基于两阶段分类算法的中国交通标志牌识别*
2022-04-07冯润泽于伟光杨殿阁
冯润泽,江 昆,于伟光,杨殿阁
(清华大学,汽车安全与节能国家重点实验室,北京 100084)
前言
自动驾驶技术被广泛地认为是一种减少交通事故、提高交通效率和舒适性的极具发展前景的技术。自动驾驶技术得以实现的基础是车辆可以自主地获取到交通环境中语义信息,而交通标志中包含了丰富的语义信息,其提供的警示、指示和禁止信息可以辅助缓解交通拥堵,降低交通事故发生率。此外,交通标志牌识别算法也是高级驾驶员辅助系统(ADAS)的重要子系统之一。正因为交通标志牌识别算法如此重要,最早的交通标志牌识别算法可以追溯到1987年,文献[3]中尝试构建一套交通标志牌识别系统。
交通标志牌识别可以分为交通标志牌的检测与分类两个步骤。传统交通标志牌识别算法依赖于人工设计的特征,一些算法将图片映射到RGB、HSV、YCbCr和LUV色彩空间利用交通标志牌的颜色特征对其进行检测,但这些算法易受到光照、天气和标志牌的表面反射率等因素影响,所以还有一些改进算法利用霍夫变换、距离变换、遗传算法或者快速径向对称算法等利用交通标志牌的形状特征对其进行检测。交通标志牌识别系统检测到图像中的交通标志牌后对交通标志牌实例进行分类进而得到交通标志牌蕴含的语义信息。传统的交通标志牌分类算法包括模板匹配算法和支持向量机算法等。通过近20年的研究,人工设计特征对交通标志牌的识别算法的性能在2010年左右达到了瓶颈。
在2012年,随着AlexNet被提出,基于卷积神经网络的方法被用于交通标志牌识别。之后由于并行计算硬件高速发展,许多基于卷积神经网络的目标识别算法被应用在交通标志牌识别领域。根据算法是否提前生成候选区域可将算法分为单阶段识别算法,如SSD和YOLO系列算法以及两阶段识别算法如RCNN、Fast-RCNN和Faster-RCNN。由于单阶段识别算法只需要进行一次特征提取便可实现交通标志牌的检测与分类,所以其运行速度较两阶段算法快,但是精度较低。
对于自动驾驶系统或者高级驾驶辅助系统而言,越早地识别出交通标志牌的语义信息就能越早地将信息传递给决策系统或者驾驶员,所以这就要求交通标志牌识别算法能够较好得识别出图像中微小的交通标志牌。YOLO系列算法的实时性和泛化性能较好,并且对于细粒度实例的识别效果好,所以YOLO系列算法非常适用于交通标志牌的识别。但由于车载相机获取得到的图片往往较大,而为了提高识别速度,识别算法会缩小图片后再输入到识别网络中。图片中的交通标志牌往往占据很小的像素区域,而且道路中的交通标志牌种类繁多,包含的语义信息可分为几十甚至上百种,各类别之间的特征差异不明显,这都增加了交通标志牌分类任务的难度,而交通标志牌的信息随着图片的缩小而丢失,导致分类的精度得不到保证,即便是性能优异的YOLO系列算法也很难在交通标志牌识别中取得优异的精度。
在交通标志牌数据集方面,因为基于卷积神经网络的识别算法需要利用大量的数据来训练神经网络,所以很多交通标志牌数据集相继被提出(如表1所示)。在交通标志牌识别领域十分流行的GTSDB(German traffic sign detection benchmark)于2013年被公开,其中包含有900张图片,这些图片中的1 200个交通标志牌分别标注为“指示”、“禁止”和“警示”3类。2016年由清华和腾讯公司联合制作的中国交通标志牌数据集TT100K(Tsinghua-Tencent 100K)包含有10 000张图片,30 000个交通标志牌分为128类被标注,但是因为其中很多种类的交通标志牌样本数量太少,所以在文献[28]中只对样本数目多于100个的45类交通标志牌进行了训练。2017年,长沙理工大学公开了CCTSDB(changsha university of science and technology Chinese traffic sign detection benchmark)数据集,其中包含有15 723张图片,其中包含有21 134个被分为“指示”、“禁止”和“警示”3类的交通指示牌。
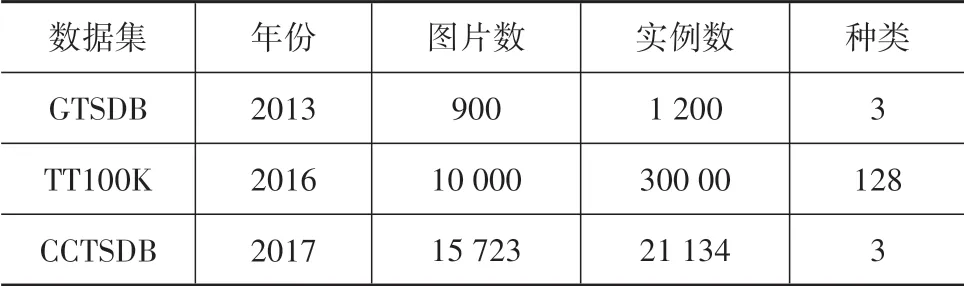
表1 主流交通标志牌数据集
由于我国的交通标志牌不同于任何其他国家,所以基于GTSDB等国外数据集的交通标志牌识别算法在我国交通场景下不具备应用价值。对于自动驾驶系统或者高级驾驶辅助系统而言,不仅需要能够识别出交通标志牌归属的大类(“指示”、“禁止”和“警示”),还需要识别出其具体的语义信息,因此CCTSDB数据集的分类方式并不满足需求。而在TT100K数据集中将限速类、最低限速类和限高类交通标志牌枚举出来(例如,“限高4.5 m”和“限高5 m”被分为两类),训练出的识别算法在实际应用中容易遗漏掉没有被枚举出来的其他限速类、最低限速类和限高类交通标志牌。
另外,由于TT100K中只标注了左转、直行等动作指示类交通标志牌(如图1(a)所示),而没有标注车道指示类交通标志牌(如图1(b)所示)。因此,在实际应用中会出现将车道指示类标志牌误识别为动作指示类标志的情况。
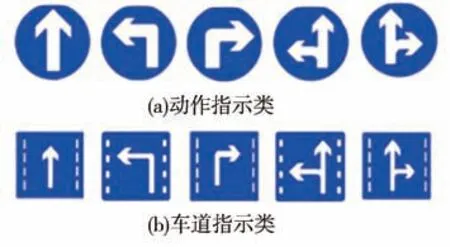
图1 标志牌
为解决目前国内交通标志牌数据集标注分类不清的问题,本文重新制作了中国交通标志牌数据集并且为了提升交通标志牌识别精度,提出了基于两阶段分类算法的交通标志牌识别算法框架(如图2所示)。本文提出的算法首先对YOLO系列单阶段目标识别算法进行改进作为检测模块,用于检测图像中的前景区域,然后从原始图片中截取出前景区域作为大类分类网络的输入将前景分为“禁止”、“指示”和“警告”这3大类,然后再将前景输入到对应的子类划分网络对前景进行子类划分。
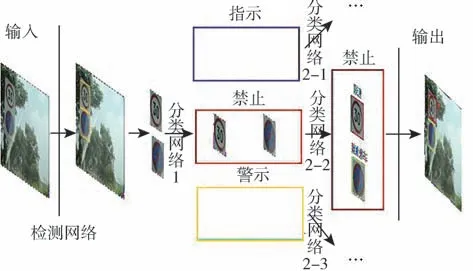
图2 算法架构
1 改进YOLO系列算法
YOLO系列算法是当前性能最好的目标检测算法之一,该算法具备单阶段算法的高实时性特征,其在Microsoft COCO数据集和Pascal VOC数据集上的效果都验证了这一点。本文中作为基线算法的YOLO系列算法首先将图片缩小到608×608像素大小,然后输入YOLO系列算法的骨干网络(YOLOv3算法的骨干网络为Darknet-53,YOLOv4和YOLOX算法的骨干网络为CSPDarknet-53)中,得到3个尺寸分别为76×76、38×38和19×19的特征图。
YOLOv3和YOLOv4算法会在最小的19×19特征图(有最大的感受野)上对每个网格生成3种尺寸不同的先验框(YOLOv3先验框尺寸为116×90,156×198和373×326像素,YOLOv4先验框尺寸为142×110,192×243和459×401像素),适合检测较大的对象。在中等的38×38特征图(拥有中等感受野)上对每个网格同样生成3种尺寸的先验框(YOLOv3先验框尺寸为30×61,62×45和59×119像素,YOLOv4先验框尺寸为36×75,76×55和72×146像素),适合检测中等大小的对象。在最大的76×76特征图(拥有最小的感受野)上还是对每个网格生成3种尺寸的先验框(YOLOv3先验框为10×13,16×30和33×23像素,YOLOv4先验框尺寸为12×16,19×36和40×28像素),适合检测较小的对象。YOLOv3和YOLOv4算法会生成预测框相较先验框的位置变化以及长宽放缩尺度,而YOLOX算法并不生成先验框,直接生成特征图网格对应的数个预测框左上角的坐标以及预测框长宽。
由于大特征图的网格(对应小感受野,适合检测小目标)数目最多,生成的先验框最多,所以YOLO系列算法有很强的小目标的识别能力,非常适于交通标志牌的识别任务。
YOLO系列算法的最终输出为预测框的位置、预测框内为前景的置信度以及前景的分类概率。YOLO系列算法的损失函数包含3个部分,分别是预测框的回归误差、置信度的误差和类别概率的误差。YOLO系列算法的损失函数中的置信度误差往往使用均方差函数计算,类别概率的误差往往使用交叉熵损失函数计算,而计算预测框的误差则各有不同,YOLOv3算法使用均方差函数计算预测框回归误差,YOLOv4算法使用CIoU误差来表示预测框误差,YOLOX算法使用IoU误差表示预测框误差。
为了使用YOLO系列算法专门检测交通标志牌前景而不进行分类,本文去掉了原损失函数关于类别概率的误差,修改后的损失如下式所示:

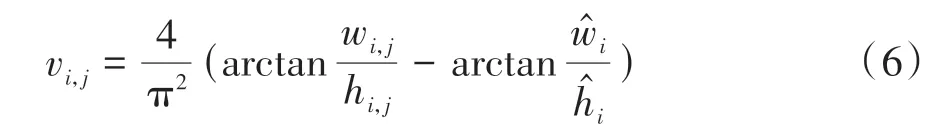
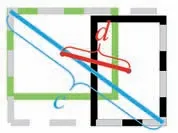
图3 CIoU参数图示[30]
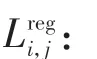
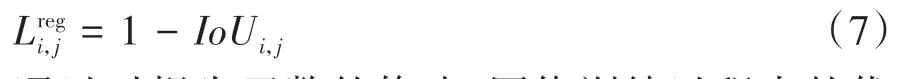
通过对损失函数的修改,网络训练过程中的优化目标变为提升预测框位置尺寸的准确度以及提升置信度的预测准确度。一方面,检测阶段更准确地对前景进行提取,有助于提升两个分类阶段对前景的分类准确度;另一方面,检测阶段更准确地对预测框置信度进行估计,有助于降低识别算法漏检率。
2 设计两阶段分类模块
为了提高检测算法的速度,当前主流算法都是将图片进行缩小后输入到识别网络中,以此来减少算法的计算量。但是在交通场景下,交通标志牌在图像中的占比往往较小,而交通标志牌各类别之间的特征差异不大,这就使得交通标志牌的分类任务难度较大,如再缩小图像,也即舍弃部分像素信息,势必会以降低检测精度为代价。因此为了提高对交通标志牌识别的准确率,算法从检测模块中获取前景,然后从原始图像中截取前景输入到分类模块中,这样便充分利用了图像中的像素信息。
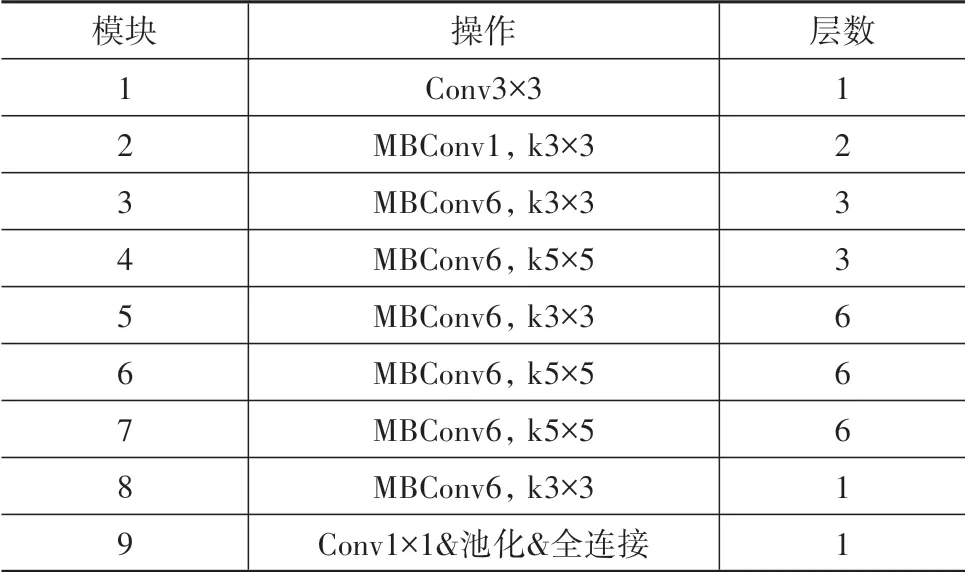
表2 EfficientNet-B3网络结构

表3 EifficientNet-B3与其他模型比较
EfficientNet-B3的网络输入是分辨率为300×300的RGB三色彩通道图像,首先经过一个大小为3×3的卷积层被处理为移动反转瓶颈卷积层(MBConv)需要的输入维度;然后经过27个卷积核为3×3或5×5的MBConv提取出特征图。之后,网络借鉴全卷积网络(FCN)的思路,将特征图输入到一个卷积核为1×1的卷积层中,这可以将任意尺寸的特征图转换到特定的通道数;最后通过1个池化层和1个全连接层得到输入图像属于各个种类的概率。训练过程中通过计算网络预测结果与真实类别的交叉熵损失函数作为损失函数,利用Adam算法优化网络参数。
因为本文提出的两阶段分类算法采用EfficientNet-B3,在保证分类准确率的情况下,运算量和参数量都达到最少,也即在相同硬件条件下,分类速度最快,所以识别算法可以利用最少的时间消耗来对识别准确率进行提升。
3 数据集标注
为解决上述数据集的问题,本文从CCTSDB和TT100K这两个中国交通标志牌数据集中抽取部分质量较好的图片并重新标注,标注种类如图4所示,图片中的交通标志牌实例的标注为中心点坐标,宽高所占像素x,y,w,h,实例所属大类C(“指示”、“禁止”和“警示”)和小类Sc(“禁止停车”、“最低速度”和“注意火车”等),所以每个实例可以用一个6维数组[x,y,w,h,C,Sc]表示。本文数据集包含18 955张如图5所示的图片以及其中的41 028个交通标志牌实例,数据集中包含实例数多于100的种类数目为53个(表4)。其中,“禁止”大类下有“禁止停车”等48个子类,“指示”大类下有“最低速度”等39个子类,“警示”大类下有“注意火车”等47个子类。

图4 交通标志牌种类

图5 数据集示例
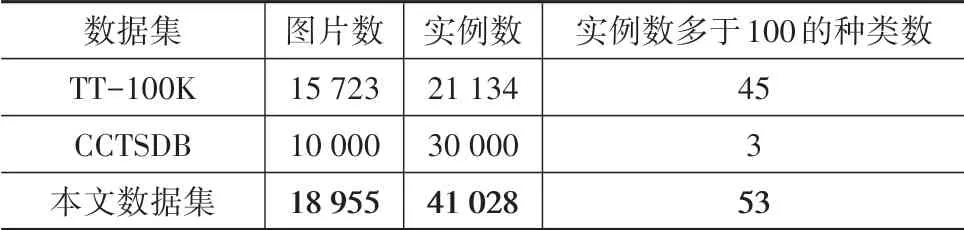
表4 数据集比较
本文所构建的数据集中禁止类实例占比58%,指示类占比32%,警示类占比10%。另外,由于一些子类样本数较少(少于100),无法用于神经网络训练,故将这些子类归入“其他”子类,处理后数据集中样本数多于100的子类数为53个。
本文从自动驾驶技术和高级驾驶辅助技术的需求出发,重构了中国交通标志牌的类别范围,构建得到的数据集较已有数据集包含的图片数目、交通标志牌示例数目和可训练类别(样本多于100)数目更多。
4 实验验证
首先本文将数据集中的图片按照4∶1的比例划分为训练集和测试集,训练集用于训练网络,测试集用于测试最终性能。其次,截取训练集中的交通标志牌,将交通标志牌实例划分为“禁止类”、“指示类”和“警告类”3大类用于训练大类分类网络,然后再将各大类交通标志牌实例划分子类,用于训练3个子类分类网络。
本文对参数进行如下设置λ=5,λ=λ=1,并利用一台配备有主频为2.3 GHz的Intel(R)Xeon(R)Gold 5118 CPU和3个显存为12 GB的Titan V GPU的服务器对YOLOv3、YOLOv4和YOLOX算法进行训练作为基线算法,并分别对YOLOv3、YOLOv4和YOLOX算法进行改进作为检测模块,结合分类模块组成two-stage-YOLOv3算法、two-stage-YOLOv4算法和two-stage-YOLOX算法,最后本文训练了传统两阶段识别算法Faster-RCNN与本文提出的两阶段识别算法进行比较。
表5为本文算法和基准算法和Faster-RCNN的性能比较结果,其中mAP@0.5是Pascal VOC挑战赛所采用的评价指标,是IoU阈值设为0.5时各类别平均准确率(average precision)的均值,通过比较基准算法与本文算法可以发现,YOLO系列算法改进为twostage-YOLO系列算法后mAP平均提高了8.52%。
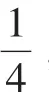
本文还比较了算法在工程实际中的性能。将置信度域值设为0.5,并根据Pascal VOC挑战赛中将与真实框之间的交并比大于等于0.5的预测框视为预测正确。将预测框与真实框之间的交并比大于等于0.5且预测种类与真实种类一致时视为算法识别准确,其余视为预测错误来计算算法对每种交通标志牌的召回率、准确率和误检(检测出前景但分类错误)率,得到的算法性能比较如表5所示。由表可见,YOLO系列算法的误检率都在11%以上,这说明YOLO系列算法在检测出交通标志牌后很容易将其划分到错误的类别中,而two-stage-YOLO的误检率都在7%以下,平均误检率降低了7.42%,这说明本文提出的算法在检测出交通标志牌前景后的分类准确率大大提升,这也使得在工程应用中,本文提出的two-stage-YOLO系列算法召回率较YOLO系列算法平均提高12.18%,准确率提高2.70%。在Titan V显卡上测试,two-stage-YOLO系列算法的帧率在14帧/s左右,而YOLO系列算法的帧率都在20帧/s以上,本文提出的算法为了提高检测精度确实牺牲了检测速度,但是文本算法的检测速度要略优于同样是两阶段算法的Faster-RCNN。
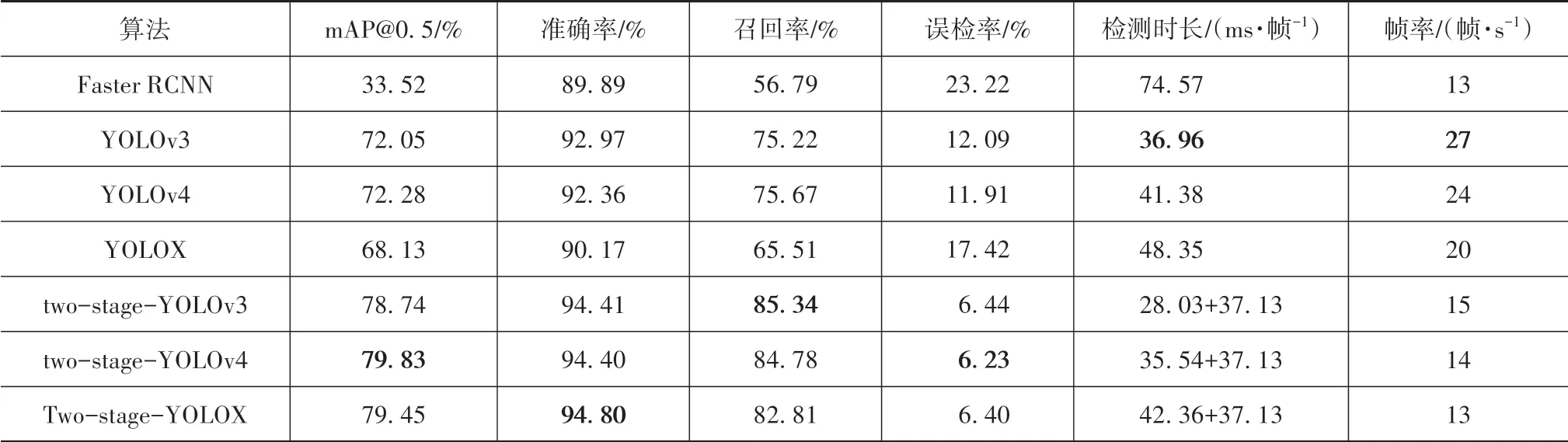
表5 本文算法与基线算法以及Faster-RCNN的性能比较
图6中列举two-stage-YOLOv3算法在测试集上的检测效果,可以看出本文提出的交通标志牌识别算法框架可以区分图4中的车道类标志牌和动作指示类标志牌。Faster-RCNN、YOLOv3以及twostage-YOLOv3的检测结果对比如图7所示,图片中的交通标志牌占比较小,Faster-RCNN没能检测出图片中的交通标志牌,而YOLOv3算法检测到了交通标志牌,但是将真实的前景的置信度检测为较低的0.42并且将“禁止鸣笛”标志牌错误地分类为“其他禁止类”,two-stage-YOLOv3算法成功地识别出了交通标志牌并且将正确的前景的置信度较好地检测为0.97(对于正确的预测框,置信度越趋近于1.00越合理)且分类正确。

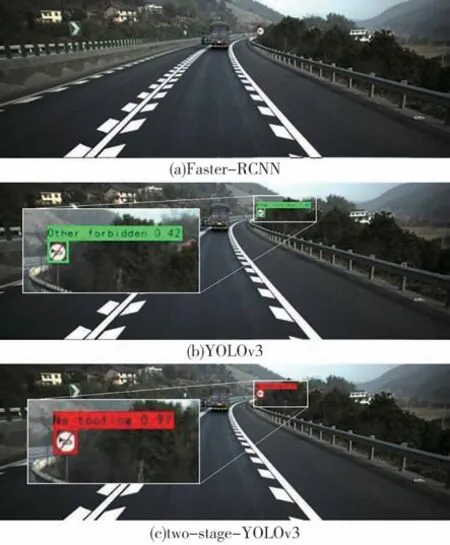
图7 检测结果对比
5 结论
本文基于中国交通场景特点以及自动驾驶系统和高级驾驶辅助系统对交通标志牌识别的高准确率需求,提出了一种基于两阶段分类算法的交通标志牌识别算法。检测模块使用善于小目标检测的YOLO系列算法对标志牌进行检测,分类第1阶段将检测到的标志牌实例进行大类分类,分类第2阶段对各大类下的标志牌进行小类划分。并针对当前数据集在实际应用中存在的问题,制作了一组包含种类更多、图片数和实例数更多的中国交通标志牌数据集。本文提出的算法通过细化分类任务,独立提升各算法模块的性能,进而提高整体算法的识别精度。本文提出的two-stage-YOLO系列算法较Faster-RCNN的mAP提升40%以上,较基准YOLO系列算法的mAP提升了8.52%,平均误检率降低了7.42%。
