基于Dueling DDQN的无人车换道决策模型
2022-03-26张鑫辰刘元盛谢龙洋
张鑫辰,张 军,刘元盛,谢龙洋
(1.北京联合大学北京市信息服务工程重点实验室,北京 100101;2.北京联合大学机器人学院,北京 100101)
0 引言
无人驾驶可以提高汽车的利用效率以及通行能力,同时也可以减少因驾驶员疲劳而导致的交通事故[1].而无人车的换道决策问题是无人驾驶中复杂且最具挑战性的问题之一[2-3].无人车的换道决策方法主要分为基于规则型和基于学习型的方法.
基于规则型的方法有Gipps[4]、CORSIM[5]模型等,这些模型的最终输出一般为换道或不换道的二元结果,而基于规则型换道决策方法的局限性在于难以覆盖所有工况,难以处理复杂道路场景.
随着无人驾驶决策技术的不断发展,对于无人车换道决策技术的研究逐渐由基于规则型的方法向学习型的方法转化.其中,学习型的决策方法分为基于机器学习和基于强化学习的方法.基于机器学习的常用方法有深度神经网络[6-7]、高斯和隐马尔可夫混合模型[8]、贝叶斯决策[9-10]、随机森林[11]、支持向量机[12]等,虽然这些方法与基于规则的模型相比可以在更多的道路场景中使用,但往往需要较为庞大的先验数据集作为训练集进行模型训练,同时这些模型在较复杂的道路驾驶场景中对突发情况的处理有所欠缺.
在基于强化学习的换道决策研究中,文献[13-15]提出了基于DQN(Deep Q Network)的换道决策模型,在高速公路场景下进行了建模.该方法与基于机器学习和基于规则换道模型相比,在面对道路突发情况的处理上有了较大的提升.但是基于DQN的换道模型中的目标网络存在着过估计的问题,这种问题的存在使得模型在选择动作时往往会得到次优的结果,同时模型会收敛到局部最优值,导致最终无法得到最优的换道决策策略.因此,本文建立基于竞争结构(Dueling Architecture)的双深度Q网络(Dueling Double Deep Q Network)算法的无人车换道决策模型,首先将无人车动作的选择和评估分别用不同的网络来实现,并将Q网络分为仅与状态S相关的价值函数(Value Function)部分和同时与状态S和动作A相关的优势函数(Advantage Function)部分.通过实验结果表明,该模型可以使无人车在较复杂的道路上以更高的速度行驶,通过与DQN以及DDQN模型对比,验证了提出模型的鲁棒性和合理性.
1 换道决策模型的构建
1.1 Dueling DDQN模型
Dueling DDQN算法在DDQN算法[16-17]的基础上加入竞争结构,将Q网络分为两部分,分别为价值函数和优势函数,即
(1)
其中:s为状态值,a为动作值,V(s;θ,β)为价值函数,A(s,a;θ,α)为优势函数,|A|为动作的个数,a′为所有可以采取的动作,θ为公共部分的网络参数,α和β分别为价值函数和优势函数各自的网络参数.
Dueling DDQN由两个结构相同网络参数不同的神经网络组成,分别为评估网络和目标网络.评估网络和目标网络的参数分别用θ和θ-表示,评估网络被用作估计无人车最佳动作价值函数的函数逼近器,即
Q(s,a;θ)≈Q*(s,a).
(2)
其中:Q*(s,a)为最佳动作价值函数.它定义当无人车处于状态s,采取某种动作a并遵循最佳策略π*时的最大期望值.将t时刻无人车的状态值st,采取的动作值at,从环境返回的奖励值rt,以及下一个t+1时刻的状态值st+1作为经验值et存储在记忆库Dt中用于训练评估网络,即:
et=(st,at,rt,st+1);
(3)
Dt={e1,e2,…,et}.
(4)
在第i次迭代时,评估网络首先从记忆库中抽取批量大小为M的序列,使用随机梯度下降的方法通过调整网络参数θi来最小化贝尔曼方程的误差,定义Li(θi)为第i次迭代的损失函数:
(5)
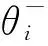
结合实验中采用的换道决策模型,整体的网络架构如图1所示.

图1 整体网络框架
1.2 基于Dueling DDQN的无人车换道决策模型构建
本文采用图1所示的网络框架构建无人车换道决策模型.无人车在行驶过程中的换道决策问题可以描述为马尔可夫决策过程(Markov Decision Process),该过程可由一组状态空间S,一组动作空间A,以及奖励函数R来具体描述.图2描述了无人车在行驶的过程中与环境进行交互的过程.

图2 无人车与环境交互过程
无人车在行驶过程中首先获取当前环境下的观测状态sp,然后无人车采取动作ap,获得奖励rp,经过1 s后,无人车进入下一个状态sp+1,其中p为当前回合的执行步数.重复上述迭代过程,直至一个回合结束.定义具体的状态空间、动作空间以及奖励函数如下:
状态空间定义:以无人车感知范围内最近的6辆环境车相对于无人车的距离和速度,以及无人车自身的速度作为状态空间,即
S={vego,s1,s2,…,s6}.
(6)
式中vego表示无人车的速度值,s1~s6表示环境车辆的状态值.其中s={exist,x,y,vx,vy},exist表示是否存在该车辆,若存在,exist=1,反之,exist=0.x表示环境车辆相对于无人车的横向位置,y表示环境车辆相对于无人车的纵向位置,vx表示环境车辆相对于无人车的横向速度,vy表示环境车辆相对于无人车的纵向速度.
动作空间定义为
A={left,right,keep,lower,faster}.
(7)
式中:left表示无人车向左换道,right表示无人车向右换道,keep表示无人车保持原车道行驶并保持速度不变,lower表示无人车保持原车道并以-1.25 m/s2的加速度减速行驶,faster表示无人车保持原车道同时以1.25 m/s2的加速度加速行驶.
奖励函数定义:为了避免强化学习中的稀疏奖励问题,同时使无人车可以学习到最佳的驾驶策略,设置奖励函数.
为使无人车避免碰撞,设置碰撞惩罚函数为
rp-collision=-1.
(8)
为防止无人车因避免碰撞而过于保守的行驶,设置速度奖励函数为
(9)
其中rhigh-velocity为速度奖励因子,设为0.25,vmax和vmin分别为无人车行驶时可达到的最高速度(30 m/s)和最低速度(20 m/s),vego为无人车的当前速度.
为避免无人车频繁的改变车道(无人车为避免碰撞而换道除外),设置换道惩罚函数为
rp-lanechange=-0.01.
(10)
若无人车在一个步长内未发生碰撞,设置单步奖励函数为
rp-step=0.01.
(11)
若无人车在整个回合行驶过程中未发生碰撞,设置成功奖励函数为
rsuccess=0.5.
(12)
故总奖励函数为
(13)
式中T为本回合执行总步数.
2 仿真环境搭建
2.1 仿真道路环境搭建
实验中选用高速场景为仿真实验场景.共分为4个主车道,仿真道路总长为800 m,高速公路仿真实验场景如图3所示,其他道路环境参数设定如表1所示.
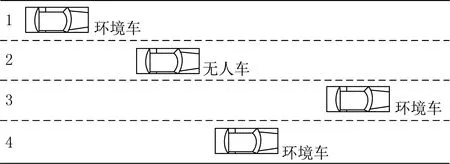
图3 实验场景示意图

表1 道路环境参数设定
2.2 仿真车辆环境搭建
采用IDM(Intelligent Driver Model)[18]对环境车辆纵向动力学进行仿真,环境车辆之间的状态关系满足:
(14)
(15)
其中:amax表示最大加速度,v表示车辆当前速度,vd表示期望速度,δ表示加速指数,Δv表示同车道当前车辆与前车的速度差,d*(v,Δv)为期望最小间距,d0表示最短车辆间距,T表示期望车头时距,b表示期望减速度.该模型可以模拟车辆的跟随行为,同时在高速公路上为车辆产生所需的加速度.
采用MOBIL(Minimizing Overall Braking Induced By Lane Change)[18]对环境车辆横向动力学进行仿真,环境车辆的加速度关系满足:
(16)
(17)
Δa>Δath.
(18)
实验中采用的主车道环境车辆最高速度为40 m/s,环境中车辆数为10辆,在车道1至车道4随机分配每辆环境车的位置,且车辆纵向初始间距为30 m.无人车的长度和宽度与环境车辆一致.假设无人车的感知范围为车辆前后距离各150 m,左右距离各8 m.其他仿真车辆环境参数如表2所示.

表2 仿真车辆环境参数设定
3 结果与分析
本文采用Python3.7搭建道路仿真环境,使用PyTorch搭建神经网络框架.仿真实验中训练和测试使用的计算机配置为Ubuntu16.04LTS系统,i7-8750H处理器,16 GB内存.设置训练最大回合数为20 000,单回合最大执行步数为20.假设车辆在实验过程中均保持在可行使区域内行驶.回合终止条件为无人车单回合执行步数达到最大或无人车在行驶过程中与环境车辆发生碰撞.实验中采用的网络参数如表3所示.

表3 Dueling DDQN网络参数设定
3.1 模型训练及结果分析
训练过程中主要研究在无人车进行换道决策时,是否可以根据周围车辆环境的变化做出应对的策略.定义若无人车在一个回合内未与环境车辆发生碰撞,即为一次成功.无人车在前i个回合获得的平均奖励定义为
(19)
其中Rt为在无人车第t个回合内获得的奖励值.
无人车在前i个回合获得的平均速度定义为
(20)
其中vt为在无人车第t个回合内获得的平均速度.
分别使用Dueling DDQN、 DDQN、DQN模型进行训练,且3种算法的网络参数、状态空间、动作空间、奖励函数均保持一致.通过分析换道决策成功率、模型得到的平均奖励以及无人车平均速度来描述模型训练的结果如图4—6所示.
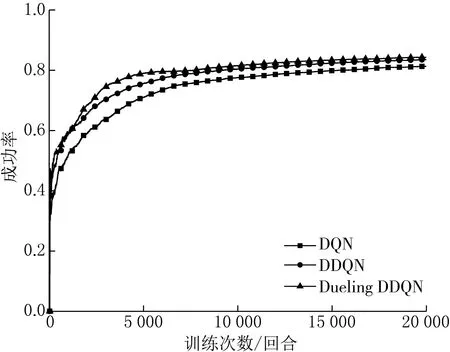
图4 训练过程中换道决策成功率对比 图5 训练过程中平均奖励值对比

图6 训练过程中平均速度对比
由图4可知,在训练开始阶段,3种模型的换道决策成功率均由0开始不断增加,随着训练回合数的增长,基于Dueling DDQN的换道模型成功率在训练5 000回合左右达到基本稳定,而DDQN和DQN算法在10 000回合左右达到基本稳定.在训练回合结束时,Dueling DDQN换道模型成功率最高,为84.39%,DDQN次之,为 83.59%,DQN最低,为 81.40%.
由图5—6,可知,在平均奖励方面,Dueling DDQN、DDQN、DQN分别在训练回合结束后获得4.47,4.37,4.28的平均奖励值.而在无人车平均速度方面,Dueling DDQN、 DDQN、 DQN分别在训练回合结束后可达到29.05,28.79以及28.77 m/s的平均速度.
综上所述,在模型的训练过程中,Dueling DDQN模型较DDQN和DQN相比可获得更高的平均奖励值,且在保持更高的换道成功率的前提下,提升了无人车的行驶速度.
3.2 模型测试及结果分析
在模型测试过程中,针对不同条件下的道路环境,通过改变环境车辆的横向模型(MOBIL)中的礼貌系数p、环境车辆初始间距以及环境车辆的数目来模拟不同车辆环境的道路场景,其他道路与车辆环境参数保持不变.其中礼貌系数p∈[0,1],p越小,说明环境车辆的驾驶风格越激进,环境车辆初始间距以及环境车辆的数目的变化用来模拟不同道路环境的车流密度.通过改变上述3个参数值来设置3个不同车辆环境的道路场景,分别使用Dueling DDQN、DDQN、DQN算法训练的模型在3个不同的道路场景中测试.设定每个场景的测试回合数为1 000,场景设置及测试过程的具体描述如下.
3.2.1 模型测试场景(1)
测试场景(1)采用与模型训练时相同的道路场景,即3个参数分别为:礼貌系数p=1,环境车辆初始间距为30 m,环境车辆数为10辆.分别从换道决策成功率、模型得到的平均奖励、无人车平均速度来描述在此场景中模型测试的结果.Dueling DDQN、DDQN、 DQN模型的换道决策成功率随回合数变化趋势如图7所示,前1 000个测试回合的成功率、平均奖励以及平均速度如表4所示.
您说像他这样,我怎么敢把大事儿交给他办?他自己也挺苦恼:“国家的事儿不归我想,家里的事儿全被你想了,我还能想点儿啥?”

图7 场景(1)换道决策成功率对比

表4 场景(1)模型测试对比结果
由图7和表4可知,Dueling DDQN的换道决策成功率较DDQN和DQN分别高出1.7%和3.9%,同时在平均奖励和平均速度方面,Dueling DDQN模型均高于DDQN和DQN.3种模型在1 000次测试回合中成功的回合次数分别为Dueling DDQN成功936次,DDQN成功919次,DQN成功897次.在这些未发生碰撞的回合中,Dueling DDQN一个回合获得的奖励值小于5.0的有4次,DDQN有19次,DQN有25次,这些回合获得奖励值较低的原因是由于无人车为避免碰撞而采取了过于保守的驾驶动作,使得无人车在一定的步长内均保持较低的速度行驶,进而导致在一个回合内获得的速度奖励值较低,由此可见,Dueling DDQN成功但保守驾驶的回合次数较少,说明此模型可以通过状态空间的变化和奖励函数反馈过程更好的理解道路环境的变化,采取更优的动作值.由此可见,在场景(1)的测试过程中,Dueling DDQN模型的表现更好.
3.2.2 模型测试场景(2)
测试场景(2)采用比场景(1)更复杂的道路场景,即3个参数分别为:礼貌系数p=0.5,环境车辆初始间距为20 m,环境车辆数为15辆.分别从换道决策成功率、模型得到的平均奖励、无人车平均速度来描述在此场景中模型测试的结果.3种模型的换道决策成功率随回合数变化趋势如图8所示,前1 000个测试回合的成功率、平均奖励以及平均速度如表5所示.

表5 场景(2)模型测试对比结果
由图8和表5可知,Dueling DDQN的换道决策成功率较DDQN和DQN分别高出3.4%和5.1%,同时在平均奖励和平均速度方面,Dueling DDQN模型均高于DDQN和DQN.在此场景中模型测试结果与场景(1)相比,每个算法的测试成功率、平均奖励、平均速度均有所下降,但Dueling DDQN成功率的下降幅度最小,说明Dueling DDQN对复杂场景的适应性更强.场景(2)中3种模型平均奖励下降的原因是因为随着换道成功率的下降,无人车发生碰撞的次数增多,导致获得碰撞惩罚函数的次数增加,同时获得的单步奖励函数也随之减少,平均速度的下降也使得无人车获得速度奖励函数减少,最终导致平均奖励下降.
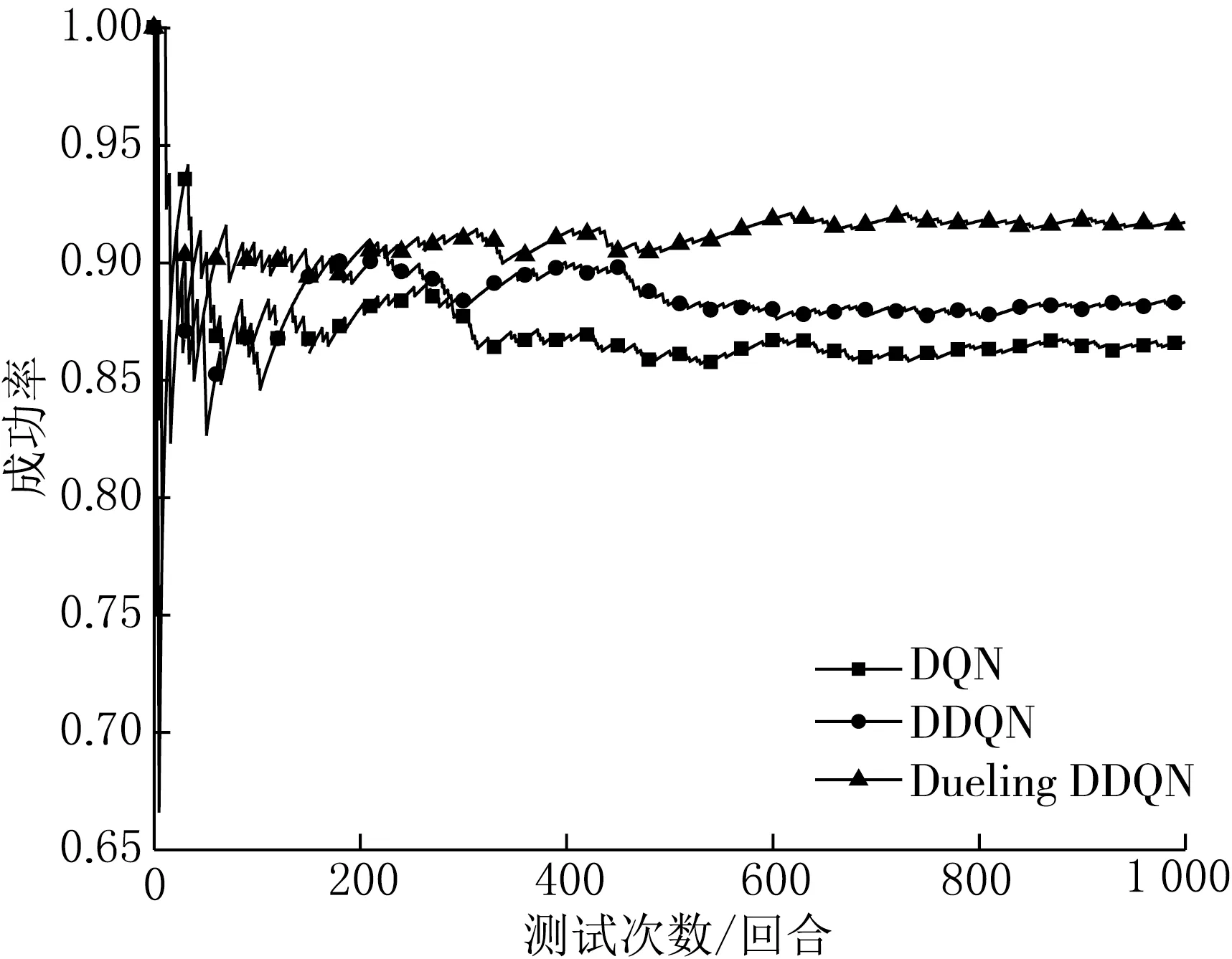
图8 场景(2)换道决策成功率对比
3.2.3 模型测试场景(3)
测试场景(3)采用最复杂的道路场景,即3个参数分别为:礼貌系数p=0,环境车辆初始间距为10 m,环境车辆数为20辆.分别从换道决策成功率、模型得到的平均奖励、无人车平均速度来描述在此场景中模型测试的结果.3种模型的换道决策成功率随回合数变化趋势如图9所示,前1 000个测试回合的成功率、平均奖励以及平均速度如表6所示.
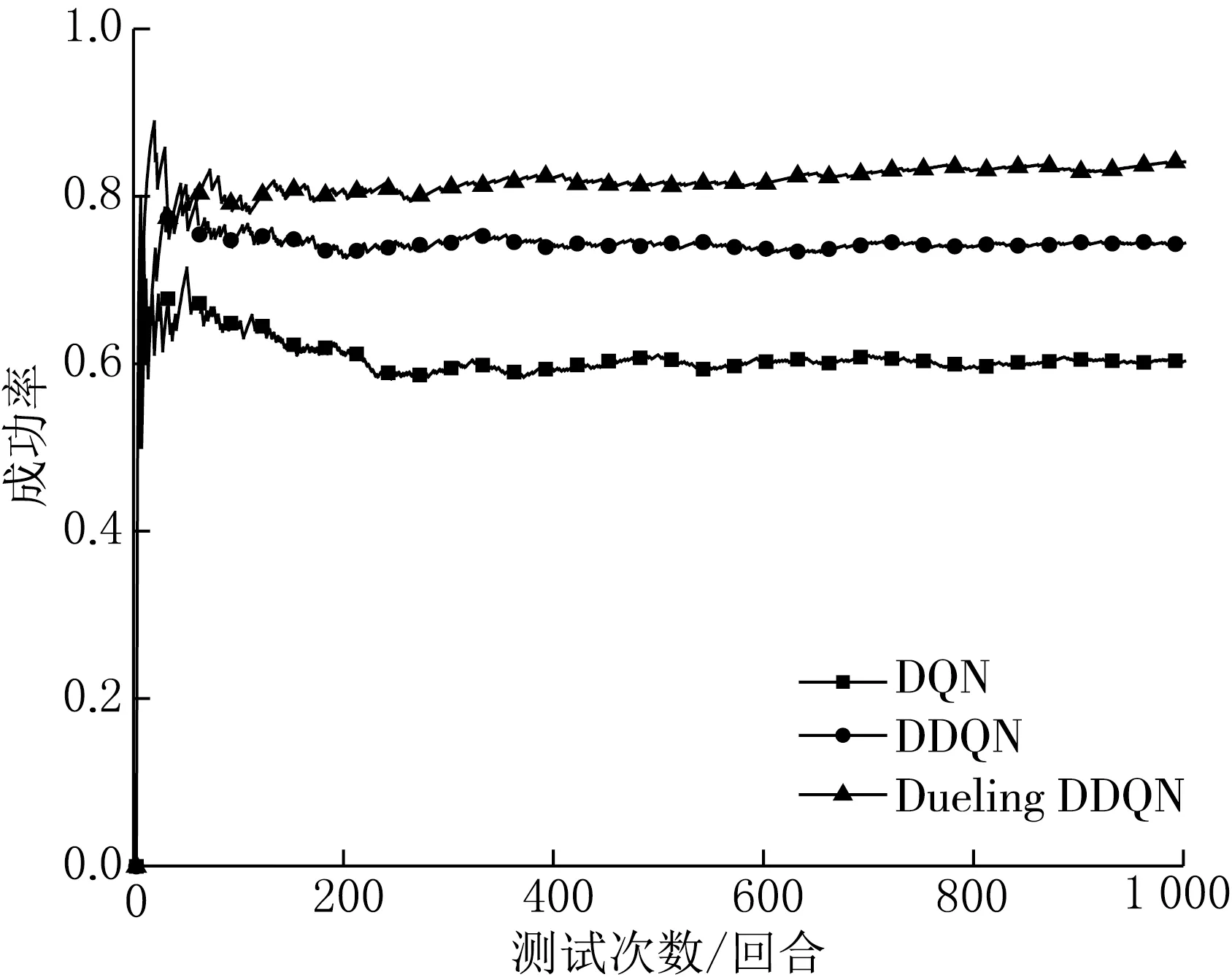
图9 场景(3)换道决策成功率对比

表6 场景(3)模型测试对比结果
由图9和表6可知,Dueling DDQN的换道决策成功率较DDQN和DQN分别高出9.7%和23.8%,同时在平均奖励方面,Dueling DDQN模型高于DDQN和DQN.虽然在平均速度方面DQN模型较Dueling DDQN高0.18 m/s,但是由于换道成功率较低,所以DQN模型无法保证在换道成功率较高的前提下提高无人车的速度.且在无人车发生碰撞的回合中,每个算法的单回合步数比例(单回合步数最大为20)分布如表7所示.

表7 场景(3)无人车碰撞单回合步数比例分布对比结果
由表7可知,DQN和DDQN在发生碰撞的回合中,分别有48.87%和45.70%的碰撞发生在前10个步长内,而Dueling DDQN有16.98%的碰撞发生在前10个步长内,说明在每个测试回合的开始阶段,DQN和DDQN对复杂的道路场景的适应性较低,无法准确地根据无人车当前所处环境进行合理的决策,DQN和DDQN算法的碰撞分布在前10个步长内的百分比分别是Dueling DDQN的2.88倍和2.69倍,说明Dueling DDQN算法在测试回合的开始阶段,可以根据当前所处环境使无人车做出合理的动作,且Dueling DDQN在复杂的道路场景中仍然可以保持较高的换道成功率.
3.2.4 不同场景之间的对比
场景(3)和场景(1)的测试结果相比,Dueling DDQN算法成功率下降9.5%,而DDQN和DQN算法分别下降17.5%和29.4%,Dueling DDQN算法无人车换道决策成功率的下降幅度最低,说明Dueling DDQN换道模型与DDQN和DQN模型相比,更适合在复杂的道路场景中使用.
综上所述,在3种车辆环境不同的测试场景中,Dueling DDQN在保证换道成功率的情况下,平均奖励和平均速度方面均高于DDQN和DQN,可见Dueling DDQN的模型性能更好.因为DDQN模型在增加了竞争结构后,在评估网络更新的时候,由于存在一个状态下的优势函数之和为0的限制,所以网络在更新时会优先更新价值函数,导致当每次模型的价值函数被更新时,在一个状态下所有的Q值均被更新,进而使得Dueling DDQN模型可以更好地理解外部的状态环境,同时提高了模型的鲁棒性和适用性.
4 结论
本文针对高速公路下无人驾驶车的换道决策问题,提出了基于Dueling DDQN的无人车换道决策模型,同时与DQN和DDQN模型进行了对比.实验结果表明,Dueling DDQN模型在无人车换道决策成功率上均高于DQN与DDQN,同时可以在保证成功率的前提下,更大幅度的提高无人车的行驶速度,进而提高通行效率.通过在不同车辆环境的道路场景下进行测试,Dueling DDQN模型在3种道路场景下可保持较高的换道决策成功率,表明此模型的鲁棒性更好,且在更复杂的道路场景下的适用性更强.
