用户态并行文件系统性能优化*
2022-03-19邓通亮陈宸殷树
邓通亮,陈宸,殷树
(1 上海科技大学信息科学与技术学院,上海 201210;2 中国科学院上海微系统与信息技术研究所,上海 200050;3 中国科学院大学,北京 100049)(2020年3月23日收稿;2020年5月11日收修改稿)
在高性能计算系统中,并行文件系统的性能表现起着至关重要的作用[1-3]。目前存在不少的并行文件系统,例如PVFS[4]、PLFS[5]和Lustre[6]等。高性能计算系统由多个部分组成,应用的工作负荷往往复杂多变,系统中的薄弱环节易成为性能瓶颈,需要对其进行针对性的优化。例如,文献[7]对并行文件系统的小文件性能进行优化,文献[8]对文件系统中元数据的访问进行优化。
一般地,文件系统(例如 ext4)在操作系统内核中实现。但是,由于开发内核态文件系统难度大,不少开发者选择使用FUSE[9](filesystem in userspace,用户态文件系统框架)作为文件系统和内核之间的中间层,在用户态开发文件系统[10-11]。通过FUSE,使用者可以在不修改内核的情况下部署文件系统,开发者可以在不进入内核的情况下调试文件系统。常见的基于FUSE的用户态文件系统有PLFS[5]、GlusterFS[12]和Sshfs[13]等。
然而,在基于FUSE实现的用户态文件系统中,由于FUSE的介入,处理每一个I/O请求都会额外引入多次用户态和内核态之间的运行态切换(下文简称:运行态切换)、上下文切换和内存拷贝,加上FUSE内部的等待队列和I/O请求重排,存在一定的性能损失。Bent等[5]发现FUSE能够造成20%左右的性能下降。Vangoor等[14]研究了ext4上FUSE的性能特点,表明FUSE在不同的工作负荷下导致不同程度的性能下降,最大下降83%。最近研究者发现Intel 处理器中存在Meltdown[15]等一系列漏洞,操作系统发布的补丁程序增强了用户态和内核态内存空间的隔离性,导致运行态切换的开销增加。
为优化用户态文件系统的性能,Ishiguro等[16]提出一种通过FUSE的内核模块直接与内核文件系统交互的方法,优化用户态文件系统的性能,但该方法需要对内核进行修改,可移植性较差。Zhu等[17]提出一种将FUSE移植到用户空间的方法,虽然消除了运行态切换和上下文切换,但是由于只有基于libsysio[18]API 进行开发的应用程序才能使用该方法,存在一定的可扩展性问题。Rajgarhia和Gehani[19]通过JNI(Java native interface)实现了基于JAVA的FUSE接口,并且给出性能测试,但是缺乏深入的性能结果分析。文献[20]基于特定应用的I/O工作负荷特征,对高性能文件系统进行优化和深入的结果分析。
本文利用动态链接技术,在用户态并行文件系统中实现了一种绕过FUSE的方法,消除FUSE的性能影响,对比了用户态并行文件系统在基于FUSE和绕过FUSE后的性能特点。该方法可以运用于所有动态链接了标准I/O库的应用,不需要对应用进行任何修改就可以提高I/O性能。实验结果表明,该方法可以显著提高I/O性能。其中,在传输块较大时,读性能最大提高131%,写性能和有FUSE时性能相仿;传输块较小时,写性能最大提高5倍左右。
1 背景与问题分析
1.1 用户态文件系统框架
文件系统通常在内核中实现,应用的I/O请求通过系统调用的方式陷入内核态,利用其更高的执行权限完成I/O。与此同时,存在一类拦截I/O请求的中间层文件系统,它们向应用提供文件的抽象,并支持POSIX文件I/O语义,但是不实际存储文件,而是将文件的内容重新组织并存储到底层存储系统中,这样的中间层称为可堆叠文件系统[21]。FUSE作为应用和用户态文件系统之间的桥梁拦截并转发I/O请求,因此可以使用FUSE开发此类可堆叠文件系统。
图1[14]展示了FUSE的基本架构与操作流程。FUSE由两部分组成,内核模块和用户态守护进程,二者通过虚拟设备/dev/fuse进行通信。在基于FUSE的文件系统上触发I/O请求时,内核虚拟文件系统(virtual filesystem, VFS)将该请求转发至FUSE内核模块,内核模块再将其重定向到对应的用户态守护进程,守护进程处理该请求,请求结果沿着原路返回。由此可见,处理1次I/O请求最少需要4次运行态切换,2次上下文切换和2次内存拷贝;如果守护进程涉及本地文件系统的读写,那么至少还需要2次运行态切换和1次内存拷贝。传统的内核文件系统处理1次I/O请求一般只需要2次运行态切换和1次内存拷贝,而不需要上下文切换。相比之下,FUSE 2次不可避免的上下文切换会带来较大的性能损失[22]。
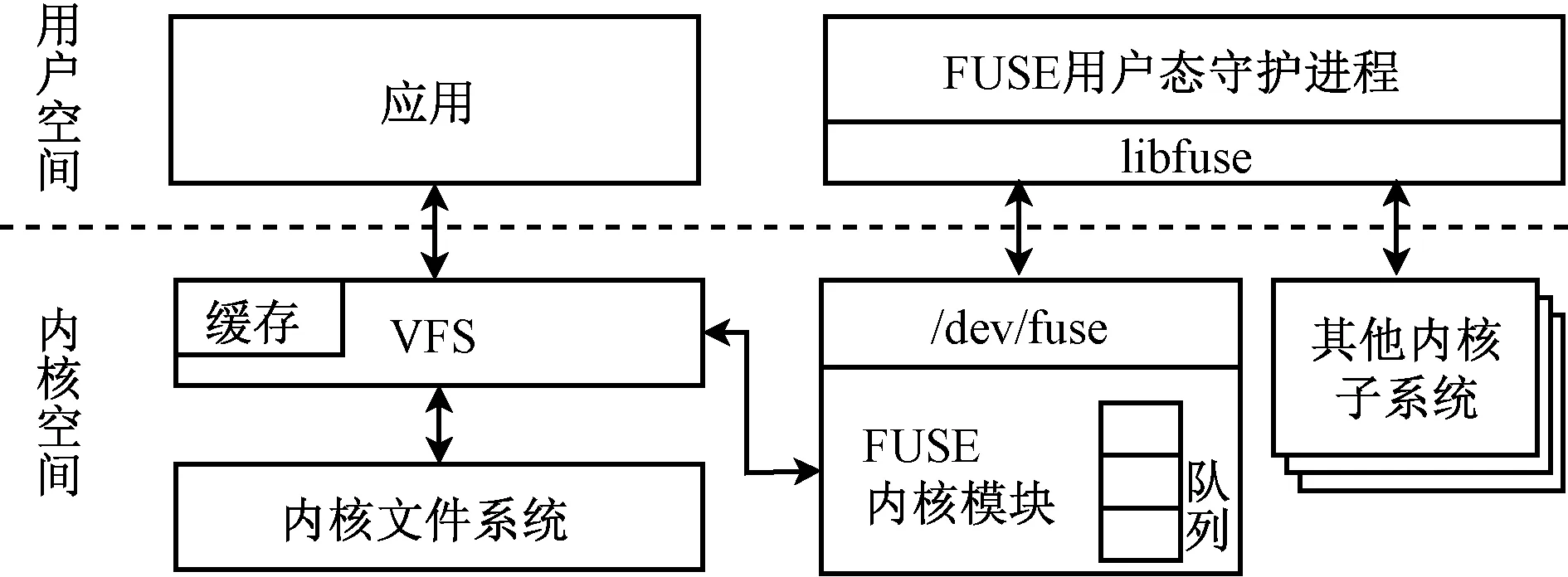
图1 FUSE的基本架构[14]
1.2 并行日志文件系统
为应对软硬件的错误,高性能计算系统会采用各种容错方案,例如检查点技术[23]。通过定期地将中间结果保存到存储系统,当系统发生错误并且被重置后,应用可以从最近的检查点中恢复状态并且继续运行。
并行日志文件系统(parallel log-structured file system, PLFS)[5]通过在存储栈中引入一个中间层的方式对检查点的写性能进行优化。PLFS重新组织存储模式,将N-1读写模式转成N-N读写模式,同时利用日志型文件系统利于写操作的特点[24],极大地提高了检查点的写入性能。PLFS专用于并行I/O,并且进行了大量的优化,可以通过FUSE挂载到目录树,因此能够在大量的I/O工作负荷下对FUSE进行测试,充分反映本文所设计方法的优势与不足。图2给出了通过FUSE挂载PLFS后的I/O操作流程。
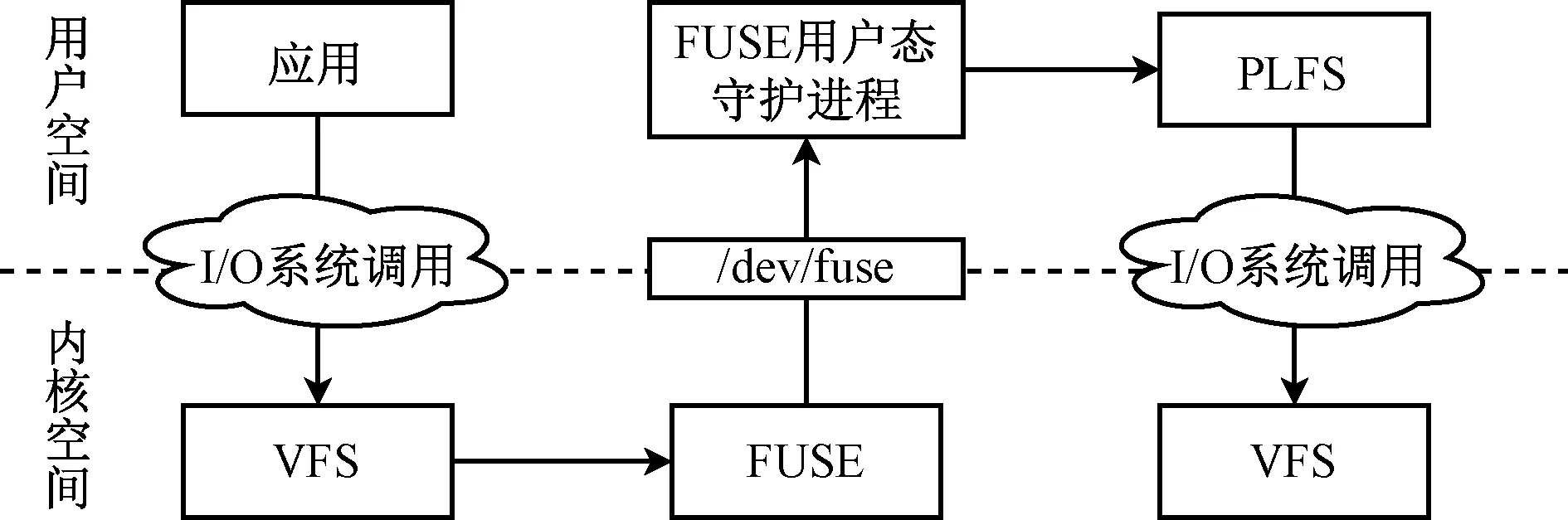
图2 PLFS通过FUSE的I/O操作流程
2 绕过FUSE的实现
PLFS提供了一组API,应用可以通过API直接使用PLFS的功能。绕过FUSE的一种方法是将应用源代码中所有I/O相关的函数调用替换成对PLFS API的调用,然后将源代码重新编译得到直接使用PLFS的可执行文件。该方法需要得到应用的源代码,并且对其有比较深入的理解,对于大多数应用来说局限性较大。
另一种方法是采用动态链接库覆盖用户态I/O函数的方式,将I/O操作重定向到PLFS内部。本文基于PLFS API设计并实现了一个动态链接库libplfs,通过libplfs能够在不需要对应用进行修改的情况下,达到绕过FUSE的目的。与此同时,在libplfs中收集相关数据,分析FUSE性能表现背后的原因。
2.1 链接与加载
动态链接库能够在运行时被链接到进程的地址空间,因此可以定义和I/O调用具有相同函数签名的函数,然后编译成动态链接库,利用该动态链接库对应用中的I/O调用进行高效地重定向,最终实现将I/O请求转发到PLFS中,把核心操作都放在用户态中完成。
LD_PRELOAD[25]环境变量用于指定最先加载的动态链接库,让自定义的动态链接库拥有甚至比标准库高的最高优先级,达到优先加载和链接自定义函数库的目的。
本文的方法是将PLFS API封装到libplfs动态链接库中,利用LD_PRELOAD实现优先加载和链接libplfs中的I/O库函数。
2.2 文件映射表与文件状态管理
由于POSIX API与PLFS API之间存在差异,上层应用通过POSIX文件描述符进行I/O操作,而在PLFS上进行I/O操作所使用的文件描述符具有其自身特点,因此需要在libplfs中实现从POSIX文件描述符到PLFS文件描述符的转换,并且对文件的状态进行管理。
本文通过2个内存中的全局哈希表(时间复杂度O(1))实现文件映射关系的管理,分别为fd_table和path_table。fd_table中的key为上层应用所使用的POSIX文件描述符fd,value为plfs_file结构体指针(见图3)。fd_table的作用是向应用提供POSIX文件描述符,保证可以在不对应用进行修改的情况下绕过FUSE并且使用PLFS。path_table哈希表用于对同一文件打开多次的情况,结合引用计数,实现将多个POSIX文件描述符fd映射到同一个plfs_file对象。fd_table中的键值对在libplfs中的open函数内完成插入(伪代码1中第10和16行),在close函数中进行删除,在libplfs中重载的其他I/O函数内,通过查询fd_table哈希表实现从POSIX文件描述符到PLFS文件描述符的转换。path_table仅在libplfs中的open函数(伪代码1中第8、9、10和15行)和close函数内使用。
以libplfs中重载的open函数为例(伪代码1),在打开某一文件时,通过路径参数判断该文件是否位于PLFS文件系统中,如果是,则在tmpfs上创建一个POSIX API所使用的文件描述符fd,然后打开该PLFS文件,利用fd_table和path_table记录fd与PLFS文件描述符之间的映射关系,为接下来应用通过POSIX文件描述符fd触发PLFS上的I/O操作提供翻译功能。伪代码1中涉及的Plfs_file结构体中具体成员信息见图3。

Pseudocode 1 open()function in libplfs
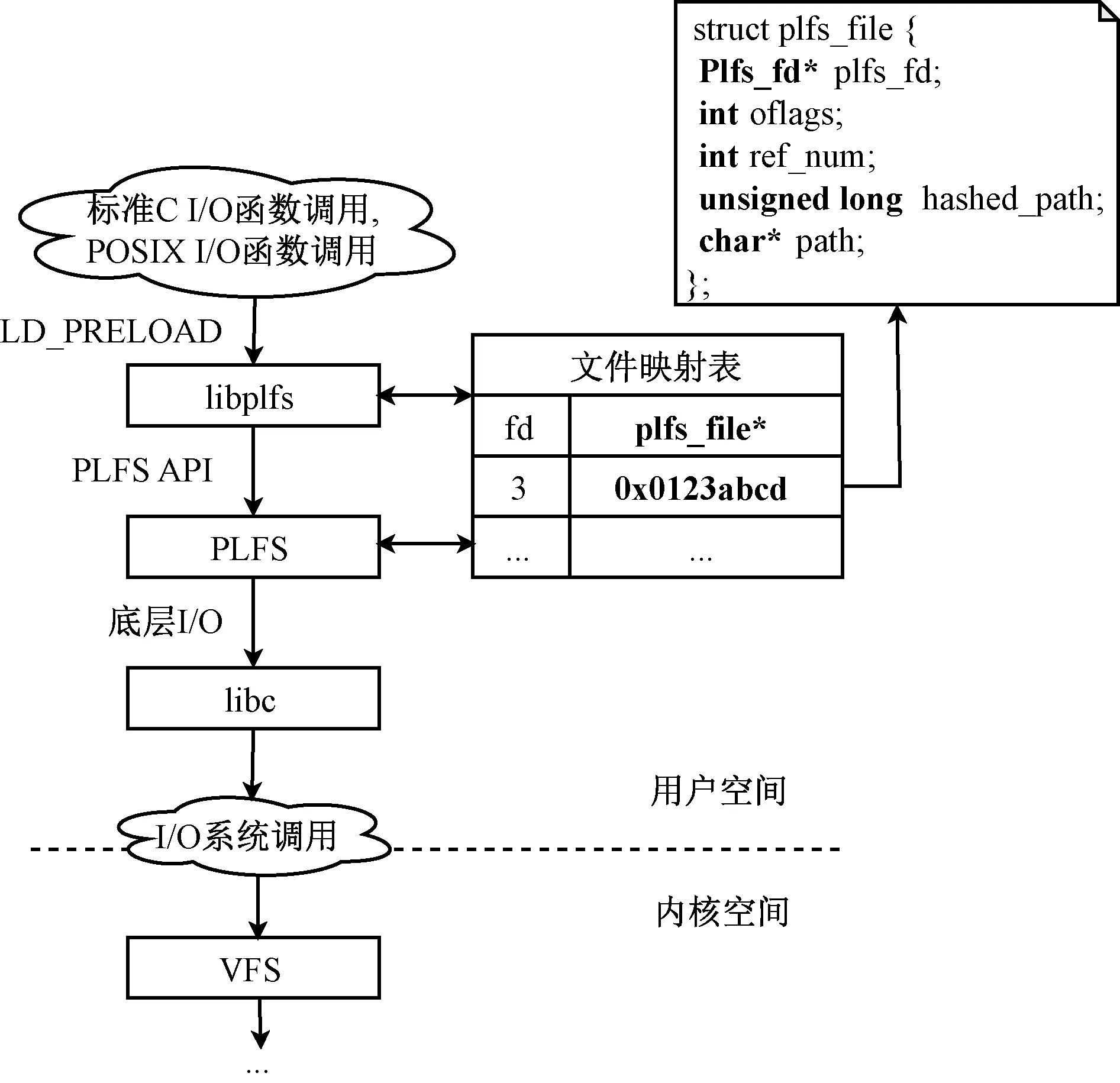
图3 libplfs的处理流程
2.3 libplfs的实现
libplfs的主要功能是在用户空间维护一个文件状态映射表,将对C标准库和POSIX I/O函数的调用转换成对PLFS API的调用。libplfs的具体函数调用流程见图3。
本文通过open(), read(), write()和close()这4个具有代表性的I/O函数对libplfs的实现进行说明。在打开一个文件时,libplfs在本地文件系统上创建一个临时的虚拟文件,为应用进程分配一个文件描述符fd。接着libplfs调用plfs_open()函数创建一个PLFS API使用的文件对象plfs_file,并且建立虚拟文件描述符fd与plfs_file的映射关系。当应用通过文件描述符fd读写文件时,libplfs利用plfs_file文件对象直接调用PLFS API,同时将应用传递过来的内存地址、请求大小和文件偏移量传递给PLFS API;在PLFS上完成I/O请求后对虚拟文件描述符fd的当前偏移量进行对应的调整。在关闭文件时,释放包括映射表中对应项在内的所有内存资源。对于并发的I/O请求,例如若干个线程同时打开同一个文件,通过引用计数的方式记录打开的次数,避免创建冗余的对象,提高内存利用率。
在进行I/O操作之前,libplfs对接收的参数进行判断,区分该操作是一般的I/O操作还是在PLFS上相关的I/O操作。如果是对PLFS的操作,那么libplfs调用对应PLFS API处理该请求,否则通过调用dlsym()函数得到libc中对应I/O函数的指针并调用它,如伪代码1中的第3和第5行。
libplfs重载了69个几乎所有libc中的I/O库函数。用户可以简单地通过设置LD_PRELOAD环境变量,将目标程序中的I/O操作重定向到libplfs动态链接库中,进而直接调用PLFS API,达到绕过FUSE的目的。该方法对所有在运行时动态链接了libc库中I/O相关函数的可执行文件都适用。
3 实验与分析
3.1 实验平台
测试集群由5个节点组成,其中1个作为主节点,4个以HDD(hard disk drive, 机械硬盘)为介质的存储节点。节点配置如表1所示。
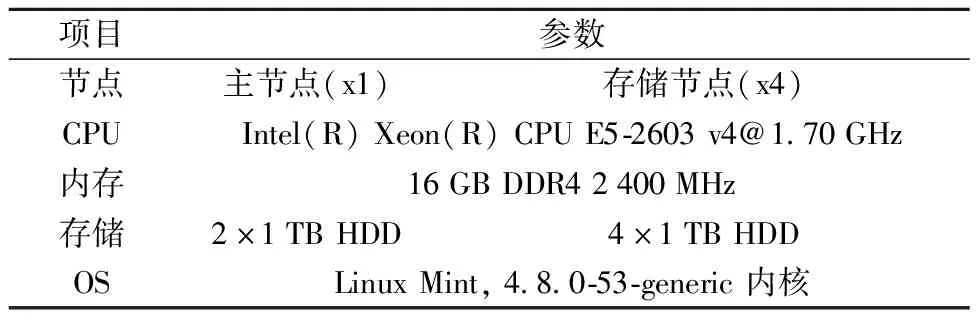
表1 集群节点配置
PLFS 作为一个可堆叠文件系统,实际不存储数据,而是将数据重新组织到底层文件系统中,向应用提供一个虚拟文件的接口。CephFS[26]是常见的高性能的文件系统,本文使用它作为PLFS的后端存储。4个存储节点组成一个Ceph对象存储池,其中1个节点还充当元数据服务器。主节点通过Ceph的内核模块将CephFS挂载到主节点的目录树中,将该挂载点目录设置成PLFS的后端存储。
3.2 实验设计
测试libplfs时,在LD_PRELOAD的作用下,所有I/O函数的调用被重定向到libplfs中,该测试探究libplfs下PLFS的性能,记作no-FUSE。在有FUSE并且默认设置的情况下进行测试,作为控制组FUSE-with-cache。在有FUSE时,不使用内核页缓存的方式下进行测试,探究FUSE内核模块中页缓存对性能的影响,记作FUSE-direct-IO。后端CephFS文件系统通过Ceph的内核模块挂载,并且启用缓存功能,采用默认配置。
本文通过文件大小、传输块大小和并发度3个参数的组合配置进行测试。每组实验重复10次,实验参数配置见表2。

表2 实验参数设置
本文采用LANL开发的fs_test[27]作为基准测试工具。为便于叙述,本文对测试点采用形如“4-512M-16K-read”的命名方式,表示4个线程并发读同一个大小为512 MB的文件,传输块大小为16 KB。在读测试之前,我们先完成对应的写测试以此来达到系统预热的效果,目的是更好地利用后端存储的缓存,避免后端存储成为性能瓶颈,从而掩盖FUSE的性能影响,造成实验数据偏差。每个测试点完成后,清空缓存中的数据。
得到测试结果之后,我们对一些测试点使用系统剖析工具进行深入分析,探究FUSE如何影响I/O性能,以及libplfs的优势。
3.3 实验结果
本文选择具有代表性的结果来进行说明,类别为小文件和大文件、串行和并发、读和写、小传输块(1 KB, 4 KB, 16 KB)和大传输块(64 KB, 256 KB, 1 MB)。
传输块大小与缓存利用率直接相关,决定了在给定文件大小条件下系统调用和内核函数调用的数量。选择传输块大小作为x轴。每一个实验运行10次,结果去掉最大最小值后取平均。
图4展示读测试的结果。从结果中可以得出,在所有传输块大小下,no-FUSE总是比FUSE-direct-IO的带宽要高。当传输块大于32 KB时,no-FUSE的带宽最高,最大提升131%。当传输块小于32 KB时,FUSE-with-cache带宽最高。FUSE-with-cache的带宽总是比FUSE-direct-IO高。变化趋势方面,FUSE-direct-IO与no-FUSE的变化趋势类似,而FUSE-with-cache的变化趋势比较平稳。单线程与多线程下读性能相仿。
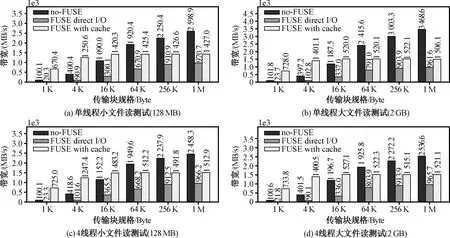
图4 读性能比较
图5展示写测试的结果。从结果中可以得出,在所有传输块大小下,FUSE-direct-IO的带宽总是比FUSE-with-cache高。当传输块小于64 KB时,no-FUSE带宽最高,最大提升5.7倍。当传输块大于64 KB时,no-FUSE被FUSE-direct-IO超过,二者性能差距大部分位于1%~8%,但二者都比FUSE-with-cache高。
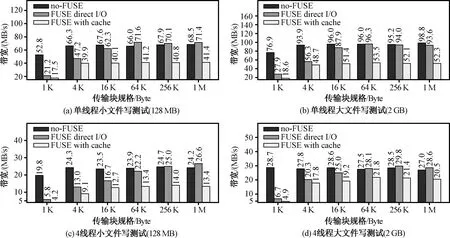
图5 写性能比较
图6给出了写测试中no-FUSE对比FUSE-with-cache所带来的的性能提升结果。结果表明,当传输块为1 KB时,4线程写测试的性能提升更大,当传输块大于1 KB时,单线程写测试提升更加明显。换句话说,在并发小请求的写工作负荷下,绕过FUSE带来的性能提升更加明显。
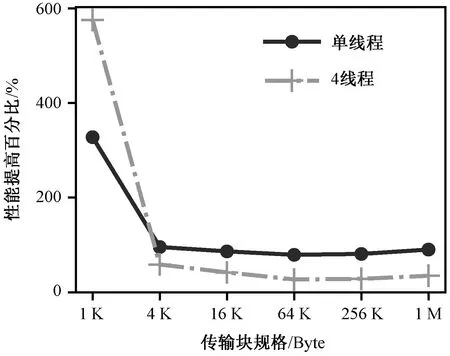
图6 写性能提高比较
3.4 结果分析
FUSE的内核模块可以利用内核页缓存,进行预取和写回操作,进而影响性能。通过libplfs绕过FUSE之后,运行态切换、系统调用和内存拷贝的减少有利于提升性能。
本节借助Linux系统提供的系统调优和调试工具对得到的结果进行分析和研究,所涉及的工具包括perf和ftrace。我们利用这些工具统计分析I/O过程中系统调用操作的数量、内核函数调用的情况以及页缓存的使用率。
3.4.1 读操作与页缓存利用率
FUSE的主要特点之一是可以利用内核页缓存。Linux内核将FUSE内核模块和底层文件系统当作2个不同的文件系统,它们在内核有独立的缓存空间,因此FUSE存在双重缓存的问题。换句话说,对一个文件进行读操作将导致同一份内容被缓存2次。在CephFS缓存被清空后运行“4-2G-1K-read”测试,页缓存使用情况见表3。
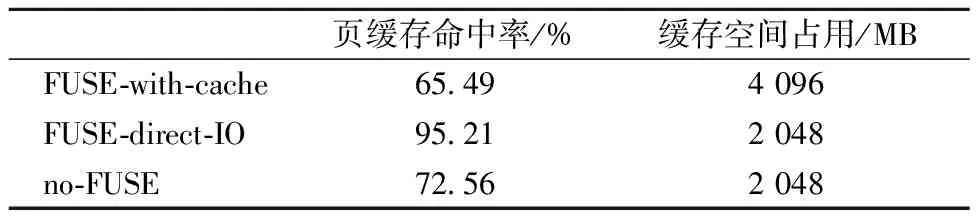
表3 清空缓存后测试缓存使用情况
表3结果显示,当后端存储缓存被清空时,双重缓存使FUSE-with-cache的缓存命中率最低;当后端缓存被预先填充时,FUSE-with-cache的缓存命中率可以提高到80%左右。
在读测试之前,先进行写测试然后卸载PLFS,保证读测试时CephFS的缓存处于有效状态。重新运行“4-128M-1K-read”和“4-128M-1M-read”测试项,统计VFS、FUSE和CephFS上内核函数的调用情况,结果见表4。

表4 内核函数调用数量
当传输块为1 KB时,FUSE-with-cache在缓存的作用下,使Ceph上的读操作只被触发1 506次;FUSE-direct-IO和no-FUSE的情况下,Ceph上的读操作是其350倍之高。当传输块为1 MB时,它们之间的差距缩小很多,只有2.4和1.1倍。结果表明,当传输块比较小时,在内核页缓存的作用下,FUSE-with-cache的性能最高。
3.4.2 系统调用(运行态切换)
I/O通过系统调用完成,系统调用数量与运行态切换数量正相关。当传输块很小时,一个I/O请求的实际数据传输时间很短,导致运行态切换开销占比很大。除此之外,系统调用数量与用户空间和内核空间之间的内存拷贝次数存在密切联系。对“4-128M-1K-write”和“4-128M-1M-read”两项测试中触发的系统调用次数进行统计,得到表5。
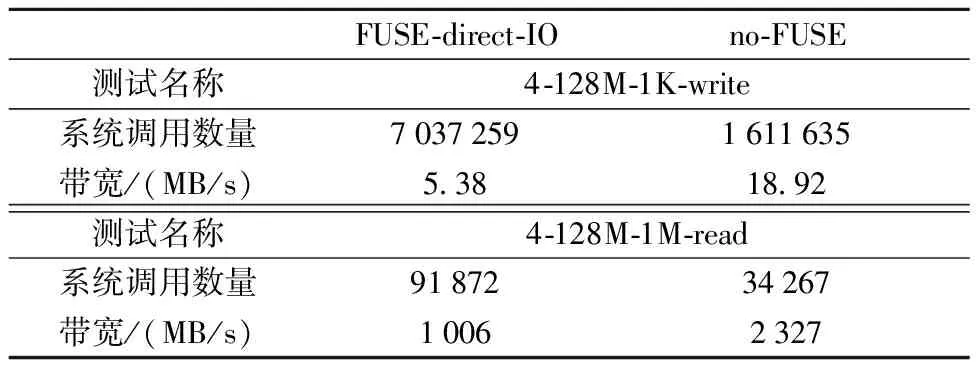
表5 系统调用情况
表5展示了测试的带宽和系统调用数量。在传输块为1 KB的写测试中,FUSE-direct-IO的系统调用数量是no-FUSE的4.4倍,然而每一个I/O请求的数据传输时间很短,大量系统调用使运行态切换的总开销占比很高,导致no-FUSE的写性能是FUSE-direct-IO的3.5倍。对于传输块为1 MB的读测试,no-FUSE的系统调用数量为34 267远小于FUSE-direct-IO的91 872,导致no-FUSE的读性能提升了131%。
4 结束语
本文研究FUSE在并行文件系统中的性能问题,基于动态链接的机制,实现了一种绕过FUSE的libplfs动态链接库,并且在PLFS文件系统进行实验和验证。实验结果表明,通过libplfs绕过FUSE后,可以在保证写性能的前提下,当传输块较大时,读性能提高最大可达131%;当传输块较小时,写性能提高最大5倍左右。对结果进行研究分析,发现内核页缓存和大量的系统调用是FUSE影响性能的重要因素。基于FUSE的文件系统在传输块较小时,双重缓存给文件系统的读性能带来了一定的性能提升,但同时大量的系统调用使其写性能降低2.5倍以上。对于并行文件系统,并且存在大量大块I/O,利用libplfs的方法可以带显著的性能提升。我们后续将对基于FUSE的不同文件系统进行研究,开展关于FUSE系统性能优化的通用性方面的探索,扩展现有的优化方案。
