基于角色管理的实用拜占庭容错共识算法*
2022-03-22贾东立贾耀清
李 腾,程 哲,贾东立,贾耀清
(河北工程大学信息与电气工程学院,河北 邯郸 056038)
1 引言
随着计算机和网络的发展,计算机系统提供的服务和功能越来越多地被人们使用。近年来,随着比特币[1]的巨大成功,出现了一种新的分布式系统应用“区块链”并受到了高度重视。主流的分类方法将区块链分为3类:公有链、联盟链和私有链[2]。不同类型的区块链对节点数量和工作要求都不一样,但都需要保证节点的一致性。对共识算法的研究由此而生,不同类型的共识算法逐渐出现,比如适用于公有链的工作量证明POW(Proof-Of-Work)算法[3]和股权权益证明POS(Proof Of Stake)算法,适用于联盟链的实用拜占庭容错算法PBFT(Practical Byzantine Fault Tolerance)共识算法[4],适用于私有链的Raft共识算法等。
拜占庭容错源自于古罗马拜占庭将军问题[5]。如何在存在恶意节点的网络系统中,保证系统的稳定运行以及信息的一致性、完整性和安全性,正是拜占庭将军模型在去中心化网络和分布式系统中所反映的问题,也是区块链中共识算法所需要解决的问题。
为解决拜占庭容错问题,20世纪80年代,Lamport等[6]提出了著名的拜占庭容错BFT(Byzantine Fault Tolerance)共识算法。BFT共识算法中节点之间相互发送消息进行数据的传递和同步,另外还需要额外的时钟同步机制支持,算法的复杂度也是随着节点增加呈指数级增大。BFT 算法由于需要展示其理论上的可行性而缺乏实用性,但是其提供的思路在解决拜占庭问题上是一种创新,减少了POW算法大量的资源消耗。
1999年,基于BFT共识算法,Castro等[4]提出了实用性拜占庭容错PBFT共识算法,由拜占庭容错带来的系统开销被大幅度降低。PBFT共识算法是一类状态机拜占庭系统,其要求共同维护一个状态,所有节点采取的行动一致。因为各个节点达成共识是在同一时刻决定的,不用等待确认以保证当前区块所在的链是最长链,所以采用PBFT共识算法的区块链不会像POW算法那样存在链分叉,保持了系统的活性[7]。
目前PBFT共识算法还存在很多不足。对于P2P[8]网络来说,节点应该相互通信而不是客户端请求直接发送到主节点。而且由于PBFT共识算法采用C/S架构[9],节点在加入时系统不能及时回应,无法正确回应处理请求。主节点的选举是按照编号轮流选取,选举方式比较随意,对主节点的可靠性没有进行验证,因此很有可能选举出恶意节点,尽管恶意节点可以在视图变更时被推翻,但频繁地更换主节点和视图变更会导致大量资源的浪费,并降低系统效率。主节点选举完成之后,因为网络等原因会导致各个节点的状态不一致[10],需要完善的同步数据过程。共识过程通信开销较大,需要进行优化和改进。
2 PBFT共识算法流程
随着网络技术的发展,对PBFT共识算法的改进研究明显增多,例如,无主节点排序的HQ(Hybrid Quorum)算法[11]、基于投机的Zyzzyva 算法[12]和以主节点切换为代价进行优化的spining 算法[13]等。而在针对区块链应用场景进行优化方面,主要有POS与PBFT 结合的Tendermint[14]和DPOS(Delegated Proof Of Stake)[15]与PBFT结合的dBFT(delegated Byzantine Fault Tolerance)[16]算法等。 通过以上分析发现,区块链共识算法及其变种都是基于PBFT共识算法的,所以本文选取PBFT 共识算法作为研究对象。
在PBFT共识算法中,客户端是请求的发送端,主节点负责接收请求,并且按照顺序对请求排序,从节点主要负责检查从主节点发来的请求,并通过超时机制检测主节点是否出错,发生出错时触发视图更换协议。PBFT共识算法流程如图1所示。其中,Node0为主节点,Node3为出错节点。
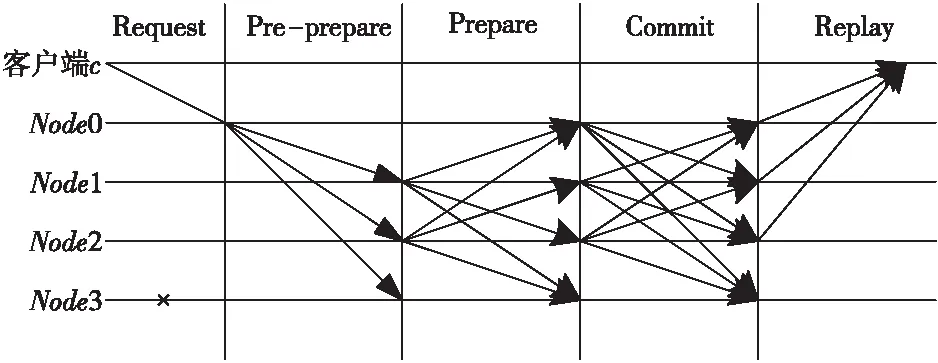
Figure 1 Flow chart of PBFT consensus algorithm图1 PBFT共识算法流程
PBFT共识算法流程分为5个阶段,每个阶段的工作方式和作用分别介绍如下:
(1)请求阶段(Request):客户端c产生交易数据并向主节点发送处理交易的请求消息〈REQUEST,m,t,c〉,其中,t是时间戳,m是需要共识的内容。请求阶段的主要作用是将需要共识的消息传递到主节点。
(2)预准备阶段(Pre-prepare):主节点收到请求后为需要共识的内容m分配序号,然后向所有从节点广播预准备消息〈〈PRE-PREPARE,v,N,d〉,m〉,其中,v是视图编号,N表示消息m的序号,d是请求消息m的摘要。视图编号v、消息序号N和摘要d是节点收到预准备消息后要检查的内容。预准备阶段完成了共识内容的序号分配和从主节点传递到所有从节点的工作。
(3)准备阶段(Prepare):编号为i的从节点收到预准备消息后,首先对消息的签名、消息序号N和摘要d进行验证。若验证通过,则将向所有从节点广播准备消息〈PREPARE,v,N,d,i〉。当节点收到2f+1(f表示PBFT共识算法可容忍的错误节点数量)个从不同从节点发送的与预准备消息一致的准备消息后,准备阶段完成。准备阶段完成对预准备阶段和准备阶段收到的视图编号、共识内容m分配的序号和消息内容的验证任务。
(4)确认阶段(Commit):从节点完成准备阶段后进入确认阶段。从节点i向所有节点广播确认消息〈COMMIT,v,N,D(m),i〉,其中D(m)是对消息m的验证签名。从节点在收到确认消息后会检查消息签名和视图编号是否一致,若检查通过并接收到2f+1个与预准备消息一致的确认消息,则确认阶段完成。这一阶段的作用是确保所有节点对本地确认的请求的序号达成一致。
(5)回复阶段(Replay):回复阶段的作用是将共识成功信息发送给客户端。回复消息格式为〈REPLAY,v,c,i,r〉,其中r是请求的执行结果。
对PBFT共识算法流程分析可知,算法存在着以下不足:
(1) 客户端只向主节点发送请求,当请求过多时容易造成主节点过载,可靠性降低,系统运行消耗增加,而且这种方式也不适合区块链的点对点网络。
(2) 主节点选取比较随意,无法保证节点的可靠性,如果连续选取恶意节点作为主节点,则会极大地增加系统消耗,降低系统的稳定性和可靠性;选择主节点后没有完备的数据同步过程,节点之间的数据无法更好地达成一致。
(3) 算法扩展性差,没有完善的节点加入或退出机制。节点加入或退出时,系统需要重新启动,开销较大。如果系统中的节点更换频率较大,将会大大降低系统的可用性。
(4) 共识过程网络消耗较大,网络中节点数较多时通信非常频繁,容易造成网络拥堵,影响请求正确执行。
3 RPBFT共识算法设计
3.1 算法主要思想
基于角色控制的拜占庭容错RPBFT (Role management-based Practical Byzantine Fault Tolerant)共识算法将网络中的节点分为3种类型的角色,分别是管理者(Manager)、候选者(Candidate)和普通节点(Normal),通过选举机制和奖励机制对节点的角色类型进行转换和管理,以达到提高效率、增加可靠性和动态性的目的。针对PBFT共识算法中存在的不足,本文主要在以下几个方面进行了改进:
(1) 为更好地适应点对点网络,改变客户端单点提交请求到主节点的方案,而是向所有节点发送带有时间戳和签名信息的交易数据。
(2) 将网络中的节点分为3种角色。普通节点服从管理者的安排,只负责完成交易。候选者不仅要服从管理者对交易内容进行分析,而且还要监督管理者的行为。管理者出现恶意行为时,将被降级为普通节点,候选者开始选举管理者的过程。管理者的主要职责是负责接收客户端的请求,同时对这些消息进行排序,分配编号,再向网络中广播请求消息。3种角色的节点在一定条件下可以相互转换,为新节点加入或退出提供了保证,提高了系统的可扩展性。
(3) 增加选举过程和奖励机制。用2种机制对节点的角色分配进行管理。候选者是系统网络重要组成部分。奖励机制下,所有节点每完成一次交易,都对其信用积分累计加一。当信用积分满足一定条件的时候,普通节点升级成为候选者,管理者是通过候选者之间的选举产生的。2种机制确保管理者节点具有最高的信用积分和最大交易序列号,降低了随意选取主节点带来的风险,提高了系统安全性。
(4) 增加数据同步及验证过程,在管理者选举完成之后进行数据同步,并且副本节点在同步过程中对主节点和数据进行验证,验证没有问题,说明管理者可靠,然后开始新的共识过程。
(5) 改进共识算法通信过程,去掉确认阶段。在去掉确认阶段的情况下,需要保证共识过程中发生视图变更后系统节点状态的一致性。本文使用交易序列号和区块高度来判定区块状态,舍弃视图这个概念,发生视图变更时通过重新选举来保证一致性。发生网络拥堵或节点恶意行为导致需要视图变更时,系统进入重新选举的过程,以此来消除系统可能面临的不一致性。
3.2 算法流程
系统初始化时,选取节点编号较小的2f+1个节点作为初始候选者。然后进行选举过程选出管理者,管理者通过发送数据块和序列号与所有节点进行数据同步达到状态一致,即存储数据、最大序列号和区块高度等信息完全一致。采用密码技术保证数据传递过程中的完整性和安全性,定义Si为消息签名,Di为消息摘要。节点初始化完成之后系统开始认证(Authentication)和提交(Submit)2个阶段的共识过程。
RPBFT共识算法流程如图2所示,各阶段具体过程描述如下:
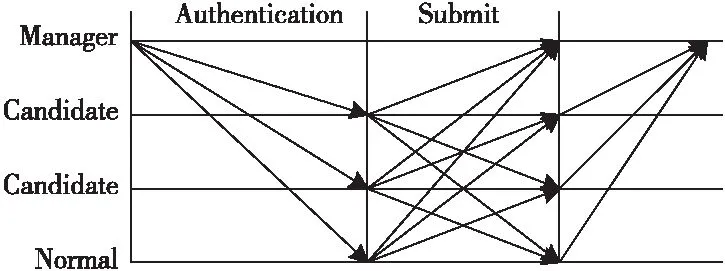
Figure 2 Flow chart of RPBFT consensus algorithm图2 RPBFT共识算法流程
客户端c广播请求到所有节点,共识节点收到请求后验证交易签名并将验证成功的交易数据存储在自己的内存中。
(1)认证阶段(Authentication):管理者收到请求后为交易数据分配序号N,然后向所有节点广播认证消息〈〈AUTHENTICATION,cp,N,Si,Di〉,data〉,其中,cp(credit points)是节点信用积分值,data是需要共识的交易数据。从节点i∈{0,1,…,|R|-1}(|R|为节点总数)在接收到认证消息时会对消息序号N、信用积分cp、签名和摘要进行检验,如果同意认证消息,则进入提交阶段,如果不同意,则对管理者产生质疑,广播重新选举消息。
(2)提交阶段(Submit):进入提交阶段后,所有从节点向除自己以外的节点广播提交消息〈SUBMIT,N,Si,Di,i〉。节点收到提交消息后对消息序号N、信用积分cp、签名和摘要进行检验,认证成功将认证消息和提交消息写入消息日志。节点收到2f+1个来自不同从节点且与认证消息一致的提交消息时,提交阶段完成。如果在一定的时间内没有收集到足够多的消息,则认定此交易过程失效,发起重新选举过程。
当节点完成提交阶段后向管理者发送已完成消息,管理者收到来自2f+1个不同节点的完成消息时,对客户端进行回复。
3.3 奖励机制
信用积分cp是衡量节点可信任程度的指标,节点成功完成交易任务数量越多,信用积分值越高,所有节点根据信用积分值cp的不同分为不同角色。初始状态下所有节点cp值为0,选举管理者之后每次完成管理者分配的交易任务即提交阶段完成,cp值加1并且记录在自己的日志中。由于网络延迟或节点恶意行为导致节点无法完成任务,节点需要接受降级惩罚。管理者发生故障时,信用积分清除到初始状态,并将角色类型变为普通节点,管理者自身发起重新选举过程;候选者发生故障时,信用积分清除到初始状态,并降级成为普通节点。
信用积分在选举管理者和推选候选者中具有重要的作用。在选举过程中,候选者通过发起投票选举出信用积分最大的候选者,当选者升级成为管理者,然后进行数据同步和验证。候选者是共识节点的主要部分,是保证系统可靠性和稳定性的重要力量。候选者的数量要占系统节点数量的大多数,假设算法可容错节点数量为f,则候选者的数量至少需要2f,确保即使在有f个候选者出现错误时,候选者数量依然可以代表系统的决策。候选者数量的保证,也可以在选举管理者时更加公平,避免恶意操纵候选者选举出恶意管理者带来的危险。在数据同步验证过程中,管理者统计由不同节点发送来的信用积分值并选择2f个信用积分较高的从节点分配为候选者。
为避免在短时间内通过大量交易刷信用积分的恶意行为,在管理者内部设立一个阈值K,当在一定时间内来自同一个节点的交易数量大于或等于K时,管理者认为该节点具有恶意行为,将该节点降级为普通节点并清除其信用积分。
3.4 选举过程
管理者的选举依据最大信用积分原则,选出候选者中信用积分(cp)最大即拥有最多完成交易记录的节点作为管理者。系统在没有管理者或管理者出错的情况下发起选举。
节点收到选举消息后,判断自己的角色,候选者首先将自己的cp值记录下来,然后对照存储的候选者列表将自己的cp值发送给所有候选者。候选者在收到所有候选者cp值后进行比较,如果cp值小于自己存储的值,则什么也不做;如果cp值与自己所存储的值相等,则比较节点编号,将节点编号较小的节点和cp值存入内存中;如果cp值大于存储的值,则清除原来存储,更换为较大的cp值。当cp值比较完成之后,将更新后的cp值及其节点编号广播给所有候选者,候选者如果收到了f+1个来自不同候选者的内容一致的投票消息,则更新自己的存储,给消息中的目标节点发送确认消息。候选者收到至少f+1个来自不同候选者发送的确认消息后升级成为管理者。
管理者在发生错误或由于网络原因导致出现不一致性时,将被降级为普通节点,然后由候选者发起新一轮的投票,投票过程与上述相同。
管理者选择完成之后,为使各节点保持状态一致并进一步验证管理者是否为恶意节点,需要管理者发起数据同步和验证过程。具体过程如下:
管理者发送同步数据请求消息,消息格式为〈SYN-REQUEST,cp,Si,i〉,其他节点收到请求消息后,对比自己cp值,如果没有异议,则向管理者回复确认同步消息,消息格式为〈SYN- COMMIT,Si,i〉;如果产生质疑则向所有节点广播否定同步消息,并发起重新选举过程。
在管理者收到2f+1个不同节点发送的确认同步消息后,进入数据同步阶段,发送数据同步消息〈〈SYN-DATA,cp,Si,i〉,data〉。节点收到同步数据消息后,更新自己的备份数据区块,向其他节点广播同步成功消息,当节点收到2f+1个来自不同节点的对数据同步消息的同步成功消息后,数据同步和验证过程完成。选举和数据同步验证过程如图3所示。
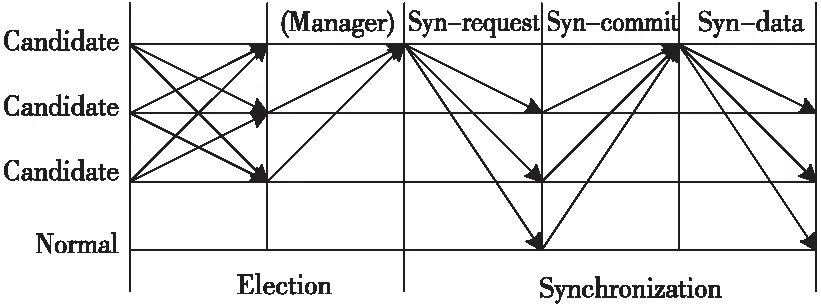
Figure 3 Schematic diagram of election process and data synchronization图3 选举过程和数据同步示意图
3.5 节点加入和退出
本文将共识节点分为3种角色,每种角色有自己的职责。普通节点在系统网络中只负责对交易的处理和转发,对候选者和管理者的状态不产生影响,这样有利于节点以普通节点的身份动态地加入系统网络。
节点加入后处于无管理者状态,发起对管理者的搜寻(Searching)过程。系统中的其它节点将告知其当前管理者的消息,当收到来自不同节点的2f+1个节点一致信息后,该节点与当前管理者建立联系,然后进入工作状态,如图4所示。
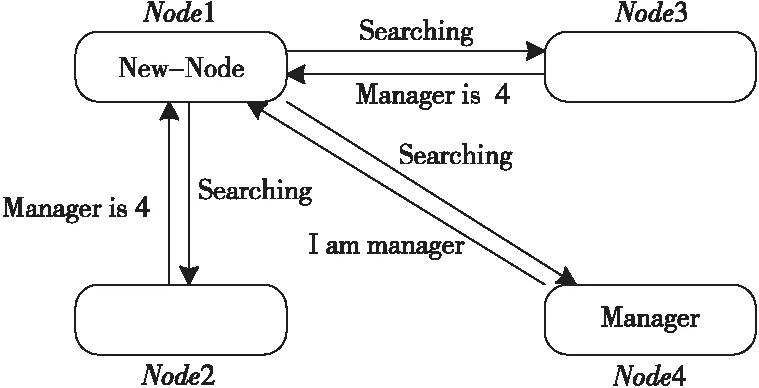
Figure 4 Schematic diagram of adding new nodes图4 新节点加入示意图
候选者或者普通节点退出时,向所有节点广播退出请求,管理者收到请求之后向除退出请求节点外的所有节点发送确认消息;管理者退出时,向所有节点广播退出请求并将降级为普通节点,同时启动选举过程。选举过程完毕之后由新当选的管理者发送确认消息。其它节点收到确认消息后查看是否与退出请求一致,如果一致则向退出请求节点发送退出回复消息。退出节点收到f+1个来自不同节点的退出回复消息时,节点退出成功,停止参与节点共识过程。
4 实验分析
本文是在PBFT共识算法的基础上提出的RPBFT共识算法,对通信开销、时延、动态性、可靠性和容错性方面进行了改进和优化。本节在配置为Iitel I5-337U处理器、8 GB内存、256 GHz固态硬盘的Windows 10系统中,通过Java多线程机制模拟网络中的共识节点通信过程。同时与PBFT共识算法进行比较,以此验证改进算法的有效性和可用性。
4.1 通信开销
PBFT共识算法的通信开销主要在预准备、准备、确认和视图更换过程中;RPBFT共识算法的通信开销主要在认证、提交2个阶段和选举、数据同步过程。
假设系统共识节点个数为n。PBFT共识算法预准备阶段主节点发送预准备消息给所有从节点需要通信的次数为(n-1)。准备阶段从节点之间相互通信所需通信次数为(n-1)2。确认阶段每个节点向除自己以外的节点发送消息,所需通信次数为n(n-1)。即PBFT共识算法共识过程共需通信次数为2n(n-1)。视图变更过程中,从节点广播视图变更消息所需通信次数为(n-1)2。主节点收到视图变更消息后广播确认消息所需通信次数为(n-1)。若出现视图变更的概率为p,则总共通信次数为:
Q=2n(n-1)+pn(n-1)
(1)
RPBFT共识过程没有错误发生时,2阶段的通信次数为n(n-1)。当系统节点出错或因网络导致超时,进行选举过程,候选者将自己的节点信息发送至其他候选者,这一阶段共需的通信次数为4(n-1)2/9。候选者收到其它节点信息并进行比较之后,将更新信息发送至其他候选者,该过程通信次数为4(n-1)2/9。管理者发送同步数据请求,该过程通信次数为(n-1)。节点验证成功发送确认同步过程的通信次数为(n-1)。确认同步完毕之后,管理者向其它节点发起数据更新的通信次数为(n-1)。由此分析可知,总共通信次数为:
(2)
假设网络环境相同,则每次通信对网络的消耗相同。2种算法通信次数比值W如式(3)所示:
(3)
由式(3)可以得出,当p=0时,W的值恒等于2,此时RPBFT共识算法的通信效率是PBFT共识算法的一半;当p=1时,W的值趋近于1,此时2种算法的网络通信次数相等;当p<1时,W的值恒大于1,而且p的值越小,W的值越趋近于2。这说明在需要视图变更情况出现较少时,RPBFT共识算法的共识过程通信开销接近于PBFT共识算法的一半。多次实验结果表明,在运行稳定的区块链环境中,系统发生视图变更的概率很小,所以RPBFT共识算法的通信开销会减少将近一半,有效降低了系统在共识过程中的通信开销。
4.2 时延测试
共识时延作为衡量共识算法的重要指标,在区块链中表示交易从发起到完成的时间差。较低的时延使得区块链的可用性和安全性更高。在同样的网络环境下,RPBFT共识算法通信次数更少,降低了共识延时。测试共识延时的计算方法如式(4)所示:
DelayTime=TSubmit-TAuthentication
(4)
其中,TSubmit为区块完成共识确认的时间,TAuthentication为认证阶段开始时间。固定交易数量为10个,在容错节点数量不超过1的前提下,分别取4,5,6,7,8,9,10个节点进行3组对照实验。对每组节点进行多次测试取平均值,得出2种算法在相同条件下的共识延时对比,如图5所示。
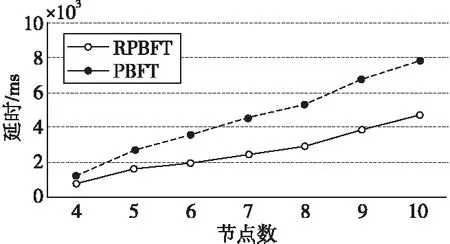
Figure 5 Consensus delay comparison between two algorithms图5 2种算法共识延时对比
由图5可知,RPBFT共识算法的时延明显低于PBFT共识算法的,而且随着节点数量的增加,2种算法时延差距也会变大。
4.3 动态性
PBFT共识算法采用静态请求响应模式,当节点加入或退出时需要重新启动系统和数据同步过程。RPBFT共识算法将整个网络的节点分为3种不同的角色,并通过一定的机制控制角色之间的转换。其中,候选者是系统的关键节点,候选者负责选举管理者,并且候选者数量需要保证为系统节点数量的大多数。节点加入时增加了寻找管理者的过程,节点退出时增加了退出确认过程,2个过程使系统可以感知节点加入或退出,相应地调整候选者的数量,并保证系统的可靠性和稳定性。
由此可见,RPBFT共识算法能够在节点加入或退出时动态调整各个角色数量,避免了系统重启的过程,减少了节点加入或退出时带来的网络资源消耗。
4.4 安全性
假设系统中有n个节点,每个节点出错的概率为q,交易次数为M。在PBFT共识算法下主节点由式(5)计算得出:
P=vmodn
(5)
节点出错后视图编号变更为v+1,通过式(5)选择主节点。假设在M次交易过程中每次出错的节点均为当前主节点编号加一的节点,此时视图变更后选择的主节点为上一个视图的出错节点,系统处于高风险。由此可知PBFT共识算法在最坏的情况下有q的概率处于高风险环境中。
在RPBFT共识算法进行M次交易之后最坏的情况是有f个节点连续M次无法正常工作,每次出错重新更换管理者,并将原管理者降级为普通节点。则此时存在2f-M个节点处于全部成功完成交易的状态,信用积分为M;存在M个节点处于积分不为零的状态。管理者就是从这2f个节点中选择信用积分最高的节点,即选择原来出错节点的概率为零。对比之下,RPBFT共识算法在增加系统安全性方面有所改进。
为验证系统在管理者行为出错下的行为,实验中设置管理者线程在系统运行10 s之后关闭。结果表明,RPBFT共识算法检测到管理者失效后重新选举管理者,并且与所有从节点进行数据同步,数据同步过程中从节点对新管理者进行检测,保证了管理者的可靠性。接着开始新的共识过程。而且在整个过程中参与选举和验证的可信节点数量超过了2f,保证了系统(n-1)/3的容错性。
实验表明,RPBFT共识算法减少了系统开销,缩短了共识延时,增加了算法的动态性,并且与PBFT共识算法一样能够保证分布式系统运行的一致性和安全性,证明了该算法的有效性和可靠性。
5 结束语
本文对在区块链中应用广泛的PBFT共识算法进行深入研究,并提出了一种基于PBFT共识算法的改进算法RPBFT共识算法。RPBFT共识算法动态管理节点的3种角色,使得节点可自由加入或者退出;对管理者的选择方式加以改进,选举出来的节点更为可信;选举完成之后的数据同步和验证过程,在验证管理者的可信性的同时,保证了节点的一致性;优化的共识过程更加适应区块链的网络环境,并减少了消耗,加快了共识速度。但是,RPBFT共识算法依然存在不足,如何进一步降低网络通信量,在保证通信效率的前提下提高容错性,在将来需要进一步深入研究。
