级联特征融合孪生网络目标跟踪算法研究
2022-03-22王景芹王敬涛孟军英
韩 明,王景芹,王敬涛,孟军英
1.石家庄学院 计算机科学与工程学院,石家庄 050035
2.河北工业大学 省部共建电工装备可靠性和智能化国家重点实验室,天津 300130
目标跟踪技术作为计算机视觉的主要研究内容之一,越来越受到广泛关注,在智能交通管理、视频监控、自动驾驶、军事侦察等多领域具有广泛的应用[1-2]。目标跟踪的任务是估计目标在图像序列中的轨迹。然而目前大多数算法是依赖于第一帧图像,使得目标跟踪利用有限的训练数据创建一个适用于各种外观变化的跟踪器[3]。但是,当出现光照变化、目标旋转、目标尺寸巨变、背景相似物干扰、遮挡等情况时,对目标的准确有效跟踪提出了严峻的挑战。当下最流行的目标跟踪算法是基于深度学习和相关滤波器的目标跟踪器。
随着深度学习的发展,最近,基于Siamese网络架构的跟踪器[4-7]由于其出色的跟踪性能,特别是对跟踪准确性和速度的良好平衡性,引起了广泛的关注。孪生网络算法采用两个网络分支,分别提取目标和候选目标的特征,将目标跟踪问题转化为了相似度计算问题。Bertinetto等人[8]提出的SiamFC是一种端到端的全卷积孪生网络跟踪模型,SiamFC跟踪器将视觉目标跟踪任务定义为目标匹配问题,使用全卷积网络结构,离线训练网络参数,通过学习目标模板的特征表示与搜索区域之间的互相关操作来计算两者的相似度,得到一张响应图,然后根据响应图判断目标出现的位置。由于一个单一的相似图包含有限的空间和语义信息,许多研究学者也提出了大量的改进方法,使得目标跟踪更加高效准确。
SiamFC[8]算法是以AlexNet[9]作为主干网络的孪生网络跟踪器,但是轻量级的卷积神经网络AlexNet对于复杂环境下的目标跟踪效果较差,尤其是处理复杂环境问题(旋转、光照变化、变形、背景相似等)时,容易出现跟踪漂移和跟踪丢失的问题。随着更深更宽的深度神经网络的研究,一些学者用更深更宽的网络取代前景网络。SiamVGG[10]算法采用更深层的VGG-16网络替代SiamFC中的AlexNet网络进行大数据集上的训练,充分利用VGG-16网络的特点提取目标高维特征,实现高效准确跟踪。SiamDW[11]为了实现对更广更深网络的应用,首先,基于“瓶颈”残差块,提出了一组内部裁剪残差(CIR)单元。CIR单元裁剪出块内受填充影响的特征,从而防止卷积滤波器学习位置偏差。然后,通过CIR单元的堆叠,设计了更深网络和更宽网络两种网络架构。通过实验对比发现基于“残差块”的主干网络跟踪器在跟踪性能上都有较大的提升。DenseNet[12]孪生网络目标跟踪算法将全局上下文特征模块嵌入到孪生网络分支,将DenseNet网络作为了孪生网络框架,从而实现目标深度特征的提取,提高跟踪精度和鲁棒性。
SiamRPN[13]算法引入区域提议网络(region proposal network,PRN),其中孪生网络用于提取特征,RPN用于产生候选区域,跟踪器回归目标位置大小,不需要进行多尺度测试。RPN网络又分为两个分支,一个分支用来对目标和背景进行分类实现判别区分;另外一个分支用来微调候选区域实现回归,从而适应目标尺度变化,提高跟踪精度和速度。SiamRPN++[14]算法在SiamRPN算法的基础上增加干扰-感知训练和增量式学习,主要目的是解决现有的孪生网络框架的平移不变性限制,采用空间感知采样策略,设置均匀分布不同偏移量,从而在SiamRPN网络上实现多层特征的融合,提高跟踪性能。DSiam[15]算法(dynamic siamese network)为解决离线训练的问题,提出动态孪生网络,通过动态在线调整学习模型,实现在线学习历史数据上的目标外边变化以及背景抑制。该算法能够直接在视频序列上进行整体训练,并能够充分利用目标的时空特征。DasiamRPN[16]算法主要解决运动目标周围干扰问题,通过目标周围干扰物感知模型,实现类内区分,解决跟踪漂移问题,并利用Local-to-Global策略解决长时间跟踪问题。SiamMask[17]算法在SiamFC基础上增加了Mask分支,同时解决了视频目标跟踪与目标分割问题,利用优化模块提高分割精度。该算法仅利用初始帧的一个边界框即可实现无类别差的实时目标分割与跟踪。SiamCAR[18]算法通过anchor-free的策略,将网络的回归输出变成了特征图映射在搜索区域上点与选定的目标区域边界(样本标注gt,ground-truth)四条边的距离。通过观察分类得分图和中心度得分图,决定最佳目标中心点。然后提取最佳目标中心点与gt框四条边的距离,得到预测框,从而实现跟踪。但是,SiamCAR算法将预测的位置映射到原始图像可能会导致偏差,从而导致跟踪过程中的出现漂移。
最近,注意力机制与孪生网络相结合被广泛地应用到各种目标跟踪任务中,商汤科技的王强提出的RASNet[19]算法在孪生网络中引入残差注意力机制实现目标的高性能跟踪,但是该算法只考虑了模板信息,从而导致限制了其特征表达能力。为了解决这一问题,SiamAttn[20]算法提出了可变形的孪生注意力网络,提出自注意和跨分支注意相结合实现模板互相聚合和搜索分支的上下文特征提取,更好地挖掘孪生网络的特征注意力的潜在特征,同时结合变形操作来增强目标的可识别性表达,提出了一种隐式的模板更新,最后通过区域细化得到更加精确的回归框。成磊等人[21]引入残差网络形式的注意力机制和特征融合策略,提出了添加残差注意力机制的视觉目标跟踪算法,该算法通过级联的方式融合网络的深层和浅层特征,进一步丰富目标定位信息,在网络训练过程中利用区域重叠率损失函数对网络输出进行优化,最终实现目标的长时间准确跟踪。王玲等人[22]在孪生网络模板分支中融合通道注意力和空间注意力,提出了融合注意力机制的孪生网络目标跟踪算法,该算法通过抑制背景信息提高正样本辨识度,离线训练模型实现对跟踪目标的深层和浅层特征的提取与融合,从而实现对目标漂移和复杂背景下的目标准确跟踪。程旭等人[23]将时空注意力机制引入到孪生网络,实现空间和通道位置的目标特征提取,通过模板在线更新机制实现图像特征融合,降低目标漂移的风险。
为了提高目标跟踪的准确性,近几年一些学者通过特征融合实现对目标信息的准确提取。Yuan等人[24]提出了多模板更新的无锚孪生网络目标跟踪算法,采用了一种基于多层特征的双融合方法将多个预测结果分别进行组合。将低级特征映射与高级特征映射连接起来,充分利用空间信息和语义信息。为了使结果尽可能稳定,将多个预测结果相结合得到最终结果,但是该算法网络结构复杂,算法的实时性较差。
YCNN[25]算法结合浅特征和深特征。深度特征用于区分物体和背景,浅特征用于表示物体的外观。提出了一种针对目标任意外观的目标跟踪方法,双流卷积神经网络,该算法经过网络训练之后适用于所有的对象。该算法帧率为45 frame/s,性能相对较高,但是该算法在光照条件变化、遮挡运动模糊等情况下,跟踪性能较差。为了进一步提高跟踪的识别能力,文献[26]中的跟踪器融合hog特征作为形状来解决拥挤场景中的遮挡问题。Zhai等人[27]提出了一种基于CF的融合跟踪方法,然而,该方法的跟踪精度不够好,鲁棒性不强。
这些跟踪器融合了hog特征、颜色特征,以及不同深度的CNN特征,但是却没有考虑空间信息在跟踪中的重要性。
为了在特征学习中融合空间信息,跟踪器SRDCF[28]提出了一种空间正则化相关滤波器,该滤波器在优化模板时对KCF引入了空间正则化。Lan等人[29]提出了一种高精度的融合跟踪算法,但速度仅为0.7 frame/s,与实时速度相差甚远。这些慢速跟踪器在实际应用中很难应用。考虑到不同的特征信道适应不同的跟踪场景,文献[30]中的跟踪器采用聚合的信道特征来提高对交通标志的鲁棒性,该算法对于复杂的交通环境下的目标跟踪准确性大大提高。
虽然基于孪生网络的目标跟踪取得了长足的发展,然而,视觉目标跟踪算法仍然受到一些问题的困扰。首先,大多数Siamese跟踪器使用较浅的分类网络(如AlexNet)作为骨干网络,但未能利用较深网络结构中较强的特征提取能力。其次,在匹配跟踪中,只使用了包含更多语义信息的最后一层特征,而低层空间特征对跟踪性能的影响还没有得到充分的探索,有些算法虽然采用了特征融合操作实现特征提取,但是大多局限于通道特征和空间特征的融合,或者是简单的深层和浅层特征的简单应用,导致深层特征分辨率较低,语义信息应用不充分。然后,这些算法大多是依赖于第一帧图像作为模板图像,当光照变化、目标变形、背景相似物干扰、目标遮挡时,模板容易失效,出现目标跟踪丢失的问题。
本文提出了基于多级特征融合孪生网络目标跟踪算法,该算法建立在ResNet-50[31]网络上。主要贡献如下:
(1)为了更好地利用深层网络的特征提取能力,对ResNet-50网络进行改进,包括网络步长、感受野,以及空间采样策略等,减少模型参数和计算量,从而提高模型的跟踪速度。
(2)将ResNet-50的最后一阶段的3层特征进行逐级级联融合,充分利用高层语义信息与浅层空间信息,从而实现对复杂环境下目标的准确跟踪。
(3)引入模板更新机制解决目标跟踪过程中目标模板退化的问题,利用相似度阈值法进行模板更新。
(4)本文算法在OBT2015、VOT2016和VOT2018公共跟踪数据集上进行实验,并取得了良好的跟踪效果。
1 基于级联特征融合孪生网络算法
1.1 网络整体架构
本文算法基于SiamRPN[13],整体流程如图1所示。该网络架构由ResNet-50组成的主干网络、特征融合模块、结果预测模块、模板更新模块组成。本文采用改进的5阶段的ResNet-50作为孪生网络的主干网络,该网络主要负责提取模板图像和搜索图像的浅层和深层特征;特征融合模板主要实现对模板分支和搜索分支的最后一阶段3层特征的逐级级联融合;然后将级联融合之后的获得特征图进行交叉互相关计算;最后通过无锚框网络将融合后的特征进行目标的分类和回归,实现结果的预测。在模板分支中引入模板更新模块,通过相似度阈值法实现对模板的动态更新,保证随着跟踪时间的增加模板自适应变化。

图1 级联特征融合网络架构Fig.1 Network architecture of cascading features fusion
多特征融合方法在目标分割与目标跟踪中能够有效地提高算法精度[32-33],通过对图像在神经网络中进行卷积运算,可以得到图像不同的浅层外观特征和深层语义特征。由于卷积特征的不同层次特性,不同层次的特征可以相互补充,因此通过特征融合是非常有效地提高跟踪精度的直接方法。在SiamFC等后续的孪生网络跟踪器中,大多只讨论了最后一层特征对目标跟踪的影响,而忽略了深层特征,导致丢失了大量的深层细节信息,尤其是当背景与目标属于相同或者是相似的语义特征时,目标跟踪过程容易出现跟踪丢失的现象。多层特征融合指的是沿通道维度方向对不同层次特征进行融合,可以通过在通道上添加元素或者是直接连接元素从而获得通道上的更多特征。
残差网络使得网络的深度得到了极大的释放,使得目标检测和语义分割任务的骨干网络逐渐地被ResNet[34]结构所取代,通过在骨干网络中增加填充结构实现网络的高分辨率特征提取,然而如果简单地使用VGG[35]、ResNet或其他更深层次的网络代替Siamese框架中的骨干网络AlexNet[9],则会导致性能下降。
SiamRPN++[14]调整正样本采样策略,训练更深层次网络驱动的Siamese跟踪器(如ResNet[22]),并提出多层聚合模块,进一步利用更深层次的特征,打破了Siamese跟踪器与深度网络之间的差距。SiamDW[11]通过对网络的内在因素进行了非常详细的消融分析实验,实验内容包括AlexNet[9]、ResNet[34]、VGG[35]和Inception[36]骨干网络的步长、填充和感受野等因素。通过实验得出了如下结论:
(1)Siamese跟踪器更中意于中层水平特征,通过实验表明4或者8的网络步长更由于16的网络步长。
(2)感受野的比例对骨干网络不敏感,输入样本图像的60%~80%可以是经验有效的。
(3)网络填充导致空间偏差,对跟踪性能有极大的负面影响。采用适当偏移的空间感知采样策略可以避免对目标产生较大的中心偏差。
实验表明使用更深层次的模型和更合理的训练策略可以显著提高孪生网络跟踪器的性能。
通过上述分析,本文采用改进的5阶段的ResNet-50作为孪生网络的主干网络构建目标跟踪框架。ResNet-50会随着网络层次的加深提取更深层的图像特征信息。网络改进如下:
(1)由于中浅层视觉特征在Siamese网络跟踪器中表现良好,为了平衡目标跟踪的准确性和效率。将Res4和Res5块的原始步幅从16和32像素减少到8像素,并通过扩张卷积操作增加感受野。
(2)采用空间感知采样策略对整个网络进行训练,解决深层网络中填充造成的绝对平移不变量破坏问题。
(3)为了减少参数的数量,通过1×1卷积操作将多层特征映射的通道改变为256。由于模板特征的空间大小为15×15,为了减少网络的计算负担,将中心7×7区域裁剪为模板特征,其中每个特征单元仍然可以捕获整个目标区域。
本文的骨干网络模板分支和搜索分支具有相同的卷积结构和相同的网络参数。
浅层特征主要包括颜色、形状和边缘等空间信息,对于目标位置标定更具有意义。深层特征包含更多的语义信息,对于目标跟踪过程中识别相似物干扰、遮挡和形变具有更重要的意义。因此本文充分利用Resnet-50网络的最后一阶段的3层进行特征的逐级融合。
1.2 特征融合模块
特征融合模块主要是研究将残差网络的最后三个残差块Res3、Res4、Res5进行级联融合,实现图像特征提取。该特征融合模板实现了通道识别基础上的整体的特征提取,通过逐级融合,有效融合了不同层的特征,特征融合模块结构如图2所示。该模块结构以R5和Res4为例进行说明。其中R5是经过Res5通过3×3的卷积获得的特征图,该特征图保持空间分辨率不变,并将通道的数量变成256。
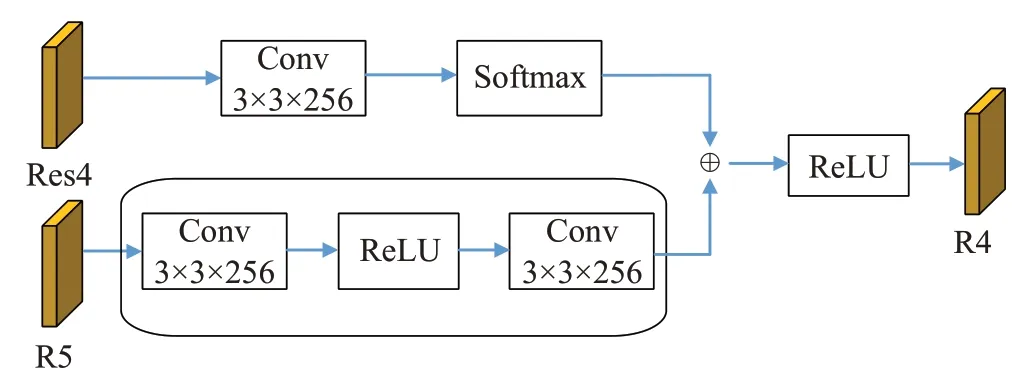
图2 特征融合模块Fig.2 Feature fusion module
本文使用改进的ResNet-50进行特征提取,该特征融合模块首先经过Res4之后的输出特征使用一个3×3的卷积核(通道数为256)和一个Softmax函数,来感知整体特征中每个特征点的注意力特征权重,这里的特征权重主要是指的上下文特征中的每个特征点的权重。然后,R5通过2个3×3的卷积核(通道数为256)和一个ReLU函数,实现特征转换,并获取通道间的依赖。最后采用逐像素相加和ReLU运算,将整体特征与通道识别的特征实现在每个位置上的融合,得到语义更加丰富但是具有相同分辨率的融合结果R4。同理Res3与R4融合得到R3特征,并将R3、R4、R5用于后续跟踪过程中。
使用特征融合机制可以得到更加丰富的上下文特征信息,以及具有相同分辨率的特征图,从而提高后续目标跟踪的效果。
1.3 跟踪框回归
本文通过端到端的卷积来训练网络,其中主干网络在ImageNet-1K[37]上进行预训练,利用ILSVRC[37]的图像对训练整体网络,其中ILSVRC包含大约4 500个视频,共计约100万个注释来描述不同跟踪场景。在训练过程中随机挑选一帧图像,剪裁包含目标的127×127的区域作为目标模板,然后在搜索图像上剪裁255×255的搜索框大小,生成训练样本,其中最大间隔为50帧。通过以上训练实现对每个目标和位置的分类与回归。
在目标跟踪过程中多数采样为正样本采样,并且使用填充方法,从而导致丢失了语义信息。虽然目前的训练方法已经增强了模型的判别能力,但是模型还是很难区分出图像中相似物干扰的情况,因此需要增加负样本采样,来学习不同语义的相似物干扰。
对于训练集来说每个图像上已经标注好的真实边框,其中Tw为宽度,Th为高度,( x1,y1)为左上角坐标,( x0,y0)为中心坐标,( x2,y2)为右下角坐标。为了有效区分采样的正负样本,以( x0,y0)为中心,以Tw/2和Th/2分别为轴长做椭圆E1,如式(1)所示:
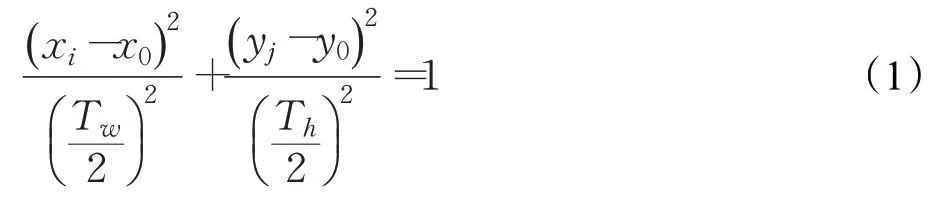
其中,(xi,yj)表示采样点的坐标位置。
同上,做以(x0,y0)为中心,以Tw/4和Th/4分别为轴长做椭圆E2,如式(2)所示:
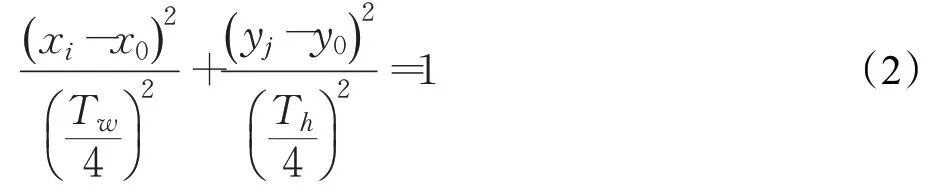
如果采样点(xi,yj)位于E2内部则为正样本,如果位于E1外部则为负样本,如果位于二者之间则忽略该样本。将标记为正样本的位置用于跟踪框回归。
回归分支中计算的回归目标可以通过目标位置距离跟踪框的距离进行表示,跟踪框计算如下:

其中,l、t、r、b分别表示目标位置到跟踪框边界的距离。
然后,计算预测跟踪框与真实边框之间的IOU(intersection over union)。仅计算正样本的IOU,其他情况IOU设置为0,因此回归损失函数定义为:


其中,λ1和λ2为超级参数。经过多次实验调参,设定λ1=1,λ2=2。
2 模板动态更新策略
基于孪生网络的目标跟踪算法中大多使用第一帧图像作为模板,通过与后续帧的相似度匹配判断是否为被跟踪目标,在跟踪过程中不再更新模板。由于使用固定不变的模板,当目标出现旋转、遮挡、变形等剧烈变化时,会出现模板匹配相似度低,导致跟踪失败。因此在目标跟踪过程中进行模板更新是非常有必要的。但是如果每帧都进行模板更新,一方面因为模板更新过于频繁导致出现跟踪漂移现象,另一方面更新频繁会导致网络整体实时性下降,因此本文采用阈值法进行更新,在必须更新时才进行更新,既满足了模板更新要求,又避免出现跟踪漂移,同时使得网络实时性损失最低。
为了解决模板动态更新问题,本文利用简单循环神经网络(RNN)学习一个模板更新子网络,模板更新公式如下:

其中,S0为第一帧图像模板,为整个模板更新过程的最真实模板,Ti为第i帧所提取的模板,Si-1为i-1帧时的历史累积模板,Si为下一帧需要匹配的最佳更新模板,F为激活函数。对于第一帧而言,需要设置Ti和Si-1均为S0。
由此可见不仅和上一帧的模板有关,还和本帧所提取的模板有关。
对于阈值更新,本文采用平均峰值相关能量APCE进行阈值评价,实现模板更新。平均峰值相关能量APCE计算公式如下:
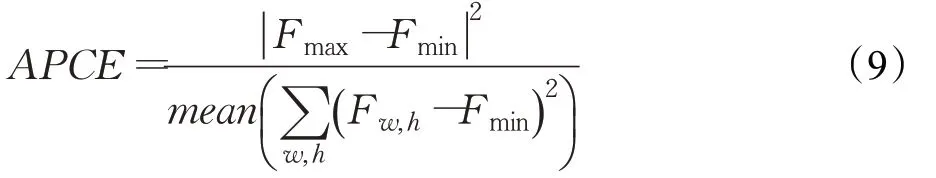
其中,Fmax和Fmin分别为响应图中的最大和最小值,Fw,h为坐标( w,h)处对应的响应值。
正常情况下当前景目标正常时响应图峰值较高,APCE值较大,并且呈现单峰状态,但是当目标形状发生剧烈变化或者是被遮挡时APCE值较小,且出现多峰,为了避免模板频繁更新,本文通过设定新旧模板之间相似度阈值的形式进行更新限定。通过APCE阈值判断是否进行更新,公式为:

其中,mean(apce)为APCE的历史均值,η为设定的APCE的阈值,当满足公式(10)时说明目标可能发生了较大的变化。为了防止发生误判断,进而通过模板相似度进行对比,模板之间卷积运算的响应值之比作为相似度S:

如果满足式(10),同时满足模板之间相似度小于式(11)设定的阈值时,通过式(8)进行模板更新。
动态模板的使用充分利用了历史帧的丰富信息,构建更加稳健的模型,同时对于目标发生剧烈变化,尤其是遮挡情况下网络具有更强的鲁棒性。
3 实验结果与分析
3.1 实验环境
本文算法运行平台配置为Intel®Xeon®CPU E5-2660 V2@3.50 GHz×40,显卡为两个NVIDIA GTX 1080Ti GPUs,共计内存24 GB。
本文使ImageNet Large Scale Visual Recognition Challenge(ILSVRC)[37]数据集进行训练,使用LaSOT[38]数据集训练模板更新模块。在ILSVRC的视频数据集上进行端到端训练。该视频数据集可以安全地用于训练跟踪的深度模型,而不会过度拟合到跟踪基准所使用的视频领域。随机选取包含相同物体的两帧。在进入跟踪网络之前,模板帧图像大小预先被调整为127×127,搜索帧图像尺寸被调整为255×255。LaSOT[38]是一个大型视频数据集,共有1 400个序列,测试集有280个序列。提供了高质量的密集注释,LaSOT[38]存在大量的变形和遮挡情况,方便实现模板更新的训练,在LaSOT[38]数据集上随机挑选20个类别的20个序列作为训练集训练模板更新子网络。
本文采用广泛使用的标准数据集OTB2015[39]、VOT2016[40]、VOT2018[41]对算法进行评估,与现有的主流算法进行比较实验,验证算法的准确性以及鲁棒性。同样,在进入跟踪网络之前,模板帧图像大小为预先被调整为127×127,搜索帧图像尺寸被调整为255×255。其中,OTB2015是视觉目标跟踪最常用的基准之一,它有100个完整注释的视频序列,对于该数据集使用两个评价指标,跟踪精度和成功率图的曲线下面积(AUC)。VOT2016和VOT2018是用于视觉目标跟踪而广泛使用的基准,二者均包含60个具有不同挑战因子的序列,VOT2018数据集用旋转的跟踪框进行标注,并采用基于重置的方法进行评估。
3.2 OBT2015数据集的定量实验
3.2.1 评价标准
对于OBT2015基准数据集上的实验,本文主要通过跟踪精度和成功率对算法进行评价。
(1)跟踪精度
设目标预测框的中心位置为( xp,yp),真实边界框中心位置为( xr,yr),则目标的跟踪精度通过二者的欧氏距离进行度量,公式表示如下:

d的值越小表明跟踪精度越高。跟踪精度的评价标准是欧式距离d小于设定阈值T的帧数占所有跟踪帧数的比例,在本文中T设定为20个像素点。
(2)成功率
目标跟踪的成功率指的是目标预测框区域Areap与目标真实边界框区域Arear的重叠率IOU,IOU计算公式如下:

IOU的值越大表明算法的跟踪成功率越高。成功率图表示重叠率大于阈值t的视频帧数占总帧数的比例,其中t∈[0,1,]在本文中取t的阈值为0.5。
本文中的跟踪准确率和跟踪成功率的计算都基于曲线下面积(area under the curve,AUC)的得分。
3.2.2 消融实验
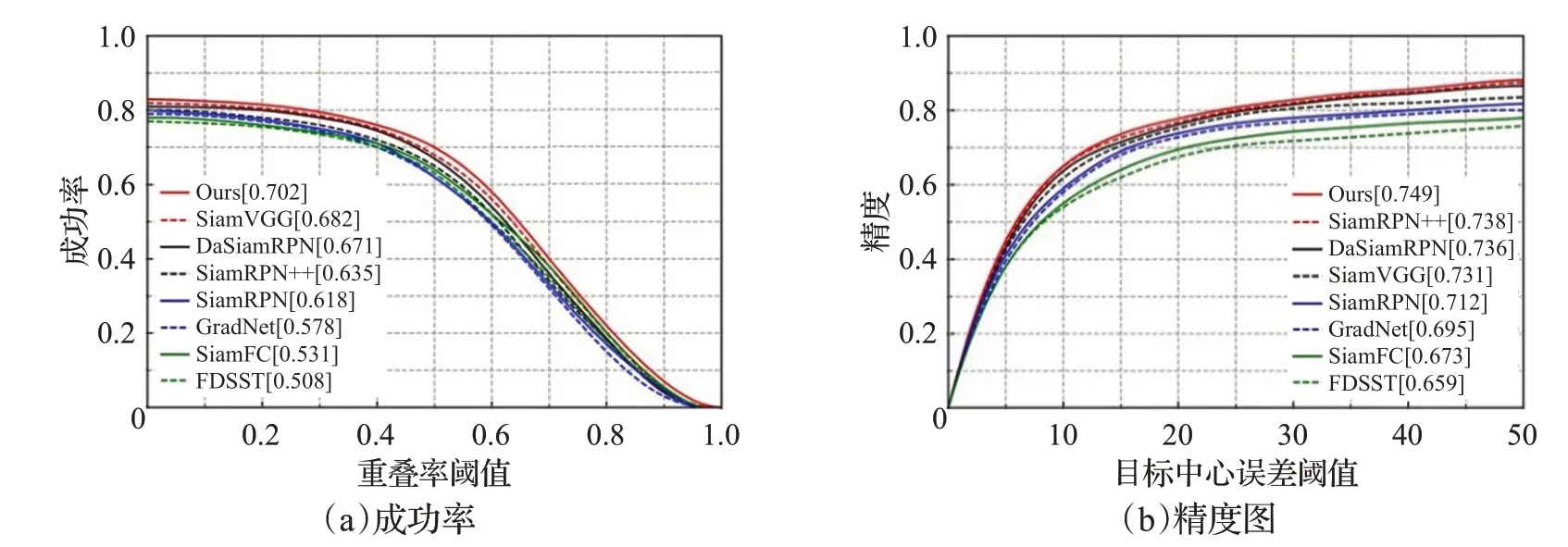
为了评价本文算法的有效性和准确性,本文选择目前主流的7种跟踪算法与本文算法进行对比做消融实验,分别是DaSiamRPN[16]、SiamRPN[13],SiamRPN++[14]、GradNet、SiamVGG[10]、SiamFC[8]、FDSST[42]。消 融 实 验结果如图3所示。由图可见本文算法的成功率和精确度分别为0.702和0.749。在成功率上相对于基准算法SiamRPN高0.084,比SiamVGG高0.02,比DiaSiamRPN高0.031。在精确度上相对于基准算法SiamRPN高0.037,比SiamRPN++高0.011,比DaSiamRPN高0.018。
通过实验对比发现,本文算法无论是精度还是成功率都有明显的提升,说明本文的级联特征融合与模板更新机制是有效的。同时本文算法在OBT2015数据集上的速度达到了41 frame/s的速度,对于目标的稳定实时跟踪是有效的。
3.2.3 定量实验
为了进一步证明本文算法对于复杂环境的适应性,本文进行进一步的定量实验。实验基准数据集OBT2015包含光照变化、遮挡、背景相似物干扰、变形、低分辨率、快速运动、平面内旋转、平面外旋转、运动模糊、快速移动、离开视野11个相关场景。通过精度图展示本文算法与以上7种算法在这11个相关场景下的对比,如图4所示。
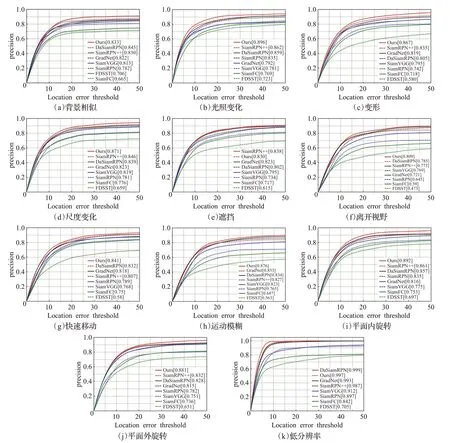
图4 11种不同场景下精度对比结果Fig.4 Precision comparison results in 11 different scenarios
由图4可见本文算法在遮挡和低分辨率两种场景下精确度相对较低,排在第2的位置,其他9种情况,均优于其他7种算法,充分证明了本文算法的有效性。
当出现光照变化、遮挡、变形、旋转、背景相似物干扰等情况时,目标的语义会因为场景的影响而发生变化,而本文充分利用级联特征深化语义特征的提取,使得目标的语义特征信息更丰富,从而使得算法的精确度更高,在光照变化中为0.896、遮挡中为0.830、变形为0.867,平面内旋转为0.892,平面外旋转为0.881,背景相似物干扰情况下为0.833。由图4中各场景下的不同算法的对比精度可见跟踪精度相对较高,充分说明本文算法中的模板更新具有积极的作用,能够使跟踪器获得更加有效的准确的语义信息,并及时更新模板,实现准确有效跟踪。
3.2.4 定性分析实验
在本实验中,将本文算法与SiamRPN++、DaSiam-RPN、SiamFC进行对比。从OBT2015中选取场景具有代表性的4组视频序列,这4组视频序列分别是ClifBar、Jogging、Lemming和MotoRilling。这四组视频序列中包含运动模糊、目标旋转、尺寸变化、目标与背景相似、光照变化、遮挡等多种复杂场景,几种对比算法的跟踪效果如图5所示。

图5 OBT2015视频序列中不同算法的对比结果Fig.5 Comparison results of different algorithms in OBT2015
在ClifBar、Lemming、MotoRolling视频序列出现了背景相似干扰、目标旋转、目标尺寸变化、光照变化、运动模糊、遮挡等多种复杂情况。由图可见,本文算法通过级联特征融合,有效提取目标的语义特征和位置特征,增强了对目标重要特征的准确表达,因此本文算法针对以上复杂情况也能够实现准确定位目标,实现目标的有效跟踪。SimaRPN和DaSiamRPN算法相对跟踪精度较差,并且在模糊和旋转情况下由图可见跟踪的重叠率和成功率降低,而SiamFC则出现跟踪丢失的现象,但是在后续的背景简单情况下又实现了目标的重定位和重新跟踪的情况,整体性能较差。
在Jogging、Lemming视频序列中主要针对遮挡情况下的实验验证,本文算法因为采用了模板更新机制,使得在遮挡情况下能够实现目标准确跟踪,但是SimaRPN、DiaSiamRPN和SiamFC算法则出现了跟踪丢失的现象,当目标再次出现时虽然SimaRPN、DiaSiam-RPN能够重新跟踪,但是重叠率较低,而SiamFC则出现了完全跟踪失败的现象。
通过以上定性实验分析,表明本文算法能够有效适应复杂环境变化,进一步证明了本文算法的有效性,以及应对复杂环境的较强鲁棒性。
3.3 VOT2018数据集实验
本文为了验证算法应对光照变化、遮挡、尺寸变化、背景相似、目标旋转等复杂情况下的挑战,测试本文算法在VOT2016和VOT2018上的表现,并将之与近几年的先进算法进行比较。该评估通过VOT(visual object tracking)官方工具包执行,评价指标包括准确度(accuracy)、鲁棒性(robustness)和期望平均重叠(expected average overlap,EAO)。
测试结果如表1所示,EAO在VOT2016和VOT2018上不同算法的对比结果如图6所示。由表1可见,本文算法在VOT2016上的结果优于DaSiamRPN、SPM等算法,在精度上与SPM相同,鲁棒性上与ECO相同,但是均优于其他算法。相对于基准算法SiamRPN则在精度上提升了6%,在鲁棒性上提升了6%。在VOT2018的结果上精度略低于SiamRPN++,位于第二的位置,在鲁棒性上则与SiamRPN++持平,相对于基准算法SiamRPN则在精度上提高了10%,在鲁棒性上提高了23%。从图6中的EAO对比可见本文算法在VOT2016上均高于其他算法,在VOT2018上则相对低于SiamRPN++,位于第二的位置。从结果分析可见本文算法在对比跟踪器中取得了良好的竞争力。
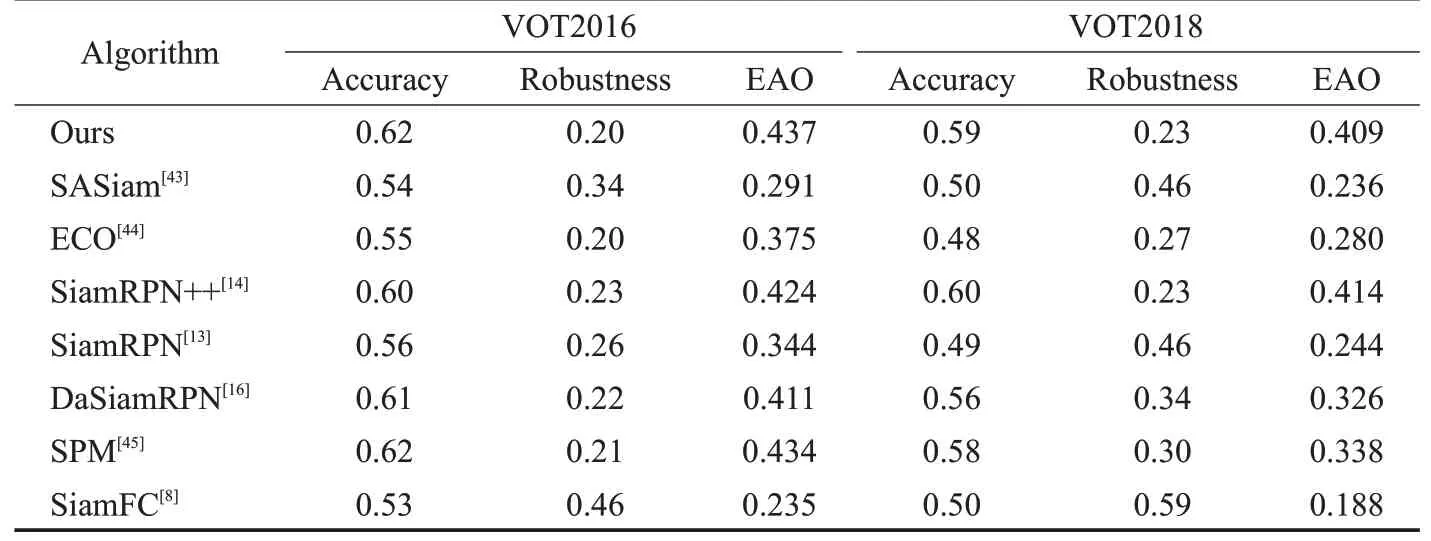
表1 不同算法在VOT2016和VOT2018上的测试结果Table 1 Results of different algorithms on VOT2016 and VOT2018

图6 不同算法在VOT2016和VOT2018上的EAO对比结果Fig.6 EAO comparison results of different algorithms on VOT2016 and VOT2018
4 结论
本文提出了一种端到端的级联特征融合的孪生网络目标跟踪算法,该算法以ResNet-50作为骨干网络,并通过减少模型参数,提高计算速度等方法进行了改进,从而提高跟踪器的特征提取能力。然后将ResNet-50的最后一阶段的3层特征通过特征融合模块进行逐级级联融合,实现目标浅层外观特征和深层语义特征的有效融合,提高目标的有效识别和定位。同时为了解决目标模板退化问题,实时适应目标的外观和状态变化,引入模板更新机制,通过相似度阈值解决模板更新问题。该算法的模型训练弥补了不同特征在跟踪效果上的缺陷,算法通过在OBT2015、VOT2016、VOT2018上的实验表明,本文提出的级联特征融合网络有效提高了跟踪器的通用性,在快速运动、运动模糊、遮挡、背景相似、光照变化、变形等复杂场景中取得了优异的性能。未来,将继续探索深度特征在目标跟踪任务中的有效集成。
