高光谱成像的煤与矸石分类
2022-04-06李廉洁樊书祥王学文王璐瑶
李廉洁,樊书祥,王学文,李 瑞,文 小,王璐瑶,李 博*
1. 太原理工大学机械与运载工程学院,山西 太原 030024 2. 北京农业智能装备技术研究中心,北京 100097
引 言
煤炭作为我国的主体能源之一,是国家快速发展的重要支撑,近年来,随着环境问题日益突出,国家大力倡导并推进煤炭的清洁利用。 煤矸石是煤矿开采过程中产生的灰色或黑色岩石,将煤与矸石分离是煤矿生产的必要工序。 由于人工分选法与湿选法存在效率低、劳动强度大,水资源消耗高,污染环境等问题,干选法成为煤矸分选的主要研究方向之一。 干选法主要有破碎法(冲击破碎,挤压破碎等),存在设备寿命较短且普适性差的问题;射线法[1],需单独隔离射线源且有辐射风险;图像识别法[2],目前仍存在识别结果易受光照、灰尘等环境因素影响的问题。
可见/近红外高光谱成像技术具有分析速度快、无损、样品无需预处理、无污染,可同时测定多项指标等诸多优势,已被广泛应用于各个领域。 基于煤与矸石的高光谱数据和多种光谱分析方法,探究实现煤与矸石的高光谱无损检测,对实现“绿色开采”具有重要的研究意义。 虽然已有很多基于近红外光谱对煤的品质[3-5](固定碳、挥发分、灰分、硫分等)、煤的种类[6]以及煤产地[7]等问题的探讨,但基于光谱数据进行煤与矸石分类的研究还较少。 宋亮等[8]在室外采集样本的光谱数据,根据样本的可见/近红外光谱反射率和热红外光谱的光谱吸收比率对煤与矸石进行区分。 杨恩等[9]基于GRB-KPCA对样本光谱进行特征提取,并采用SVM区分烟煤与碳质页岩。 Mao等[10]同样在室外采集样本光谱数据,基于IAM-ELM算法实现煤与矸石的分类。 Hu等[11-12]基于多光谱成像技术挑选单一通道的光谱图像进行图像处理,从而实现煤与矸石分类。 Zou等[13]借助微型光谱仪,在样本正上方20 mm处采集光谱数据,基于lasso回归的宽度学习对煤与矸石进行区分。
基于光谱信息对煤的分析研究中,需对样本进行粉碎、研磨、筛选等预处理,且未考虑样本的背景颜色,与实际应用场景不符。 通过光谱仪和光纤进行光谱采集,只能获取样本部分区域的光谱信息,导致数据所包含的样本信息不够充分。
本研究的具体目标是: (1)基于高光谱成像系统采集块状煤与矸石样本在黑色背景下的高光谱数据,提取样本光谱信息并进行预处理后,探究不同分类模型对煤与矸石分类的可行性;(2)基于特征波长筛选算法挑选的特征变量建立简化模型,对比不同简化模型对煤与矸石分类的效果;(3)选择适用于开发煤与矸石分类的多光谱成像系统的分类模型,并对煤与矸石进行分类可视化。
1 实验部分
1.1 样本
样本为山西太原西铭矿的焦煤以及黑色矸石,样本总数168块(煤85块,矸石83块),样本高度在15~60 mm之间,随机划分校正集和预测集,其中校正集包含煤和矸石各60块,预测集包含煤25块,矸石23块。 实验前,将所有样品置于室内阴暗环境下,放置至室温。 图1为部分样本图片,从图中可看出,煤与矸石的颜色相似,肉眼难以将二者区分。

图1 部分煤样本(a)与矸石样本(b)Fig.1 Coal samples (a) and gangue samples (b)
1.2 高光谱数据采集及光谱提取
图2(a)为搭建的高光谱采集系统,整个系统主要包含两部分:
可见/近红外(visible/near infrared, Vis/NIR)高光谱成像系统,包括成像范围在326~1 000 nm的Vis/NIR高光谱成像仪(ImSpector V10E, Spectral Imaging Ltd., Oulu, Finland)、23 mm的C口变焦镜头(OLE23 f-2.4/23 mm, Spectral Imaging Ltd., Oulu, Finland)、像素为1 004×1 000的EMCCD相机(Luca-R, AndorTechnology, Belfast, UK)。
近红外(near infrared, NIR)高光谱成像系统,包括成像范围在930~2 548 nm的NIR高光谱成像仪(ImSpector N25E, Spectral Imaging Ltd., Oulu, Finland)、30 mm的SPCECIM口变焦镜头(OLES30 f-2.0/30 mm, Spectral Imaging Ltd., Oulu, Finland)、像素为320×256的CCD相机(Xeva-2.5-320, Xenics Ltd., Belgium)。
其余附件包括: 一对150W的卤素灯(Antefore International Co., Ltd., Taiwan, China),通过步进电机控制的样本移动平台(EZHR17EN, AllMotion, Inc., USA)。 整个采集平台置于暗箱中以降低外界杂散光的影响,通过计算机(Dell OPTIPLEX 990, Intel (R) Core (TM) i5-2400 CPU at 3.10 GHz)以及配套的专业软件(Isuzu Optics Corp., Taiwan, China)进行动作控制及数据采集。 经过调试,先将镜头与样本平台表面之间的垂直距离调整至400 mm,两光源相距550 mm置于镜头两侧,角度调整为45°。 采集数据时,将成像光谱仪和相机打开,30 min后待设备稳定,以纯黑色纸板为背景,将样本置于移动平台上,分别将曝光时间和平台移动速度设置为16 ms,0.73 mm·s-1与2 ms,42 mm·s-1以获取Vis/NIR数据以及NIR数据。 确保数据在同一时间段内获取以提高数据的可靠性。
为了减少照明不均匀以及相机暗电流的影响,需要对所采集的原始高光谱数据(Iorigin)进行黑白校正,在相同的环境下,利用反射率接近100%的聚四氟乙烯白板采集白参考(Iwhite),再将光源关闭后盖上镜头盖,采集暗参考(Idark)。 参照式(1)获得校正后的高光谱图像(I)
(1)
为提取样本光谱信息,先去除数据的背景信息,针对Vis/NIR高光谱图像与NIR高光谱图像,通过处理目标与背景对比度明显的918 nm,2 154 nm的单波段灰度图像获得掩膜图像以去除背景信息。 然后进行光谱数据提取,为了提高模型的适应能力,利用样本不同区域光谱信息的差异性,针对获取的Vis/NIR和NIR高光谱图像,分别随机选取大小为100×100像素、50×50像素的区域,提取区域内的平均光谱作为该区域的光谱信息。 重复10次,在两个波段各获得煤与矸石光谱850条和830条。 对Vis/NIR高光谱图像的分析流程如图2(b)。 最终,校正集共1200条光谱(煤和矸石各600条),预测集共480条光谱(煤250条,矸石230条)。
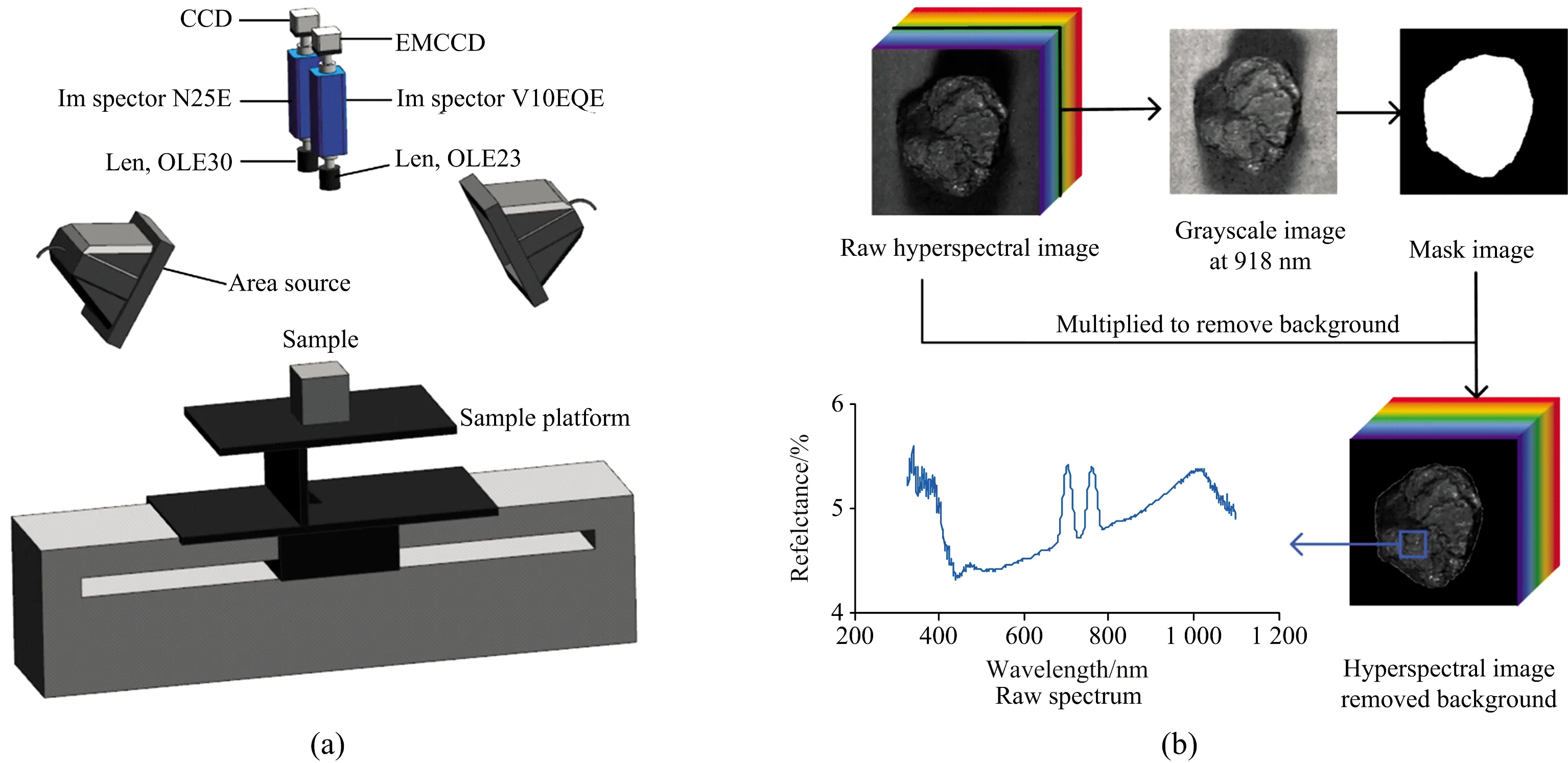
图2 高光谱采集系统(a)以及光谱提取过程(b)Fig.2 Hyperspectral imaging system (a) and process of spectrum extraction (b)
1.3 光谱预处理及特征波长变量的选择
光谱数据中不仅包含样本的化学信息,还包含仪器噪声,杂散光等无关信息,且全波段的光谱数据具有多重共线性和信息冗余性,通过对原始光谱进行预处理和波长选择,不仅可以减少噪声,还能剔除不相关或非线性的变量,减少数据量,简化模型,提高运算速度,一定程度上提高模型的性能,可为构建多光谱分类系统提供理论参考。
通过Savitzky-Golay(SG)卷积平滑(窗口为7,拟合一次多项式),消除光谱的随机噪声;由于样本尺寸有一定差异,因此再对数据进行标准正态变量变化(standard normal variate transformation, SNV)以消除光程变化等因素对反射光谱的影响。
竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)通过随机采样的方式,在校正集中随机选择一部分样本进行偏最小二乘(partial least square, PLS)建模,然后根据指数衰减函数保留回归系数相对较大的波长,N次重复获得对应的新变量子集,基于此建立PLS模型,选择交互验证均方差最小的变量子集作为最佳特征波长变量集。 在执行CARS特征波长筛选时,设置交叉验证为10折,采样次数为100次。
连续投影算法(successive projections algorithm, SPA),基于向量空间基变换原理,通过将波长投影到其他波长上,选择投影向量较大的波长子集作为最佳特征波长变量集。 在执行SPA特征波长筛选时,设置最大特征波长个数为5。
1.4 建模方法及模型评价指标
为获取可靠分类结果,选用支持向量机(support vector machines,SVM),k近邻法(k-nearest neighbor,KNN),偏最小二乘判别分析(partial least squares discriminant analysis,PLS-DA)三种经典的分类算法进行判别模型的建立与对比。 基于校正集训练判别模型,基于预测集对模型进行性能评估。 将煤作为正类,矸石作为负类,将敏感度(sensitivity),特异度(specificity),准确率(accuracy) 作为模型的评价指标,计算公式如式(2)—式(4)
(2)
(3)
(4)
式中: TP为实际为煤,预测也是煤的数量;TN为实际为矸石,预测为矸石的数量;FP为实际为矸石,预测为煤的数量;FN为实际为煤,预测为矸石的数量。
1.5 煤和矸石的分类可视化
高光谱数据提供了样本丰富的空间光谱信息,将样本表面所有像素点光谱的平均光谱代入已建立的模型进行判别,通过不同的颜色表示煤和矸石,不但可以检验模型的预测能力,还能更直观的反映样本种类。
所有数据处理均借助MATLAB R2019a(The MathWorks Inc., MA, USA)进行。
2 结果与讨论
2.1 反射光谱的曲线特征
由于原始光谱前后端有相当大的随机噪声,对Vis/NIR和NIR数据,分别取474~940 nm(600个变量)和1 235~2 477 nm(196个变量)范围内的光谱进行分析,并对光谱进行SG-SNV预处理。 图3为煤与矸石样本在指定范围内的原始光谱,显然煤与矸石的光谱曲线在相同的波段范围内显示出相似的趋势,但也存在一定的差异。
在474~940 nm范围,煤和矸石的光谱曲线均在700和760 nm附近有明显波峰,矸石光谱曲线的斜率大于煤光谱曲线的斜率;在1 235~2 477 nm范围,煤和矸石的光谱曲线在2 315 nm附近有明显波峰,在2 347 nm附近有明显波谷,矸石的反射率整体大于煤的反射率。 由于在近红外波段,芳香分子中电子跃迁趋向长波长方向,煤分子的芳构化程度高使其在近红外波段长波方向的光谱吸收系数大,整体反射率较低且反射光谱的斜率小于矸石[14]。

图3 煤与矸石在474~940 nm范围(a)和1 235~2 477 nm范围(b)的原始光谱Fig.3 The original spectral curves in the range of 474~940 nm (a) and 1 235~2 477 nm (b)
2.2 基于全波段光谱的煤与矸石的分类模型
在Vis/NIR和NIR范围内,基于校正集的全波段光谱训练SVM,KNN,PLS-DA模型,预测集的分类结果如表1。 三种全波段分类器的预测结果相同,对应的sensitivity,specificity,accuracy分别为1,0.956 5和0.979 2;在NIR范围,PLS-DA模型的预测结果最好,sensitivity,specificity,accuracy分别为1,0.987 0和0.993 8。 由结果可看出,在两个波段范围内,基于全波段光谱的三种分类模型结果均较好,证明基于煤和矸石的光谱信息可将二者区分。 但全波段光谱数据的处理速度较慢,故对其进行特征挑选。

表1 基于全波段光谱的不同分类模型对比Table 1 Comparison of different classification models based on the full-band spectra
2.3 基于特征波长的煤与矸石分类模型
为了消除冗余变量,进一步优化预测模型的性能,提高检测速度,采用CARS和SPA两种波长挑选算法筛选光谱变量,基于有效变量建立分类模型。
对全波段光谱进行CARS特征波长筛选的过程如图4,在两个波段范围内选择的波长数量随采样次数的增加而减少,波长数量的减少速度先快后慢。 在Vis/NIR波段,第85次采样获得的交互验证均方差最小,选择的变量子集包括716.94,717.73,718.51,768.82和769.61 nm共5个特征波长,占全波段的0.5%;在NIR波段第95次采样获得的交互验证均方差最小,选择的变量子集包括1 247.81,1 398.11和2 186.18 nm共3个特征波长,占全波段的1.17%。
对全波段光谱进行SPA特征波长筛选后的结果如图5所示,采用SPA筛选特征波长时,通过对比不同特征波长下的预测集样本均方根误差来确定最优特征波长数量。 在Vis/NIR波段,当特征波长数大于3时,预测样本集均方根误差变化不显著,选择了585.64,722.43和766.46 nm共3个特征波长,占全波段的0.3%;在NIR波段,当特征波长数等于3时,预测样本集均方根误差最小,选择了1 923.48,2 237.68和2 276.36 nm共3个特征波长,占全波段的1.17%。
基于校正集在Vis/NIR和NIR范围内的特征波长训练SVM,KNN,PLS-DA模型,针对预测集的分类结果如表2。 可以看出,在Vis/NIR范围内基于SPA筛选的3个特征波长所建立的SVM模型与在NIR范围内基于CARS筛选的3个特征波长所建立的KNN模型效果最好,二者不仅有效的减少了波长数量,还提高了模型的分类效果,对应的sensitivity, specificity, accuracy分别为1.000 0,0.965 2,0.983 3和0.988 0,0.991 3,0.989 6。
近红外光谱仪器的检测器在Vis/NIR范围多采用硅(Si)基检测器,成本较低;在NIR范围多采用硫化铅(PbS)或铟砷化镓(InGaAs)检测器,成本较高。 因此,综合预测精度以及后续多光谱系统开发成本的考虑,可选择Vis/NIR范围内基于SPA算法筛选的特征波长所建立的SVM模型作为煤与矸石的分类模型。
2.4 煤与矸石的分类可视化
相较于传统光谱,高光谱数据还包含空间光谱信息,这使得煤与矸石的分类可视化具有可行性。 选取在Vis/NIR范围内的SPA-SVM简化模型,基于样本表面所有像素点的平均光谱,对样本进行分类和可视化,用不同的颜色映射煤与矸石,不仅能够直观地表示样本的类别,在实际应用中还可保存可视化图像,便于系统故障时排查问题,图6为部分煤和矸石样本的分类可视化。

图4 Vis/NIR (a)和NIR (b)范围内CARS波长筛选过程Fig.4 The process of variable selection by CARS in the spectral ranges of (a) Vis/NIR and (b) NIR

图5 Vis/NIR (a), (c)和NIR (b), (d)范围内SPA波长筛选的结果Fig.5 The results of variable selection by SPA over the spectral ranges of (a), (c) Vis/NIR and (b), (d) NIR
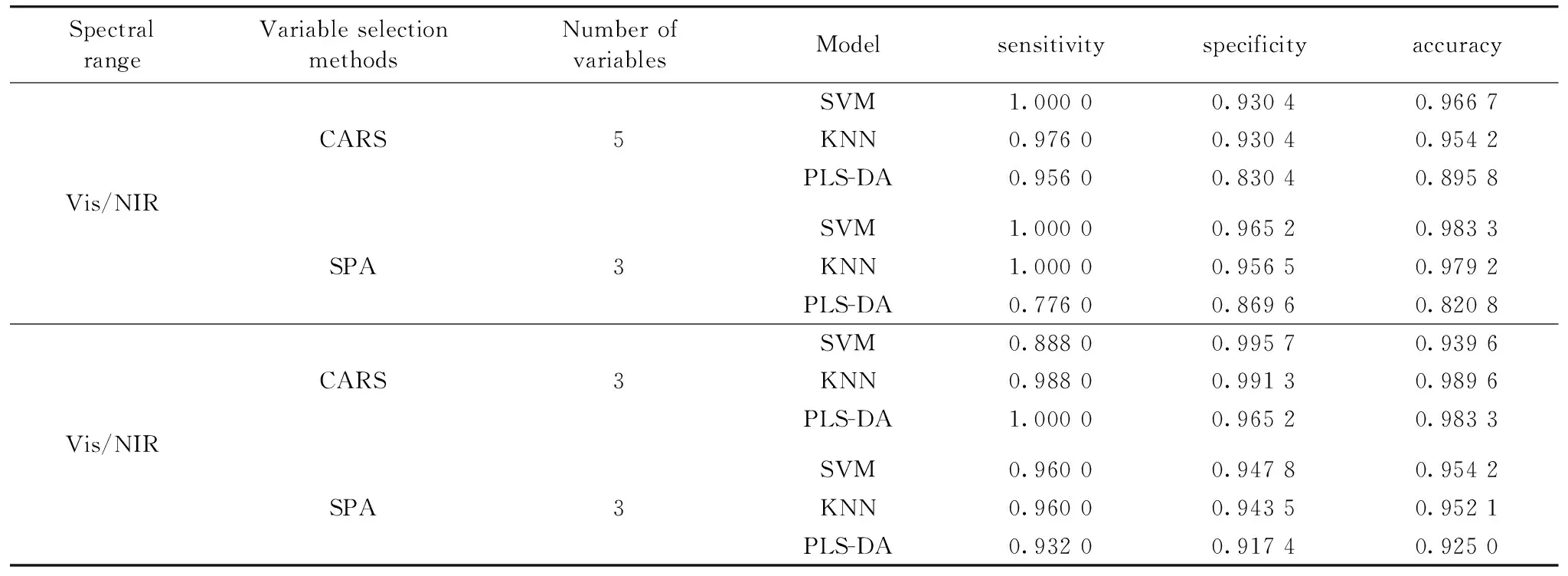
表2 基于特征波长的不同分类模型预测结果Table 2 The prediction results of different classification models based on characteristic wavelengths

图6 部分样本的灰度图及对应的分类可视化 红色: 煤;蓝色: 矸石Fig.6 Grayscale images of some samples and corresponding classification visualization red: Coal; blue: Gangue
3 结 论
针对黑色背景下块状煤与矸石的准确分类的问题,提出一种基于高光谱成像技术的煤与矸石的分类及类别可视化方法,得到以下结论:
(1)煤和矸石在Vis/NIR以及NIR范围内的光谱差异明显,基于光谱信息可将两者区分。
(2)与基于全波段光谱所建立的判别模型以及其他简化模型相比,Vis/NIR范围内基于SPA筛选的3个特征波长所建立的SVM模型与在NIR范围内基于CARS筛选的3个特征波长所建立的KNN模型效果最好,二者不仅有效的减少了波长数量,还提高了模型的分类效果。 对应的sensitivity, specificity, accuracy 分别为1.000 0,0.965 2,0.983 3和0.988 0,0.991 3,0.989 6。
(3)基于精度以及成本等因素考虑,可选择Vis/NIR范围内的基于SPA算法筛选的特征波长建立的SVM模型用于开发煤与矸石分类的多光谱成像系统。 同时可通过样本平均光谱以及分类模型实现样本的可视化,能够更直观的体现分类结果。
