Python数据处理在“侵犯公民信息”案司法取证中的运用研究
2022-03-30金波
金波
中浦鉴云(上海)信息技术有限公司司法鉴定所 上海 200080
1 “侵犯公民信息”案司法取证常规方法及使用Python数据处理的意义
近年来随着手机及互联网技术普及运用,海量信息唾手可得。为有效保护公民隐私、保障金融环境健康运行,银行账号、电子支付、网上交易等与居民息息相关的日常事务均采用了以手机号和身份证号等具有唯一性特征的公民信息进行实名认证[1]。同时,倒卖公民信息,用以实施诈骗、洗钱等违法犯罪活动也层出不穷。在“侵犯公民信息”类案件的司法诉讼过程中,需要对涉案检材中的公民信息的数量进行统计排重,以检测检材中具有多少不重复的公民信息作为定罪量刑提供有效依据。
此类案件的数据处理通常是在各表格栏位格式一致的情况下对检材中含有公民信息的数据表格进行合并,再对身份证号或手机号进行统计排重。传统处理方法是以Excel为工具对表格进行手工处理,表格数量稍大则利用“方方格子”等插件进行半自动化处理。由于Excel效率低下、且不能超过百万行的局限,遇到巨量数据时,则须将表格导入到关系型数据库,再以结构化查询语言进行统计[2]。
本文通过实例,阐述了在处理大量的栏位格式不一致的电子表格的情况下,克服手工处理的弊端,解决Excel和传统关系型数据库处理能力的瓶颈,运用Python数据处理模块高效、精准地解决公民信息统计排重的难题。
2 使用Python数据处理所使用的材料与处理步骤
2.1 检材
含有公民信息清单的Excel文件共12555个,总大小约为2.2GB。
2.2 检测设备
2.2.1 硬件:PC 1台:CPU Intel i9 8核心,内存 32G,硬盘500G SSD
2.2.2 软件。
2.2.2.1 操作系统:Windows 10 专业版 20H1。
2.2.2.2 Python 3.8:含模块os,datetime,xlrd,re,pandas。
2.3 处理步骤
2.3.1 利用os模块遍历检材中含有Excel文件的目录树,并记录其中每个文件名。
2.3.2 利用xlrd模块读取每个Excel文件中所有工作表的内容,对其中的每一行数据以字符串“::”作为分隔标识进行横向合并,合并结果定义为源数据行的特征字符串字段,全部结果行合并写入一个文本文件中。
2.3.3 利用Python中list和set两种数据类型,对合并结果的文本文件中的特征字符串字段进行初步排重,先将所有特征字符串读入list中,再对其以set进行处理,处理后每一行都是唯一的,重复的特征字符串只保留一行,以提高后续处理的效率[3]。
2.3.4 利用re模块,编辑正则表达式对初步排重结果中的特征字符串进行判断,按定义规则识别手机号和身份证号,并将其单独提取为号码字段,分别按身份证号和手机号保存为两个含格式的文本文件。文件中每行的格式为:列1.号码字段;列2.特征字符串。若在同一特征字符串中提取到多个手机号或身份证号,则对应分为多行,每行中只保存其中一个号码。
2.3.5 在pandas模块的dataframe类中,使用drop_duplicates方法对识别到的号码进行统计排重,对重复号码只取排在最先的一行。
3 异常情况的处理思路及核心代码展示和处理结果
3.1 观察到的异常情况
3.1.1 损坏且无法打开的Excel文件。检验过程中提取恢复到检材中所有的xls和xlsx文件均被识别为Excel文件,但其中部分以“$”开头的文件名为恢复到的因打开Excel文件而产生的临时缓存文件,在非正常退出时未被及时清除,通常此类文件无法打开,因此记录在日志文件中,以便进一步追溯核实[4]。
3.1.2 公民信息记录特征-格式。
3.1.2.1 邮政、快递的收发信息。格式:发货人姓名、电话、地址、发货时间、收货人姓名、电话、地址。
3.1.2.2 客户服务系统实名认证的通讯录。格式:姓名,证件号,电话号1,电话号2,电话号3……(电话号数量不一)。
3.1.2.3 银行系统的客户实名信息。格式:姓名,电话号,证件号。
3.1.2.4 政府机构通讯录。格式:省,市,区县镇,机构名称,负责人及联系电话(合并在同一单元格)。
3.1.2.5 金融系统的核销记录。格式:姓名、委托批次、手别、本月任务类型、账户类型、账户分包、来源、城市、单位电话号码、性别、住宅电话、手机号码……(多达150余列)。
3.1.3 公民信息记录特征-异常情况。
3.1.3.1 在一个单元格中填塞入整个通讯录名单。因此需将该单元格中的内容处理为多行数据,而非粗暴的合并为1行。
3.1.3.2 由于Excel会将18位身份证号当作数字处理,由于限制,前15位数字可正常显示,后3位会被处理为000,因此有些单元格会在身份证号前加“‘”号,强制将单元格当作文本格式处理。有些手机号被当成浮点数处理,例如:19990909555.0,保留小数点后n位的数字形式。因此区分“‘”和“.”符号也需纳入考虑。
3.1.3.3 容易混淆的身份证号为手机号的情况。例:身份证号31010219990909555X,其中19990909555易被误识别为手机号。因此不能将该号码既识别为身份证号,又识别为手机号。
3.2 公民信息的定义及作业思路
唯一性是定义的核心。身份证号人手一份且只有一份,与他人不重复,是最佳的界定唯一性的特征[5]。其次为手机号,手机号也不重复,注册时需与身份证挂钩,已被纳入实名认证的特征之一,缺点是一人可以有多个号码,可做参考。为避免同名同姓的发生概率高,以及同一住址可能会有多人居住的情况,因此姓名、地址不宜作为唯一性的特征用以区别。
因此,以身份证号(手机号为参考)区分唯一性。将所有数据的每一行合并为保留分隔形式的特征字符串,在特征字符串中识别提取符合身份证号(手机号)特征的号码,最后对所有提取到的号码进行排序去重。
3.3 特征识别的规则及正则表达式
3.3.1 身份证号。18位身份证号生成规则由国标GB 11643-1999《公民身份号码》定义,由一系列特征码组合而成,前17位数字为本体码和最后1位则是校验码。本体码依照先后次序为:6位地址码,由各省市地方的标准代码转换而来;8位出生日期码,分别为年份4位月份2位和日期2位;3位序列编码,其含义为出生当日的出生顺序及性别;1位校验码,由前17位通过一定算法计算而来的,校验码为0…9和X共11种。18位和15位的共同特征是:在特定位置有6位日期码,分别为年年月月日日,其长度是固定的。
3.3.2 身份证号码特征识别的正则表达式。正则表达式:(?
该表达式用来识别18身份证号,即:18位连续数字或17位连续数字后跟X,第7位起为2位世纪号18、19或20,后跟2位任意数字,第11位起为2位月份即01-12,第13位起为日期即01-31。以零宽断言(?
3.3.3 手机号。手机号编码相对较为简单,其特征为11位连续数字,第一位为数字1,第二位为3-9的任一数字,不可为0、1、2。但手机号前有时会被加上86以区分国别,或加0作为长途拨号的便捷方式,因此需加以考虑和区分。
3.3.4 手机号码特征识别的正则表达式。正则表达式:(?
该表达式用来识别11位手机号,即:开头可以为86或0,后跟11位数字,其中第一位为1,第二位为3-9的任一数字,后跟9位任意数字。以零宽断言(?
3.4 Python的运用
3.4.1 Python的优点。其次,Python开发语言的执行效率虽并不在最理想状态,但可以看到因为通过lists和sets等数据变量处理数据,Python进程会占用到5-10G的内存,在硬件内存充足的情况下,统计排序去重等操作均在内存中完成。这避免了关系型数据库为提高Cache Hit Rate减少磁盘读写而做的各种复杂的参数调整工作。
3.4.2 os模块。os模块用来遍历检材中含有Excel文件的目录树,并记录其中每个文件名。代码如下:


3.4.4 lists和sets数据类型。python中有lists(列表)和sets(集合)两种数据类型,其表现形式均由元素组成的清单,list以[]形式表示,而sets以()表示,以“,”分隔的元素。但sets与lists不同的是,list的元素可以重复,而sets不可以。通过set()方法将List的内容去重,转换为set。代码如下:

3.4.5 re模块。re模块用来使用正则表达式在对象字符串中识别提取符合正则模式的内容。此处理步骤为检验检测工作的核心。代码如下:


3.4.6 pandas模块。在pandas模块的dataframe类中,通过使用drop_duplicates方法对“号码,特征字符串”中的号码字段进行排重,同时保留第一行特征字符串。代码如下:

3.5 检验检测结果
在检验设备硬件上,对检材中含有公民信息清单的12,555个Excel文件应用上述代码功能进行统计排重,检验检测到可读取的Excel文件11,202个,无法读取的为1,353个。在可读取的Excel文件中,检测到10,121,012条记录,经统计排重后获得手机号2,230,034条,身份证号2,338,503条。检验检测过程总时长为14分钟。经抽样核对,精确度达到99.99%。
相比之下,若按平均每个文件花5min的人工处理时间,由1人处理,需要56010min(近131个工作日),且无法保障结果的精确度。对比情况见下表:
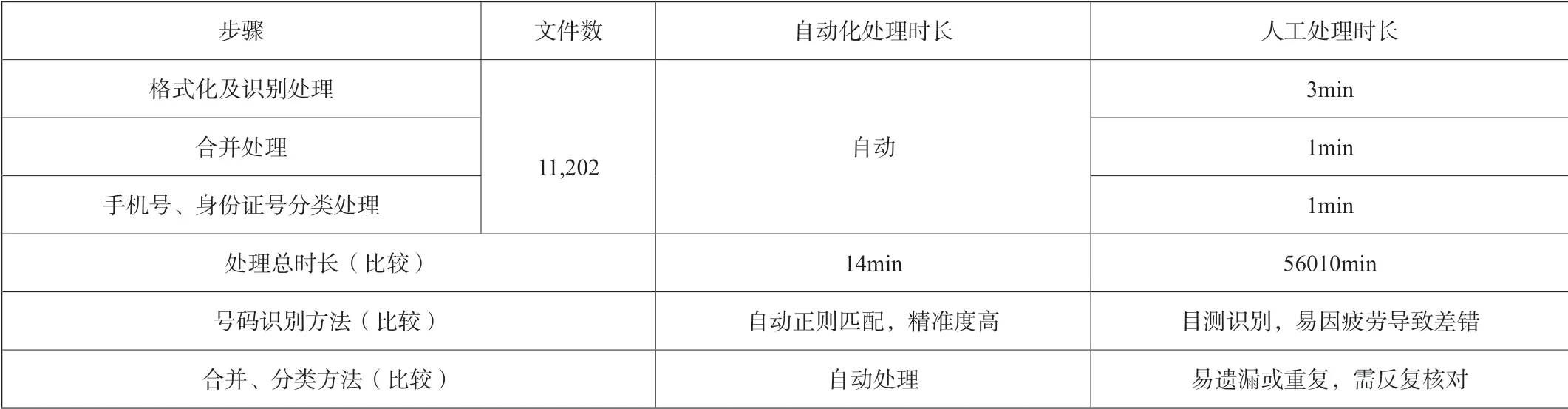
表1 python数据处理与人工处理的对比
4 结束语
综上所述,本文通过研究Python编程语言中数据结构及模块应用的特点,结合对巨量涉及公民信息的Excel工作簿文件中记录特征的观察,在对公民信息统计去重的司法鉴定工作实践中,编写代码,建立了一套高效准确的合并、识别、统计、去重的方法,摆脱了对巨量Excel工作表进行人工处理的繁重劳动,为法庭科学提供了科学客观且有效的证据,可为相关司法鉴定实践提供参考。
