基于大数据的油料装备保障模型研究*
2022-03-17邬美春左永刚陈福泽党海鹏
邬美春 左永刚 陈福泽 党海鹏
(陆军勤务学院 重庆 401331)
1 引言
随着科技的不断进步,大量运用高精尖技术的武器被投送到战场,导致现代化局部战争变得复杂化、多样化,战场态势也发生重大改变,这使得人员对装备的依赖度越来越高,大大增加油料装备保障的难度和成本。从最近几次局部冲突中可以看出,占据信息优势的一方能很快掌控局势,人员和装备补给较为迅速。
随着军队改革步伐的不断加快,新型装备也在快速列装,但大量不同型号的武器装备给后勤装备保障部门的保障能力带来较大的压力。近年来,我军推动了后勤保障建设向信息化转型,在精确化保障、规范化管理、科学化建设等方面取得了创新发展。但我们同时也应该看到在装备信息智能化保障方面还存在不足,传统低效单一化的保障模式仍然存在。因此,寻求新技术、新手段提高装备保障的信息化水平,对提升军队作战能力具有重要意义。
大数据深度挖掘技术作为一种较为日渐成熟的数据处理手段,能够快速理清需求和供应之间复杂的关系,提供最优的解决方案。将常年累积的装备保障信息进行了处理,建立装备保障预测模型,为提升装备保障能力提供了新思路。刘洪伟[1]分析了常用的保障模式,针对信息化装备具备数据下载、加注的保障特点,并需要定期进行更换的特点,完成装备保障信息化模型的建立及系统实现。焦敬义等[2]利用数据挖掘技术对装备保障信息资源中大量数据进行挖掘,为装备保障部门的正确决策提供科学的依据是装备信息管理的重要内容。
上述研究表明,大数据技术对装备保障信息化建设具有一定的指导作用,但目前研究还远远不足。本文基于大数据挖掘技术,建立了装备保障信息化管理模型,并验证了模型的可靠性,为提升装备保障水平提供了有价值的参考。
2 油料装备保障水平现状
目前,后勤保障建设信息化水平不断提高,油料装备保障作为其中的重要组成部分,信息化建设也取得了较大的进展。为满足不同类型装备及作战形式的油料装备保障需求,各级后勤装备保障部门依据实际需求,搭建了许多不同类型的装备保障平台。然而,由于数据种类繁琐、通用性较差,平台之间的关联性不强、数据利用效率较低,出现了许多“信息孤岛”,造成一定程度上的资源浪费。
为了对标现代战争,必须要运用大数据思维和精确算法,准确掌握后勤保障需求、供应、保障数据信息,畅通保障链路。在建立后勤大数据资源库的基础上,通过电脑与人脑的有机结合,运用精确算法,实现缺什么补什么的目标。通过依托后勤大数据平台,统筹平战时可动用的各类资源及分布情况,通过深度计算和精确计算,对军内资源和地方资源、部队资源和联勤资源、自我资源和友邻资源进行测算、统筹、优化和设计,生成适应作战需求的后勤供应保障方案。
大数据时代的到来,既是挑战、更是机遇。以数据为坐标,统筹后勤整体建设,积极抢占数据保障主权,实现我军后勤和装备信息化建设的跨越式发展。
3 大数据技术研究现状
当前物联网、大数据和云计算的发展,掀起了第三次信息化浪潮[2]。随着数据量的积累,传统的数据处理模式已经不能满足任务需求,大数据处理技术应运而生。大数据具有数据体量大(Volume)、处理速度快(Velocity)、数据类别大(Variety)、数据真实性高(Veracity)、价值密度低,商业价值(Value)高[3]等特点[3]。表1表达了传统数理统计与大数据处理技术的异同。
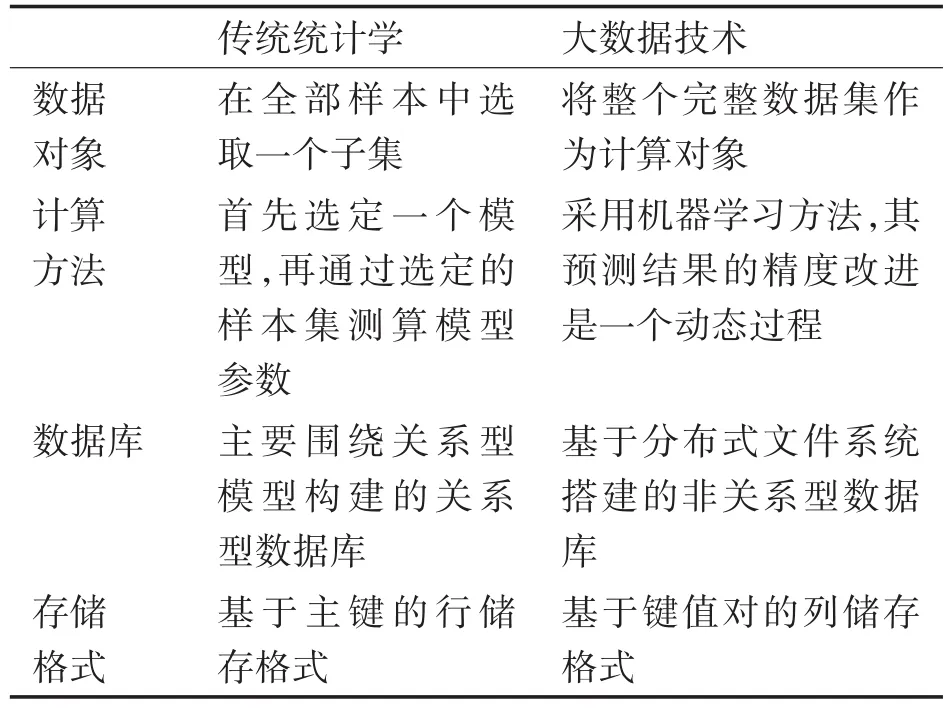
表1 大数据与传统统计学的不同
大数据计算体系由数据存储系统、数据处理系统、数据应用系统三个基本系统组成。具体如图1所示。
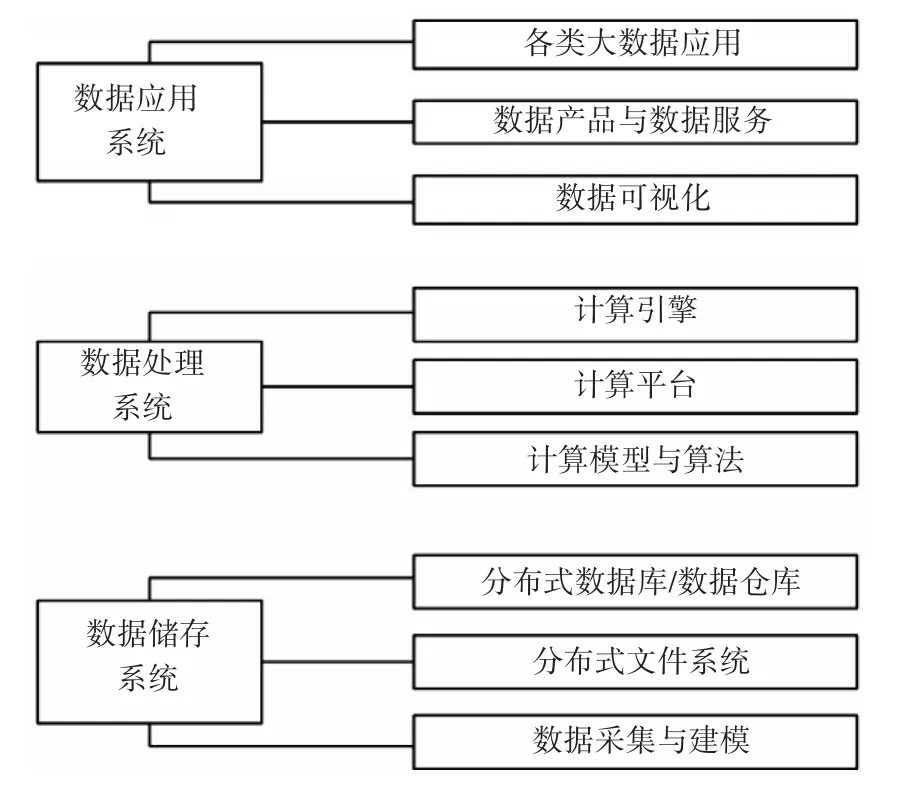
图1 大数据分层计算系统
三个阶层各有不同的作用。相较于传统的关系型数据库系统,大数据的数据存储系统较为复杂的多[4~8]。主要表现为关系型数据库通过外键关联来建立表与表之间的关系,非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定。对于数据处理系统而言,可按照功能和相似度对不同算法进行分类[9~12]。计算处理模型需要针对不同数据的类型、不同处理方式需要不同的计算模型来提供计算范式和数据处理逻辑。
对于油料装备保障系统而言,数据是分析数据之间内在规律以及建立模型的关键,但油料装备活动包括装备发展规划与计划、研究设计、试验定型、生产制造、筹措、供应与调拨、编配、储备、分级与转级、日常保管、日常操作使用、战时运用、维护保养、维修与抢修、退役与报废和教学与培训等。各种类型信息之间难以互联,因此,在数据存储层要对数据进行归一化处理。
4 油料装备管理模型
4.1 建模思路
建模的目的是实现油料装备的快速化、智能化保障。大数据平台构建,应该以油料装备管理人员的业务应用需求的先导,只要弄清需求才能提出具体的应对措施,从而根据需求进行相应建模。魏忠平等[13]从业务和技术两个方面论述了油料装备保障应满足的主要需求,本文以此需求为出发点进行模型建立。
通过大数据技术建立模型可分为几个步骤:
1)数据收集:在现有军事综合网的基础上,组织对采集数据的分类、甄别和统计、梳理。
2)数据归一化处理:制定归一化指标规则,对不同类型的数据进行归一化处理。
3)数据清洗:为保障模型的可靠性,应摒弃不合理的离散数据。
4)特征提取与数据拟合:以MIC作为相关性评价指标,找出黏性系数相关性较高的参数,通过泛函网络自适应拟合方法,给出各参数之间的大数据特征函数[14~15]。
4.2 建模流程
根据装备保障信息管理需要解决的问题,进行数据采集,然后不同的数据进行权重设置。具体流程图如图2。
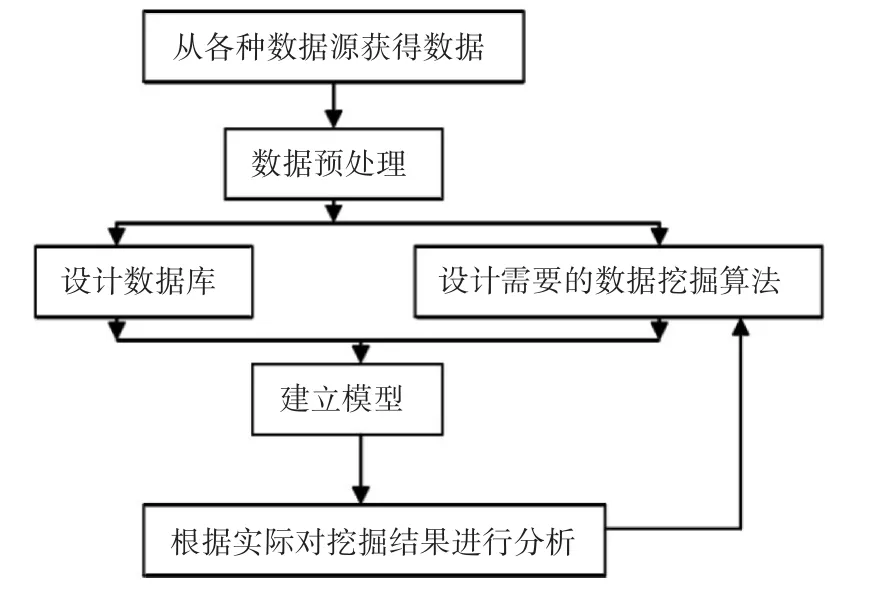
图2 建立模型流程图
数据的归一化是数据分析的关键,对数据样本的处理方法至关重要。本文所获取的样本当中,有些样本获取的年代较久,有些样本较新,有些样本来源于实战,而有些样本则来源于训练或是仿真实验等。这些因素决定着样本在关系挖掘过程中的重要程度是不一样的,若不考虑这诸多的不同而将每个样本的惩罚系数设置为一样,则必然使所得模型的精度与泛化能力受损,影响模型的使用。因此,本文选取样本加权最小二乘支持向量回归模型处理数据。
设有N个训练样本(xi,yi)。因此在标准最小二乘支持向量优化问题中引入样本权vi,就变为如下优化问题:
其相应的对偶问题为
由上式可以到最终的拟合函数为
其中 Kf(x,xi)=K(VTx,VTxi)为加权核函数。
在确定了模型之后,就将模型转化为计算a、b值的问题。由于a、b非线性的关系。最大互信息系数作为一种非线性相关度量,具有普适性、公平性和对称性等优点。普适性是指在样本量足够大(包含了样本的大部分信息)时,能够捕获各种各样有趣的关联,而不限定于特定的函数类型(如线性函数、指数函数或周期函数),或者说能均衡覆盖所有的函数关系。公平性是指在样本量足够大时能为不同类型单噪声程度相似的相关关系给出相近的系数。例如,对于一个充满相同噪声的线性关系和一个正弦关系,一个好的评价算法应该给出相同或相近的相关系数。MIC与其它相关性算法对比如表2所示,MIC是一种计算复杂度低,适用于线性与非线性数据,鲁棒性高的相关系数算法[16~18]。
MIC源于互信息概念,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不确定性。简而言之,互信息可理解为联合分布与边缘分布的相对熵,但是一般情况下联合概率计算比较麻烦。
MIC是针对两个离散在二维空间中变量之间的关系,使用散点图来表示,将当前二维空间在x,y方向分别划分为一定的区间数,然后查看当前的散点在各个方格中落入的情况,这就是联合概率的计算,这样就解决了在互信息中的联合概率难求的问题。MIC的计算方法如下所示:
式中:a,b是在x,y方向上划分格子的个数,本质上就是网格分布,B是变量,一般取数据量的0.6次方。
对于给定i和 j的情况下 M(X,Y,D,i,j)的计算方法,即:给定很多(i,j)值,计算每一种情况下M(X,Y,D,i,j)的值,将所有M(X,Y,D,i,j)中的最大那个值作为MIC值。MIC计算分为三个步骤:1)给定i,j,对 X ,Y 构成的散点图进行i列 j行网格化,并求出最大的互信息值;2)对最大的互信息值进行归一化;3)选择不同尺度下互信息的最大值作为MIC值。
4.3 模型的训练与可靠性测试
从已有的数据库中选取14组样本数据,共分为4类(a.信息化时代、训练演习、同类装备2组数据;b.信息化时代、训练演习、近似装备6组数据;c.半机械化半信息化时代、实战、近似装备3组数据;d.信息化时代、仿真实验、同类装备3组数据)。进行训练,并另选择8组数据(信息化时代、训练演习、同类装备)进行精度测试。训练数据如表2所示。
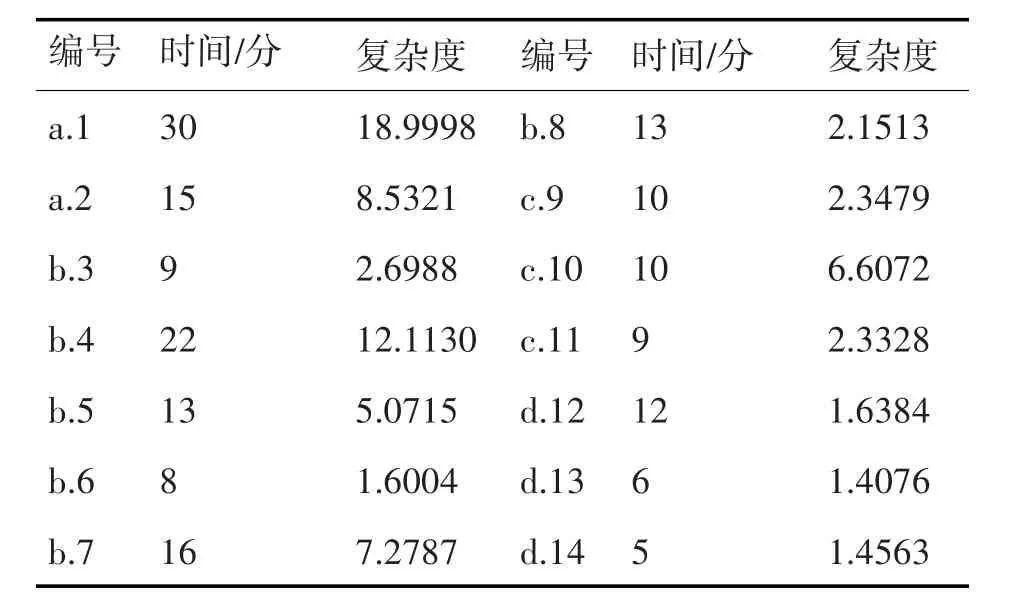
表2 训练数据
利用该模型对测试样本进行测试所得结果如图3及表3所示。
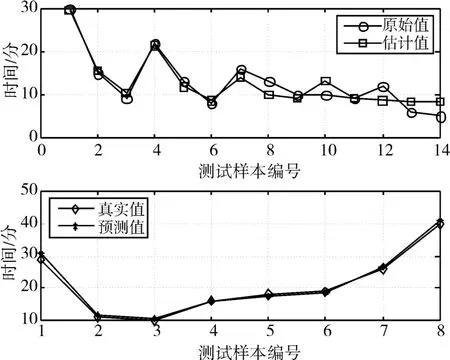
图3 测试结果
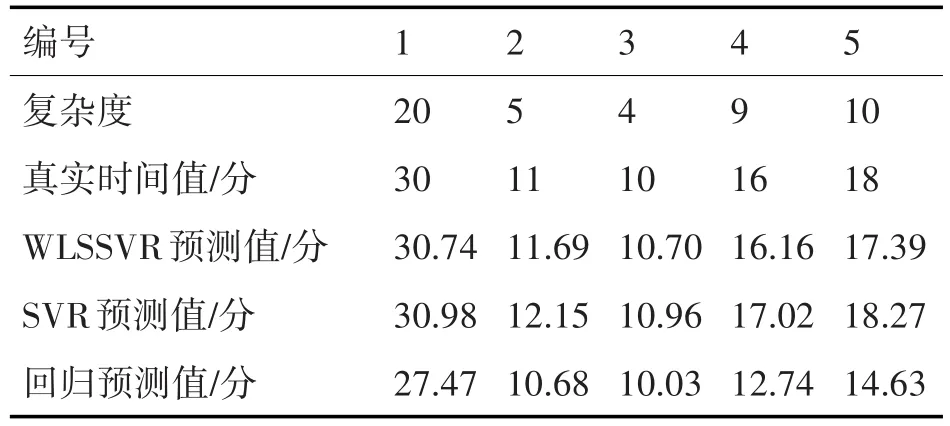
表3 不同方法的测试结果
5 结语
研究分析了目前油料装备保障的现状,介绍了大数据挖掘技术的原理,关键技术及系统组成。基于大数据技术建立了样本加权的最小二乘支持向量回归模型,并进行模型的可靠性验证,结果表明本文所提出的能够较好地预测在复杂战场环境下,油料装备保障的最优时间,能够为油料装备保障信息化建设提供有价值的参考。
