基于Fisher算法的无桩共享单车故障预测
2022-03-16张曼雪张勇斌
张曼雪,张勇斌
(北京印刷学院 机电工程学院,北京 102600)
共享单车是共享经济的衍生产品,以按时租赁模式、价格合理以及绿色环保的理念而受到大众欢迎。然而,无桩共享单车“重投放、轻维护”的运营方式,导致共享单车的故障率直线上升,数量急剧减少,据不完全统计,约有1/4的无桩共享单车由于车链断裂、二维码损坏、刹车失灵、车锁丢失以及爆胎等故障而无法使用[1]。企业主要依靠人工排查和APP用户上报获取单车故障信息,效率和精度低下且报修率极低,不能满足当前需求,迫切需要先进的单车故障诊断技术,进而减轻人工作业压力,帮助共享单车企业实现自动化、智能化发展。故障诊断作为单车维修的重要环节,在人工定期维修过程中会出现以下3方面的问题:首先,故障诊断任务枯燥乏味,检修人员会因缺少耐心而出现漏检情况;其次,由于需要诊断的单车数量众多,因此,人工检测故障的速度较缓慢;最后,共享单车企业对各地区的维修人员分配不均,造成资源浪费。而关于APP用户的上报方式,存在由于用户上报不积极而造成报修率低、获取故障信息较少的问题。在单车故障诊断过程中,故障诊断方式落后已经严重影响到用户体验感以及企业的未来发展。因此,如何将共享单车故障诊断的过程智能化、高效化已成为迫在眉睫需要解决的问题。
关于共享单车出现的大部分问题,学者们展开了深入研究,并提供可行的解决方法。毛敏等[2]对故障共享单车的回收维修,提出以总运营成本最小为目标,研究了故障共享单车的回收策略和装运方式,以及两者的最优组合,结果表明根据不同情况多策略混合使用效果最佳。陈佳惠等[3]研究共享单车调度路径问题时,提出用禁忌搜索算法获得最小的成本优化调度路径,实验表明该模型和算法有效。潘纪成等[4]利用 Python 将单车数据可视化,结合单车数据和天气数据建立预测天气对共享单车影响情况模型,结果显示具有较好的运用价值。孙卓等[5]考虑多仓库的共享单车重新配置问题,设计了变邻域搜索算法,构建初始解及贪婪算法,结果表明,该模型具有有效性和合理性。刘明等[6]基于订单数据分析的共享单车重置调度优化研究,从多角度为共享单车的重置调度提供有效决策和建议。安婷婷[7]在基于大数据共享单车服务规划与骑行路线优化研究中提出Logit模型标定法、服务点规划模型及规划热点路段提取方法,很好地解决了共享单车的服务点选址问题与骑行路线优化问题。施嘉伟[8]在基于多目标遗传算法共享单车停放点分配算法的研究中提出了基于多目标遗传算法的分配模型,对算法进行改进,将车辆分配顺序作为染色体的基因序列,并在遗传算法的子代生成步骤中采用回归算法代替变异算子,成功加快了单车停放点的分配速度。Yu等[9]提出一种短时间内高性能本地搜索优势的GTS算法,有效模拟动态重新定位问题。Liu等[10]利用共享单车系统的预定数据来评估单车需求模型,并向新城市预测扩张。袁超等[11]提出骑车共享系统及灵活响应用户需求的动态模型,该想法减少用户的自行车等待时间、提高用户满意度,从而提高自行车的使用率。Bucsky[12]根据服务规划问题设计自行车道网络,规划多模式集成系统的未来发展方向。Kadri[13]考虑到车站的平衡是共享单车运营效率和经济可行性的最关键问题,通过考虑静态情况,研究车站与多车的平衡问题,提出问题的数学公式,并根据伊斯特曼的绑定和SPT规则开发出两个下界。
文中在已有研究基础上,有针对性地研究和解决单车故障诊断问题。经调查研究发现,要实现节约成本、高效又准确地诊断故障共享单车目标:首先,需要考虑的是建立共享单车故障模型;其次,考虑合理挖掘共享单车的数据作为判定条件,使模型更符合实际需求;最后,思考选择合适的算法解出该模型。文中依据上述3个思考方向把共享单车的故障诊断过程简化和智能化,从而节省劳动力、降低维修成本、提高精度,可以为各共享单车企业提供一个新思路,使维修机构的诊断环节更符合当前的发展理念。
1 共享单车故障预测模型
1.1 问题描述
企业对无桩共享单车故障诊断有统一的流程:在城市的运营区内修建若干位置的固定维修站,负责该片区域内共享单车的检测和故障维修。检修人员一般从两个途径获得共享单车的故障信息:一是用户通过APP上报故障共享单车信息,另一个途径是在日常的定期检测工作中发现有故障的单车。收集完这些有故障的共享单车后,工作人员将它们统一送往维修厂进行维修,如若有新增故障车辆次日再进行检修[14]。共享单车故障检测流程如图1所示。

图1 共享单车故障检测流程
在整个维修流程中,企业在单车如何高速度、高精度诊断故障方面束手无策,导致共享单车行业的发展止步不前,因此,故障诊断环节成为文中的研究重点。传统的故障共享单车诊断方法主要依靠人工,所以诊断的精度和效率偏低,这就需要维修机构采用先进的手段在定时检修之前获得故障单车的信息,也就是说需要将故障诊断问题看成故障共享单车的预测问题,实现预定目标,因此,文中主要研究故障共享单车的预测问题。
1.2 共享单车故障建模分析
合理的共享单车预测模型条件和算法,会给人民的实际生活和共享单车企业的发展带来益处,因此,研究满足实际需求的共享单车故障预测问题十分必要。先结合实际情况对共享单车故障模型进行分类,进而达到预测目的,该模型的分析操作流程如图2所示。
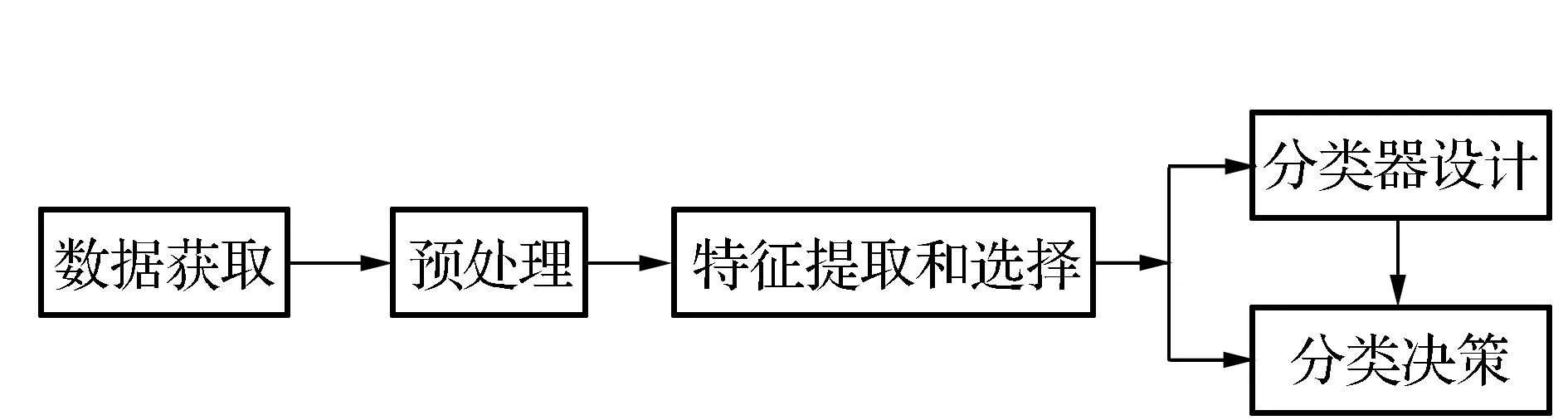
图2 判别分析操作流程
1.2.1 共享单车数据挖掘与预处理
数据挖掘时首先要明确数据挖掘的目标,也就是要达到什么样目的;其次,数据库需要大量的数据积累,提高数据的准确度;最后,数据挖掘是数据的选择和预处理,数据质量是其中至关重要的环节[15]。
文中数据来源为哈啰单车系统,挖掘数据是为了给故障预测模型提供合理的数据来源,进而达到提高预测模型精度的目标[16]。单车系统中除了车辆ID等基础数据之外,还有用户信息、租赁时间、地理位置、骑行速度、打开率、报修率、骑行时长、还车时间等数据,每隔15 s刷新一次,在数据库中存下海量数据。挖掘合适的数据、对数据进行去重是数据预处理的关键环节,能保证数据分析的质量[17]。
文中选择骑行时间和骑行距离进行特征分析,骑行时间过短或长时间未开锁都可以被认为是单车故障预测的一种,但单一的骑行时间变量并不能排除其他情况存在的可能性,如堵车、偏远地区人员数量少等[18],这就需要另外一个变量骑行距离提供判断。一般来说,骑行时间和骑行距离的关系存在着线性关系,骑行时间越长骑行的距离也越远,反之则亦然。结合实际情况,可能会出现骑行时间长、距离短或者骑行时间短、距离长的情况,模型不能预测该共享单车一定处于故障状态。若选择单一骑行时间或骑行距离来预测该单车是否存在故障,偏差会较大,将两者结合起来作为条件约束模型,能够全面考虑到突发情况,进而减小误差,使模型的精确度得到大幅度提升。
综上所述,在海量共享单车数据中,挖掘骑行时间和骑行距离信息、建立共享单车分类模型能够很好地实现文中的预期结果,简化共享单车故障诊断过程,从而节省劳动力并提高精度。
1.2.2 预测模型判定规则的设定
一个完整的故障预测模型的建立除了挖掘简单的数据信息之外,还需要预测合适的判定规则才能完善此模型[19]。在预测判定规则时,需要收集并分析用户使用共享单车的骑行时间,按照数据分布规律预定更符合实际问题的判定条件。北京市用户骑行时间和骑行距离如图3所示。

图3 共享单车骑行时间、骑行距离分布
结合图3可看出,大部分用户共享单车的骑行时间为10~30 min,而5~10 min和超过30 min的使用频数较少;骑行距离分布主要集中在0.5~1.5 km,主要解决2 km以内的出行需求。因此,设定判定条件时,在以下条件范围内判定共享单车故障:用户骑行时间短,骑行距离长;用户骑行时间长,骑行距离短。
1.2.3 预测模型判别法
在研究共享单车故障分类模型判别问题时,要充分考虑共享单车特点来选择最佳的判别法,研究分析发现,Fisher线性判定更加符合文中的总体思路[20]。很显然,文中的分类器设计和分类决策需要使用Fisher线性判别法。Fisher线性判别法的原理是利用方差分析的思想,从已知的各总体中抽取样本p维观测值,构造一个或多个线性判别函数Y=L×X,其中,L={l1,l2,…,lp}为判别式,X={x1,x2,…,xp}为样本观测值,将样本空间折射到某一投影上[21],如图4所示。
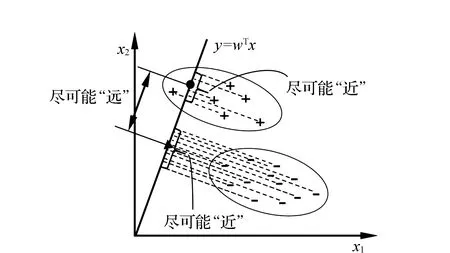
图4 Fisher线性判定
2 共享单车故障预测模型及求解算法
从企业维修部门角度看,节省时间和人力就是节约成本,模型先对共享单车进行故障预测能很好满足企业的要求[22],因此,文中构建的模型应该对共享单车是否存在故障进行预测,并把正常车辆和故障车辆进行分类。为使模型更加符合实际问题,根据上述分析得出最佳判定规则,构建共享单车故障预测模型。
模型中最主要的目标是智能化检测共享单车是否出现故障,从而解放人力并节约时间。城市中建立若干个位置固定的维修站,每个维修站负责规定区域的车辆检修任务,共享单车上报的数据信息采用Fisher线性判定进行预测分类,通过人力搬运的方式送到聚类服务点,将共享单车拉回维修站,然后完成下一个聚类服务点的收集任务[23],如图5所示。

图5 共享单车故障预测局部网络
根据上述分析,基于Fisher线性判定单车故障预测模型步骤如下:
步骤1:假设研究的共享单车有k个总体G1,G2,…,Gk,从每个总体中选取n组的样本数据,利用判别式L={l1,l2,…,lp}计算样本的组间离差平方和矩阵B及组内离差平方和矩阵E,则有
(1)
(2)

投影后的矩阵B和矩阵E之间的比值为
(3)
因此,若k个总体样本的均值有显著差异,λL应尽可能的大,才能使得各样本之间的距离较大,进而实现故障和正常的分类。
步骤2:利用拉格朗日乘子法进行求解,令
φ(L)=LBL′-λLLEL′
(4)
解方程
(5)
解|B-λLE|=0得到特征值,按照从大到小的顺序排列λ1≥λ2≥…≥λr>0,特征值对应的特征向量可记作α1,α2,…,αr。
之后,判定故障需要达到的设定下阈值,需要与积累贡献率进行对比,算式为
(6)
通过对比,根据实际的数据分析设定下阈值,从前往后选m个判定函数,满足条件sm≥T,且sm-1 步骤4:根据选定的Fisher判别函数,将待识别样本数据的特征参数向量X映射到低维空间,得到低维特征向量Y,并计算其与各样本判别矢量的距离 (7) 计算距离大小,判定样本数据属于故障还是正常,即若 Dj (8) 则样本数据X属于正常。 共享单车已逐渐受到大众青睐,目前,北京市各区都有共享单车,文中以北京市某区的哈喽共享单车系统为例,通过挖掘哈喽共享单车的实际数据来验证文中提出的方法是否可行[24]。根据上述建模原理和解法,利用MATLAB软件对数据进行分析处理,得到如图6所示的结果。 图6 Fisher判定故障单车二维分布 Fisher线性判定可以根据骑行时间和骑行距离的长短把数据集的所有共享单车数据进行聚类、分类[25]。根据图6可以看出,利用文中提出的方法能够区分该地区无桩共享单车的正常车辆和故障车辆。正方形部分的共享单车在这个时间段能够骑行合理的距离,也就是说在骑行时间和行驶过程中,共享单车没有出现故障;十字形部分的共享单车在较长的距离里面却骑行少量时间,或者在短距离中却骑行较长时间,那么这些小车一定存在着一些故障,可能出现的一种情况是用户在共享单车开锁之后便发现共享单车出现故障,或者在共享单车行使过程中,共享单车出现故障,导致用户不得已关闭共享单车[26]。还有一种情况是单车本身的故障不耽误骑行,用户不愿更换继续使用单车。 图7所示即为人工定期维修和APP用户上报两种传统方法检测出的故障单车和正常车辆,可以发现故障的车辆较少,正常车辆数量较多。由于人工误差,对正常车辆进行再次检测时发现,正常车辆里面还存在很多的故障车辆,数量超出可忽略不计的范围。 图7 传统方法判定故障单车二维分布 实验所需要的数据均来自北京市某地区2020年上半年统计,文中采用的模型和算法得出的结果与上半年实际情况进行对比发现准确率高达86.13%,可见,文中算法具有很高的精准度。 同时,本实验方法依据的是Fisher算法,其步骤可由计算机进行计算与分析,将分析之后的结果发给工作人员,工作人员再根据所得到的结果去实际检查,简化了工人的工作量,使工人能够更加快速地了解到哪些共享单车存在问题[27]。经过实际数据测量,在没有使用本实验方法前,工人一辆一辆的检查车况,一天大概能够检查700辆,而使用本实验方法之后,在确保准确性的同时,工人每天能够检查约2 000辆,大大提高了工作效率。 通过对共享单车检测问题的研究分析,提出采用骑行时间作为条件构建共享单车故障预测模型,并采用了Fisher线性判定解法求解该模型,通过分析研究得出以下结论。 1)在考虑检测方式可以解放人力的情况下,进一步挖掘共享单车的数据信息。借助大数据技术挖掘有效数据信息构建共享单车故障预测模型,该模型的目标是节省维修部工作人员的工作时间和劳动力,从而提高维修效率,减少损坏的车辆,提高共享单车使用用户的满意度,实现企业智能化,并促进其可持续发展。 2)利用文中提出的共享单车预测模型和解法预测北京市某地区单车是否出现故障,最后通过上位机的计算以及与实际真实测量的比较结果相比,表明文中提出的模型和FLD解法能够有效节省检测时间和人工劳动,进而节约企业的运营成本。 3)迄今为止,关于利用用户骑行时间和行驶距离来预测共享单车是否存在故障的研究非常少,文中提出的预测模型和解法还不够成熟,对于骑行时间和行驶距离等判定规则仍存在于个人的强制规定上,没有考虑到每个人的实际情况,判定条件不够全面,并且不能对那些临时停车用户进行预测,因此,未来本研究还需要进行深入探讨,进一步探索解决方法。 4)文中实验用到的数据有限,导致本实验结果具有一定局限性。由于没有全国性的数据集,所以无法对全国范围内的共享单车进行预测,进而不能确保在全国范围内文中的实验方法是否适用。如需对全国范围内共享单车进行预测,则需要更多的数据支撑。
3 实例分析


4 结 论
