基于CNN-集成学习的多风电机组故障诊断
2022-03-24叶祎旎李艳婷
叶祎旎,李艳婷
(上海交通大学 机械与动力工程学院, 上海 200241)
风能作为一种可再生的清洁能源,已展现出优异的特性,在世界能源市场上的份额越来越大。我国风电场计划容量显著增加,风电并网容量和装机量也在逐年增长[1]。但风电机组往往处于偏远恶劣环境,承受着高度变化的随机负载,导致风电机组性能衰退、部件损坏、故障频发。由此导致停机时间增加、风能损失,甚至造成安全事故。因此,对风电机组进行实时状态监控和故障诊断,尽快检测和识别风电机的潜在异常情况,具有重要意义。
大多数故障诊断的方法可以分为基于模型的方法,基于信号的方法和数据驱动的方法。基于模型的方法包括线性的Takagi-Sugeno (TS)模型[2]、逻辑斯谛模型[3]和非线性的威布尔分布模型[4]、奇偶空间法[5]等。基于信号的方法包括经典的快速傅立叶变换(fast Fourier transform, FFT)[6]、短时傅立叶变换 (shortterm Fourier transform, STFT)[7],以及包络分析[8]、希尔伯特变换[9]等。风电机组内置的监督控制和数据采集 (supervisory control and data acquisition, SCADA)系统记录着大量历史数据,通常采用数据驱动的方法加以分析。高斯过程分类器 (Gaussian processes classifier, GPC)[10]、支持向量机 (support vector machine,SVM)[11]都曾被用于故障分类。基于神经网络[12]的方法近年来也得到深入研究,包括多层感知器 (multilayer perceptron, MLP)、长短时记忆 (long short-term memory, LSTM)[13]、卷积神经网络 (convolutional neural network, CNN)[14]等。
由于风电机组是一个复杂的非线性动态系统,而本文研究对象未提供有效的故障机理信息,无法建立准确的数学模型。本文所获得的SCADA数据集具有低频采样、样本小的特点,不适合应用基于信号的方法。浅层神经网络达不到理想的故障诊断效果,故本文采用卷积神经网络,在传统LeNet-5网络结构基础上进行改进,进行多风电机组故障诊断研究。
1 数据集介绍
本文所研究的数据,来自位于上海市浦东新区东海大桥西侧的一个风电场,研究对象一共包含24台风电机组。该数据包括风电机组的状态监测(condition monitoring, CM)系统和SCADA系统采集到的数据集,采集时间从2019年1月2日9时30分0秒至2020年1月1日0时0分0秒。
CM数据集包括故障状态码值、状态码描述、故障的激活时间和复位时间。状态码示例如表1所示。

表1 风电机组状态码示例Table 1 Examples of wind turbine status code
每台风电机组发生的故障数量和故障类型不完全相同,故障类型主要包括过热故障、主电力供应故障、馈电故障、硬件故障、运行状态异常5大类故障。CM数据集更新时间滞后,无法及时处理故障。
SCADA系统每隔10 min采样一次,每台风电机组一共采集到49 549条数据样本和80个数据变量。数据的采样频率较低,且数据量较少。图1为故障发生时的其中3 000个平均风速、机舱振动传感器、电网频率和塔筒温度按时间序列编号的折线图。
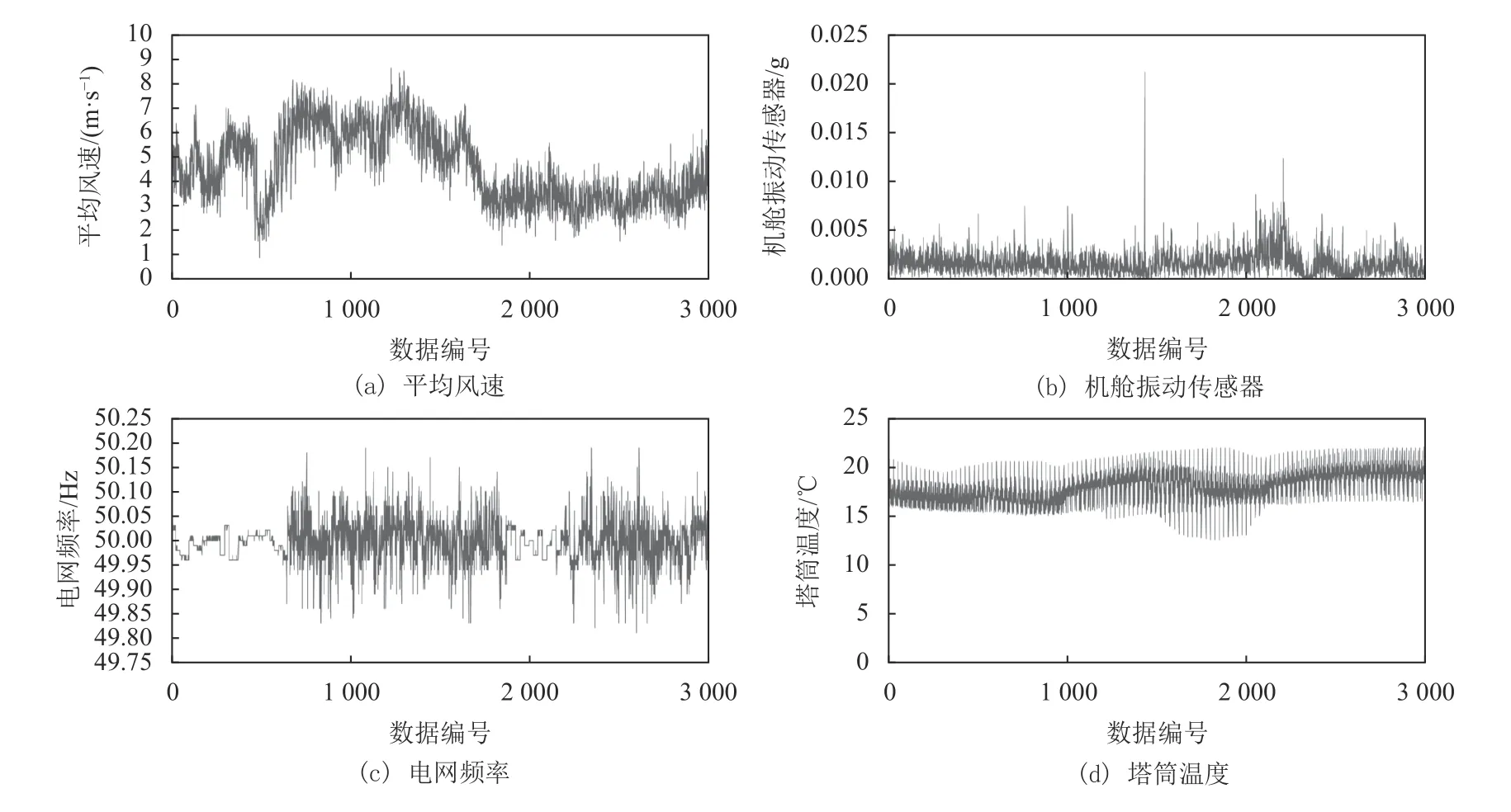
图1 不同特征的时间序列图Figure 1 Time series plot of different characters
2 风电机组故障诊断方法
2.1 基于改进LeNet-5的风电机组故障诊断过程
基于改进的LeNet-5网络的风电机组故障诊断过程如图2所示。

图2 风电机组故障诊断流程Figure 2 Fault diagnosis process of wind turbines
首先,对原始SCADA数据集进行预处理。构建单个风力发电机组故障诊断模型时,将所得训练集输入改进的CNN进行训练,模型训练完毕后使用测试集进行测试,检验其有效性。构建多风力发电机组故障诊断模型时,对预处理后的数据集进行聚类分析,利用集成学习方法组合单个CNN模型,并将训练集输入模型进行训练,利用测试集检验模型的有效性。
2.2 数据预处理
不同特征的数值数量级差别较大,故对数据进行Min-Max归一化处理,将数据映射到[0, 1]区间。
数据集具有高达80维的变量,为避免过拟合,采用主成分分析 (principal components analysis, PCA)[15]筛选出30维主要特征。
初步筛选后,将进入故障状态后10 min到该状态改变前10 min数据提取出来,标记状态码值,作为该故障类型的数据。将进入正常状态后30 min到正常状态改变前2 h的数据提取出来,以排除故障状态前后的过渡数据,确保选定的是无故障数据,并加上标签“0”。
经过数据筛选,标记状态码,发现数据样本存在严重的不平衡问题。以37号风电机组为例,数据集共获得49 206条无故障数据,而状态码为“800002”的数据2仅有6条。数据不平衡会影响模型性能,使得模型对少数样本的特征学习不够充分,导致诊断效果变差,不能很好地反映不同类型故障的分类效果。因此,将每类故障数据利用合成少数类过采样(synthetic minority oversampling technique, SMOTE)[16]方法进行过采样,获得1 000条训练数据和300条测试数据。
2.3 单个风电机组的LeNet-U设计
传统的LeNet-5神经网络是一种基于梯度学习的CNN结构,最初应用于手写体数字字符识别[17]。其特征提取过程主要采用卷积层的卷积核在数据矩阵上依次移动,进行权值求和,所得值加上偏置后,经过激活函数输入下一层。为了减少神经网络的参数,通常在两个连续的卷积层之间添加池化层,缩小数据规模,增强鲁棒性。针对本文所研究的风电机组SCADA数据集,在传统的LeNet-5基础上进行调整与改进,设计一种新的网络LeNet-U。
1) 添加一个卷积层、一个池化层和一个全连接层。从理论上讲,神经网络越深,特征表达能力越强,但优化问题就越困难。改进的LeNet-U网络可以提取更多的故障特征信息并进行整合,获得更好的训练效果。
2) 选择ReLU函数作为激活函数,如式(1)所示。

当输入太小或太大时,Sigmoid函数的输出趋于0并接近平滑,不利于权值的更新。Krizhevsky等[18]讨论了卷积神经网络中不同的激活函数,通过实验发现, ReLU函数不仅可以解决梯度消失问题,而且收敛速度较快。
3) 对卷积核的形状和数量进行调整。传统LeNet-5网络的每个卷积层的卷积核数量较少,有必要仔细调整卷积核的大小和数量以提高故障分类能力。LeNet-U的3个卷积层的卷积核分别为16、32、64个,形状均为1×3。
4) 在卷积之后,采用“padding”操作填充数据。由于卷积之后数据的长度会变短,因此,在数据两端填充“0”,使卷积前后的数据形状一致,从而在进行下一步池化操作时,尽可能不丢失数据信息。
5) 最初的LeNet-5设置固定学习率,但随着网络层次的加深,同一学习率难以达到最优化的效果。太大的学习率可能导致结果振荡,错过最优解,而太小的学习率容易导致模型陷入局部最优解。因此,本文设置衰减学习率,随着网络层次的加深自适应地减小学习率,有利于模型的训练。经过初步实验,将初始学习率设为0.001。
改进后的LeNet-U结构如图3所示。
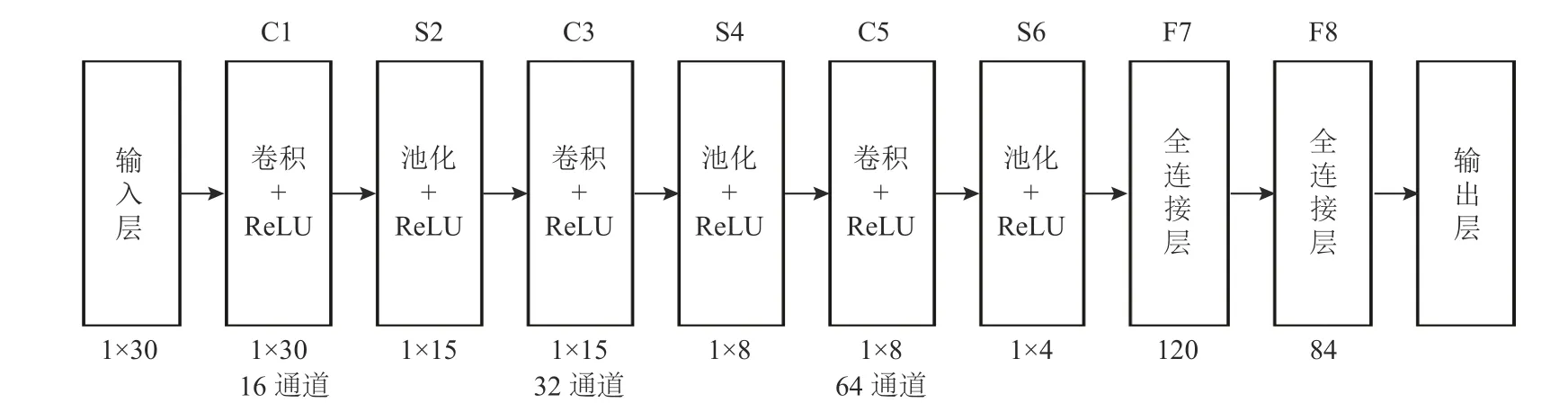
图3 LeNet-U卷积神经网络结构Figure 3 The structure of convolutional neuro network LeNet-U
对于本文所研究的风电机组数据集,输入层为经过预处理后的SCADA数据,输出层为模型对数据进行诊断所得的故障类型标签。在训练过程中,模型会将输出结果与真值进行对比,自适应地调整隐藏层的权值和偏置,以达到诊断效果的优化目的。
2.4 多风电机组故障诊断模型
由于单个风电机组的某些故障类型数据极少,不利于CNN对数据的学习,影响诊断效果。鉴于不同风电机组的故障类型有重合,同时利用不同风电机组的数据,可使模型对于重合类型故障的数据特征学习更为充分。但不能盲目将不同风电机组之间的数据混合使用,因此,考虑对各台风电机组数据进行聚类分析,并采用集成学习方法,构建多风电机组故障诊断模型。
集成学习的结构如图4所示,通过训练输入数据生成多个基学习器,采用特定策略组合各个学习器的预测结果,提高模型的性能[19]。
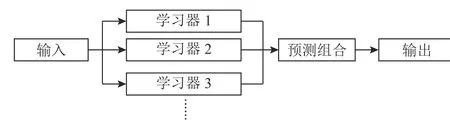
图4 集成学习结构Figure 4 The structure of ensemble learning
本文将LeNet-U模型作为集成学习的基学习器,采用AdaBoost[20]和Bagging[21]两种方法进行集成设计。
AdaBoost最初为训练数据分配相同的权重,得到初始的LeNet-U模型。在进行下一轮训练时,初始模型中被错误分类的数据权重增加,从而得到新的LeNet-U模型。依次迭代后,最终的故障诊断模型是训练所得的多个LeNet-U模型的加权组合,精度越高的模型权重越大。
Bagging引入自助抽样法来构建故障诊断模型。在训练数据集中均匀、有放回地选取数据样本,分别用于训练不同的LeNet-U模型。当测试数据呈现给每个模型时,使用投票法来组合预测结果,即选取出现次数最多的结果作为故障诊断的类别。
3 实验研究及结果分析
3.1 单台风电机组故障诊断
为评估所提出的LeNet-U模型的有效性,利用单台风电机组的数据集对模型进行训练和测试。为更好地观察模型的训练效果,在训练阶段,每200次迭代进行一次模型测试。以37号风电机组数据集为例,图5和图6显示在故障诊断模型的训练和测试阶段基于LeNet-U网络获得的精度曲线和损失函数曲线。
如图5所示,经过约7 500次迭代,故障分类精度趋于稳定,可达95.32%。如图6所示,损失函数值在前1 000次迭代中迅速减小,然后缓慢减小并接近于0。从图5和图6可以看出,模型训练结果通常接近模型测试结果,且没有欠拟合或过拟合,证明了所提出的故障诊断模型的有效性。
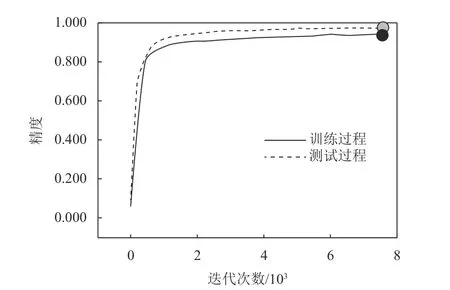
图5 LeNet-U模型训练精度曲线Figure 5 Accuracy curve during the training process of LeNet-U

图6 LeNet-U模型训练损失函数曲线Figure 6 Loss curve during the training process of LeNet-U
分别使用24台风电机组数据集训练与测试模型,采用平均精度(AC)和平均召回率(MAR)作为评价指标,所得实验结果如表2所示。
由表2可知,采用LeNet-U模型,在24台风电机组中的17台达到了最优精度,13台达到了95%以上,且召回率也达到了较高水平。另外7台的精度接近最大值,但在召回率上有极好的表现。由于LeNet-U的稀疏连接网络参数较少,相较于SVM、MLP和GPC,不易产生过拟合,更容易达到收敛;其多通道网络可以更有针对性地进行特征提取,在不同故障状态都能达到较高的准确率。

表2 单风电机组故障诊断结果Table 2 Fault diagnosis results of single wind turbines%
以37号风电机组为例,其接受者操作特性(receiver operating characteristic,ROC)曲线如图7所示。曲线越接近左上角,模型的性能越好。由图7可知,LeNet-U的诊断效果优于其他3种模型。
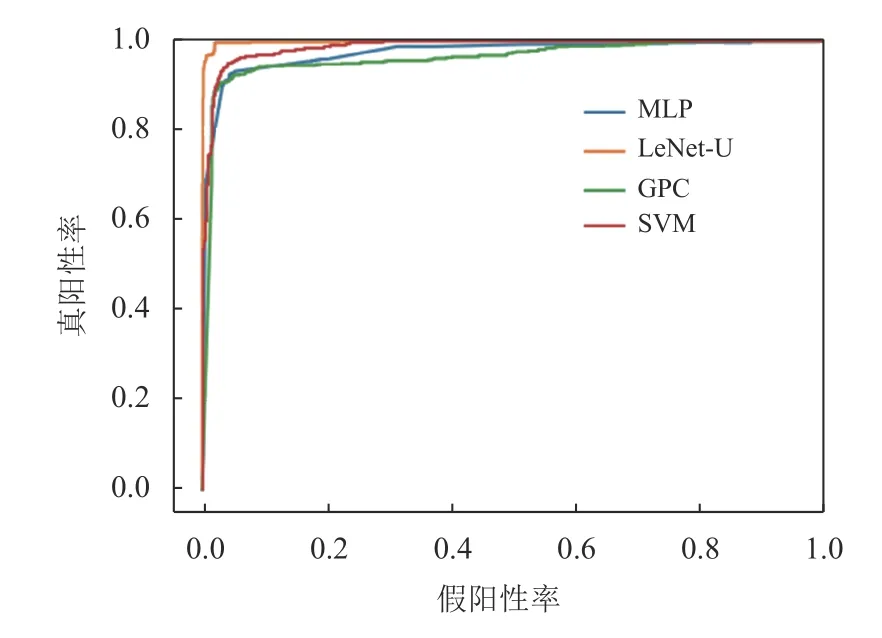
图7 37号风电机组ROC曲线Figure 7 ROC curve of wind turbine 37
综上所述,LeNet-U模型对于本文风电机组数据集表现出了优异的性能,不仅在所有类型数据上平均精度较高,且能够有效地对故障数据进行准确分类,对于故障诊断和维护具有重要意义。
3.2 多风电机组故障诊断
从表2的结果可以看出,部分风电机组的诊断效果仍存在提升空间。由于某些故障类型数据极少,单独研究时模型对于数据特征的学习不够充分。因此,本文选取诊断精度小于97%的风电机组,进行进一步研究。
采用均值移动算法进行聚类分析后,可得3个聚类,如表3所示。

表3 风电机组聚类结果Table 3 Clustering results of wind turbines
将表3中所得同一聚类的风电机组数据整合到一起,合并相同故障类型数据,整合得到聚类数据集。
分别采用AdaBoost和Bagging的方法集成LeNet-U模型,初始学习率设为0.001,Bagging的采样率设为0.75。利用各个聚类数据集对模型进行训练,可得故障诊断结果如表4所示。
由表4结合表2可知,聚类1、聚类2和聚类3的多风电机组故障诊断精度相对于每一台风电机组单独诊断的精度,提升幅度分别为8.8% ~ 12.07%、3.14% ~ 6.32%和 2.45% ~ 3.05%。精度达到90%以上时,这样的提升效果是非常显著的。
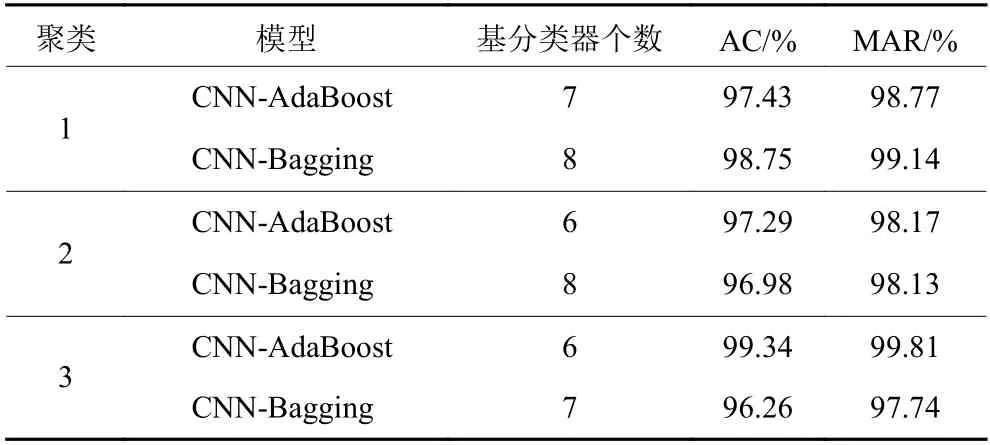
表4 多风电机组故障诊断结果Table 4 Fault diagnosis results of multi wind turbines
3个聚类的混淆矩阵如图8所示。对角线上的方块颜色越深,对应类别的诊断准确度越高,其余方块颜色越浅越好。
由图8可知,CNN-集成学习模型不仅能够达到较高的总体诊断精度,对每个故障类型的诊断准确率也十分出色,证实了该多风电机组故障诊断模型的优越性。
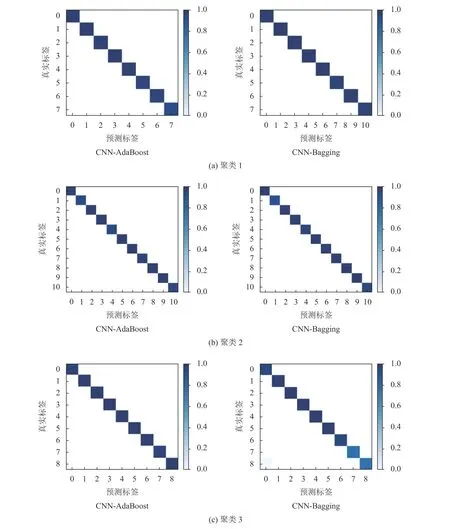
图8 诊断结果混淆矩阵Figure 8 Confusion matrices of diagnosis results
综上所述,本文所提出的CNN-集成学习模型具有很强的提取特征的能力,利用集成学习使模型对分类难度大的数据进行更加充分的学习。结合多个强分类器的模型不仅具有较高的分类精度,而且具有稳定的分类性能,应用于小样本数据集的多分类故障诊断问题是有效的,达到了良好的故障诊断效果。
4 结论
本文针对风电机组的故障诊断问题,对采样率较低、样本量较少的多分类SCADA数据集,进行了筛选、标记、平衡处理和数据划分,将卷积神经网络LeNet-5进行改进,增加卷积层、池化层和全连接层,改变卷积核形状和数量,改进激活函数,增加padding操作,设置衰减学习率,从而构建LeNet-U网络,达到优于其他方法的诊断效果。且将风电机组数据进行聚类分析,利用集成学习中AdaBoost和Bagging的方法集成单个LeNet-U模型,构建多风电机组故障诊断模型,达到了优于任一台单风电机组故障诊断的效果,验证了模型的优异性能。
在未来的研究工作中,可以尝试将LSTM神经元与本文构建的卷积神经网络结合,使模型可以充分利用数据集的时序性。另外,还可以考虑在集成学习的模型训练过程中,根据不同类别的分类精度自适应地调整权重,分类精度更低的类别权重降低,进一步提高模型对难以区分的类别的诊断能力。
