工业物联网的工业边缘云部署算法
2022-03-11颜晓莲邱晓红陈庆奎
颜晓莲 ,章 刚 ,邱晓红 ,陈庆奎
(1.江西理工大学南昌校区 软件工程学院,江西 南昌 330013;2.江西北大科技园,江西 南昌 300033; 3.上海理工大学 光电信息与计算机工程学院,上海 200093)
1 问题的提出
工业物联网(Industrial Internet of Things,IIOT)作为一种智能制造技术形态,能够实现原料灵活配置、过程按需执行、工艺合理优化和环境快速适应,因此广泛应用于制造业领域[1-2]。随着大批量工艺复杂且异构的数字化生产设备接入IIOT,产生了生产设备实时性运维等新型工业需求,然而受限于工业带宽与传输距离,IIOT无法通过云端有效解决生产设备实时性运维问题,在IIOT体系中引入边缘端数字孪生技术势在必行[3-4]。
作为IIOT实践的产物,边缘端数字孪生是一种集感知、通信、建模、分析和控制等技术为一体,能够在靠近生产设备处构建与物理设备完全对称的虚拟映射,借助运行数据模拟生产设备运行过程,并通过智能分析提供实时运维服务,从而满足工业实时性要求的技术体系[4-5]。由于能够在物理设备近端处搭建物理设备与虚拟设备沟通交互的桥梁,其必将成为工业物联网的核心部件之一[5-6]。推动工业物联网与边缘端数字孪生融合被视为工业物联网技术成熟到一定阶段的必然结果,而当前边缘端数字孪生技术全面融入工业物联网体系依然面临各类挑战,工业边缘云部署问题便是其中之一。
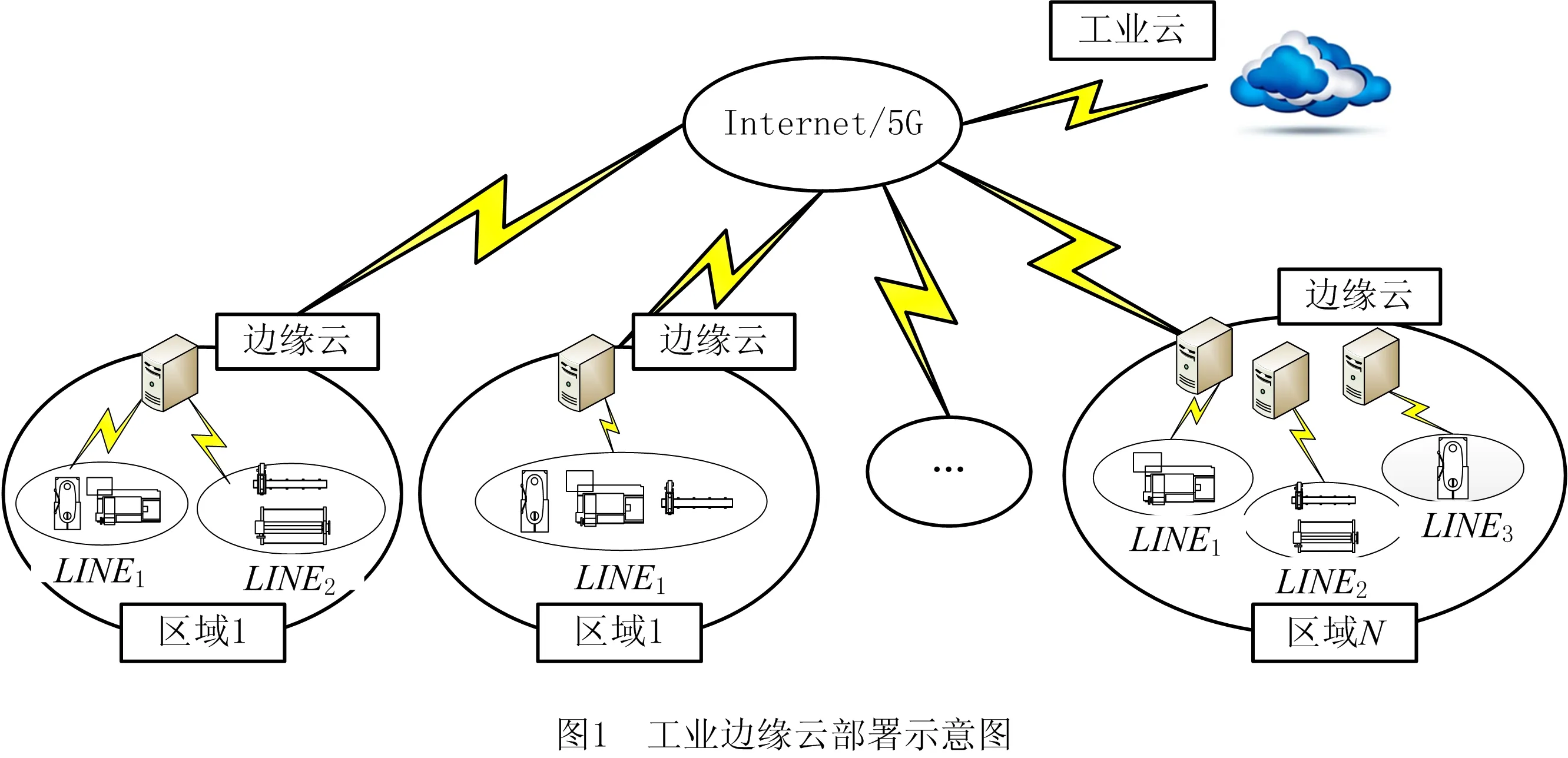
一般而言,制造型企业的生产资料分散在不同区域。在生产需求驱动下,不同生产区域(或生产车间)需安置数量或规模不同的生产线(每条生产线上附属的生产设备数量不同)方可满足制造要求。为保证设备实时性运维的服务质量和节约成本,在每条生产线的内部网关处(或多条生产线的共享网关处)部署工业边缘云,覆盖相应的生产线及其生产设备,有效构建起以数字化改造后的生产设备为终端,各类通信网络为载体,工业边缘云为核心的边缘端数字孪生技术架构,该架构能够有效贴近应用场景,为生产设备提供实时性运维服务。其中,工业边缘云是适用于工业领域,部署于物理设备周围,集建模、分析和控制等技术为一体的中低端服务器(或服务器集)。
由于企业产能受市场影响时刻变化,每个工厂内的生产线会随制造需求变化而动态调整,包括扩大或缩小生产线的数量和规模,这种无规则动态调整容易造成工厂间生产线的差异化安置,以及生产设备不均匀分布。
工业边缘云是构建边缘端数字孪生技术架构的核心,也是提供实时性运维服务的关键。当每个工厂内的生产线数量和规模发生改变时,由于工业边缘云的网络资源、存储资源和计算资源有限,为保障继续提供实时性运维服务并节约成本,必须对工业边缘云原有的部署方式进行调整。任何随意部署,包括不充分部署或过度部署,都将造成服务延迟增加、工业边缘云负载失衡及企业成本增加等一系列问题。总之,合理部署工业边缘云,不仅能够提升资源利用率、节约企业生产成本,还能优化工业边缘云的负载,保障服务质量,为边缘端数字孪生乃至IIOT后期实践打下基础。工业边缘云部署的示意图如图1所示。
综上可知,工业边缘云部署是保障实时性运维服务质量与节约成本的前提,而且依此产生的工业边缘云部署问题(Industrial Edge Cloud Deployment Problem,IECDP)正逐渐成为热点[7-9]。通过综合考量已有成果及实践中所关注的重点,本文认为IECDP指在部署总成本受限的条件下,如何合理部署工业边缘云,使其在所提供的总服务延迟最小的同时总负载最小[9-13]。
值得注意的是,边缘云(服务器)部署问题不只是工业物联网所关注的基础性问题,也是移动边缘计算体系中主要讨论的基础问题之一。与IECDP不同之处在于,移动边缘云(服务器)部署主要关注的是如何在移动用户周围合理部署移动边缘云(服务器),使得服务质量优、移动用户访问延时小、服务提供商收益高[8-13]。
综上所述,IECDP的研究不但为工业物联网与边缘侧计算融合研究提供了基础理论依据,而且将为其他领域中的边缘云部署问题研究提供解决思路。
2 现状描述
现有研究成果有关工业物联网中IECDP的讨论比较少,但对移动边缘计算领域中的边缘云(服务器)部署问题有详细介绍。
首先,移动边缘计算的目标是保证移动用户能够就近获取云计算服务。然而由于移动用户不但会在某范围内频繁移动,而且对服务的需求也不相同,在移动边缘云(服务器)覆盖范围受限的条件下,为保证移动用户获得高质量服务,有效地部署移动边缘云(服务器)极为重要。现阶段大多数移动边缘计算的研究均基于边缘云(服务器)已部署完成的前提进行,必然会影响后期研究成果,因为不同的部署策略对研究成果的影响也不同,可见移动边缘云(服务器)部署是移动边缘计算体系中的一个基础性问题。WANG等[8]讨论移动互联网环境中具有约束限制的边缘服务器放置策略,将放置问题抽象为多目标多约束优化问题,并提出启发式混合整型规划算法解决。文献[9-11]集中讨论如何在规模城市中为移动用户安置边缘侧服务器,从而提高移动服务质量问题,区别在于,文献[9]以工作任务卸载平均等待时间为优化指标,基于排队论和分类算法思想设计部署模型;文献[10]以移动用户平均访问延时为优化指标,用线性规划思想设计部署算法;文献[11]以边缘服务器部署成本为优化指标,采用改进型贪婪算法予以解决;文献[12]讨论随机分布环境下的Cloudlet放置问题,以覆盖移动用户数量为优化指标,提出基于K-means思想的Cloudlet部署算法;文献[13]以服务提供商收益为优化指标,提出一种基于资源需求预测的边缘端服务器放置启发式算法。
以上研究成果部分尝试借助分类思想(如K-means或K-median),以优化指标为导向不断调整分类策略,使得优化指标最优,从而确定潜在的边缘端服务器部署点[8-10,13];部分尝试从某一特性出发,预测出移动用户的迁移轨迹,并基于迁移轨迹确定潜在的边缘端服务器部署点[11-12]。虽然都具有一定优势,但是显然都不适合解决IECDP,主要原因为:①工业制造领域,生产需求驱动着生产线的动态调整,无法通过预测方式获得;②相对移动用户异构的应用需求,生产线及生产任务均具有同构属性,而且生产线动态调整的频率较低,无法通过分类策略划分。
因此,本文提出一种启发式遗传算法(Heuristic Genetic Algorithm,HGA)有效地解决IECDP,主要工作如下:
(1)讨论了工业物联网与边缘端数字孪生融合的基础性问题——工业边缘云部署问题,并进一步将该问题转化为带约束的最小子集划分问题。
(2)针对传统遗传算法在解决带约束的最小子集划分问题时存在的不足,提出HGA进行解答。该算法以保障种群多样性和可靠有效为导向,分别从编码方式选定、初始种群筛选、下一代种群选择、交叉和变异等方面进行深度优化,确保提高HGA的搜索准度和搜索速度。
(3)构建模拟场景,确定期望负载偏差率、期望服务延时偏差率、算法收敛率和解误差率4个测试指标,通过4组实验数据尝试验证HGA的有效性、收敛性和全局搜索能力。
3 问题描述
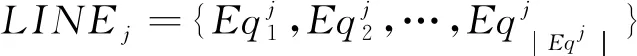
(1)IECDP描述
给定一组边缘云EC集合、生产线LINE集合及每个生产线所对应的生产设备集合,在部署总成本Cost[EC]受限的条件下,寻找一种边缘云部署方案,使边缘云总服务延时Delay[EC]最小的同时边缘云总负载Balance[EC]最小,目标函数形式化为:
minDelay[EC](X)&&minBalance[EC](X)。
s.t.
Cost[EC](X)≤CostC。
(1)
其中:X为部署方案解;CostC为企业成本约束量。边缘云总服务延时指所有边缘云服务延时的总和,表示为
(2)
单个边缘云ECi服务延时包括ECi所覆盖的生产设备与其之间的数据传输延时,以及ECi对每个生产线的服务处理延时,表示为
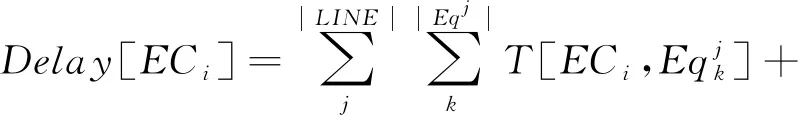
(3)
式中:T[·]为生产设备与边缘云之间的数据传输延时;Dispose[·]为边缘云服务处理延时。
同理,边缘云总负载指所有边缘云负载的总和,表示为
(4)
单个边缘云ECi负载包括CPU消耗、内存消耗和通信消耗,通信消耗指与生产设备通信的消耗,即
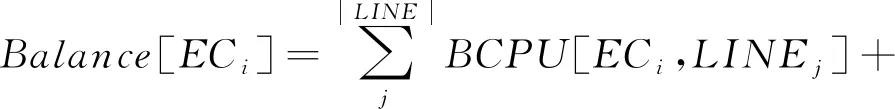
(5)
式中:BCPU[·]为CPU消耗;BCACHE[·]为内存消耗;BCOM[·]为通信消耗。
(2)问题变换
IECDP属于带约束的多目标优化问题,在实际求解过程中存在一定难度。通过分析所求问题,因为工业边缘云部署在单一网关处(或共享网关处)覆盖所有域内生产线及其生产设备,而每个生产线需要被工业边缘云覆盖(暂不考虑生产线被多重覆盖情况),所以IECDP可转化为带约束的最小子集划分问题(Minimum Subset Partition Problem with Constraints,MSPPC)。IECDP转化的意义在于,将IECDP转化为经典NP难问题的同时对目标优化函数进行降维,降低计算复杂度。
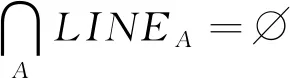
s.t.
(6)
对每个生产线而言,其划分权重由某个边缘云为该生产线提供服务所产生的服务延时,以及边缘云处理该生产线业务所造成的资源消耗(负载)的线性加权组成[7-8],其划分代价由部署到某个边缘云所需的代价组成。
MSPPC属于经典的NP难问题,本文提出HGA来解决。
4 改进的启发式遗传算法
4.1 传统遗传算法
传统遗传算法(Genetic Algorithm,GA)[14]由美国学者John Holland提出,是模拟生物进化的一种高效、通用、并行优化算法,该算法的本质是通过不断迭代来靠近最优解。GA在解决MSPPC问题上具有一定优势,因为MSPPC的本质是寻找一个由单个或多个子集组成的集合。对于任意给定的由N个生产线组成的集合,其子集个数为2N-1(不包括空集),根据MSPPC的思想,如果将被选中的子集赋值1,未被选中的子集赋值0,则问题的最终解可用一组数字0和1表达。而GA相对于已有的智能算法,更贴合MSPPC的思想,有利于快速搜索问题的最终解。
GA存在早熟现象[14](也称过早收敛,指算法过早陷入局部最优,很难从局部最优跨到全局最优),因此提出HGA,在优化相关问题的同时解决MSPPC。
4.2 算法描述
算法的改进思想为:①以提高全局搜索准度和提升收敛速度为目标;②为保证种群可靠和有效,筛选多样化的可行解作为初始种群;③为保持种群多样性,选择下一代种群时,有目的地进行混合式挑选;④为维持种群多样性并提升探索新区域的能力,进行多轮多维度多点交叉操作;⑤实施较优新个体优先动态变异策略,进一步保障种群多样化,及其可靠性和有效性。
4.2.1 编码
采用二进制编码方式,对被选中的子集赋值1,未被选中的子集赋值0,则任意一个问题解可以用一组0与1的二进制码表示,即表示为一条染色体。
4.2.2 初始化种群
种群由一组染色体(或解)组成,为提升搜索速度并提高搜准率,采用多轮随机不重复解策略产生种群,过程如下:
(1)设定一个数组array保存初始化种群,转步骤(2)。
(2)随机产生一组问题解,删除不满足条件的解,并与数组array中的问题解逐一比较,删除重复解,将剩余满足条件且不重复的解存入数组array,转步骤(3)。
(3)判定数组array中解的个数是否满足种群规模,如果不满足,则转步骤(2),否则退出初始化过程。
多轮随机不重复解策略的优势在于,不但实现的初始化种群由可行解组成,而且能够尽可能保证可行解的多样性,为提升搜索速度并提高搜准率打下基础。
4.2.3 适应度函数
适应度函数反映被选个体(染色体)的优劣,个体的性能越好(满足约束条件且权重小),适应度函数值越大;个体的性能越差(不满足约束条件或权重大),适应度函数值越小。适应度函数F(X)定义为:
(7)
s.t.
其中:X为候选解(即一组子集划分);Θ∪(X),Θ∩(X),ΘC(X)分别为并集、交集和约束的惩罚因子;r∪,r∩,rC分别表示并集、交集和约束惩罚程度;ΘW(X)为目标函数。
4.2.4 选择操作
选择操作需要保持种群的多样性,本文采取混合式选择法,按一定规则选取一组较优个体与较差个体作为下一轮迭代种群,具体过程如下:
(1)在可行解作为初始种群的条件下,种群中的较优个体靠近最优区域,较差个体会远离最优区域。任一个体都具有个体偏移特征,个体偏移反映个体在种群中所处的位置(靠近或远离最优区域),设Un(Xi,·)为个体i的偏移量,则:
(8)
(9)
式中:Un(Xi,Xj)为个体i相对个体j的偏移量,反映个体i相对个体j所处的位置;Un(Xi,·)反映个体i所处种群的位置;N0为种群规模。
(2)对种群中的所有个体i,根据式(8)和式(9)计算其个体偏移量Un(Xi,·)。
(3)根据步骤(2)计算结果,借鉴聚类思想将种群等分为较优个体和较差个体两类。
(4)对较优个体类而言,以等概率选择一定数量个体,根据式(7)计算适应度并排序,选取适应度值最大的个体为候选个体,重复步骤(4),直至满足退出条件。
(5)对较差个体类而言,以等概率选择一定数量个体,根据式(7)计算适应度并排序,选取适应度值最小的个体为候选个体,重复步骤(5),直至满足退出条件。
(6)合并步骤(4)和步骤(5)产生的候选个体,组成下一轮迭代种群。
选择规则基于以上混合选择策略,可以保证被选种群趋于多样化。
4.2.5 交叉与变异操作
(1)交叉操作体现全局搜索能力,本文采取多轮多维度多点交叉法,具体过程如下:
1)基于被选中种群,按较优个体与较优个体、较优个体与较差个体、较差个体与较差个体两两随机组合思想,根据步骤(2)进行交叉操作。
2)交叉操作采用随机多点交叉策略,即任意两个个体随机选择多个交叉点进行多点交叉。
3)对新产生的种群,根据选择操作中的步骤(2)和步骤(3)将种群划分为较优个体集和较差个体集,并进行合并和排序。
4)如果满足退出条件,则退出交叉操作,否则转步骤(1)。
交叉规则优势在于,通过较优个体与较优个体、较优个体与较差个体、较差个体与较差个体多轮多维度多点的交叉操作,在维持种群多样性的同时,不断探索新的区域,提升全局搜索能力。
(2)变异操作体现局部挖掘能力,具体过程如下:
1)基于上述交叉操作结果,对被选中的种群重新按适应度值的大小排序,并计算每个个体i的适应度比例Fitness(Xi),
(10)
式中N0为种群规模。
2)根据式(11)计算每个个体i的累积适应度比例,
(11)
3)根据均匀分布策略随机产生一个随机数γ∈[0,1]。
4)若γ的值落在两个个体累积适应度比例之间,则以累积适应度比例高的个体为被选待变异个体,并随机选取一个指针作为变异点进行变异操作。
5)判定变异后的新个体是否在本轮中重复出现,是则重新选取一个指针作为变异点进行变异操作,直至出现新个体。
6)如果满足退出条件,则退出变异操作,否则转步骤(3)。
变异规则的优势在于,对交叉操作产生的较优新个体所在区域优先进行局部深挖,并在深挖过程中不断调整深挖方向,以保持种群的多样性,进一步提升全局搜索能力。
4.2.6 算法过程
步骤1按照二进制编码规则和适应度函数定义确定适应度函数F(X)。
步骤2初始化参数r∩,r∪,rC,设定种群规模N0,并根据定义初始化种群,设定迭代次数It0,根据适应度函数F(X)计算种群中所有个体的适应度值。
步骤3为保持个体多样化,根据种群选择规则挑选候选种群。
步骤4根据交叉与变异规则产生下一代种群,再根据适应度函数F(X)计算下一代种群的适应度值。
步骤5检查搜索条件是否达到退出准则,是则保存搜索到的解集并退出,否则转步骤3。
4.3 算法有效性分析
HGA的有效性体现在提高全局搜索能力和提升算法的收敛速度。根据HGA的思想,在编码阶段采用二进制编码方式可降低算法设计难度;在初始化阶段,以多样化的可行解作为初始种群,可在提高搜优概率的同时提升收敛速度;在下一代选择阶段,采用有目的等概率的混合式选择操作可提高全区域搜优概率;在交叉阶段,采用多轮多维度多点操作可提升探索新区域的能力;在变异阶段,通过较优新个体优先动态变异操作,可以进一步提升全局搜索能力并保证算法快速收敛。总之,HGA在每次迭代搜索过程中,都能保持种群的多样性和可靠性,从而为提高全局搜索能力和算法的收敛速度打下基础。
5 实验与分析
(1)软硬件环境
20个曙光天阔系列服务器,CPU型号为Xeon E5-2620V3,内存8 G,SATA硬盘300 G,操作系统为SUSE Linux Enterprise Server 15。
(2)核心参数设置
在综合考虑文献对参数取值的建议并基于多次重复实验的结果,参数设定为:r∪,r∩,rC∈(0.2,0.6)。划分权重中两个线性加权系数取值分别在0.35~0.65之间,且两系数之和为1[7-8],It0∈[80~100],N0∈[60~80]。
(3)场景模拟
将20个曙光服务器分成两个功能区,其中12个服务器随机放置在不同区域,用于仿真生产线及其所提交的服务请求(例如生产线数量及规模增加或减少,则服务请求量变大或变小),服务请求类型包括传输请求、存储请求、计算请求等。剩余8个服务器同样随机放置在不同区域,用于仿真工业边缘云和处理接入请求[15-17]。
(4)对比算法
为展示实验的客观性,分别选取智慧城市的边缘服务器部署算法(Edge Server Placement algorithm,ESP)[8]和自适应Cloudlet部署方法(Adaptive Cloudlet Placement Method,ACPM)[12]与本文HGA进行比较。
(5)测试指标
为体现实验的全面性,本文从多个维度验证HGA的性能:
1)期望负载偏差率(Expectation Load Deviation Rate,ELDR)
ELDR=(算法实际总负载-期望最小总负载) /
期望最小总负载。
该指标主要衡量各算法实际计算的总负载距离期望总负载的程度,值越小越靠近期望总负载。
2)期望服务延时偏差率(Expectation Service Delay Deviation Rate,ESDDR)
ESDDR=(算法实际总服务延时-
期望最小总服务延时) /期望最小总服务延时。
该指标主要衡量各算法实际计算的总服务延时距离期望总服务延时的程度,值越小越靠近期望总服务延时。
3)算法收敛率(Algorithm Convergence Rate,ACR)
ACR=(收敛延时均值-正常收敛均值) /
正常收敛均值。
该指标主要衡量各部署算法的执行效率和收敛速度。
4)解误差率(Solutions Error Rate,SER)
SER=(算法搜索到最优解均值-期望最优解) /
期望最优解。
该指标主要衡量HGA、精英遗传算法(Elite Genetic Algorithm,EGA)[18-19]与GA[14]的全局最优解搜索能力。
实验1通过不断增加仿真生产线数量并给定相应的部署总成本,测试各类部署算法的ELDR。其中,处于不同区域的12个服务器随机模拟功能各异的生产线,并由各生产线模拟数量不同的服务请求;剩余放置在不同区域的8个服务器分别模拟功能一致的工业边缘云,并由工业边缘云各自模拟计算生产线请求时的处理情况。
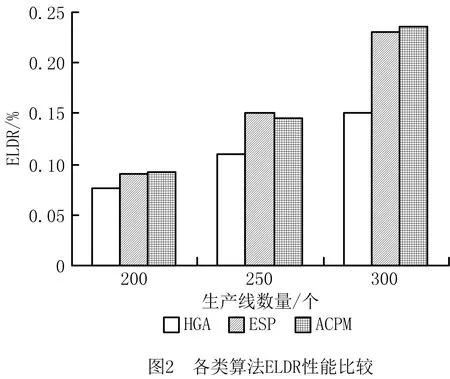
如图2所示,生产线为200个时,HGA的ELDR接近7.6%,ESP的ELDR接近9.1%,ACPM的ELDR接近9.3%,HGA相对其他两种算法分别降低了16.4%和18.2%。
生产线为250个时,HGA的ELDR接近11%,ESP的ELDR接近15%,ACPM的ELDR接近14.6%,HGA相对其他两种算法分别降低了26.6%和24.6%。
生产线为300个时,HGA的ELDR接近15%,ESP的ELDR接近23%,ACPM的ELDR接近28%,HGA相对其他两种算法分别降低了34.7%和36.4%。
实验2基于实验1的环境,测试各类部署算法的ESDDR。
如图3所示,生产线为200个时,HGA的ESDDR接近9.1%,ESP的ESDDR接近11.8%,ACPM的ESDDR接近11.5%,HGA相对其他两种算法分别降低了22.8%和20.8%。
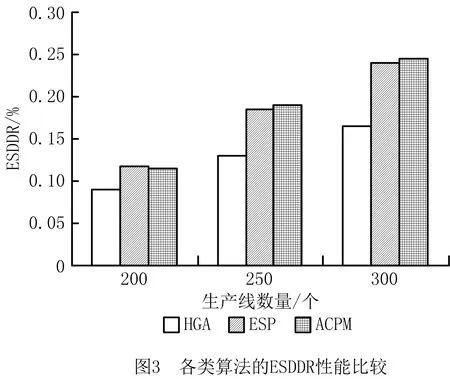
生产线为250个时,HGA的ESDDR接近13%,ESP的ESDDR接近18.5%,ACPM的ESDDR接近19%,HGA相对其他两种算法分别降低了29.7%和31.5%。
生产线为300个时,HGA的ESDDR接近16.6%,ESP的ESDDR接近23.9%,ACPM的ESDDR接近24.6%,HGA相对其他两种算法分别降低了30.5%和32.5%。
由实验1和实验2可见,随着生产线规模和数量的增加,各算法的ELDR和ESDDR均相应增加。基于K-median的ESP主要根据移动用户的异构应用需求分类部署,但生产线的生产任务同构无法有效进行分类部署,降低了ESP搜索最优解的性能;ACPM主要根据地理信息位置预测移动用户的迁移轨迹并预留多个潜在部署点,但生产线动态调整频率偏低,无法通过轨迹预测潜在部署点,降低了ACPM搜索最优解的性能。因此,HGA的性能相对较优。
实验3基于实验1的环境,测试各类部署算法的ACR。
如图4所示,生产线为200个时,HGA的ACR接近5.8%,ESP的ACR接近8.1%,ACPM的ACR接近7.7%,HGA相对其他两种算法分别降低了28.3%和24.6%。
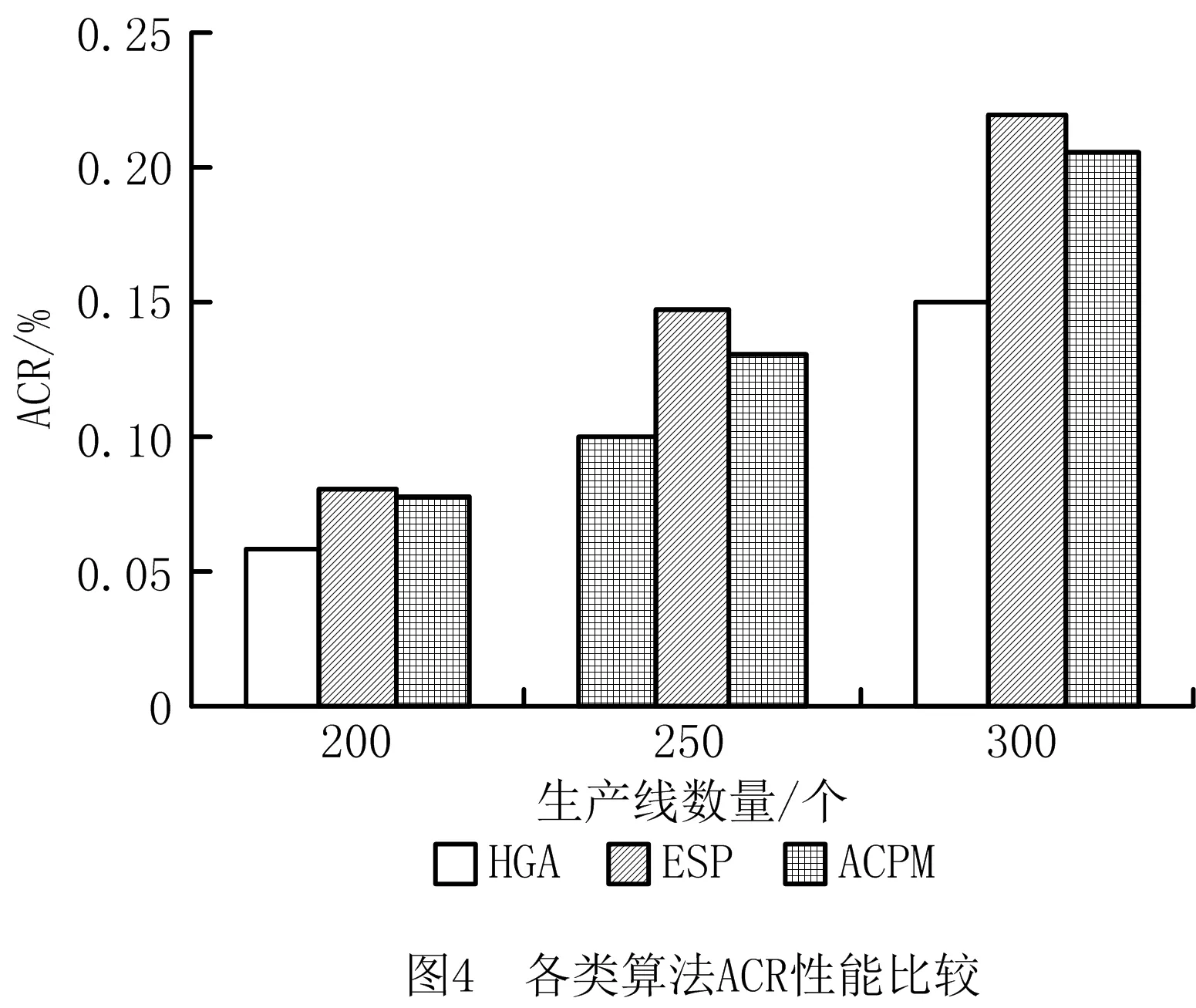
生产线为250个时,HGA的ACR接近10.1%,ESP的ACR接近14.6%,ACPM的ACR接近13.1%,HGA相对其他两种算法分别降低了30.8%和22.9%。
生产线为300个时,HGA的ACR接近15%,ESP的ACR接近22%,ACPM的ACR接近20.6%,HGA相对其他两种算法分别降低了31.8%和27.1%。
由实验3可见,随着生产线规模和数量的增加,各算法的ACR均相应增加,以ESP增加幅度为最大,主要原因是ESP的分类策略(基于K-median思想)有较大的时间开销;ACPM轨迹预测策略的时间开销得益于生产线动态调整的频率较低,因轨迹预测收敛性较快而提升了算法的执行效率,但相对于HGA,其收敛性仍然较差。
实验4基于实验1的环境,测试HGA,EGA及传统GA的SER。
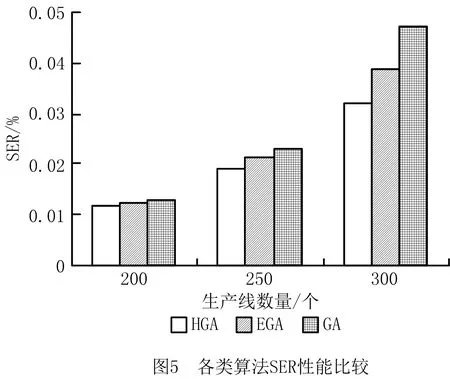
如图5所示,生产线为200个时,HGA的SER接近1.2%,EGA的SER接近1.25%,GA的SER接近1.3%, HGA分别降低了4.16%和7.6%。
生产线为250个时,HGA的SER接近1.9%,EGA的SER接近2.12%,GA的SER接近2.3%, HGA分别降低了10.3%和17.3%。
生产线为300个时,HGA的SER接近3.2%,EGA的SER接近3.9%,GA的SER接近4.7%, HGA分别降低了17.9%和31.9%。
由实验4可见,随着生产线规模和数量的增加,各算法的SER均相应增加。以GA为例,其思想是随机产生初始种群,采用轮盘赌策略选择种群,交叉和变异时完全采用随机策略,这些操作将导致搜索速度变慢且易陷入局部最优。而EGA的思想在于每次迭代时,尽可能将较优解保留至下一代种群中,这样虽然能够提高收敛性,但是易陷入局部最优,再加上随机初始化种群、随机单点交叉及基本变异等操作,进一步限制了其搜索准度。因此,HGA的全局最优解搜索能力较优。
通过以上多组实验测试说明,HGA在优化传统GA弊端(早熟)的同时,相对已有科研成果,能够更加有效地对工业边缘云进行部署,为后期工业物联网的场景应用打下了基础。
6 结束语
以物联网为代表的新一代信息技术与制造业深度融合是学界和业界共同关注的话题,本文以此为背景,讨论了工业物联网与边缘端数字孪生深度融合的一个基础性问题——工业边缘云部署问题,分析了其探讨意义及价值,从优化论角度将该问题转化为带约束的最小子集划分问题,并针对该NP难问题提出一种HGA。算法以可行解作为初始种群,经过混合选择法、多维度交叉和优先变异等操作,能够较好地求解实际问题。通过对比实验,算法在ELDR,ESDDR,ACR,SER 4方面均有较优的性能。
虽然本文所提算法在解决工业边缘云部署问题上表现良好,但是仍有需要改进之处:①在新一代信息技术加持下,生产线和生产设备必将自动化、智能化。在产能驱动下,生产线和生产设备会根据实际情况智能化动态调整,如何实现自适应性动态工业边缘云部署是今后工作的一个重点。②随着产业分工的全球化,跨国型企业生产线规模必将延伸,本文算法所支持的生产线规模依然偏小,未来如何支持上千个生产线的工业边缘云部署是今后工作的另一个方向。
