融合注意力机制的枸杞虫害图文跨模态检索方法
2022-03-14刘立波赵斐斐
刘立波 赵斐斐
(宁夏大学信息工程学院, 银川 750021)
0 引言
枸杞具有免疫调节、滋肾、润肺、补肝等功效,在国内外市场备受青睐。同时,作为防风固沙和改良盐碱地的先锋树,枸杞兼具生态与经济价值,随着气候条件的变化和栽培技术的引进,近年来种植面积逐渐扩大[1],已成为宁夏乃至整个西北地区重要的经济作物之一[2-3]。枸杞属于多虫寄主且抗虫害能力较差,极易遭受虫害侵扰,并呈现逐年加重趋势,对于产量及品质影响巨大,造成了严重的经济损失。因此快速准确检索得到枸杞虫害多方面信息并给予及时精准防治,对于避免虫害进一步扩散进而提高枸杞产量与品质,推进枸杞产业带动区域经济发展至关重要。
传统的农作物病虫害检索主要通过人眼查看病虫害目标区域的颜色、纹理、虫子体态等特征,与农作物病虫害图像信息手册进行人工对比来实现[4]。该方法依赖个人经验以及肉眼观察,导致主观性强、误判率高并且耗费时间和精力[5]。随着精准农业和智慧农业的发展,农作物病虫害信息量爆炸式增长,其数据也因自身特点呈现多模态形式,图像和文本两种模态数据经常同时产生、相互关联并互相补充。如何通过计算机视觉、图像处理等先进信息技术,从这些不同模态且语义关联的数据中获取有价值的信息,进而实现图像文本信息间的跨模态检索,对满足人们日益增长的农作物病虫害信息多样化检索需求具有重要意义。
现有研究[4,6-8]在农作物病虫害检索任务中都取得了很好的成效,但均存在检索模态单一的问题,即仅能够以图像检索图像,或者以文本检索文本,很难将农作物病虫害不同模态信息进行展示。随着农业数据化信息及形式的多样化[9],研究人员更加注重不同模态信息的互检及模态的综合分析,而跨模态检索 (Cross-modal retrieval)正是兼具多模态数据之间的相似互检这一特性,并融合图像、文本等多个模态对数据进行高效互查与量化,使其不断成为多媒体信息检索中的一个研究热点[10],被广泛应用在医疗、交通、艺术等领域[11-12]。在农业领域,由于农作物病虫害信息模态更加多样化[13],图像或文本的单模态检索显然已经不能满足人们的需求,对于经验不足的人员,仅凭农作物病虫害图像、文本等单模态信息并不能全面且直观、形象地了解想要检索的内容[14]。跨模态检索能够实现不同模态之间信息互检,获得更加多元化的农作物病虫害信息,从而对农作物病虫害的及时防治提供帮助。但目前跨模态检索尚未在农业领域应用,因此将跨模态检索引入农业领域实现农作物病虫害的跨模态检索更能满足农业发展的现实需求。
由于不同模态在进行某些特定特征与语义交互学习时,往往存在细节信息不互补或者高级语义不平衡的现象,导致模态间的映射关系不对等,造成不同模态间特征描述缺失或者语义关联匮乏。比如,枸杞虫害图像和枸杞虫害文本之间的模态学习,图像具有比文本更多的细节信息,而文本又包含了很多比图像更强的语义描述。因而,为了解决上述问题,通过引入具有模拟人类视觉系统功效的注意力机制,能够更加突出图像与文本中更具区分性的重点部位,来缓解这种模态间的不对等以及不平衡性。
本文以17类枸杞虫害图像和与其相对应的枸杞虫害文本为研究对象,针对现有方法检索模态单一的问题,将跨模态检索技术引入枸杞虫害检索中,利用注意力机制对图像和文本数据进行特征提取,使模型能够集中于图像和文本中必要细粒度部分,学习图像与文本的显著性语义信息,从而挖掘两者之间的语义关联,针对枸杞虫害的图文跨模态检索,期望获得更高的实时性和更丰富的内容,为农作物病虫害检索提供新思路。
1 融合注意力机制的图文跨模态检索模型
1.1 数据符号化表示及模型框架概览
本文模型框架如图1所示,由文本编码模块、图像编码模块以及模态交互模块3部分组成。

图1 模型框架图Fig.1 Frame of model

对于图文跨模态检索任务来说,给定任一相似的图像文本,其中的内容往往只存在一部分相似性,不可能完全相似,该任务的这一特点便促使模型需要首先将数据拆分为多个部分,探索数据不同部分之间的语义关联,进而挖掘数据中所包含的细粒度信息。再者,在本文自建的枸杞虫害数据集中,这样的局部相似性往往集中在图像中包含害虫的区域,以及文本中包含对虫害特点进行描述的部分,这又进一步要求模型能够提取图像和文本中的显著性语义信息。本文首先通过文本编码模块和图像编码模块获取各数据的细粒度特征序列,并基于注意力机制对序列进行聚合以获取文本和图像的显著性语义特征,接着通过模态交互模块提高文本和图像特征的判别力,并对文本和图像特征进行语义对齐,保证文本数据和图像数据之间的模态间一致性。
对于文本模态,首先通过word2vec方式来获取文本中每个单词的词向量作为文本的细粒度特征序列。接着通过Transformer模型获取包含文本上下文信息的细粒度特征序列,使序列中每一个元素既包含其本身独有的信息,又包含与整个数据的关系,增强可判别性。然后通过注意力机制获取序列中每个元素的注意力权重,即每个元素对数据的重要性,并基于所得权重对序列元素进行加权求和以得到包含了显著性语义信息的文本特征。同样地,对于图像模态,首先通过VGG19网络提取该网络最后一个池化层的特征图谱,并将其拆分为49个子区域特征,形成图像的细粒度特征序列。接着通过LSTM网络获取包含图像上下文信息的细粒度图像特征序列。然后通过注意力机制以同样的方式得到图像的特征表示。最后,通过模态交互模块的模态内判别损失以及模态间一致性损失来共同引导模型的训练。
1.2 文本编码模块

图2 Transformer模型的编码器结构Fig.2 Encoder structure of Transformer model
在处理枸杞虫害文本内容时,采用Transformer编码器对文本进行编码,Transformer[15]是Google团队在2017年提出的一种自然语言处理(NLP)经典模型,是一种新的、基于注意力机制来实现的特征提取器,可以用于代替卷积神经网络(CNN)和循环神经网络(RNN)来提取序列的特征,其结构如图2所示。图中,N为Transformer的层数。
以1层Transformer模型为例,该模型可以被简单表示为
yi=transformer(xi)
(1)
式中xi——输入的词向量
yi——输入的词向量经过模型编码后的输出向量
在对文本信息进行编码时,对于给定的一个枸杞虫害文本ti,设每个文本ti中包含T1个单词,可表示为ti=[w1,w2,…,wT1]。在本文所提数据集文本语料库中添加Wikipedia语料库,基于skip-gram与Negative Sampling策略构建word2vec模型,将ti中的单词wj转换为一个词向量,记为xj,得到该文本的细粒度特征序列,再将得到的序列送入Transformer编码器中以获取序列中每个单词包含了文本上下文信息的特征向量yj,得到包含了文本上下文信息的细粒度特征序列Yi=[y1,y2,…,yj,…,yT1]。具体公式为
xj=word2vec(wj) (j∈[1,T1])
(2)
yj=transformer(xj) (j∈[1,T1])
(3)
接着采用类似的方法[16]实现注意力机制,将Transformer编码器输出的文本特征序列Yi送入前馈神经网络中,然后利用softmax函数计算得到序列中每个yj的注意力权重αj,对应的注意力权重序列可被表示为α=[α1,α2,…,αT1],具体计算公式为
α=softmax(WtaQt)
(4)
(5)

(6)
1.3 图像编码模块
在处理枸杞虫害图像时,首先将图像vi的尺寸调整为256像素×256像素,并将其输入到VGG19网络中获取该网络最后一个池化层的特征图谱,该特征图谱的尺寸为7×7×512,3个参数分别表示特征图谱的高、宽以及通道数,由此将该特征图谱看作图像49(7×7)个子区域对应的特征,每个子区域可被表示为512维的特征向量,将这49个子区域连接起来便可构成图像的特征序列,可以表示为r=[r1,r2,…,rj,…,rT2],T2为图像区域总数,rj为第j个区域所对应的特征向量。然后利用长短期记忆网络[17](Long short term memory,LSTM)获取包含了图像上下文信息的细粒度特征序列Hi=[h1,h2,…,hj,…,hT2]。
LSTM是一种特殊的循环神经网络,通过记忆单元学习长期依赖关系和更新门的能力较强,同时保留了之前的时间步长信息,能够有效解决一般的RNN存在的长期依赖问题,图3为LSTM计算单元内部结构。
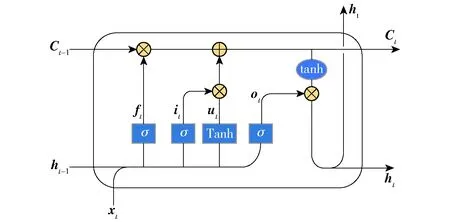
图3 LSTM单元架构Fig.3 Architecture of LSTM unit
LSTM单元计算公式为
it=σ(Wi[ht-1,xt]+bi)
(7)
ft=σ(Wf[ht-1,xt]+bf)
(8)
ut=tanh(WC[ht-1,xt]+bC)
(9)
ot=σ(Wo[ht-1,xt]+bo)
(10)
Ct=ftCt-1+itut
(11)
ht=ottanh(Ct)
(12)
其中ft为遗忘门,表示Ct-1的哪些特征被用于计算Ct,ft是一个向量,向量的每个元素均位于[0,1]范围内;ut表示单元状态更新值,由输入数据xt和隐节点ht-1经由一个神经网络层得到,单元状态更新值的激活函数通常使用tanh。it为输入门,同ft一样也是元素介于[0,1]区间内的向量,由xt和ht-1经由Sigmoid计算得到。it用于控制ut的哪些特征用于更新Ct,使用方式与ft相同。最后为了计算预测值和生成下个时间片完整的输入,需要计算隐节点的输出ht,ht由输出门ot和单元状态Ct得到,其中ot计算方式与ft和it相同。σ为Sigmoid激活函数,其定义为
(13)
接着同样利用注意机制将从LSTM得到的特征序列Hi送入前馈神经网络中,利用softmax函数计算对应的注意力权重序列β=[β1,β2,…,βT2],计算公式为
β=softmax(WvaQv)
(14)
(15)
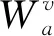
(16)
1.4 模态交互模块
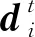
在整个模态交互模块中,采用类似文献[18]中提出的跨媒体联合损失函数,对枸杞虫害图像和文本两种媒体类型数据间的语义关联进行约束。
使映射入隐空间后的文本与图像特征向量通过一个分类器,进而通过模态内判别损失约束模型训练过程,使得到的图像和文本特征在各自模态内保持语义类别方面的可判别性。该分类器以图像和文本特征作为输入,预测各特征所属语义类别的概率分布,本文通过计算特征真实标签与所得概率分布间的交叉熵来构建模态内判别损失,具体公式为
(17)
式中Lsem——所有图像文本对语义类别分类的交叉熵损失
n——图像文本对总数
ci——真实类别标签

(18)
(19)

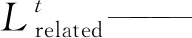
λ——平衡参数μ——边缘约束
D(·,·)——两向量间的余弦距离

(20)

(21)
因此,模态交互模块中跨媒体联合损失函数L可表示为
L=ε1Lsem+ε2Lrelated
(22)
其中超参数ε1和ε2用于平衡各损失项在训练时对模型的影响。
综上,本文首先引入注意力机制提取枸杞虫害图像与文本数据自身所蕴含的显著性语义信息,接着通过最小化跨媒体联合损失函数来探索枸杞虫害图像与文本特征间的语义关联,挖掘不同模态间语义相关关系,最终达到提升枸杞虫害图文跨模态检索准确率的目的。
2 数据预处理
2.1 试验数据准备与数据集构建
以尺蠖、大青叶蝉、负泥虫、木虱、蚜虫、蓟马等17种常见枸杞虫害为研究对象,通过实地调研拍照、书本收集以及网络爬虫技术共获取9 380幅包含17类枸杞虫害图像样本,图像样本均为.jpg格式。根据图文跨模态检索数据集构建的需要,充分利用网络渠道并借助专家力量为每类枸杞虫害中所有虫害图像撰写对应的文本描述,图4为自建枸杞虫害数据集部分类别图像及文本示例。给17类枸杞虫害分配所属类别标签,标签0为尺蠖,标签1为大青叶蝉,标签2为负泥虫,以此类推到标签16蛀果蛾。以跨模态检索常用的Wikipedia数据集结构为基准,构建枸杞虫害图像-文本对列表,按照8∶2的比例将自建的枸杞虫害数据集划分训练集与测试集。Wikipedia数据集图像-文本对列表格式为“文本名称 图像名称 所属类别标签”,自建的枸杞虫害数据集图像-文本对列表格式为“图像相对路径 文本相对路径 所属类别标签”。

图4 自建枸杞虫害数据集部分类别图像及对应文本示例Fig.4 Some category images and corresponding text examples of self-built Lycium pest dataset
2.2 数据增强与扩充
针对自建枸杞虫害数据集学习样本少,在复杂网络中容易发生过拟合问题,本研究采用数据增强技术对原始数据集进行扩充。数据增强可使原始数据集更具多样性,从而减少过拟合现象,进一步提升训练模型的泛化能力。

图5 枸杞虫害图像数据增强操作Fig.5 Lycium pests image data enhancement operation
在处理图像样本时,通过对原始图像进行垂直翻转、调整亮度、随机裁剪以及旋转操作扩增枸杞虫害图像样本,部分图像扩增前后结果如图5所示。
在处理文本样本时,现有自然语言处理的数据样本增强扩充主要有2种方法:加噪和回译。加噪即在原始文本数据基础之上通过替换词、删除词等方式生成新的与原始数据相似的文本样本;回译即将原始文本数据翻译为其他语言,再将翻译得到的结果再次翻译回原始语言。本文采用文本分类任务的简单数据增强(Easy data augmentation for text classification tasks,EDA)方法通过加噪的思路对文本进行处理,该方法中主要的加噪形式有同义词替换、随机插入、随机交换以及随机删除,其处理效果如图6所示。
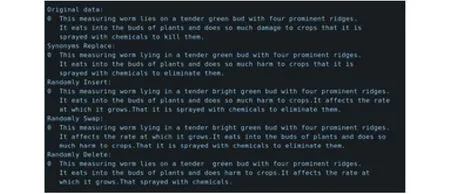
图6 枸杞虫害文本数据增强操作Fig.6 Lycium pests text data enhancement operation
将扩增后的文本内容与扩增后的图像相对应,更新枸杞虫害样本内容,得到扩增后的枸杞虫害样本集,按照8∶2的比例划分训练集与测试集,并用新得到的枸杞虫害数据集代替原始数据集进行后续试验。
3 试验与结果分析
3.1 试验环境设置
试验在宁夏大学高性能计算平台上进行,平台操作系统为Ubuntu 16.04 LTS。加载软件环境有gcc、cuda 9.0和Python 3.6.10。GPU为NVIDIA quadro p 5000。采用深度学习框Tensorflow 1.13.1。
3.2 评价指标和对比方法
为了充分验证本文方法的可行性及准确率,在自建的枸杞虫害数据集上,使用枸杞虫害图像检索枸杞虫害文本以及枸杞虫害文本检索枸杞虫害图像2个任务对模型准确率进行衡量。
采用平均精度均值(Mean average precision,MAP)和准确率(Precision)-召回率(Recall)曲线作为枸杞虫害跨模态检索准确率的评价指标。
相同试验环境下通过试验对比了2种传统跨模态检索方法:典型相关分析[19](Canonical correlation analysis,CCA)和核典型相关分析[20](Kernel canonical correlation analysis,KCCA),以及6种基于深度神经网络的方法:深度典型相关分析[21](Deep canonical correlation analysis,DCCA)、端到端的深度典型相关分析[22](End-to-end DCCA)、深度语义匹配[23](Deep semantic matching,Deep-SM)、通信自编码器[24](Correspondence autoencoder,Corr-AE)、对抗式跨模态检索[25](Adversarial cross-modal retrieval,ACMR)、特定模态的跨模态相似度测量[26](Modality-specific cross-modal similarity measurement,MCSM)。传统的跨模态检索方法CCA通过学习映射矩阵,最大化公共空间中不同模态投影特征之间的相关性。KCCA是CCA的一种扩展,它使用核函数将特征投影到一个高维空间,能更好的处理特征集合非线性的情景。DCCA是CCA的一个非线性延伸,能够同时学习2个数据视图间的非线性投影,使得到的映射特征高度非线性相关。End-to-end DCCA采用GPU以及减少过拟合的方法可以应对原始DCCA框架的不足。Deep-SM采用2种不同的卷积神经网络进行深度语义匹配,实现跨模态检索。Corr-AE由2个耦合在编码层的自编码器网络组成,可以同时对重构误差和相关损耗进行建模。ACMR在不同模态之间互相作用获得一个有效的共享子空间,能够有效解决一个模态的一项数据可能存在多个语义不同项的问题。MCSM为不同模态数据构建独立的语义空间,通过端到端框架直接从每个语义空间生成特定于模态的跨模态相似度。为公平对比,所有对比方法的图像端输入均为从预训练VGG19网络中提取的4096维深度特征,文本端则首先通过word2vec提取词向量然后将文本中所有词向量的平均值作为输入。除了CCA、KCCA、DCCA、End-to-end DCCA 为20维,其他所有方法最后的特征维数均为1 024。
3.3 结果对比
本文方法与所对比方法的结果如表1所示。实验结果表明,本文方法的平均精度均值平均值达到了0.458。不论通过图像检索文本,还是通过文本检索图像,本方法的平均精度均值均高于对比方法。在所有对比方法中,MCSM方法表现最好,而本文方法相较于该方法平均精度均值平均值提高了0.011。ACMR方法和Corr-AE方法效果相当。本文方法比Deep-SM、End-to-end DCCA以及DCCA方法的平均精度均值平均值分别提高了0.045、0.069、0.074,而CCA方法的平均精度均值平均值只有0.263。
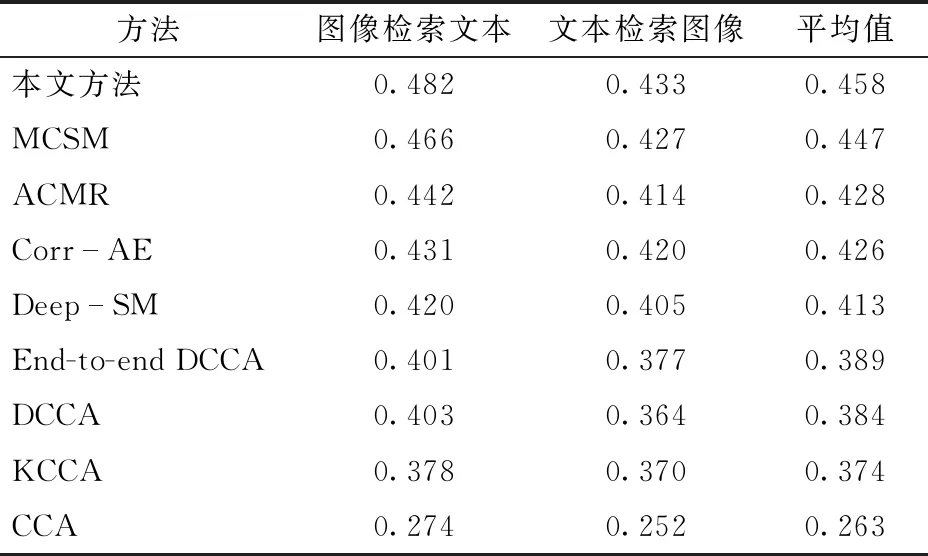
表1 不同方法平均精度均值结果对比Tab.1 Comparison of results of different methods
现有的跨模态检索方法大多将来自其自身特征空间的不同模态的数据平均投影到一个单一的公共空间中,以找到它们之间的潜在对齐方式,学习它们之间的内在联系。但这些方法只能粗略捕捉枸杞虫害图像与文本之间的对应关系,无法探索图像与文本数据中的细粒度信息。而本文方法有针对性地融合注意力机制对枸杞虫害图像和文本分别进行处理,能够充分挖掘枸杞虫害图像与文本之间复杂的跨媒体关联,从而提高检索准确率。
为进一步证实本文方法的有效性,在枸杞虫害数据集上的Precision-Recall曲线如图7和图8所示。由图7可知,本文方法在图像检索文本任务中性能明显优于其他对比方法。对于图8中文本检索图像任务,召回率取0.3~1.0时,本文方法的准确率略低于某些对比方法,但基本与性能最优方法持平,而在召回率取0~0.3时,本文方法的准确率明显高于其他对比方法。综合来看,本文方法在文本检索图像任务中的检索性能也优于其他对比方法。
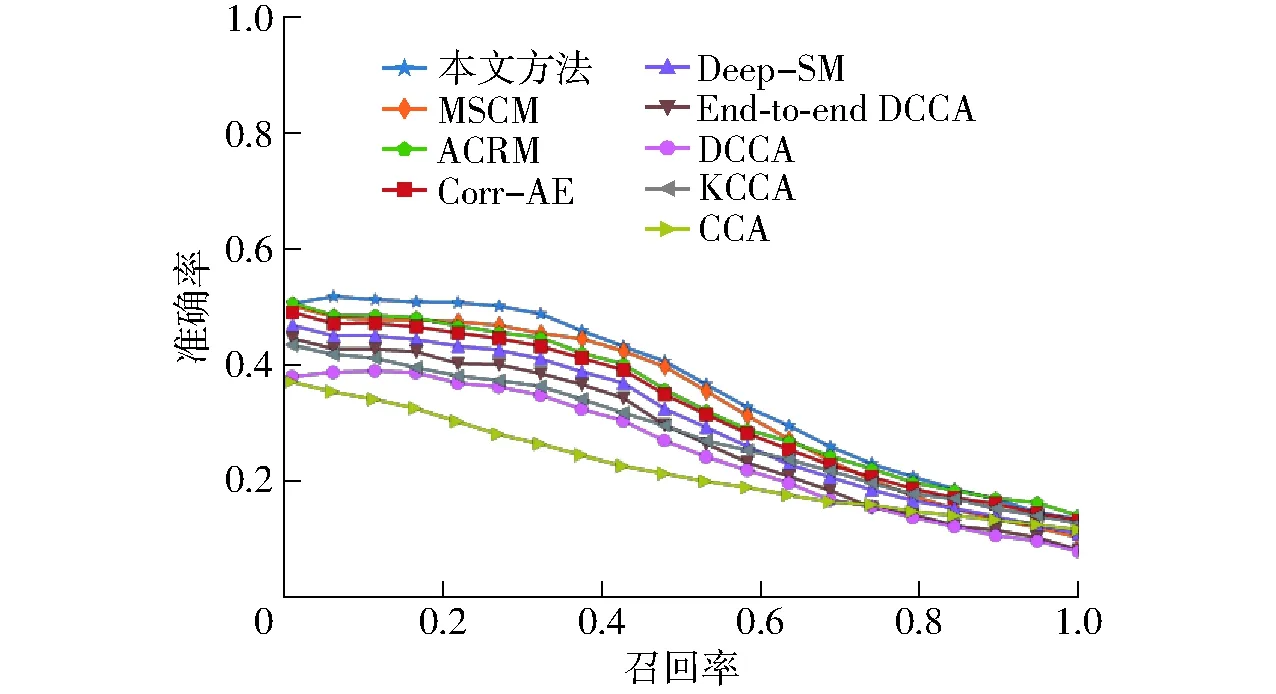
图7 图像检索文本任务的Precision-Recall曲线Fig.7 Precision-Recall curves of image to text task

图8 文本检索图像任务的Precision-Recall曲线Fig.8 Precision-Recall curves of text to image task

图9 本文方法与比较方法MCSM在自建枸杞虫害数据集上的跨模态检索结果示例Fig.9 Examples of cross-modal retrieval results of proposed method and comparison method MCSM on self-built Lycium pest dataset
图9给出了本文方法与MCSM方法在自建的枸杞虫害数据集上的跨模态检索结果对比示例,带有绿色边框的表示正确的检索结果,带有红色边框的表示错误结果。以大青叶蝉的图像检索文本任务为例,在本文方法检索得到的前8个文本中,检索正确的有7个,错误的有1个,而通过MSCM方法检索得到正确结果有5个,错误结果有3个。从图9中可看出,不论在图像检索文本任务上,还是在文本检索图像任务上,本文方法的跨模态检索表现均略优于MCSM。
3.4 消融试验
为了进一步验证注意力机制对所提方法各个部分的影响,本文进行了消融试验,结果如表2所示。其中 I表示图像编码模块,T表示文本编码模块,A表示图像或文本编码模块中包含注意力机制,NA则表示不包含注意力机制。从表2可以看出,融合注意力机制的模型可以突出枸杞虫害图像和文本内容中较为重要的细粒度局部信息,更好地为2种模态间的关联关系建模,提高检索准确率。
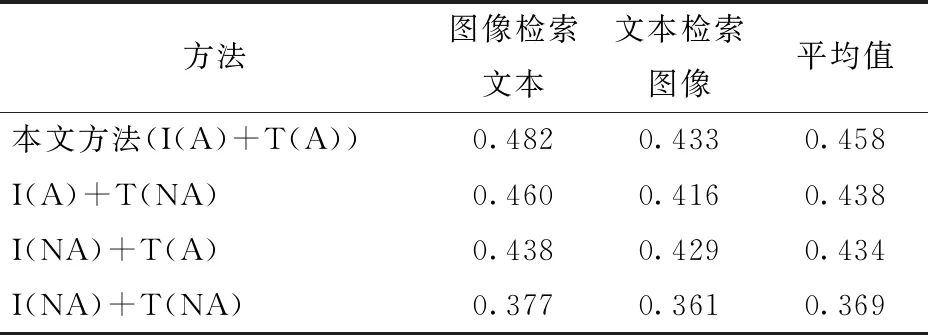
表2 自建枸杞虫害数据集上基线试验的平均精度均值结果Tab.2 MAP results of baseline experiment on self-constructed Lycium barbarum pest dataset
另外,为进一步证明模型的鲁棒性,本文探索了隐空间中特征维度对本文模型的影响。在构建网络时分别将隐空间设置为256、512、1 024维并进行试验,结果如表3所示。从表3可以看出,在特征维度取1 024时,模型性能最佳,但在特征维度取256或512时,模型性能并没有出现显著下降。
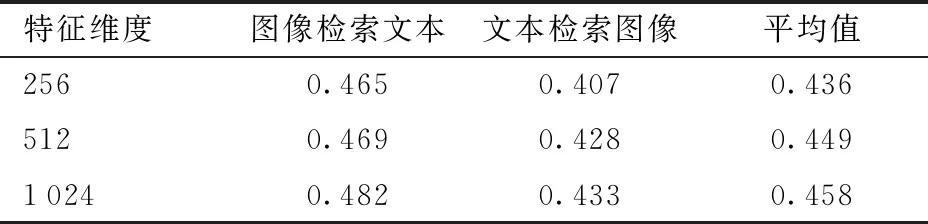
表3 不同特征维度的平均精度均值结果Tab.3 MAP results of different feature dimensions
4 结论
(1)针对现有农作物病虫害识别与检索方法识别或检索模态较为单一的问题,本文以枸杞尺蠖、大青叶蝉、负泥虫、木虱、蚜虫、蓟马等共17类枸杞虫害为研究对象,提出了一种融合注意力机制的枸杞虫害图文跨模态检索方法。根据跨模态检索任务需要,构建枸杞虫害数据集,然后通过图像编码模块以及文本编码模块分别对图像和文本信息进行细粒度处理,经过模态交互模块中损失函数的约束,深入挖掘不同模态间的语义相关关系,实现跨模态检索任务,并在自建的枸杞虫害数据集上对本文方法以及一些经典方法的性能进行了对比分析。
(2)提出的融合注意力机制的枸杞虫害图文跨模态检索模型,将跨模态检索引入枸杞虫害检索中,为枸杞虫害多模式数据检索提供了有效而强大的方法,相比于传统的基于单模式的技术更加方便且检索结果更加直观、丰富。
(3)通过在模型中融入注意力机制,能够挖掘数据中的细粒度信息,捕捉数据的显著性语义信息,从而提升检索性能,与8种现有方法相比,本文方法平均精度均值平均值提高了0.011~0.195,优于所有对比方法。
