高校图书馆查收查引中他引区分策略研究与实现
2022-03-13吴帼帼

摘 要 图书馆的查收查引服务,有助于学者及其单位客观认识自身科研成果产出和学术发展。论文结合查收查引工作实践,从数据、算法、交互3个层面分析构建了他引区分策略,并对其进行系统实现。通过随机抽取样本报告做对比验证,实验得出该策略在时间效率和操作便捷性上更具优势,最后针对影响因素进行探讨,希望为学者唯一身份标识领域的研究提供思路参考。
关键词 高校图书馆;查收查引;他引;姓名消歧;Python
分类号 G258.6
DOI 10.16810/j.cnki.1672-514X.2022.02.004
Abstract The search and citation service of the library helps scholars and their units to objectively understand the output of their own scientific research results and academic development. Combining the work practice of checking, receiving and citation, the article analyzes and constructs a different citation strategy from three levels of data, algorithm and interaction, and implements it systematically. Through a random sample report for comparative verification and analysis, this strategy has advantages in time efficiency and operational convenience, and the influencing factors are discussed, which hopes to provide a reference for scholars’ research in the field of unique identification.
Keywords University library. Search for citations. Other citations. Name disambiguation. Python.
0 引言
查收查引服务是指根据用户需求在国内外权威数据库中检索学术文献被收录和被引用的情况。查收查引服务作为图书馆情报分析中的重要工作,最早可追溯到20世纪80年代。定量分析方法在科研绩效分析评价中的广泛使用[1],使得查收查引服务在图书馆参考咨询服务中逐渐开展和普及而来。苏秋侠通过对“985工程”高校网站数据实证调研发现,38所高校图书馆网站均设置了“查收查引”栏目[2]。在查收查引服务中,除了关注自引文献情况,了解学者的研究方向,其中进行他引的区分有助于学校、科研单位、学者个人更为客观、全面地了解自身科研学术成果。本文从目前高校图书馆的查收查引服务中他引区分实践出发,分析目前图书情报界常用的他引区分中学者唯一身份标识问题的评判依据和区分算法,系统性地构建了算法复杂度为O(n)的他引区分策略,并以Web of Science数据库为例进行他引区分系统实现,验证该他引区分策略的可行性。
1 查收查引业务研究及他引区分问题
随着我国学术科研事业的蓬勃发展,查收查引需求量愈来愈大,促使各图书馆尤其是高校圖书馆逐步将查收查引业务从参考咨询中独立出来,形成查新站、信息服务中心等专职部门进行学术文献的收录和引用报告的开具。业务最初多为人工查收查引,包含十余个步骤,随着信息化时代的发展,查收查引工作逐步向业务半自动化、流程自动化转变。业务半自动化实现主要依靠机器辅助检索,樊亚芳提出利用文献管理工具去重、统计总他引次数[3],这里CALIS技术中心与北京大学图书馆开发的论文收录与引用检索系统具有代表性[4]。查收引证工作流程自动化方面的代表有山东大学阚洪海基于水晶报表研发的查收引证报告自动生成系统[5]。2011年底中国科学院软件研究所研发了“引证报告自动生成原型系统”,王学勤在该原型系统基础上实现数据预处理、增加检索数据源等功能模块优化[6],李桂影提出使用Web of ScienceTM新平台精炼检索结果去除自引[7],北京邮电大学严潮斌提出查收引证服务融入机构知识库[8],但目前机构库多采用接口或数据抓取等方式获取文献源数据,这两种方式均获取不到作者识别号字段,存在元数据缺失现象。
查收查引业务中的他引区分究其根本,与学术界姓名消歧(即Author Name Disambiguation)为同族问题。沈喆等对2016至2020年姓名消歧相关研究归纳梳理发现在特征表示上网络表示学习、异构网络元路径以及概率模型受到研究者的青睐,模型仍以机器学习为主,集中于优化聚类算法效率,并指出相关研究在模型推广和时间复杂度上存在问题,模型推广上目前实证研究多基于如AMIner、DBLP等仅涵盖计算机信息科学的研究成果的数据库,应用于大型综合数据集合如Web of Science的相关研究较少;在时间复杂度上,目前相关研究中用到的聚类算法在增量消歧中时间复杂度较优的为O(n)[9]。目前他引区业务通过系统区分的代表有CALI查收查引、机构知识库[10]。但系统获取数据库的数据多为接口实现,会出现部分字段如作者识别号、地址等字段缺失现象进而影响区分;另外,其判别标准都是对姓名、姓名别称的判断,这就导致判断的准确率不高,部分结果仍然需要科研人员人工干预再次核对。汤森路透(http://thomsonreuters.com/)推出的ResearcherID和ORCID (open researcher and contributor ID) 两者均可解决学术研究中的研究者姓名混淆的问题。ORCID着重于作者的标识[11],ResearcherID着重于作者学术科研产出展示与分析,ResearcherID 旨在将作者与其学术作品紧密结合[12]。最受业界推崇的根本解决方法仍为建立researchID和ORCID的统一身份标识体系。但目前国内学者作者标识意识不高,很少有学者发文标注作者ResearcherID或ORCID,且作者识别号申请机制并未严格控制,存在一个学者对应多个作者识别号的现象。
2 他引区分策略研究
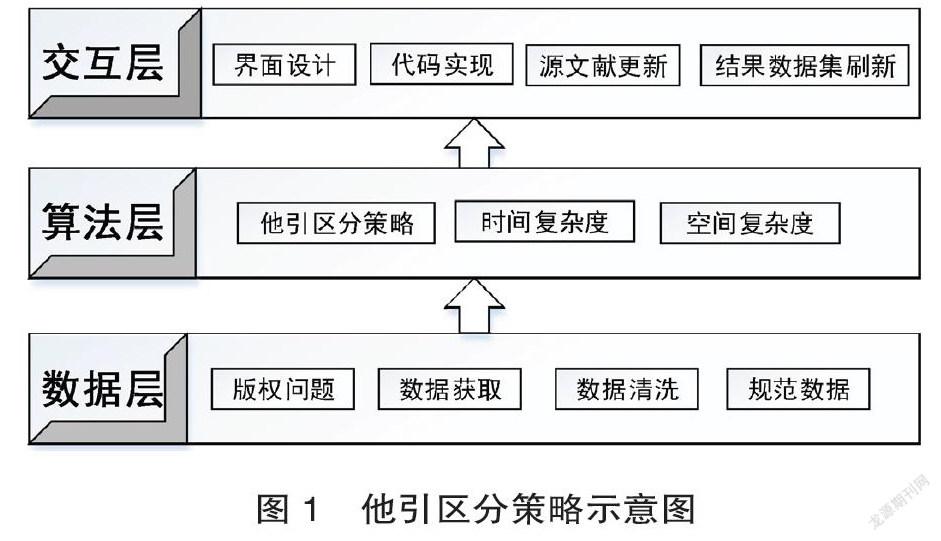
为解决数据接口获取数据库元数据字段缺失问题,使他引区分数据获取更加规范、数据质量有所保证,区分流程更加优化,确保区分结果准确率的同时提升人工他引区分效率,本研究通过梳理分析查收查引服务中他引区分工作实践,构建他引区分策略,如图1所示。
2.1 数据层
在数据层首先要考虑知识产权的保护及版权问题,目前我国公共文化机构中与版权有关的数据库资源主要包含开放存取数据库、自建数据库、商业数据库[13],学术评价中涉及到的主要为商业数据库。目前对于商业数据库的版权保护,主要依赖于图书馆与数据库商签署的采购合同中的规定,为有效规避版权问题,本他引区分策略的数据层的相关操作中不对商业数据库资源进行抓取,采用比较保守的方式。源数据获取在已购买可访问商业数据库的网络环境下进行,由于商业数据库平台在数据注入、数据加工上存在疏漏,需要对源数据(即施引文献、被引文献记录信息)进行清洗,去除“脏数据”和“噪音数据”,得到包含用于他引区分的关键字段的“数据范式”,得到规范化的数据字段。
2.2 算法层
在算法层需要考虑他引区分算法、算法的时间复杂度及空间复杂度。算法执行的效率度量方法分为事后分析法和事前分析评估方法[14]。事后分析法是设计好测试程序和数据,利用计时器记录不同算法编写的程序运行时间,通过比较进而得到算法效率的高低。事前分析估算方法是在编写程序之前,依据统计方法对算法进行估算。在进行算法的分析时主要针对算法的时间复杂度和和空间复杂度。时间复杂度用来度量算法运行需要的时间,空间复杂度是指算法所需的存储空间需求。算法时间复杂度是时间度量,渐近时间复杂度T(n)=O(f(n))简称为时间复杂度,记作:T(n)= O(f(n)),它表示随问题规模n的增大,渐近时间复杂度T(n)=O(f(n))简称为时间复杂度,算法执行时间的增长率和f(n)的增长率相同,其中f(n)是问题规模n的某个函数[15]。随着输入规模n的增大,T(n)增长最慢的算法为最优算法。在他引区分算法的设计中应充分考虑循环、递归等函数对于算法执行效率、算法时间复杂度、空间复杂度的影响,注意结合实践经验,在保证结果准确度的基础上,对算法进行优化。
2.3 交互层
交互层是在算法层的基础上,结合数据层处理后得到的规范化數据,通过编写代码对他引区分算法进行实现,进而得到操作流程清晰规范的完整他引区分系统。首先在界面的设计上应充分考虑“交互设计七大定律”[16],依据“Occams Razor”奥卡姆剃刀原理和HICKS law ,精减实体数量保证功能设计中尽量简单,在满足功能的基础上给用户最少的选择,实际使用中交互选择时间就会缩短,从而提高交互效率和信息产出。1956 年乔治米勒对短时记忆能力定量研究发现人类头脑最好的状态为记忆7(±2)项信息块,所以在交互界面设计上设置5~9个信息块即可。关于信息块在页面布局上依“The Law of Proximity”接近原则设计,非交互信息设置为不可编辑或灰色色块。数据结果集的刷新采用Reload重载函数代码实现,刷新后的结果集前台展示。
3 源数据获取与处理
3.1 数据获取与处理工具选择
对所构建的他引区分策略进行验证主要采用WOS(Web of Science)平台数据,它是情报分析工作中查收引证工作重要依托平台[17]。在数据的处理上,除WOS平台自带的数据导出功能,还使用到了noteExpress文献管理工具软件。NoteExpress核心功能包含数据收集、管理、分析、发现和写作等[18],可为整个科研流程中高效利用电子资源提供帮助:检索并管理得到的文献摘要、全文;在撰写学术论文、专著或报告时在正文指定位置便捷地添加笔记;按照不同格式要求自动生成参考文献。同时还可以通过自定义样式导出题录的样式,进行简单的数据规范化处理。
选择WOS导出与noteExpress软件相结合使用的原因主要为:初期采用Python编写程序直接进行数据的规范化处理,但后来发现当检索员采用不同浏览器或选择浏览器的兼容/IE不同模式,以及当WOS版本更新后,从WOS端导出的txt文件中的内容格式会发生变化,相对应的需要进行代码的修改。由此可见,使用代码实现数据规范化处理,存在一定的局限性。相对应地,noteExpress能很好地解决这两方面的问题。
3.2 数据规范化处理操作说明
数据的规范化处理主要包含作者姓名地址数据对、作者识别号两部分基准数据清洗和规范化。因施引文献的时间发生在被引文献刊出后,所以可以同时对被引、施引文献进行数据规范化处理。
作者姓名地址数据的处理方法为:在WOS平台中首先检索出被引文献以及其在WOS核心合集中的施引文献,勾选后添加至“标记结果列表”后按照日期顺序排列。而后选择“其他文件格式”后以“其他参考文献软件、全记录”方式导出txt文本格式文件,一般默认文件名称为savedrecs.txt。之后在noteExpress中选择“导入题录”,设置题录来源为来自文件,过滤器对应选择noteExpress自带的Web of Science过滤器。导入后重点核对列表文献与在WOS网页端的页面中文献是否一致,如有缺少作者、地址等信息的进行手工补充,如果已知作者其他姓名写法、地址其他写法、其他地址等信息也可进行补充完善,对源数据进行扩展完善。然后在noteExpress导出题录页导出文献题录,此处需要“自定义样式”设置提出题录模板,导出含有“作者姓名、地址、获取号”的被引文献nebase.txt以及施引文献列表nelist.txt文本文件。需特别注意在导出题录时应选择UTF-8编码格式,否则会影响后期他引区分。最后使用Python编写程序处理得到形如{文献序号1:作者A-该作者地址集;作者B-该作者地址集……作者N-该作者地址集}规范化数据。
与此同时,作者识别号字段在noteExpress处理时会出现缺失。所以仍需采用WOS平台自带的“打印”功能另存为txt格式文件,通过编写Python代码读取文本文件进行数据处理,数据抽取出被引、施引文献中各篇文献的作者识别号数据,形成“文献序号—作者识别号”数据对作为二维数组进而做比对分析。
4 算法设计及其复杂度分析
4.1 算法设计
他引区分是以被引文献中的作者姓名、地址、作者识别号等唯一身份标识信息为判定依据。在对施引文献集合中的文献逐条进行辨别的过程中,通过比较可得到每一条作者自引或是他引的“施引文献”记录,从而得到被引文献的他引文献结果集。
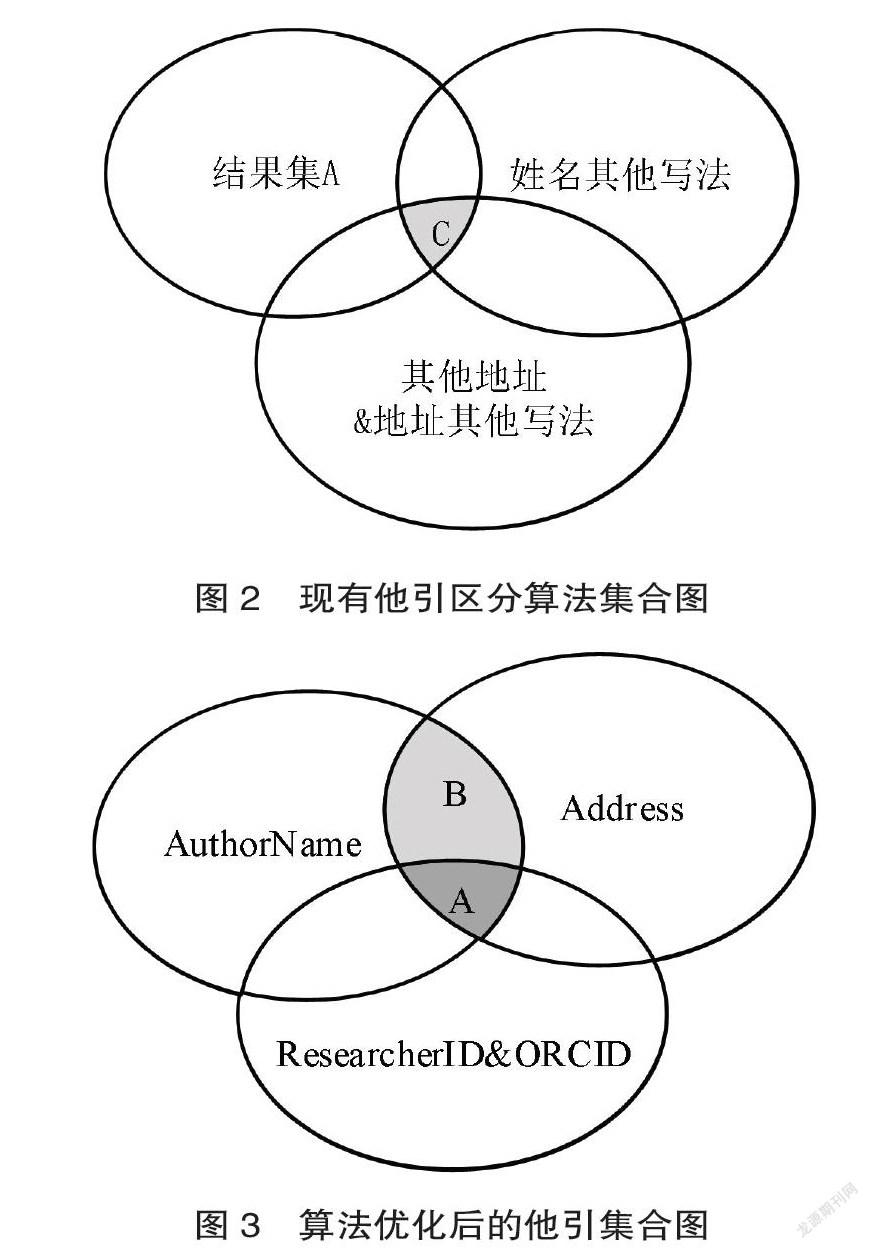
在他引区分算法的设计上,考虑到目前人工区分自引/他引大多是根据作者姓名判定,当出现重名现象时往往通过判定作者地址是否相同,在ResearcherID&ORCID属性不为空时,有经验的检索员也会将其作为判定依据。从现有他引区分算法集合图2中可以看出AuthorName+address判定出的结果集比AuthorName结果集要精确很多,AuthorName+address+ResearcherID&ORCID判定出的结果集A又比单姓名、地址、ResearcherID&ORCID的结果更加精准。与此同时,目前存在作者姓名简写、姓名写法不规范、作者地址变更、同一地址写法多样等问题,所以我们考虑在结果集A的基础上加上姓名其他写法、作者其他地址、作者地址其他写法等判定依据,从优化后的他引区分算法集合图3可以看出结果集A+姓名其他写法+其他地址&地址其他写法得到的数据集C是判断依据最为全面、结果最为精确的结果集。
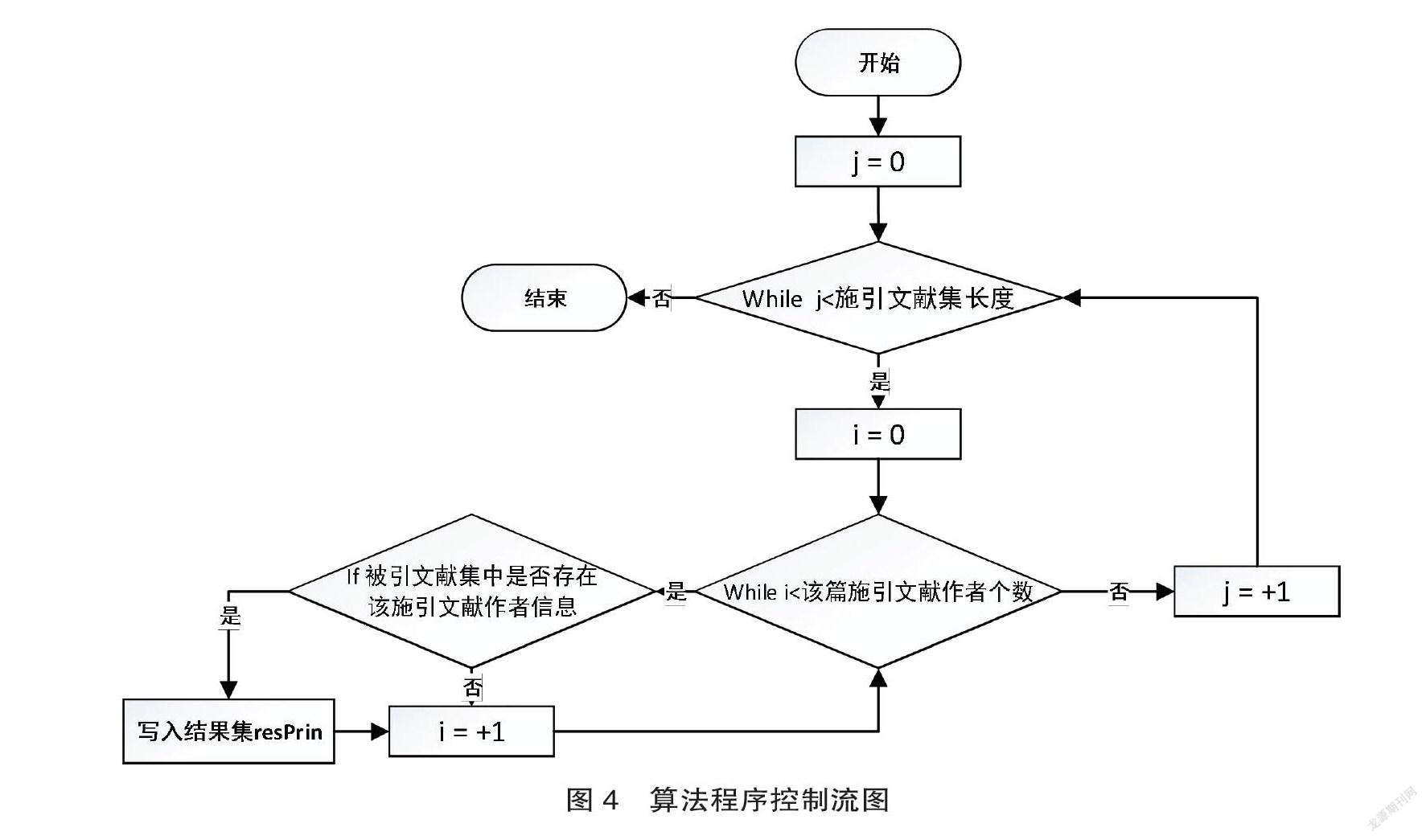
相对应地,该他引用区分算法程序控制流图如图4所示。
4.2 算法复杂度分析
在进行算法分析时,语句总执行次数T(n)是关于问题规模的N的函数,通过推导大O阶方法分析算法的时间复杂度进而推导语句总执行次数T(n)的数量级。算法伪代码为:
resPrin = [];j =0; /* resPrin[ ]为他引结果集 */
while j< len(egData): /* EgData 为施引文献的二维数
组[[][][][]……]*/
test = egData[j]
i = 0;
while i <len(test): /*遍歷施引文献集合
中的作者集数组*/
if egSors.find(test[i]) != -1: /* EgSors 为被引文献的
一维数组[……]*/
if j+1 not in resPrin: /*得到他引区分结
果,写入结果集数组*/
resPrin.append(j+1)
i += 1
j +=1
根据算法导论中算法复杂度计算方法得出该算法的时间复杂度主要取决于施引文献的文献数目、以及施引文献中含有作者数目。时间复杂度为:
(其中施引文献为二维数组,m表示该施引文献长度, n 表示施引文献中每篇文献中作者数组的长度。)
5 系统设计与实现
5.1 技术路线选择
该他引区分系统实现采用C/S架构,使用Python语言编写算法实现数据分析和处理,依照不同依据分别区分出他引文献序号列表并前台输出展示。C/S架构即为客户端/服务器(Client/Serve)模式,该架构更少依赖网络传输且更为稳定。Python是一种动态的、面向对象的脚本语言,相比于Java、C语言等计算机程序设计语言,Python可以以很少的代码高效完成任务。著名的网站包括YouTube就是Python写的,Google也在大量使用Python进行开发,github上基于Python研究实践越来越多。使用Python开发完成后通过Pyinstaller打包发布Windows平台、MacOS平台的可执行文件,可满足跨平台使用需求。与此同时,考虑到Web of Science数据库版权问题本研究实践并未进行数据抓取。本研究实践中的实验环境配置为:浏览器采用Internet Explorer11,实验阶段Web of Science[V5.31],开发语言Python为3.6.3版本。
5.2 系统实现
他引区分算法主要依据作者姓名地址、作者识别号等特征信息进行判定,均使用Python编写代码实现。
姓名地址依据下的他引区分实现方法为:首先基于Python的re函数库分别读取noteExpress处理后的被引文献/施引文献对应的文本文件,获取作者地址数据后通过数据处理程序得到规范化数据对集合,即需字符串转数组、数组拆分、字符串拼接、字符串转数组、去空、循环嵌套等程序操作进行数据规范化处理。
作者识别号依据下的他引区分实现方法为:首先读取被引文献文本文件,无“作者识别号”字段则被引文献作者识别号缺失,无需进行作者识别号的依据的判断,在结果页打印“源文献无作者识别号信息”即可;当被引文献存在作者识别号字段的情况下,再读取被引文献文本文件。由于不是每篇施引文献都有作者识别号信息,所以该部分数据处理时根据文本文献结构特点,首先判断“入藏号”与“作者识别号”是否存在,当两者均存在时则截取该条记录的作者识别号信息存入施引文献数组,若不存在“作者识别号”则说明该条记录下的施引文献无该字段,需向施引文献数组中添加一条空记录。最后通过程序对比被引文献、施引文献数组中每篇论文的作者识别号数据集合即可得到以作者识别号ResearcherID&ORCID为判定依据的他引区分结果集。由于考虑到目前作者识别号的使用并不是很广泛,所以将其单独实现并展示结果集,将来随着作者识别号的推广范围增加、作者使用识别号的意识逐步提高,即可单独使用该部分功能区分。
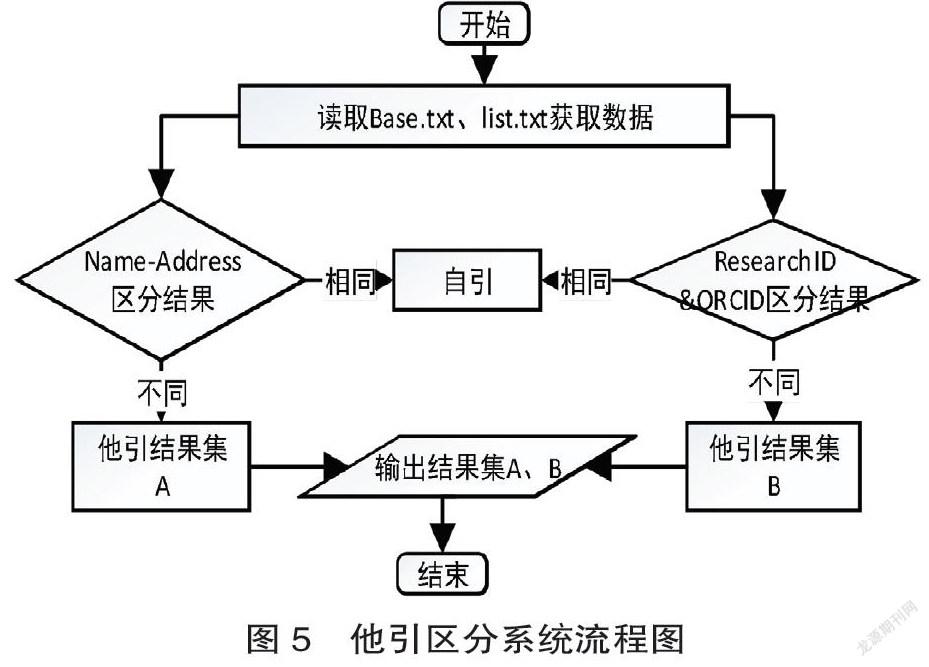
在交互层的实现上他引区分系统整体流程设计如图5所示。首先读取被引文献文件、施引文献列表文件;然后分别以为作者识别号、作者姓名地址为依据进行判定得出对应的结果集;最后同时输出两个结果集合供检索员参考。在界面实现上,首先基于Python的tkinter工具进行展示界面绘制、然后通过函数调用方法分别运行区分功能得到作者识别号、姓名地址的依据下区分的结果集的可视化展示。当更换被引文献、施引文献后点击“重新载入”按钮触发后台Reload方法刷新程序得到对应的结果集。
至此该他引区分系统已经完成,通过Pyinstaller打包发布后即可应用于实际查收查引相关工作中。
6 同源数据集对比验证分析及不足
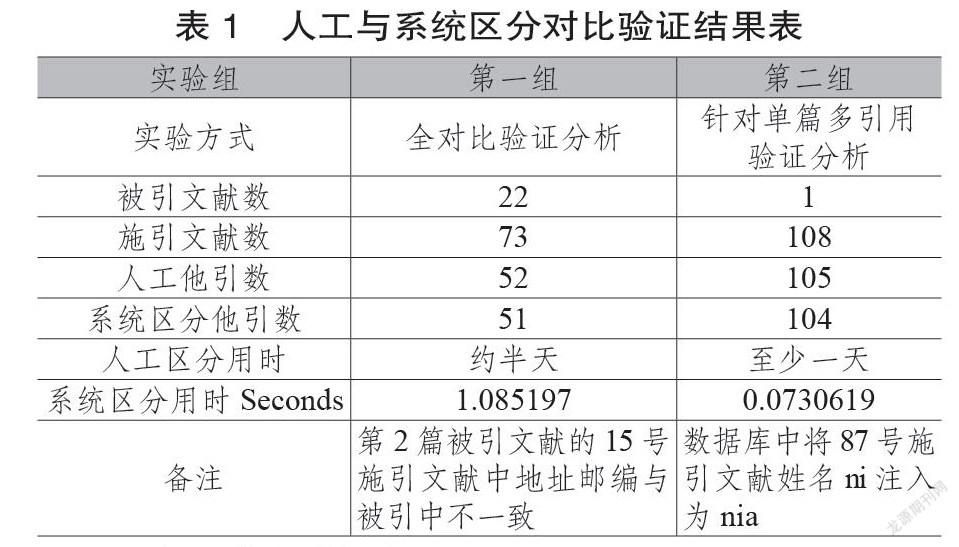
为验证他引区分系统的可行性、准确性,随机选取两位检索员的检索引证报告,与本他引区分系统结果集进行对比分析。他引数据截至2020年8月30日。第一组报告中包含22篇被引文献,其中施引文献数超过2篇的有9篇,由于区分效率受被引/施引文献中作者数目、被引文献篇数影响,所以针对第一组报告进行全对比分析。与此同时,针对存在施引文献较多或作者信息较多的情况,在第二组报告中选取多于50篇施引文献的文献进行重点对比分析,着重分析其结果可靠性以及时间效率。两组实验对比分析的结果如表1所示。第一组验证分析中的基准数据为检索员A 完成的引证报告,其中包含22篇被引文献,73篇施引文献共计52次他引,人工区分用时约半天。
6.1 对比分析结果
(1)通过他引区分系统的WOS中的ResearchID&ORCID作者识别号以及作者姓名地址数据对为判定依据得到的施引文献列表中的自引文献序号基本覆盖人工区分出的自引序号。
(2)时间效率上,系统区分时间均在1秒以内,且算法程序的运行时间是相对稳定的,所以程序区分在时间效率上较人工区分具备时间优势。第二组验证分析中单篇文献的施引文献最多为108篇,时间效率上,系统区分他引用时仍在1秒以内,说明算法程序时间、空间复杂度是可以接受且受文献数目影响较小的。
(3)结果准确性上,22篇文献中除一篇施引文献因施引文献中的地址属性与被引文献中的路段信息不符,导致未识别出为自引文献外,其他结果均与人工区分结果一致。
(4)操作便捷性上,人工区分需要多次对比被引/施引文献中的姓名、地址、识别号等字段详细信息,人脑每次可记忆的作者姓名数目、姓名地址数据对信息是相对固定的,而每篇文献作者数目不定,像是药学、物理学等合作研究者较多的作者数目可能上百个。相对应地,程序处理信息单元的优势就突显出来,只需导入被引/施引文献,即可生成结果集合,操作更为便捷。
综合两组实验数据分析可以发现,系统区分在时间效率以及操作便捷性上具有较为明显的优势,但是受文献地址信息以及数据库注入错误等问题的影响,他引区分结果集会出现小部分偏差,其中姓名拼写问题的数据库注入错误影响较大且不易避开。与此同时,检索员反馈较多的姓名缩写、简写、姓名顺序写法等问题,由于区分策略中采用的为地址信息中的作者姓名,所以姓名写法问题的影响并不是很大。其次,本数据验证对比分析是针对Web of Science大型综合类数据库展开的,由于未对数据源进行数据抓取,而是完全遵照查收查引实际工作流程展开的,所以数据集不会受到数据库接口的影响,相对更为稳定,且网站端前台展示的元数据信息也更为完善,更加贴合查收查引工作实际需求。一方面结合邮箱、地址等特征信息进行算法区分,与此同时借助在noteExpress进行数据规范化处理时,可进行必要且准确的人工干预,该人工干预是检索员与作者本人为查收引证报告开具的,相较于等待科研学者自主在系统内消歧,其参与主动性和积极性更强,且在检索员的专业指导和判定下人工干预结果更为真实可靠。
6.2 验证分析中发现的不足及改进方法
针对地址信息中缺失路段信息、同一作者同一地址投稿时写的邮编不一致等情况,下一步可以考虑将地址字段拆分为细粒度,即像是地址中的国家、省、市、区、路段、邮编等,检索员可自行设置匹配度,目前系统相当于是精确匹配即匹配度100%时认定为同一个作者,设置颗粒度后可模糊区分在作者姓名匹配的前提下,地址信息字段低层级信息像是邮编、路段等信息不匹配情况。与此同时,针对作者姓名、地址等存在多地址或者多姓名写法的问题,现为检索员在noteExpress中核实后手工添加。下一步可考虑通过自学习算法建立学者信息库,将每次开具引证报告中自己可提供的或查引中积累的该作者多地址,建立数据集合。这样可以减少在noteExpress中完善作者写法、多地址信息的操作步骤,随着系统使用时间积累和数据集数据的不断增加,可进一步提高区分结果的精准度。
参考文献:
朱玉奴. 查收查引用户需求及高质量服务策略研究[J]. 情报探索, 2019(4): 65-70.
苏秋侠. 智慧图书馆背景下查收查引服务探析:基于“985工程”高校图书馆网站的调查[J]. 图书馆学研究, 2019(24): 61-68.
樊亚芳.利用文献管理软件提高论文查收查引工作效率的实践与应用[J].高校图书馆工作,2017,37(2):63-66.
马芳珍,李峰,季梵,等.对CALIS查收查引系统的测试和应用效果评价[J].大学图书馆学报,2016,34(2):97-102.
阚洪海,赵杰.基于水晶报表的查收查引报告自动生成的设计与实现[J].现代情报,2017,37(4):129-133.
王学勤,郝丹,郑菲,等.“查收查引报告自动生成系统”应用实践研究[J].图书情报工作,2014,58(16):131-137.
李桂影.基于Web of ScienceTM新平台的查收查引技巧分析[J].图书馆学刊,2015,37(11):62-64.
严潮斌,陈嘉勇,侯瑞芳,等.查收查引服務支撑需求驱动下的高校机构知识库建设[J].现代图书情报技术,2015(5):94-100.
沈喆,王毅,姚毅凡,等.面向学术文献的作者名消歧方法研究综述[J].数据分析与知识发现,2020,4(8):15-27.
张旺强,祝忠明,李雅梅,等.机构知识库作者名自动消歧框架设计与实践[J].数据分析与知识发现,2019,3(6):92-98.
吴飞盈,季魏红,谢浩煌,等.“互联网+”时代ORCID在学术期刊审稿专家管理中的应用[J].编辑学报,2018,30(4):399-401.
窦天芳,张成昱,张蓓,等.ResearcherID现状分析及应用启发[J].图书情报工作,2014,58(4):40-45.
高峰.公共数字文化资源整合中的数据库版权问题[J].图书馆,2015(9):11-16.
CORMEN T H.算法导论[M]. 北京:机械工业出版社,2013:13-15.
徐雅静.数据结构与算法[M]北京:北京邮电大学出版社,2019:48-53.
交互式设计七大定律 [EB/OL].(2018-11-20)[2021-01-21]. https://www.jianshu.com/p/5bca0d91f802.
伦志军,张见影,安力彬.Web of Science数据库及检索方法[J].现代情报,2004(8):135-136.
盘俊春.撰写和管理论文的实用辅助工具:NoteExpress[J].中国信息技术教育,2019(20):68-70.
吴帼帼 山东大学图书馆馆员。 山东济南,250100。
(收稿日期:2021-03-26 编校:陈安琪,刘 明)
3159500338210
