手机游戏消费潜在现象的预测
2022-03-25朱文瑞




摘 要:文章利用了人工神经网络模型,通过被调查者的基本信息、手游时长、消费态度等方面,预测被调查者是否存在长期消费的现象,以期更容易辨认出氪金玩家与平民玩家,使得开发者的宣传以及策划更具有目的性和有效性。
关键词:长期消费行为;手机游戏消费;人工网络模型
中图分类号:F49 文献标识码:A 文章编号:1005-6432(2022)05-0123-02
DOI:10.13939/j.cnki.zgsc.2022.05.123
1 引言
如今的社会中,科技迅速发展,手机也变成人手一个的生活必需品,网上支付的便捷性和安全性也使手机从20年前的联系工具,变成了人们移动的钱包。对于公司而言,能从庞大的玩家群体寻找出未来可能存在长期消费行为的人群,会使其策划、宣传的过程中的对象更加集中,对于手游公司来说百利而无一害。宋子健等[1]通过构建二元Logistic回归模型消费者的游戏意愿和消费意愿进行实证分析得到“年龄”“平均每天游戏时长”“接触手机游戏时间”对消费者的消费意愿均起到正向作用这一结论。洪晶[2]考虑通过神经网络算法预测出每一位客户最终所属的消费模式类别,能够帮助客户服务人员按照每一类客户群体消费行为的特点提供相应的服务和采取针对性的营销策略。本文采取人工神经网络模型,通过玩家的基本信息、游戏时长等方面对玩家是否存在长期消费行为进行预测,使得游戏开发商能够针对不同的玩家采取不同的策划宣传方式。
2 理论概述
人工神经网络,就是人们利用计算机模仿生物的神经网络,解决信息分类处理的模型[2]。神经元大致可以分为树突、突触、细胞体和轴突。神经元在神经系统中,起着接收信息、传递信息、处理信息的作用。而人工神经网络,将输入数据看成是接收信息,而激活函数则是神经元处理信息的能力,输出数据则是经过神经元多层处理传出的信息。经过一层层神经元的处理之后,便可以由原始的输入数据得到对应的输出数据。由于迭代的次数,神经元的层数比较多,相比于大多回归模型,预测精度可能会更高,拟合效果会更好。
本文经过多层神经元处理所得到的神经网络模型:
其中的g(i),i=1,2,3,…,n指的是每一层的激活函数,在每一层中神经元处理数据所遵循的函数。而b(i),i=1,2,3,…,n代表了每一层的阈值,在生物神经元中,只有足量的信息输入神经元后,达到一定的阈值之后,神经元才会向下一层神经元传递信息,这里用bi表示第i层的阈值。W(i),i=1,2,3,…,n指的是每一层神经元中的权重,用来说明每一层对应分量的影响程度。上述模型,就是模拟了输入数据经过一层层神经元激活函数的作用后,输出对应y的过程。
3 变量选取
本文中所研究的问题存在12个自变量,所以设X=(x1,x2,…,x12)为输入数据,而调查中所得到的数据中存在缺失的问题,倘若学生并没有进行过手机游戏的消费行为,那么手机的消费体验以及更倾向的消费模式的数据就会缺失,设计问卷时,有意将y=0看作是玩家无消费行为。因此,笔者将缺失的部分数据用0进行对应的补齐。输入数据X包括性别、收入、游戏时间、手机内游戏数量、最近所玩游戏的游戏时长,以及对于游戏品质、社交系统等属性偏好,共12方面,通过被调查者的选择,预测被调查者是否大概率存在消费状况。
y为问题中的输出数据,由于笔者感兴趣的是消费玩家的是否存在长期稳定的消费行为,所以如果玩家存在氪金的情况,笔者设y=1,若玩家不氪金,设y=0,相当于笔者将其看成了一个二分类的问题。由于数据本身并非如上的表示方法,所以笔者对数据y进行了一定的处理,方便后续模型的建立。
4 模型的建立
由于解释变量X存在12个分量,所以在设计第一层神经元时,遵从规律,设计约为变量个数的百分之七十五,第一层的神经元个数设置约为8个。在构建模型之时,所选用的激活函数是“relu”函数:
相比于其他函数,经过测试发现,“relu”函数的迭代次数更少,并且更快地达到了所需要的精度。由于问题最后的输出数据为二分类型,为了能更好地映射到0,1上面,输出层的激活函数使用“sigmoid”,公式如下所示:
通过以上两种形式激活函数,便可以将输入数据进行有效的分类,使得最后的输出数据对应想得到的0,1。
为了验证模型的准确性,将数据集分为三个部分,从理论上说,训练集、测试集、验证集的比例为8∶1∶1,根据所得到的数据数量共792组,将其分为训练集634组,测试集79组,验证集79组。首先,利用634组训练集的数据,对神经网络模型进行训练构建好模型,利用测试集的数据,对模型的拟合度等进行测试。
在本文中,笔者利用loss函数,以及模型的精度,对模型进行检验。所采取的loss函数是可以度量预测值与实际值之间的差异的二分类交叉熵公式:
笔者先分别在训练集、测试集中计算其loss函数。训练集中损失函数的值越大,说明训练集中预测的差异与真实情况越大,验证集中的损失函数同理。
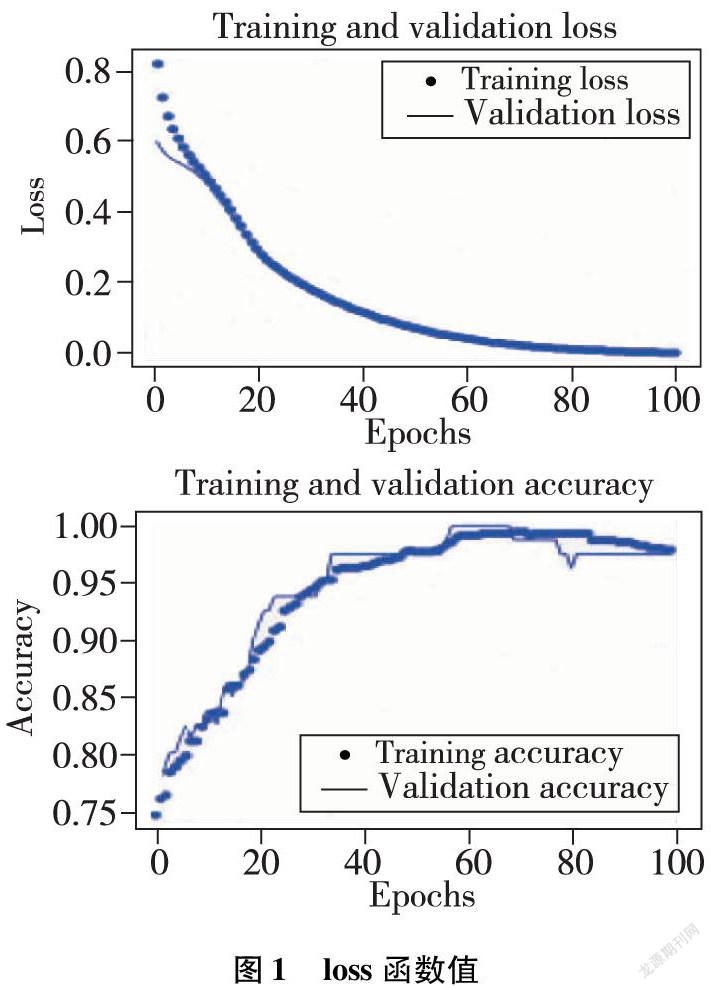
如图1的上方图所示,点集代表训练集的loss函数值,线条代表验证集的loss函数值。随着迭代次数的增加,两者都在逐步减小,可见迭代的次数增加,模型的预测效果会更好。当训练集和测试集的loss函数值在迭代了20次时,两者接近重合,可见其拟合的效果。最为重要的是,随着迭代的次数增加到80次后时,训练集和验证集的loss函数值已经无限的趋近于0,可见在两者中,模型的预测值与真实值的差异逐步减少,甚至是消失。如图1的下方图所示,就算是迭代的次数不超过20,训练集所训练的模型的精度也高达0.6,而随着迭代的次数逐步增加,在迭代次数达到40时,不管是训练集,还是验证集,产生的模型精度都高达0.9以上。笔者为了测试模型的精度,绘制训练集与测试集的精度图。为了确保模型的准确性,利用测试集对模型进行了同样的测试,结果如图2所示。
如图2所示,当迭代次数足够时,测试集的loss函数足够小,精度也同样足够高,所以可以说本文所提到的模型通过了检验。也可以根据测试集的数量,将数据分为10组,每组79份,每组都进行精度的计算,得出精度分别为0.9744、0.9465、0.9487、0.8077、0.8846、0.8846、0.9872、0.9615、0.6538、0.6538,算出其平均值约为0.8703,在多次训练的模型精度的平均水平达到了0.8703,可见相比于logistic回归模型,神经网络的模型预测的能力之强,结果之准确。除已有的数据外,又收取了10份问卷,将其数据处理之后,代入到已经训练好的模型中,发现在迭代多次后,最多只会出现一次错误,大多数情况甚至没有出现预测错误的情况。
5 结论
倘若对数据使用Logistic回归模型,预测的正确率只有60%左右,神经网络的精度高达90%,其預测的效果有着极大差距。神经网络模型所训练出的模型,其精度较高,预测出错的概率在迭代次数较高时,非常低,利用神经网络构建的模型,可以通过玩家的一些基本信息,平时游戏的时长,还有其对于游戏内一些消费内容的偏好性,很好地预测玩家是否存在消费行为。玩家如果经过神经网络的检测之后,输出的数据为1时,可以认定玩家存在着长期的、稳定的手机游戏消费行为,是未来游戏盈利的主要对象,可以针对其游戏偏好设置一些更新内容,道具,促使消费;当输出结果为0时,玩家被认定为平民玩家,消费的潜在可能性较低,在策划运营过程可以不用太过于迎合其心理需求。综上而言,本文所得出的神经网络模型,可以有效且高精度地判断学生是否为一个有着长期稳定消费行为的群体,可以方便游戏开发商针对这些长期稳定的消费群体做出合理的游戏运营策略。
参考文献:
[1]宋子健,陈家乐,赵家悦.手机游戏广告对消费者游戏意愿和消费意愿的影响因素:基于Logistics回归和SEM模型[J].现代经济信息,2019(13):129-131.
[2]洪晶. 聚类和神经网络算法研究及其在电信业客户消费模式中的应用[D].景德镇:景德镇陶瓷学院,2007.
[作者简介]朱文瑞,男,汉族,江西南昌人,研究生学历,研究方向:数理统计。
