基于近红外高光谱的梨叶片炭疽病与黑斑病识别
2022-03-14陶红燕郑文娟王良龙
刘 莉 陶红燕 方 静 郑文娟 王良龙 金 秀
(1.安徽农业大学园艺学院, 合肥 230036; 2.安徽农业大学信息与计算机学院, 合肥 230036)
0 引言
梨在我国的种植范围广泛,产量仅次于苹果、柑橘[1]。在梨树的生长过程中,各种病害不仅威胁着梨树的生长,还会影响梨果实的品质,最典型的有黑斑病、炭疽病、锈病等,且病害的大规模爆发会造成严重的经济损失[2]。因此,及时检测梨叶片病害,并采取针对性的病害防治措施,对于梨树病害防治、减少经济损失有着重要意义。
在梨树诸多病害中,炭疽病和黑斑病的发病症状相似,仅凭肉眼很难区分。尽管目前可见-近红外检测技术[3-5]、机器视觉检测技术[6-7]等已经广泛运用于农作物的无损检测,但是可见-近红外只能检测到农作物的内部信息,而无法获取其外部特征,机器视觉检测技术虽然可以获得农作物的外部特征,但是却无法检测其内部信息。相比之下,高光谱技术具有图谱合一的特点,既可以探测到农作物的外部图像信息,又可以获得其内部品质信息。
目前已有很多学者利用高光谱技术在农产品品质检测方面做了大量研究[8-10]。国外学者侧重于将高光谱技术用于肉类以及水果的品质测定[11-12],国内学者则多将此技术应用于蔬菜水果农产品的无损检测、病虫害识别与分类[13-15]。ELMASRY等[16]利用波长400~1 000 nm的高光谱成像仪采集“Mclntosh”苹果的高光谱图像,建立了“Mclntosh”苹果的早期损伤判别模型,并通过试验表明,利用高光谱技术可以有效识别损伤1 h以上的苹果与正常苹果;MEHL[17]利用高光谱技术建立了Golden Delicious、Gala、Red Delicious 3个品种苹果的表面损伤程度的检测模型,检测结果的准确率分别为85%、95%和76%;吴龙国等[18]利用高光谱图像采集技术采集了波长400~1 000 nm范围的高光谱图像,对灵武长枣表面的外部碰伤缺陷进行检测,结果较为理想;李勋兰等[19]利用高光谱成像技术采集了4种柚子的上表面与下表面的高光谱图像,构建了柚子种类鉴别的识别模型,准确率分别为99.46%和98.44%。但目前有关利用高光谱技术对梨树病害种类进行识别研究的报道比较少。
本文以砀山酥梨叶片黑斑病与炭疽病为研究对象,以砀山酥梨正常叶片、炭疽病叶片与黑斑病叶片的高光谱图像为试验样本,通过对高光谱图像光谱信息的预处理、特征波长提取,并结合支持向量机(SVM)与反向传播(BP)神经网络模式识别等建立砀山酥梨炭疽病和黑斑病的识别模型,以期为果树的病害识别提供参考依据与技术支持。
1 试验材料与识别方法
1.1 试验材料
本试验供试材料为安徽农业大学资源育种实验室盆栽砀山酥梨叶片,挑选采集叶片大小均匀、叶面较为宽大、位于新梢顶端且健康的嫩叶叶片,共90片。
提前在实验室配置好炭疽病与黑斑病菌丝。接种病菌前,用标签标注每片叶片,并采集所有叶片正反两面的高光谱图像,共获取180幅高光谱图像。然后对90片样品叶片进行菌丝块接种处理。
为了观察各叶片从健康状态到发病状态的连续动态过程,自接种病菌当天开始连续对叶片进行高光谱图像采集,每天记录发病叶片的标签号及其发病症状,并将肉眼所能看到的发病症状与高光谱图像上的症状作比较。
1.2 高光谱图像采集
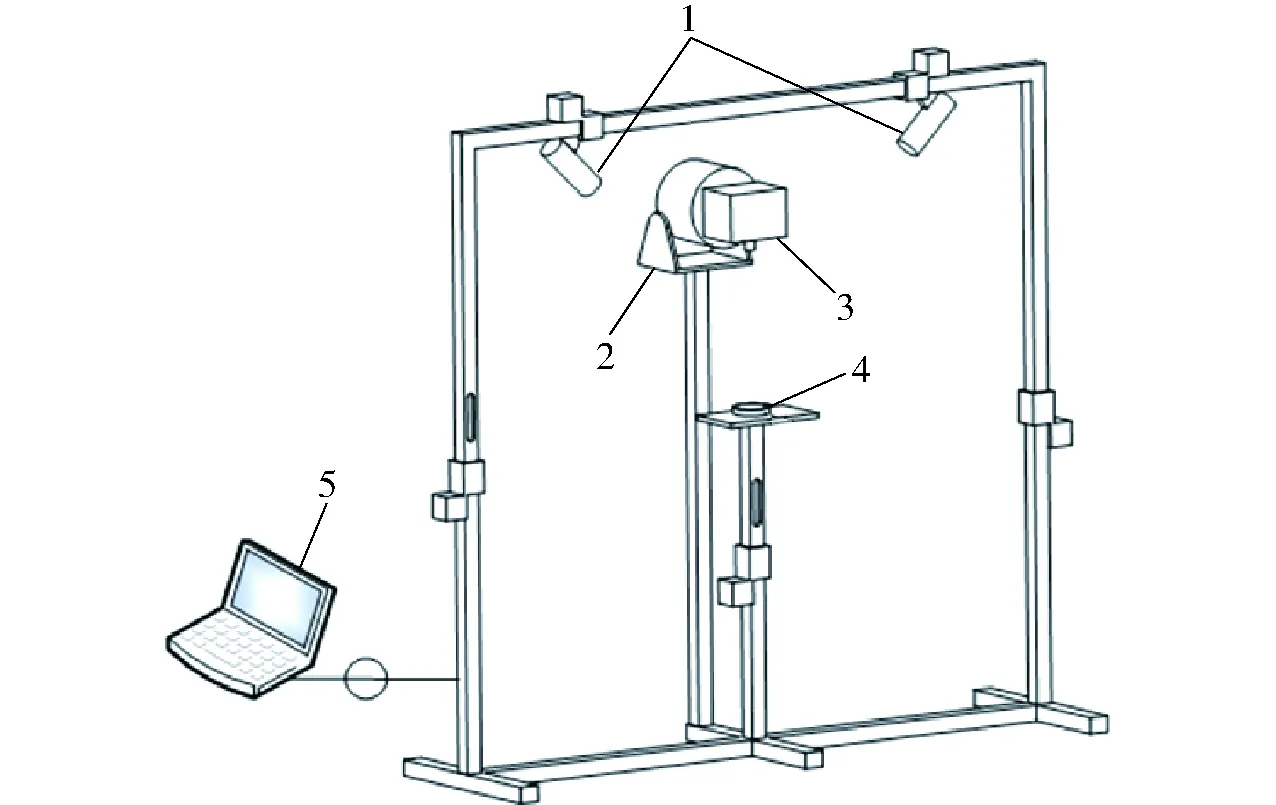
图1 高光谱图像采集系统Fig.1 Hyperspectral image acquisition system1.50 W卤素灯 2.精密云台 3.高光谱相机 4.样本 5.便携式计算机
试验所采用的高光谱图像采集系统如图1所示。采用美国OKSI公司的Hycan1211型高光谱相机,其图像分辨率为1 620像素×2 325像素,光谱分辨率为1.79 nm,波长范围为400~1 000 nm,光谱采集点有339个波段。
拍摄环境封闭,仪器被置于用遮光布搭建的棚中,拍摄时除了光源外无其他任何干扰。同时,为了确保稳定的光源照射强度,每次采集高光谱图像之前将高光谱仪预热30 min,然后在计算机上对配套软件进行参数设置以保证采集到的图像清晰且不失真:扫描角度设置为-10°~10°,扫描速度设置为1.844(°)/s,镜头焦距为60 nm,相机曝光时间为10 ms。图2为利用高光谱仪器采集的高光谱图像样例。
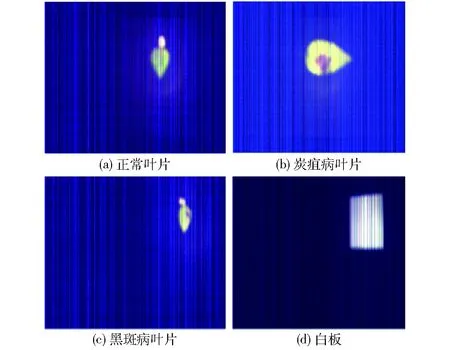
图2 高光谱图像Fig.2 Hyperspectral images
为了减少试验过程中外界自然光、暗箱内照明以及采集系统本身暗电流对高光谱图像质量的影响,需要进行黑白板图像校正。黑白板标定公式为
式中R——校正后图像I——原始图像
W——白板图像B——全黑图像

图3 病害叶片图像样例Fig.3 Sample images of diseased leaves
同时为了进一步从光谱图像上确定对应的病害区域,用相机拍摄发病叶片每天的状态,进行对照,分辨率在70ppi以上。拍摄背景统一使用单一白色,拍摄距离为15~20 cm,图像保存为JPEG格式,采集的图像样例如图3所示。
1.3 高光谱图像信息提取及预处理
1.3.1信息提取
基于ENVI 4.7软件对高光谱图像进行操作,操作过程主要分为2部分:①提取感兴趣区域,获取病害区域与健康叶片的平均光谱反射率,通过光谱反射率曲线从光谱角度找差别并建立模型,从而进行炭疽病、黑斑病与健康叶片的高精度分类。②对所有的图像进行主成分分析,一方面可以对高光谱数据进行数据降维,获取每个感兴趣区域的数据矩阵,另一方面可以通过计算主成分贡献率获取主成分图像与特征波长。
高光谱图像感兴趣区域提取的具体操作:首先,在ENVI 4.7软件中打开需处理的梨叶片高光谱图像(图4a);然后,采用ROI TOOL多边形感兴趣区域选择工具分割出感兴趣区域,如图4b所示,即叶片中形如圆形斑点所示的发病区域;将感兴趣区域的数据保存为.txt文件和.sta文件,.txt和.sta文件中都包括了400~1 000 nm高光谱图像339个波段,曲线中间一条白色曲线即为DN值(像素值)的平均值;用Excel将.sta文件与.txt文件打开,获取到感兴趣区域的相关信息后,通过DN平均值数据,并根据黑白标定公式计算出感兴趣区域的平均光谱反射率;最后,得到有效光谱反射率图。
1.3.2信息预处理
为了提高后期建模效率,使得光谱变化轮廓更加清楚并提高光谱数据的信噪比,需在建模前对提取出的高光谱图像感兴趣区域的平均反射率数据进行预处理。剔除不符合条件的曲线后,获得可供建模的光谱反射曲线共计440条,如图5a所示, 叶片平均光谱反射率如图5b所示。从整个光谱反射率曲线可以观察到,健康叶片、炭疽病叶片与黑斑病叶片的光谱反射曲线整体走势一致,差别在于反射率的大小。
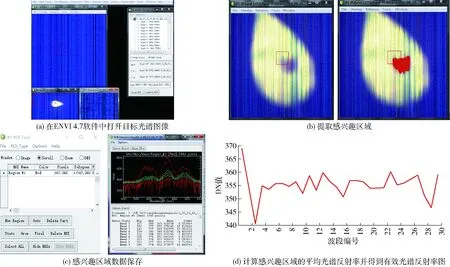
图4 提取感兴趣区域流程图Fig.4 Flow chart of extracting region of interest
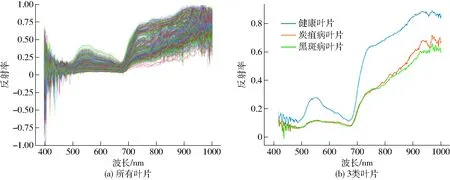
图5 叶片光谱反射率Fig.5 Leaf spectral reflectance diagrams
获得原始曲线后,采用多元散射校正(MSC)、标准正态变换(SNV)和Savitzky-Golay(S-G)卷积平滑法分别对其进行预处理,预处理后反射率见图6。由图6可知,MSC减少了样本之间发生基线偏移或平移现象,最大限度地保留样本中与化学成分相关的光谱吸收信息;S-G法对光谱数据进行平均计算并重新分配误差,对每个数据点进行处理,去除光谱数据中的高频噪声并保留有用的低频信息,不存在波峰与波谷的区别,这样的优点是可以让光谱曲线发生倾斜偏移与线性平移;与MSC算法相比,SNV算法的不同之处在于单独对每个样本的光谱进行校正,并且不需要理想光谱,但是每个波段吸光度均符合正态分布[20]。
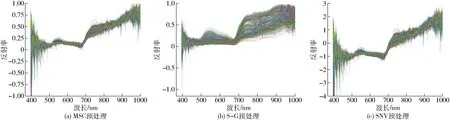
图6 不同算法预处理后所有叶片原始平均光谱反射率Fig.6 Original average spectral reflectance of all leaves after preprocessing by different algorithms
3种方法虽然具体运算过程不同,但都间接提高了原始光谱数据的信噪比及后期的建模效率。其中,基于SNV法的预处理效果最佳。
1.4 特征波长提取
通过高光谱成像技术得到的数据信息量丰富,但冗余信息也相对较多,继而对后期建模效率、模型精度等会产生一系列影响,因此需从原有光谱中提取与样本化学成分相关的波段和波长来进行降维处理。本试验采取的特征提取方法有主成分分析法(PCA)、连续投影算法(SPA)、无信息变量消除法(UVE)、竞争性自适应重加权算法(CARS)和随机蛙跳算法(SFLA)。PCA算法需要选择贡献率大的波长,且要求累计贡献率之和大于85%;SPA算法利用少数几列光谱概括大部分原始光谱的变量信息[21-22];UVE算法可以去除光谱中含有的较多噪声,优选出特征波长;CARS算法不仅可以有效去除无信息变量,而且还可以最大程度地减少共线性变量对模型的影响[23];SFLA算法具有遗传算法和PSO算法的优势,在数据降维中具有重要的作用[24]。
1.5 识别模型建立
1.5.1基于特征波段的支持向量机(SVM)分类识别建模
SVM模型的核心思想是通过找出边际最大的决策边界ωx+b=0,对数据进行分类。本研究中SVM算法选取的核函数为径向基核函数(Radical basis function, RBF)。研究通过调整惩罚参数c及核函数参数g来提升模型的泛化性能,从而使得模型有更好的预测效果。
具体步骤如下:
(1) 选定建模集与测试集
本试验所采集的样本分为两部分:①采集的样本包括炭疽病与黑斑病病害区域的平均光谱反射率,以这部分样本的高光谱数据作为测试集。②所获取的样本经过了从叶片健康状态到发病状态且病斑从小到大的连续动态过程,样本量大,以这部分采集的高光谱数据作为建模集。
(2) 数据归一化预处理
SVM网络训练对建模集与测试集都进行归一化处理,以提高寻找最优解的效率,保证程序在运行时收敛加快。
(3) 参数寻优
本次建模试验以准确率为评价指标,通过十折交叉验证,选取建模效果最优的c和g,有效避免模型欠拟合现象的发生,同时保证了模型的泛化能力。
1.5.2BP神经网络分类识别建模
BP神经网络由输入层、隐含层与输出层组成,各层有若干个节点,层与层之间直接通过权重来连接。核心步骤分为正向传播与反向传播。反向传播依靠学习率η和梯度更新权重。本研究搭建的BP神经网络隐含层设置为1层,激活函数为tanh,输出层的激活函数为softmax。
1.6 模型效果评测
用测试集验证模型在未知样本上的表现,所建的各SVM模型以分类准确率作为评价指标。对各BP模型以分类准确率、召回率、F1值为评价指标进行综合评价。准确率即从模型预测角度出发,表示在预测为i(i=1,2,3)的样本中,预测正确的比率。召回率是从样本的角度出发,表示的是标签为i(i=1,2,3)的样本中,被正确预测的比率。F1值为准确率与召回率的调和平均值。
2 结果与分析
2.1 样本划分
样本的平均光谱反射曲线共440条,分别编号1~440。具体划分结果如表1所示,用标签1、2、3分别代表健康叶片、炭疽病叶片和黑斑病叶片。类别1健康叶片所对应的编号为1~140,建模集曲线100条,测试集曲线40条;类别2炭疽病叶片所对应的编号为141~290,建模集曲线110条,测试集曲线40条;类别3黑斑病叶片所对应的编号为291~440,建模集曲线110条,测试集曲线40条。

表1 砀山酥梨叶片样本光谱划分Tab.1 Spectral division of ‘Dangshan’ pear leaf samples
2.2 梨叶片近红外特征波长提取结果
PCA、SPA、UAE、CARS、SFLA法提取的特征波长如表2所示。
(1)PCA法。对砀山酥梨健康叶片、炭疽病叶片和黑斑病叶片光谱数据求取各变量的标准差并进行标准差变换,然后计算各主成分的累计贡献率,并对加权系数加权平均,经过内部的交叉验证,将339个原始光谱波段压缩为27个主成分。
(2)SPA法。原始光谱数据是一个440×339的光谱矩阵,将最小特征波长数设置为15,任意选择一列向量,计算该列向量在剩余所有列向量上的投影,输出最大投影对应的列向量序号,当均方根误差(RMSECV)最小时,对应的波长即特征波长。
(3)UVE法。经过UVE处理之后,共有15个被认为是有用信息的特征波长。
(4)CARS法。CARS是利用蒙特卡洛方法采样,当程序运行100次时,采样次数为56,从中选择44个样本建立偏最小二乘模型并计算该模型的回归系数的绝对值与各回归系数的权重,当最优变量子集确定的十折交叉验证法均方根误差(RMSECV)最小值等于1.27时,提取的特征波长数有26个。
(5)SFLA法。利用SFLA法可以计算出每个变量被选择的概率,经过之前对梨树叶片光谱数据的分析,本试验中将变量被选择的概率阈值设置为0.8,经过程序运行,提取出的最优特征波长为20个。
5种方法提取的特征波长多集中在400~550 nm间,表明病变叶片内部成分变化较为明显的多集中响应在此波段范围内。

表2 不同算法提取的特征波长Tab.2 Characteristic wavelength selected by different algorithms
2.3 基于特征波长的SVM模型分类结果
各模型分类准确率如表3所示。
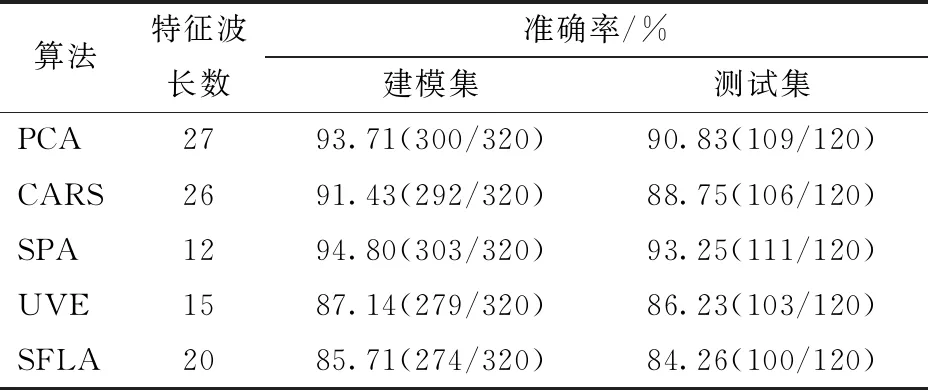
表3 各SVM模型分类预测准确率Tab.3 Prediction results of SVM models
将PCA、CARS、SPA、UVE和SFLA算法所选取的特征波长作为SVM支持向量机的输入变量,本试验中SVM所应用的核函数为RBF,其中参数g与c的最优取值均采用十折交叉验证法实现。参数g即函数自带参数gamma,决定了数据映射到新的特征空间后的分布,gamma值影响支持向量机的数量。参数c即惩罚参数,即对误差的宽容度。因此,PCA-SVM、CARS-SVM、SPA-SVM、UVE-SVM和SFLA-SVM模型中的最优c值均为16,最优g值均为0.062 5。
(1)PCA-SVM测试集的实际分类和预测分类结果见图7a。将这27个特征波长作为输入变量,并对c和g划分网格进行搜索,采用十折交叉验证方法,得到最佳的c值为16,最佳的g值为0.062 5,最佳的RMSECV,即得到的所有分类准确率的平均数为87.925 7。总支持向量数为137,每类样本支持向量数为115,建模集分类识别率为93.71%,测试集样本分类识别率为90.83%,均方根误差为0.205 1,预测效果良好。
(2)SPA-SVM测试集的实际分类和预测分类结果见图7b。最佳的RMSECV为87.735 8。总支持向量数为146,每类样本的支持向量数为123,建模集识别率为94.80%,120个预测样本中正确分类的个数为111,测试集识别率为93.25%,均方根误差为0.154 7。建模集和测试集的识别率均达到了90%以上,说明SPA-SVM具有较好的预测效果。
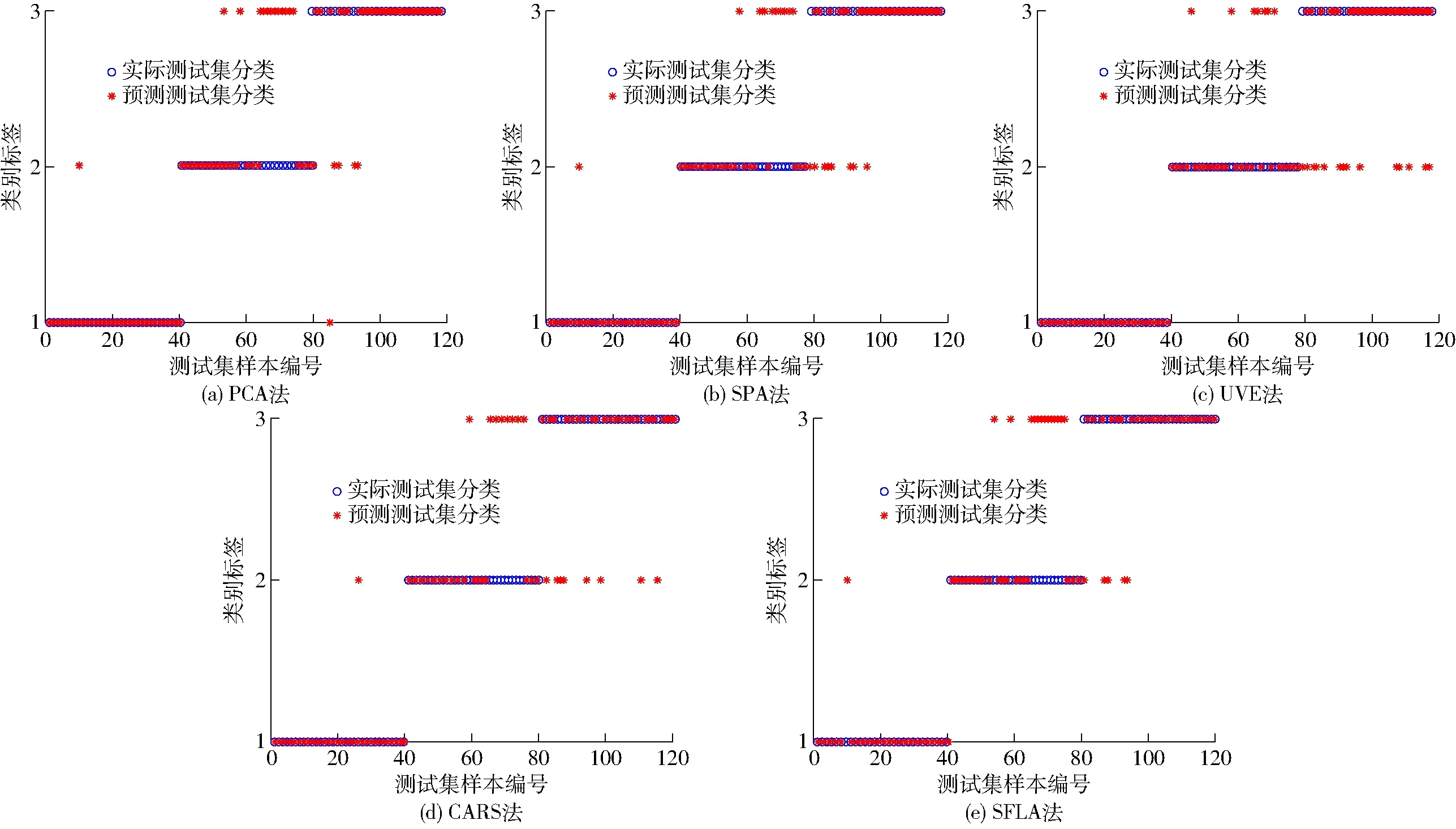
图7 基于不同算法的SVM模型测试集分类结果Fig.7 Classification results of SVM model test set based on different algorithms
(3)UVE-SVM测试集的实际分类和预测分类结果见图7c。得到惩罚参数c为16,核函数参数g为0.062 5,最佳的RMSECV为80.625 0。总支持向量数为236,每类样本的支持向量数为198,建模集分类识别率为87.14%,测试集样本分类识别率为86.23%,均方根误差为1.175 0。与PCA-SVM和SPA-SVM模型相比,UVE-SVM模型的优点在于准确无误地将健康叶片样本识别出来。
(4)CARS-SVM测试集的实际分类和预测分类结果见图7d。得到惩罚参数c为16,核函数参数g为0.062 5,最佳的RMSECV为86.525 6。总支持向量数为155,每类样本支持向量数为129。最终得到的建模集样本分类识别率为87.14%,测试集样本分类识别率为86.23%,均方根误差为0.158 3。
(5)SFLA-SVM测试集的实际分类和预测分类结果见图7e。得到惩罚参数c为16,核函数参数g为0.062 5,最佳的RMSECV为81.25。总支持向量数为238,每类样本支持向量数为203。建模集分类识别率为87.14%。
当实际测试集分类图例与预测测试集分类图例相重合时,分类结果即为正确,反之则说明模型分类错误。通过所有测试集的实际分类与预测分类图发现,SVM支持向量机几乎可以识别所有的正常叶片,分类误差较大的为黑斑病叶片与炭疽病叶片。
2.4 基于特征波长的BP模型分类结果
各模型分类准确率如表4所示。

表4 各BP模型分类预测准确率Tab.4 Prediction results of BP models
(1)PCA-BP测试集的实际分类和预测分类结果见图8a。此模型的学习率为0.1,网络结构为27-20-3(输入层有27个节点,隐藏层有20个节点,输出层有3个节点)。此模型几乎可以识别所有的正常叶片,但在炭疽病识别上,表现能力欠佳,在测试集40个炭疽病叶片样本中,有29片被误判为黑斑病叶片。
(2)SPA-BP测试集的实际分类和预测分类结果见图8b。此模型学习率为0.1,网络结构为12-50-3。SPA-BP建模集准确率为86.88%,为5个模型中最佳,且可以识别所有的正常叶片,误差集中在2处:将16片炭疽病叶误判成黑斑病叶片,将9片黑斑病叶片误判成炭疽病叶片。
(3)UVE-BP测试集的实际分类和预测分类结果见图8c。此模型学习率为0.2,网络结构为15-16-3。UVE-BP在识别正常叶片方面表现出色,38片正常叶片分类正确,仅将2片正常叶片误判为黑斑病叶片。在识别炭疽病叶片方面,UVE-BP 将28片炭疽病叶片判定正确,但将余下12片误判为黑斑病叶片。在黑斑病叶片的识别上,25片被判定正确,只有1片叶片被误判为正常叶片,还有14片叶片被误判为炭疽病叶片。
(4)CARS-BP测试集的实际分类和预测分类结果见图8d。此模型学习率为0.2,网络结构为26-40-3。CARS-BP测试集准确率为79.17%,为5个模型中最高,且识别出了大部分正常叶片,仅有6枚叶片被误判为炭疽病叶片。分类误差较大的集中在炭疽病叶片和黑斑病叶片的识别上,但CARS-BP可识别将近75%的炭疽病叶片,以及80%的黑斑病叶片。
(5)SFLA-BP测试集的实际分类和预测分类结果见图8e。此模型学习率为0.1,网络结构为20-50-3。SFLA-BP几乎可以识别所有的正常叶片,40片正常叶片样本中仅有2片被误判。SFLA-BP识别了75%的炭疽病叶片,余下的叶片样本被误判为黑斑病叶片。然而此模型在黑斑病叶片样本的识别方面误差较大,40个样本中有18片叶片被误判,且大多被误判为炭疽病叶片。
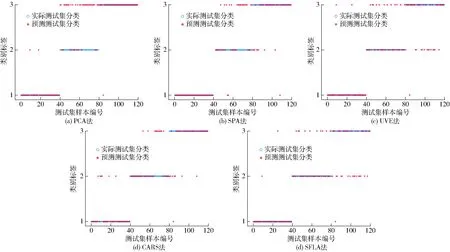
图8 基于不同算法的BP模型测试集分类结果Fig.8 Classification results of BP model test set based on different algorithms
所建的各模型中,健康叶片、炭疽病、黑斑病叶片测试集的分类准确率、召回率、F1值如表5所示,建模集的各评价指标如表6所示。

表5 BP模型测试集分类预测结果Tab.5 Test set classification prediction results of BP models

表6 BP模型建模集分类预测结果Tab.6 Training set classification prediction results of BP models
2.5 模型效果评估对比
在所建的5个SVM模型中,测试集准确率大于85%的模型为SPA-SVM、PCA-SVM、CARS-SVM、UVE-SVM。其中基于SPA算法优选的特征变量建立的SVM模型性能最好,在减少模型变量的同时提高了模型精度。SPA算法将用于建模的特征波长由339个减少到了12个,测试集精度达到了93.25%,且相对于其它模型,SPA-SVM可以准确无误地将健康叶片样本识别出来,表明SPA法较其他4种特征波长提取方法,更大限度地剔除了噪声数据,降低了相关性小的波长的干扰,同时提高了光谱的表现能力。在所建的各BP模型中,建模集准确率最高的模型为SPA-BP模型,准确率为86.88%,测试集准确率最高的模型为CARS-BP模型,准确率为79.17%。综上所述,SPA-SVM模型效果最佳。
经试验发现,所建的10个模型分别能识别大部分的梨炭疽病与黑斑病叶片,但由于2种病叶的表现症状过于相似,导致识别结果存在或多或少的偏差。在实际生产中,可以将模型结果与肉眼观察到的果实发病特征相结合进行对比分析,从而进一步提高2种叶片识别的准确率:梨炭疽病果实表面有褐色的病斑,明显下陷,软腐,中央有大量轮纹状排列隆起的黑色小粒点,即病菌分生孢子盘,且潮湿时呈绯红色黏液形式从中溢出;患有黑斑病的梨果果面通常出现一至数个黑色斑点,略凹陷,随着时间的推移,颜色变浅,形成浅褐至灰褐色圆形病斑,且发病后期病果畸形、龟裂,裂缝可深达果心,果面和裂缝内产生黑霉,并常常引起落果[25-27]。
3 结论
(1)采用近红外高光谱成像技术,获取目标样本的光谱数据,用ENVI 4.7软件提取砀山酥梨病叶的感兴趣区域并进行处理,再用MSC、S-G平滑法、SNV分别对原始图像进行预处理。相较而言,基于SNV法的预处理效果最佳。
(2)基于PCA、SPA、UVE、CARS和SFLA分别提取了27、12、15、26、20条特征波长,5种方法均有效剔除了与建模无相关性或相关性小的波段,提高了信噪比并提升了后期建模精度。
(3)在病害识别模型建立的方法上,一方面,基于特征波长并利用支持向量机进行数据建模,在基于5种方法所建的分类模型中,SPA-SVM模型识别效果最佳,其建模集准确率为94.80%,测试集准确率为93.25%,均方根误差为0.154 7。另一方面,BP神经网络是完全不同于SVM的识别分类方式,CARS-BP模型的测试集准确率最高(79.17%)。结果表明,近红外高光谱技术可以较好地应用在梨炭疽病和黑斑病叶片的识别检测中,且利用高光谱技术可以为识别砀山酥梨叶片黑斑病与炭疽病提供在线技术支持与理论依据。
(4)由于梨炭疽病叶片和黑斑病叶片内部物质元素的变化,借助近红外高光谱技术,2种病叶能在相应波段呈现出不同的特点,因此2种病叶能被区分开,叶片识别率较人工分辨显著提高,大大改善了凭肉眼难以区分2种病叶的问题。
