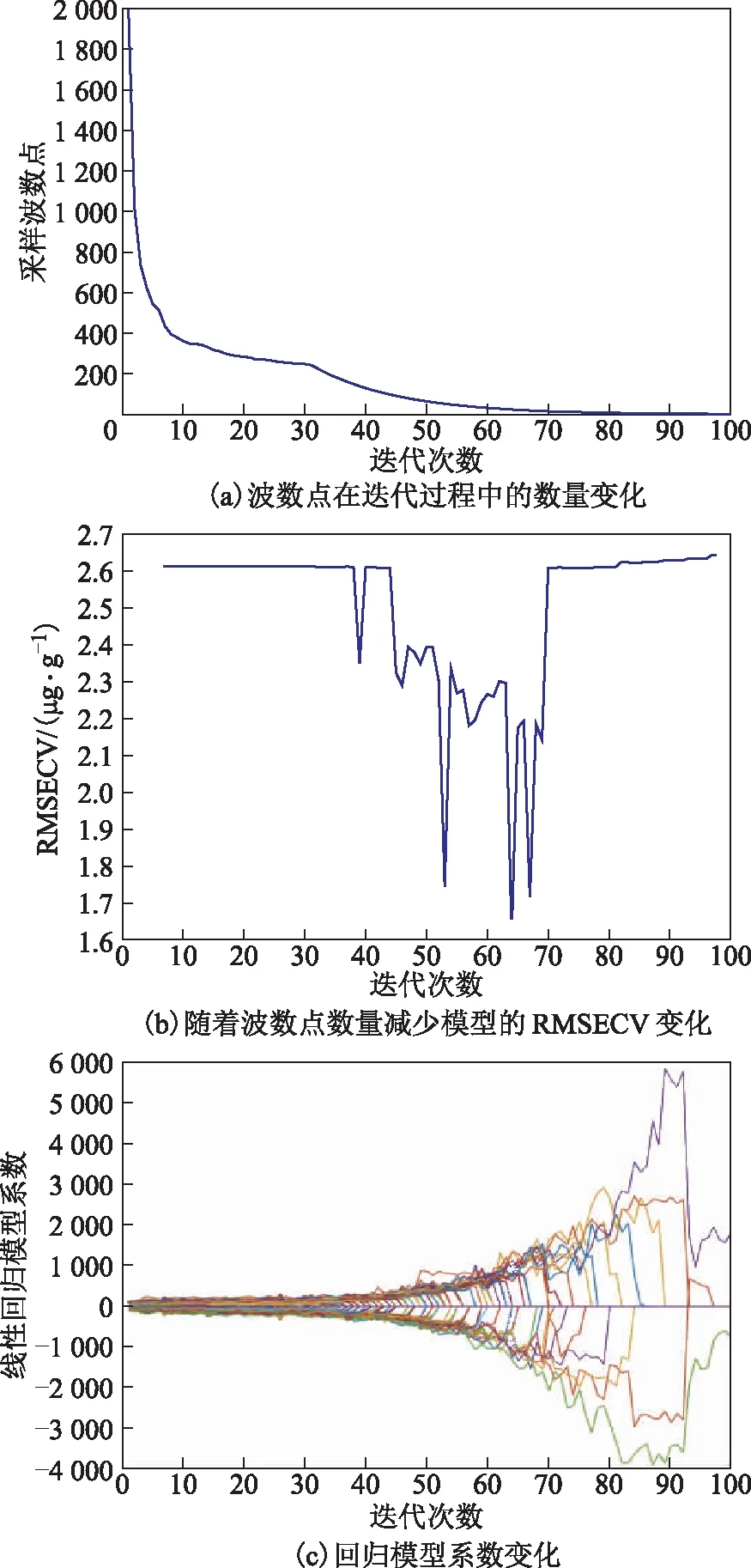
图6 基于竞争自适应重加权采样算法的谱段优化结果
竞争自适应重加权采样算法是结合蒙特卡洛采样和重加权采样方法,筛选出线性回归模型中回归系数绝对值大的特征,淘汰回归系数绝对值小的特征,并通过交叉验证评价经过筛选重建后的模型预测性能[8]。该方法能够搜索出与预测性质最相关的特征变量,对应光谱分析方向就是光谱的采样波数点,使用筛选后的光谱波数段建模,将提高模型的预测性能[9]。该方法在迭代过程中不断淘汰权重较小的波数点直到波数点个数为0,在这个过程中监测模型RMSECV的变化,并找到最优的波数段。设置采样次数为100次,作为算子的偏最小二乘法回归模型的主成分数为6,验证方法为5折交叉验证法。基于竞争自适应重加权采样算法的谱段优化结果见图6。由图6可知:随着迭代次数的增加,筛选的波数点数量减少;在迭代40次后,RMSECV呈现震荡下降的状态,在迭代64次时最小,随后又呈现出震荡上升的趋势;在迭代的过程中不断有线性回归模型的系数被归零,即对应的波数点被淘汰。在迭代初期,淘汰的波数点往往代表了数据的噪声,模型的性能随着噪声过滤得到了提升;在迭代64次之后,一些含有预测信息的波数点也被淘汰,模型由于数据信息量不足而性能劣化。因此,选取RMSECV最小的第64次迭代使用的波数点作为最优谱段,波数点的分布如图7所示。

图7 基于竞争自适应重加权采样算法的最优谱段波数点分布 —拉曼光谱; ■—被选择的波数点
2.5 模型预测结果与分析
分别采用全波段和3种选谱方法优化后的谱段进行偏最小二乘法建模,模型预测结果见图8。由图8可知:单独使用偏最小二乘法建模(全波段法),模型的预测值接近实际值,但是仍有一定的偏差,需要进一步优化;3种选谱优化方法中,竞争自适应重加权采样算法在1~5 μg/g的低原油质量分数区间以及10~100 μg/g的高原油质量分数区间的预测值偏差均明显减小,能够精确检测质量分数为1~100 μg/g的痕量原油。因此,利用拉曼光谱的荧光背景去检测炼化企业换热设备痕量原油泄漏是完全可行的。
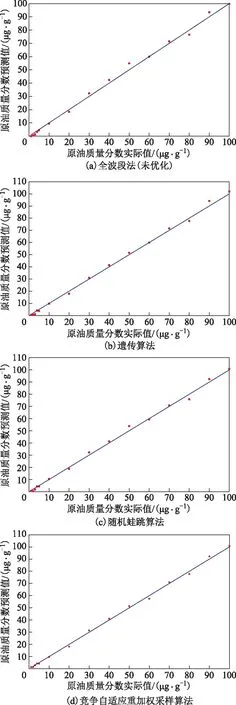
图8 各算法模型的预测结果
全波段和3种选谱优化算法的模型指标如表1所示。由表1可知:全波段法使用2 048个波数点数据进行建模;遗传算法对波数点分区间进行搜索优化,优选了504个波数点;随机蛙跳算法优选了93个波数点;竞争自适应重加权采样算法优选了25个波数点,其对波数点个数的筛选效果最为明显。从模型的预测性能上看,3种选谱优化方法均提高了模型预测精度,其中竞争自适应重加权采样算法的预测精度最高,预测均方根误差(RMSEP)为1.567 4 μg/g,相比于全波段法,降低了27.99%。因此,竞争自适应重加权采样算法具有最突出的谱段优化效果,在简化预测模型的同时提高了模型的预测精度。组合采用竞争自适应重加权采样算法和偏最小二乘法进行拉曼光谱痕量原油检测,可减少训练数据的规模,简化回归模型的复杂度,能够精确检测质量分数1~100 μg/g的痕量原油。

表1 各算法模型的性能比较
3 结 论
提出了一种利用拉曼光谱荧光背景对常压蒸馏塔塔顶石脑油中痕量原油杂质进行定量分析的方法,该方法通过偏最小二乘回归建立了拉曼光谱强度与痕量原油的线性回归模型。在偏最小二乘法的基础上,使用遗传算法、随机蛙跳算法以及竞争自适应重加权优化算法对拉曼光谱的全谱段进行选谱优化,剔除拉曼光谱数据中的噪声,在简化回归模型的同时提高模型的预测性能。结果发现,竞争自适应重加权算法的优化效果最佳,可以精确检测质量分数1~100 μg/g的痕量原油。炼化企业可以利用拉曼光谱的特性同时进行常压蒸馏塔塔顶石脑油性质分析和痕量原油泄漏检测,不仅可以节约成本,而且也符合当前炼化企业加工高硫高酸原油的大环境。
