基于VAE-D2GAN的涡扇发动机剩余使用寿命预测
2022-03-11侯贵生
徐 硕,侯贵生
(山东科技大学 经济管理学院,山东 青岛 266590)
0 引言
预测和健康管理(Prognostic and Health Management,PHM)由于能够帮助改善系统设备的健康状态,确保系统按照其最优的运行条件正常工作,近年来在工业领域被重点关注[1]。与传统的设备故障检修相比,PHM通过预测系统的健康状态,提前安排维修活动,在保证设备可靠性的同时降低了维修成本。剩余使用寿命(Remaining Useful Life,RUL)预测是PHM研究领域中的关键任务,其目标是提供系统设备健康状态的有效信息,并估计设备到达安全操作限制的剩余时间。对于飞机涡扇发动机这类高安全性和高可靠性要求的设备,PHM是降低设备维护成本、确保运行安全,从而提升企业核心竞争力的有效方法。准确预测涡扇发动机的RUL可以及时采取合适的维修活动(替换、维修),降低人力、物力成本,提高企业经济效益。
目前,预测方法可以被分为基于模型的预测方法、基于数据的预测方法与混合预测方法3类[2]。基于模型的预测方法是通过建立明确的数学模型来分析设备的退化过程,该方法通常需要精准、明确的系统退化方面的知识,然而涡扇发动机系统非常复杂,建立精准的数学模型难度太大。基于数据的预测方法通过收集到的设备运行数据学习设备退化行为趋势,提取关键信息,再通过机器学习、数理统计学习等方法构建设备运行数据与RUL之间的映射关系,更容易处理复杂建模问题,近年来由于传感器使用普遍,设备监测数据更易获得,该方法受到越来越多的关注。BABU等[3]提出新的学习结构,通过在多通道传感器数据的时间维度上应用卷积层和池化层学习原数据隐藏特征来提高预测精度;LI等[4]将深度卷积神经网络(Convolutional Neural Network, CNN)结合时间窗口,通过多个堆叠的卷积层学习深层表征来预测RUL,并通过和其他流行方法相比证明了所提方法的优越性。混合预测方法将前两种方法结合,可以克服两种方法的缺点,然而至今没有很好地发展,相关研究较少。因此,本文选择基于数据的预测方法。
传感器数据可以视为时序数据,在深度学习中处理此类数据常用的方法是长短期记忆网络(Long Short-Term Memory, LSTM)[5]。LSTM通过在循环神经网络(Recurrent Neural Network, RNN)加入“门”结构而形成长期依赖特征,该方法因在机器翻译、语音识别、自然语言处理等领域取得很大成功[6]而被应用到RUL预测中。ZHENG等[7]结合多层LSTM和标准的前馈网络揭示传感器数据的隐藏模式,通过与其他机器学习算法相比证明方法的高效性;MALHOTRA等[8]提出基于自编码器(Autoencoder,AE)的LSTM模型,从原数据中估计系统的健康指数,通过重构系统时间序列健康信息获得的重构误差计算健康索引,据此估计系统的RUL,以更好地进行预测;YU等[2]也采用构建健康指数的方式,不同的是在通过双向循环神经网络(bidirectional recurrent neural network)计算出健康指数后,采用曲线相似性匹配的方法估计系统的RUL;WU等[9]应用vanilla LSTM(LSTM的一种变体)解决复杂工程系统中的RUL估计问题。另外,动态差分技术也被用于从原数据中提取新特征。
目前,设备监测数据量大,而且由于多种工况和故障模式的影响,增加了数据固有的退化复杂性,使得预测算法很难直接发现原始数据中的退化趋势,特征提取是解决该问题的关键。ELLEFSEN等[10]提出一种半监督结构预测RUL,其中作为预训练模型,受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)从无标签数据中提取退化信息,用多层LSTM与全连接网络估计目标RUL,并采用遗传算法对训练过程中不同数量的超参数进行优化,从而达到更高的预测精度。YOON等[11]提出一个半监督模型解决有限标签数据下的RUL预测问题,通过基于变分自编码器(Variational Autoencoder,VAE)非线性映射学习原数据的隐含特征,进行更精准地预测;宋亚等[12]首先利用自编码器对发动机数据进行抽象特征提取,然后借助BLSTM(bidirectional LSTM)捕捉特征双向时序退化趋势,从而预测发动机RUL,提高算法预测精度。
为了提高对监测数据有效信息的挖掘提取能力,本文提出一种基于VAE-D2GAN的预训练模型。通过将VAE嵌套为双判别式对抗式生成网络(Dual Discriminator Generative Adversarial Nets,D2GAN)的生成器,形成双生成模型嵌套结构,新生成的数据不仅参与VAE的误差重构训练,还作为生成器的生成数据参与D2GAN的误差重构。双重生成模型的组合使所生成的数据更接近原数据,能够保证在生成过程中提取到的中间特征含有更多更重要的原始信息。最后,将提取到的特征传入多层LSTM预测模型,以提取其中的时间序列退化信息,揭示与RUL之间的映射关系。通过与最新研究结果比较发现,本文所提模型显著提高了涡扇发动机RUL的预测精度。
1 问题描述
本文提出新的涡扇发动机RUL预测模型,原始传感器数据在标准化后被直接用作模型输入数据。由于多种工况和故障模式的影响,模型很难直接捕获数据中隐藏的退化趋势,影响了模型的预测精度,有必要对数据进行高质量的特征提取工作。商用模块化航空推进系统仿真(Commercial Modular Aero-Propulsion System Simulation,C-MAPSS)是一款模拟大型商用涡扇发动机五大旋转部件(风机、低压压气机、高压压气机、高压涡轮、低压涡轮)在不同工况下的故障及劣化影响的软件[13]。C-MAPSS数据集共有4个子集,每个子集分为训练数据集和测试数据集,包括26个列,即引擎号、操作周期、3个传感器操作设置和21个传感器测量值。3个传感器操作模式指标分别为飞行高度、马赫数、节流解析器角度,它们决定了涡扇发动机不同的飞行条件;21种测量值来自21个传感器。详细的传感器变量描述如表1所示。

表1 传感器检测数据描述
2 理论方法
2.1 变分自编码器
自编码器是提取中间特征的有效方法,其由编码器和解码器组成。给定输入数据x,通过编码器henc(x)进行编码,提取隐藏特征z,然后交由解码器hdec(z)解码,得到重构数据。通过尽可能地最小化重构数据与原数据之间的误差实现参数优化,提取原数据中的隐藏信息形式为
H(x,x′)=‖x-henc(hdec(x))‖。
(1)
VAE是自编码器的变体,其根源是贝叶斯推理[14]。VAE继承了自编码器的编码器—解码器结构,能够对观测值P(z)的潜在分布进行建模,并通过引入一组潜在的随机变量z生成新的数据,将这一过程表示为
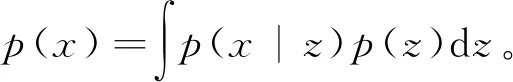
(2)
因为z为连续域,积分很难处理,所以将单个数据点进行边际对数似然表示为
logP(x)=DKL(qφ(z|x)‖
pθ(z))+Lvae(φ,θ;x)。
(3)

(4)
第一项通过最小化潜在变量近似后验与先验之间的KL散度,对潜在变量z进行正则化;第二项通过最大化从qφ(z|x)采样得到的对数似然log (pθ(x|z))来重构x。
分布类型的选择很重要,因为VAE根据先验分布pθ(z)和似然pθ(x|z)对近似后验分布qφ(z|x)进行建模。后验分布的典型选择为高斯分布N(μz,Σz),先验分布采用标准正态分布N(0,1)。对于似然性,经常将伯努利分布或多元高斯分布分别用于二进制或连续数据。
2.2 双判别式对抗式生成网络
D2GAN来源于对抗式生成网络(Generative Adversarial Nets,GAN)。GAN[15]的核心思想是由生成器模型和判别器模型形成对抗性损失,生成器用于从随机噪声中生成数据,并努力覆盖真实的数据分布,判别器用于区分数据来自真实数据集还是由生成器生成。
生成器G和判别器D形成二元极小极大值博弈,其中G努力学习真实数据分布来欺骗D,D被训练来检测G的输出是否为真。为了实现上述目标,训练D使log(D(x))最大化,调整G的参数使log(l-D(G(z))最小化。总对抗损失可描述为
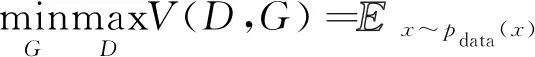
(5)
D2GAN为GAN的变体,是一个三元博弈,包括两个不同的判别器D1,D2和一个生成器G。给定数据空间中的样本x,如果x从真实数据分布pdata中获取,则D1(x)将获得高分;如果x从模型分布PG中生成,则D1(x)获得低分[16]。相反,对于从PG中生成的x,D2(x)返回高分,而从pdata中提取的样本则给出低分。与GAN不同的是,判别器返回的分数是正实数而不是在[0,1]之间的概率。生成器G从噪声空间映射合成数据来欺骗两个判别器D1,D2,这3个参与者均由神经网络参数化,其中D1,D2不共享参数,如图1所示。
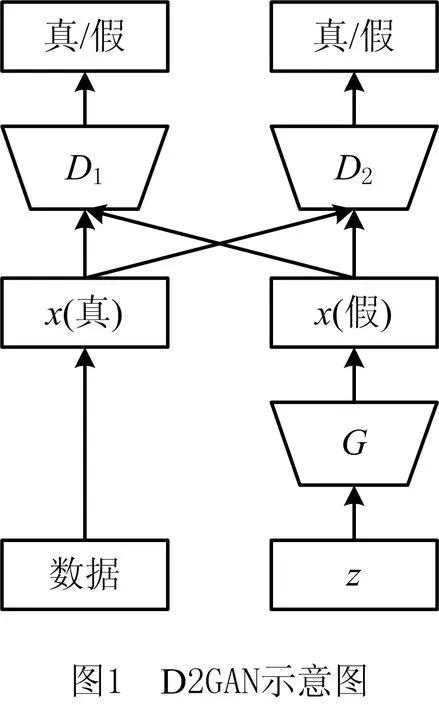
D1,D2和G三者构成三元极小极大值优化博弈:

(6)
引入超参数0<α,β≤1来稳定模型的学习,并控制KL和反向KL散度对优化问题的影响。
3 VAE-D2GAN半监督预测模型
本文提出的半监督深度学习预测模型的构建思想是,将VAE作为D2GAN的生成器构成双生成模型嵌套结构,使VAE中提取到的中间特征含有更多有用的原始信息;然后将提取到的特征输入到双层LSTM,进一步提取时序退化信息;最后通过全连接神经网络(Fully-connected Neural Network,FNN)输出目标RUL。模型的整体框架如图2所示。

本文所提模型的最大特点是VAE-D2GAN形成的双生成嵌套预训练模型,为了突出所提取中间特征的高效性,在监督学习阶段,本文采用最简单的双层LSTM进一步提取特征中的时序信息,而不是BLSTM。从双层LSTM得到的时序退化信息被传入第一层全连接层,为了使模型更好地拟合训练数据并加快收敛,选用ReLU[17]作为激活函数,同时对此全连接层进行参数正则化以减轻过拟合。最后,在第二层全连接层输出预测的RUL,由于为最后的输出层,输出节点设置为1,使预测RUL与标签RUL的数量保持相同。
在所提模型的核心结构——预训练模型中,VAE作为生成器参与到D2GAN的训练中,VAE的生成数据不仅参与其本身的误差重构,还要作为D2GAN的生成数据来欺骗D2GAN的两个判别器。通过双重生成模型嵌套使生成数据更接近原数据,编码器可提取到更高质量的中间特征,这对后续预测至关重要。预训练模型的结构如图3所示。

考虑到输入数据来自于不同的传感器,在VAE的编码器部分首先使用4个步长为1的一维卷积核(16×1)提取每个传感器数据内在的退化信息,然后通过紧随其后的三层步长为2的二维卷积核(18×4)提取数据样本中空间相邻要素之间的关系。对每个卷积层都用ReLu作为激活函数,然后通过7层CNN进行特征提取。将提取到的特征通过Flatten层转换维度后,送入FNN输出均值和方差,构建正态分布,用于随后的解码器采样。详细的编码器结构如图4所示。
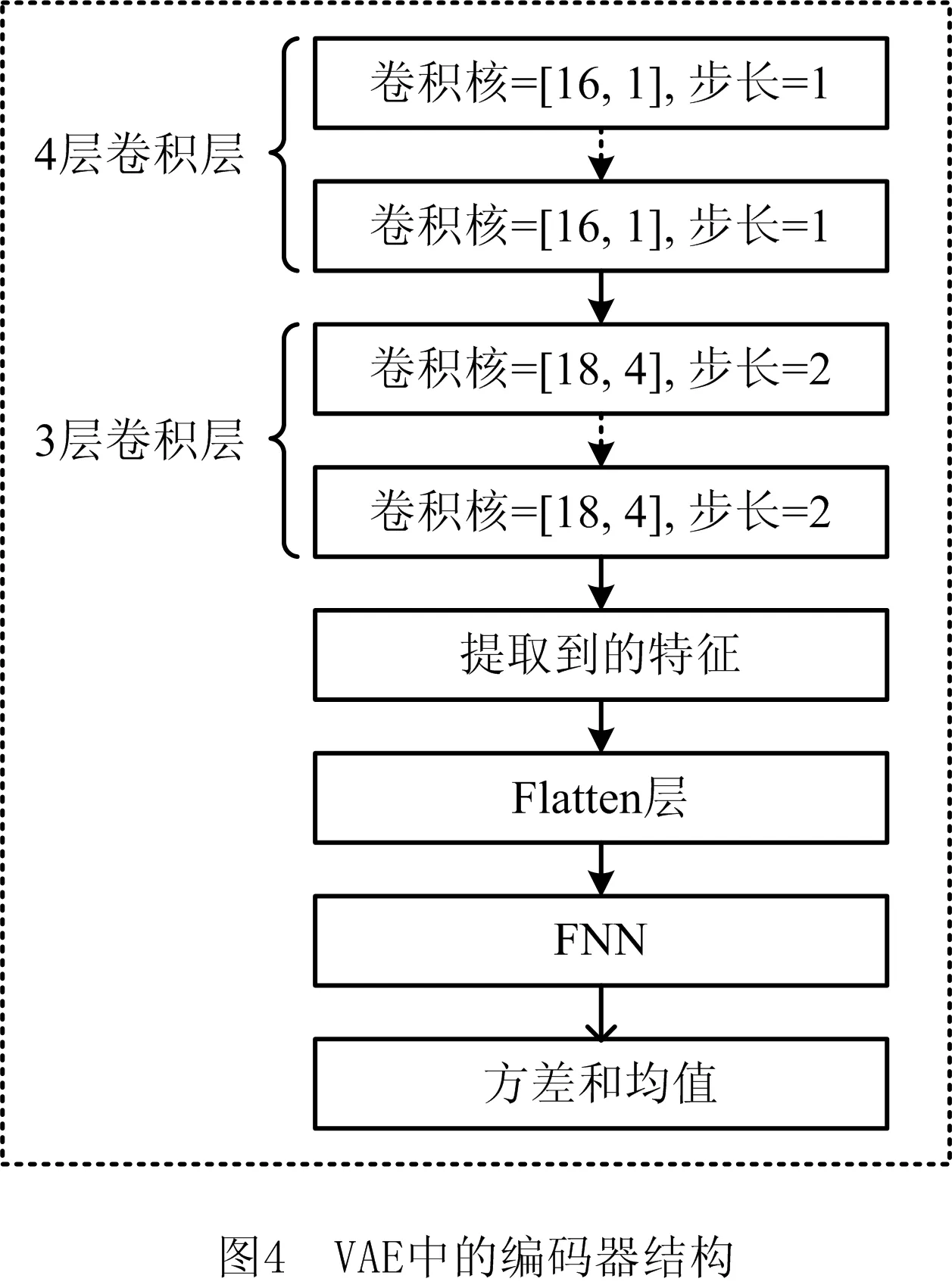

编码器结构对所提取特征的质量有重要影响,本文提出的4层一维卷积结合3层二维卷积的编码结构通过实验逐一寻优得到,不同结构的特征提取能力不同,预测精度也不同,实验结果如图5所示,其中RMSE表示均方根误差。无论减少一维卷积层数或二维卷积层,都会增大预测误差,因为减少卷积层会减弱模型的特征提取能力,降低对原始数据有效信息的挖掘程度,从而降低预测精度。而在7层结构已经取得优秀预测结果的情况下,如果继续增加卷积层,则会导致编码器结构过于复杂,增加运算资源消耗,从而延长训练时间。

为了进一步减轻过拟合,在解码器的第一个卷积层以及监督阶段中的双层LSTM和第一层FNN中采用Dropout技术,通过在训练过程中随机丢弃部分神经元,相当于在多个神经网络结构上训练,来提高模型的泛化能力[18]。另外,本文还采用提前终止训练的方法,在训练集上训练模型后,在验证集检测模型的表现,如果发现验证集的误差连续在多个时期内没有下降,则提前停止训练,并将停止之后的参数作为神经网络的最终参数。
为了加速模型收敛,生成器与判别器中的卷积操作都采用CNN-BatchNorm-ReLu的形式 (除了输出层),即在卷积操作之后先进行批标准化(Batch normalization,Batchnorm),再传入激活函数。Batchnorm对每一层神经网络的激活输入值进行规范,使其保持相同的分布,从而减少梯度消失问题,加快模型训练速度[19]。对权重初始化采用xavier标准初始化器;无监督训练模型中用RMSprop[20]对损失进行优化,微调阶段采用Adam[21]算法对参数进行优化;所有训练过程的初始学习率均设为0.000 2。
整体训练算法如算法1所示。首先训练VAE-D2GAN模型,获得高质量的中间特征,然后通过监督学习进行RUL预测。
算法1基于VAE-D2GAN的预测模型训练算法。
输入:涡扇发动机退化监测数据集。
初始化参数:时间窗口长度、批尺寸、训练次数、神经网络节点数、初始学习率(Adam)。
输出:权值确定的基于VAE-D2GAN的预测模型。
训练过程如下:
(1)数据选择及标准化。
(2)滑动窗口准备数据。
(3)当VAE-D2GAN 模型训练时期数小于设定值时:①将数据输入VAE-D2GAN模型向前传播获得输出x′;②计算生成误差(包括生成器误差和重构误差);③计算判别误差(双判别器误差之和);④应用RMSprop分别最小化生成误差和判别误差,更新模型权值。
(4)获得训练好的VAE-D2GAN模型。
(5)获得提取到的特征。
(6)当 LSTM-FNN阶段训练时期数小于设定值或未达到EarlyStopping条件时:①将提取到的特征输入LSTM-FNN向前传播得输出预测值yi;②计算预测值与真实值之间的误差;③应用Adam更新LSTM-FNN的权值。
(7)获得训练好的预测模型。
4 实验研究
将所提模型在预测基准问题(美国国家航空航天局涡扇发动机退化问题)上进行实验,并将结果与最近的研究进行比较,以证明模型的高效性。该流行数据集是由美国国家航空航天局开发的C-MAPSS生成的仿真数据,其发动机模拟器可以在5个旋转组件中的任何一个上模拟故障,并为感测到的发动机变量提供输出响应。在该实验中,4个不同情况的数据子集包括3个操作条件指标和输出变量中的21个传感器测量值,4个不同情况的数据子集包括第1章中提到的3个操作条件指标和输出变量中的21个传感器测量值。
4.1 数据集介绍
C-MAPSS数据集被广泛用于在设备RUL预测实验中验证预测方法的有效性,其4个子集包括不同数量的涡扇发动机,而且每个发动机的运行周期也不同。为了与所选研究进行比较,本文参考文献[12],只选取第一个数据集FD001来验证模型。FD001训练集中记录了100台发动机从正常运行到发生故障的过程,测试集样本中的100个发动机在故障发生前停止运行,预测100个发动机的RUL,其中真实的RUL值已经在另一个文件中给出,用于计算模型预测精度。
4.2 训练流程
详细的训练流程如图6所示。在传入模型之前,首先对发动机数据进行预处理,包括数据选择和标准化。在数据集FD001的21个传感器监测数据中,传感器1,5,6,10,16,18,19在整个发动机运行周期中是常数,意味着这些数据对发动机RUL预测的贡献不大。另外,因为FD001服从单一操作条件,所以可以从输入数据中排除3个操作指标参数。然而,为了能使VAE的输出数据与输入数据保持相同的尺寸,需要用一个常数监测数据组成16个输入变量,可以采用任意一个常数传感器数据,因此本文选择传感器19。
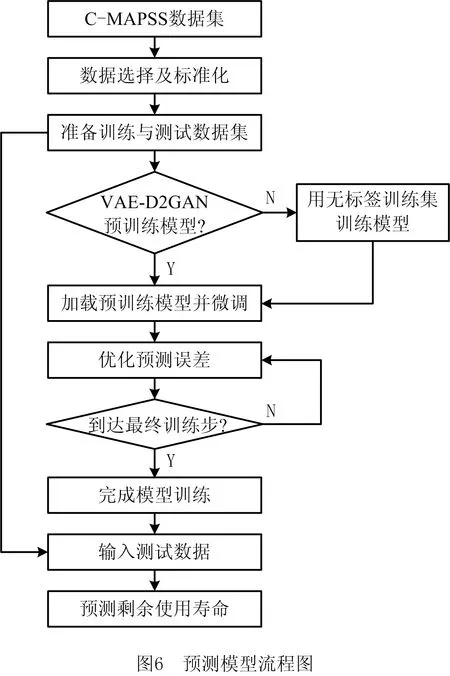
因为各传感器返回的物理特征值不同,所以需要对所选择的输入变量进行归一化处理,以消除不同量纲对预测结果的影响。本文选择最小最大值标准化方法,将输入数据规范到[-1,1]之内,具体公式为
(7)
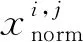
与在单个时间步长采样的多变量数据点相比,时间序列数据可以提供更多信息。因此,本文采用滑动窗口策略来有效使用多元时序信息。模型的输入为二维矩阵[xtw,xf],其中xtw表示滑动窗口的尺寸,xf表示选择的输入特征数。为了在提高数据利用率的同时保证VAE生成数据的尺寸不变,将滑动窗口尺寸设为32,即xtw=32;因为共选定16个输入变量,所以xf=16。为了尽可能利用数据,将滑动窗口的步长设为1。
训练集中并未提供真实RUL标签,因此本文采用分段线性退化模型为涡扇发动机的每个运行周期构建训练标签,如图7所示。通常设备在使用初期正常运行,其退化可忽略不计,将这时的RUL视为常数。随着设备的运行,发动机开始线性退化,即当超过一个临界值时,RUL开始随运行周期的增加而线性减少。前期研究表明,RUL的设定主要为115,120,125,130四种,为了更直观地显示该超参数对预测精度的影响,本文通过实验逐一寻优,结果如图8所示。实验表明,RUL的突变临界值设定为120时的预测精度最高。


将FD001数据集经过预处理步骤后获得的标准化数据传入VAE-D2GAN预训练模型中提取抽象特征。完成模型预训练后进入微调阶段,通过最小化输出预测RUL与标签RUL之间的误差,反传更新模型参数。
为了方便与其他算法进行比较,本文选用与文献[12]相同的评估标准衡量算法的优劣,即评分函数S和均方根误差RMSE:
(8)
(9)
式中:n为测试集中真实的RUL标签数;di=Rpre-Rtrue,Rpre为RUL预测值,Rtrue为RUL真实值。提前预测和延后预测对RMSE的影响权重相同,延后预测对评分函数的影响权重大于提前预测。原因是延迟预测会因预测不及时而产生更严重的后果,而提前预测相对只是增加维修成本。预测算法的主要目标是在评分函数与RMSE两者尽可能小的情况下,使预测误差di=0。
4.3 模型参数设置
在训练时,将FD001数据集分为训练集和验证集,其中验证集占总数据的15%,剩余的85%属于训练集。采用小批次方法训练,为了选取最合适的批尺寸,对常用的超参数(取值为128,256,512,1 024)进行逐一实验,结果如图9所示。因为批尺寸取1 024时效果最好,所以每个批次设置1 024个滑动窗口样本,共3 000个批次用于训练模型。另外,由两个LSTM和两个FNN层组成的监督训练阶段中,二者的隐藏节点数对RUL预测精度有重要影响。为了探求合适的参数(取值为(32,32),(64,32),(128,64),(256,128)),对常用的4种设置进行实验验证,结果如图10所示。可见,当LSTM和FNN的隐藏节点分别为64和32时,预测误差最小;对于Dropout技术的超参数p,本文选择最通用的0.5。监督阶段的详细参数如表2所示。

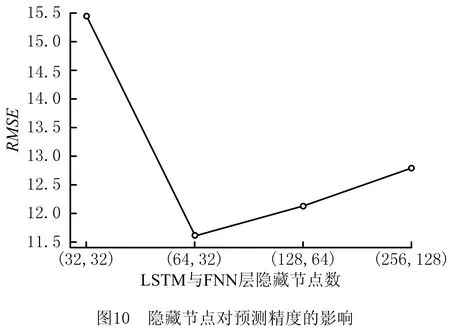

表2 监督模型参数
4.4 预测结果及比较
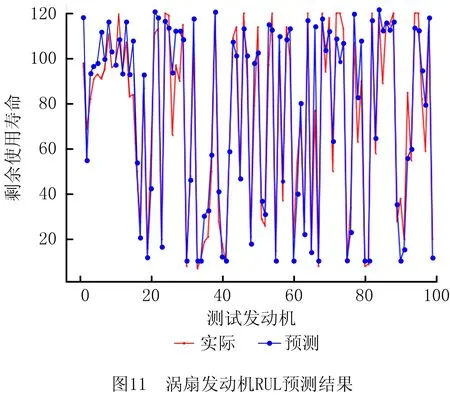
模型完成训练后,对预测准确性进行测试。将测试集输入模型得到测试结果如图11所示。可见,预测的RUL值与实际的RUL标签相差不大,说明所提模型表现优秀。为了更精确地衡量模型预测表现,分别计算评分函数与RMSE。
将本文模型与在相同训练集上测试的算法进行误差比较,结果如表3所示。通过对比可知,无论RMSE还是评分函数,本文所提VAE-D2GAN深度学习预测模型的预测误差均为最低水平。其中预测误差RMSE比之前最优的深度CNN[4]降低了8%,评分函数比之前全部算法中最优的Autoencoder-BLSTM[12]降低了15.3%,原因是双重嵌套生成模型提取到了更高层次的抽象特征,其中包含更多有用的原始数据退化信息,为之后的监督模型预测RUL打下了坚实的基础。本文所提VAE-D2GAN深度学习预测模型的预测精度高,且无需专家知识和物理建模知识,具有较强的推广性,可以指导涡扇发动机预测维修活动,能够在保证安全性和可靠性的同时降低人力物力成本。

表3 不同预测方法实验结果对比
5 结束语
为了解决涡扇发动机数据难以提取有效抽象特征的问题,本文提出一种基于D2GAN-VAE的预训练特征提取模型,模型通过双重嵌套生成结构使生成的数据更接近原数据,能够保证提取到的特征含有更多原始信息,随后通过微调阶段进一步提取时序退化信息来预测RUL。通过将所构建的模型在C-MAPSS数据集上测试,并与最近的预测算法进行比较,证明了本文模型可有力保障设备安全。未来将进一步提高模型的稳定性,并缩短模型训练时间。
