基于JavaCC的抽象语法树生成错误处理技术研究
2022-03-30王国隆金大海宫云战
王国隆,金大海, 宫云战
(北京邮电大学 网络与交换技术国家重点实验室,北京 100876)
0 引言
为保障计算机软件质量,应尽早进行软件测试,而软件测试的重要手段之一就是静态测试[1-5]。随着C++语言标准11/14/17的不断演进,新标准对C++语法进行了诸多补充和优化,同时也带来了许多扩充的新特性[6]。随着C++新标准在市场上大面积的普及应用,对支持C++新标准的静态测试也显得尤为重要。
目前存在很多用于C++静态测试的工具,如Cpplint[7],PMD[8],Cppcheck[9]等。在这些静态测试工具中都必须对代码解析。抽象语法树是对代码的一种重要的中间表示形式,也是一个对代码进行静态测试的不可或缺的数据结构,在代码测试分析领域有着广泛的应用[10]。
目前存在的很多用于C++语言的词法语法分析工具,如JavaCC[11],ANTLR[12],LEX/YACC[13]等不能完全支持C++新标准的某些特性。而文中采用错误处理技术,较好地解决了这个问题,它可以确保对抽象语法树生成出现错误的地方采取对应的策略进行错误处理并完成抽象语法树的创建。在本文中,提出了一个针对抽象语法树生成的错误处理框架,用以解决抽象语法树生成错误问题。
1 相关工作
在词法语法分析工具方面,彭虎臣[14]以LEX作为词法分析器,读入字符串后根据词法规则,将单词或者字符转换为token;采用YACC作为语法分析器,通过在符合BNF范式的语法规则中嵌入语法动作,之后搭建抽象语法树提取网页中CSS部分。Liu等[15]采用用户自定义的语法规则及词法规则,利用ANTLR来生成相应语法分析器及词法分析器的代码。之后,首先把输入的字符流,通过词法分析器转变为由token组成的流,然后利用语法分析器的输出获得最后的抽象语法树进行Scratch语言的特征提取和检测。黄松等[10]使用纯Java代码编写的免费编译工具JavaCC,经过用户自定义的词法语法规则文件jjt生成抽象语法树。肖一飞[16]提出一种基于JavaCC的通用的缺陷检测预处理方法,通过修改jjt规则文件对不同类型的词法异常和语法异常进行支持解决。孟春辰[17]提出一种基于JavaCC的中间文件化简的方式,通过保留一些类型定义信息从而避免了对头文件中导致静态分析失败的复杂语法结构的分析。本文鉴于JavaCC的易用性以及平台无关性等优势继续使用JavaCC作为抽象语法树的生成工具。
但是,JavaCC也有缺点。JavaCC遇到语法错误或者不匹配的语法时,仅仅会报告第一处错误并停止分析。也就意味着,对于代码的抽象语法树生成错误且不完整,所以需要对此进行错误处理。
对于错误处理方面,罗海丽[18]提出抛弃输入记号直到某个定界符,JavaCC默认的错误处理就是使用了跳过字符到指定符号的方式,但是这种抛弃可能会引入更多的错误;郝丽波等[19]提出受到最大重复次数约束的可重试的错误处理策略,但是对于JavaCC来说不做出改动每次生成结果都是一样;Jia等[20]提出了可替换的对输入做局部修改的错误处理策略,但是很难猜测符合意愿的替代方式;曾祥文[21]提出了一种可以回退K个的分析器,使用两个分析栈,一个栈负责将新单词压入栈,另一个栈负责维护K个单词,相当于对K个单词的窗口进行修复。由于无法预测出错的常见形式和替换方式,本文使用跳过符号的方式进行错误处理。
现有的词法语法分析工具对C++新标准支持的不多,一些研究人员是面向C++98标准构造抽象语法树并进行分析,与他们工作不同的是,本文是面向C++新标准生成抽象语法树并对生成错误进行处理,此方法既可应对不支持或者不匹配的语法片段,也可应对C++日后的语法更新。
2 抽象语法树生成错误分析
2.1 抽象语法树生成错误原因
抽象语法树(AST,abstract syntax tree)是以树状的形式表达源代码语法结构的一种表现形式[17],用T=
抽象语法树生成过程如图1所示。
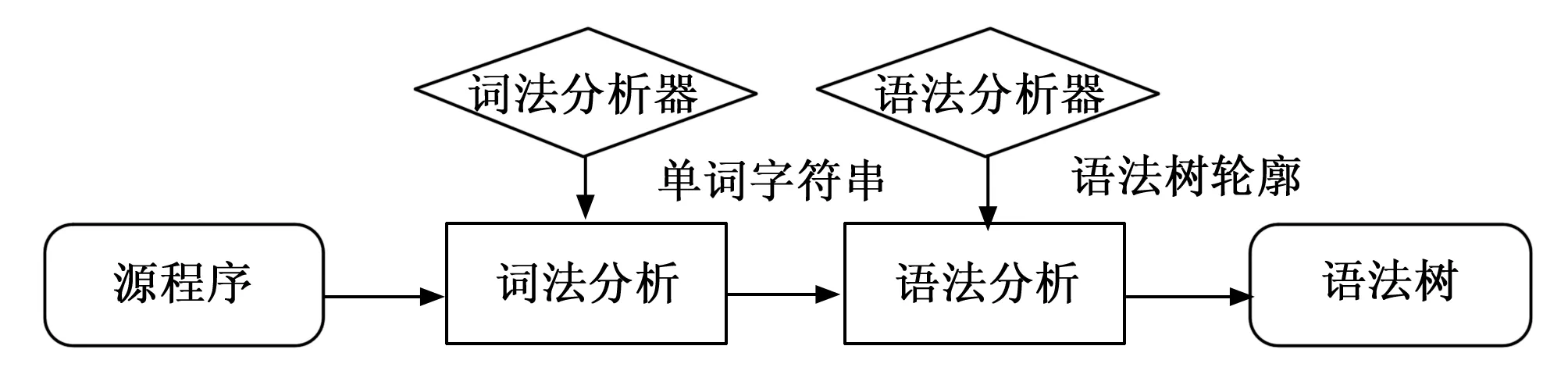
图1 语法树生成过程示意图
源程序经过词法分析和语法分析生成抽象语法树。BNF(Backus-Naur Form)是描述编程语言的文法。词法分析和语法分析[22]根据对应的符合BNF范式的规则文件生成对应的语法树节点组成语法树。词法分析错误可以通过在规则文件中添加新token来支持,语法分析则需要针对语法逻辑对规则文件进行修改。现有的规则文件可以较好地支持C++98标准和C++14标准的绝大部分语法和特性,但是针对语法逻辑修改的规则文件不能做到对不断迭代的C++新标准的完全支持,进而就会产生语法树生成错误。
2.2 语法规则文件不能完全支持的原因分析
语法规则文件不能完全支持C++新标准的原因主要有以下3点:
2.2.1 C++新标准BNF范式无法获取
官方的C++新标准的BNF范式文档无法获取,并且网上存在的新标准BNF范式各有出入,无法确定是否和官方一致。如果范式文档选择出现问题,会对后续分析处理产生重大影响。
2.2.2 C++新标准语法结构变化大
C++新标准语法更改中,提出了新的语法结构,新的功能,在新关键字的配合之下或不需要新的关键字,在原有关键字的基础之上,提出新的结构,完成新的功能。这主要目的是为了更加方便地实现相应的功能。以语法树中statement节点的语法结构的变化为例,如图2所示。
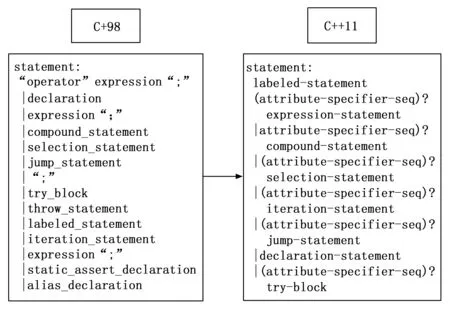
图2 C++新标准语法结构变化示例
标准更新后出现更多的是语法结构的变化,有些结构是在原有结构的基础之上进行扩展,这种在构建抽象语法树的时候相对容易进行更改,但是很多结构的更改是在推翻原有结构的基础上进行重新架构(如图2),同时还会糅合其他新的结构进来,层层嵌套。这种在破坏原有结构的基础上进行的更改在构建抽象语法树时相对困难。
由于破坏原有的语法结构,所以在修改抽象语法树规则文件时,也需要对相应结构进行破坏,这样无法保证在破坏现有结构后仍然可以对原有结构进行支撑,这是较难的问题。对于这种问题,一方面对新的语法尽量修改规则文件进行支撑,无法支撑的语法需要通过错误处理技术进行处理。
2.2.3 C++新标准核心库变更大
C++新标准的库更乐于使用复杂的嵌套结构和模板类来对相关代码进行声明,所以结构变得相对复杂,而之前的C++98的库更多的是使用直接声明的方法。例如C++98和C++11核心库iostream的变化如图3所示。
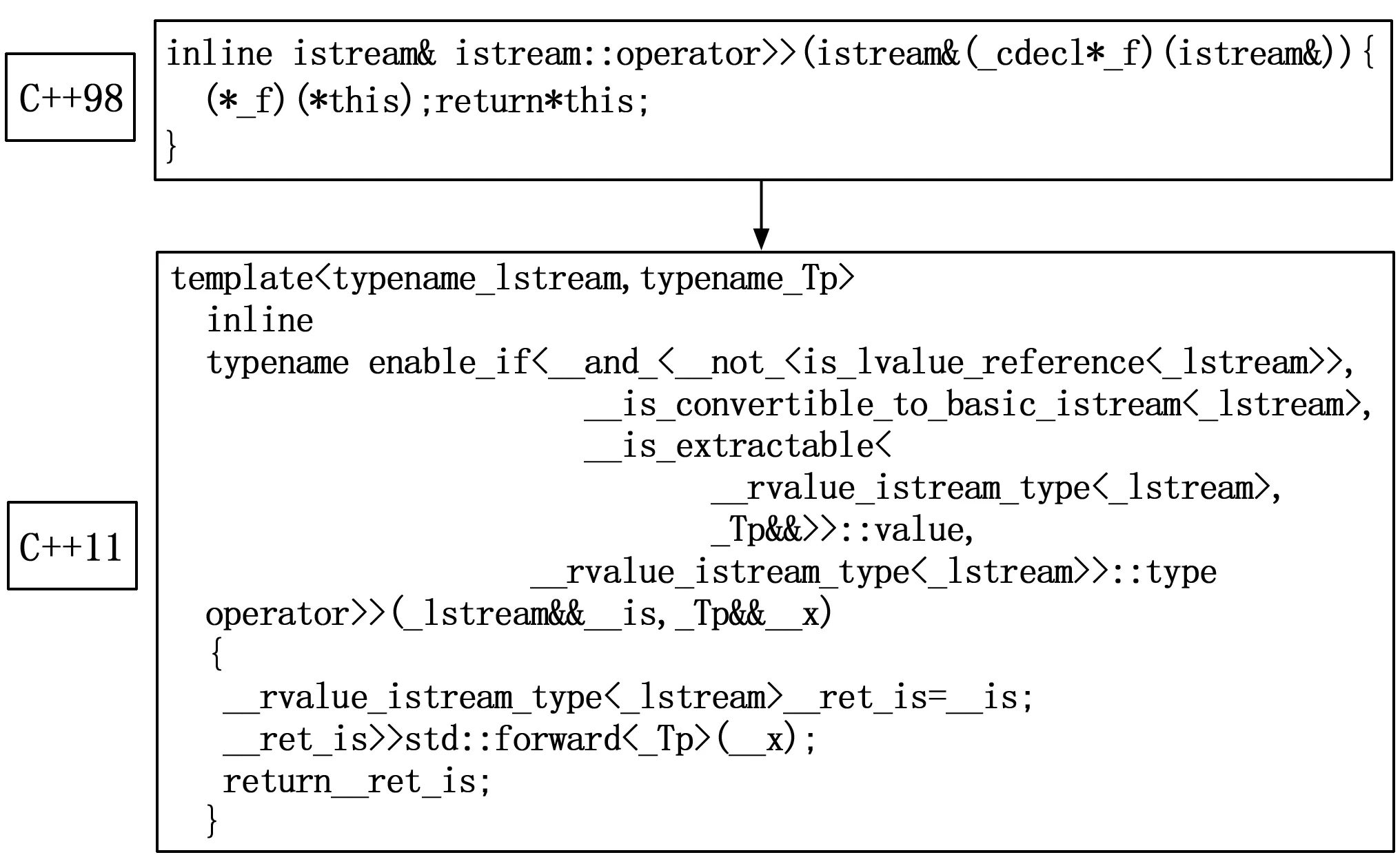
图3 C++新标准核心库变化示例
可以看出,新标准的库文件结构变得异常复杂。因此,C++98的库文件内容更加容易被抽象语法树支撑。由于测试时,为了获取到更全面的分析数据,会将全部的头文件进行展开,以获取到更多的信息来分析,获取分析结果。但是目前来说,在极度复杂的库文件的情况之下,很难做到对头文件的完全支撑。相反地,用户所写源文件的结构相对简单,不会大量使用复杂的结构,更加容易进行语法的支撑。所以建立抽象语法树时,构建的主体应为源文件,要做到不丢失源码信息。
综上,在对C++新标准的语法逻辑做到最大可能的支撑的基础上,对于还不支持的会导致语法树生成错误的语法要进行错误处理。因为错误会导致语法树生成中断,错误点之后的源代码不能生成相关的语法树节点,导致对应源文件的语法树不完整,从而影响后续静态分析。所以本文重点讨论在语法树生成中跳过不支持或不匹配的语法片段的错误处理技术。
3 针对抽象语法树生成的错误处理框架
对于语法树生成失败的源文件,希望通过错误处理技术可以继续生成语法树并且保证语法树尽量完整,也由此本文提出了针对抽象语法树生成的错误处理框架,框架设计如图4所示。

图4 抽象语法树生成错误处理框架
首先,源代码经过预处理后生成中间文件。之后是一个迭代的过程,如果中间文件生成抽象语法树成功,直接结束;如果抽象语法树生成错误,则需要根据报错行数跳过附近语法片段以此继续生成抽象语法树直至成功。
3.1 预处理
中间文件(intermediate file)是在分析C++程序时使用编译器对源代码进行预处理后生成的文件,以方便进行后续分析。
先要对C++源文件进行预处理,预处理是通过编译器进行的,包括一些宏替换,条件编译以及头文件展开等操作。正是因为需要上述操作,所以不能使用.cpp文件直接进行处理,需要使用预处理后生成的中间文件.i进一步生成抽象语法树。
3.2 语法树生成错误处理
中间文件经过词法和语法规则文件生成抽象语法树,如果成功生成,当前文件分析完成;如果生成出错,那么接下来进入语法树生成错误处理流程。
α1α2…αn=w1αiw2
(1)
式中,w1为已经分析并且生成语法树节点的部分;αi为当前分析的token;w2为当前文件剩余的token流。
假定分析到αi生成语法树时发生错误,因为分析是自上而下的,那就意味着当前已经建立了部分语法树,并且已经生成的语法树已经涵盖了w1,但是语法树却无法继续生成以涵盖w2。此时,就必须应用错误处理技术来继续生成语法树。可采取的措施如下:
1)删除当前tokenαi并继续分析;
2)于w1和αi之间插进终结符号α,从而把式(1)改写成式(2):
α1α2…αn=w1ααiw2
(2)
然后再从αi开始分析;
Lakoff提出的意象图式(image schema)是人们理解和认知事物的基本结构和组织形式,也是概念范畴内的原型结构[4]。由于人体本身就属于空间概念范畴,所以基本的意象图式就是空间图式,凡是涉及到空间结构的概念都是以意象图式认知模式储存在大脑中。at表示空间概念范畴是基于路径意象图式基础的,如图1:
3)从w1的尾部删去若干个token后继续分析。
上述措施可以单独使用也可以结合使用,其中措施(2)直接添加终结符可能会导致程序不能正常编译。这里可以结合措施(1)和(3)进行错误处理,多次使用措施1并结合措施3进行处理相当于在式(1)中从w1的尾部删除若干个token并且在w2的首部删除若干个token,即把式(1)修改为式(3):
α1…αi-p…αi…αi+qα2…αn=w0Uw3
(3)
式中,
U=αi-p…αi…αi+q
(4)
如果这样的U存在,就删除或注释Uu后继续分析。
基于以上措施,对于每一个cpp文件,先不考虑源代码中引用的头文件,只对纯源代码部分生成抽象语法树。如果在这个过程中出现异常,解决措施是不考虑报错行数附近的函数区间,继续分析其他可以正常生成抽象语法树的部分。
解决办法是,从完整的中间文件中分离出源程序部分,根据这部分用户写的源代码生成抽象语法树,如果发生异常,通过报错行数和函数区间标识算法略过附近函数区间后重新生成语法树直至成功。
模块流程设计如图5所示。
如图5所示,新语法错误处理模块可以分为3个部分:1)源程序分离;2)文件内函数区间划分;3)注释报错区间迭代生成抽象语法树。
3.2.1 源程序分离
在完整的中间文件中,有用户写的源代码部分,也有头文件展开的部分,这里先不考虑头文件展开部分,只对源程序生成抽象语法树。所以,需要从完整的中间文件中得到源程序部分。
中间文件片段以及预期分离效果如图6所示。

图6 中间文件片段以及预期分离效果
孟春辰[17]根据“# 行号 文件存放路径”从后向前遍历,直到遇到文件后缀.h就结束遍历。但是对于图6代码,在源程序中还插入了一些扩展进来的头文件部分,之前的算法不能准确截取出源程序部分,所以提出了算法1所示的通用的源程序分离算法。
算法1:源程序分离算法
输入:源文件名fileName,完整中间文件content;
输出:只包含源程序部分的中间文件result。
index ← 0
isSourceLine ← false
rightPattern← "#s(d+)s”(.*)" + fileName + "”s(d+)"
falsePattern ←"#s(d+)s”(.*)”s(d+)"
while index < content.size() do
if line matches rightPattern do
index++
isSourceLine ←true
continue
end if
if line matches falsePattern do
isSourceLine ←false
end if
if isSourceLine do
result.add(line)
end if
index++
end while
return result
算法描述:算法从上向下扫描,通过两种正则表达式进行识别,一种表示含有源文件后缀的文件提示信息,另一种表示普通的文件提示信息,并且通过一个布尔值标识当前行是否加入结果集中,最后返回源程序部分代码。
3.2.2 文件内区间划分
对上述中间文件分离出的源程序部分生成语法树,如果发生错误,就需要根据报错行数注释相应的区间,所以接下来就需要对中间文件进行区间划分。
定义1:函数区间:函数区间是文件内用来标识一个函数名称和范围的结构,该结构由一个三元组表示,该结构描述记为I={Name,StartLine,EndLine},其中:
Name:表示该函数区间的函数名称;
StartLine:表示该函数区间的起始行数;
EndLine:表示该函数区间的终止行数。
文件内区间划分分为两部分:第一部分是函数区间的标识,第二部分是函数区间优化。
1)函数区间标识算法:函数区间标识算法通过状态机来实现,定义11种状态,利用互相的转化关系求出函数范围。状态机转化关系如表1所示。

表1 函数区间标识状态机转化关系
主要算法是在函数头结束状态中遇到{和}的处理逻辑,具体的算法如算法2所示。
算法2: 函数区间标识算法
输入:文件路径path;
输出:函数划分后起始行结束行的集合list。
switch state do
……
case 7 do
if 3=lastState and 6=lastState then
startLine ←line /*lastState表示当前状态的上一个状态*/
end if
if c ='{' then
bracket ←bracket + 1 /*bracket表示大括号的个数*/
end if
if c ='}' then
bracket← bracket - 1
end if
if 0 =bracket then
endLine← line + 1
list.add(startLine, endLine) /*list是保存起始行和结束行的集合*/
end if
……
end switch
算法描述:查看状态机中的状态,状态7表示函数体开始,如果从成员变量初始化列表状态(状态3)或者从函数头结束状态(状态6)转换而来,需要记录函数开始行数startLine.bracket表示括号个数,当前字符c如果是{符号需要增加括号个数,如果是}需要减少括号个数,如果括号个数减为0,则当前函数结束,记录相应的结束行数endLine,随后加入到函数划分的集合中。
2)函数区间优化算法:对于区间划分后的文件中,会存在部分没有在任何区间中的代码行需要进一步被划分到现有区间中,区间划分后剩余部分如图7所示。
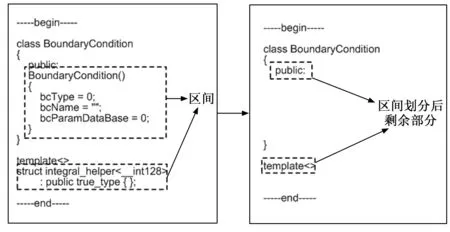
图7 区间划分后剩余部分
可以看出,例如“public:”“”等剩余行需要进一步划分进现有区间中,否则如果注释掉当前区间后这些行会残留导致语法树生成不精确。除此之外,还有换行函数头的剩余部分也是通过类似的区间优化算法进行进一步划分。函数区间优化算法如算法3。
算法3:函数区间优化算法
输入:划分区间funcList,文件内容content;
输出:经过区间优化的区间funcList。
pattern← " #s(d+)s”(.*)”s(d+)"
foreach func in funcList do
startLine ←func.startLine
while startLine > 1 do
behindLine ←content.get(startLine -2)
if behindLine.trim().length()=0 then
startLine--
continue
end if
if lastChar =';' || lastChar ='{' || lastChar ='}' then
break
else if Pattern.matches(pattern, behindLine) then
break
else
startLine--
end if
end while
func.startLine← startLine
end foreach
算法描述: 从当前区间向上扩展,如果上面的行是以“;”或者“{”或者“}”结尾的,或者遇到形如“# 577 "C:/Program Files/stl_multimap.h" 3”的标识文件名称的行就停止扩展,最后返回优化后的区间。
3.2.3 注释迭代生成语法树
生成语法树的报错信息可由定义4进行描述:
定义2:语法树错误信息特征:语法树错误信息特征是用于对一个语法树报错信息进行特征描述的结构,该结构由一个三元组进行表示,语法树错误信息E的特征记为:E={ErrorLine,Tokenlmage,TokenKind},其中:
ErrorLine:表示产生错误信息的中间文件行数;
TokenImage:表示产生错误信息的token名称;
TokenKind:表示产生错误信息的token种类。
一次迭代可以通过语法树错误信息特征中的ErrorLine去之前划分的区间中查找对应区间并注释,再继续生成抽象语法树。从语法树角度来看,注释相当于从当前节点开始向上删除部分节点后继续向下生成语法树,如图8描述。
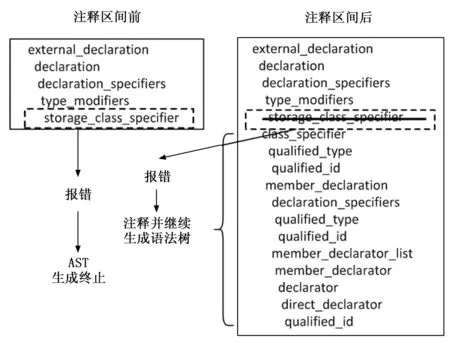
图8 注释区间前后语法树效果示意图
图8表示的是一次迭代的效果,注释区间之后重新生成语法树,如果还是失败继续根据ErrorLine注释区间直到成功生成为止。
注释并迭代生成抽象语法树的具体算法如算法4所示。
算法4:注释迭代生成语法树算法
输入:文件路径path;
输出:成功生成的抽象语法树根结点astroot。
flag ←true/*语法树生成成败的标志*/
try:
astRoot← createAST(path)
catch Exception e:/*生成语法树失败*/
flag ←false
errorLine ←e.getBeginFileLine()/*记录错误行号*/
if !flag then
funcList ←funcDivide(path)/*调用函数划分算法*/
end if
while !flag do
commentFunc(errorLine)/*注释出错函数区间*/
try:
astRoot ←createAST(path)
flag ←true
catch Exception e:
errorLine← e.getBeginFileLine()
算法描述:通过flag记录生成语法树是否成功,成功后跳出循环。通过errorLine记录具体生成语法树错误的行数。如果生成抽象语法树异常,根据报错的行数到文件内划分的区间中寻找对应区间并注释代码,之后重新生成抽象语法树,并迭代直至成功生成语法树。
4 实验及实验结果分析
本文提出了一种针对抽象语法树生成的错误处理框架并进行了实现。为了对此框架构建抽象语法树的完成度和错误处理效果进行验证,本文选取了应用C++新标准的5个开源工程利用本文开发的工具进行抽象语法树的生成对比实验。选取的测试工程如表2所示。

表2 选取的测试工程列表
4.1 抽象语法树完成率
由于JavaCC自上而下的分析特性,在遇到语法不匹配的时候报错就结束了当前文件的分析,也就是报错行后的源代码并没有生成语法树节点,也就丢失了源代码信息。
假设开源工程中的源文件数量为totalNum,分析完整源代码后生成的抽象语法树数量为astNum,则本文定义完成率如式(5):

(5)
将表2中5个工程进行抽象语法树生成后结果如表3所示。
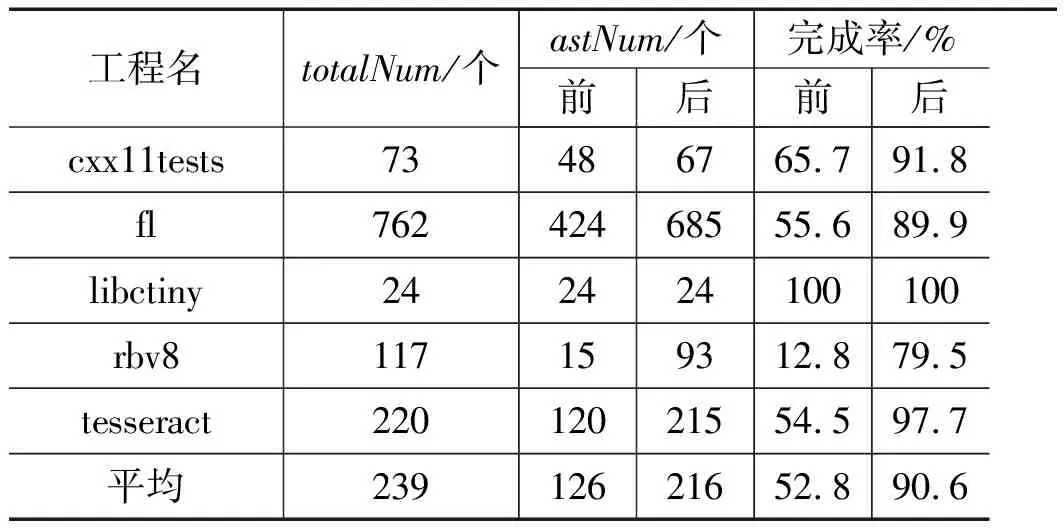
表3 使用错误处理框架前后语法树完成率对比结果
从表3可以看出使用错误处理框架后,超过90.6%源文件的抽象语法树都是分析完全部源代码后生成的,其余部分源文件的抽象语法树可以分析部分源代码后生成。同时,使用错误处理框架前语法树完成率为52.8%,使用错误处理框架后语法树完成率为90.6%,这里提高了37.8%完成率的原因主要是对于生成错误相关的代码区间进行注释,使得文件跳过错误后能继续生成语法树。
但是可以发现还是有9.4%源文件没有在分析完全部源代码的基础上生成语法树,主要原因是因为个别源文件区间划分的结果没有包含报错行数,所以导致根据报错行数无法注释对应区间导致无法跳过出错的语法片段进而无法继续生成语法树。
4.2 抽象语法树错误处理效果
以上部分对抽象语法树能否能在分析完源代码后生成进行了测试,下面利用错误处理策略前后生成的抽象语法树进行分析行数以及时间相关的对比,效果见表4。
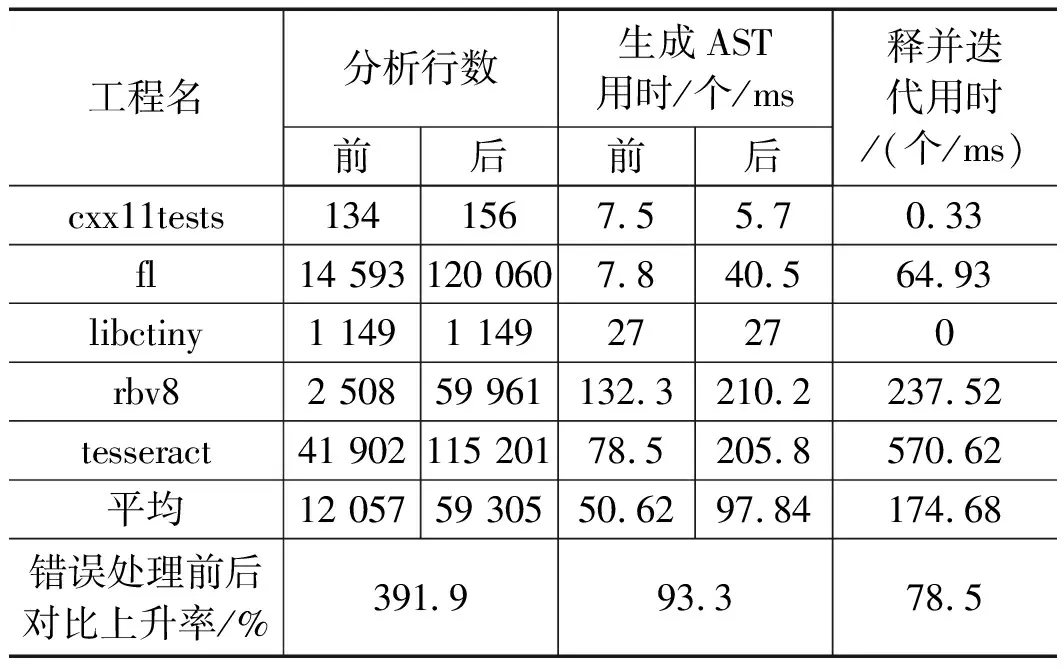
表4 使用错误处理框架前后分析行数及时间对比
表4对错误处理框架使用前后的抽象语法树生成用时,分析行数等方面进行了对比,并统计了注释迭代生成语法树的时间。经过错误处理后,单个文件语法树生成用时上升93.3%,分析行数上升391.9%,这是因为跳过出错的语法片段后,语法树生成不会因为报错而停止,而是继续分析,所以语法树更加完整,更多的代码也加入了分析。同时也伴随着额外78.5%的注释并迭代生成语法树的时间开销,但牺牲了时间却换取了更完整的抽象语法树和更全面的代码分析,这是非常值得的。
但是注释的部分代码可能含有符号类型信息,导致后续生成的符号表中可能含有未知类型,这对后续的分析可能造成影响。
5 结束语
本文提出一个针对抽象语法树生成错误的处理框架,通过注释报错行所在函数区间来跳过不支持或不匹配的语法片段的方式进行错误处理并迭代生成语法树,用于解决词法语法工具对C++新标准无法完全支撑的问题。实验结果表明,经过错误处理后语法树完成率较高,有较好的错误处理效果;由于迭代注释并重新生成语法树,会导致分析时间上升。但以上代价所带来的效果是更全面的代码分析,这具有重要的价值。本研究不仅可以应对不支持或不匹配的语法片段,还可以应对C++日后的语法更新。成功生成的抽象语法树可以应用于静态测试分析领域。在下一步的研究工作中,一方面可以改进函数区间标识算法,使得区间覆盖更加全面,另一方面可以优化注释区间范围,使得注释粒度更小影响更小,并通过这两个方面达到更好的错误处理效果;同时,如何提高错误处理效率也将是下一步研究的主要内容。
