典型车载场景下语音识别算法效果评价与分析
2022-03-23朱哲慧张立军何志祝宋正河朱忠祥
李 臻, 朱哲慧, 张立军, 何志祝, 宋正河, 朱忠祥
(1.中国农业大学机械与农业工程国家级实验教学示范中心,北京100083;2.同济大学汽车学院,上海201804)
0 引 言
语音交互日益成为人机交互的主流途径,在智能家居、智能汽车座舱等领域应用日益深入。车载场景下,语音交互与触摸、按键等交互方式相比,具有更加自然、直接优势,并且能够抑制驾驶员注意力的分散。此外,语音交互是扁平化的,使信息本身作为核心凸显出来,增加驾驶的安全性和便捷性[1]。因此,其作为智能车载系统交互方式之一,具备良好的发展前景。
随着语音识别技术的快速发展,目前的语音系统基本可实现在安静室内环境中准确识别出语音内容,但汽车车厢内的语音交互质量易受车辆多源性和时变性噪声的干扰[2],导致语音识别准确率下降,用户体验受损。此外,汽车产业共享化趋势使得用户具有多源性特征,声源的多样化直接导致车载语音交互的适应性较差[3]。虽然机器学习的发展已经很大程度提升了语音识别的性能,但依然面临环境噪声、说话者口音、发音风格多变等诸多挑战[4],在很大程度上影响了语音识别系统的实际应用进程。
本文以车载环境为研究场景,针对目前车载语音识别系统在环境噪声、说话者口音、发音风格多变等应用场景中适应性较差的问题,从典型车用场景输入语音信号的特征提取、4种主流语音识别算法模型的部署、算法的效果分析与评价方面展开研究,并基于以上研究内容提出了合理的算法优化建议,为增强模型算法的稳健性提供了实际测试结果依据。
1 信号特征提取
语音识别需首先对语音信号进行特征提取及分析处理,得到其本质参数,并据此设计出表现良好的语音识别算法。因此,本文基于MATLAB对测试音频(采样频率:16 kHz;音频内容:“播放音乐”;录制环境:安静室内)进行时域以及频域特征提取,并采用双门限法实现语音端点检测。
对于信号{x(n)},短时能量的定义如下:
式中:n为离散信号值的编号;m为加窗运算时的积分变量;w(n)为窗函数;N1为窗函数长度。
短时平均过零率的计算公式,

基于以上计算原理,对测试音频进行时域分析,绘制其短时能量谱图和短时平均过零率图。对语音信号先进行分帧加窗处理,选择窗长为480,帧移为240的汉明窗函数,可获得较为平滑且包含细节信息的曲线。对语音信号进行端点检测,用红色直线绘制出语音信号开始及结束位置,如图1所示。

图1 测试音频时域特性图及端点检测示意图
综合考虑测试音频的时域及频域信息,绘制图2所示的声谱图和Mel频谱图。Mel频谱图将语音信号的频率转换到Mel频率标度,

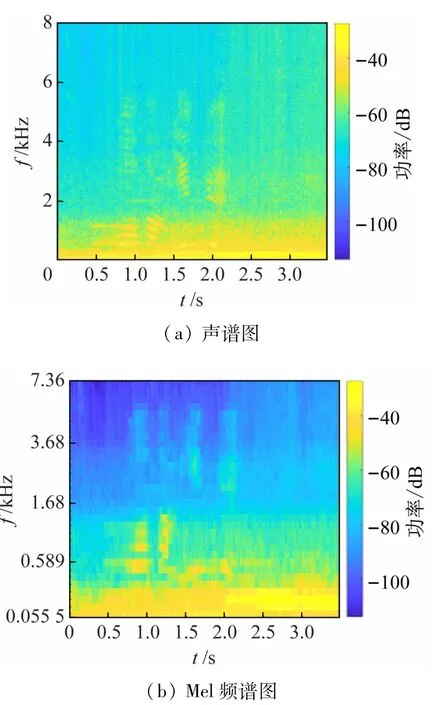
图2 测试音频声谱图及Mel频谱图对比
结合Mel频率标度转换原理,将测试音频的声谱图和Mel频谱图进行对比。可以看出,低频信号尺度被放大,该特性与人耳对低频声音更敏感的原理具有一致性,因此多种语音识别模型算法均采用MFCC或Mel滤波器组输出能量作为前端语音信号特征[5-7]。
运行测试音频MFCC提取程序,将窗函数大小设为20 ms,即每帧长度为20 ms,共获得1 016帧信号MFCC。预先设定MFCC维度为12,即每帧语音信号具有12个梅尔倒谱系数,组合为1 016×12个特征参数。选取测试音频第50帧的12个特征参数进行展示,如表1所示。

表1 第50帧的12维MFCC特征
2 算法模型
2.1 云端模型
分别选取基于全卷积网络(科大讯飞DFCNN模型)、基于前馈神经网络(阿里云DFSMN模型)、基于LSTM网络(百度云Deep Peak2模型)及基于双向循环网络(百度DeepSpeech2模型)4种主流算法模型。
科大讯飞DFCNN模型、阿里云DFSMN模型及百度云Deep Peak2模型均属于云端部署模型,以WebSocket API方式向客户端提供可开发接口。科大讯飞实时语音识别模型接口程序流程图如图3所示。
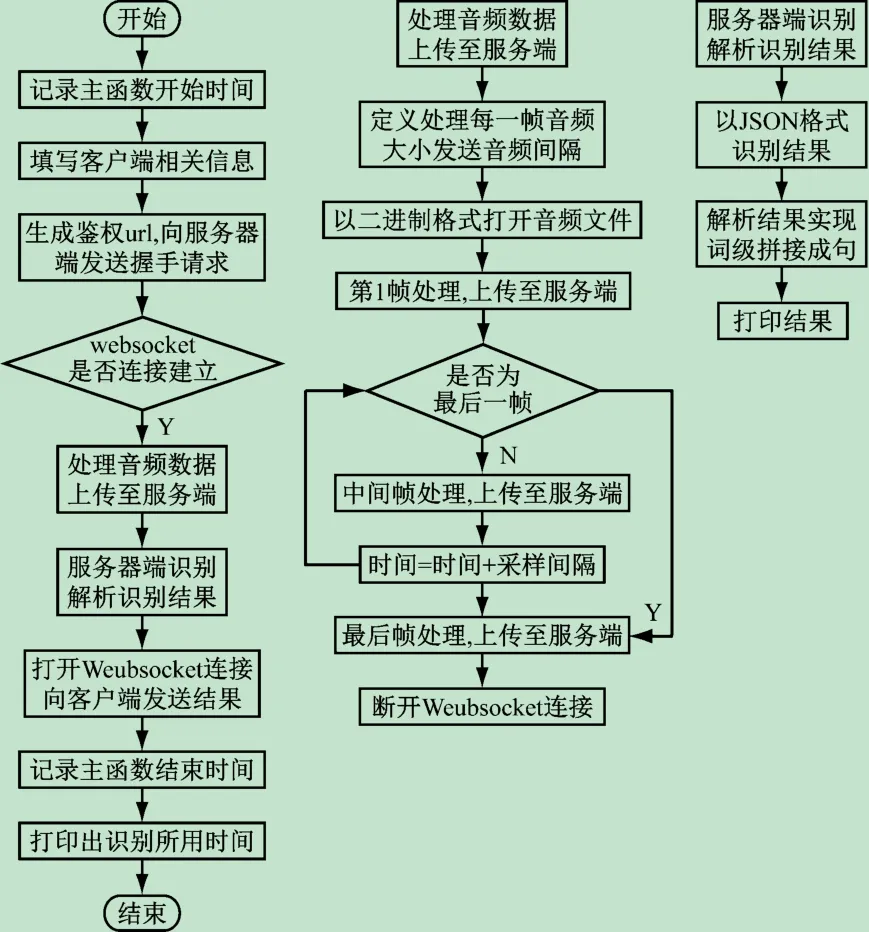
图3 科大讯飞模型接口程序流程图
该接口要求音频的采样频率为16 KB或8 KB,音频格式为pcm或mp3。本文使用音频处理软件Adobe Audition,将音频修改为16 KB采样频率、16位采样精度的pcm wave格式。将测试音频输入模型进行验证,得到基于词的正确识别结果,识别结果以json格式返回客户端。在程序优化过程中,将元组“w”类内容进行拼接,即基于词进行返回结果解析,得到最终完整的识别结果、程序修改结果以及最终返回的识别文本。
同样,阿里云和百度云的实时语音识别模型接口均为基于WebSocket协议的WebAPI,本文选择基于Win10和python3.7的模型demo进行本地部署,根据接口对音频格式的要求进行音频格式规范化处理,借助Adobe Audition软件完成部署。
2.2 本地模型
百度DeepSpeech2模型则为基于Linux系统的PaddlePaddle平台的语音识别模型。因此在Win10系统上安装Linux虚拟机,利用Virtual box虚拟机安装助手安装Ubuntu18.04桌面系统,基于此进行模型部署。其安装部署的完整过程如图4所示。

图4 Deep Speech2模型完整安装部署过程
3 模型算法评价与实验结果分析
3.1 云端模型测试
构建3种不同的模型测试环境,图5所示为实际测试场景图。

图5 真实场景测试图
(1)测试环境与语料。
场景1噪音场景。噪音场景数据包括人工合成和真实录制音频。人工合成噪音场景测试语料为信噪比分布在2~8 dB的“播放音乐”指令,指令基于音频混合函数,在MATLAB平台获取。真实录制噪音场景测试语料为依据智能车载系统基本功能需求[8]设计的小型语料集,语料内容如表2所示。音频由智能手机在出租车上录制完成,录制时车窗为半开状态,地点为闹市区,个别录音伴有多重人声。

表2 噪音场景语料内容
场景2中英文混合输入场景。中英文混合输入场景使用音频为出租车真实场景录制音频,音频文本内容涉及导航、音乐播放、拨打电话等基本操作功能,如表3所示。

表3 中英文混合测试音频文本内容
录制设备为智能手机,录制地点为闹市区、车窗为半开状态,录制时间为早高峰时段。
场景3混叠人声输入场景。混叠人声输入场景测试音频为真实场景录音,语料内容与真实录制噪音场景语料内容一致,用于混合的人声为自行录制的现场科目三教学音频。该音频由放置在说话者后座上的智能手机录制完成,音频内容为:“踩离合器、踩刹车,打左转向灯,按喇叭,看左后视镜,松手刹,挂一档。”绘制出该音频的波形图及声谱图,如图6所示。从声谱图中可以看出,背景人声的基音频率基本分布在300 Hz以内。

图6 背景人声音频波形图及声谱图
(2)评价指标。
指标1字错率(Character Error Rate,CER)。选取字错率为第1个评价指标,针对不同的指令内容和指令场景,测试模型识别准确率。CER定义为[5]

式中:S为替换的字数;D为删除的字数;I为插入的字数;C为正确的字数。
指标2实时率(Real Time Factor,RTF)。在主流模型算法文献[9-10]中都提及实时率指标,由于面向实际应用的移动语音识别设备不仅要求字错误率低,还要求延迟时间低,因此该指标具有现实意义,实时率定义为[11]

基于python程序语言datetime库函数,在各模型接口程序中添加识别音频处理时间该输出指标,用于计算模型的实时率。
(3)实验结果及分析。
场景1噪音场景。在合成噪音场景中,各模型均能准确地识别出音频内容,在合成噪音情境下准确率较高,人工合成的噪音环境对语音识别的精度影响不大,各模型实时率与信噪比关系如图7所示。

图7 各模型实时率与信噪比关系
实时性能方面,实时率越高,实时性能越差,且一般来说,RTF<1时实时性能较好。从图6可以看出,科大讯飞模型对噪声数据的敏感度低,实时性能良好且稳定。随着信噪比降低,阿里云模型以及百度云模型的实时率上升趋势明显。因此对噪声较敏感的模型来说,信噪比越低,实时性能越差。
在真实噪声场景中,各模型识别准确度较高。其中,阿里云模型、百度云模型在“播放电台FM101.1”这条测试音频上分别有插入字和删除字错误。将真实场景音频时长与各模型测得的实时率进行相关性分析,其关系图和变化趋势如图8所示。图中可以看出,随着音频时间增长,各模型实时率有下降趋势,即音频越长,实时率越低,实时性能越好。从实际情况分析,音频时间越长,可利用的上下文信息越多,因此实时率有所提升。
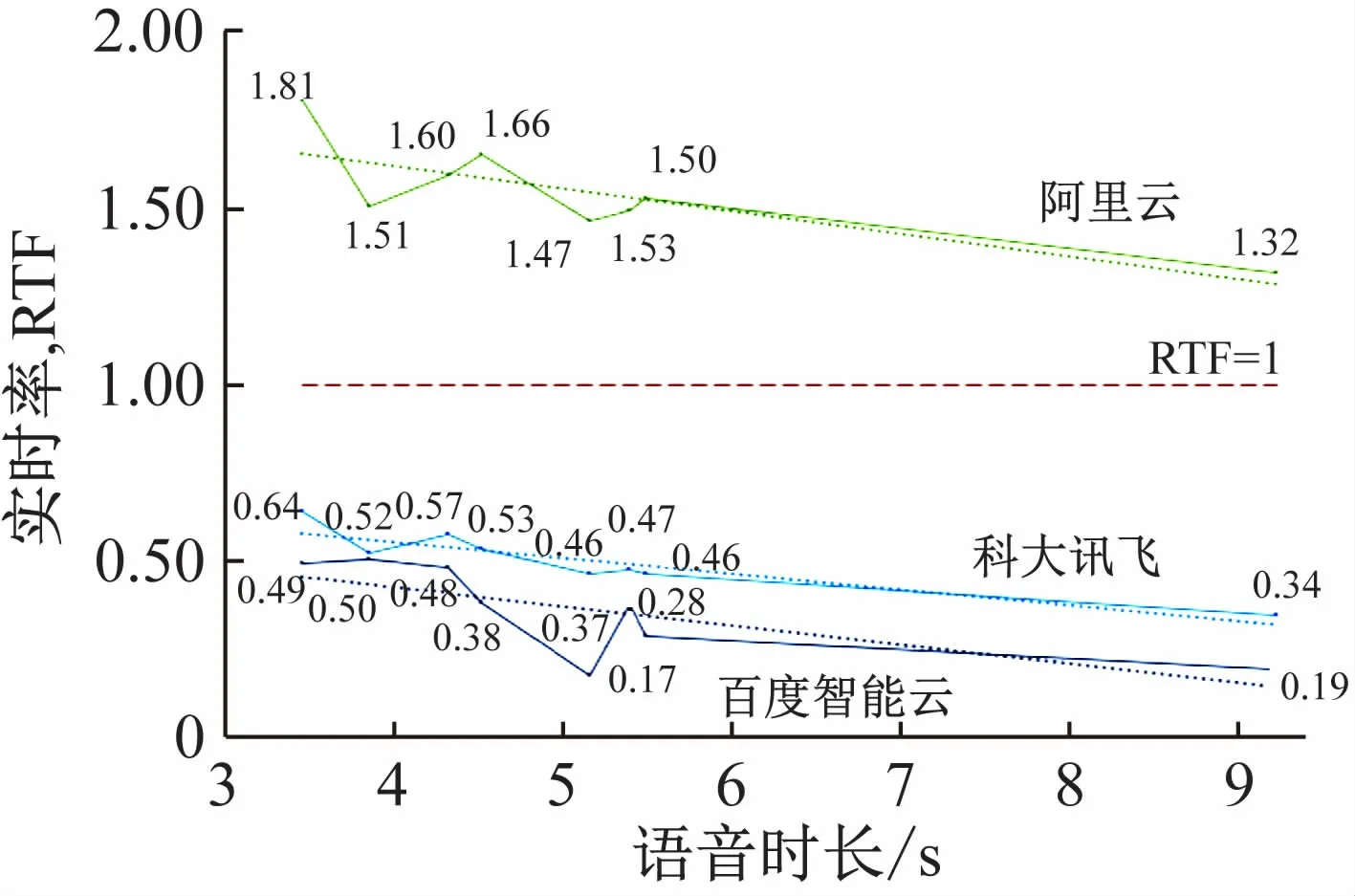
图8 各模型实时率与音频时长关系
场景2中英文混合输入场景。将各模型的识别字错误率及实时率进行对比,如图9所示。科大讯飞模型的识别准确率和实时性能最优,得益于DFCNN建模技术[4],实现了中英文混合输入的高准确率、高实时性能识别。且由于模型未使用传统BRNN(Bidirectional Recurrent Neural Network)结构,不需要将完整的语音输入就可得到识别结果,因此实时性能优异。

图9 各模型中英文混合测试字错误率及实时率对比
场景3混叠人声输入场景。设置混合信噪比为15,在测试结果中找到几个实时率极大值点,即实时性能较差的点,对应的字错误率也较高,因此绘制出字错误率与对应音频实时率的关系图,并标出趋势线,如图10所示。从图中可以看出,在有背景人声干扰的情况下,模型的实时率随字错误率的增加呈上升趋势。因此可通过适当提高模型识别准确率的方式提升实时性能。

图10 各模型实时率与字错误率关系
考虑该场景下输入音频的Mel频谱特征与输出结果之间的关联,分别绘制出原始音频和在信噪比为15时音频混合的Mel频谱图,如图11、12所示。

图11 原始音频Mel频谱图

图12 混合音频Mel频谱图
结合Mel频谱图分析模型识别结果,以声谱图为模型输入的科大讯飞模型,在“导航至大市口”“打电话给爸爸”两者音频能量整体升高后,识别准确度较其他模型而言准确率低,尤其当句子的后半段出现较宽频率上下限的高幅值乱纹时,模型识别的字准确率大幅降低。此外,原始音频的所有开始音均为塞音与擦音。在频谱图中,即使塞音或擦音前有能量较大的背景人声,3个模型也均能准确判断音频的开始音。汉语中的塞音有“/b/、/p/、/d/、/t/、/g/、/k/”,擦音有“/x/、/f/、/sh/”。在Mel频谱图中表现为乱纹的清擦音“/f/、/x/”受背景音影响小,各模型均能准确识别。
(4)模型评价。将3种应用场景的识别准确率和实时性能作为模型的6个评价方面,分别绘制出各模型的性能雷达图进行可视化对比,如图13所示。
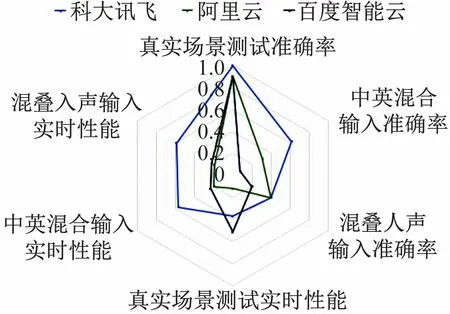
图13 各模型综合性能对比雷达图
从图13可看出,科大讯飞模型在各应用场景的综合性能最优。科大讯飞模型基于多层卷积和池化进行建模,具有良好的平移不变性,从而能够较大程度地解决说话者口音、说话风格不同带来的多样性问题,因此在3种模型中稳健性最优。百度Deep Peak2模型以音素组合体为全新的建模单元[9],能够更好地利用神经网络的表达能力,不受上下文信息的约束,因此在真实场景下的实时性能最优。
3.2 本地模型优化
优化方式1运行硬件适配。研究表明,百度DeepSpeech2模型在实时语音识别方面表现欠佳,原因是该模型具有多个BRNN网络层,需将整段语音输入模型后才能得到识别结果,且由于模型使用beam search进行解码,解码时间增长。因此,在对模型进行测试时,模型实时率均远大于1。考虑到硬件的并行运算速度,将硬件进行相应优化处理。
虚拟机原安装在运行内存为2 GB的CPU服务器,现更换硬件设备为16 GB内存CPU服务器,并将虚拟机内存调整为8 GB。识别相同语句时,运行速度得到了50%左右提升。
优化方式2参数调整。DeepSpeech2模型基于CTC损失函数将语言模型、声学模型作为整体训练,得以实现端到端的训练过程[12],因此该模型中语言模型与声学模型具有统一的目标函数,训练模型目的为对该目标函数进行最小化处理,以提高识别精度。目标函数为

式中:pRNN指在循环神经网络模型中给定语音输入x下输出为文本y的概率;pLM指在语言模型中能输出文本y的概率;wc(y)指识别文本y中汉字的数量;α(语言模型权重)指用于调整语言模型和CTC网络的权重;β(单词插入权重)指用于调整允许识别文本中插入汉字的数量。对这些参数进行适当调整,可在一定程度上增加模型的识别精度。
使用二维网格搜索法对权重α、β进行查找,开源网格搜索法会在参数空间中打印出每一个权重对应的字错误率,确定合适的权重查找范围,根据所得CER结果进行调整,找出字错误率为全局最小值时对应的权重值。搜索结果表明,在α=2.01,β=0.32时,模型在aishell训练集上的识别精度可由原92.3%提高到93.6%,如图14所示。

图14 字错误率下降0.013
3.3 模型优化建议
百度DeepSpeech2模型是基于BRNN的语音识别模型,通过CTC损失函数实现了端到端的识别过程。近年来实现端到端训练及预测的模型成为该领域的研究热点和主流趋势。端到端模型更加简洁,省去了传统语音识别系统中独立存在的声学模型和语言模型,真正实现了从输入到输出只需要一个神经网络的目的。但在实际测试中,由于预训练网络并未达到优异的泛化效果,因此识别准确率较差。除此之外,虽然BRNN结构使得模型可充分利用上下文信息,但同时存在必须输入完整的一段话才能进行识别的弊端,因此该模型在实时性能方面存在劣势。在后续的百度DeepSpeech3模型中,研究人员开发了Cold Fusion策略[13]。可轻松实现预训练模型在不同应用领域的迁移,且模型不再局限于BRNN结构,能够实现实时效能的提升。总体而言,未来的语音识别模型应做到针对不同应用场景,在无需该场景千级、万级训练数据的情况下,具有良好的迁移能力和适应能力,且针对移动语音设备,其性能不再受限于滞后的返回结果。
科大讯飞模型是基于卷积网络的语音识别模型,模型结构简洁,经测试发现正常情况下准确率高、实时性能优异。卷积网络的优势为良好的平移不变性,可能够较大程度解决说话者口音、说话风格不同带来的多样性问题。近年来卷积网络对图片的特征表达能力愈加增强,由ResNet[14]提出的小卷积网络快速推动了卷积神经网络的发展。但该模型在多重人声识别过程中无法有效屏蔽背景人声噪声,对识别精度产生了较大影响。因此可将卷积网络作为语音识别神经网络的前端网络层,称为特征提取的辅助工具。相对而言,百度Deep Peak2模型[13]以音素组合体为全新的建模单元,能够更好地利用神经网络的表达能力,而不受上下文信息的约束,在识别多重人声音频任务上成为新的解决思路。
4 结 语
本文从语音识别系统前端信号处理出发,运用语音信号特征提取方法,基于双门限法实现了语音信号端点检测,验证了语音信号的Mel频谱图和高维MFCC系数作为大多数语音识别系统输入特征的优势所在。目前的主流模型算法在低频噪声的抑制方面表现良好,但并非所有模型都具备中英文混合输入识别能力。在云计算愈加普及的当代,云端模型的实时性能远优于本地模型,但实时率对于大多数云端模型来说依然是一个挑战。此外,针对本地模型识别准确率低的劣势,本文基于开源二维网格搜索法优化了百度DeopSpeech2模型,并对其进行硬件适配,使得模型识别精度、识别速率得到小幅度提升。最后,本文基于以上研究内容,提出了各模型的优化建议。
