基于微服务架构的农业数据云存储研究
2022-03-31杨改改高贤强
杨改改, 高贤强
(塔里木大学 信息工程学院,新疆 阿拉尔 843300)
近年来,随着农业信息化建设的发展和农业综合生产力的提高[1],各类农业数据得到重视,合理的保存和利用这些农业数据可以更好地指导和推动农业经济的有效发展。然而,我国农业数据分布广泛,增长迅速,农业信息资源呈现多元化与异构化特征[2-3]。面对海量农业数据[4],通过购买昂贵的大型服务器存储,不仅成本高,而且这些服务器大多采用传统的关系型数据库管理数据,导致系统扩展升级困难,可维护性差。云存储能有效地解决海量数据的存储问题,最大限度地整合系统的存储能力,减低数据存储成本,大幅提高系统的整体性能及可维护性[5-7]。
随着平台的不断发展,用户数量和业务需求日益增多,传统单体应用程序显然很难满足较大的网络流量和复杂的业务需求,在这种情况下,可以采用微服务的架构模式。这种架构模式可将传统的单体应用按照业务划分为一个个小的服务,而这些小的服务之间又能相互通信、相互协调、相互配合,并具有可独立部署、高可用、容错等特点[8-10]。微服务架构有效解决了单体架构代码量质量差、耦合性高、系统可维护性差和可扩展性差等问题[11-12],使得农业大数据可以更好地存储和管理。
1 材料与方法
1.1 微服务架构
Martin Fowler和James Lewis于2014年共同提出微服务架构的概念[13]。微服务架构是软件开发中的一种架构风格,它将一个大型复杂软件应用根据业务功能划分成多个微服务。每个服务运行在独立进程中,服务底层可选择适合自己的技术栈,实现并进行独立部署,服务之间采用轻量级协议进行通信。
与微服务架构相比,传统的单体架构系统耦合度高,扩展性和维护性较差。应用微服务架构可将业务系统彻底的组件化,围绕业务功能组织服务,边界清晰,耦合度降低,使基础设施自动化,利于应用开发和部署[14]。本农业数据云存储平台研究使用的SpringCloud微服务[15],是以SpringBoot[16]为基础,拥有一套完整的微服务实现组件,使分布式系统的开发更加简单,平台更易部署和维护。
1.2 Hadoop存储原理
Hadoop是一个分布式系统基础架构,由Apache基金会开发,实现了分布式文件系统HDFS(Hadoop Distributed File System)[17]。Hadoop适于存储TB和PB级别的大型数据,其原理就是使用HDFS作为存储系统。HDFS可运行于普通廉价机器,具有高容错性,为数据存储提供所需的扩展能力[18]。在一个Hadoop集群中,客户端Client把上传的文件切分成一个个Block,由NameNode处理客户端请求,管理HDFS的名称空间和数据块(Block)映射信息。此外,多个DataNode节点存储数据块,执行数据块的读写操作,而SecondaryNameNode辅助NameNode,分担其工作量。图1为Hadoop存储数据的结构图。

图1 Hadoop存储数据的结构
2 结果与分析
2.1 微服务架构设计
农业数据云存储平台是采用SpringCloud微服务架构,基于SpringBoot搭建微服务、前后端分离的理念进行开发的。图2为基于SpringCloud 微服务架构图,采用SpringCloud的组件Eureka为注册中心进行服务注册,Feign完成服务间的调用,Hystrix为熔断器来提高系统整体的弹性,使用Gateway集群实现路由、限流、鉴权功能。

图2 SpringCloud 微服务的架构
2.2 平台整体架构设计
基于SpringCloud开发的农业数据云存储平台主要使用Hadoop分布式存储进行农业数据的海量存储,主要分为访问层、转发层、接口层、服务层和存储层,图3是平台整体架构图。

图3 基于SpringCloud的农业数据云存储平台架构
访问层。该层主要是在客户端展示平台的业务,给用户提供访问的端口,例如用PC端或者移动端去访问农业数据云存储平台,实现用户和存储平台之间的交互。
转发层。为避免服务器崩溃,让用户有更好的体验,该层搭建Nginx集群作为负载均衡承受高用户量的访问,可把用户的请求分布在各个服务器上来缓解服务器的压力,使性能得以提升。
接口层。农业数据平台在该层搭建SpringCloud Gateway网关集群,提供一个简单而有效的方式,对API进行路由。通过转发服务,使前端的调用逻辑和复杂的内部服务调用变得更加简便易操作,同时还具有安全、鉴权和限流功能。
服务层。该层基于微服务实现,主要分为业务服务、公共抽取服务以及服务管理。业务服务主要完成平台要实现的逻辑功能和对数据的操作,公共抽取服务主要是对Feign、Ribbon、Hystrix等微服务组件和常用工具类的抽取,而服务管理通过注册发现、配置管理和监控报警来支撑服务有效的运行,这些服务之间可通过HTTP或RPC协议互相调用。
存储层。该层包括数据缓存和数据存储。使用Redis数据库做数据缓存可保证数据的高速访问,同时还可将数据持久化到磁盘中,使数据的安全性得到保证。用Hadoop中的分布式文件系统HDFS做海量非结构化农业数据的存储。
2.3 Hadoop分布式集群搭建
本试验安装了4台版本为Centos7.4的Linux系统,并安装了JDK和Hadoop,JDK版本为Java 1. 8.0_271,Hadoop版本为Hadoop 2.7.5。在4个节点组成的分布式集群中,包含1个master主节点和3个slave从节点,分别命名master、node01、node02和node03。4个节点分别关掉防火墙和selinux、host映射,配置时钟同步。具体的集群规划如表1所示。在实际生产环境中,可根据具体需求,动态的添加和删除节点,提高集群的可维护性。

表1 分布式集群服务器节点规划
4台机器关闭防火墙和设置时钟同步之后开始配置Hadoop集群环境:在core-site.xml中设置fs.default.name定义master的URI和端口,设置hadoop.tmp.dir指定临时文件存储目录;在hdfs-site.xml来设置HDFS参数,dfs.namenode.http-address指定namenode的访问地址和端口,dfs.namenode.name.dir和dfs.datanode.data.dir指定数据的存放位置,设置文件的副本个数dfs.replication的值为3;配置slaves文件,把从节点名称加入到Master配置中;使用start-all.sh启动Hadoop集群,输入命令jps验证成功。
2.4 平台功能的实现
农业数据云存储平台主要由客户端、数据管理、数据存储和系统管理4个部分组成,每部分分别对应各自的微服务单元。每个微服务单元可以部署多个实例注册到Eureka上,通过Feign互相调用,每个微服务单元专注自己业务互不影响,使得存储平台变得高内聚和低耦合,提升了平台的扩展性和可维护性。
客户端服务用来实现客户与平台的数据存储交互,只要经过授权的用户都可以进入云存储平台,它包括用户注册、用户登录、用户鉴权等功能。
数据管理服务是客户端和云存储之间的交互介质,对上负责接收客户端的请求,对下衔接数据存储,对数据进行相应的转换处理,其中具体包括农业数据文件的查看、上传、下载、删除、分享等功能。
数据存储服务是云存储的基础,是农业数据存储的具体介质,包含设备管理、状态监控、升级维护等功能。
系统管理服务是对用户及其权限管理和日志管理的设置,是其他功能模块运行的基础。主要包括用户管理、权限管理和日志管理。
农业数据云存储平台整体页面使用Bootstrap前端框架搭建而成。使用spring security完成对用户的认证、授权和非法攻击防护,确保用户输入正确的用户名和密码后才能进入平台进行相关操作,登陆平台首页面,侧边菜单栏可以直观地展示出该平台不同权限的用户所看到的业务功能模块,用户可点击菜单栏就可进入子菜单进行更详细的功能操作。
2.5 性能测试与分析
对本文所设计的云存储平台与Mysql这种通用存储管理系统进行相关测试,对比两者在存储农业数据时性能上的差异。本实验所选取的环境是由Hadoop集群和Mysql数据库管理系统组成。Hadoop集群由4个服务器节点组成,其中1个节点为Master主节点,另外3个节点为slave数据节点。通过国家农业科学数据中心,获取实验中的46 775个数据资源。应用分布式存储方法将这些实验对象存入Hadoop集群中,同时将相同的实验数据文件以longblob类型的形式存储到Mysql数据库中。
在实验过程中,通过不同数量用户并发访问上述2种存储方式,计算读取数据耗时的差异,进而分析上述2种存储方式的性能区别。本实验各组所耗费时间是基于多次实验耗时结果所得的平均值,如图4为实验所得的结果。
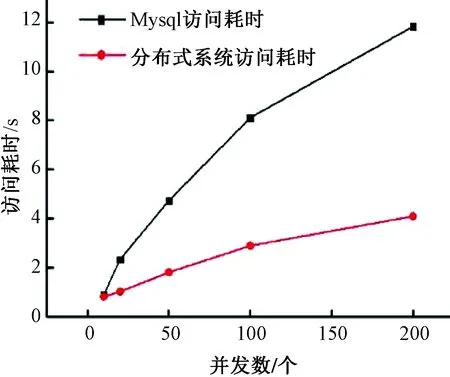
图4 访问耗时与并发数的关系
通过访问耗时与并发数的关系结果图可以看出,随着用户访问并发数的增加,分布式存储访问耗时与Mysql存储访问耗时的差距逐渐增大,说明在高并发的情况下,分布式存储中数据访问性能要优于Mysql数据存储访问性能,从而说明本文所提出的基于微服务架构的分布式数据存储方法可满足海量农业数据的存储和管理。
3 小结与讨论
目前,农业信息化是我国农业生产发展的战略化目标,对农业的生产和发展起着至关重要的作用[19-20]。然而我国农业数据具有种类繁多、数量庞大及数据结构复杂等特点。传统单体架构面对复杂业务时可维护性和可扩展性较差以及并发性不足等问题,使得海量农业数据存储过程中出现能力不足和管理困难等问题。
本研究创新性地将微服务与Hadoop技术结合,设计出一种基于SpringCloud微服务架构的农业数据云存储平台。在这个平台中,通过Hadoop分布式集群实现农业数据的海量存储,同时SpringCloud微服务架构提升了系统可扩展性、容错性,以及开发和维护效率。系统测试结果表明,所构建的云存储平台性能稳定,能满足海量农业数据的存储,为农业信息化的发展提供一定的参考价值。
