基于阶梯收费刷卡数据的公交下车站点算法优化与实证评估
2022-03-18姜海航郭煜东刘健国
杨 飞,姜海航,郭煜东,刘健国,周 涛
(1.西南交通大学 交通运输与物流学院,四川 成都 611756;2.重庆市交通规划研究院,重庆 401147)
公共交通因其成本低、能耗低、占用资源少等优点,成为众多城市倡导的出行方式。随着相关政策[1]的提出,智能公交系统建设与优化受到关注。相比常规公交体系,智能公交在指挥调度、运营管理上实现自动化、精细化操作,大幅提升公交服务水平。准确分析公交客流下车站点,了解客流出行特征,摸清客流需求,对智能公交的调度、运营、规划具有重要意义。公交IC卡作为各个城市智能公交的基础部分,存储了持卡用户大量的乘车交易时空记录,成为获取公交基础数据的新来源。基于公交IC卡数据的下车站点研究成为研究热点。
在下车站点推算方法中,集计推算是一种常用、便捷的估计方法,但该方法仅能推算出站点客流总量,无法确定每位乘客的下车站点。个体推算方法中,基于公交出行链的估计考虑较多,这些方法相对容易且易于理解。2002年,James等[2]根据地铁出行日志的记录设计了两个假设:一是乘客会返回上次的目的地车站开始下一次出行,二是乘客的最后一次出行会返回第一次出行的起点,据此利用纽约市的AFC(automatic fare collection)数据实现了下车站点的推算。之后一些学者在该研究基础上进一步修正,Munizaga等[3]研究中发现仅通过该假设易导致下车站点推算错误,在James等假设的基础上,进一步考虑了下一次公交出行的上车位置和时间并增加了额外的约束条件,优化了站点推算目标函数。Alsger等[4]利用澳大利亚昆士兰州公交系统中含有乘客下车记录的特殊收费数据验证了出行链理论的下车站点推算模型,并研究了最大步行距离取值对推算结果的影响。He等[5]针对出行链断裂情况(无下一次公交出行或下一次公交出行起点不能作为上次出行的终点),利用乘客历史出行数据建立了个体空间和时间的下车复合概率模型,用以推算出行链理论无法解决的记录。Kumar等[6]放松了现有公交出行链方法的参数限制,采用多元logit模型计算连续上车站点之间的路径选择概率,以最大概率方式推算乘客的下车站点。
但基于公交出行链的经典推算方法难以估计单次、独立出行的下车站点,造成估计客流不能代表所有公交乘客真实的出行情况。一些研究通过补充多日刷卡记录推算更多的数据,其主要思路是在多日数据中寻找相似的出行记录或与他日出行记录建立连接修复断裂出行链。但该方法在海量数据中需要设定复杂的规则,同时并不能有效地提升推算率。为解决该问题Gordon等[7]研究中补充了公交投币箱票务数据和登车器人次数据,以此估算规则算法无法确定乘客和票务现金支付乘客的出行流量。Yan等[8]提出应用朴素贝叶斯、SVM(support vector machine)、决 策 树、随 机 森 林、KNN(k-nearest neighbor)和集成学习等机器学习算法进行下车站点的识别,杨鑫[9]以乘客的基本上车特征作为模型的输入,采用Bi-LSTM-CRF模型对乘客的下站点实现推算。
乘客在选择某线路某站点上车后,可供选择的下车站点是有限的,因此相关研究将乘客下车站点推算视为分类问题,采用机器学习方法实现推算[8-11]。相对于出行链的推算方法,基于机器学习的方法能够解决单次出行的下车站点识别,但也需要大量的训练数据及标签,同时预测耗时长,预测结果也存在较大偏误。对此,Yan等[8]利用POI(point of interest)数据确定站点所在区域的土地性质,估计下车站点所在的交通小区,最终正确率达到70%以上,识别效果较优。
对于这类数据,也有学者从概率角度进行分析。胡继华等[12]通过计算站点上车客流,推算指向下游站点吸引权最大的站点,李佳怡等[13]同样采用了该方法。这些方法都假设个体服从群体的下车分布概率,即乘客很有可能选择最大概率(最大吸引权)站点下车。
然而,大部分公交线路采用“一票制”收费方式,乘客下车时不会进行刷卡操作,基于公交IC卡的下车站点估计缺乏有效验证。对此,本文首先利用随机森林算法对现有出行链算法进行优化,构建了完整的公交出行下车站点估计模型。然后结合具有公交上下站点的阶梯收费刷卡数据,对两种算法的识别效果进行实证评估,保障了算法的可靠性。
1 公交下车站点估计模型
根据个体乘坐公交的行为模式,下车站点推算包括两个步骤:首先结合乘客常见行为模式,构建出行链估计模型,再针对出行链断裂等复杂情况,利用随机森林网络进行进一步优化。
1.1 出行链估计模型
个体每日出行活动具有一定规律性,其公交出行多呈现时空闭环特性。本文结合现有研究,以个体多日或连续的公交出行行为为基础,首先构建包含下述3条推断的出行链估计模型,初步推算下车站点。
(1)当乘客存在相邻的两次乘车出行,若后次的乘车站点位于前次乘车站点的下游,则乘客前次乘车的下车站点位于后次乘车站点附近。
(2)当乘客为最后一次乘车出行,若该乘车站点远离当日第一次乘车站点,则为返程出行,下车站点应位于第一次乘车站点附近。
(3)当乘客为最后一次乘车出行,若该上车站点靠近当日第一次乘车站点,则为非返程出行,下车站点位于第一次乘车的下车站点附近。
1.2 随机森林网络
由于个体出行行为相对复杂,仅依靠出行链模型不可能实现所有情况分析,尤其是单次刷卡记录和出行链断裂记录。对此本文结合随机森林网络,对两类数据的下车站点进行预测。利用公交IC卡数据推算下车站点可视为一种分类问题,即通过乘客上车时间、乘坐线路等特征筛选最可能的下车站点。随机森林网络是一种统计学习算法,通过重抽样方法从原始样本中抽取多个样本,对每个样本进行决策树建模,组合多棵决策树的预测并投票得出最终结果。随机森林网络具有分类回归精度高、不易过拟合、高维数据适应性强等优点,适用于复杂问题的分类与拟合分析。公交下车站点估算本质可视为一种分类问题,本文以下车站点编号为目标,将上车时间、乘坐线路、上车站点、持卡类型、用地性质等个体属性作为输入,构建相应随机森林网络。公式(1)为预测函数。

式中:H(x)为随机森林对输入变量x的最终预测;hi(x)为单个决策树分类模型;I(X)为示性函数。边缘函数是随机森林网络的重要属性,代表着对于输入变量X的分类中,正确分类得票数超过错误分类得票数的概率,边缘函数越大,随机森林分类的正确率越高,决策树与整个森林的边缘函数如公式(2)、(3)所示。

式中:g(X,Y)与r(X,Y)分别为决策树与整个森林的边缘函数;ak I()为所取平均值;Pθ(h(X,θ)=Y)为判断正确的分类概率为判断错误的其他分类的概率的最大值。
公式(4)为泛化误差,表示模型对未知数据的预测能力,泛化误差越小模型预测效果越好。公式(5)为随机森林的边缘函数期望。

公式(6)为决策树之间的相关程度,其中v(r)、s(h(r))2分别为r(X,Y)的方差与标准差。
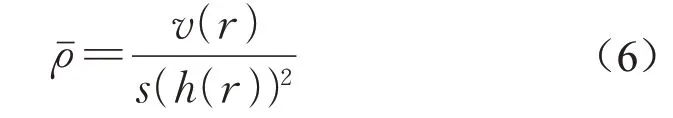
最终随机森林网络模型表达式如式(7)所示。
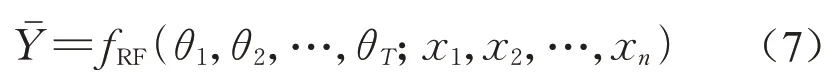
式中:(θ1,θ2,…,θT)为随机森林中待标定参数;T为待标定参数的个数;n为输入变量维度。
2 数据分析
2.1 公交阶梯收费刷卡数据
公交阶梯收费刷卡数据是乘客下站识别的基础,相比传统公交IC卡数据,乘客在分段计费线路的上下车均要刷卡,为个体层面数据验证提供了保障。本文公交IC卡数据涵盖某市连续5个工作日城市区域全部数据,共计11条分段计费线路,215 212条刷卡数据。线路均为中长距离干线,沿城市主要客流走廊布设,占城市公交总运量的40%,具有良好的代表性。刷卡数据字段包含乘客持卡编号、刷卡时间、乘坐线路、乘坐车辆、刷卡行为等信息,其中刷卡行为用以说明乘客是上车还是下车。表1为2019年7月15日公交刷卡数据样例。

表1 公交刷卡数据样例Tab.1 Sample of bus swiping card data
2.2 公交GPS数据
公交GPS用于确定公交实时位置,判断公交到站情况。其数据字段包含车辆牌照、线路、时间、速度和经纬度等信息。表2为公交GPS数据样例。

表2 GPS数据样例Tab.2 Sample of GPS data
2.3 公交站点数据
由于公交GPS数据不包含公交进出站信息,需要联合公交站点数据,识别不同时间公交到站点。数据字段包括站点名称,经纬度,途经线路等,表3为站点信息数据样例。

表3 公交站点数据样例Tab.3 Sample of bus station data
2.4 模型输入特征分析
乘客公交出行中将产生多种关联信息,合理的输入参数是下车站点估计的关键,根据个体实际分析,本文选择如下特征,同时结合其他信息构造新的特征,作为随机森林的输入。
2.4.1 上车时间、上车路线、上车站
个体的一日活动通常具有规律,同一时段、同一路线及站点的活动目的相对固定,下车站点也基本相同。
为保障识别结果的准确,上车时间以小时为间隔进行离散化,上车路线、上车站点利用标签编码法(label encoding),从0开始进行重新编码。
2.4.2 持卡类型
持卡类型代表乘车人属性,能够大范围缩小目标用户,与(1)中特征联合,能够较好刻画乘客特征。持卡类型同样利用标签编码法进行编码。
2.4.3 活动半径与出行频率
活动半径表征乘客活动空间大小[14],代表乘客站点空间特征,出行频率代表乘客对各个站点的出行偏好。图1为活动半径示意图。本文以5个工作日全部乘车数据为基础,分析乘客所有上车站点分布特征,公式(8)为活动半径计算公式。

图1 活动半径计算原理Fig.1 Calculation principle of active radius

式中:μ为活动半径;r i为形心到上车站点i的距离。
由于活动半径μ与出行频率分别为连续型与接近连续型变量,直接使用难以获得准确估计结果,同时无法直接确定分类类型。对此,本文利用K-means聚类方法对两个变量分别聚为3类,以划分不同出行特征的乘客,表4为出行频率与活动空间的最终聚类结果。

表4 出行特征划分规则Tab.4 Classification rules of travel feature
为了更直观地展示特征取值分布,将取值进行min-max归一化,取值界限约束到[0,1]之间。以出行频率f为例,转换函数如式(9)所示。

式中:fk为出行频率f中第k个取值;f*k为fk归一化后的取值;min(f)为所有出行频率f中的最小值;max(f)为所有出行频率f中的最大值。
图2为聚类结果示意图。可见不同活动空间与出行距离被分为9类,不同类别间的特征差异显著。
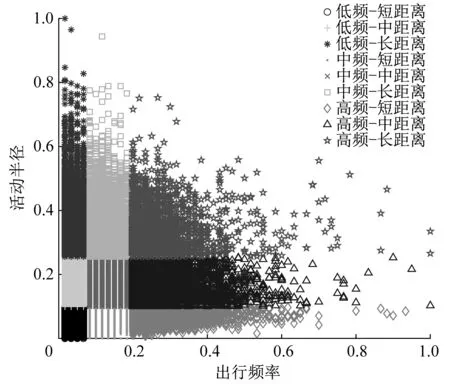
图2 公交乘客聚类Fig.2 Clustering of bus passengers
2.4.4 下游站点用地类型
不同用地类型下的站点客流吸引力存在较大差异,本文以站点周围500 m半径为活动范围,统计下游主要用地类型,图3为站点周围用地类型示意图。

图3 站点500 m覆盖用地示意图Fig.3 Schematic diagram of 500m site land use coverage
由于乘客并不会在所有下游站点进行选择,本文以R为活动空间影响阈值,提取当前站点到R内特定站点C的用地面积,并将最大面积作为输入特征。

式中:C为阈值范围内的下游站点数;R为活动范围直径;lnon为线路非直线系数;ds为线路平均站间距。
2.4.5 下游站点下车概率
受站点周边区域人口、岗位和土地利用等因素的影响,不同站点的下车客流存在差异,区域内站点下车客流能够反映出区域的吸引力,吸引力较大的区域更有可能吸引乘客下车。本文将同一群体在同一线路、同一方向、同一站点的下车分布频率作为先验概率,则概率最大的站点为乘客最可能前往站点。以0.5为最大概率的下限值,若最大概率大于下限值,则最大概率对应的站点可推算为下车站点,若小于下限值则需要采用其他规则重新推算。其中,本文利用乘客下车信息直接获取该先验概率,对于非阶梯收费线路,可预先调查获取目标线路各站点的下车乘客数,再统计获取目标站点下游站点的下车概率。
对于无法确定最大概率站点(概率>0.5)的情况,可利用相邻站点概率分布进行叠加,以此反映相邻站点周边区域的下车吸引力。如图4所示,在同一站点上车的群体出行数据中提取各下车站点(s1~s10)的出行频率(f1~f10),将频率大于零的相邻下车站点划分为多个站点区域,叠加各区域内的站点频率作为该区域的下车概率P,则下车概率最大的区域为乘客最可能前往的区域,该区域中概率最大的站点可作为乘客的下车站点。
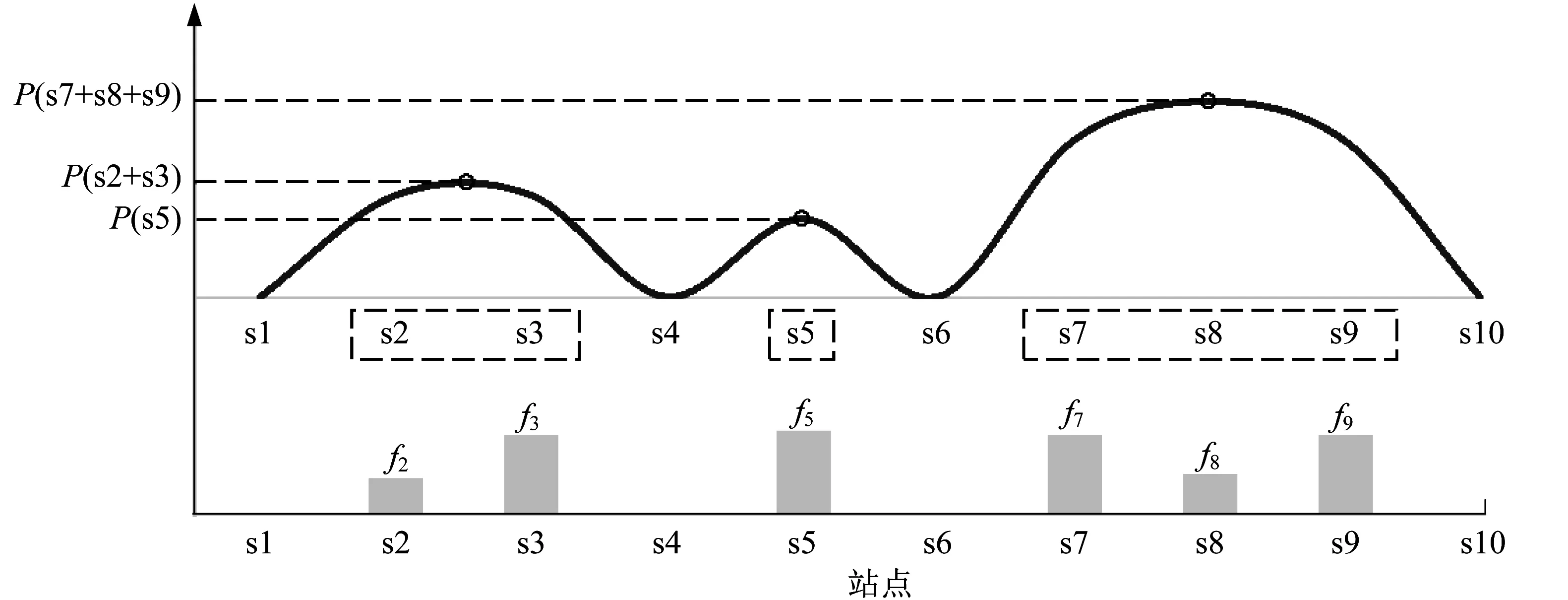
图4 站点连续区域下车概率示意图Fig.4 Probability diagram of getting off in continuous area of station
3 实例应用
本文针对5个连续工作日内采集的215 158条公交出行数据,分别对比现有公交出行链模型、随机森林算法与本文构建融合模型的下车站点识别差异,并结合推算率、有效率、正确率3种指标分析识别结果。其中正确率代表估计站点与实际站点一致;有效表示推算站点与实际站点误差在一个站范围内。


式(11)、(12)中:N为有效估计的站点数量;P为全部样本数;Cl为推算率;E为有效率;Ea为全样本有效率;Pe表示有效估计的站点数量。
3.1 与公交出行链模型对比
表5为公交出行链模型与本文融合模型的识别结果对比。可见公交出行链模型尽管具有较高的正确率和有效率,但全样本有效率仅为55.6%,无法估计单次刷卡记录和出行链断裂记录,也难以代表全样本情况。而本文提出的融合模型能够实现100%出行数据推算,全样本有效率达到76.2%,同时样本有效率与正确率相比出行链模型差异不大,整体提升效果显著。

表5 融合方法与公交出行链模型结果对比Tab.5 Comparison of fusion method and bus travel chain model
3.2 与随机森林方法对比
针对公交出行链模型无法推算的35.5%剩余数据,将既有的随机森林方法与本文提出的融合模型的识别效果进行对比,如表6所示。由表6可知,两类方法均能实现100%结果估计,尽管既有的随机森林方法在公交出行起讫交通小区识别的正确率达到70%以上,然而本文以出行起讫公交站点为评价单元,相比交通小区层面识别更加困难。将既有方法应用到公交站点识别中,识别正确率约为19%,而本文提出模型通过增加乘客活动半径、出行频率等输入,将正确率提升至33.4%。两种方法的正确率都相对较低,这主要由于单次刷卡以及出行链断裂的出行记录无明显规律性,难以准确推算乘客的下车站点。但值得注意的是,本文模型在错误估计的估计下车站点中,57.2%与真实站点仅相差1个公交站,相比现有研究仍具有较大提升,说明算法仍具有相对准确的识别效果。

表6 融合方法与随机森林方法结果对比Tab.6 Comparison of fusion method and random forest
3.3 基于融合模型的下车估计结果
图5、6为不同出行距离下,本文提出融合模型的下车站点估计的详细结果。在2 km误差范围内,误差分布于0~100 m内占比最高,其次主要集中于200~600 m,大致为两个站点之间的距离。可能原因是乘客下车在站点周边移动后并未返回前次出行的站点上车,造成推算结果与真实站点间存在一段距离。

图5 下车站点短距离误差分布Fig.5 Error distribution of short distance at leaving station

图6 下车站点长距离误差分布Fig.6 Error distribution of long distance at leaving station
从长距离出行的误差分布来看,近80%的误差在0~1 km之内,误差在5 km以上的占6.4%。由于城市交通出行需求研究中,常以交通小区为基本单位,占地面积为1~2 km2,因此从小区尺度看,近80%的推算记录能够满足分析需求。
4 结论
准确预测公交客流下车站点是了解站点客流、线路客流以及公交起讫点的基础,有助于把握公交出行特征,对智能公交规划、调度、运营、管理具有重要的意义。
(1)本文以公交阶梯收费刷卡数据、车载GPS数据为基础,在传统公交出行链识别算法基础上,结合随机森林算法,构造了一套公交下车站点融合分析模型。首先基于公交出行链的方法,估计大部分乘客的下车站点,然后对未推算记录,利用随机森林方法进一步完成估计。
(2)构建的融合模型针对刷卡记录的下车站点成功推算率达到100%,全样本有效率达76.2%,其中近80%的记录误差在1 km范围以内。说明本文提出模型具有较高的识别效果,能够满足区域层面(交通小区)的分析需求。
作者贡献声明:
杨 飞:核心思想提炼。
姜海航:论文撰写,论文修改。
郭煜东:论文撰写,论文修改。
刘建国:数据收集处理,论文撰写。
周 涛:资料整理,思想提炼。
