小麦籽粒多角度图片库构建
2022-04-06李平郑颖冯继克李艳翠马玉琨
李平,郑颖,冯继克,李艳翠,2,马玉琨
(1.河南科技学院信息工程学院,河南 新乡 453003;2.河南师范大学计算机与信息工程学院,河南 新乡 453007)
中国小麦常年种植面积和总产量分别占粮食生产面积和总产量的25%和22%左右[1].小麦种子质量是决定小麦正常生长以及产量的重要因素之一,其质量问题一直是国家关注的焦点.小麦籽粒识别和分类是小麦种子质量评估的重要任务.快速准确的小麦籽粒识别可以为种子企业和育种者挑选优质品种提供帮助,节省成本.
随着信息技术的发展,农作物资源信息化构建已成趋势.农业种质资源是保障国家粮食安全与重要农产品供给的战略性资源.需构建多层次收集保护、多元化开发利用资源库,为发展现代种业、保障粮食安全奠定基础[2-3].中央一号文件指出加强种质资源库的构建,保护好资源是重中之重,加强完善种质资源的保护,可以丰富我国种子库的战略储备[3-6].
近几年机器学习发展迅速,人工智能在农业领域应用越来越广泛,深度学习作为机器学习的一个分支,能够从数量繁多的原始无监督数据中提取复杂特征,是当下进行数据分析的有效方式之一[7-8].樊超等[9]研究对于实现基于机器视觉的小麦品种分类的实用化提供了理论依据和参考.何胜美等[10]研究表明,形状特征和颜色特征能对小麦品种和来源地有效识别,品种识别率95.0%以上,来源地识别率平均为87.5%.Punn等[11]利用机器学习算法对小麦颗粒进行分类,SVM准确率为86.8%,神经网络的准确率为94.5%.孟惜等[12]利用改进BP网络对小麦品种识别,结合PCA降维后小麦品种平均准确率为91.582%,利用PSO算法优化网络后准确率增加到94.3%.陈文根等[13]基于深度卷积网络对小麦品种进行识别研究,该方法平均识别率达到97.78%.在机器学习中,模型越复杂越专注于训练数据,会导致训练效果较好,但测试效果欠佳,造成这种现象是因为产生了过拟合.而深度神经网络因为其网络结构,往往需要更多的数据来避免其过拟合的发生,保证训练模型在新的数据中有可以接受的结果.
在现有的小麦信息网站中,没有同一小麦籽粒多幅图片,不利于未来对种子资源的传播和使用.在已有的研究中,大多数为采集小麦籽粒的单面,不能很好地体现小麦籽粒的特征性,本文通过3种角度采集构建小麦籽粒数据库,可以更好地提高小麦籽粒品种识别的兼容性和准确性.本文选取种植面积较大的6种小麦种子籽粒进行图片库构建,每一粒小麦籽粒采集选用3种不同的角度,每一种小麦有3 000张不同的图片,对所采集的图片进行预处理得到不到1 GB的数据集.分角度的实验可以借助于深度学习模型更有利地提取小麦籽粒特征,避免一系列问题产生的干扰.最后,基于VGG16[14]模型进行分类识别.
1 数据库构建
1.1 传统图像采集
樊超[9]在对小麦品种进行分类研究中,采用的是BENQ_5000E型扫描仪进行4个不同品种和6个不同品种图像采集,拍摄时采用的方法是按照腹沟向上的形态进行扫描.孟惜[12]在对小麦品种识别中,采用的是BENQ_5000E型扫描仪进行6个不同品种图像采集,拍摄时采用的方法是按照腹沟向上的形态进行扫描.陈文根[13]在对小麦品种识别中,采用索尼IMX258进行9个不同品种图像采集,拍摄时采用的方法是籽粒背面图片.所采集的图像方式太过单一,都是采集的小麦籽粒的单面,不能很好地体现小麦籽粒的特征性,采集图像较少也不利于在深度学习模型中训练.
1.2 本文图像采集
河南科技学院生命科技学院实验室有小麦品种300多个,本文筛选出黄淮麦区种植面积较大的6个小麦品种,进行图像采集.表1为选择拍摄的小麦品种编号、品种名称以及本文对品种设置的标签.表1中品种编号为实验室原始编号,品种标签为本文处理并报告结果所用标签.图1为小麦品种实例.

图1 小麦品种实例Fig.1 Examples of wheat varieties
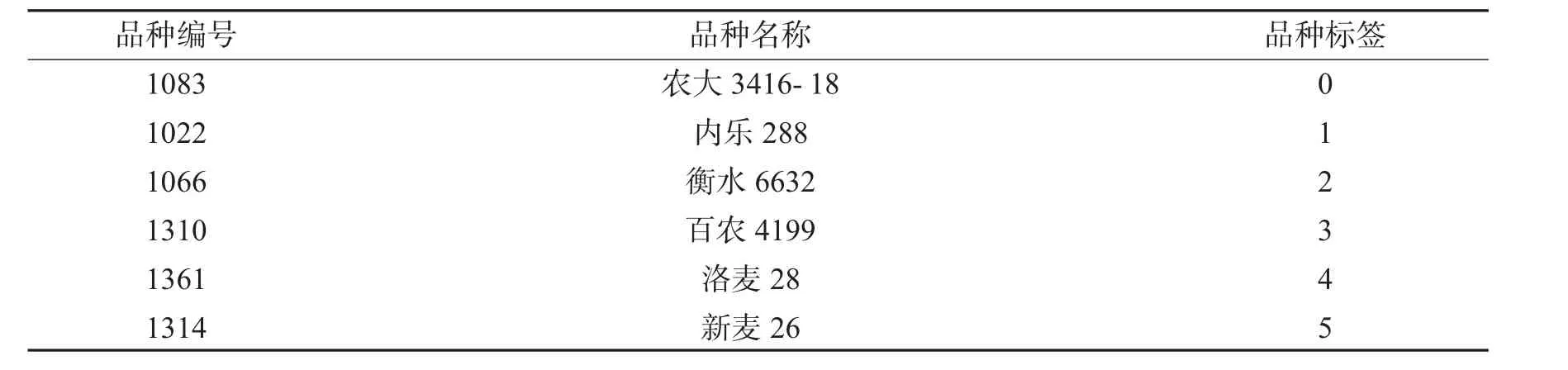
表1 小麦品种籽粒信息对照表Tab.1 Comparison tableof grain information of wheat varieties
本文为了更好地提高品种识别的兼容性和准确性,对选取的品种进行同一小麦籽粒,分为三种角度进行拍摄,分别为腹沟向上、腹沟朝前、腹沟向下.针对表1中选出的6个小麦品种,采用体视镜进行籽粒拍摄,拍摄时每个品种挑选出颗粒饱满的种子1 000粒.拍摄在室内自然光照和灯光条件下进行,同时,保持拍摄板的干净整洁,避免杂质影响后续的图像处理.拍摄时以黑色吸光绒布为背景,体视显微镜参数设置为:放大倍数1倍,分辨率2 688×1 520,自动白平衡(AWB)关闭,宽动态平衡(WDR)关闭,LED补光灯设为中等.通过调整体视显微镜右侧焦螺旋对小麦种子聚焦,每粒小麦分别拍摄腹沟向上、腹沟朝前、腹沟向下和空白4张图片.小麦籽粒图像采集过程中,为避免籽粒之间出现漏拍、多拍、错拍等现象,同时为方便后期筛选处理,使用空白照片将不同颗粒之间的小麦进行分隔,图2所示为采集的小麦籽粒三个方向的原始图像,拍摄时图像名是日期加自动编号.拍摄根据品种籽粒类别逐类拍摄,每类品种保存至一个文件夹中.最终得6个品种的19 800张照片(包含空白照片),照片大小合计为3.8 GB.

图2 小麦籽粒三种角度图片Fig.2 Image of wheat grain fromthreeangles
1.3 图像命名
本文拍摄的原始图像命名格式是时间加自动编号,没有体现小麦的品种类别和拍摄角度信息.使用Python编写自动命名标记程序,重命名后的小麦图像命名格式为品种标签_籽粒编号_拍摄角度,如图3所示.如0_1_1,0_1_3,0_1_3等,命名结合表1的品种标签,0代表农大3416-18,1代表内乐288等;标签中第2位数字代表每个品种拍摄的小麦颗粒数,0_1代表农大3416-18的第一粒小麦,0_2代表农大3416-18的第二粒小麦,以此类推;第3个数字表示每粒小麦分不同角度拍摄的3张图像,1代表小麦腹沟向下,2代表小麦腹沟朝前45°,3代表小麦腹沟向上.综上,3_1_1代表百农4199第一粒小麦,拍摄的第一个角度的图像,3_2_1代表百农4199第二粒小麦,拍摄的第一个角度的图像,1_2_3代表内乐288第二粒小麦,拍摄的第三个角度的图像.使用程序对6个小麦品种统一命名,删除空白照片,统一命名后得到18 000张图像,图像总大小为3.2 GB.
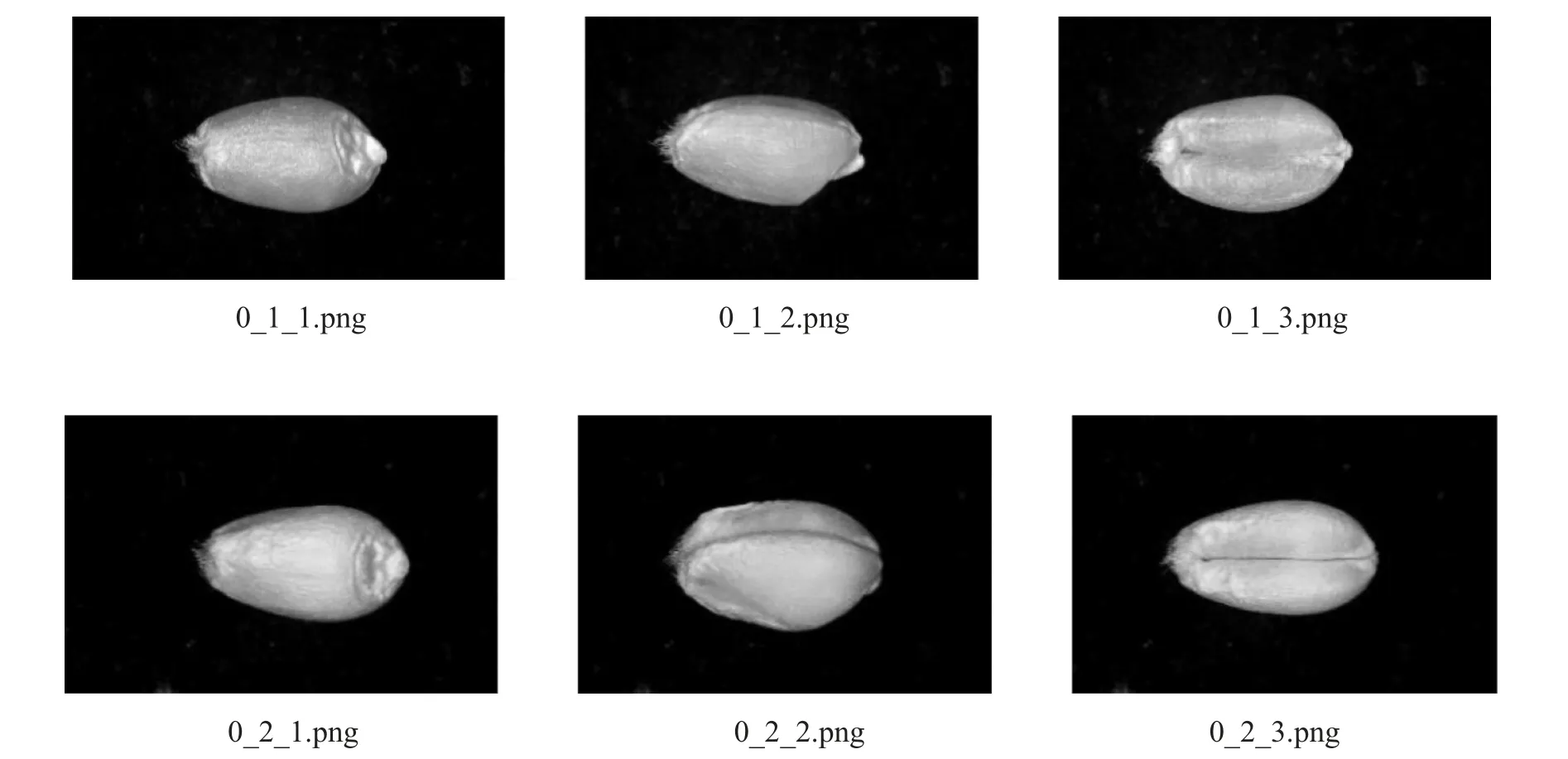
图3 小麦图像命名标签Fig.3 Wheat image naming label
1.4 图像预处理
由于在拍摄中一些图片会存在主体不够突出,辨识度低等问题,图片拍摄时没有按照角度进行命名,为方便后续实验本文对图片先进行了预处理.
原始小麦图像分辨率为2 688×1 520像素,且原始数据中小麦两边有部分黑边.原始图片带有影响图片的因素,因此要先对数据进行降噪处理,去除掉照片中的干扰因素,方便后续实验.为使数据更加适合训练模型和降低图像黑边对训练的影响,本文将2 688×1 520像素的图像切割为1 520×1 520像素.如不对图像进行压缩,则易造成内存溢出和训练时间较长的情况,内存溢出将导致模型无法完成训练,本文将其按比例压缩为152×152像素.图4为裁剪后的小麦籽粒图像.对所有图像进行压缩后小麦籽粒图片大小共计为433 MB.

图4 裁剪压缩后图像Fig.4 Imageafter clipping and compression
1.5 VGG16网络
卷积神经网络[14-15]是深度学习的代表算法之一,一般有卷积层、池化层、全连接层和Softmax成组成.卷积层的功能主要是对输入数据进行特征提取,内部包含多个卷积核,组成卷积核的每个元素都对应一个权重和偏差量,类似于一个神经元.在卷积层进行提取特征后,数据的特征图就会被传递到池化层进行特征选择和信息过滤.全连接层位于卷积神经网络隐含层的最后部分,并只向其他全连接传递信号.本文以VGG16为例,验证视觉领域的主流算法深度学习在本数据集上的适用性.
2 实验验证
2.1 实验环境
实验使用PyCharm开发环境和Python语言,计算机硬件为Intel Core I7-9300HQ,16G内存,NVIDIA Ge Force GTX 1600Ti显卡,Windows10 X64操作系统.实验数据共有6组实验对比,按照8∶1∶1的比例划分为训练集、验证集和测试集,模型训练使用Kreas框架,训练模型使用的参数batch_size设置为32,epochs设置为15,激活函数为softmax,优化器为SGD.
2.2 数据增强
卷积神经网络结构比较复杂,需要大量的数据支持训练并获得其结果,目的就是为了避免发生过拟合现象.在实际应用中很难获得大量的图像数据,所以采用数据增强成为一种可以获得大量数据的方法.本文通过原图、翻转、旋转、对比度增强、亮度增强、颜色增强扩充数据集.翻转角度图采用整体旋转180度,旋转角度图片采用逆时针旋转20度,对对比度、亮度、颜色采用Python图像处理库中Image Enhance模块对其进行数据增强,对其设置的范围都在1.5.图5为数据增强的效果图.
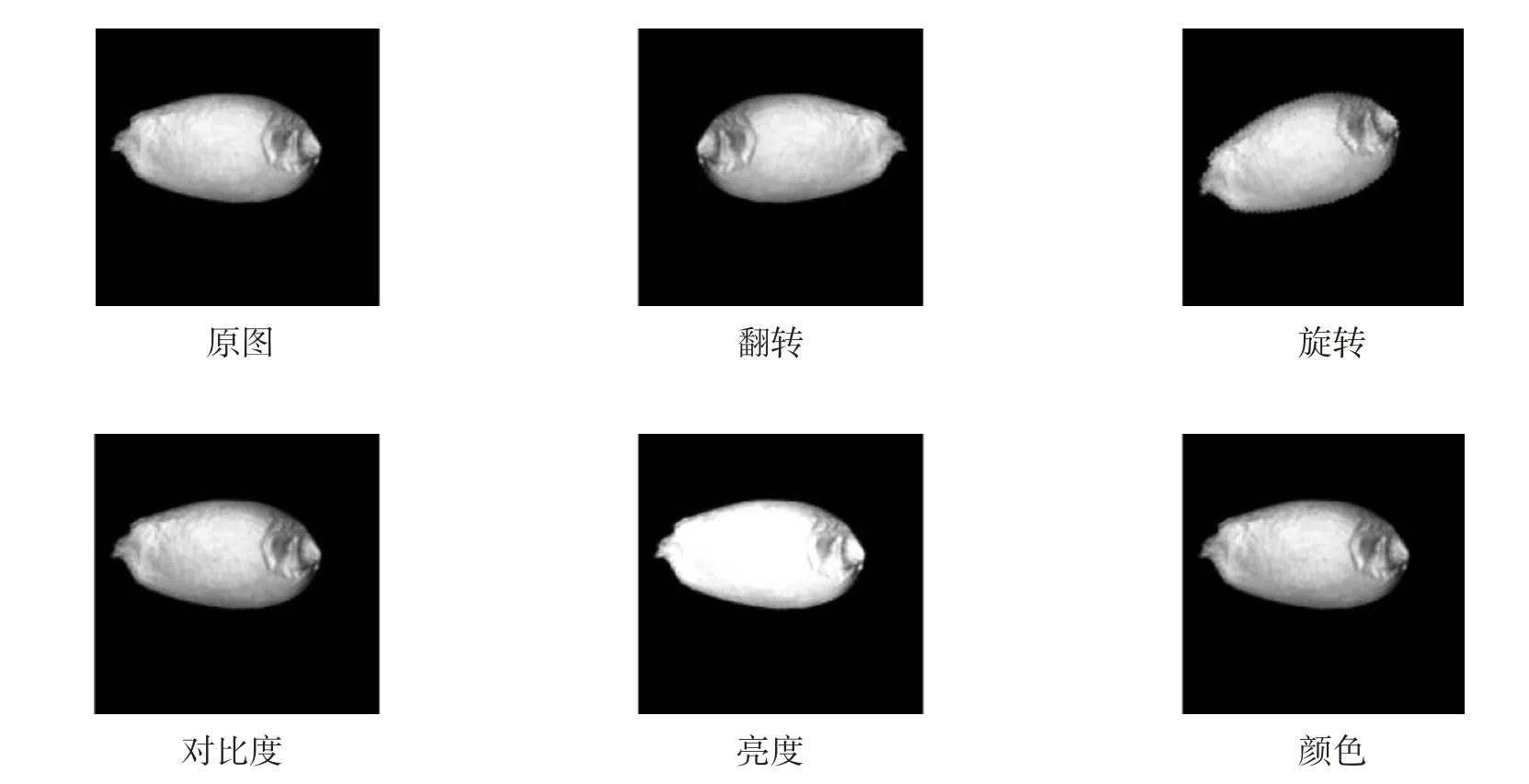
图5 数据增强图片实例Fig.5 Examplesof dataenhanced picture
2.3 实验设置
针对本文图像数据,分别进行分角度原数据、分角度增强数据、角度混合数据实验,具体实验设置如下:
分角度原数据:腹沟向下、腹沟朝前、腹沟向上原数据,选择每种品种1 000张图片,每个角度计6 000张图片.
分角度增强数据:选择每个角度的图像,对其进行数据增强操作,将数据量进行扩增,这样可以使复杂的卷积神经网络更好的训练,从而减少过拟合的风险.增强方式分别为翻转、旋转、对比度增强、亮度增强、颜色增强,每个角度每种品种1 000张图片,每个角度数据扩充完为5 000张,每个角度共计30 000张图片.
角度混合数据:对于角度混合数据分为两种,第一种是腹沟向下、腹沟朝前、腹沟向上原数据,选择每种品种1 000张图片,三种角度共计6 000张图片;第二种是腹沟向下、腹沟朝前、腹沟向上原数据,选择每种品种3 000张图片,三种角度共计18 000张图片.图6为实验流程图.
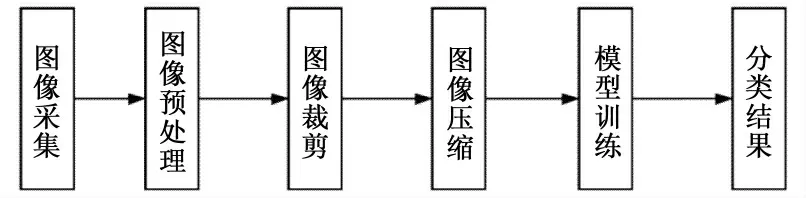
图6 实验流程Fig.6 Experimental flow chart
2.4 结果及分析
对小麦的腹沟向下、腹沟朝前、腹沟向上、腹沟向下数据增强、腹沟朝前数据增强、腹沟向上数据增强、角度混合6 000张图片、角度混合18 000张图片进行实验,模型的小麦腹沟朝前数据训练损失精度曲线和验证损失精度曲线如图7-a和图7-b所示.由表2和图7-a可以看出,腹沟朝前在曲线的末端验证精度和训练精度并未达到了重叠,但验证损失和训练损失基本一致,准确率达95.1%.由表2和图7-b可以看出,腹沟朝前数据增强在曲线的末端验证精度和训练精度达到了重叠,验证损失和训练损失也基本一致,准确率达98.7%.如表2所示,通过实验对比对原始数据和数据增强的三种角度来说腹沟朝前的准确率是最高的,准确率为95.1%和98.7%;当对所有角度混在一起分别选择6 000张图片和18 000张图片进行实验,结果显示准确率分别为92.6%和97.5%,从结果看角度混合图片在6 000张的时候比18 000张图片低几个百分点,说明从数据量来说没有达到,当图片数量到达18 000张时,对于小麦籽粒特征提取更加准确.通过角度混合后的准确率相比3种角度单独实验的准确率有明显提高,进行同一小麦籽粒多幅图片更有利于小麦籽粒特征的提取,进而提高小麦籽粒品种的兼容性和准确性.
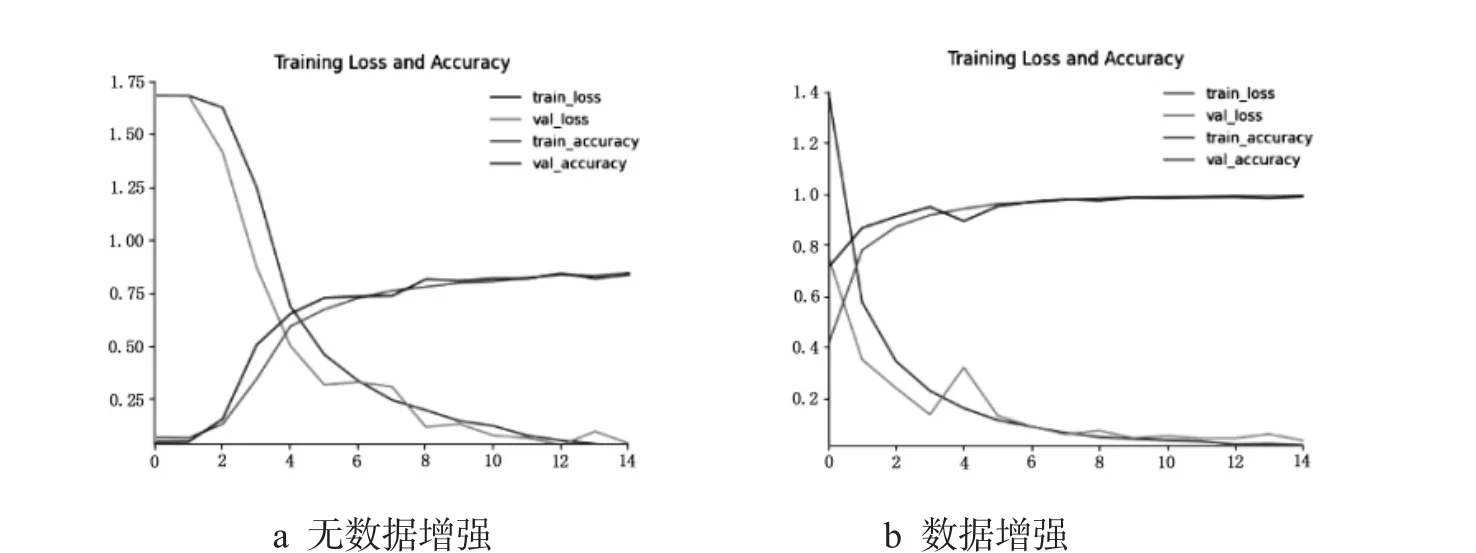
图7 小麦腹沟朝前数据损失和精度曲线Fig.7 Enhancement loss and precision curveof wheat ventral sulcusforward downward data

表2 不同数据结果比较Tab.2 Comparison of different dataresults
由3种角度单独实验结果来看,腹沟朝前的图片更有利于深度学习模型提取小麦籽粒特征.对腹沟向下的图片进行数据增强,准确率有明显的提升,说明可用采用数据增强等方法进一步提高识别性能.
为分析不同品种小麦籽粒的识别效果,本文利用混淆矩阵对结果进行分析.在混淆矩阵中,深色表示识别准确率,颜色越深表示识别率越高.0-5代表了6种小麦类别,具体的介绍在表1.图8-a到图8-c分别代表的是腹沟向下、腹沟朝前、腹沟向上.图9-a到图9-c分别代表的是腹沟向下数据增强、腹沟朝前数据增强、腹沟向上数据增强.综合图8和图9可用发现1和5识别错误率最高,出现这种错误的原因是它们和其他品种在纹理、颜色、形状等特征上比较相似,如图10所示.

图8 原始数据混淆矩阵对比Fig.8 Confusion matrix pair results

图9 数据增强混淆矩阵对比Fig.9 Confusion matrix pair results

图10 错误率最高的种子对比Fig.10 Comparison of seeds with thehighest error rate
3 小结
对于传统的小麦籽粒种子图像采集,本文构建了同一小麦籽粒多幅图片的小麦种子籽粒图片库.然后对图片进行自动更名、裁剪和压缩等处理.使用卷积神经网络中的VGG16模型进行腹沟向下、腹沟朝前、腹沟向上、腹沟向下数据增强、腹沟朝前数据增强、腹沟向上数据增强、角度混合的识别,结果表明分角度小麦籽粒分类数据库有助于深度学习模型更准确地提取小麦籽粒特征,数据增强后准确率达98.7%,当混合所有角度进行实验,准确率达97.5%,高于3个角度单独实验的结果,说明构建同一小麦籽粒图片分角度采集数据是有必要的,更有利于小麦籽粒特征的提取,提高了品种识别的兼容性和准确性.而腹沟朝前数据增强后准确率比其他两种角度有明显的提升,表明腹沟朝前数据更有利于深度学习模型提取小麦籽粒特征,验证了分角度数据采集的合理性.实验结果表明本图片库的图片经过预处理之后一致性较好,有助于深度学习模型更好地提取特征,为后面做小麦分类更深层的研究提供基础资源.下一步工作是针对小麦资料图片数据进行深入的分析,探索适用小麦籽粒识别的模型并将之应用于实际工作中.
