基于SNN 神经元重分布的NEST 仿真器性能优化
2022-03-12刘家航郁龚健李佩琦柴志雷陈闻杰
刘家航,郁龚健,李佩琦,华 夏,柴志雷,2,陈闻杰
(1.江南大学 人工智能与计算机学院,江苏 无锡 214122;2.江苏省模式识别与计算智能工程实验室,江苏 无锡 214122;3.华东师范大学软硬件协同设计技术与应用教育部工程研究中心,上海 200062)
0 概述
深度学习在数据挖掘、自然语言处理、语音处理、文本分类等诸多领域都取得了突出的成果,但其存在需要海量标注数据、通用智能水平弱等局限性[1],难以成为解决人工智能问题的终极手段。人类大脑是由约1011个神经元、1015个突触构成的复杂的生物体,具有很高的智能水平,但功耗只有25 W左右[2],其计算模式值得借鉴。目前,出现了越来越多的大脑神经计算科学的研究工作,以期通过解析人类大脑工作机理、发展类脑计算来克服现有深度学习的不足[3]。类脑计算的基础是脉冲神经网络(Spiking Neural Network,SNN),与传统的深度神经网络(Deep Neural Network,DNN)相比,SNN 的工作机理更接近于生物大脑。
大脑规模所需的计算资源远超单个计算节点或芯片的功能[4],因此,为了获得最佳的计算能力,构建大规模集群形成分布式计算平台成为当前主流[5-7]。然而随着计算节点的增多,通信时间所占比例越来越大,有效计算的比例逐渐下降,导致SNN的计算效率下降。
针对通信的优化,压缩、打包尖峰数据等[8-10]传统方法只关注对通信的脉冲数据进行优化,局限性较大。在神经元映射对通信的影响方面,CARLOS等提出HP-NBX 方法[11],利用超图分区和动态稀疏交换减少进程之间的连接,从而提高通信平衡性,优化通信过程。URGESE 等提出SNN-PP方法[12],在SpiNNaker 中使用谱聚类算法将神经元分组成亚群,使亚群中紧密相连的组保持在同一个计算节点(进程)中,目的是最小化相互的连接并保持高度连接的组件相互靠近。BALAJI 等提出SpiNeCluster 方法[13],根据尖峰信息将SNN 划分为局部和全局突触,最大限度减少共享互连上的尖峰数量。XIANG等提出一种基于跨层的神经映射方法[14],将属于相邻层的突触连接神经元映射到同一片上网络节点,同时为适应各种输入模式,还考虑输入尖峰率并重新映射神经元以提高映射效率。
针对大规模分布式类脑计算的仿真,NEST 仿真器是一款主流的类脑模拟器开源软件[15]。NEST 仿真器可以模拟任何规模的脉冲神经网络,并且支持集成式的MPI、OpenMP 通信协议,其通过分布式计算大幅提高了仿真速度。NEST 的通信机制采用“缓冲区动态相等”的方法,各节点无需通信,直接动态保持发送缓冲区相等。
虽然NEST 对通信时间进行了一定程度的优化,但是由于缓冲区互相无交流,使得通信数据量持续增加,因此其在能耗方面表现较差。针对这一问题,本文提出基于SNN 子图跨节点优化的神经元重分布算法ReLOC,通过分析SNN 模型中神经元之间联系的紧密性,减少神经元到其他节点的连接,并以稀疏交换思想对NEST 本身的通信机制进行改进,利用其稀疏性提高通信效率。
1 研究背景与相关工作
1.1 脉冲神经网络
脉冲神经网络(SNN)被誉为第三代人工神经网络[16],其模拟神经元更加接近实际,并且把时间的影响也考虑在内。脉冲神经网络中的神经元不是在每一次迭代中都被激活,而是在其膜电位达到某一个特定值时才被激活。当一个神经元被激活时,它会产生一个信号传递给其他神经元,并改变其膜电位。
神经科学家通常用SNN 评估理论和实验结果[17-18]。SNN 仿真分为2 个阶段:计算和交换。计算阶段包括基于偏微分方程更新神经元模型;交换阶段将神经元产生的脉冲发送到其突触后神经元处。在分布式系统中,交换涉及到进程间通信过程,而节点规模越大,通信所占的比例就越大。
1.2 NEST 仿真器
NEST 是一款应用广泛的SNN 模型仿真器,其大规模分布式计算特性非常适合用来作为SNN 负载表征的模拟器工具。本节介绍NEST 的仿真架构、并行分配和通信机制。
1.2.1 NEST 仿真架构
图1 展示了NEST 的运行过程。首先使用Create在各个节点上创建神经元;然后Connect 连接神经元,创建突触;最后Simulate 进行仿真,此过程分为三步,即更新所有神经元变量(Update)、将产生的脉冲发送出去(Communicate)以及更新本地突触变量(Deliver)。

图1 NEST 运行流程Fig.1 Procedure of NEST operation
1.2.2 NEST 并行架构和神经元分配
NEST 并行架构采用支持MPI 节点间通信和OPENMP 线程通信,并使用虚拟进程(Virtual Process,VP)的概念来统一管理并行系统,虚拟进程数量NVP由进程数量P和线程数量T决定,NVP=P×T。
神经元分配采用基于VP 的循环分配,使得神经元在各个节点上均匀分布。如图2 所示,其中:Sg 代表spike-generator 脉冲激发器,此设备在VP 上是完整创建的;Iaf 代表神经元,是基于虚拟进程的分配。由于这种分配方式不可避免地将联系紧密的神经元分配到不同的节点,导致通信消耗增大,因此神经元分配对于通信的改进是必要的。

图2 NEST 并行架构和神经元分配方式Fig.2 Parallel architecture and neuron allocation mode of NEST
1.2.3 NEST 通信架构
NEST 采用将单个时间片内的神经元连续更新的思想:神经元先进行若干次连续更新,然后一次时间片内产生的脉冲统一进行MPI 通信。
NEST 使用MPI_Alltoall 函数进行通信,通常的设计是每次通信前先通信一次确保每个节点的发送缓冲区都保持相等,这样通信两次的设计毫无疑问会随着节点增加造成通信时间剧增,因此,NEST 不使用这种设计,而是采用所有节点同时自主保持通信缓冲区相等的策略。
如图3 所示,在进行每一轮通信时,首先将脉冲放入发送缓冲区中,如果缓冲区的容量小于脉冲数,则将脉冲放满进行通信,然后扩大发送缓冲区的容量,继续放入剩下的脉冲,直到脉冲传输完成,其中发送缓冲区的容量会一直变大。这样设计提高了通信的可扩展性,但是会导致通信能耗迅速增加,并且NEST 集体通信导致发送缓冲区无论有没有脉冲都需要发送数据,这无疑增加了通信消耗,而并行SNN 的通信应当是进程间存在脉冲交换时才会发生。

图3 NEST 通信机制流程Fig.3 Procedure of NEST communication mechanism
1.2.4 NEST 负载特性
在使用多节点仿真时,神经元会被均匀地分发到每个节点上,产生跨节点通信。如图4 所示,在NEST 上运行平衡随机网络模型,随着节点增加,通信所占比例逐渐增大,计算效率逐渐下降。

图4 NEST 各阶段时间占比Fig.4 Time proportion of NEST each stage
图5 显示了NEST 通信能耗的变化,可以看出,随着节点的增加,通信数据量迅速上升,NEST 在通信能耗方面可扩展性变差。针对通信能耗可扩展差的问题,本文对NEST 进行稀疏性通信优化,以期提高通信效率。
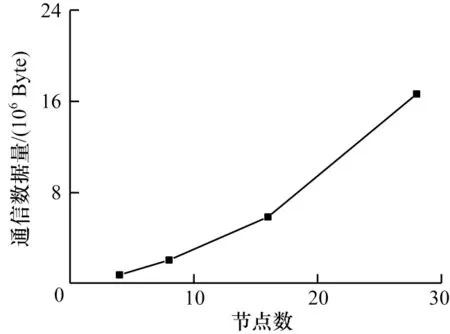
图5 通信数据量Fig.5 Communication data volume
2 稀疏性通信优化设计与实现
针对NEST 集群的神经元循环分配带来的问题,本文实现神经元重分布算法ReLOC。通过对神经元之间连接关系的分析,重新分布神经元,使得跨硬件节点之间的连接变得更加稀疏。在此基础上,改进NEST 通信方式,使NEST 集群可以更好地利用稀疏性以减少通信代价。
2.1 影响通信的因素
分布式集群最重要的问题就是节点间的通信问题,因为突触前和突触后神经元总是不可避免地被分布到不同的节点,最优分布是所有神经元都被放入同一个节点,但是此分布无法体现分布式集群的优势。节点间通常使用以太网连接,因此,网络带宽和延迟直接影响通信速度。除此之外,神经元彼此之间的连接也会对跨节点通信造成较大影响。
将一个SNN 模型建立为如图6 所示的SNN 连通图,圆点代表神经元,中间带箭头的线段表示突触。然后将一个神经元和它的突触后神经元共同组成这个SNN 图的子图,如图7 所示,假如一个神经元产生脉冲,那么脉冲数据会被发送给所有的突触后神经元。所有的脉冲传输都是基于这样的SNN子图。

图6 并行SNN 连通图Fig.6 Parallel SNN connected graph

图7 SNN 子图Fig.7 SNN subgraph
在NEST 仿真器中,当一个节点上包含一个神经元的多个突触后神经元时,这些突触后神经元会共享一个脉冲数据。因此,无论突触后神经元的数量如何,此神经元发出的脉冲传输到此节点都只算作一个,即神经元到节点的连接。每次神经元更新产生的总脉冲总是小于或等于节点数乘以神经元数。因此,如何将一个SNN 子图中的神经元分布到尽可能少的节点上,并且改进NEST 通信机制使其更适用稀疏性优化成为重要问题,本文设计的ReLOC 算法每次都加入当前匹配集最优匹配的神经元,形成新的匹配集。根据最优匹配规则选取属于匹配集中的突触后神经元最多的神经元,将SNN子图放入尽可能少的节点,从而减少跨节点脉冲。在此基础上,改进NEST 原本的集体通信,利用稀疏交换的思想,在跨节点脉冲减少的同时,避免多余的进程数据交换,从而提高NEST 通信效率。
2.2 ReLOC 算法
2.2.1 算法描述
ReLOC 算法描述如算法1 所示,其将神经元按照紧密度的联系分布到若干节点上,通过对节点神经元容纳量的限制,平衡节点的负载。
算法1ReLOC 算法

ReLOC 算法输入为节点数和神经元连接表。一个SNN 模型可以建立成一张连通图G=(V,E),V代表所有的神经元集合,E代表神经元之间的突触连接。而神经元连接表可以表示为图G的邻接矩阵A,A是Nn×Nn维的,Nn表示神经元的总数,节点数用Nnp来表示。ReLOC 算法输出为各节点的神经元分布,表示为一个分布矩阵T,T是Nn×Nnp维的。
首先选取一个节点,将一个随机的神经元r分布到此节点上,k表示当前节点;然后依次在此节点上放入未分配的神经元,直到节点k达到最大容纳量max_neurons,规则是每次放入的神经元都是未分配的神经元集neurons 中神经元的突触后神经元在节点k中分布最多的神经元。当神经元按照此方法依次进行匹配时,每次匹配的神经元都是与匹配集联系最密切的神经元。ReLOC 算法中的符号定义如表1 所示。

表1 符号定义Table 1 Symbolic interpretation
ReLOC 算法的思想是先选定一个神经元,每次匹配一个和它联系最紧密的神经元,形成一个神经元集,然后继续循环匹配和此神经元集联系最紧密的神经元,生成新的神经元集。此算法中决定神经元之间密切程度的是神经元集中属于突触后神经元的数量。因为每次匹配都会使一个SNN 子图(见图7)最大化分布到同一个节点上,当所有匹配都是最优时,每个子图都会避免分布在多个节点上,从而减少通信量。
ReLOC 算法只需要在任意一个节点上运行,然后将分布结果发送给其他节点即可。内存使用按照式(1)计算:

其中:M表示总内存;N表示神经元总数量;Mint表示整型参数占用内存。
2.2.2 ReLOC 算法的有效性
ReLOC 算法的核心是匹配过程,每一次匹配都会选择最优的匹配集,最优意味着最低代价的SNN子图切割,即SNN 子图分布在最少的节点上。
为了描述SNN 的拓扑,将神经元连接图用邻接矩阵A来表示,A[i,j]∈{0,1},当神经元i和j之间存在突触连接时,A[i,j]=1,否则A[i,j]=0。用T来表示分布矩阵,当神经元i被分布到节点j时,T[i,j]=1,否则T[i,j]=0。
根据上文提到的突触后神经元共享脉冲数据,衡量跨节点通信可以用神经元到节点的连接数量NNP来表示。首先定义P:

P[i,j]≥0 表示神经元i到节点j存在连接,那么NNP可以表示为:

2.2.3 基于ReLOC 算法的NEST 性能优化
为了利用ReLOC 算法的便捷性,并且与原先的NEST 调用代码不产生冲突,本文改变了NEST 的基本架构,在Connect 时不创建具体的突触对象,只是通过所有连接得到一个连接表,然后在调用Simulate函数初始化仿真时根据连接表进行神经元的重分布处理,之后再创建突触和运行仿真过程。重分布具体流程如图8 所示。其中,Setnod 是系统调用ReLOC 进行神经元重新分配的标志,对于非稀疏性SNN 模型,则无需调用此模块。Setnod 函数可以输入参数,根据参数选择不同的重分布算法,此模块是可扩展的,可以自行添加新的算法。

图8 重分布流程Fig.8 Procedure of relocation
用户调用应用重分布稀疏方法的NEST 内核的Python 代码以如下为例,对比原代码新增了2 个函数调用,设置重分布(Setnod)和设置通信方式(Setcomm),两者都需要在ResetKernel 后进行调用。如果不调用则默认使用原来的NEST 神经元分配和通信方式。


2.3 稀疏交换
稀疏交换是HOEFLER 等提出的动态稀疏数据交换算法[19],是节点对节点通信的模式,即一个节点只发送必要的数据给另一个节点,期间需要启动多次MPI通信,总体效率不如集体通信(MPI_Alltoall)。但是如果减少每个节点的通信节点(一个节点需要向另一个节点发送脉冲数据,即本节点神经元到其他节点的连接)的数量,那么就可以减少启动MPI 通信的次数,进而提高通信效率。
如图9 所示,在启动通信阶段,每个节点都会使用MPI_Reduce_scatter 函数与其他节点交流得到源节点的信息,避免与非相邻进程交流,以此提高通信效率。然后每个节点都将脉冲数据异步发送给其所有的目标节点,并等待接收其源节点发送的脉冲,一旦接收完毕,则表明通信阶段结束。

图9 稀疏交换流程Fig.9 Procedure of sparse exchange
每个节点与其他目标节点进行数据传输时使用非阻塞通信,即用MPI_Isend 进行发送数据,用MPI_Recv 接收数据,最后使用MPI_Waitall 等待数据全部传输完成,然后继续仿真操作。此过程不需要等待全部节点通信结束,通过非阻塞通信、重叠通信与计算阶段提高并行计算的效率。
在NEST 上使用稀疏交换之前需要先调用Setcomm(type)函数,其中的参数可以设置,从而启用不同的通信机制,如果不调用此函数则默认通信为NEST 原本通信模式。
在使用稀疏交换之前先进行神经元重分布操作,减少本节点神经元到其他节点的连接,由于稀疏SNN 模型每一轮神经元产生的脉冲比较稀少,因此减少了节点到节点通信的发生,并且只需要发送目标进程所需的脉冲数据,一定程度上解决了NEST集体通信带来的通信能耗可扩展性差的问题。
3 实验结果与分析
3.1 实验案例选择
本文选择以下2 个实验案例进行分析:
1)皮质微电路SNN 模型
此案例基于POTJANS 等提出的皮质微电路(Cortical Microcircuit,CM)模型[20]。CM 模型网络包含4层,每层由抑制性和兴奋性神经元群组成,分为8个群体,共7.7 万个神经元和3 亿突触。神经元类型为iaf_psc_exp,所有连接均为静态突触,连接规则为fixed_total_number,另有8 个泊松和对应的神经元群全连接。此案例在生物学上比较合理地模拟了大脑皮层的神经活动,为了验证网络稀疏性对于SNN 分布式计算的好处,将该模型的神经元和突触缩放至0.1和0.02,以0.1 ms 的时间步长仿真200 ms。
2)平衡随机网络模型
在此案例中,平衡随机网络模型的神经元被分成2 个种群,分别由400 个兴奋性神经元和100 个抑制性神经元构成,每个神经元的固定入度为5,因此,共有2 500 个突触。神经元类型为iaf_psc_alpha,所有连接均为静态突触,连接规则为fixed_indegree,1 个泊松和所有神经元连接。将该模型分别在类脑平台上以0.1 ms 的时间步长仿真200 ms。
3.2 实验平台
本文选取由28 块PYNQ-Z2 组成的高性能异构类脑平台,每个节点包括PS(Process System)端的ARM A9 双核处理器系统和1 个PL(可编程逻辑)端的FPGA 器件,物理内存512 MB。节点之间使用1 000 Mb/s 网络带宽的以太网进行通信,采用TCP/IP 协议。
3.3 实验内容
上述2 种模型都是Python 编写的NEST 案例,本文调用NEST 的内核(C++实现)对SNN 进行仿真,主要特征是采用时间步驱动,并行通信使用MPI 库。
对模型进行时间统计:1)计算时间是指每个节点所有神经元顺序状态更新所花时间;2)通信时间是指节点通信启动到数据接收完成所花的时间;3)仿真时间是指完成仿真所花的全部时间,包括计算时间和通信时间;4)通信数据量是指MPI 函数在200 ms 仿真时间内所有节点实际发送的全部数据字节量(unsigned int 型)。
3.4 结果与分析
3.4.1 神经元重分布
分别测试应用神经元重分布算法和循环分布算法的交换数据量和神经元到进程的数量,通信模式均采用NEST 默认通信机制。如图10(a)所示,在应用ReLOC 算法后,神经元到进程的数量平均减少约20%,但是由于NEST 的通信机制为集体通信,无法利用稀疏连接带来的好处,因此交换的数据量并未减少,如图10(b)所示。

图10 重分布和循环分布算法实验结果对比Fig.10 Comparison of experimental results by relocation and cyclic allocation algorithms
3.4.2 神经元重分布和稀疏交换
使用重分布稀疏交换方法(ReL-SE)和原版本NEST 模式运行3.1 节的2 个实验案例,这2 个案例对于仅使用静态突触的稀疏性SNN 网络有比较好的代表性。分别使用4、8、16、28 个节点进行仿真,运行结果如图11 和图12 所示。可以发现,对于稀疏SNN 模型,在通信数据量大幅减少的情况下,通信时间和仿真时间与原版本相差不大,这就使得通信能耗大幅减少。如图11 所示,在皮质微电路模型中,由于起初神经元脉冲比较密集,导致发送缓冲区一开始就会非常大,因此后续通信数据的浪费更加明显,在28 个节点上的仿真结果表明,使用重分布稀疏交换方法的通信能耗相比NEST 模式减少约98.63%。由图11(a)和图12(a)可以看出,当节点较少时,NEST 模式的仿真时间少于重分布稀疏交换方法,然而节点继续增加,NEST 模式的仿真时间却呈快速上升趋势。与此相应,通信时间也在快速接近,可以预见的是,节点的扩张有利于稀疏通信。由图11(c)和图12(c)可以看出,NEST 原本通信数据量随着节点的增加呈现快速上升趋势,而稀疏交换的数据量却缓慢增长,由此可见,同时配后稀疏交换能够大幅降低通信能耗。

图11 皮质微电路模型运行结果Fig.11 Running result of CM model

图12 平衡随机网络模型运行结果Fig.12 Running result of balanced stochastic network model
3.5 ReLOC 算法的实现代价
如图13 所示,随着节点的增加,ReLOC 算法花费时间越来越少,这是因为节点的增加导致每个节点上所能容纳的神经元减少,因此在算法循环进行神经元匹配时,突触后神经元位于节点神经元集的个数的计算次数大幅减少。

图13 ReLOC 算法耗时Fig.13 Time consuming of ReLOC algorithm
由于神经元重分布是仿真前一次性消耗的时间,因此随着仿真时间的增加,ReLOC 所需代价逐渐降低。所以,节点和仿真时间与ReLOC 算法的代价成反比,使得代价最终可以忽略不计。
4 结束语
NEST 循环分配导致联系紧密的神经元易产生分离。针对该问题,本文通过实现神经元的重分布,使联系紧密的神经元更容易分布到同一节点,使进程间的通信更加稀疏。同时,对NEST 本身的通信机制进行改进,利用稀疏交换思想大幅减少通信数据量,并配合ReLOC 算法提高通信效率。本文在使用重分布稀疏交换方法时只需要调用2 个函数来启动使用,与原版本NEST 的用户交互相比并未发生很大的变化,此方法的效果随着节点增多进一步明显,而实现代价随节点和仿真时间的增加逐渐减少。后续将通过对神经元进行更有效的分配,进一步缩短通信时间。同时,由于本文算法对于拥有STDP 突触的案例效果不佳,因此下一步也将考虑2 种突触的平衡性优化神经元重分布算法。
