样本不均衡下的DCGAN轴承故障诊断方法
2022-03-15张笑璐邹益胜曾大懿彭飞赵市教
张笑璐,邹益胜*,,曾大懿,彭飞,赵市教
(1.西南交通大学 机械工程学院,成都 610031;2. 中车工业研究院有限公司,北京 100070)
轴承作为主要的旋转机械之一,被广泛应用于工程机械、轨道交通、精密机床、仪器仪表等领域。在工作运行时受到力与载荷的作用容易发生磨损、疲劳剥落、锈蚀等故障,据Cerrada等[1]统计,约40%的旋转机械故障是由轴承故障引起的。轴承一旦发生故障,将严重影响设备的正常运行,甚至可能造成较大安全事故及经济损失。故而需要对轴承故障进行监测和诊断,及时发现潜在的安全隐患[2]。
轴承故障诊断方法多基于对采集的振动信号进行处理与分析,现有故障诊断方法采用的模型如:支持向量机(Support vector machines, SVM)[3]、BP神经网络[4]、贝叶斯分类器[5]和随机森林(Random forests,RF)[6]等都立足于充足且均衡的样本数据。而实际工况下,滚动轴承故障中内圈和外圈出现裂纹是最常见的,据统计内外圈故障占滚动轴承的90%[7],其余部位仅占10%,故而在采集故障样本数据时,往往出现个别故障类型采集的样本较少的情况,导致总体样本不均衡。
传统用来解决样本不均衡问题的方法可以归类为以下3个:样本采样、改进诊断模型和样本扩增。其中,样本采样分为Oversampling[8]和Under-sampling[9]两类:Oversampling通过复制操作产生重复样本,会导致分类器倾向过度拟合;Underr-sampling 技术剔除了部分大样本,信息可能严重丢失从而导致信息空间的扭曲与不完整。改进诊断模型的方式从诊断模型本身出发,常通过调整分类器敏感度来提高诊断精度,提升的程度往往有限且较难获得最优权重。样本扩增方法通过生成虚拟样本填充小样本空间,能有效避免采样方法存在的问题,但传统的样本扩增方法多运用SMOTE及其改良模型[10],存在局限性:一是在近邻选择时具有一定的盲目性;二是该算法无法克服非平衡数据集的数据分布问题,容易分布边缘化。
Goodfellow等[11]在2014年提出的一种基于博弈场景的半监督特征学习算法——生成对抗网络(Generative adversarial network, GAN)改善了这种局限性。随着对抗学习思想的不断完善,GAN已经在图像生成、图像辨识和风格迁移等领域有了较多的应用[12],并且衍生出了实现不同功能的变体。GAN通过生成网络和鉴别网络的博弈过程学习训练样本的数据分布,使生成网络输出能够以假乱真的训练样本,从而解决实际故障诊断中故障样本少于正常样本的数据不平衡问题。
为了更好地解决样本不均衡情况下轴承的故障诊断问题,提出一种基于DCGAN(Deep convolution generative adversarial network)的故障诊断模型。轴承诊断常采用原始数据作为研究对象,但在简单的生成对抗网络中常常无法获得较好的结果。将轴承振动数据进行了快速傅里叶变换凸显特征。此外结合卷积神经网络(Convolution neural network,CNN)[13]与GAN的优点,提高了生成对抗网络对原始数据特征的挖掘能力。并在模型中加入Dropout层防止过拟合,提高模型的泛化能力。此外,模型采用衰减学习率提高模型的训练速率,能更快速的生成虚拟样本填充不均衡样本空间,实现不均衡情景下轴承故障诊断效率的提升。采用德国Paderborn大学的公开轴承数据集进行对比实验,实验结果表明,该方法在样本不均衡情景下能够有效提升诊断精度及稳定性。
1 模型描述
1.1 卷积神经网络
卷积神经网络是受神经科学感受野机制启发而提出的一种前馈多级神经网络,主要由卷积层、池化层和全连接层堆叠形成。卷积层中,前一层的输出信号通过卷积核提取出一个局部特征,并将该特征输出。池化层则通过特征选择降低特征数量,常用的有最大池化和平均池化两种操作。全连接层则连接前一层的所有特征,整合卷积层或池化层中具有类别区分的局部信息并将输出值发送到分类器。提出的方法在生成对抗网络上应用了卷积以及反卷积方法,故障诊断模型中采用了一维的卷积神经网络模型。卷积原理为
(1)
式中Mj表示输入的神经元集合。
在卷积层中,每个神经元仅对局部区域进行感知,而不以全连接的形式,极大的降低运算量。此外,卷积神经网络的权值共享,每个神经元对应的参数是相同的,同一个卷积核对不同数据进行处理时具有相同的权值和偏置值,减少了网络的参数量。这些卷积核按照设定的步长对给定的数据进行卷积操作,并提取特征,上一层的特征神经元被一个卷积核卷积并通过一个激活函数,获得新一层的特征神经元。为了防止过拟合情况的发生,采用的卷积神经网络模型都加入了Dropout层。
1.2 深度卷积生成对抗网络
生成对抗网络GAN是一种无监督学习方法,通过生成模型(Generative model)和判别模型(Discriminative model)的零和博弈生成虚拟样本。其中,生成器接收随机的噪声z并通过反卷积的方式生成一组生成样本Xf,将Xf与原始样本Xr一起放入鉴别器,利用鉴别结果反向训练生成器优化生成样本。
针对轴承故障诊断,基础的GAN模型会出现梯度消失、模式崩溃等问题,生成的结果较差,即使将训练时间增长,生成结果依旧没有得到改善。并且未经过预处理的原始数据量级相差较大,特征较为复杂往往会导致模型崩溃。DCGAN是在GAN基础上提出的一种新的模型,在网络结构上有所改进,主要的变化有:采用步长卷积代替上采样层,利用卷积层能挖掘样本特征的优点,更好的促进生成器的训练。这种网络模型多应用于图像样本。生成对抗网络模型如图1所示。
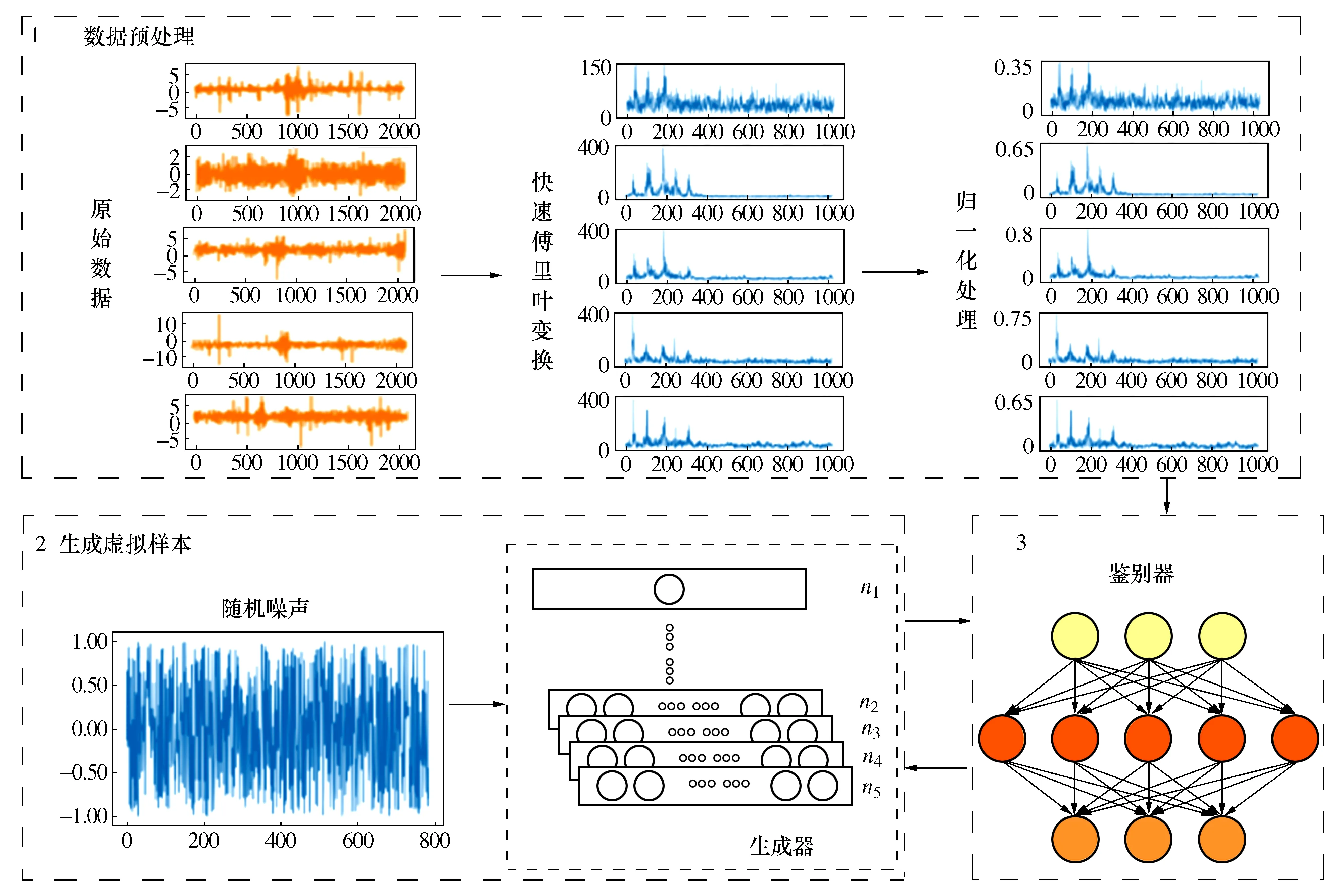
图1 生成对抗网络模型
提出的基于DCGAN诊断模型利采用卷积与反卷积的结构。生成器由五层反卷积组成,针对轴承的样本情况给每个反卷积层分配不同的步长,通过反卷积的形式将接收的一维噪音扩充到所需的样本大小;鉴别器则由卷积层组成,通过输出0或1的集合来反向给予生成器信息使其进一步优化,并在鉴别器中使用LeakyReLu激活函数增强模型的稳定性。此外,在采用Adam优化器进行训练的同时,应用衰减学习率,初始的学习率设定为0.000 2,其后每500次训练衰弱5%。在训练过程中,针对实验采用的轴承情况,出现了生成器和鉴别器的优化训练速度并不一致的情况。为了获得较好的结果进行了不同的训练比例的尝试,当生成器与鉴别器的训练比例调高时,生成器的loss值上升的情况会相较1∶1有所减缓但趋势不会产生变化。鉴别器的损失函数为
Ez~Pz(z)[lg(1-D(G(z)))]
(2)
式中:G、D分别代表生成器和鉴别器,G的输入是一维随机噪声向量z,输入的真实试验样本为x;G(z)是生成的虚拟样本。
1.3 诊断流程
故障诊断模型构建的一维卷积神经网络,由2个卷积层、2个池化层、Dropout层以及Softmax层构成。利用卷积层挖掘训练集的特征,在池化层放大后通过Softmax层输出对应判定结果。该模型中,Batchsize取值为10,池化采用最大池化。DCGAN故障诊断流程如图2所示。
图2 DCGAN故障诊断流程
首先对轴承数据进行快速傅里叶变化并用归一化进行处理。将处理后的真实样本导入DCGAN模型进行对抗训练,生成所需的虚拟样本。根据不同实验要求分别构建对应的训练集和测试集,将划分好的数据集导入一维卷积神经网络进行诊断,得到对应的诊断精度。
2 试验与分析
2.1 数据来源及预处理
试验数据来源于德国帕德伯恩大学设计与驱动技术系滚动轴承状态监测试验台。如图3所示,试验台由5个模块组成:电机、扭矩测量轴、滚动轴承试验模块、飞轮和负载电机。

图3 滚动轴承状态监测试验台
试验轴承为6203型滚珠轴承。轴承以900 r/min的转速运转,负载扭矩为0.7 Nm,轴承径向力为1 000 N,数据采集系统频率为64 kHz,轴承温度大致保持在45~50 ℃,试验采用了3种轴承状态:内圈损坏、外圈损坏和健康。每个轴承采集20个原始振动时间序列信号,每个信号记录约256 000个数据点。
为了构造样本不均衡的情景,在单一工况下,针对5类不同轴承状态各提取20*2 048的样本数据,包括4类对应内外圈不同故障严重程度以及对照健康组,具体信息如表1所示。
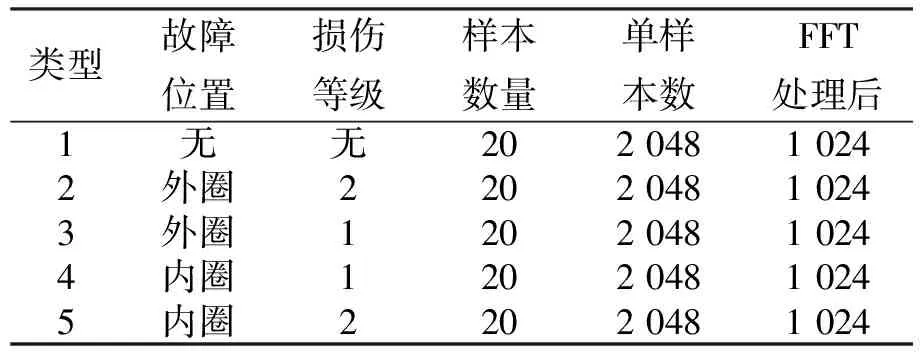
表1 故障类型和总量
原始振动数据作为作为时域信号,可以看作由多个不同频率的正弦波信号无限叠加组成。傅里叶变换通过累加的方式将组成该信号的所有正弦波信号在频域中表示出来。未处理过的原始信号在生成器中训练较为困难,为了提升模型训练能力并且考虑整体运算量,对振动数据进行了快速傅里叶变换。其次,考虑到不同的样本特征数据量级差异较大,为使每个特征都能获得一定的权重,对数据进行了归一化处理。
2.2 生成样本真实性验证
为了验证生成样本的真实性。首先采用T-SNE(t-distributed stochastic neighbor embedding)[14]将原始数据以及生成数据的特征进行可视化处理,将所有特征降至三维。通过对比两者的三维特征分布,评估生成数据的有效性。真实样本与生成样本的频域特性对比如图4所示。由图5可知,两者的三维特征存在较大的重合区域,保证了生成数据对原始特征的学习,而部分离散的点则留存了一定的差异性。
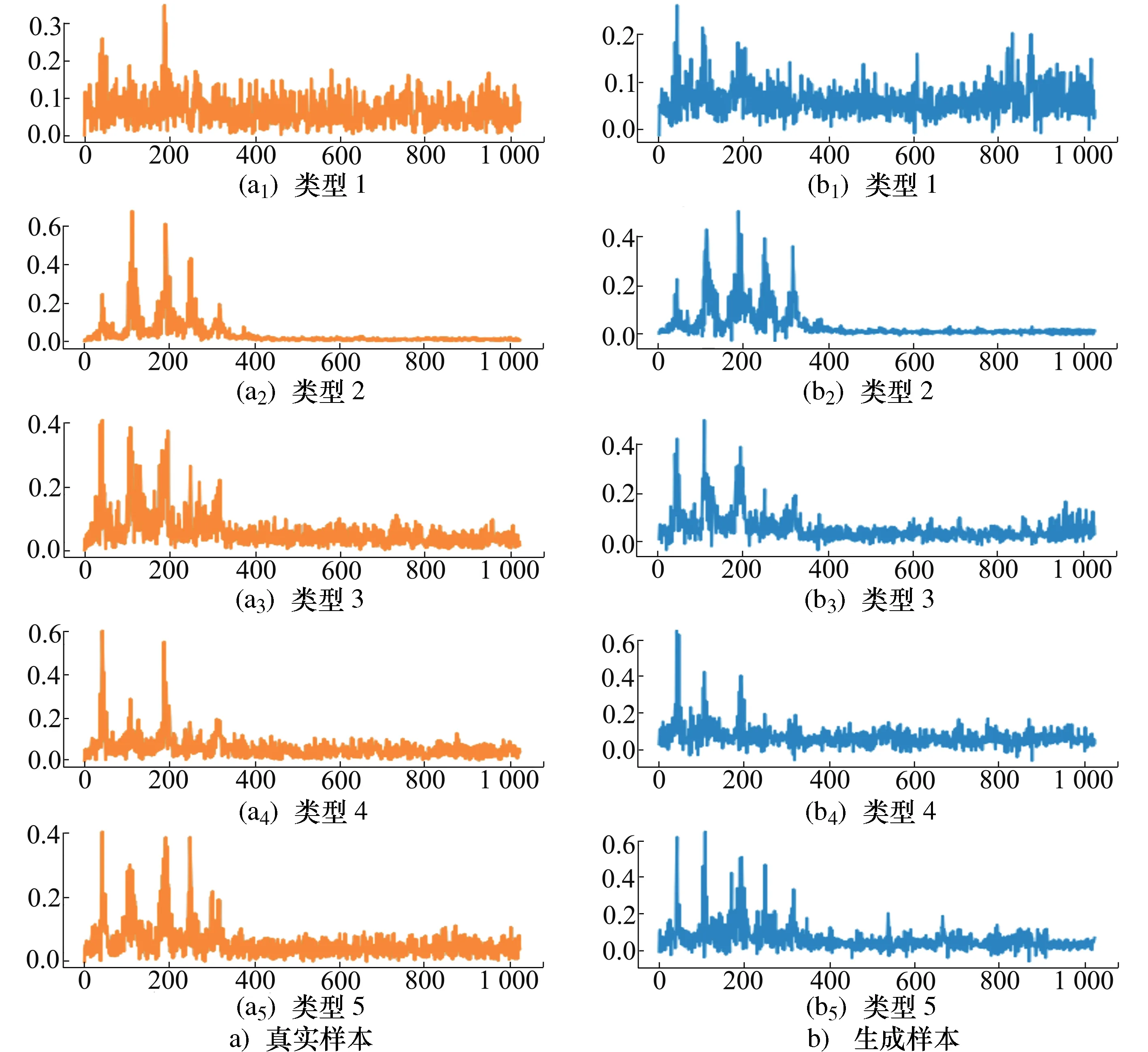
图4 真实样本与生成样本的频域特性对比分析
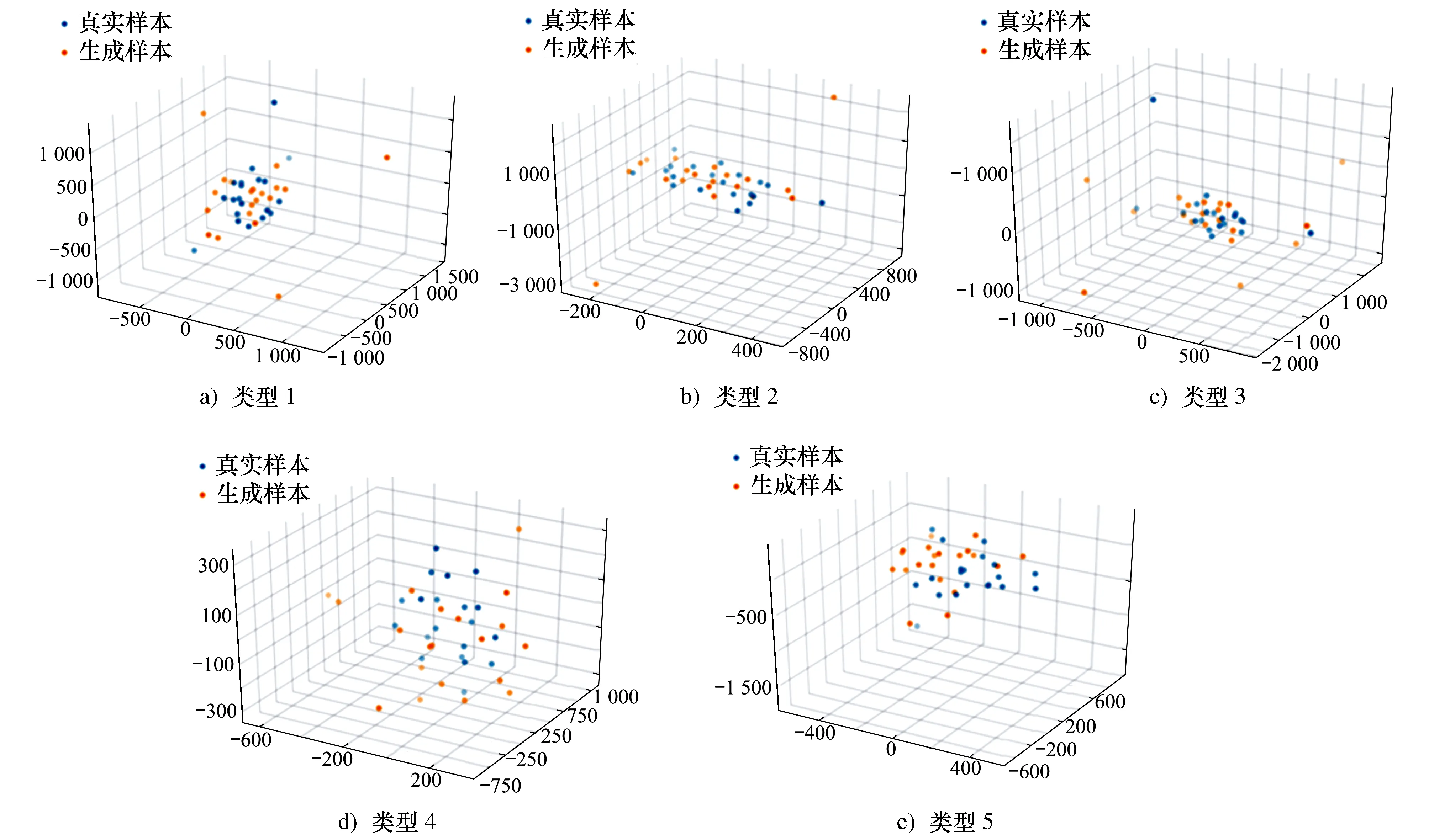
图5 真实样本和生成样本的空间分布情况对比分析
此外,为了进一步评估生成数据的真实性,采用最大均值差异(Maximum mean discrepancy,MMD)指标[15]通过计算生成样本以及真实样本的概率分布距离来评估样本的真实性,其计算式为
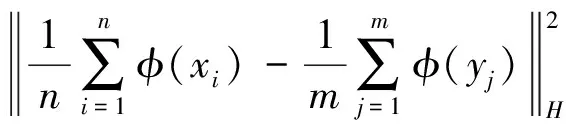
(3)
式中H表示该距离通过映射函数将数据映射到再生希尔伯特空间中进行度量。
利用高斯核函数对MMD进行求解,5类不同情况下生成样本过程中的变化趋势见图6。随着训练次数的上升,MMD的数值会有所波动但整体呈现下降趋势,生成样本与真实样本的概率分布逐渐接近。
2.3 真实样本和生成样本的轴承故障诊断对比分析
为了验证生成数据的真实性以及所提方法的有效性,设计了两组对比试验,具体如图7所示。
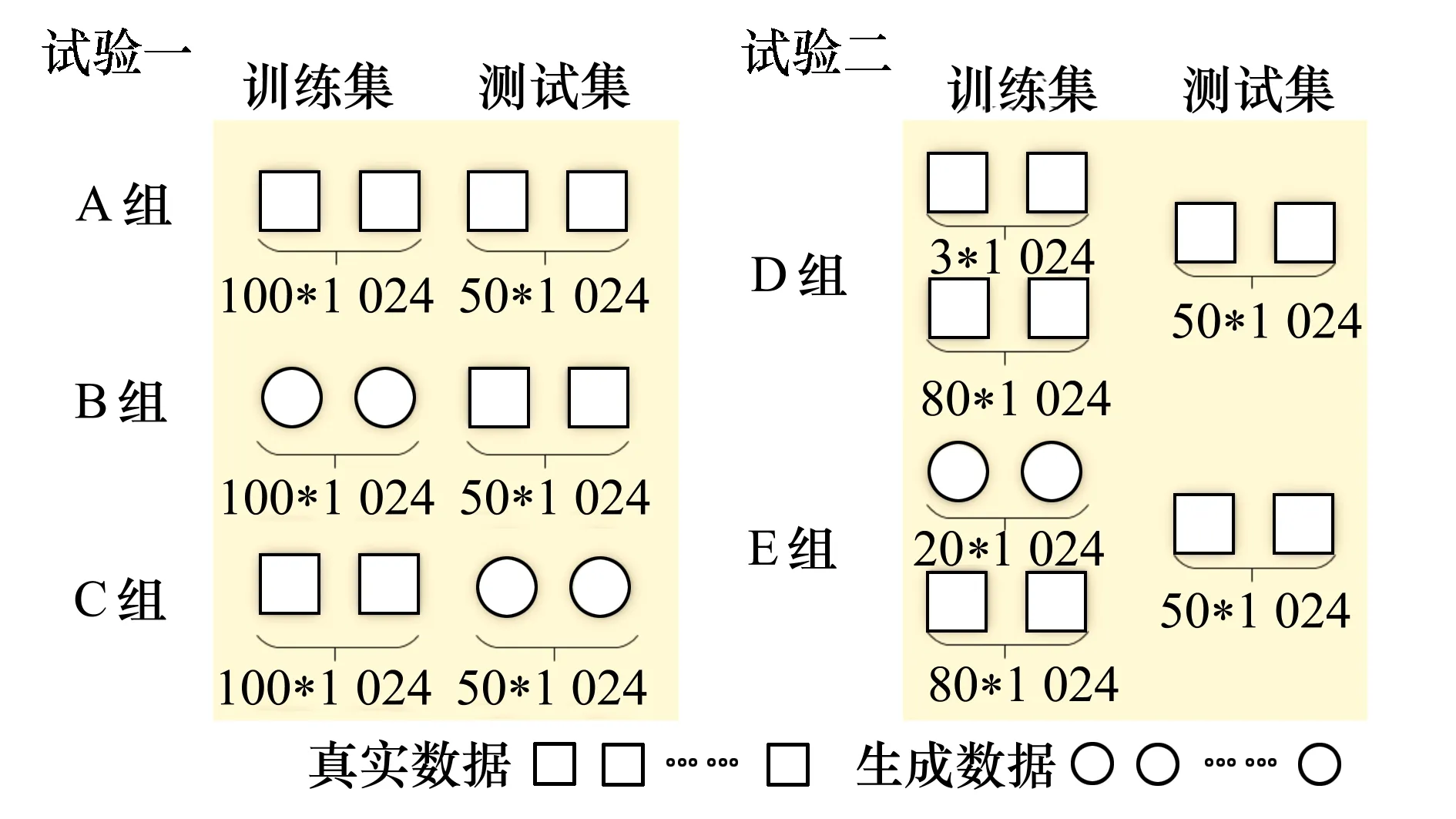
图7 试验设计
试验一利用真实样本以1∶1比例生成对应的生成样本,并将两者进行组合构成A、B、C这3组。其中:A、B组训练集为真实样本,C组为生成样本;A、C组测试集为生成样本,B组为真实样本。每组进行20次诊断,以此验证生成数据在实际轴承诊断中的真实性和可靠性。试验二则构造了样本不均衡情况,将其中一类的样本数据减少至3个,并利用这3个样本进行生成,将生成的虚拟数据进行填充,填充前为D组,填充后为E组。以此验证虚拟数据在真实样本不均衡情景下提高轴承诊断精度的有效性。同样每组进行20次诊断。
采用最低精度、最高精度、平均精度以及方差4个统计量分析原始样本与生成样本在两个试验中的表现情况,具体如图8所示。A、B两组均能获得较高的诊断精度,B组较A组诊断精度提高方差下降。而生成样本作为训练集的C组最低精度也在90%以上。证明生成样本较好的学习了原始样本的特征并且能够训练模型以分类原始数据构成的测试集。不均衡的D组在加入生成样本后,诊断精度有了较大的提升,且增强了稳定性。
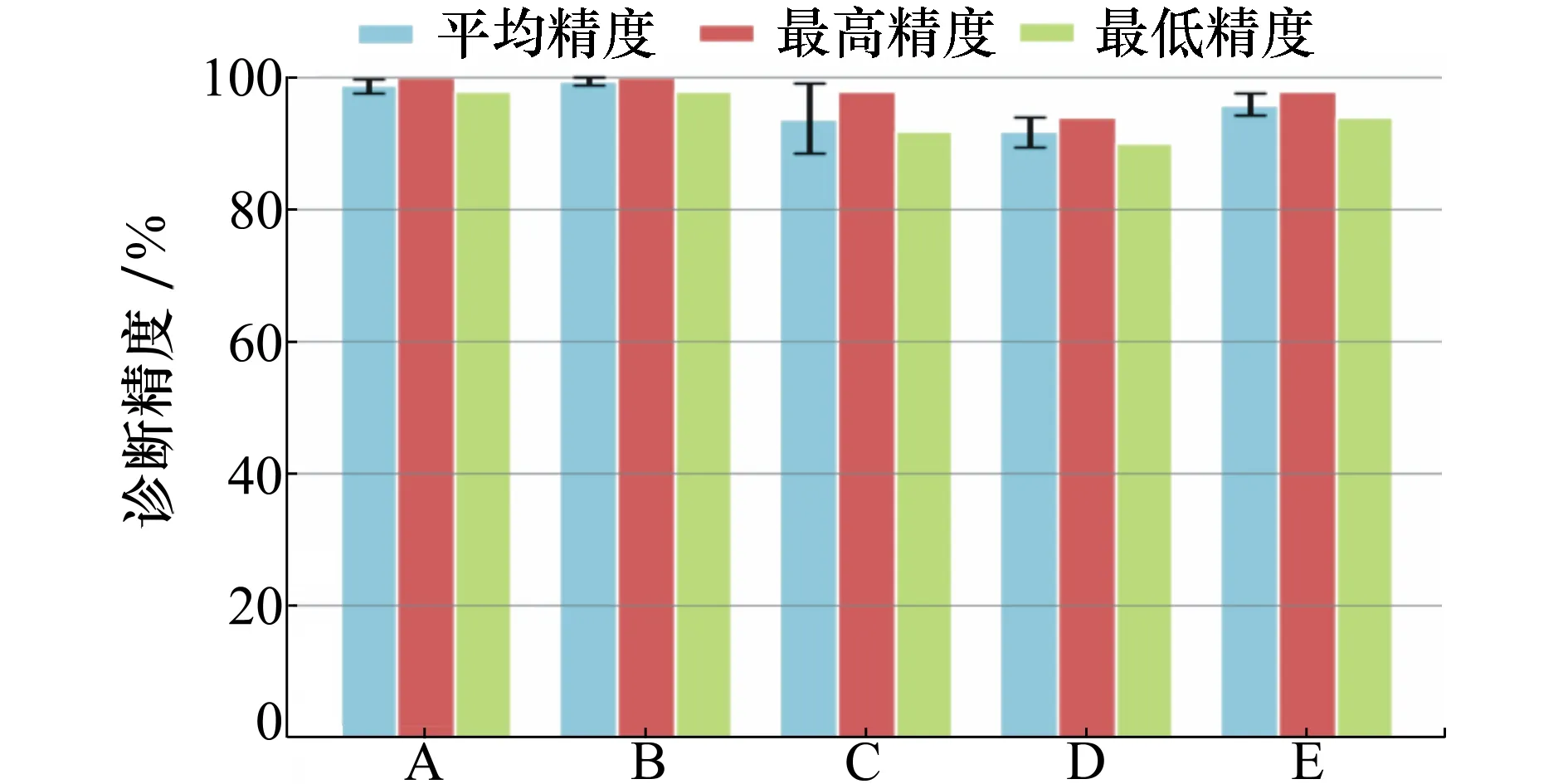
图8 各试验整体平均精度
此外,为了进一步分析各轴承状态的诊断情况,针对每个不同轴承状态的故障诊断精度见图9,当类1的样本数据大幅度下降时,其诊断精度出现大幅的下跌。而当生成样本作为填充时,使得模型样本均衡后,精度有明显的提升。模型对不同情况的轴承故障误判的几率并不相同。在图10中,类1的误判主要出现在试验D组与试验E组中,与设计实验的初衷相符。试验D组因大幅度减少了类1的轴承样本,从而导致误判几率急剧上升,大量类1样本被误判为类4。在利用生成样本填充后,误判几率有明显的下降。结合图9、图10,试验中其他类最容易被误判为类4,在试验A、D组中分别为将类5错分为类4,类5及类1错分为类4。类5错分类的原因来自诊断模型无法完全正确的对类5和类4进行分类。而出现类1错分类的原因可以归结于类1样本数量的减少。在试验D、E组的对比下,通过生成样本填充的方法,能有效降低小众类被误判的几率,从而提高整体诊断精度。
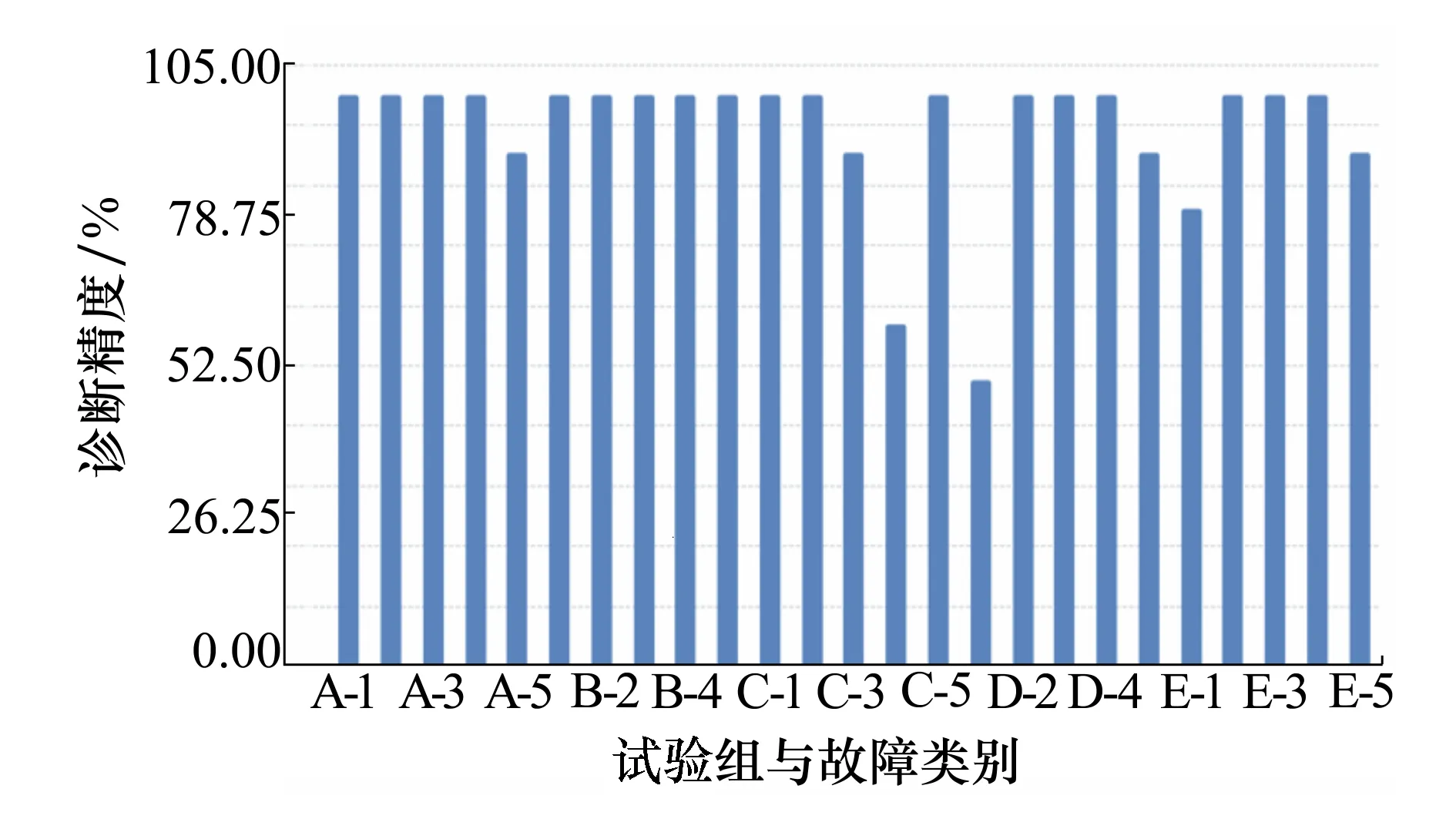
图9 各试验诊断结果
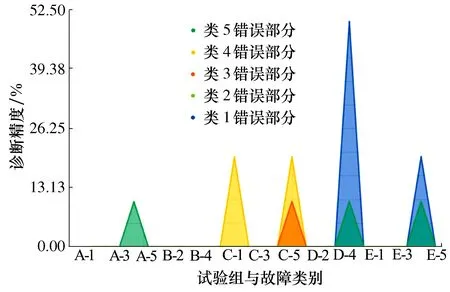
图10 各试验不同类型错误诊断结果统计
为进一步考虑极端情况下的小样本情况,当类型一的真实样本仅存在1个,利用仅1个样本进行生成虚拟样本填充样本空间,使之达到均衡,填充前后的混淆矩阵结果如图11所示。
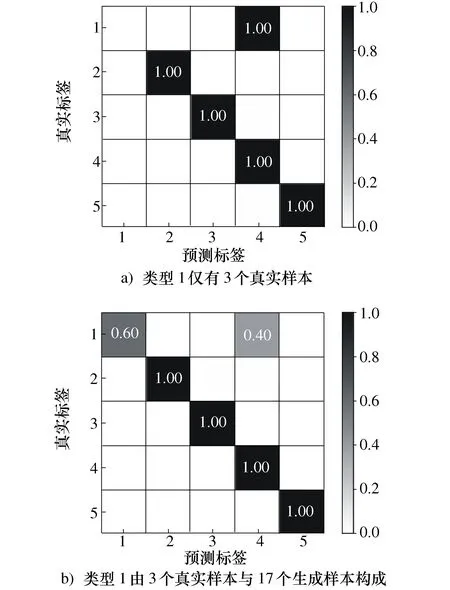
图11 诊断结果的混淆矩阵
通过混淆矩阵可以发现,原先仅放入1个样本导致出现误判的类1,在加入生成样本使样本数据均衡后,诊断成功率有了明显的提升。实验证明,采用生成虚拟样本的方法,能有效的降低误判率,防止了极少样本类被当作离群点的情况,同时在样本不均衡的情况下也能有效的提高故障诊断精度以及诊断的稳定性。
3 结论
针对样本不均衡情况下轴承故障诊断问题,提出了基于DCGAN的轴承故障诊断方法。该方法具有以下优点:
1) 采用快速傅里叶变换对原始样本进行了数据预处理,提高了深度卷积生成对抗网络生成虚拟样本的能力。
2) 将深度卷积生成对抗网络引入不均衡情景下的轴承故障诊断问题,通过生成虚拟样本填充样本空间的方式提高了模型在样本不均衡情景下的诊断能力。并在模型中加入了Dropout层,以及采用衰减学习率提高了生成样本生成的有效性以及效率。
提出的方法在样本不均衡情景下能有效的生成虚拟样本。多角度分析以及构建的实验结果证明,该方法能有效提高模型在不同样本情景下的诊断精度以及诊断的稳定性。
