改进标签一致KSVD字典学习的人脸识别算法*
2022-03-22严春满张昱瑶
严春满,张昱瑶,张 迪
(西北师范大学物理与电子工程学院,甘肃 兰州 730070)
1 引言
人脸检测与识别是图像处理领域的热门研究课题,也是具有挑战性的计算机视觉问题。人脸作为一种生物特征,能够直观地反映个体之间的差异,是进行个人身份识别的载体。人脸识别率容易受到表情、光照变化和年龄等因素[1 - 3]的影响。早在20世纪50年代,学者们就开始关注人脸识别相关内容的研究。到了60年代,研究人员主要通过分析面部特征点(如眼睛、鼻子和嘴巴)之间的距离和拓扑关系实现人脸识别[4,5]。这种方法简单直观,但识别精度易受影响。1991年,特征脸Eigenfaces[6]算法将人脸图像投影到低维特征空间,在识别效果上得到有效提升,这一创新思路为后续的研究奠定了基础。Belhumeur等[7]提出基于线性判别分析的Fisherface算法,能够在低维子空间中产生良好的分离效果。2009年,Wright等[8]将稀疏表示应用到人脸识别领域并提出了基于稀疏表示分类的人脸识别SRC(Sparse Representation based Classification)算法,在含噪声污染及光照变化等复杂环境下的人脸识别问题上取得了较好的识别率。该算法利用所有样本来构成字典,测试样本依据最小残差分类。与传统的识别方法相比,SRC无需提取精确的脸部特征,但该算法的字典生成需要用到所有的训练样本,当训练样本数量多且图像的维数较大时,字典维数相应增加,导致稀疏分解部分耗时较长。为了解决这一实际问题,又提出了一系列改进SRC的算法。扩展稀疏表示分类ESRC(Extended Sparse Representation-based Classifier)算法在SRC的基础上构造了一个类内差异字典,可以与其它类别共享类内差异[9]。Deng等[10]提出了一种基于叠加模型的稀疏表示分类SSRC(Superposed Sparse Representation-based Classifier)算法,该算法从每一类的训练样本中提取共性特征和相对特征构造字典。基于Gabor特征稀疏表示算法GSRC(Gabor-feature based SRC)改善了人脸遮挡情况下的计算复杂度[11]。以上算法在人脸识别问题中取得了较好的识别效果,但当训练样本过多时会增加算法的复杂度,占用更多的存储空间。所以,通过字典学习来解决人脸识别问题受到越来越多研究者的关注。
目前,字典学习算法主要分为2大类:无监督式字典学习和监督式字典学习。在无监督式字典学习算法中,Engan等[12]提出了最优方向方法MOD(Method of Optimal Direction),该方法旨在选择一个误差减小最快的最优方向,是最早提出的经典字典学习方法之一。Aharon等[13]提出了KSVD算法,该算法在最优方向方法的基础上对字典更新阶段进行了优化。Mairal等[14]提出了Online字典学习算法,获得了更高的运行速度。与无监督式字典学习算法不同,监督式字典学习算法在训练阶段用到了样本的类别标签信息。 Yang等[15]提出了一种基于 Fisher 判别准则的字典学习FDDL(Fisher Discrimination Dictionary Learning)算法,该算法将 Fisher 判别准则融入到字典学习过程中,学习字典原子与类标签对应的结构化字典,利用稀疏编码后的重建误差进行分类。Zhang等[16]提出了判别KSVD字典学习算法D-KSVD(Discriminative KSVD),该算法将分类误差引入到目标函数中来扩展K-SVD算法。Jiang等[17,18]在D-KSVD算法的基础上进一步提出了标签一致KSVD字典学习算法LC-KSVD(Label Consistent K-SVD),在判别性字典学习算法的基础上新增了稀疏码误差来提高字典的判别能力,但是该算法只考虑了字典原子的类标特征,而忽略了它们之间的相似性特征,对提高字典的判别性能有限。
本文提出一种基于改进标签一致KSVD字典学习的算法并应用于人脸识别,在有光照变化的Extend Yale B人脸库、表情变化以及遮挡影响的AR人脸库上的实验结果表明,本文算法相比于对比算法有较高的识别率,同时对噪声污染条件下的人脸识别具有较好的鲁棒性。
2 稀疏模型及LC-KSVD算法原理
2.1 稀疏表示模型
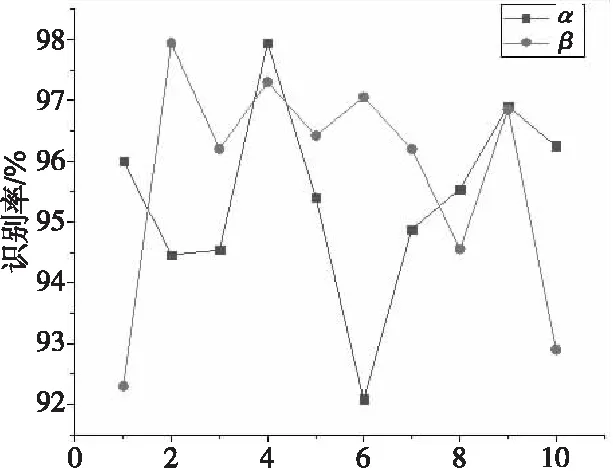
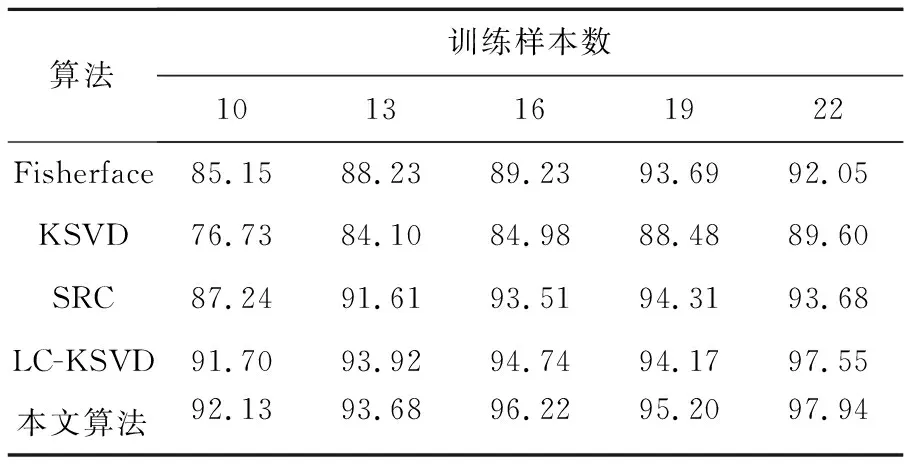
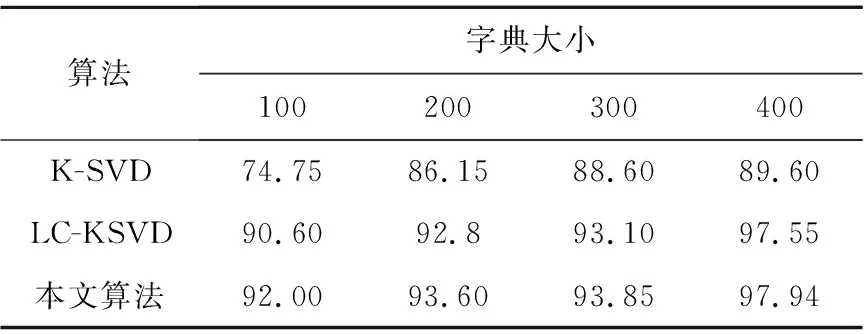
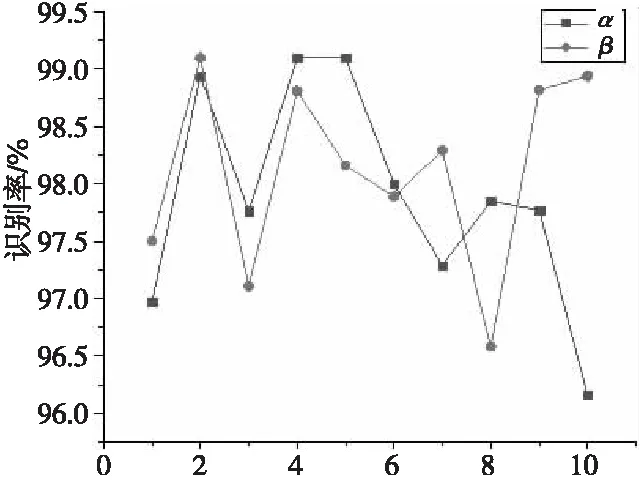
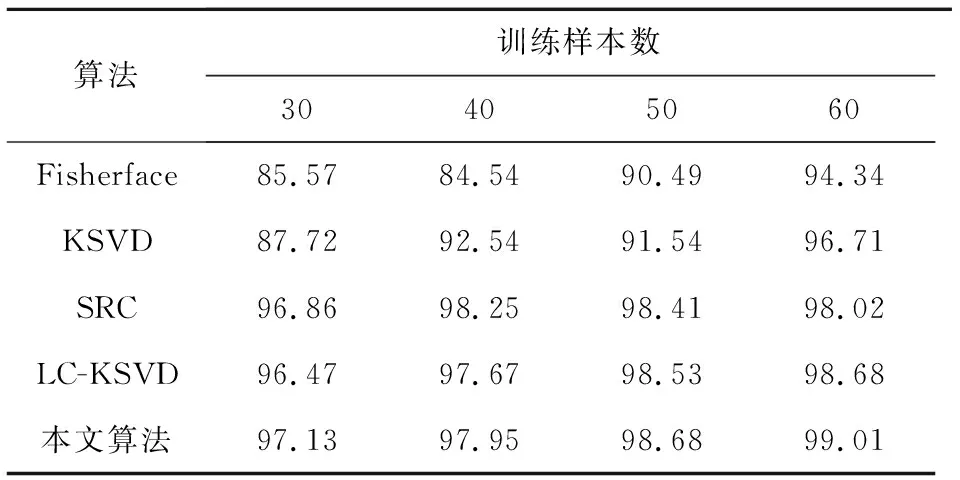
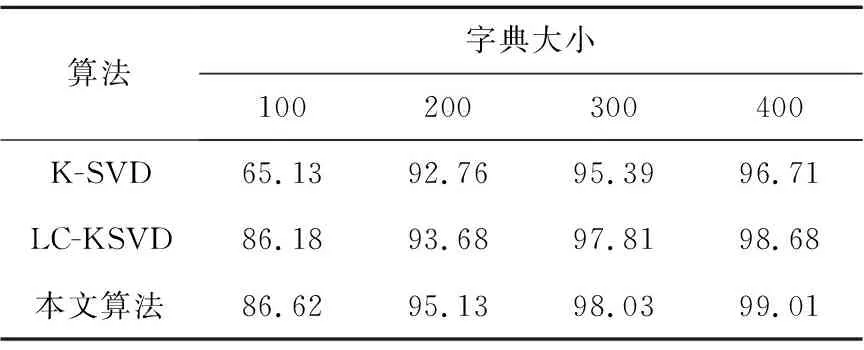
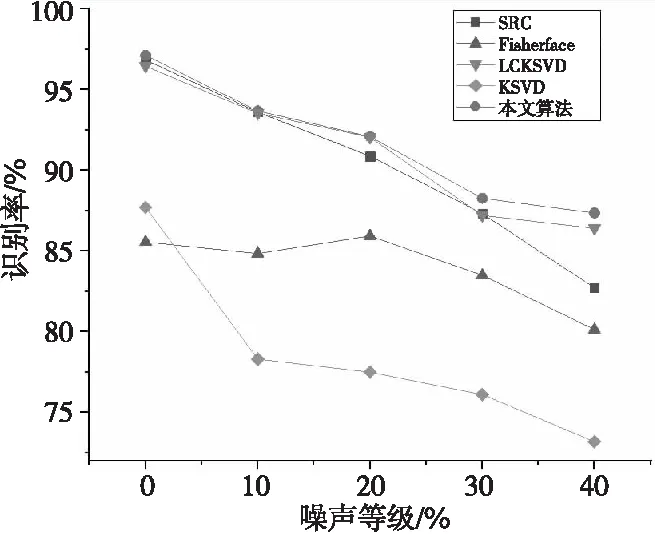
从数学角度看,稀疏表示是针对不确定方程组Ym×n=Dm×KXK×n求解提出的。当m min‖X‖0 s.t.DX=Y (1) 其中‖X‖0是X的L0范数,表示非零元素的个数。 在实际应用中,多数情况下是近似表示的情形,因此把式(1)的求解问题转化为: min‖X‖0 s.t. ‖DX-Y‖2≤ε (2) 其中,ε是与噪声相关的参数。求解min‖X‖0是一个NP-hard问题,L0范数最小化问题可以近似等价于求解L1范数的最小化问题,式(2)可以转化为如下形式: min‖X‖1 s.t. ‖DX-Y‖2≤δ (3) 稀疏分解求解分为贪婪算法和凸优化算法。贪婪算法有匹配追踪MP(Matching Pursuit),正交匹配追踪OMP(Orthogonal Matching Pursuit)等。凸优化算法有基追踪基追踪BP(Basis Pursuit),同伦算法等。 KSVD算法在字典更新阶段的核心思想是使字典中的每一列字典原子都发挥自身的价值以最小化重构误差,学习到的字典仅用来求解稀疏表示系数,但在分类过程中缺乏判别能力。为了得到一个具有判别性的训练字典,文献[17]提出标签一致KSVD(LC-KSVD)算法,引入了样本类别标签,加强了字典原子与标签之间的对应关系。另外,在目标函数中加入了稀疏编码误差约束项和分类误差约束项,最终使学习到的字典同时具有表示和判别能力。 2.2.1 LC-KSVD1 令样本矩阵Y=[y1,…,yi,…,yN],yi表示第i个样本,字典D=[d1,…,dk,…,dK],K表示字典原子总数,dk表示字典中的第k列原子。分类器的性能取决于稀疏编码的判别性,为了得到具有判别性的稀疏编码,LCKSVD1的目标函数定义如式(4)所示: s.t. ∀i,‖xi‖0≤T (4) 2.2.2 LC-KSVD2 为了得到更有利于分类的字典,LC-KSVD2在目标函数中添加了分类误差项,相比较于LC-KSVD1,新引入了线性预测分类器f(X;W)=WX,目标函数如式(5)所示: s.t. ∀i,‖xi‖0≤T (5) KSVD算法能够同时找到所有参数的最优解,式(5)可以被重新写为: s.t. ∀i,‖xi‖0≤T (6) s.t. ∀i,‖xi‖0≤T (7) 在字典更新阶段,KSVD算法采用奇异值分解SVD(Singular Value Decomposition)的方法随机更新字典的某一列原子,式(7)可以写为: (8) (9) 其中,U是主成分矩阵,Λ是特征值矩阵,将Λ中最大的特征值对应的U中的特征向量作为字典原子dk的更新。 算法1改进标签一致KSVD字典学习的人脸识别算法 输入:训练样本Y={yi},i=1,…,N,判别矩阵Q,样本类别标签矩阵H,稀疏阈值T,控制参数α,β。 输出:字典D,线性变换矩阵A,分类器参数W,识别率。 Step1初始化得到D0,A0,W0,设定参数值α,β。根据KSVD算法分别计算每一类图像的初始字典,合并得到D0,求解稀疏表示系数X0,采用多元脊线回归模型初始化: Step2根据改进的LC-KSVD字典学习过程计算Ynew和Dnew,然后分离出D=[d1,…,dK],A=[a1,…,aK]和W=[w1,…,wK]: Step4输入测试样本yj; AR人脸库包含了来自126个人超过4 000幅的正面人脸图像,每个人有26幅图像,每幅图像的尺寸为165×120,分别在不同光照变化、表情以及面部遮挡条件下拍摄,遮挡包括墨镜(眼镜)遮挡和围巾遮挡,分2个时期采集,每个时期13幅,包括7幅具有表情和光照变化图像,6幅遮挡图像,AR人脸库中部分人脸图像如图1所示。 Figure 1 Some face samples in the AR database图1 AR人脸库中部分人脸图像 本节实验选择100人的图像库(50名男性,50名女性),共计2 600幅图像进行实验,将每幅图像的大小标准化为55×40。进行以下3组实验(重复5次,取平均值作为最终的识别率): (1)关键参数选取。式(5)中参数α和β是2个相互独立的控制参数。α调节目标函数中稀疏编码误差项所占比重,β调节分类误差。当β=0时,即为2.2.1节中的LC-KSVD1。显然,不同的α值和β值对算法性能有不同的影响,为了探讨参数α和β对实验结果的影响,分别选取不同值进行对比实验,结果如图2所示。从图2中可以看出,α和β分别取4和2时,算法识别率较好。 Figure 2 Recognition results on AR database with different parameters α and β图2 AR人脸库上取不同参数值α,β时的识别结果 (2)为验证不同的训练样本数对于识别率的影响,从每类人脸图像中随机抽取p(p=10,13,16,19,22)幅共5组组成训练集,剩余样本组成测试集。本文算法对比经典的SRC算法、Fisherface算法、KSVD算法以及识别率较好的LC-KSVD2算法,表1为5种算法在不同的训练样本数下的识别率。 Table 1 Recognition results on AR dataset with different training samples (3)字典大小的设置也会对识别率产生影响,当字典原子数较少时,不能充分反映训练样本的信息,字典原子较多时也会消耗时间和占用资源。第3组实验随机选择每人22幅图像组成训练集,剩下样本组成测试集,总共训练样本2 200幅,测试样本400幅。分别设置字典大小为100,200,300,400,实验结果如表2所示。 Table 2 Recognition results on AR dataset with different dictionary sizes 从表1和表2的对比结果可以看出,KSVD算法在对比实验中识别率最低,因为KSVD算法学习到的字典在分类中没有判别能力。当训练样本数取最小(10)时,LC-KSVD和本文算法识别率明显高于其他对比算法的,随着训练样本数的增加,各算法识别率呈上升趋势。对于数量不同的训练集,本文算法都有着较高的识别率。表2的结果表明,字典越大,识别率越高,因为字典中囊括不同类别的训练样本图像越多,张成的类别子空间越准确。在固定训练集样本数只改变字典大小的实验中,再一次验证本文算法在字典大小取值一致的情况下识别率依然高于其他对比算法的。 根据本节实验2和实验3结果可知,本文算法对含表情、遮挡变化的人脸图像有较好的识别率。 Extended Yale B人脸库包含38人(包括男性人脸和女性人脸),每类64幅人脸样本图像,一共2 432幅,分别为不同光照条件下大小为192×168的图像。Extended Yale B人脸库中部分人脸图像如图3所示。与4.1节一样,本节进行3组实验。 Figure 3 Some face samples in the Extended Yale B database图3 Extended Yale B人脸库中部分人脸图像 (1)同样进行关键参数的对比实验,通过分别选取不同的α和β值进行对比,结果如图4所示,结果表明:α取4或5,β取2时,实验识别率较高。 Figure 4 Recognition results on Extended Yale B dataset with different parameters α and β图4 Extended Yale B人脸库上取不同参数值α,β时的识别结果 (2)依次从每个人脸图像中随机抽取p(p=30,40,50,60)幅图像组成训练集,剩余样本组成测试集。表3显示的是不同算法在Extended Yale B人脸库上的识别率情况。 Table 3 Recognition results on Extended Yale B dataset with different training samples (3)随机选择每人60幅图像组成训练集,分别改变字典大小为100,200,300,400,实验结果如表4所示。 Table 4 Recognition results on Extended Yale B dataset with different dictionary sizes 实验结果表明,在有不同的光照影响的人脸库上,本文算法在改变训练样本数量和改变字典大小的实验中都表现出较好的识别性能。随着训练样本数量的增加,改进算法的识别率保持上升的趋势,反映出改进算法识别性能稳定,具有较好的字典学习效果。 为全面评估本文改进算法的性能,对Extended Yale B人脸库中的图像分别添加了如图5所示不同等级的椒盐噪声(10%,20%,30%,40%),进行噪声对比实验。实验时,分别从每个人的全部人脸图像中随机抽取30幅组成训练集,剩余图像组成测试集,在4.2节实验的基础上,取字典大小为400,α和β的值为4和2。图6给出了在固定训练样本数的情况下,本文算法与其它4种对比算法随噪声等级变化的识别率对比曲线。从图6中可以看出,在噪声等级较小时,本文算法与对比算法识别率接近,随着噪声等级逐渐加大,本文算法在噪声环境下有一定的鲁棒性。 Figure 5 Samples with different noise levels图5 不同噪声等级下的样本图像 Figure 6 Recognition results with different noise levels图6 不同噪声等级下的识别率 本文提出一种基于改进标签一致KSVD字典学习算法并应用于人脸识别。用主成分分解的方式提取其主成分分量,作为字典中每列原子的更新,代替了字典学习过程中对残差项进行K次奇异值分解的方式,再利用学习到的具有表示和判别能力的字典对样本进行分类。在人脸图像存在遮挡、光照和表情变化等复杂情况下的AR和Extend Yale B人脸库上的实验结果表明,本文算法有着较高的识别率。同时,噪声实验表明本文算法在噪声存在的情况下依然保持较好的鲁棒性。2.2 标签一致字典学习算法
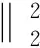
3 改进标签一致字典学习算法

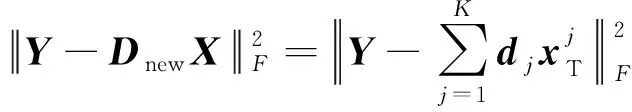
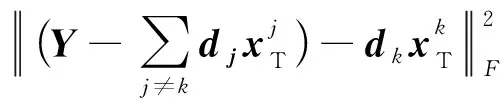
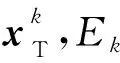
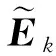
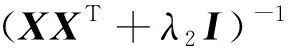
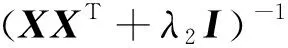
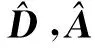
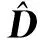
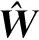
4 实验与结果分析
4.1 AR人脸库实验

4.2 Extended Yale B人脸库实验

4.3 噪声环境实验

5 结束语
