基于深度神经网络的关系抽取研究综述*
2022-03-25周筠昌陈振彬陈珂
周筠昌,陈振彬,陈珂
(1.广东石油化工学院 计算机学院,广东 茂名 525000;2.广西师范大学 计算机科学与工程学院,广西 桂林 541000)
关系抽取作为自然语言处理(Natural Language Processing,NLP)领域的基础性任务之一,同时对自然语言处理的发展也产生着一定的影响。关系抽取的目标是在给定文本中识别实体以及实体之间的关系,组成关系三元组(头实体,关系,尾实体)。目前的研究中关系抽取仍存在有待解决的关键性问题和瓶颈,如数据稀疏和误差传递等问题,这些问题影响着关系抽取的模型效果,因此在未来的研究中关系抽取仍充满挑战性。
本文在基于英文的实体关系抽取的基础上,综合了句子级和文档级别两个类别的关系抽取、基于流水线和联合抽取两种抽取框架的关系抽取和基于远程监督的关系抽取。本文只讨论基于神经网络的关系抽取研究成果,并对具有里程碑意义的研究成果进行详细的探讨,以及分析了关系抽取目前存在的不足和仍需解决的问题。
1 关系抽取语料集
目前关系抽取研究中,从文本的长度进行分类大致可分为句子级别(sentence-level)的关系抽取和文档级别(document-level)的关系抽取。句子级别的关系抽取相对于文档级别的关系抽取而言简单,所给的文本句子中,头实体和尾实体及其关系皆通过单句进行表达;文档级别的关系抽取中,其头实体和尾实体并不一定出现于同一句中,且其实体之间的关系可能存在于多个句子甚至多个段落之中。由于两类关系抽取的任务具有差异性,因此其所使用的语料集也并不相同。
除了待抽取文本长度外,目前的语料集可以细分为通过人工标注生成的语料集和通过远程监督生成的语料集两类,这两者之间的主要差别在于数据标注的质量。关系抽取研究中,较为广泛的公开语料集如表1所示。
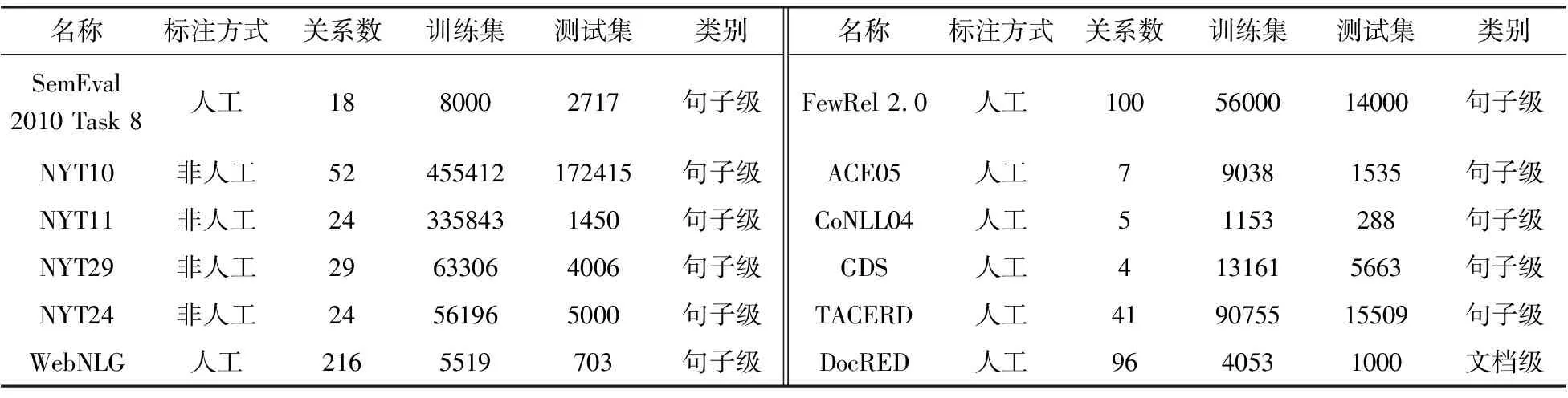
表1 关系抽取公开语料集汇总
2 基于流水线的关系抽取
目前的关系抽取研究中,基于流水线的关系抽取相对较多,该类关系抽取一般将关系抽取任务分成两步:命名实体识别和关系分类。
2.1 基于特征的关系抽取模型
早期的关系抽取模型中,比较依赖于对文本的特征的抽取工作。Mintz等[1]提出基于特征的关系分类模型,他将实体事件的词序列、词性标注、实体位置、实体临近的k个词作为词法特征,另外使用依存句法分析,将实体之间的路径作为语法特征。在此基础上,Riedel等[2]提出了多实例学习来解决语料集在远程监督过程中产生的噪音问题。该方法提高了当时关系抽取任务的模型效果。
关系重叠是关系抽取领域中一个待改进的关键性问题。在关系抽取中,一个实体可能只和另一个实体存在单一的关系,这种关系类型被定义为Normal类型,代表没有重叠的部分;但实际情况中,一个实体可以和另一个实体存在着多种关系,这种则被定义为EPO(Entity Pair Overlap);更复杂的情况则是一个实体和其他不同实体之间存在着多种关系,则被定义为SEO(Single Entity Overlap)。Hoffmann[3]等则提出多实例多标签(multi-instance multi-labels,MIML)来解决关系重叠的问题。他们即将一系列包含实体对的句子作为输入,利用概率图模型,最终来获得它们之间的关系。
2.2 基于卷积神经网络的关系抽取
2013年Mikolov等[4]提出了Word2vec,词嵌入工具的提出改变了自然语言处理领域的版图,深度学习方法开始广泛应用于自然语言处理领域。词的分布式嵌入表示,也成了基于深度学习的自然语言处理模型的核心部分。卷积神经在图像处理中的应用取得不错的效果,因此在自然语言处理领域也逐渐被重视起来。2014年,Zeng等[5]使用卷积神经网络进行关系抽取任务。文中使用了词嵌入模型[6],还使用了词和两个实体之间的距离向量作为模型的输入,通过卷积神经网络来抽取出句子的特征向量,最后经过一个带softmax分类器的前向神经网络进行关系分类。
2015年,Zeng等[7]提出了分段卷积神经网络(Piecewise Convolution Neural Network,PCNN),进一步提升关系抽取的模型效果。在PCNN中的max-pooling操作并非是整个句子的特征,而是将句子分为三个部分:句子开始到实体1,实体1到实体2,实体2到句子末,每个单独的分段都有单独的卷积神经网络,它们之间的参数并不共享。这种优势在于能更好地学习到句子各个分段的特征,并且通过拼接的方式综合考虑三个分段的信息,最后将其输入softmax分类器进行分类。
2.3 基于注意力机制的关系抽取
注意力机制的发展极大地促进了自然语言处理的发展,在自然语言处理各个子领域(如文本分类、情感分析等)上皆取得了不错的效果。Shen等[8]将注意力机制结合卷积神经网络进行关系抽取任务。该文献中,卷积神经网络被用于提取全局特征,而注意力机制则分别基于两个实体应用于句子中的单词。实体最后的一个字的词嵌入和其他词语的词嵌入进行拼接,计算每个词语的注意力权重。词向量通过使用注意力分数进行加权平均后得到注意力特征向量,然后将其和词向量进行拼接,输入带softmax的前馈神经网络进行关系分类。Zhang等[9]提出了基于LSTM的位置意识的注意力机制模型,也取得了不错的效果,其模型结构见图1。
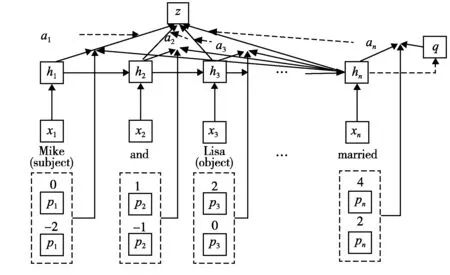
图1 基于LSTM的位置意识注意力机制模型结构
2018年,Devlin等[10]提出了基于Transformer的BERT(Bidirectional Encoder Representations from Transformers)模型,它只采用了Transformer的编码器部分却超过了当时自然语言处理各个任务的前沿模型和方法。随后,基于BERT的子注意力模型不断被提出,例如效果更好的ALBERT[11]等。BERT的基础模型直接应用到中文的关系抽取中就已经取得不错的效果,Han等[12]则在开放领域的文档级关系抽取任务中使用了BERT模型,基于DEMMT(Document-level Entity Mask Method with Type Infor mation)的基础上,提出了基于BERT的one-pass模型,文中模型在DocRED数据上进行实验,相比于其他State of art模型的F1值提高了6%。
2.4 基于图神经网络的关系抽取
近5年来,图神经网络(Graph Neural Network,GNN)逐渐被NLP领域学者们关注。
2017年Quirk等[13]提出基于图网络的跨句关系抽取,该文中以句子中的词作为图的节点,而其中的边则由相邻的词、依存关系还有语义关系等决定。接下来在图中计算出所有实体之间的可达路径,而每一条路径也表示着不同的文本特征,如句法特征、语义特征和词性标注等。通过以上特征来抽取出实体之间的关系。同年,Peng等[14]也在N元关系抽取中使用了图神经网络,不同的是该文中是将LSTM用于图神经网络中。而基于LSTM的图神经网络中,如果以文本中的词作为节点,其中的边只包含词与词之间的邻接关系,此时的LSTM是常规的线性LSTM神经网络;但如果边的信息包含了依存句法树中所表现的词之间的依存关系,则变成了树形LSTM(tree-LSTM),其模型架构见图2。而与之相近的成果就是Song等[15]所发表的文献。Song等与Peng等的任务不同之处在于并没有把图分为两个,而是直接在图上进行迭代t个时间步更新图的节点,如图2所示,当前时间步的隐藏状态,通过在图结构中与之相邻的结点信息的上一时间步的信息对其更新获得。

图2 基于Graph-LSTM的跨句N元关系抽取模型
在关系抽取任务中,最短依存路径(Shortest Dependency Path,SDP)被证实能有效地提取实体之间的关键信息,Guo等[16]提出了在GCN中使用软剪枝会对GCN模型的效果有所提升,因此考虑整个依存树信息来构建邻接矩阵,并使用多头子注意力机制进行软剪枝来区分获得重要程度。
图神经网络在文档级的关系抽取中,也取得了不错的效果。Sahu等[17]将文档中的单词作为图结点,同时基于依存句法树、邻接的词语和公指关系来确定边。类似的工作如Christopoulou等[18]提出的方法,不同之处在于Christopoulou等使用启发式算法在文档的不同成分之间建立自然联系的边,用边来构建图,而这些边的建立又基于预先定义的文档级的相互关系,比如Mention-Mention(MM)、Mention-Sentence(MS)等,然后使用图神经网络进行特征学习,最后在推理层迭代N次后进行关系分类,该模型在CDR数据集上进行实验并取得了不错的效果。
3 联合抽取
上述所有工作都是基于实体已经被识别出来的基础上,进行关系抽取任务,我们称之为基于流水线的关系抽取,它大致地将关系抽取任务分为实体识别和关系抽取两步。是否能将这两个步骤进行一体化则是联合抽取重点解决的问题。
在初期的联合抽取研究中,学者们试图通过共享参数的方式将命名实体识别和关系分类任务一体化。这些工作首先找出文本中所有可能的实体对,然后在文中抽取所有的实体组合的关系。命名实体识别任务和关系分类任务都是通过同一个神经网络进行实现,严格意义上,并没有实现真正的联合抽取。
Zheng等[19]提出了第一个真正意义上的联合抽取模型。文中工作的主要思想是将联合抽取任务转换成序列标注任务处理。通过组合实体标签和关系标签,构建新的标注标签,通过新的标签能够对实体信息和关系信息进行编码,然后通过使用由BiLSTM和LSTM组成使用该标签进行序列标注任务,最终通过标注的结果给出句子中所包含的关系三元组。Zeng等[20]提出了使用Eoncode-Decode网络中的复制机制(Copy Mechanism)进行抽取关系三元组来解决实体重叠的问题。Takanobu等[21]提出使用层次强化学习进行关系抽取任务;Nayak等[22]在Encoder-Decoder框架的基础上提出了一个词级的解码器框架和一个基于指针的解码器框架。
4 结语
基于流水线的关系抽取中,数据稀疏问题尤为严重,None类别的数据占据了绝大部分,但None类别的数据中并非所有样本都是无关系类别,部分样本所属关系类别可能不在定义的关系集中,导致最终被分类为None类别,而None类别的关系样本对于深度学习模型没有太多的帮助也不能帮助构建知识图谱。
联合抽取的研究中,目前已有的工作并不能很好地考虑到样本训练集或者测试集中不存在关系三元组的情况,因此在未来的研究中如何识别和处理文本中无关系的类别将是一项挑战。另外,由于数据稀疏的问题和数据集的质量都普遍不高、迁移性差等问题,基于Zero-shot和Few-shot的小样本学习关系抽取将是未来一段时间的研究热点。
