基于组合输入ES-GA-BP的中欧班列货运量预测
2022-03-22张英贵杨蕙瑜雷定猷
张英贵,杨蕙瑜,雷定猷
1)中南大学交通运输工程学院,湖南长沙 410075;2)中南大学轨道交通大数据湖南省重点实验室,湖南长沙 410075
随着“一带一路”倡议的深入推进,中欧国际铁路通道沿线各国的经贸往来日益深入,巨大的物流需求使得中欧班列发展迅猛[1].中欧班列的常态化运行有力促进了中欧及其沿线各国之间的经济贸易往来.为准确判断中欧班列运输市场的发展趋势及增长空间,需对中欧班列的出口需求量进行准确预测,这不仅利于国家资源配置,也是铁路运输部门调整经营管理方式的依据.精准预测对中欧班列开行方案研究、营运策略制定、基础设施建设、价格制定和提高市场分担率具有重要现实意义[2].
近年来,针对如何提高铁路货运量预测方法的精确度已展开大量研究.张玥等[3]提出利用新陈代谢GM(1,1)模型预测东北地区铁路货运量;邵梦汝等[4]通过建立灰色神经网络组合模型,提高了铁路货运量预测的模拟性能和预测准确度;RUIZAGUILAR等[5]利用多个机器学习和集成模型对港口货物的检验过程进行辅助决策,提出聚集分解预测方法,提高了货物检验的预测精度;TSIOUMAS等[6]通过建立具有外生变量的多元向量自回归模型,提高干散货指数的预测精度;UYAR等[7]提出基于遗传算法(genetic algorithm,GA)的训练递归模糊神经网络用于长期干货运价预测;WANG等[8]采用基于方差倒数和最优加权的组合模型对弹性系数法、GM(1,1)模型和DGM模型进行优化,建立最优权重组合模型对客货运量进行预测;雷定猷等[9]提出基于非线性主成分分析和遗传算法优化的径向基函数(nonlinear principal component analysis and genetic algorithm-optimized radial basis function)神经网络的交通量预测方法,有效提高了交通量的预测精度;YANG等[10]提出基于聚类搜索策略的改进遗传算法和小波神经网络预测模型,提高了短期交通流预测精度;XU等[11]基于多个统计检验开发比较程序,对两种预测模型进行比较;周程等[12]基于时空调整策略改进粒子群算法-反向传播(particle swarm algorithm-optimized back propagation,PSO-BP)神经网络模型,提高了货运量预测精度;ZHOU等[13]提出改进的PSO-BP神经网络来确定组合权重,建立一种新的组合预测模型来预测物流货运量;冯芬玲等[2]提出将改进粒子群算法与胶囊神经网络相结合的预测模型,对中欧班列出口需求量进行预测;HASSAN等[14]提出一种支持短期至长期货运运营计划的需求预测方法;YANG等[15]建立4种基于多元统计方法的预测模型,并成功应用于铁路货运量的预测.
在国际货物运输通道新环境下,传统单一货运预测方法存在一定局限性,无法解决中欧班列货运量波动性较大的问题.本研究通过调整神经网络输入,将神经网络预测模型与指数平滑法组合,构造基于指数平滑(exponential smoothing,ES)法和GABP神经网络的组合预测模型.ES能更好拟合数据波动较大的序列,从而调整神经网络的输入;同时将相关性高的影响因素和指数平滑后得到的历史数据作为神经网络的输入,克服单一预测方法在原始货运量数据波动较大情况下,预测精度低的不足;通过遗传算法优化传统BP神经网络的权值和阈值,提高预测精度.以“湘欧快线”国际运输通道货运量的预测为实例,对比分析所提方法的有效性.
1 中欧班列货运影响因素分析
中欧班列在中国镜内主要分为西、中、东3大通道[16].中欧班列货运量的变化趋势整体波动较大,由于经济水平提升,2008年之前的货运量逐年递增;从2008年全球金融危机开始,部分欧洲国家爆发主权债务危机,中欧贸易受到较大影响,其货运量连续几年大幅下降;随着经济好转,2010—2012年的货运量再次上升;2013—2015年世界经济进一步呈现分化和割裂的趋势,欧洲经济再次面临冲击,导致货运量再次受到影响.近年来,欧洲国家经济结构改革取得一定成效,中国政府提出的“一带一路”倡议也加强了中国与欧洲、亚洲之间的贸易往来,货运量开始逐年上升[2].
以“湘欧快线”为例,考虑外部经济需求、铁路运输总出口贸易额、主要出口品类量值和政府补贴政策对快线货运量的影响.“湘欧快线”于2014年10月正式开始试运行,现已有多条班列实现常态化运行,货运量逐年升高.图1为“湘欧快线”某段时间内连续30个月从西(阿拉山口和霍尔果斯)、中(二连浩特)及东(满洲里)口岸的出口货运量(货运集装箱数).其中,横坐标数值的第1位代表年份,后两位代表月份,如101表示第1年的第1个月,下同.可见,“湘欧快线”的货运量仍处于不稳定的发展阶段,数据波动较大.

图1 “湘欧快线”西、中、东部通道货运量统计Fig.1 Statistical chart of freight volumeof western,central and eastern corridors of Hunan Europe Express
1.1 外部经济需求
“湘欧快线”公司某段时间30个月去往不同目的地的货运集装箱数表明,“湘欧快线”的主要出口国是德国、白俄罗斯、匈牙利、伊朗及荷兰.图2为“湘欧快线”货运量与湖南省同5个主要国家的总出口贸易额对比.可见,“湘欧快线”货运量与湖南省总出口贸易额的变化基本一致,即外部经济需求的波动会带动中欧班列货运量的波动.

图2 主要出口国总贸易数额与“湘欧快线”货运量对比Fig.2 Comparison between total tradevolumeof major exporting countriesand freight volumeof Hunan Europe Express
1.2 铁路运输出口贸易额
图3为“湘欧快线”货运量与湖南省铁路运输的总出口贸易数额对比.可见,“湘欧快线”货运量与铁路运输总出口额的波动情况大致相同,表明“湘欧快线”货运量的波动与铁路运输存在一定相关性.

图3 铁路运输总出口贸易数额与“湘欧快线”货运量对比Fig.3 Comparison chart of total export trade volume of railway transportation and freight volumeof Hunan Europe Express
1.3 主要出口品类量值
由“湘欧快线”公司获取时间段内的分品类货运数据发现,“湘欧快线”的主要出口商品为鞋类和箱包及类似容器.图4为“湘欧快线”货运量与湖南省出口的鞋类和箱包及类似容器的贸易总量对比.可见,二者波动大致相同,表明主要出口品类数量的波动会带动“湘欧快线”货运量的波动.

图4 不同品类出口商品量值与“湘欧快线”货运量对比Fig.4 Comparison between the volume of different categoriesof export commoditiesand thefreight volumeof Hunan Europe Express
1.4 政府补贴政策
中欧班列存在空载率高、线路重复严重及运输成本较高等问题,其运费与海运相比相对较高,为引导海运货物转为铁路运输,政府补贴成为有效方法之一.然而,中欧班列过高的政府补贴,导致班列运行公司过分依赖补贴,也给政府带来巨大的财政压力.因此,财政部从2018年开始,要求地方政府降低中欧班列补贴标准:以全程运费为基准,2018年补贴不超过运费的50%,2019年补贴不超过40%.因此,对于当前未完全市场化的中欧班列,政府的补贴政策对货运量具有较大影响.
中欧班列货运量的波动还受到自然资源、铁路运输系统供给及疫情等其他因素影响,因此,传统单一货运量预测方法无法满足中欧班列货运量预测的实际要求.本研究提出基于组合输入ES-GA-BP的预测方法,以提高中欧班列货运量的预测精度.
2 基于组合输入ES-GA-BP的中欧班列货运量预测方法
2.1 基于指数平滑的中欧班列货运量预测方法
在指数平滑法中,每期的指数平滑值都是本期实际观察值与前一期指数平滑值的加权平均.对于某些基础数据波动较大的序列,采用指数平滑法得到的预测值的变化趋势更接近实际值的变化趋势.本研究采用三次指数平滑法拟合数据波动较大的序列,以调整神经网络输入,提高预测精度.
三次指数平滑法的计算公式为

三次指数平滑法的预测模型为

其中,t为当前时期数;T为由t到预测期的时期数;α为平滑系数,0<α<1;为第t时期的一次指数平滑值;Bt为第t年货运量实际值;为第t-1年的货运量一次指数平滑值;为货运量的二次指数平滑值;为货运量的三次指数平滑值;为第t+T期的货运量预测值;at、bt及ct均为平滑系数.
指数平滑预测中需确定α和越大,近期数据对预测结果的影响越大,表现出重近轻远的特点,因此,α的选择与原序列趋势有关.本研究通过计算货运车数偏差的平方均根值MSE最小时的α值,选取对于样本数据更合适的α.MSE为

当时间序列的原始数据样本较多时(≥20个),可选择第1年的数据值作为初始值当时间序列的原始数据样本较少时(<20个),可取最开始几期实际值的加权平均值作为
2.2 基于BP神经网络的中欧班列货运量预测方法
中欧班列BP神经网络货运量预测模型包含输入层、隐含层和输出层,每一层均有激活函数和若干节点相连接,其中,每个神经元又具有不同的连接权值和阈值(图5).
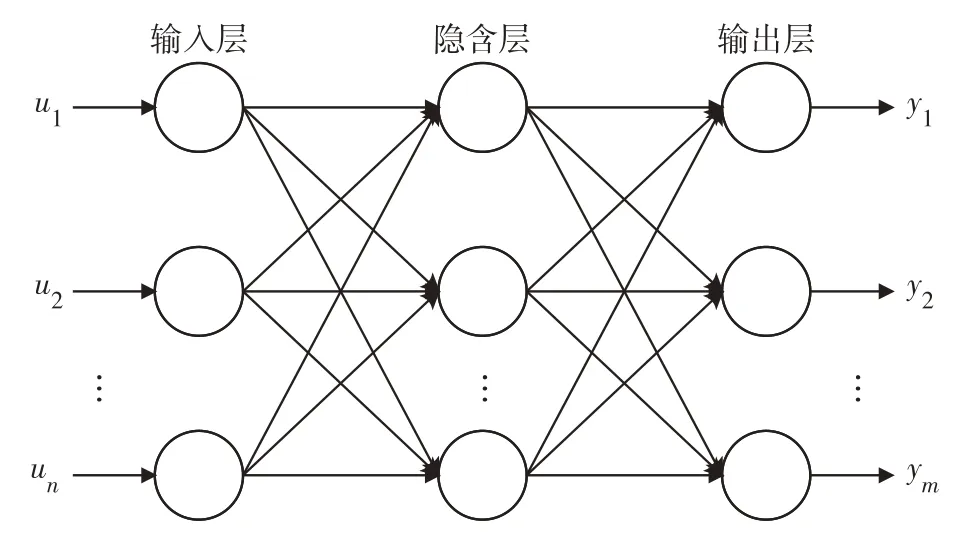
图5 中欧班列BP神经网络预测模型结构Fig.5 Structureof BPneural network prediction model for China Railway Express
误差反向传播由输入信号的正向传播和误差信号的反向传播过程组成,两个过程交替进行,按照梯度下降算法迭代更新网络权值,最终使误差函数最小,则网络对P个训练样本的总体误差函数为

使用BP神经网络预测中欧班列货运量时,其输入层神经元数取m,输出层神经元取n,隐含层神经元数b取经验值取1~10.由于BP神经网络存在权值和阈值不能准确获得的缺陷,且权值和阈值的取值对BP神经网络的预测精度具有很大影响,利用GA优化BP神经网络的权值和阈值,以提高货运量预测准确性.
2.3 基于组合输入ES-GA-BP模型的货运量预测方法
本研究通过调整神经网络输入,将神经网络预测模型与指数平滑法进行组合,构造基于组合输入ES-GA-BP模型的货运量预测方法.指数平滑法对于波动大且不存在明显线型相关性的时间序列拟合具有明显优势,因此,可用于调整神经网络输入.将相关性高的影响因素和指数平滑后得到的历史数据作为神经网络输入,能更好克服单一预测方法的缺陷与不足.通过引入GA,解决BP神经网络的权值和阈值不能准确获得的缺陷,提高预测精度.得到的预测值优于以指数平滑法与神经网络单独预测的结果,适于解决波动较大的货运量预测问题.ES-GA-BP模型的逻辑关系如图6,具体步骤如下.

图6 ES-GA-BP模型逻辑关系示意图Fig.6 Logic relationship of ES-GA-BPmodel
步骤1计算训练数据和测试数据.通过Pearson相关性分析确定影响因素对货运量的影响,利用三次指数平滑预测方法处理原始货运量数据,得到训练数据和测试数据,以确定神经网络的输入.
步骤2初始化参数.建立BP神经网络预测模型,并确定神经网络的网络层数、各层节点、训练及学习等参数,确定遗传算法种群规模、迭代次数、遗传及变异等参数.
步骤3生成初始种群.利用步骤1中得到的数据训练BP神经网络,得到神经网络的权值和阈值,将其赋值作为GA的初始种群.为得到高精度权值和阈值,在给定范围内,采用实数编码方法和线性插值函数生成初始种群和染色体.
步骤4确定个体的适应度函数.采用步骤3中生成的染色体对BP神经网络的权值和阈值进行赋值,再对BP神经网络进行训练,达到设定的标准后得到训练输出值,以训练误差的平方和作为种群中个体的适应度.
步骤5选择操作.采用轮盘赌法选择算子,即基于适应度比例选择策略选择每代种群的染色体.设群体共有N个染色体,第i个染色体对应的适应度函数值为fi,则该染色体被选取的概率pi为

步骤6交叉操作.采用实数交叉法,第k个染色体ak和第l个染色体al在位置j的交叉操作分别为akj与alj,表示为

其中,b为[0,1]中的随机数,即交叉概率;u为迭代次数.
步骤7变异操作.选取第i个个体的第j个基因aij进行变异操作,表示为
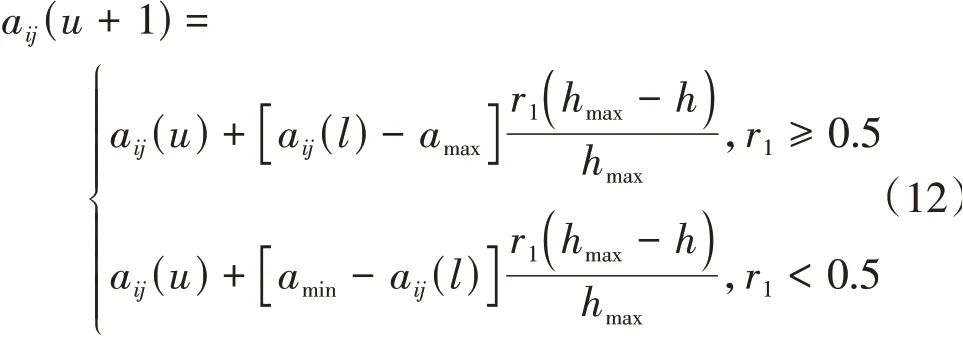
其中,amax和amin分别为基因取值的上下界;r1为随机数;h为当前迭代次数;hmax为最大进化数.
步骤8获得最优值.若步骤7获得的新群体满足终止条件,将GA运行后所得的最优个体解对BP神经网络的权值ωk和阈值θk赋值,BP神经网络经过训练后,再输入步骤1中的测试数据对货运量进行预测,算法结束,输出预测结果;否则返回步骤5,重新运行.
3 实例分析
本研究以某段时间内各月度分别从西部口岸(阿拉山口和霍尔果斯)、中部口岸(二连浩特)及东部口岸(满洲里)出口的“湘欧快线”货运量(表1)作为实际案例,验证组合预测模型的实用性.

表1 “湘欧快线”货运量统计Table1 Statistical data of freight volumeof Hunan Europe Express
在将影响因素输入组合神经网络预测模型前,需要对全部影响因素进行相关性分析,从而判断相关指标能否作为神经网络的输入进行货运量预测.利用SPSS软件中的相关性分析功能,以第1节分析选择的4个影响因素作为输入,“湘欧快线”货运量作为输出对数据进行相关性分析,计算得到各影响因素的Pearson相关系数,见表2.可见,各影响因素与“湘欧快线”货运量的Pearson相关系数都处于较高水平,表明这些影响因素与“湘欧快线”货运量存在较高的相关性,因此,将这4个影响因素作为组合神经网络预测模型的输入.

表2 影响因素的Pearson相关系数Table 2 Pearson correlation coefficients of influencing factors
由于“湘欧快线”3个口岸的输出货运量波动很大,且与时间无明显线性相关性,因此,首先将总货运量进行三次指数平滑预测,分别计算不同平滑系数α下的MSE,结果如表3.根据测算结果,取α=0.36,得到三次指数平滑预测结果如表4.
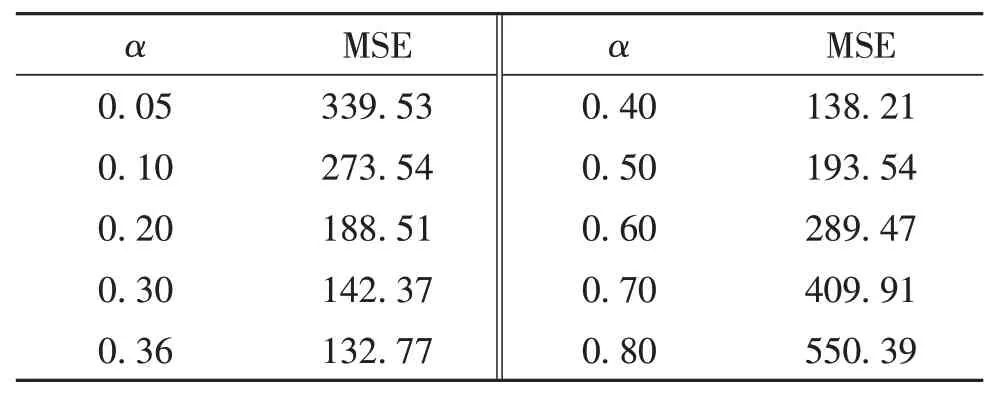
表3 不同平滑系数下的均方差值Table3 MSE under different smoothing coefficients
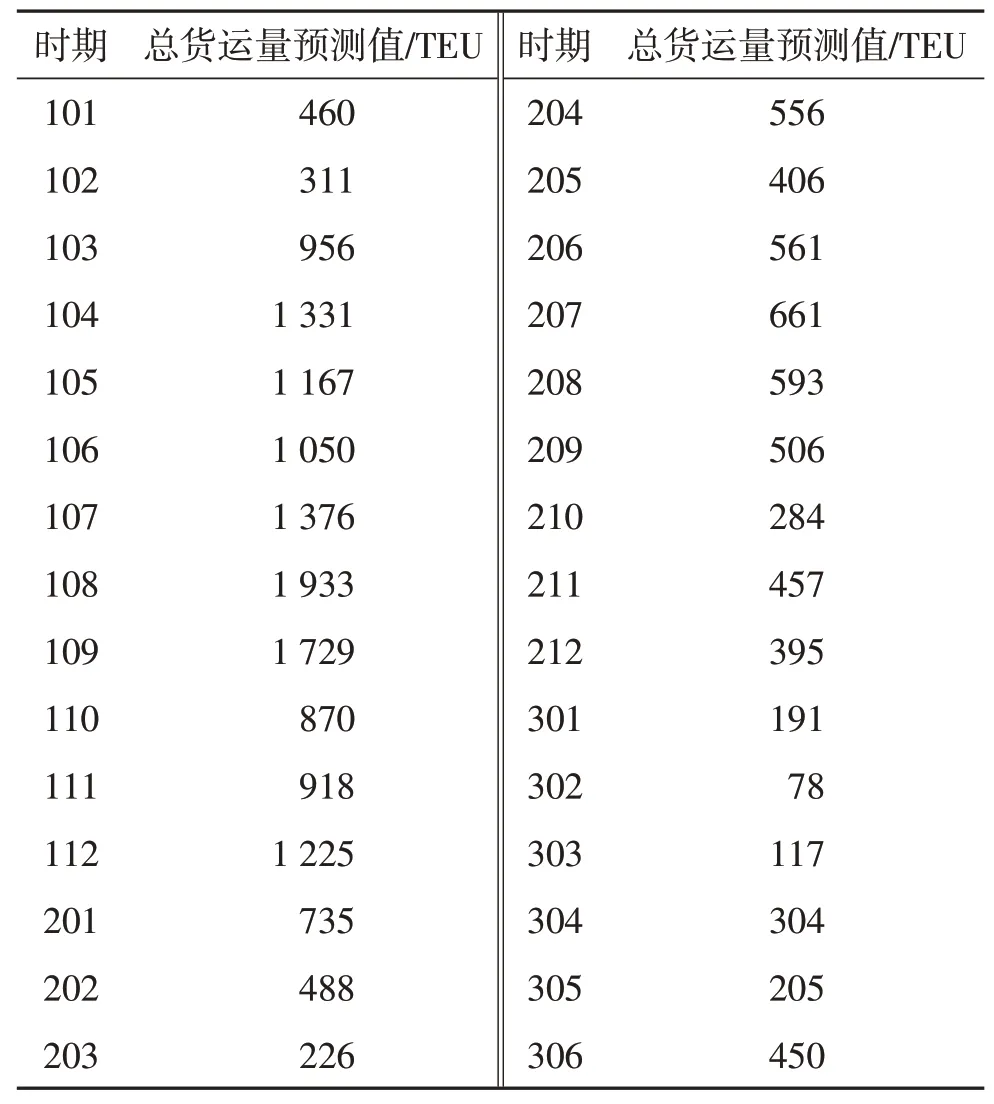
表4 总货运量三次指数平滑预测结果Table4 Tripleexponential smoothing prediction resultsof total containers
通过近年的政府补贴比例标准作为补贴影响系数.第1年的补贴影响系数为1.0,第2年为0.5,第3年为0.4.将补贴影响系数与三次指数平滑后得到的预测结果相乘,代表政府补贴对中欧班列货运量的影响,得到BP神经网络输入1,如表5.

表5 BP神经网络输入1Table5 Input 1 of BPneural network
采用Matlab R2016a软件建立BP神经网络预测模型,对GA相关参数的取值进行仿真测试;针对相同的影响因素数据,进行预测对比实验.以平均相对误差δˉ进行评价,其计算公式为其中,n为测试样本数;x̂i和xi分别为第i时期货运量的预测值和实际值.

选取训练样本为1月1日至1月12日共12期数据,测试样本为2月1日至2月3日共3期数据.输入样本为4个相关影响因素的数据,神经网络采用4-11-1的3层结构,训练次数为10 000次,训练目标为0.000 1,学习率为0.01.在固定其他参数取值的前提下,分别对遗传代数、种群规模、交叉概率及变异概率的不同取值进行对比试验,其平均相对误差如表6至表9.可见,当其他参数取值不变时,遗传代数、种群规模、交叉概率及变异概率分别取200、600、0.95及0.05时,神经网络的测试结果最好.

表6 不同遗传代数取值下相应的平均相对误差Table6 Averagerelativeerror under different valueof genetic algebras
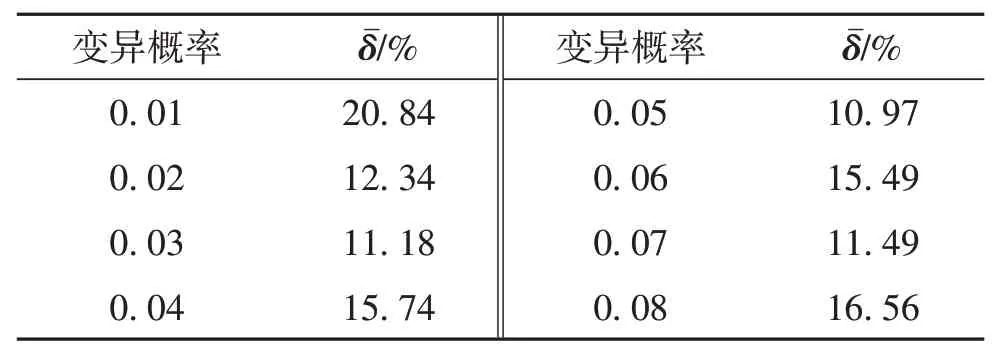
表9 不同GA参数取值下相应的平均相对误差(变异概率)Table9 Averagerelativeerror under different valueof GA parameters(mutation rate)
为验证预测方法的有效性和先进性,使预测结果的对比分析更显著,将本方法与一般的三次指数平滑法、输入仅为相关影响因素的BP神经网络预测方法(BP方法)、指数平滑-BP神经网络预测方法(ES-BP方法)及GA-RBF神经网络预测方法(GA-RBF方法)在相同条件下进行货运量预测对比.

表7 不同种群规模取值下相应的平均相对误差Table7 Averagerelativeerror under different valueof population sizes

表8 不同交叉概率取值下相应的平均相对误差Table8 Averagerelativeerror under different valueof crossover rates
将数据分为两部分,选取前24个月度的预测数据作为训练样本,后6个月度的数据作为测试样本;BP和RBF神经网络的训练次数为10 000,训练目标为0.000 1,学习率为0.01,以式(13)中的δˉ和相对误差δ作为评价指标,δ的计算公式为

在Matlab环境下构建BP、ES-BP、GA-RBF及组合输入ES-GA-BP.BP预测方法以4个相关影响因素的数据作为输入样本,神经网络采用4-11-1结构;ES-BP预测方法仅以原始数据经过3次指数平滑后的数据作为输入样本,神经网络采用1-9-1结构;GA-RBF预测方法以4个相关影响因素的数据作为输入样本,神经网络采用4-9-1结构;组合输入ES-GA-BP预测方法同时以4个相关影响因素的数据和原始数据经过三次指数平滑预测数据作为输入样本,神经网络采用5-11-1结构;4种预测方法的输出样本均为表1中的总货运集装箱数据,分别得到5种模型对应的预测结果和预测误差如表10.图7为实际值和几种方法的货运量预测结果对比.

表10 预测结果和误差Table10 Prediction results and errors

图7 货运量预测结果Fig.7 (Color online)Forecast resultsof freight volume
由预测结果可知,组合输入ES-GA-BP和ESBP预测方法的平均相对误差分别比三次指数平滑法和BP预测方法降低14.11%、7.3%和8.05%、1.24%,可见,组合输入ES-GA-BP预测方法和ESBP预测方法的预测精度均比单一的指数平滑预测方法和单一的BP预测方法高,说明组合预测模型的预测精度比单一预测方法更高;组合输入ESGA-BP预测方法的平均相对误差比ES-BP预测方法降低6.06%,可见,组合输入ES-GA-BP预测方法的预测精度比ES-BP预测方法高,说明组合输入比单一的神经网络输入预测精度更高,且通过GA优化BP神经网络能提高BP神经网络预测模型的精度;组合输入ES-GA-BP预测方法的平均相对误差比GA-RBF预测方法降低1.17%,表明所提出的组合预测方法更适于数据波动较大的“湘欧快线”货运量预测.对于研究国际货运通道货运量的预测领域,组合输入ES-GA-BP模型的预测结果更理想.
将未来3个预测期的湖南省出口货物贸易额、铁路运输贸易额、鞋类和箱包及类似容器的出口贸易额,和三次指数平滑数据输入到组合输入ESGA-BP预测模型中,得到“湘欧快线”未来3个预测期的货运量分别为1 509、1 205及1 097 TEU.可见,短时间内“湘欧快线”的货运量暂时呈现下降趋势,近段时间应减少直达列车开行,可在过境口岸与其他班列集结开行节约运输成本.同时,政府也应继续加强中国铁路口岸的基础设施建设,政策制定要根据中欧班列货运量进行相应调整.
结 语
提出一种基于组合输入ES-GA-BP的预测方法,在克服传统单一预测方法缺陷的同时,优化神经网络输入,减少预测复杂性.与单一预测方法相比,本方法预测精度高,其货运量预测值更接近实际货运量,能够满足合理管理国际货运通道的客观需求,对建设国际货运通道具有一定指导意义.中欧班列货运通道是一个复杂的非线性系统,还受疫情、环境及政策等多种因素影响,如何同时考虑其他影响因素设计出精度更高的货运量预测方法是下一步的研究重点.
