基于残差网络和小样本学习的鱼图像识别
2022-03-14袁培森徐焕良
袁培森 宋 进 徐焕良
(南京农业大学人工智能学院, 南京 210095)
0 引言
鱼在全球各水域分布广泛,对人类的生产、生活影响极为重要。对鱼类图像数据的识别研究可对鱼种群的观测及其栖息地生态环境的治理起到重要作用,在环境保护、学术研究以及经济生产方面,均有着重大意义[1]。
近年来,得益于海量数据标注和计算能力的提升,利用深度神经网络进行图像识别,在各领域的研究取得了重大的进展和突破[2]。然而,基于鱼图像的鱼种类识别进展缓慢。由于水底环境光线较弱,鱼图像采集难度大,获得的鱼图像标注数据集数量较少[3],无法满足深度神经网络训练所需的大数据集要求。因此,基于小样本学习(Few-shot learning)的方法[4]仅通过少量样本学习,可以用于鱼图像标注少情况下的识别研究。
最早的小样本学习基于贝叶斯框架[5]对视觉对象进行学习。由于此方法采用传统学习技术,自动学习能力较弱。研究者提出了语义迁移的方式解决小样本识别问题,MENSINK等[6]通过各类别的语义,使用度量学习方法来让模型能够在类别变换时保持稳定。ROHRBACH等[7]采用直推式学习,通过构建已知类别空间分布的方式,对未知类别的表示进行预测。这些方法能够让网络模型自动进行学习,但由于需要人为添加语义描述,使用的便捷性仍然有限。SANTORO等[8]首次提出了采用外部存储的记忆增强方法,其通过存储部分输入数据的方式,让网络模型将不同时刻的输入建立联系,以学习识别的共性过程。SNELL等[9]提出的原型网络方法,通过学习将输入数据映射到嵌入空间,建立类别的均值中心,以便在面对新的数据时通过距离度量判断其所属类别。SUNG等[10]所提出的关系网络在原型网络的基础上,将距离度量方式也作为网络学习的内容,以便通过最佳的距离度量方式进行类别判断。CHOI等[11]通过让网络学习不同的调节器,使其能够学会不同领域内、差距较大类的小样本识别能力。TSENG等[12]在训练阶段利用仿射变换增强图像的特征,模拟不同领域下的特征分布,从而让模型的跨域能力进一步增强。ZHANG等[13]提出了一种自适应的网络模型AdarGCN,以便在样本量不足的情况下,在网络上爬取数据后进行有效地降噪处理,完成样本量更为稀少的小样本图像识别任务。
目前,小样本学习已经被广泛地应用于标注数据稀少的图像识别、目标检测和自然语言处理等领域[14-15],陈英义等[16]构建了FTVGG16卷积神经网络提高复杂应用场景鱼类目标的识别精度,本文主要针对鱼图像标注稀少情况下的识别质量问题。
为提升小样本情况下的鱼图像准确识别率,本文基于度量学习的小样本学习方法,采用残差块结构作为鱼图像样本深层特征提取器,并将其映射至嵌入空间,形成各类别的均值中心,计算样本与均值中心的距离,实现鱼图像识别。利用小样本学习和残差网络在mini-ImageNet数据集上进行训练,得到识别鱼的初步模型。为准确识别细粒度鱼图像,将前一阶段得到的网络模型利用迁移学习技术[17],在Fish100数据集上进行重新训练,最终得到小样本鱼图像识别模型。为验证本文方法的可行性,运用5类常用的小样本学习方法在Fish100数据集和ImageNet数据集上进行对比分析。
1 试验材料
选用mini-ImageNet、Fish100作为试验数据集, 数据集ImageNet用于测试。
1.1 mini-ImageNet
mini-ImageNet[18]作为小样本图像识别中常用数据集,选用ImageNet数据集中的100个类别,包含鱼、鸟等类。文中利用mini-ImageNet数据集对小样本学习模型进行预训练,数据集划分如表1所示。

表1 mini-ImageNet数据集划分Tab.1 Partition of mini-ImageNet dataset
mini-ImageNet数据集中的示例如图1所示。

图1 mini-ImageNet部分图像示例Fig.1 Samples of mini-ImageNet’s images
1.2 Fish100
Fish100[19-20]数据集是深度学习图像标注数据集Image CLEF中Marine animal species的一个子集,包含100种鱼,共计6 358幅图像。本文所采用的Fish100数据集划分详情如表2所示。图2为Fish100数据集中部分图像示例。
1.3 ImageNet
ImageNet[21]是一个面向机器视觉的大型可视化数据集,拥有共计超过1 400万幅图像,是深度学习领域最为常用的数据集之一,其中包含多种鱼图像数据。

表2 Fish100数据集划分Tab.2 Division of Fish100 dataset

图2 Fish100图像示例Fig.2 Sample of Fish100’s images
ImageNet数据集除存在与Fish100相同的特点,即类内差异性大、类间相似性高之外,还存在一些背景干扰因素等情况,增加了识别难度。为了检验本文方法的识别能力,本文选用ImageNet数据集中的20种鱼进行测试,具体如表3所示。

表3 ImageNet数据集Tab.3 ImageNet dataset
图3为ImageNet数据集中部分图像示例。

图3 ImageNet图像示例Fig.3 Sample of ImageNet’s images
2 试验方法
2.1 数据预处理
预处理操作分为裁剪、格式转换、图像增强等,对于卷积神经网络(Convolutional neural networks, CNN)而言,输入图像必须被调整为统一尺寸。本文图像预处理步骤为:①将所有图像转换为3通道的RGB图像。②将所有图像的尺寸统一调整为224像素×224像素。③将调整后的图像以中心为原点,进行随机裁剪。④对所有图像进行正则化,降低网络模型过拟合的可能性。
2.2 网络模型
本文的小样本学习采用基于度量的小样本学习模型,其在面对输入样本时,首先会通过网络模型将其映射至嵌入空间,在此过程中,会通过残差块结构进行特征提取,得到特征向量;随后,通过求平均值的方式,得出类别的均值中心。最后通过度量来进行类别判断。
本文模型共包含4个基本单元,即块(Block),每个块内均包含1个残差块(内含4个卷积层)、1个Batchnorm层、激活层和1个最大池化层,其整体结构如图4所示。
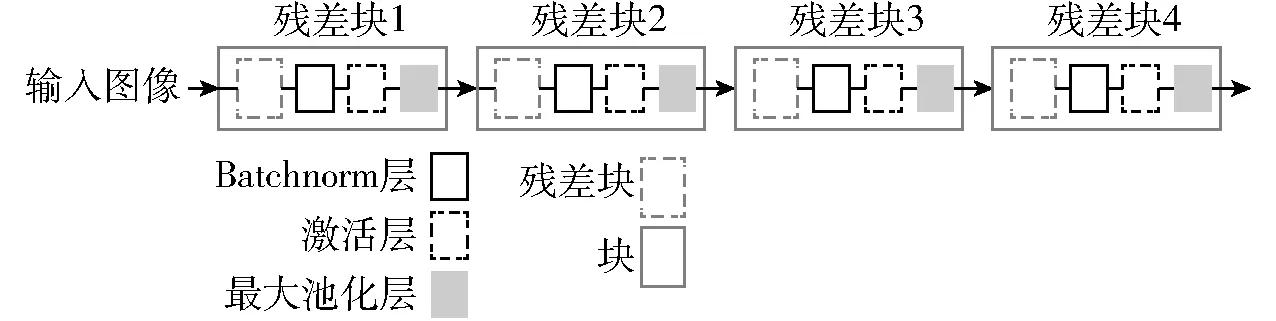
图4 本文网络模型整体结构Fig.4 Overall structure of network model
传统的CNN网络直接通过训练,学习输入x与输出H(x)之间的关系,即x→H(x),其中x为输入数据,H(x)为经过网络层的输出。而残差块则致力于使用图4所示的有参网络层,来学习输入、输出之间的残差,其中残差块结构[22-23]如图5所示。其计算公式为
F(x,Wi)=W2σ(W1x)
(1)
式中W1、W2——有参卷积层的权重
σ——ReLU函数
F——残差映射函数
Wi——第i层卷积层的权重矩阵
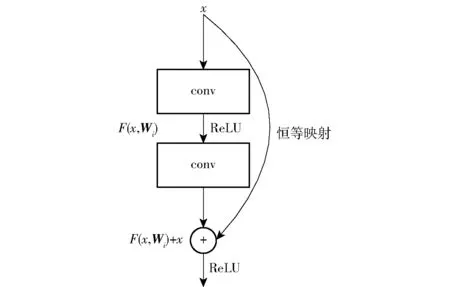
图5 残差块结构图Fig.5 Structure of residual block
则输入x与输出H(x)之间的关系就变为x→F(x,Wi)+x。
由于输入与残差之间的关系较其与输出之间的关系更易表示,因此具有该结构的网络模型,具有更强的图像特征提取能力。
模型中各残差块中卷积层的卷积核数目(Num output)如表4所示。
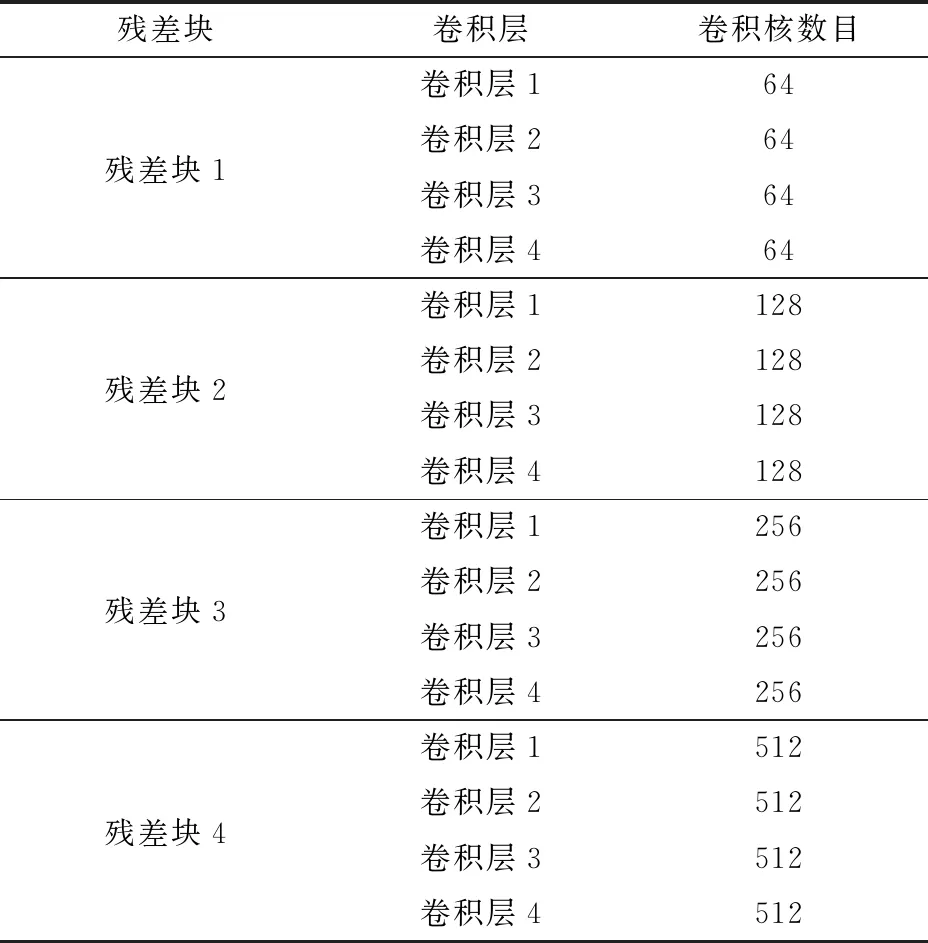
表4 网络模型各卷积层的卷积核数目Tab.4 Number output of each convolution layers of network model
模型的其它参数如表5所示。
2.3 识别过程
在每次元任务中,采集N(K+Q)个数据,其中N为类别数量,K为支撑集样本数量,Q为验证集样本数量。采集完成并进行预处理之后,将支撑集中的样本作为输入图像输入网络模型,在每一个块内通过残差块进行特征提取。当输入图像通过每个卷积层时,其通道数c、宽度w和高度h都会根据网络参数而变化。

表5 网络模型参数Tab.5 Parameters of network model
c=o
(2)
w=(w0+2p-k)/s+1
(3)
h=(h0+2p-k)/s+1
(4)
式中o——卷积核数量
p——边缘填充尺寸
k——卷积核尺寸
s——步长
w0——输入图像宽度
h0——输入图像高度
随后,通过BatchNorm层对数据进行归一化处理,公式为
(5)
式中E(·)——均值函数
Var(·)——方差函数
y——归一化值
之后通过激活层,使用ReLU函数,通过引入非线性因素的方式,增强神经网络对模型的表达能力。
ReLU(x)=max(0,x)
(6)
随后通过最大池化层,对邻域特征点取最大值的方式,对提取到的特征向量进行过滤,降低特征提取的误差。图6为最大池化的示意图,特征矩阵中4个邻域内分别有4个特征点,每个邻域中的最大特征点分别为7、9、9、8,即通过最大池化层后,每个邻域内只有最大的这4个特征点被保留。
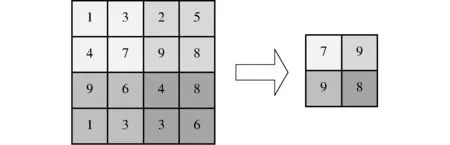
图6 最大池化示意图Fig.6 Illustration of max pooling
池化层的运算方法和卷积层基本相同,只是不再改变图像的通道数。再依次通过网络模型的4个块后,输入数据将从原来的D维变为N维,即被映射至N维的嵌入空间。映射完成后,通过将映射完成的各类别所有样本数据取均值,形成各类别的均值中心。
(7)
式中Sk——类别k在支撑集中样本的特征向量
fφ——嵌入函数
ck——类别k的均值中心
xi、yi——支撑集中第i个样本及该样本所属类别
在确定每个类的均值中心后,将验证集数据样本通过嵌入函数映射到嵌入空间,由于训练当中验证集的数据已经标记了类别,将通过其与各类别均值中心的欧氏距离得出其属于其自身类别的概率Pφ为
(8)
式中d——欧氏距离函数
ck′——类别k′的均值中心
通过在训练过程中重复上述类别判断过程,网络模型将不断地进行优化,这使得同类别样本在映射到嵌入空间后,处于更为相近的位置,由此所得出的均值中心,也将更能代表类别的真实位置。
测试过程如图7所示。验证集的样本未标记类别,嵌入函数在通过支撑集中的样本构建类别均值中心后,将验证集中的样本映射到嵌入空间,通过将其与各均值中心进行距离度量,给出其属于各类别的概率,概率最高者即为该样本的预测类别[24]。
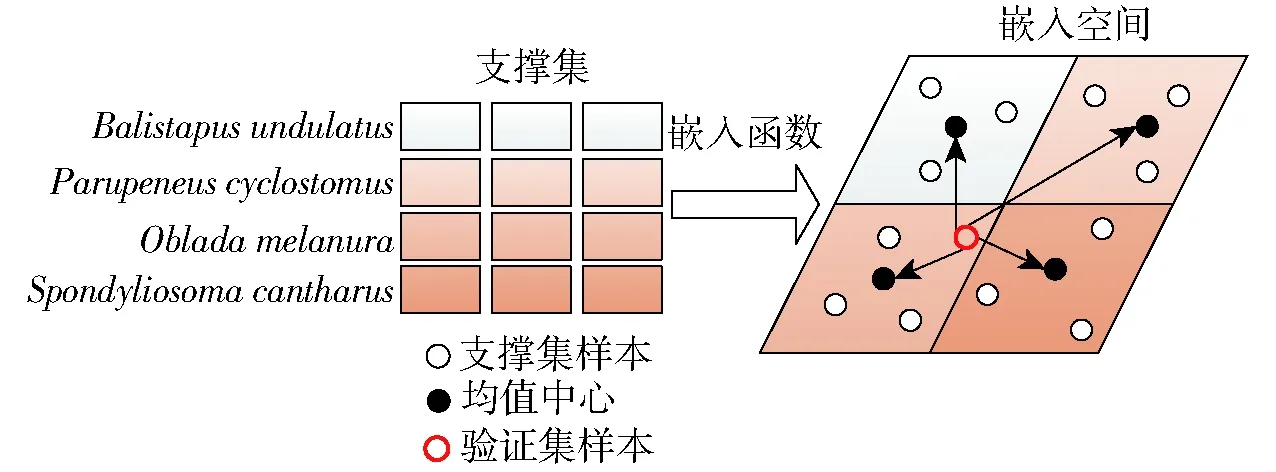
图7 类别判断过程示意图Fig.7 Category recognition process of samples
2.4 迁移学习
迁移学习技术已广泛应用于深层网络模型设计和参数训练,本文的迁移学习过程如图8所示。

图8 迁移学习过程Fig.8 Transfer learning process
采用小样本学习中常用的数据集mini-ImageNet对模型进行预训练,预训练过程与训练和测试过程保持一致,同样被分解为多个元任务,每个元任务中抽取包含N个类别的共计N(K+Q)个样本,让网络模型学习如何将这些样本通过距离度量的方式判断类别。在预训练过程中,使用特定的优化器,对网络各层参数,即卷积层的权重W以及Batchnorm层的γ和β进行调整。
将预训练后的模型使用鱼图像数据集进行训练,并微调网络最后一个块中的各层。由于本文所设计的模型不通过全连接层输出类别,因此无需进行全连接层的调整。
3 结果与分析
3.1 试验环境
试验平台为Windows 10,64位操作系统,CPU为i5-8300H,2.30 GHz,GPU为NVIDA Geforce GTX 1080ti,5 GB,内存为16.0 GB。
3.2 试验参数与评价标准
本文中的预训练及训练阶段的试验参数设置如表6所示。优化器选用Adam[25]。

表6 试验参数设置Tab.6 Parameters setting of experiment
每次采样抽取5个类别,即way为5;每个类别中15个样本作为支撑集,即shot为15;15个样本作为测试集,即query为15,每次采样共抽取5×(15+15)幅图像。每次元任务共进行20次采样,最大迭代次数为1 000次。
本文采用精度、召回率以及F1值来衡量模型识别效果,其中精度衡量模型识别的准确性,召回率衡量模型的查全能力,F1值衡量模型的综合性能。
3.3 模型训练损失值对比
将本文模型与MAML[26]、Meta-baseline[27]、Meta-learning LSTM[28]、Prototypical network[9]以及Relation network[10]等5种常用小样本学习模型在训练阶段的损失值进行对比,结果如图9所示。
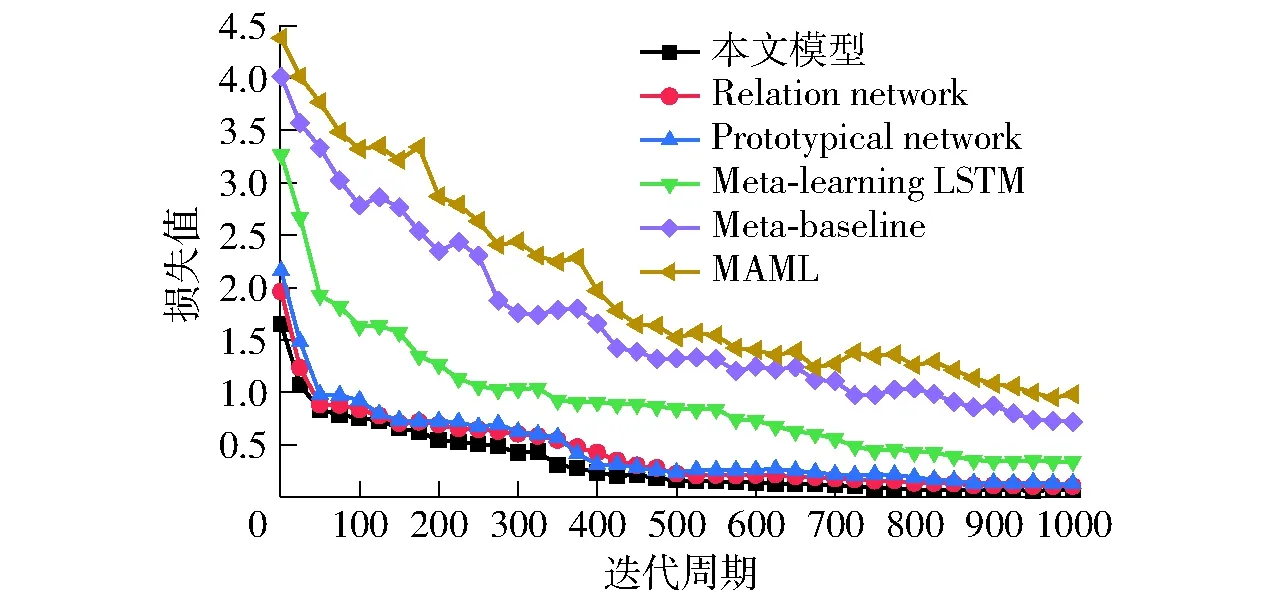
图9 不同模型训练损失值Fig.9 Training loss of different models
从图9可以看出,本文模型不仅初始损失值较低,且波动较小,损失值始终低于其它各模型,最终收敛值也最小,为0.06左右。Relation network以及Prototypical network两种基于度量的小样本学习方法的表现虽不如本文模型,但总体也较好,整体均呈明显的下降趋势,虽然波动较本文方法更大,但最终收敛到的损失值较为理想,分别为0.10和0.12左右。Meta-learning LSTM的表现较前述3种模型差,在收敛速度以及损失值方面,都不如前者,最终损失值约为0.34。Meta-baseline和MAML这两种方法的损失值较高,且处在波动状态,最终的损失值也较其它模型高,分别为0.71和0.97左右。
3.4 参数对结果的影响
测试各模型在way、shot改变情况下的识别能力。分别设置way为5、shot为5,way为3、shot为5,way为5、shot为3,way为3、shot为3,各模型在3组参数设置下,在两数据集上的测试精度、召回率和F1值分别如图10~12所示。
图10为不同参数设置下各模型精度结果。由图10可知,各模型在两数据集上的识别精度在不同参数设置下均有明显的区别,其中way为3、shot为5时精度最高;way为5、shot为5时次之;随后是way为3、shot为3;最后是way为5、shot为3。但在不同参数设置下,各模型的识别精度仍保持了相对的差异,且在Fish100上的识别精度普遍高于ImageNet。

图10 不同参数设置下各模型精度结果Fig.10 Model accuracy results under different parameter settings
图11为不同参数设置下各模型召回率结果。由图11可知,各模型在两数据集上的召回率在不同参数设置下均有明显的区别,其中way为3、shot为5时的召回率最高;way为5、shot为5次之;随后依次为way为3、shot为3和way为5、shot为3。在不同参数设置下,各模型的召回率之间也保持了相对差异,且在Fish100上的召回率高于ImageNet。
图12为不同参数设置下各模型F1值测试结果。由图12可知,各模型在两数据集上的F1值遵循与精度和召回率一样的规律,F1值由高到低的参数设置依次为way为3、shot为5,way为5、shot为5,way为3、shot为3以及way为5、shot为3。模型、数据集之间的差异也同精度和召回率。
3.5 way和shot对结果的影响
为进一步确认不同参数设置对模型识别效果的影响,使用本文模型保持way为5,分别设置shot为1~6,在2个数据集上分别进行测试,测试结果如图13所示。

图11 不同参数设置下各模型召回率结果Fig.11 Recall rate results of various models under different parameter settings
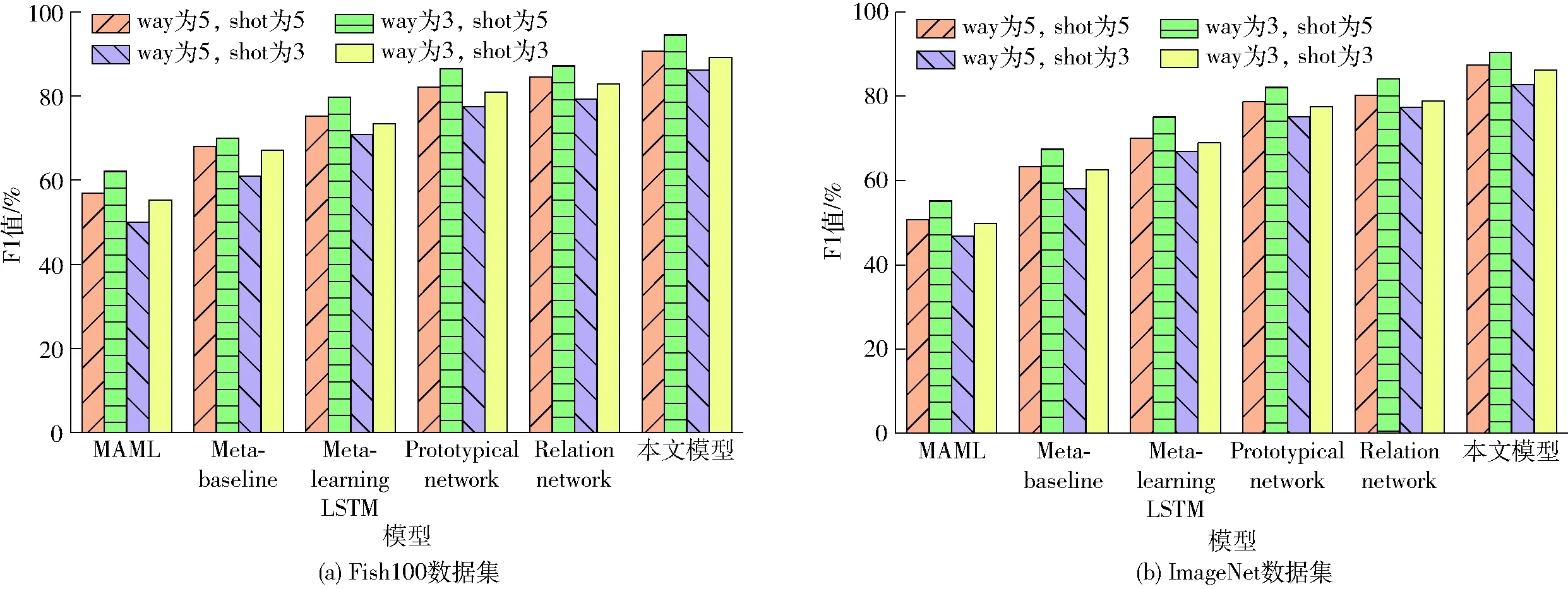
图12 不同参数设置下各模型F1值测试结果Fig.12 F1 results of each model under different parameter settings

图13 不同shot值下本文模型测试结果Fig.13 Test results of proposed model under different shot values

图14 不同way值下本文模型测试结果Fig.14 Test results of proposed model under different way values
由图13可知,在way相同的情况下,模型识别的精度、召回率和F1值随着shot的上升而上升,且在shot值越小时上升幅度越大。可见在way相同的情况下,shot值与识别效果之间成正比关系。
保持shot为5,分别设置way为2~6,使用本文模型在两个数据集上分别进行识别测试,结果如图14所示。
由图14可知,在shot相同的情况下,模型的识别精度、召回率和F1值随着way值的上升而平缓下降。可见在shot相同的情况下,way值与识别效果之间成反比关系。
3.6 模型识别结果对比
将本文模型与MAML、Meta-baseline、Meta-learning LSTM、Prototypical network以及Relation network等5种小样本学习模型的试验结果进行对比。选择最优参数way为3、shot为5对模型效果进行比较。表7为各模型在Fish100数据集上的测试结果。
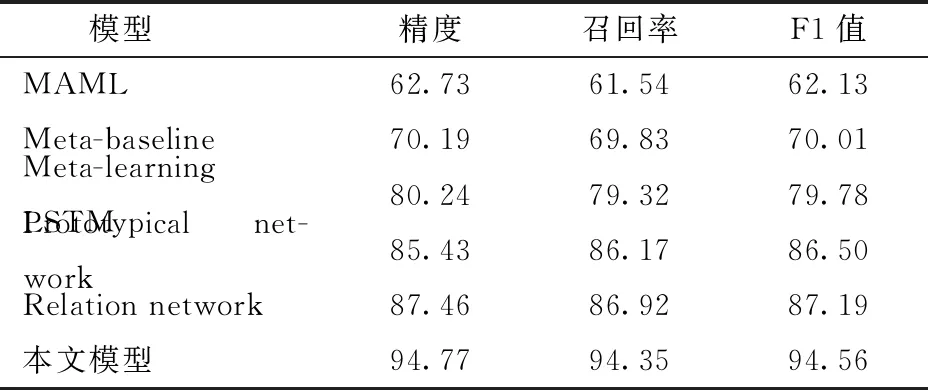
表7 Fish100数据集上 way为3、shot为5测试结果Tab.7 Result on Fish100 dataset while way was 3 and shot was 5 %
由表7可以看出,在Fish100数据集上本文模型在精度、召回率以及F1值上,均显著优于其它模型,其中精度较其它模型中识别效果最佳的Relation network高7.31个百分点,较Prototypical network高9.34个百分点,较Meta-learning LSTM高14.53个百分点,较MAML高32.04个百分点。本文提出利用残差块结构改进小样本学习网络,有效提取鱼图像深层特征,提高了鱼图像识别精度,使得其表现优于其他模型。
各模型在ImageNet数据集的识别结果如表8所示。由表8可以看出,各模型在ImageNet鱼图像识别任务中的结果,较Fish100数据集均有一定的降低,本文模型的识别精度下降了3.74个百分点,Relation network、Prototypical network、Meta-learning LSTM、Meta-baseline以及MAML则分别下降了3.14、3.00、4.78、2.28、6.43个百分点。其原因是受ImageNet数据集中复杂背景环境因素影响,模型识别效果均有所降低。即使如此,相比于其它5种小样本学习模型,本文模型识别效果仍然最佳,识别精度为91.03%,召回率为90.78%,F1值为90.90%。综上,本文模型对鱼图像识别具有较好的效果,可为后期小样本鱼图像识别在实际环境中的应用提供技术支撑和参考。
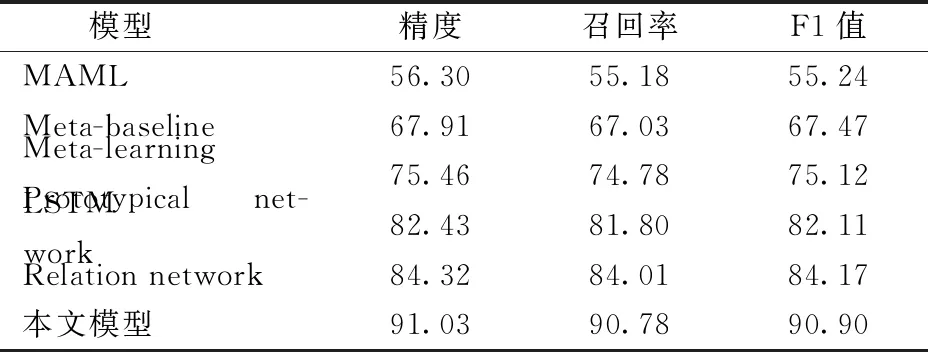
表8 ImageNet数据集上way为3、shot为5测试结果Tab.8 Result on ImageNet dataset while way was 3 and shot was 5 %
4 结论
(1)本文模型在Fish100、ImageNet数据集上均优于其他小样本学习方法,特别在Fish100数据集上,试验效果最佳,其中精度、召回率以及F1值分别为94.77%、94.35%和94.56%。
(2)在不同参数下,各模型在Fish100数据集上的识别效果均优于ImageNet,表明ImageNet数据集识别难度高于Fish100数据集。
(3)在小样本学习中,way、shot的取值会影响模型识别结果,其中way的取值与识别结果成反比,而shot则与识别结果成正比,且shot的影响权重大于way。
