改进的YOLOv3 算法对伪装目标检测
2022-03-23王伦文朱敬成
吴 涛,王伦文,朱敬成
(国防科技大学电子对抗学院,合肥 230037)
0 引言
对伪装目标的检测与识别,一直以来都是军事目标检测研究的重点内容,其任务就是检测出伪装目标的位置信息和类别信息[1-2]。与常规目标不同的是,伪装目标与周围背景环境高度融合,视觉特征与背景相似,特征模糊难以辨析,给伪装目标检测带来巨大挑战。
传统算法将伪装目标看成特殊的纹理结构进行特征提取[3-5]。该类算法需要手工提取伪装目标特征,检测效率低,不能满足军事目标检测实时性的要求。2014 年,Girshick 等人成功将卷积神经网络应用在目标检测领域[6]。伪装目标的特殊性质决定了其与背景融合度较高,常规的基于深度学习的目标检测算法在伪装目标数据集上效果受到限制,检测效果有明显下降。为此,文献[7]构建了一个全连接反卷积网络用于抵抗背景中的噪声,有效提取并融合了深层卷积网络中的高层语义信息特征;文献[8]在基于VGG-Net 的基础上提出了SSDN 网络,增加了语义信息增强和样本扩展两个模块,与FCN8S 等其他模型相比,平均绝对误差(Mean Absolute Error,MAE)有所降低;文献[9]在RetinaNet框架的基础上,针对伪装目标特点,在检测模型中嵌入了空间注意力和通道注意力模块,与不同深度目标检测算法进行比较,在检测精度和准确度上有所提升。
本文以回归模型YOLOv3 为基础,提出了一种基于改进YOLOv3 网络的伪装目标检测算法。YOLOv3 是一种实时性效果较好、检测精度较高的单阶段目标检测算法。为使其能够适用于伪装目标检测,对算法模型进行了改进:1)针对现有伪装目标数据集,充分挖掘数据的先验知识,对算法的先验框进行了重聚类;2)依据YOLOv3 的骨干网络多次利用残差网络的特点,将原网络的级联方式由单级跳连改为多级跳连,在增加网络模型深度的同时,提高了检测精度并避免了因模型过深带来梯度消失的问题;3)在残差网络中引入注意力机制,为不同的特征层赋予不同的特征权重,网络在提取特征时具有不同的偏好,提升了模型读取关键信息和提取有效特征的能力。在文献[9]公开的伪装目标数据集上进行实验,结果表明,与原始算法相比,本文提出的算法具有更高的检测精度。
1 YOLOv3 算法模型
2018 年Redmon 等人提出YOLOv3 算法后,其在公开的经典数据集上表现出了良好的检测性能[10]。YOLOv3 是一种基于回归的单阶段算法模型,在YOLOv1、YOLOv2 基础上有了很大改进,采用了与YOLOv1、YOLOv2 不同的网络结构,引入了多尺度融合的方式对不同尺度目标具有很好兼容性,同时具有良好的检测速度和精度[11-12]。
YOLOv3 的骨干是一种新型的网络结构——Darknet53,它借鉴了残差网络的优点,采用了多个残差块进行特征提取,残差模块的设计和使用可以使网络很深时仍具有良好的收敛性能,其结构如图1 所示。

图1 Darknet53 模型结构
网络的输入会被调整为三通道的416*416 大小的图片,在经过一系列的特征提取后会得到13*13,26*26,52*52 三类不同大小的输出。不同分辨率的输出,其感受野不同,有利于对不同尺寸的目标进行检测。YOLOv3 算法依然采用了先验框机制,经过聚类算法,YOLOv3 聚类出9 种大小不同的先验框,每个特征图分配了3 种大小的先验框。相比之前的YOLO 版本,YOLOv3 减少了先验框的种类,提升了检测速度。先验框尺度如表1 所示。

表1 特征图对应不同尺度的先验框
2 基于改进YOLOv3 的目标检测算法
2.1 先验框重聚类
目标检测算法中先验框的设计,使得模型不需要直接对物体的位置信息进行预测,而是通过先验框相对于真实框的偏移距离对目标进行预测。YOLOv3 算法在训练数据集上通过K-means 方法对先验框尺度进行聚类,如表1 所示,得到了9 种尺度的先验框。先验框的设计能够降低预测难度,提升检测召回率。
本文在公开的伪装人员数据集下,对YOLOv3的9 种先验框进行了重新聚类,重新聚类的先验框能够更好贴合当前数据。重新聚类后的先验框宽高比如表2 所示。

表2 重新聚类后先验框宽高比
2.2 残差块的多级跳连
当网络层数不断叠加时,网络越来越难以训练,会出现梯度弥散的问题。为了解决这一问题,He等人提出了残差网络的概念,重新定义了输出层的学习剩余函数,以便于对网络进行更深入地训练,使得模型在网络层数较深时仍具有良好的收敛能力和效果[13]。YOLOv3 借鉴了残差网络的特点,在特征提取阶段使用了多个残差网络进行特征提取,表现出了良好的提取性能。
由于YOLOv3 的骨干网络多次使用了残差块结构,本文调整了残差块的级联方式。由原先的单级跳连增加到两级跳连甚至是多级跳连。增加级联方式融合了多个残差块内多个卷积层的特征,有利于误差回传。此外,在扩展模块、增加网络层数时,模型依然具有较好的收敛效果。
如图2 所示,其他输出层学习参数的引入,能够进一步融合其他输出层的训练效果,增强模型的训练能力,保证模型能够进行更充分训练且在增加模型深度时模型不会产生梯度消失的问题,进一步确保了模型训练时的可靠性和预测的准确性。

图2 残差块
2.3 注意力机制嵌入
由于伪装目标的特征模糊,难以有效辨别,所以改进算法主要关注如何提高伪装目标的有效特征,增大有效特征权重,提高特征分辨率。因此,将注意力机制[14]引入到YOLOv3 的算法模型中。在神经网络的模型当中,能够有针对地选择某些输入,或者根据算法需要给网络输入分配不同的权重值。注意力机制的引入能够帮助我们从诸多特征中选择特定的重要特征,筛选出有用信息,提升网络的表达能力[15-17]。
残差块得到的输出会首先进行压缩操作,通过最大值池化或者平均池化的方式得到一组权重值,也可将两种方式得到的权重值相加作为新的权重值。该权重值是整个特征层进行压缩得到的,因而具有全局的感受野,通过压缩后权重的通道维度和数据的通道维度保持不变。
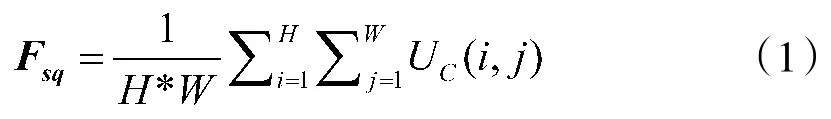
其中,Fsq是全局平均池化得到的C通道的权重矩阵。H,W表示单个通道的宽和高像素值,通过对通道上所有像素值求平均得到相对于该通道的权重值。
在多级联残差块后添加通道注意力机制,通道注意力的具体实现方式如图3 所示。

图3 注意力机制
如图4 所示,伪装的存在,背景中的目标难以被有效发掘,特征很难提取。注意力机制的嵌入,增大了有效特征的权重,待检测的目标区域成为焦点区域,抑制迷彩对目标特征的伪装效果,提高了特征有效性表达。

图4 添加注意力机制后效果图
从图4 可以看出,添加了注意力模块之后,部分图像中待检测目标的有效特征权重进行了增强,被进行了重点关注,图中颜色越深表示权重值越大,颜色越浅,权重值越小。
2.4 改进的算法模型
在YOLOv3 的基础上,对现有数据先验框信息进行挖掘,利用K-means 算法对先验框进行了重聚类(聚类中心数为9),计算出了当前数据集下9 种最佳的宽高比;接着对YOLOv3 的骨干结构进行了调整,在特征提取阶段改变了残差网络的级联方式,增加了残差块的残差边,使原先的级联方式由单级跳连改为二级跳连;并在每个残差模块之后嵌入了注意力机制进行特征提取,改进后的网络结构如图5 所示。
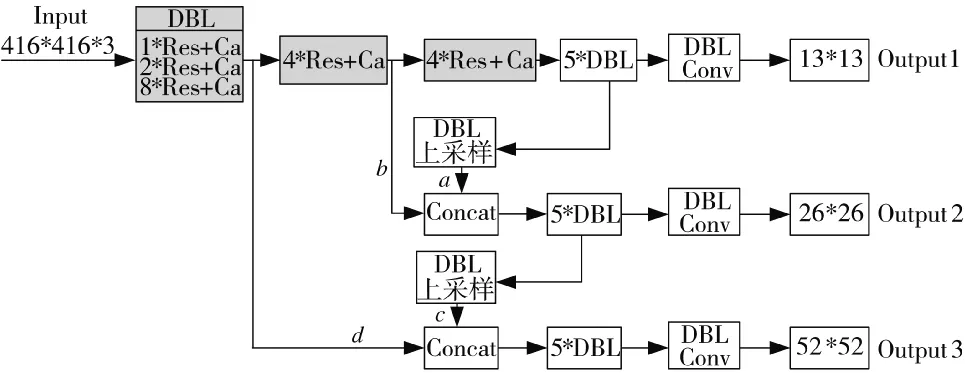
图5 改进后的网络结构
在改变了残差块级联方式的基础上,将注意力模块嵌入到每个残差块之后,利用注意力机制具有的特征筛选能力来进行特征提取。注意力模块相当于是一维卷积模块,通过全局池化+两层卷积+Sigmoid 的方式得到了相应通道的特征权重,权重的运用使得网络在进行特征提取时具有不同的偏好,是进行有用特征提取的一种有效方式。骨干网络提取的特征经过不同的卷积和上采样,借鉴了特征金字塔[18](feature pyramid networks,FPN)构造,融合了低层和深层特征,提取的特征内容更丰富。
3 实验
3.1 数据与数据增强
本次实验数据集共包含图片3 279 张,涉及丛林、雪地等不同场景,33 种不同的迷彩类型,不同的人员及其姿态。实验数据与常规目标数据相比,场景更加复杂,目标特征难以辨别,符合伪装特征。

图6 部分实验数据
为了增强模型的泛化能力,提高模型在其他类似目标检测上的良好性能,本文利用数据增强的方式扩充了数据集。通过数据扩充处理,图片数据量成倍增加,处理后的图片如下页图7 所示。

图7 数据增强扩充数据集
3.2 评价指标
两个重要的指标就是查准率(Precision)和召回率(Recall)。对于目标检测结果有4 种可能,真正例(true positive,TP)、真反例(true negative,NF)、假正例(false positive,FP)、假反例(false negative,FN)。4 种检测结果代表的含义如下,且由此可计算出Precision和Recall,如表3 所示。
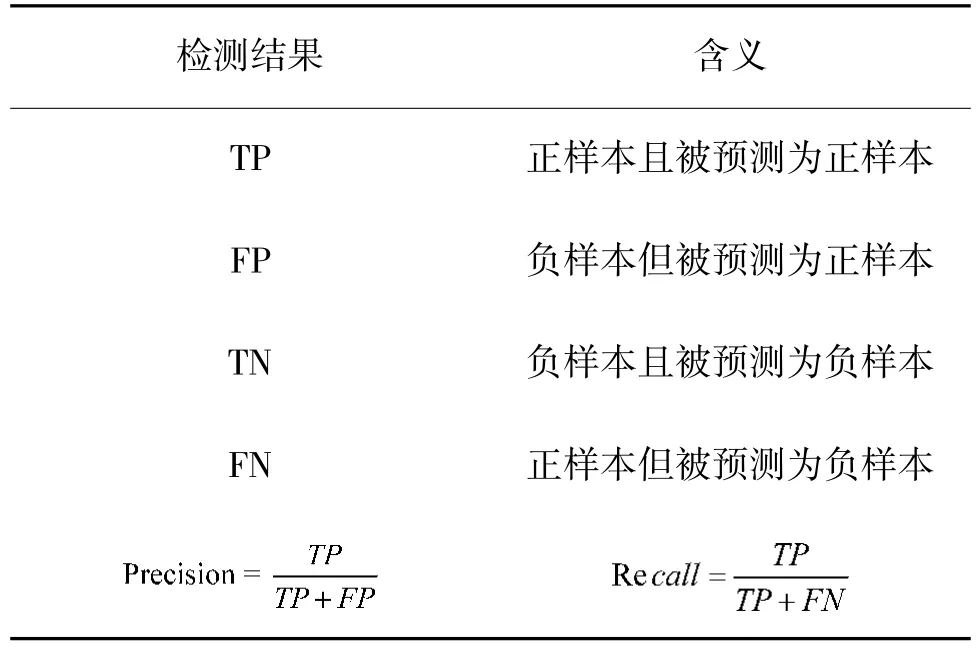
表3 检测结果分类和指标计算
通过绘制并计算P-R 曲线下方面积(也即mAP)大小来作为算法检测性能的评价指标。
采取的平均精度均值(mean average precision,mAP)作为模型的衡量指标,反映了待检测类别的平均检测精度。平均精度(average precision,AP)是描述单个类别识别精度的衡量指标,在本文中,因为只对单个目标进行检测,mAP和AP 在数值上相等。所以有

在目标检测任务中,对单张图片的检测需要计算检测的交并比[19](Intersection over Union,IoU),这是对目标识别效果的一次衡量,是作用在单张图片上的。IoU 描述的是预测框和真实框之间的重合度。IoU 愈大,重合度越高,预测就越精准。IoU 计算方法如式(3)所示,其中,A表示真实框,B表示预测框。

也可写成如下关系式:
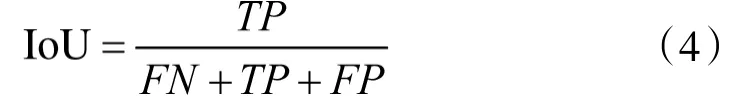
3.3 损失函数
在目标检测任务中,对一个目标的检测包括判断物体的位置、类别以及置信度,所以在YOLOv3中,对应的损失包括的位置损失、类别损失和置信度损失3 类。3 类损失函数的计算如下:
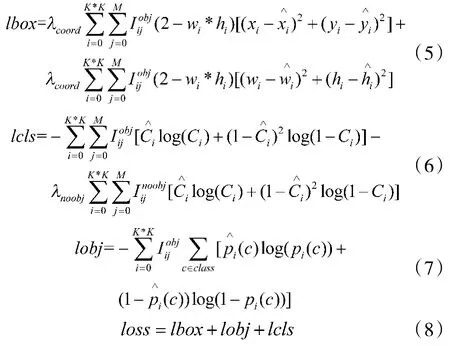
式中,lbox、lcls和lobj分别代表位置损失、置信度损失和类别损失。在位置损失中,是调节系数,K*K代表YOLOv3 的13*13,26*26,52* 52 3 种输出,M代表着候选的数量,实验中设置M=9,代表着对候选框内是否包含物体的判断,有物体则,否则为0。在置信度损失中,Ci为决定矩形是否负责预测某一物体,如果是,则Ci=1,否则为0;,是对候选框是否不负责预测目标的判断。在类别损失中,为标记为类别c的真实值,如果属于类别c,则,否则为0。和分别为权重系数。
3.4 实验结果及分析
本文模型基于Pytorch 架构,在显示内存为6 GB 的GeForce GTX 1660 Ti GPU 上运行。实验过程中没有采用YOLOv3 预训练权重,实验数据90%用于训练,10%用于验证。实验中实验参数和含义如下页表4 所示。

表4 实验参数及其含义
本次实验图像输入大小调整为416*416,初始学习率设定lr=0.001,迭代次数iterations=250 次,批处理大小Batch_size=8。对比了不同的级联方式下训练过程中训练损失和验证损失情况。结果如图8所示。

图8 改变级联方式前后损失曲线对比
分析图8 中曲线可知,在不增加其他模块的情况下,模型在当前学习率下训练时,虽然含有两条残差边的模块收敛速度略低于改进前,但误差在网络中反传的效果有所增强。无论是训练损失还是验证损失,含有两条残差边模块的网络收敛效果优于只含一条残差边模块的网络,收敛效果更好。
保持学习率lr=0.001,迭代次数iterations=250,批处理大小Batch_size=8 不变的情况下,在残差网络之后增加了通道注意力模块,并进行实验验证,绘制出训练和验证损失曲线图,实验结果如图9所示。

图9 添加注意力模块前后损失曲线对比
与原始模型相比,增加了注意力机制的模型在误差反传效果上有所改善,收敛值有所降低,证明了在残差网络中增加注意力机制方式的有效性。
接着,在实验过程中采用了不同的训练方式。与上面实验不同的是,实验起初仍然设定初始学习率lr=0.001,Batch_size=8,在训练了一定的轮次后,设定学习率lr=0.000 1,Batch_size=2,总的iterations=250 次不变。相当于整个实验采用了初始学习率不同的两个阶段,并同时结合了以上两种改进方式与原始算法以及添加不同模块的方式进行了对比,损失曲线如图10 所示。

图10 调整学习率前后损失曲线对比
从实验效果来看,调整不同的学习率进行训练,在训练约20 轮之后,将学习率从0.001 调整至0.000 1,并结合改进的网络模型,算法的收敛效果优于原始网络模型,并优于只改变级联方式或只增加注意力模块的情况。实验对比了改进后的模型和原始模型的mAP 值,结果如图11 所示。
从图11 可以看出,改进前算法模型的平均精度均值为70.14%,改进后为74.49%,改进后的模型在平均精度均值上要优于原始算法,算法精度大约提高了4.35%,验证了改进后算法的有效性。
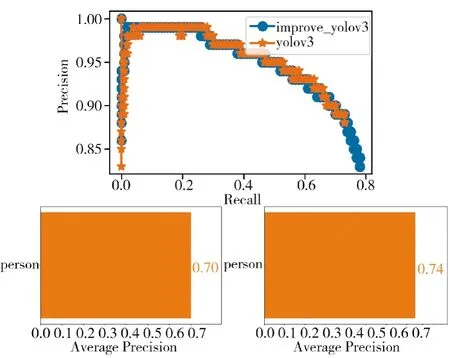
图11 改进前后的P-R 曲线和mAP 对比
在同一伪装目标数据集下,将改进后的算法与Faster-RCNN,SSD,YOLOv3 原始算法进行了对比。Faster-RCNN和SSD 分别是两阶段和一阶段典型算法[20-21]。对比结果如下页表5 所示。
从表5 可以看出,改进后的算法相比Faster-RCNN,SSD和改进前的YOLOv3 算法,算法检测精度有了提升,尤其是在综合了以上3 种改进之后,检测精度有了显著提升。
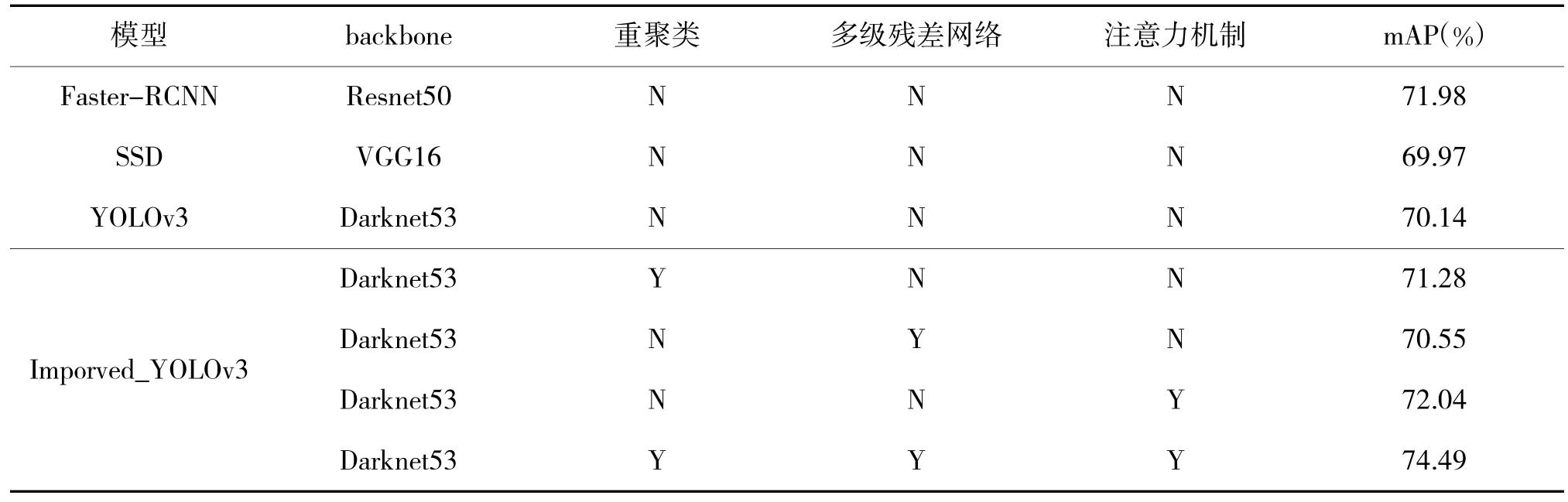
表5 不同模型的mAP 对比

图12 部分检测结果对比
4 结论
针对YOLOv3 算法对伪装目标检测精度不高的问题,本文提出了一种改进的YOLOv3 伪装目标算法。首先基于现有数据,通过K-means 聚类算法对先验框进行了重聚类,重聚类后的先验框对数据具有更好的贴合效果;接着改变了残差模块内部的连接方式确保了在增加网络层数的情况下,网络模型依然具有良好的训练效果,并将注意力机制嵌入到特征提取网络中。
实验结果表明,在调整了先验框的基础上,改变残差模块的级联方式和增加注意力机制后,算法的收敛性能更好,具有较低的损失值。与原始算法相比,改进后的算法收敛值更小,平均精度更高,平均检测精度大约提到了4.35%。
