基于优化极限学习机的非侵入式负荷识别
2022-04-08尤艺,梁喆
尤 艺, 梁 喆
(安徽理工大学 电气与信息工程学院,安徽 淮南 232000)
0 引 言
智能电网技术在各个国家用电节能发展进程中发挥着重要的作用[1]。非侵入式负荷监测技术(Non-intrusive Load Monitoring,NILM)作为智能电网的关键技术,最开始是由Hart教授进行阐述说明的[2]。NILM就是将采集的全部负荷信息分别转化成单个负荷的详细信息,实现负荷识别,这不仅可以促使用户关注用电情况,获取丰富的电力负荷数据,而且还可以使供电部门更加准确地了解用户的用电需求及趋势,更好地优化能源结构[3-4]。
非侵入式负荷识别领域的算法较多,文献[5]通过人工神经网络对家用电器设备进行识别,这种网络模型结构较为简单,易于理解,同时利用训练好的模型对电器工作状态进行判断,具有一定的有效性,但是该算法需要反复调整权值和阈值,会产生局部极值的弊端,并且测试时间长;文献[6]利用极限学习机(Extreme Learning Machine,ELM)对负荷进行辨识,跟传统的人工神经网络相比,输入权值和隐含层阈值是随机给定的,设置后不需要调整,具有速度快、误差小的优点,同时还在确定隐含层节点数的问题上做了详细的分析,但是没有考虑对权值阈值做进一步优化,使得识别结果达不到理想的水平;文献[7]采用粒子群算法对ELM的权值和阈值进行改善,其参数设置简单,并且可以依靠较少的隐含层节点进行分类,但是如果数据量大就会导致优化算法复杂,网络性能差识别精度不高。
本文在上述文献研究的基础之上提出了改进的极限学习机算法,即改进遗传算法中的选择算子,并结合爬山法,解决网络阈值和权值随机设定的不足,提高负荷辨识的正确率。到目前为止,采用ELM对负荷辨识的文献和资料少之又少,所以对ELM进行研究并拓展就有了必要性。
1 NILM基本框架
NILM是根据全部负荷特征信息,辨别出每个家用电器的运行状态及电能消耗量,其中包括数据采集与预处理、事件检测和特征提取等几个重要的环节,如图1所示。负荷识别是根据家用电器监测到的电压、电流信号提取特征量,基于机器识别算法识别出相应的电器设备。

图1 非侵入式负荷监测示意图
负荷特征可以分为稳态和暂态特征。其中,稳态特征包括电流波形峰值、均方根值、有功功率、谐波等。本文主要介绍了以下几种特征:
(1) 电流波形峰值:
Ip=max(i(n)),0≤≤n≤N
(1)
(2) 均方根值:
(2)
(3) 波峰系数:
式(1)和(2)中,i(n)代表的是第n点处电流,N代表的是总采集个数。
(4) 有功功率与无功功率:
(3)
(4)
式(3)和式(4)中,P,Q,U,I,各自代表的是有功功率、无功功率、电压、电流,i为谐波次数。
(5) 为了提取负荷的谐波特征,采用快速傅里叶变换(Fast Fourier Transform,FFT)将时域信息特征转换为频域信息特征[8-9],获取丰富的负荷谐波特征信息。FFT公式为

通过获取不同负荷的典型特征量,创建负荷特征数据集,用于下文家用电器的负荷识别。
2 基于优化ELM的负荷识别
2.1 极限学习机构建模型
极限学习机对于单隐层神经网络有新的优势,可以随机给定输入权值和隐含层阈值,而输出层的连接权值只需要解方程组就可得到。其模型简化结构如图2所示。详细的极限学习机相关介绍可以参考文献[10]。

图2 ELM模型结构简化图
2.2 优化极限学习机
ELM相对于传统的BP神经网络,学习速度快,参数选择也较为简单。但由于输入权值和隐含层阈值随机产生,网络的性能不能达到令人满意的程度,会导致识别效果不理想。针对存在的问题,提出了改进的遗传算法(Improved Genetic Algorithm,IGA),即结合爬山法对遗传算法中的选择算子进行改进。选择算子改进方法:首先对种群进行初始化操作,选择负荷识别准确度作为适应度函数,求解出个体的适应度值;其次将个体适应度值按由小到大依次递增的顺序进行排序,把排完序的种群平均分成4个等份,质量最差的为第一等份,其次为第二、第三等份,最好的为第四等份,分别用W,X,Y,Z表示;然后按0.6∶0.8∶0.8∶1的比例从4个等份中依次选择给新一代,被选择个体按照适应度值大小择优选择,新一代种群中剩余个体再从Z中择优,使新一代种群的数目跟最初种群数目等同。
利用IGA-ELM算法对居民负荷识别的具体方法如下:
(1) 根据家用电器特征参量个数确定ELM网络结构。其中隐含层神经元的数目经过多次实验确定选择25,激活函数选择Sigmoid。
(2) 设置IGA的迭代参数、种群大小等,然后根据采集电器样本数据对种群进行初始化和编码操作。本文迭代参数为100,种群大小40。
(3) 适应度函数是测试数据预测输出和实际输出的电器分类识别准确度函数即Accuracy,交叉和变异概率为0.7和0.01。
(4) 计算种群中个体适应度值,依照遗传算法规律进行改进的选择、交叉、变异操作,然后选择若干适应度值大的个体遗传给下一代。
(5) 利用爬山法在子代种群中再次进行择优选择,将选择的最初个体和临近区域内的个体进行比较,保存适应度值最好的个体。
(6) 判断有没有达到结束条件,如果是,将获得最优的权值和阈值,继续完成(7),否则回到(4)并执行。
(7) 获取的最优参数赋予ELM网络,并重新训练样本,将训练好的ELM网络用于识别家用电器。
通过改进的遗传算法使种群的多样性增加,且每次迭代过程均朝着最优的方向运行,最终寻得最优的输入权值和隐含层阈值。
3 仿真实验分析
3.1 负荷信号采集
随着经济和社会发展,电器设备类型越来越多样化,可以根据每个家用电器的电气性质,实现负荷识别。本文选取了电脑主机、电风扇、台灯、主机显示屏和吹风机5种电器。
在学校实验室搭建了基于阿尔泰USB3202多路同步数据采集卡的数据采集装置,利用该实验装置,可以实现对电流电压数据的采集,然后对数据特征分析完成电器负荷识别工作。其中采集装置如图3所示,电器(电风扇、台灯、主机显示屏和吹风机)电流波形如图4所示。
图3 数据采集装置

(a) 电风扇

(b) 台灯
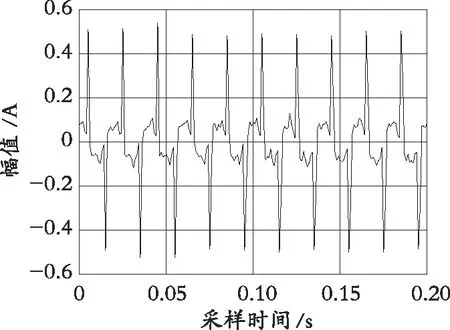
(c) 主机显示屏

(d)吹风机图4 电器电流波形图
3.2 数据预处理
采集到的负荷数据经过相应滤波处理后,提取负荷特征量。由于篇幅有限,只列举负荷部分特征量,各负荷典型特征量举例如表1所示。
3.3 仿真结果分析
为了验证已优化算法的有效性,进行仿真实验,实验平台为Window10,MATLAB R2018a。本文分别对吹风机、主机显示屏、电风扇3种电器的稳态特征进行提取,定义标签种类分别为种类1,种类2,种类3,每个电器抽取3/4的数据用于训练,剩下的用于测试,两种算法训练集和测试集的识别率如表2所示,其中ELM和IGA-ELM测试集的识别结果如图5和图6所示。
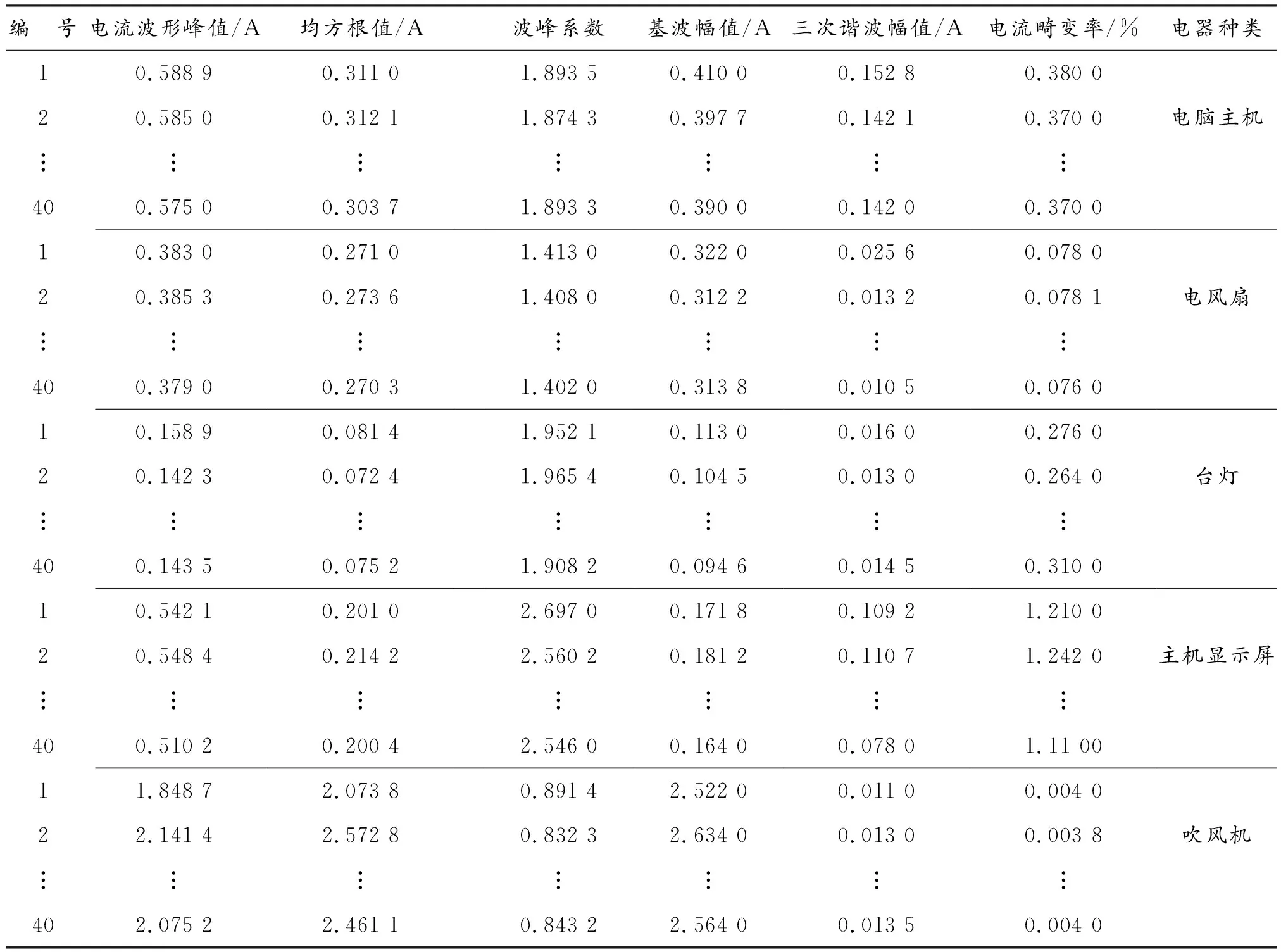
表1 各负荷典型特征量举例
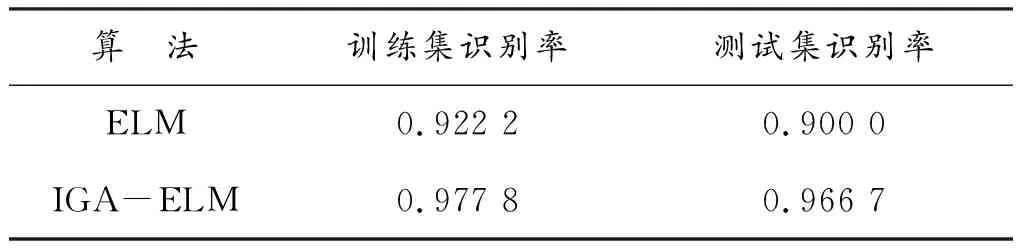
表2 两种算法结果识别率对比
从图5测试结果可以看出:ELM负荷识别率为90%,对种类2和种类3都有了识别错误,其中种类2识别率为90%,种类3识别率为80%。图6测试结果可以看出:基于IGA-ELM的负荷识别率为96.67%,仅只有种类2识别错误,种类3识别率为100%。与ELM算法相比,IGA-ELM算法对种类3识别率提高了25%,由此验证了IGA-ELM算法比ELM算法识别率高,表明了改进算法对极限学习机的权值和阈值进行优化是有良好效果的,利于负荷分类识别。
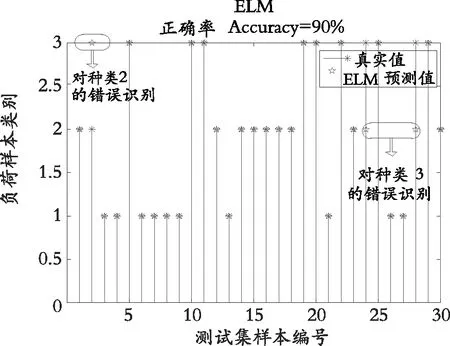
图5 基于ELM负荷识别结果

图6 基于IGA-ELM负荷识别结果
4 结 论
针对极限学习机输入权值和隐含层阈值随机产生导致对家用电器设备误判,识别效果不佳等问题,提出了改进遗传算法优化极限学习机,通过在MATLAB上进行反复测试验证,结果表明IGA-ELM算法比ELM算法在家用电器识别精度上得到了提高,由此验证了优化后极限学习机算法对负荷识别的有效性,同时也验证了该算法在非侵入式识别领域的实用性,具有一定的研究价值,可以做进一步的深入研究。
