大规模用户语义描述需求建模与分析
2022-03-11成方敏余隋怀初建杰樊佳爽胡宇坤
成方敏,余隋怀,初建杰,樊佳爽,胡宇坤
(西北工业大学 陕西省工业设计工程实验室,陕西 西安 710072)
0 引言
在当前激烈的市场竞争下,制造企业在产品开发过程中全面分析并快速响应大规模用户需求,是提高产品用户满意度、提升企业市场竞争力的关键[1]。用户需求的多样性、模糊性、动态性等特点,使得准确把握用户需求十分困难[2],如何准确分析用户需求已经成为一个研究热点。
用户需求分析大致分为需求获取、需求建模、需求转化3个阶段[3]。需求获取是采集用户需求信息的过程,传统的需求获取方法有用户访谈、问卷调查、发明问题解决理论(Theory of Invention Problem Solving,TRIZ)等。近年来,一些学者提出了新的需求获取方法,如基于用户需求本体模型[4]、基于设计结构矩阵[5]、基于电商平台产品评论挖掘[6]等技术。需求转化指设计人员将用户需求映射到设计域中的产品功能、结构、设计参数,最终形成产品设计方案的过程,具有代表性的方法包括基于需求—结构相似特征匹配[7]、基于模糊关系矩阵[8]、基于质量功能配置(Quality Function Deployment,QFD)[9]等技术的转换方法。
需求建模是需求获取与需求转化的中间环节,指将多样化、非结构化的用户需求进行归纳整理,形成标准形式需求的过程。需求建模质量极大影响着企业对用户需求的快速响应能力[10]。谢建中等[11]基于模糊认知图(Fuzzy Congitive Map,FCM)构建了客户需求模型,采用免疫遗传算法对需求进行相关性分析,并将需求信息存储在需求数据库中;耿秀丽等[12]基于加权网络对客户需求进行聚类,获得典型客户需求偏好类型;张文旭等[13]提出基于产品评论数据的Kano需求分析方法,并引入物元表示法对用户需求进行量化表达;WEI等[10]利用事物特性表技术对产品需求信息元素进行形式化表达;GAO等[14]建立了客户偏好本体知识库,利用基于本体的语义表达式规范化地描述客户需求。
上述研究采用不同方法对用户需求进行建模与分析,虽然具有很大的借鉴意义,但是所分析的大多是通过需求模板、选择菜单等方法获取的结构化或半结构化用户需求,对于以自然语言表达的非结构化需求,即语义描述需求的研究比较少。利用自然语言表述需求更符合用户的表达习惯,且较少受到需求采集人员的主观影响,有利于获得更为真实的需求信息[15]。互联网技术的发展使得获取大规模用户的语义描述需求不再困难,然而如何处理大量的语义描述需求成为需求分析研究中新的难点。大规模用户的语义描述需求具有较高的建模与分析难度,具体体现在两方面:①语义描述需求具有模糊性、不确定性等特点,而且由于缺乏专业知识,用户所表述的需求信息具有更强的不准确性和多样性,加大了需求信息处理的难度;②大规模用户提出的需求种类多、相关性复杂,增加了识别关键需求和确定需求优先级的难度。解决上述两个难点,是对大规模用户语义描述需求进行合理建模与分析的关键。
在此背景下,本文提出大规模用户语义描述需求建模与分析方法。首先,分析用户语义描述需求形式与类型,并定义需求模型和需求建模过程;然后,提出不同需求类型的需求合成方法;最后,评估用户需求项之间的相关关系,并据此修正需求量,根据需求量计算需求重要度,最终输出用户群体的需求方案。
1 用户语义描述需求建模过程
用户需求一般指用户对产品功能、结构、性能等产品特征的观点[16]。在形式上,用户语义描述需求可归纳为“产品特征—观点”组[17],例如在句子“操作系统要流畅”中,“操作系统—流畅”是代表用户需求的“产品特征—观点”组。可形式化地将用户语义描述需求表示为cn=〈rid,(fea,req)〉,rid为需求标识,fea,req分别为用户语义描述需求中的产品特征词与观点词。对大规模用户语义描述需求建模,就是将不准确的、混乱的产品特征—观点组转化为标准形式的需求项,并识别筛选重要的需求项,构建代表用户群体意见的需求方案。需求建模过程分为需求合成与计算需求重要度两个阶段。
由于知识水平、语言习惯等方面的差异,不同用户会采用不同词汇描述相同的产品特征和观点。为了分析用户群体需求,应将不同词汇描述的相同产品特征和观点进行合成,转化为标准形式的需求项,合成时需考虑需求的类型差异。根据产品特征能否被定量描述,可将需求划分为参数型需求与非参数型需求,由于两类需求中用户观点的表达方式不同,合成时应采用不同的方法。对于非参数型需求,用户采用诸如“可靠”“安全”“时尚”等感性词语表达观点;对于参数型需求,用户观点可用两种形式表达,即语义型(如用“多”“很大”“高”等词语表达观点)和数值型(如用大于或小于某个值表述观点)。
各需求对用户群体的重要性不同,计算需求的重要度可识别出关键需求及其优先级,进而指导产品开发。在计算需求重要度时,不仅要考虑提出某项需求的用户数量即需求量,还要考虑需求项之间的相关关系,根据需求间的相关关系挖掘用户的隐性需求并修正需求量,从而得到较为准确的需求重要度。
综上,可将需求模型表示为CN=〈Rid,(Fea,Req),Type,Weight〉,其中:Rid为需求标识;(Fea,Req)表示经合成后的标准形式的需求项,Fea为标准形式的产品特征,Req为标准形式的用户观点;Type为需求类型,分为参数型需求和非参数型需求;Weight为需求项的重要度。本文研究的大规模用户语义描述需求建模与分析过程,就是将语义描述需求转换为标准化需求模型的过程(如图1),可形式化地表示为
cn=〈rid,(fea,req)〉→CN=〈Rid,
(Fea,Req),Type,Weight〉。

2 语义描述需求合成
在充分获取用户显性和隐性需求后[4],利用自然语言处理(Natural Language Processing,NLP)技术从用户语义描述需求中提取“产品特征—观点”组[18]。首先合成产品特征词,由于产品特征词数量较小,可由设计人员进行人工合成[19];然后,根据产品特征属性将需求分为参数型需求和非参数型需求,针对不同的需求类型,采用不同方法将对应于同一产品特征的观点词进行聚类。本节重点研究观点词聚类的方法。
2.1 非参数型需求观点词聚类
对于非参数型产品特征,用户基于对产品特征的感性认知,采用感性词表达观点。对一个产品特征的观点可能有多个维度,例如对手机操作系统,可能有流畅、稳定、易操作等维度的观点。由于感性词数量较大,语义较多,难以基于专家经验进行合成,本文基于Hownet计算感性词之间的语义相似度,根据语义相似度聚类感性词。
2.1.1 感性词语义相似度算法
Hownet是一个以汉语和英语词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有属性之间的关系为基本内容的语言知识库[20]。Hownet利用“义原”和“义项”描述词语。义项是对词语语义的一种描述,一个词可以表达为几个义项;义原是描述义项的基本单位,每一个义项用第一基本义原、其他基本义原、关系义原描述、关系符号描述4类特征表示。根据这种词语语义描述方式,词语的语义相似度可通过计算词语义项和义原的语义相似度获得[20]。
Hownet定义了义原之间的上下位关系,形成了义原层次体系。根据义原层次体系计算义原相似度
(1)
式中:s1和s2为两个义原;dis(s1,s2)为s1和s2在义原层次体系中的距离;α为可调参数。
义项相似度通过组合4类义原相似度进行计算,计算公式为
(2)
式中:p1和p2为两个义项;βi为可调节参数,需满足β1+β2+β3+β4=1且β1≥β2≥β3≥β4。
对于两个词语w1和w2,将词语义项中相似度最大的值作为词语语义相似度的值,即
(3)
感性词可以是一个包括多个词语的词组。假设词组W1与W2的词语集合分别为W1={w11,w12, …,w1a},W2={w21,w22, …,w2b},则两词组的语义相似度为
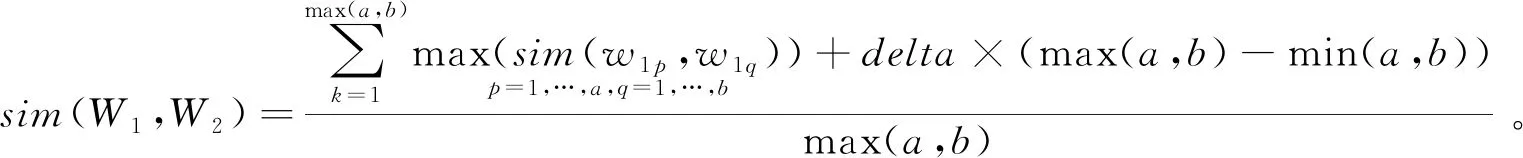
(4)
式中delta为调节参数。
2.1.2 感性词聚类算法
基于感性词语义相似度对感性词进行聚类。假设某非参数型产品特征对应的感性词集为WS={W1,W2,…,Wn},则聚类步骤如下:
步骤1根据式(1)~式(4)逐次计算感性词之间的语义相似度,构建语义相似度对称矩阵
(5)
步骤2最大最小距离算法是确定聚类中心数的常用算法[21]。本文针对语义相似度值改进最大最小距离算法,计算感性词聚类中心数K。步骤如下:
(1)选取与所有感性词相似度之和最大的感性词作为初始聚类中心,即计算SW中每一行数据之和,最大值对应的感性词即为初始聚类中心,设为Wa。
(2)给定θ(0<θ<1),选取与Wa语义相似度最小的感性词,记为Wb。若sim(Wa,Wb)≥θ,则将所有感性词归为一类;若sim(Wa,Wb)<θ,则将Wb作为第2个聚类中心。
(3)比较各感性词与Wa和Wb的语义相似度值sim(Wx,Wa)和sim(Wx,Wb),判断是否有sim(Wc)=min{max[sim(Wx,Wa),sim(Wx,Wb)]},c=1, 2, …,n,且θ×sim(Wc) (4)统计聚类中心总数K并记录聚类中心感性词。 步骤3根据各感性词与聚类中心感性词的语义相似度,将感性词分配进入语义相似度最大的类。计算各类中语义相似度之和最大的感性词作为新的聚类中心,重新将所有感性词分配进入语义相似度最大的新类,再计算聚类中心,不断循环,直至各类中的感性词不再变化为止,得到最终的聚类结果。 步骤4计算各类中各感性词的词频,将词频最大的感性词作为标准的用户观点。 对于参数型产品特征,用户通过语义型与数值型两种方式表达观点。例如,对于吸尘器“吸力”这一产品特征,一些用户会采用“较大”“很大”等词语表述观点,而具备较多产品知识的用户可能会采用“至少15 000 Pa”“大约16 000 Pa”等含有参数数值的短语表述观点。数值型观点表示方式主要有4种,即大约某个值、大于某个值、小于某个值、某两个值之间[8]。为了明确用户群体的需求,需将同一参数型产品特征对应的观点进行聚类整合。 参数型需求观点合成的目标是通过具体数值表达用户观点,以便于后续构建需求域到设计域的映射。利用模糊集理论可有效对模糊语义信息进行量化表达,为了便于合成两种方式表述的观点,统一采用梯形模糊数表达观点[22]。本文将语义型观点等级设为5,若某产品特征参数的论域为[α,β],则可确定语义型与数值型观点对应的梯形模糊数,如表1所示。 表1 语言变量与梯形模糊数的转换关系 对同一参数型产品特征对应的用户观点,利用其对应的梯形模糊数计算相似度。设两个梯形模糊数分别为P1=(a1,b1,c1,d1),P2=(a2,b2,c2,d2),其相似度 (6) 设某一参数型产品特征对应m个用户观点,将其全部转换为梯形模糊数,构成观点模糊数集合FP={P1,P2, …,Pm}。基于模糊数相似度将各观点进行聚类合成,步骤如下: 步骤1根据式(6)逐一计算各项观点之间的梯形模糊数相似度,构建相似度对称矩阵 (7) 步骤2利用改进的最大最小距离算法确定聚类中心数K,方法与2.1.2中步骤2类似。 步骤3根据各观点与聚类中心观点的梯形模糊数相似度,将各观点分配进入相似度最大的类。计算各类中模糊数相似度之和最大的观点,作为新的聚类中心,重新将所有观点分配进入相似度最大的新类,再计算聚类中心,不断循环,直到各类中的观点不再变化为止,从而得到最终的聚类结果。 步骤4确定各类所表示的参数观点。假设某类共有l个观点项,对应的模糊数构成模糊数集合FP={(a1,b1,c1,d1), (a2,b2,c2,d2), …, (al,bl,cl,dl)},则此类观点对应的梯形模糊数 (8) 式中:Ni为本类第i项观点存在的数量;Nall为本类包含的观点总数量。 合成后的产品特征和对应的观点组成标准形式的需求项,将需求项中包含“产品特征—观点”组的个数称为该需求的需求量。需求重要度可由需求量反映,需求量较大表示有较多用户提出该需求,其重要度较高。 然而,原始需求量并不能全面反映用户的真实需求。在产品开发实现过程中,需求之间存在技术层面的相关关系,将需求相关关系定义为:在产品开发过程中,若需求A得到满足时,需求B也在一定概率上需要得到满足,则称需求A与需求B存在相关关系,将这一概率称为相关关系值。需求的相关性反映了用户的隐性需求,若需求A与B相关,则当用户明确表达需求A时,其在一定程度上也存在需求B。因此,在计算需求的重要度时,应考虑需求之间的相关性,修正原始需求量,以得到更为客观的需求重要度。 本文采用两轮评估的方式评估需求相关关系: (1)判断产品特征之间的相关性 对应于需求相关关系的定义,将产品特征相关关系定义为:在产品设计中,若对产品特征A进行设计时需考虑产品特征B的约束,则称产品特征A与B相关。若一组产品特征无相关性,则可认为其对应的需求项之间也不存在相关性;反之,若一组产品特征有相关性,则其对应的需求可能也存在相关性,对其进行下一轮评估。通过第一轮评估,可识别并忽略大量无相关性的需求组,从而降低评估工作量。 (2)分类评估需求相关性 1)参数型需求相关性评估 很多产品参数之间存在定量关系,可根据定量关系计算需求间的相关关系值。对于两个参数型产品特征Fa与Fb,将其参数取值分别记为Pa和Pa。假设两个参数取值存在定量关系Pb=f(Pa),需求项Ri对Fa的取值范围记为[xi,yi],需求项Rj对Fb的取值范围记为[xj,yj]。当用户存在需求Ri时,隐含了用户对Fb参数取值范围的要求为[f(xi),f(yi)],则Ri与Rj的相关关系值为 (9) 式中Δd为[f(xi),f(yi)]和[xj,yj]重叠部分的绝对值。 2)其他需求相关性评估 (10) 假设经需求合成后共得到m项用户需求,构成需求集合RS={R1,R2,…,Rm},令无相关性需求间的相关关系值与同一需求之间的相关关系值均为0,则需求相关关系矩阵 (11) 确定需求之间的相关关系值后,修正每个用户所提需求的需求量。假设对应于标准需求集RC={R1,R2,…,Rm},用户y所提需求的需求量构成需求量集RD={N1(y),N2(y),…,Nm(y)}。对于Ni(y)(1≤i≤m),若用户提出需求Ri,则Ni(y)=1;若用户未提出需求Ri,则Ni(y)=0。计算该用户所提需求的修正量 (12) 确定用户y对于需求Ri最终的需求量 (13) 对于n个用户组成的用户群体,需求Ri修正后的需求量 (14) 需求Ri的重要度 (15) 确定需求重要度后,就将用户语义描述需求转化为符合需求模型的标准化需求。 进一步确定用户群体需求方案。设置需求重要度阈值为k,若weight(Ri) 以手持吸尘器产品为例,应用本文方法对用户语义描述需求进行建模分析。 通过在线平台收集100名用户以自然语言描述的需求,在获取需求时启发用户挖掘自身隐性需求[4],以提供尽可能全面的需求。将语义描述需求处理为〈产品特征,观点〉的形式,共计545项。设计人员对产品特征进行人工合成,共得到17个产品特征,包括8个非参数型产品特征和9个参数型产品特征。 4.1.1 非参数型需求聚类 对非参数型需求中的观点即感性词进行聚类。以产品部件“尘杯”为例,对应的感性词及其词频如表2所示。 表2 “尘杯”对应的感性词及其频率 根据式(1)~式(4)计算感性词组之间的语义相似度。式(1)中α=1.6,式(2)中β1=0.6,β2=0.15,β3=0.15,β4=0.1,式(4)中delta=0.2,得到语义相似度对称矩阵 给定θ=0.85,利用改进的最大最小距离算法确定聚类数为3,初始聚类中心为W8,W5,W1。根据语义相似度聚类感性词,得到3个类,以各类中词频最高的词作为类的名称,分别为“易拆装”={W1,W4,W10},“卫生”={W2,W3,W5,W9},“耐用”={W6,W7,W8,W11},从而将尘杯的非参数型语义描述需求转换为3类标准形式需求。以同样的方法将所有非参数型需求进行合成。 4.1.2 参数型需求聚类 对参数型需求中的观点进行聚类。以“重量”为例,经专家分析其论域为[1, 3],将相关的观点用梯形模糊数表示,如表3所示。 表3 “重量”对应的参数观点及梯形模糊数 根据式(6)计算观点之间的模糊数相似度,构建相似度对称矩阵 S重量= 给定θ=0.85,利用改进的最大最小距离算法确定聚类数为2,初始聚类中心为P1和P2。根据模糊数相似度对参数观点进行聚类,得到两个类,分别为{P1,P3,P4,P6}和{P2,P5}。根据式(8)计算出两类需求的梯形模糊数,分别为[1.32, 1.47, 1.75, 1.95]和[1, 1.13, 1.31, 1.51]。将两类观点用语言分别描述为“在1.47 kg~1.75 kg之间”和“在1.13 kg~1.31 kg之间”,从而将重量的参数型语义描述需求转换为标准形式的两类需求。以同样的方法将所有参数型需求进行合成。 经过需求合成,将用户语义描述需求转化为42个标准形式的需求项,构成标准需求集RC={R1,R2,…,R42}。仍以尘杯和重量对应的需求为例展示需求重要度确定过程。经第一轮评估,尘杯相关的产品特征为“操作”“尘杯”“吸尘杆”,重量相关的产品特征为“操作”“吸力”“充电时间”“续航时间”“长度”,然后进行第二轮评估。首先计算存在定量关系的参数型需求的相关关系值。以重量和续航时间的相关需求为例,有关重量的需求为R19:1.47 kg~1.75 kg和R20:1.13 kg~1.31 kg,有关续航时间的相关需求为R28:24 min ~33 min,R29:35 min ~41 min,R30:44 min ~49 min。重量w与续航时间t存在经验公式t=27.5w,则R19对应于续航时间的要求为40.425 min ~48.125 min。根据式(9)可得Ral(R1928)=0,Ral(R1929)=(41-40.425)/(41-35)=0.10,Ral(R1930)=(48.125-44)/(49-44)=0.83。以同样的方法可得R20与续航时间相关需求的相关关系值。由6名专家对不存在定量关系的需求进行相关性评价,将评价结果转换为粗数,计算粗数均值得到相关关系值,最终得到所有需求项之间的相关关系值,然后构建相关关系矩阵。以尘杯和重量对应的需求为例列出相关关系矩阵,如表4所示。 表4 需求相关关系矩阵(部分) 根据需求之间的相关关系值修正每名用户所提需求的需求量。以某用户为例,其初始需求集为RS={R1,R6,R11,R16,R23,R32,R36},根据式(12)~式(14)对需求量进行修正。例如对于R30,根据相关关系矩阵得初始需求中与其相关的需求为R23,R36,相关关系值分别为0.83,0.15,因此R30的修正需求量为1×0.83+1×0.15=0.98。通过修正需求量得到该用户的最终需求项集和对应的需求量。 计算所有用户修正后的需求量之和为1 034.85,根据式(15)计算各需求的重要度。设需求重要度阈值为0.03,排除需求量低于阈值的需求后得到11个需求项,如表5所示。 表5 关键需求项及其重要度 经检验,R30和R29为互斥需求,表明用户群体对续航时间的需求存在偏好差异。若企业只计划开发一款产品,则最终的用户需求方案确定为{R21,R4,R35,R8,R1,R30,R2,R23,R26,R39};若计划开发两款产品,则最终的用户需求方案确定为{R21,R4,R35,R8,R1,R30,R2,R23,R26,R39}和{R21,R4,R35,R8,R1,R2,R23,R26,R29,R39}。可利用QFD等方法构建需求项与结构解的映射,优先满足重要度高的需求,形成产品初步设计方案。然后在考虑企业供给能力等约束下进行产品详细设计,完成用户需求驱动的产品设计过程。 相比采用需求模板、选择菜单等传统方法获得的结构化用户需求,用户以自然语言形式提出的语义描述需求具有符合用户表达习惯、较为客观真实等优点,因此受到广泛关注。本文针对大规模用户语义描述需求提出一种需求建模与分析方法,相比其他方法,本文具有以下优势: (1)提出系统的语义描述需求合成方法,将大规模语义描述需求分类整合为标准形式的需求项。语义描述需求的标准化处理是大规模用户语义描述需求分析的基础,然而现有研究并未提出比较全面系统的处理方法。在一些用户需求研究中,虽然将语义描述需求作为研究对象,但是忽略了需求的标准化过程,只关注分析标准化处理后的需求[11,24]。一些研究虽然提出需求的标准化处理方法,但是不够全面,例如文献[8]提出半结构化需求的处理方法,然而该方法主要针对参数型需求,未考虑无法定量描述的非参数型需求的标准化过程。本文所提需求合成方法弥补了现有研究的缺陷,解决了语义描述需求标准化处理这一关键问题。 (2)在确定需求重要度时考虑了需求相关性,挖掘了用户隐性需求,修正了需求量。一些研究在用户需求方案向结构解映射阶段考虑了需求相关性问题[3],但在用户需求方案决策研究中则很少考虑需求相关性[2,12],使得需求方案因客观性不足而影响产品开发质量。本文方法将需求相关性分析前移至需求方案决策过程中,确定了比较客观的需求方案。 然而,本文方法仍存在一定局限。在确定需求重要度时,本文未考虑需求类型。根据Kano模型的定义,用户需求大致分为基本型需求、期望型需求和兴奋型需求[13],本文根据需求量(即用户表述需求的数量)确定需求的重要度,更多地考虑了期望型需求,而对于一些重要的基本型需求和兴奋型需求,由于用户表述较少,可能无法被筛选出来,未来研究将着力解决这一问题。 本文针对产品开发过程中大量用户提交的语义描述需求,提出一种大规模用户语义描述需求建模与分析方法,其主要特点与创新点如下: (1)在对用户语义描述需求形式与类型分析的基础上,将需求分为参数型需求和非参数型需求,并根据其语义表述特点提出相应的需求合成方法。非参数型需求基于感性词语义相似度进行合成,参数型需求采用梯形模糊数表示,并基于模糊数相似度进行合成。 (2)提出考虑需求相关性的需求重要度计算方法。根据需求相关性挖掘了用户隐性需求,并提出需求量修正算法,最终得到较为客观的需求重要度和需求方案。 (3)在分析需求相关性时,根据不同类型需求相关关系特点制定两轮评估的方法来分类评估相关关系值。针对不同类型的需求相关性,分别采用基于定量关系的客观值计算方法和基于语义变量与粗数的专家评价方法,降低了评估结果的主观性,保障了相关性评估的准确性。 未来将重点研究Kano模型的引入方法,识别大规模用户语义描述需求中重要的基础型需求与兴奋型需求,形成更为全面准确的用户需求方案。2.2 参数型需求观点合成


3 确定需求重要度
3.1 需求相关性评估

3.2 需求量修正与需求重要度计算

4 应用案例
4.1 需求合成



4.2 确定需求重要度


5 讨论
6 结束语
