基于空间通道注意力机制的渐进式图像超分辨重建算法
2022-03-17谢超宇王晓明
秦 玉,谢超宇,王晓明
(西华大学计算机与软件工程学院,四川成都 610039)
近几年来,对深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展。其中,将视觉注意力(attention)机制与深度学习相结合的研究工作,是近年来深度学习研究的一个热点。例如:1)将注意力机制用在分类问题上,在2017ILSVR竞赛取得冠军的SENet 网络(squeeze-and-excitation networks)就是此类典型应用,Hu 等[1]还将其子结构SENet block 插入到现有多种分类网络中,都取得了比较好的效果;2)将注意力机制用于改进激活函数,Zhao 等[2]提出了“自适应参数化修正线性单元”(adaptively parametric rectifier linear unit),也叫APReLU 激活函数,该激活函数借鉴SENet block中通过注意机制对特征进行调整的思想,通过注意力机制对PReLU 激活函数的斜率进行调整,使得固定的非线性变换能够自动学习[3]。在计算机视觉(computer vision)中,注意力机制的基本思想是让模型学会注意力,能够忽略无关信息而关注重点信息。
在当前的单帧图像超分辨率(SISR)算法研究中,注意力机制也被广泛引入,例如在SEnet 基础上Zhang 等[4]提出了RCAN 网络(image superresoulution using very deep residual channel attention networks),它在更深层的网络中加入残差思想,并考虑到特征通道之间的相互依赖性,提出通道注意机制,进行通道上的特征自适应学习。还有基于视觉应用的自注意机制的非局部注意力机制用于SISR,例如Dai 等[5]提出的SAN(second-order attention network for single image super-resolution),其不再探索更深更宽的网络,而是在网络中加入非局部模块同源残差的思想来对网络的中间特征进行探索。Mei 等[6]提出了CSNLN(image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining),其将远距离特征相似性考虑进网络模型中,探索不同尺度特征之间的关系。
他们都取得了比较好的结果,但是也有一些不足。例如RCAN 注意了通道之间的关系,但是没有注意到空间尺度上空间区域的关系,而且在统计全局信息时,由于捕获长范围特征依赖需要累积很多层的网络,所以学习效率太低,此外,网络累计过深,需要小心地设计模块和梯度。CSNLN 的非局部注意力模块虽然考虑到了长范围特征依赖,但是在非局部注意力的计算中,存在计算量偏大等问题,而且只涉及到了位置。注意力模块没有涉及通道注意力机制。为了更好地解决上述问题,本文提出一个端到端的可训练的网络结构,即基于空间特征变换(spatial feature transform,SFT)层的空间通道注意力机制重构的渐进式网络算法。其主要工作总结如下。
1)引入空间特征变换的思想,对提取的中间层特征进行仿射变换自适应调整,为图像重建阶段提供更多的空间不同且相似的特征信息。
2)利用空间特征变换的思想,对通道注意力模块进行改进,提出基于空间特征变换的空间通道注意力机制,使注意力分配更加合理,从而使得网络在重构时更合理地利用中间特征进行超分率图像重建。
3)引入反投影的思想,在对特征进行融合时,让融合特征更加注重差异性,使网络在重构时,融合特征不至于过于冗余。
1 相关工作
1.1 通道注意力机制
SENet block[1]的核心思想是让网络根据损失函数去学习特征权重的分布,然后将学习出的权重施加在特征上,即SENet block 是采用有效特征的权重更大,无效或者效果小的特征权重更小的方式去训练模型,以达到更好的重建结果。
如图1 所示,它在只用卷积网络连接的经典网络中,加入Squeeze 和Excitation 结构。Squeeze 过程是对提取的特征进行全局平局池化,将W×H×C的特征挤压成1×1×C,即图中的Fsq操作。然后经过Excitation 过程,即图中Fex操作。Fex由2 个全连接层组成,它融合了各通道的特征信息,学习出C个权重。最后通过Fscale操作将权重重新分配到各个通道。

图1 通道注意力机制模块
1.2 空间特征变换
Wang 等[7]在SFTGAN(recovering realistic texture in image super-resolution by deep spatial feature transform)中引入语义分割概率,用其对特征进行指导学习。受到SFTGAN 的启发,Gu 等[8]提出SFTMD(blind super-resolution with iterative kernel correction),它利用SFT 模块引入多个模糊核,模拟多种下采样情况让模型进行学习。前者将语义分割概率用空间特征变换(SFT)层进行传递,用语义指导特征学习和重建,后者将多种模糊核用SFT 层进行传递,让网络学习出兼容多种模糊核的模型。在SFTGAN 中SFT 学习一个映射M,输出一对调制参数 β 和 γ,然后用得到的调制参数对,对输入特征进行仿射变换。其模型可以表示为:

式中:ψ定义为语义分割后的概率;F为提取的特征;⊙代表像素之间的乘积。引入这样一个设计,使输出至少能够回到输入状态,不至于降低模型的表现(当γ=1,β=0时)。
2 本文方法
RCAN 虽然成功引入通道注意机制,让全局特征信息在通道间进行自适应调整,并最终取得了比较好的效果,但是忽略了中间特征图在图像重构时的作用。D-DBPN[9]虽然使用了稠密连接的思想防止梯度弥撒的问题,并且在最后将中间特征图进行级联以增强特征,但是忽略了不同中间特征图在图像重构时贡献力度不同的问题。CSNLN 虽然使用跨尺度非局部注意模块提取特征,并且在最后使用级联的方式来重构图像,但是非局部注意模块存在计算量偏大的问题,且只考虑了长范围特征依赖。
为此,受到SFTGAN[7]和SFTMD[8]思想的启发,本文对RCAN[4]中的通道注意模块进行改进,提出了一种新的注意力机制,即基于SFT 的空间通道注意力机制。它可以使网络在重构阶段,对聚合的中间特征在通道和空间上进行全局信息自适应调整,解决了RCAN 只注意通道的问题,解决了D-DBPN 忽略了不同特征层在重构时贡献力度不同的问题,与CSNLN 的跨尺度非局部注意模块相比计算量也相对偏小。此外,本文还结合LapSRN[10]的渐进式思想和SFTGAN、SFTMD 的特征变换的思想提出了基于SFT 的空间通道注意力机制重构的渐进式网络。本文算法网络主要分为3 个阶段:图像输入阶段、特征提取阶段、图像重构阶段。其中,特征提取阶段包含浅层特征提取单元、渐进式特征提取单元、伪仿射特征提取单元、SFT 单元,如图2 所示。
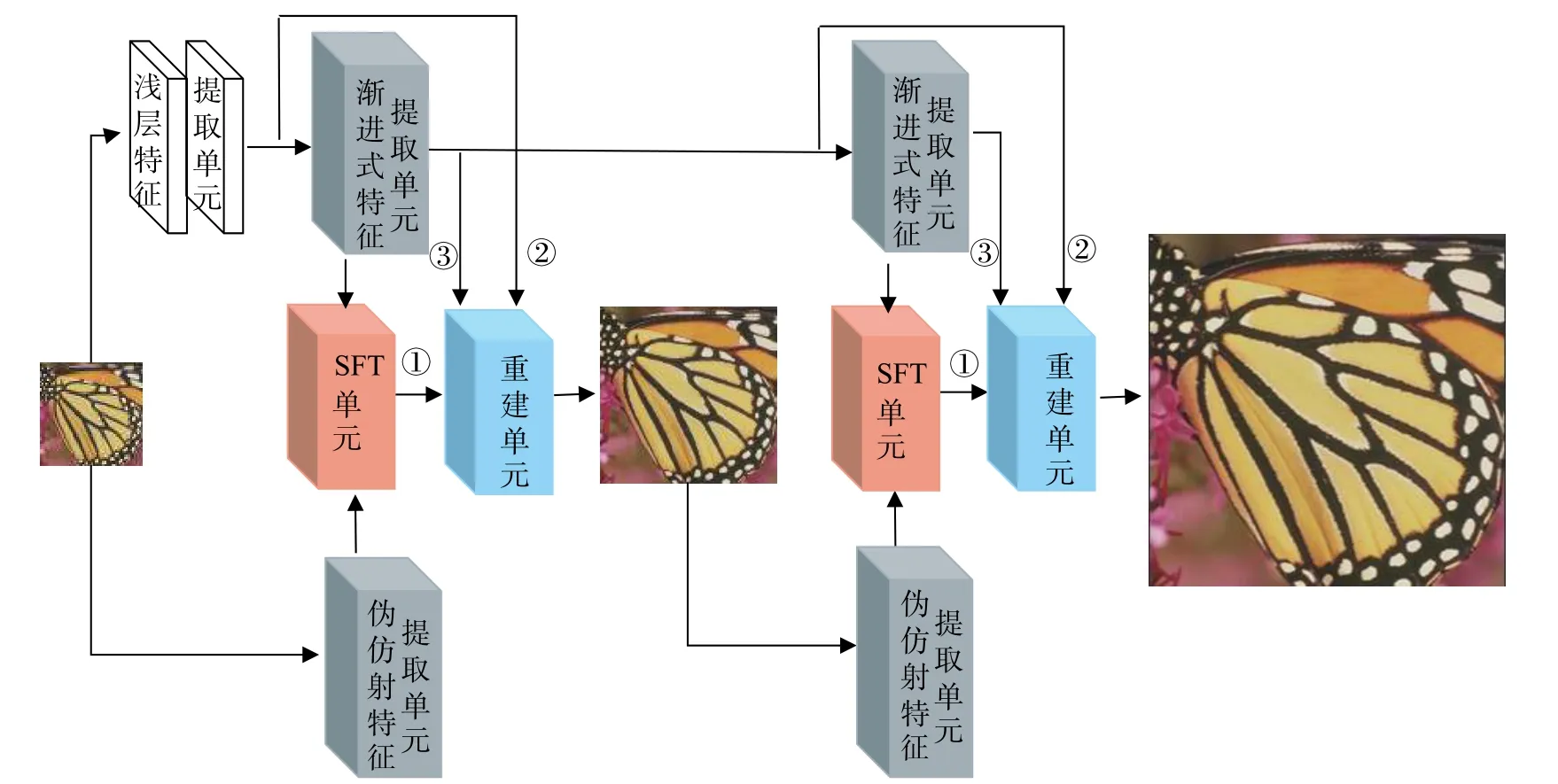
图2 本文算法网络结构
为了对指定放大倍数的SR(super resolution)进行更好地重建,在特征提取阶段,本文借鉴渐进式逐步放大至目标尺寸的策略,这不仅降低了预处理方法引入的噪声,还减少了放大过程中高频信息的丢失,减小了在图像重建时造成可见重构伪影的可能[11]。同时,为了在重构阶段重建出纹理细节更加丰富的图像,使用SFT 层在特征层之间进行自适应调整空间特征。最后采用本文提出的SFT 空间通道注意力模块(SFTCA 模块)进行图像重构,使网络可以在通道和空间尺度上利用各层中间特征值进行超分辨图像重建。
2.1 渐进式特征提取单元
在本网络结构中,使用渐进式放大的思想进行特征提取。首先对输入的LR 图像进行浅层特征提取,然后经过一个级联的卷积操作挖掘更深层次的特征信息,最后通过一个反卷积层,将其放大2 倍。
假设输入图片ILR大小为(H,W),输出图片为ISR,大小为(sH,sW),s为尺度因子,这里可以取2,4,8。渐进式上采样模型可以表示为:
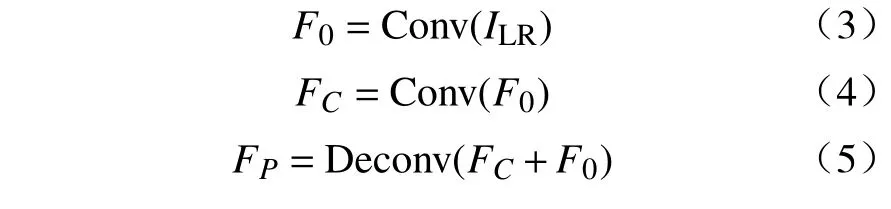
式中:F0定义为提取的浅层特征;Conv(·)定义为卷积操作;FC表示级联卷积后的特征;D econv(·)表示反卷积操作;FP表示最后得到的渐进式特征。
在进行反卷积操作时,加入残差连接的思想来增强特征学习,如图3 所示。

图3 渐进式特征提取单元
渐进式上采样单元最后的输出连接到2 个不同的层:一是将渐进式特征FP输入到下一级渐进式上采样单元中;二是将渐进式特征FP,作为SFT 层的一个输入特征FP输入到SFT 层。
2.2 空间特征变换单元
文献[12]提出的U-net 网络(convolutional network for biomedical image segmentation),对压缩路径的特征进行裁剪,并将其加入到扩展路径进行归一化操作,来增强网络特征细节。本文用空间特征变换单元,代替特征压缩进行裁剪来实现空间多尺度的纹理细节增强。
对于SFT 层的输入,本文与SFTGAN 和SFTMD 采用的SFT 又有所不同,这里不再输入语义分割概率 ψ或者模糊核H。受到U-Net 思想的启发,本文先将LR 图像送入类似于U-net 的压缩路径,将得到的特征再输入到SFT 单元,进行空间特征相似性自适应,以此来加强特征。
空间特征变换单元(SFT 层),可以减少进行裁边操作的开销,这不仅减少了压缩路径和扩展路径一一对称对应操作的开销,也降低了由不能完美裁剪和对应关系造成的特征累加或抵消的可能[13]。空间特征变换单元在不直接处理输入图片的情况下,利用仿射变换对中间特征层进行变换,最后影响输出结果。空间特征变换单元如图4 所示。

图4 空间特征变换单元
在本网络中作为特征提取阶段时的空间特征变换模型可以表示为:

式中:γ为缩放因子;β为平移因子;⊙代表像素之间的乘法。
空间特征变换单元的另一个输入,本文暂时称为伪仿射特征Fω,其结构如图5 所示。获取它的操作可以看作VGG 网络的语义提取[14]和自编码解码结构[15]对其降噪的结果。
图5 伪仿射性特征提取单元
2.3 基于SFT 的空间通道注意力重构单元
多数超分辨方法,在图像重构阶段,使用一个卷积或者反卷操作。D-DBPN[9]、CSNLN[6]等网络使用级联操作,对中间特征进行融合。本文网络结构会产生2 个分支,4 种特征。为了更好地融合中间特征,受到SFTGAN 和SFTMD的思想启发,本文采用基于SFT 改进RCAN 后的通道注意力机制,即基于SFT 的空间通道注意力机制,来对中间特征层进行融合。这个新的注意力机制重构模块,称之为SFT空间通道注意力模块(SFTCA 模块),如图6 所示。

图6 SFTCA 模块
首先,将网络模型的中间特征进行级联,对其进行Squeeze 操作,提取全局特征信息;然后使用SFT 结构代替Excitation 操作和注意力分配操作。这样不仅在通道上进行注意力自适应,而且还在空间上进行特征自适应,以求得一种空间依赖关系。其过程可以表示为:

式中:FU定义为级联的中间特征;ZC是全局平均池化后C个通道的全局信息的描述;γ为缩放因子,β为平移因子,是一对调制参数对;⊕代表矩阵加法;⊙代表像素之间的乘法;δ代表sigmoid 门控函数;H′是经过SFTCA 模块后得到的重新分配注意力的特征;HR表示最后重建出的图像。
在基于SFT 的空间通道注意力重构单元中,为了更好将模型的中间特征进行融合,重构单元不是简单地将3 个特征进行级联后送入SFTCA 模块,而是采用部分迭代反投影的思想,对3 种特征进行进一步处理,让级联的特征不至于冗余。重构单元的结构如图7 所示。

图7 基于SFT 的空间通道注意力重构单元结构示意图
文献[16]指出,融合特征层数并不是越多越好。为此,本文在进行级联特征时也做了简单的特征层筛选。
在多数深度学习超分辨重构模块中,大多使用单一卷积操作,忽略了不同特征层之间关系,或者将不同特征层之间的特征进行简单级联,这样不仅忽略了不同特征层在重建时,其贡献力度不同的特性,还忽略了空间特征层之间的自相似性。基于SFT 的空间通道注意力重构单元不仅学习不同特征层之间的在通道和空间上的依赖和差异性,还利用不同特征源进行残差学习,从而使得特征更加具有鉴别性。
3 损失函数
大多数基于深度学习的超分辨重建算法使用的是L2损失函数或者L1损失函数作为网络模型训练时的损失函数。文献[17]指出:L2损失函数忽略了图像内容本身的影响,不可避免地产生模糊预测,恢复出的高分辨图像往往过于平滑;L1损失函数可以忍受异常值,相较前者而言,没有那么平滑且收敛效果也比较好。本文网络大体结构类似于LapSRN,但是又有所不同。本文网络中间结构加深,特征提取类型变多。为了选取更加适合本文模型的损失函数,本文4.1 节对3 种不同损失函数进行对比实验。其结果表明,LapSRN损失函数比L1损失函数和L2损失函数的重建效果更好。LapSRN损失函数[10]的表达式为

式中:x是 输入的低分辨图像;y是真实图像;是预测图像;L是 放大级数;S为对应级数的因子(例如放大因子为2、4、8,对应级数为1、2、3);N是输入图片的数量;ρ是惩罚函数,,这里设置ε=1×10−3。
4 实验
实验使用含800 张图片的DIV2K 数据集[18]进行模型训练,不做数据增强。实验测试集采用Set5[19]、Set14[20]、BSDS100[21]以及Urban100[22]。在进行测试时,首先将模型输出的结果,转成YCbCr 格式,然后只计算Y通道上的2 个客观评价指标:指标峰值信噪比(PSNR)和结构相似性(SSIM)[23]。同时,使用He等[24]提出的方法初始化网络权重,batchsize 设置为20,训练图片裁剪大小为32×32。初始学习率为1×10−4,实验一共迭代106次,并且在迭代训练的过程中做学习率衰减以优化模型训练,令每5×105次,学习率衰减10 倍[13]。实验使用动量为0.9 的Adam 优化器[25],使用L1损失函数验证SFTCA 模块的有效性,使用LapSRN损失函数验证本文算法的有效性。实验部署在Nvidia TITAN X(Pascal)GPU 以及Inter(R)Xeon(R)W-2125CPU 下。
4.1 L1、L2和L apSRN损失函数对比
在机器学习和深度学习模型中,损失函数的选取往往对模型结果影响较大。在SISR 任务中,大多使用的是L1损失函数和L2损失函数作为网络训练的损失函数。由于本文模型结构和LapSRN 相类似,同时为了选取更加适合本文模型的损失函数,因此,将LapSRN损失函数纳入比较范畴,对3 种不同损失函数进行对比。
实验将3 种损失函数分别作为本文所提网络的损失函数进行模型训练。为了方便展示效果,实验选取了3 种损失函数训练出的模型的中间结果,每隔5×104取样1 次,共取样8 次,并将取样出的模型在Set5 与Set14 测试集上做测试,进行结果对比。实验结果如图8 所示,可以明显地看出,L2损失函数相比L1损失函数、LapSRN损失函数而言,总体收敛效果比较差,而且训练的模型也不稳定。就L1损失函数、LapSRN损失函数而言,2 种损失函数在Set5 上表现得差不多,但是在Set14 上,以LapSRN损失函数作为损失函数,模型在PSNR 上有一定提升,且稳定提升。因此,文本采用了LapSRN损失函数作为损失函数。究其原因,渐进式网络将每层的梯度用于网络更新权重,更加适合渐进式网络的层次型结构。

图8 不同损失函数在Set5,Set14 上的表现
4.2 SFT 空间通道注意力模块实验
为了验证2.3 节所提模块的有效性,本文做了2 组对比实验。由于D-DBPN 在重构时,对中间特征进行融合比较简单明了,在此基础上实验,能更好体现SFTCA 模型的有效性和模型层数对网络的影响,所以选择了D-DBPN 来测试SFTCA 模块的功能而不是CSNLN。第1 组实验用于验证SFTCA模块的有效性,设置了3 个模型,即模型Ⅰ、模型Ⅱ与模型Ⅲ。模型Ⅰ是D-DBPN 的原文模型;模型Ⅱ是在模型Ⅰ的基础上,在网络最后进行图像重构时加入一个RCAN 网络使用的通道注意模块[4](channel attention,CA);模型Ⅲ是在模型Ⅰ的基础上,在网络最后进行图像重构阶段加入一个SFTCA 模块。构建这3 个对照模型,是为了验证2.3 节所提模块的功能:SFTCA 模块不仅在通道上对特征信息进行自适应学习,还在空间尺度上也学习到了特征信息。
实验数据集是对DIV2K 数据集进行随机裁剪13 次构成的集合,不做数据增强,每张大小为32×32,共1 万400 张。所有模型缩放因子为4,损失函数采用的是L1损失函数,这是因为通过4.1 节对3 种损失函数的对比实验,可以看出就重构后的PSNR 而言,LapSRN 损失函数最好,但是L1损失函数也比较相近,同时使用L1损失函数,计算量小,便于快速验证SFTCA 模块的有效性。实验结果如表1 所示。

表1 不同注意机制模型在Set5,Set14 上的表现
从实验结果看,在D-DBPN 后面接入一个CA 模块(即模型Ⅱ),虽然在Set5 数据集上PSNR 值有一定的提高,但是在Set14 数据集上却没有提高。模型Ⅲ,无论是在Set5 还是Set14 上,PSNR 值都有所提升,分别提升了0.06dB 和0.02 dB。这验证了本文提出的SFTCA 模块的确有效,它学习到了中间特征在空间和通道上的依赖关系。但是其效果在SSIM 上似乎没有明显改进。
此外,对于中间特征的融合,本文做了进一步研究,即第2 组对比实验。在重构阶段,增加融合特征模块数量的时候,模型参数会增大。文献[16]指出融合的特征层数和重构效果并不成正比。为此,本文做了进一步实验,验证所提重构模块是否满足这一结论。实验条件和第1 组实验一致。实验结果如图9 所示。

图9 不同特征层数Set5,Set14 上的表现
通过对特征层融合数量的调整实验可以发现:在D-DBPN 实验模型来看,对于Set5 而言,层数越多,效果越好,但是在Set14 上效果变化不是很明显;在将本文提出的SFTCA 模块加上时,在融合特征层数为5 层和6 层时,效果基本一致,实验结果印证了文献[16]的推论。为此在2.3 节中,本文选择了网络中能使重构效果达到最好的3 种特征,来重建图像。这样既可以减少级联冗余特征,又可以减少网络模型的参数量,并同时加速网络收敛。
4.3 综合实验结果对比
将本文提出的算法与部分主流深度学习算法进行比较,并且给出综合评价。所有算法采用的测试集是Set5、Set14、BSDS100 和Urban100。其中Set5、Set14和BSDS100数据集中包含了人物、动物、植物等多个自然场景,Urban100包含了不同角度、不同场景等城市场景。实验结果对比算法有SRCNN[26],FSRCNN[27]、VDSR[28]、EDSR[29]、Lap-SRN[10]、DBPN[9]、RDN[30]、RCAN[4]、SAN[5]、CSNLN[6]。采用公开代码实验,并且对这些算法的PSNR 和SSIM 指标在放大不同倍数时进行对比分析[31]。为了使实验具有可比性,在训练的时候,都采用同样的数据集进行训练,并且在测试集上对结果取平均值。
表2、表3 分别示出各个算法在放大倍数为4、8 倍时的结果。从表中实验结果来看,本文算法比多数算法取得的重建效果好。从D-DBPN 与DDBPN+SFTCA的对比实验结果来看,当放大4 倍时,在4 种测试 数据上,D-DBPN+SFTCA 的PSNR 值分别提高0.04、0.02、0.02、0.09dB;当放大8 倍时,PSNR 值分别提高0.02、0.04、0.00、0.06dB。可见,无论是在放大因子为4、还是8 时,SFTCA 模块的确有效。该模块在通道和空间尺度上学到了一定东西。此外,本文算法在放大4 倍时,在Set5、Set14 以及BSDS100 上,相比SAN 来说,2 个指标不相上下,但在Urban100 上有所提升,在放大8 倍时,有显著提升。相比目前比较优秀CSNLN 而言,在放大因子为4 时,本文算法的2 个指标却不及。

表2 各SISR 算法的x4 模型在不同数据集上的表现

表3 各SISR 算法的x8 模型在不同数据集上的表现
针对不同算法模型在测试数据下的表现,图10 至图13 展示了其中部分算法在缩放因子为4 时的实际预测结果。它们分别选自不同的测试数据集:Set5 中的“baby”、Set14 中的“foreman”、BSDS100 中 的“ 210088”以 及 Urban100 中 的“img_018”。观测各种算法下重建图像的局部放大图,可以发现,从视觉角度主观感受而言,各种算法(Bicubic 除外)在Set5 和Set14 上的重构结果基本没有太大区别。在BSDS100 的“210088”(如图12所示)的局部放大图上可以明显感觉到,本文算法的“发光触手”的边缘相比LapSRN、D-DBPN 等算法更加锐利,色泽也更加饱满。在Urban100 测试数据集的“img_005”中,如图13 所示,本文算法预测出的“砖头之间的沟壑”也更加清晰,显得有层次感。
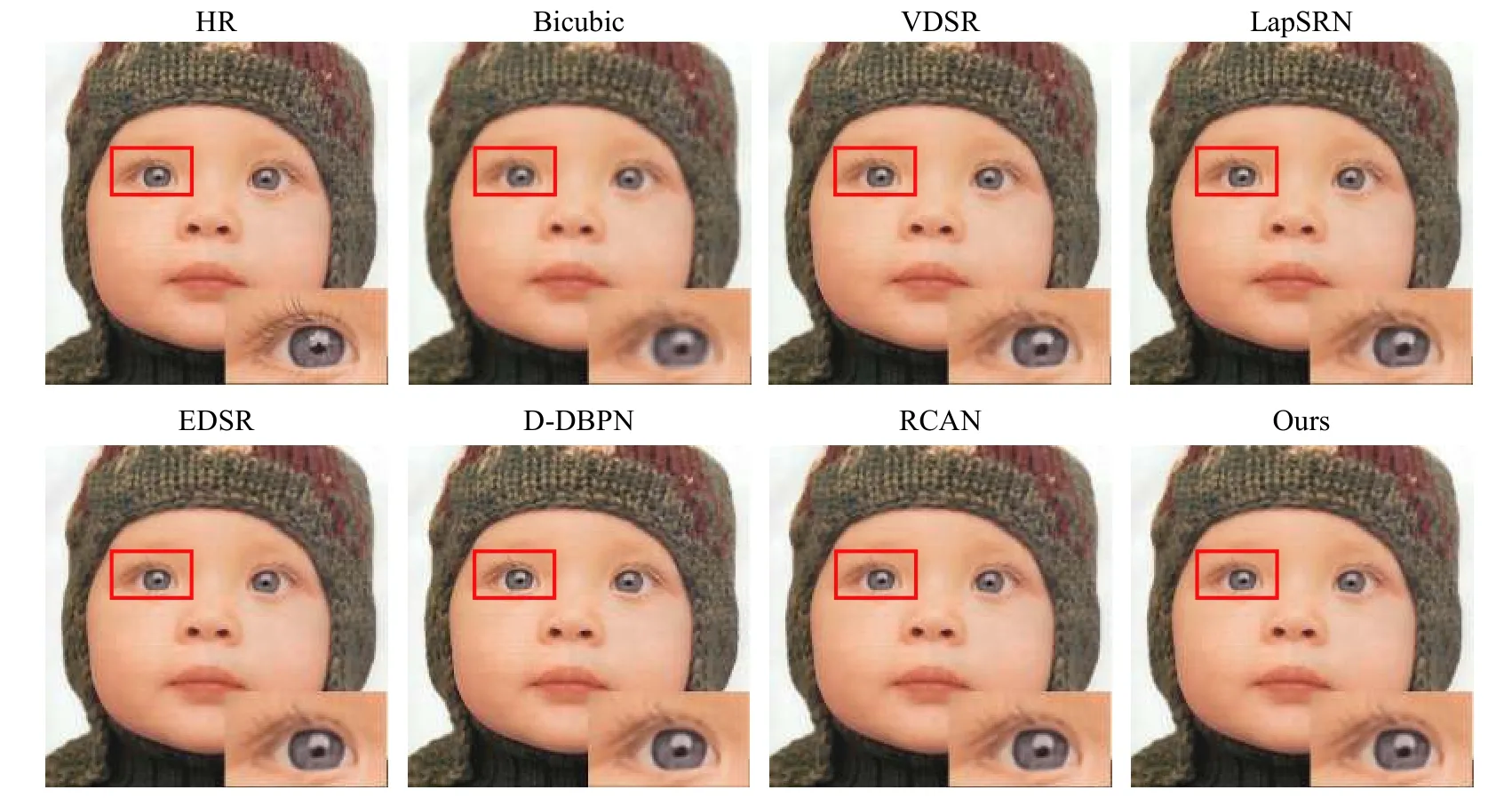
图10 测试集Set5 中的“baby”重建效果对比

图11 测试集Set14 中的“foreman”重建效果对比

图12 测试集BSDS 中的“210088”重建效果对比

图13 测试集Urban100 中的“img_018”重建效果对比
从上面的客观指标分析和主观视觉效果分析来看,由本文算法重建出的结果,表现出了一定优越性,证明了网络中所提结构模块的有效性。本文算法在特征提取阶段,利用经伪仿射性特征单元后得到的特征指导中间特征学习,在重构阶段,利用空间变换的思想,使得重构模块在空间和通道2 个维度对中间特征进行重构,从而使重构出的结果包含多角度的特征信息,效果更好。
5 结束语
本文首先利用SFT 思想对RCAN 中的CA 模块进行改进,提出SFTCA 模块,并在D-DBPN 上验证了其有效性;然后将SFT 思想和渐进式思想融合与SFTCA 模块进行结合,提出基于SFT 的空间通道注意力机制重构的渐进式网络。网络总体效果相对于基于通道注意机制的RCAN 网络和基于非局部注意机制的SAN 有一定提升,但是相比CSNLN 有待提高。本文算法结构,相对于CSNLN而言却比较简单,且计算量偏低。此外,为了使得整个模型计算量最小,在空间变换单元使用SFT层的数量为1,这可以作为下一个研究方向进一步探索。
