史书多维知识重组与可视化研究
——以《史记》为对象
2022-03-11王东波黄水清邓三鸿
张 琪,王东波,黄水清,邓三鸿
(1.南京大学信息管理学院,南京 210023;2.南京农业大学信息管理学院,南京 210095;3.江苏省数据工程与知识服务重点实验室,南京 210023)
1 引 言
浩如烟海的史籍承载着我国悠久的历史文化。在古籍保护与利用引起广泛重视的背景下,尽管史籍电子化已经取得了大规模的成果,但是目前大众化利用程度仍然较低。
从信息获取的角度来看。一方面,艰涩的古汉语文法、深厚的历史文化背景为阅读史书原文设立了门槛;另一方面,史书体裁自身维度的单一性筑起了从时间、地点、人物等多种维度出发获取信息的壁垒。例如,编年体史书以时间为主线展开,便于以时间为索引定位所需信息,却难以从中获取某一人物或某一地点的全部史料。而在纪传体、纪事本末体史书中,因采用帝王年号、王公即位等中国古代纪年法,时间描述的歧义、共指、省略、模糊等特性,使得查找某一时间点的历史事件非常困难。
首先,尽管目前史籍电子化已经取得了大规模的成果,但是大部分古籍知识库仅支持浏览和字符串检索,利用方式处于比较原始的纸质替代状态[1]。而上述问题的解决需要完成史籍知识重组与形式再造,支持从时间、人物、地点等多个维度出发,查询并以图结构的方式展示承载于史书之中的结构化知识及对应原文,从而易于被人们理解[2],便于语义计算的展开。然而,目前的相关研究多在知识来源与可视化呈现方面与史书原文相割裂,不利于拉近读者与经典史籍之间的距离。其次,尽管有研究从史书原文中获取结构化知识,但从所采用的方法来看,大部分研究通过人工标注或正则匹配的方法获取语义知识。尽管有部分研究探讨了自动获取方法,但复杂的本体建模在现有的技术条件下难以实现高质量自动填充,而简单的三元组抽取则容易丢失历史事件的时间等重要维度。
综上分析,目前史籍知识重组与形式再造主要存在以下痛点和难点:(1)知识重组:从史籍原文出发,综合考虑史书知识表示的充分性与自动抽取的可行性,实现史书多维知识抽取、融合、存储与知识库自动构建;(2)形式再造:结构化知识与所对应的史籍原文相结合的多维度可视化呈现。本研究围绕上述问题,试图基于知识组织、古籍智能处理技术、可视化等相关理论、方法和技术提出并实现史书多维知识重组与可视化系统,最后将其应用于我国第一部纪传体史书《史记》中。
2 相关研究与实践梳理
史书多维知识自动重组与可视化隶属于数字人文的研究范畴,主要涉及史书体裁的演变、历史领域语义知识库构建以及古籍智能处理三个研究领域。本节对上述领域的实践和研究进行回顾,以借鉴已有研究的可取之处并发现其不足。
2.1 史书体裁与历史事件描述维度
在我国历史上的几种主要史书体裁中,最早出现的是编年体。编年体史书以时间为主线展开的方式便于展现历史的动态变化,同时也存在一定的缺陷[3]。例如,与重大历史事件密切相关的人物事迹无法得到描述,无法展现不同时间发生事件之间的联系等。此后,又出现以人物为主线的纪传体、以国家(诸侯国)为主线的国别体、以地点为主线的地方志、以事件为主线的记事本末体、以典章制度为主线的典制体。然而,每本史书在写就时只能采用一种体裁,史书内容只能就人物、时间、地点、事件等一条主线展开。采用一种体裁,从对历史记录的角度而言,难以反映复杂的历史进程[4]以及人与社会的复杂联系[5];从信息获取的角度,则使得读者难以从其他维度入手获取相应信息。
为了弥补单一史书体裁组织史料的缺陷,史学家采用丰富支线和人工辅以多维度主线等方式加以改进。司马迁在纪传体史书《史记》中引入年表,但年表中只能概述历年大事,而无法涵盖本纪、世家、列传中丰富的历史知识,并且大部分纪传体史书中并未包含年表这一体例。东汉史学家荀悦将“纪传体的《汉书》删改成编年体的《汉纪》”[5],但我国史书规模巨大,难以人工完成对所有史书的重写。北宋司马光在编年体史书《资治通鉴》的撰写中增加与主体事件极为密切的人物事迹,但传记中的时间与编年体中的人物信息均为支线,尽管多面的历史知识得以纳入史书之中,但多维信息获取的问题未能得到解决。
2.2 历史领域语义知识库的构建
不同于史料全文数据库,实体级知识库的构建包含历史人物、地点、官职、时间、著作等实体以及实体之间的关系。尽管目前自动从史籍原文中获取结构化知识的研究较少,但人工构建实体级历史知识库的研究早在20世纪便已萌芽。研究宋代社会经济史的郝若贝教授从20世纪80年代开始将宋代历史人物的生卒年、亲属等信息手动录入计算机,以便自己的研究使用,之后将其捐赠给哈佛燕京学社,并逐渐演变为中国历代人物传记资料库(China Biographical Database,CBDB)[6-7]。CBDB搜集了公元7世纪至19世纪将近40万个历史人物的传记资料,包含人物姓名、地址、官职、著作、亲属关系和社会关系等历史人物信息[5],目前主要知识来源是历史人物资料索引。历史知识APP“全历史”[8]提供关系图谱展示实体之间的关系,其知识主要来源是百科及用户人工补充。武汉大学董慧等[9]从文献语义分析的角度出发设计了一个史籍语义分析系统,该系统主要采取人工标注的方式获取实体间关系。
2.3 古文智能处理
古文智能处理是指对数字化后的古籍原文进行自动断句、词汇处理、语义和句法标注,自动获取史书中的结构化知识并实现知识融合,主要涉及语义三元组抽取、实体消歧以及共指消解,其受到断句、词汇处理及句法分析等前序任务效果的影响。目前,古汉语领域的自动断句以及分词、词性标注、实体识别等词法分析经过近十年的研究已经取得了较好的效果[10],MARKUS[11]等古籍实体半自动标记及自动标记平台已较为成熟。古汉语自动句法分析方面,冯秋香等[12]从自然语言处理的角度出发梳理了《左传》中的句法结构,基于Perl构建的句法分析器的召回率达到88.8%,但语料覆盖范围较小,目前仍没有公开可用的古汉语句法分析器。
从英语、现代汉语语义三元组抽取的相关研究来看,基于机器学习的抽取系统效果受句法特征的影响较大[13],因此,古汉语领域语义三元组的抽取也在初期受到一定限制。陈雅玲[14]采用基于触发词匹配的方法获取实体关系类型,在此基础上基于条件随机场模型获得实体对,但古汉语言简意赅的特点导致实体关系类型识别的召回率较低。
实体链接包括实体消歧和指代消解,是结构化数据三元组知识互联的前提,古汉语方面,于丽丽等[15]探究了基于条件随机场的古汉语词义消歧。
2.4 已有研究的贡献与不足
结合叙事维度回顾中国历史上的主要史书体裁,可知古代史学家从时间、人物、事件、典制、地点等不同维度出发,确定了编年体、纪传体、国别体、纪事本末体、典制体、地方志等史书体裁,并采用引入支线、辅以主线、体裁改写等方式解决单一体裁难以反映复杂社会生活的问题。然而,引入支线不利于读者集中获取相关信息。在史书中增加以其他维度为主线的体例,如在纪传体史书中引入年表可以较为有效地缓解信息获取问题,但这种方式在史书中较为少见。而人工构建或人工体裁改写较为困难,并且鉴于我国史书数量之多,难以人工完成对所有史书的处理。
从增强读者与史书原文关联的角度来看,已有的历史领域语义知识库的构建存在以下问题:首先,从知识来源来看,已有历史领域知识库主要从索引、百科而非史书原文中获取具体实例,因此一定程度上与史书原文相割裂,无法起到拉近普通读者与史籍原文的作用;其次,从基于史书原文的知识抽取方法来看,一方面,目前具体知识实例、尤其是实体之间的语义关系主要来自人工标注,难以向大规模史书扩展;另一方面,目前自动化抽取方面主要限于三元组知识,人物关系等随时间的动态变化无法得以体现;最后,知识库可视化层面,已有研究或实践均将重点置于对结构化知识的展示,割裂了与史书原文之间的关联,难以拉近读者与史书原文之间的距离。
基于上述分析,本研究从史书原文出发,提出并实现史书多维知识重组与可视化系统,引入古籍智能处理领域的相关技术与方法,在考虑知识动态变化的基础上,从史书体裁所涉及的人物、时间、地点、典制等不同维度入手重组史书知识并完成可视化,以期缓解由艰涩的古汉语文法以及史书线性的展开方式所带来的信息获取问题。
3 史书多维知识重组与可视化系统
本研究从满足史书信息获取的需求出发,提出史书多维知识重组与可视化系统框架。系统框架如图1所示,主要包括史书多维知识建模、史书多维知识库构建以及史书多维知识可视化三部分。

图1 史书多维知识重组与可视化系统框架
系统各部分承担着不同的作用。基于不同史书体裁所采用的主线如时间、人物、地点等不同维度展开史书知识建模是史书知识重组的前提和基础;基于古籍智能处理技术的多维知识库构建是史书多维知识重组实现自动化及规模化的前提,其中,历史事件时间轴自动生成是使纪传体、国别体、纪事本末体等体裁的史书以时间为主线展开的关键技术,三元组知识抽取是将史书知识以人物、地点、社会集团等维度为中心展开的关键技术,史书知识融合是不同来源的知识相互连接的关键技术,史书知识存储方式则直接用与知识库后续的应用场景相关;史书多维知识可视化是同时以多个维度呈现史书历史知识的关键手段。下文将依次对系统各部分所涉及的主要理论、方法与技术进行阐述。
3.1 史书多维知识建模
知识建模又被称为本体构建或知识体系构建,旨在通过定义和描述事物、概念、属性和关系对目标领域知识进行合理组织与描述。史书多维知识建模需要从人物、时间、地点多个维度出发对史书中知识实例及实例之间的语义关系加以概括性的描述和定义,是史书知识以多个维度展开的基础。
SPO(subject-predicate-object)知识表示模型与RDF(resource description framework)兼容的同时,能够统一表示实例型数据和描述型数据,目前DB‐pedia[16]、Zhishi.me[17]等知识图谱均采用SPO知识表示模型。然而,SPO知识表示模型难以建模复杂知识。对于史书多维知识建模而言,其无法展现知识的时间信息以及知识来源。时间是信息空间的重要维度,尽管目前已有知识图谱中以SPO三元组的形式建模人物出生时间、死亡时间等常见的实体与时间之间的关系,但三元组知识所构成的事实(facts)的时间信息被忽略,例如其难以表示人物身份随时间的变化。
为了弥补SPO在表示现实世界知识方面的缺陷,Hoffart等[18]提出SPO-X知识表示模型,并在YAGO2中将X具体化为TL(time,location),在已存在时间和地点实体用于描述实体存续时间、固有地点的基础上,为事实(facts)增加时间和空间维度,从而描述事实的时间、空间变化。
本研究从史书多维知识重组的需求出发,将X具体化为TS(time,source text),保留实体与时间的关系从而表示实体消亡时间的基础上,该知识表示模型可以为由SPO三元组组成的事实提供释明其相关时间以及所依据原文的能力。SPO-TS(subject property object-time source text)知识表示模型及具体应用示例如图2所示。
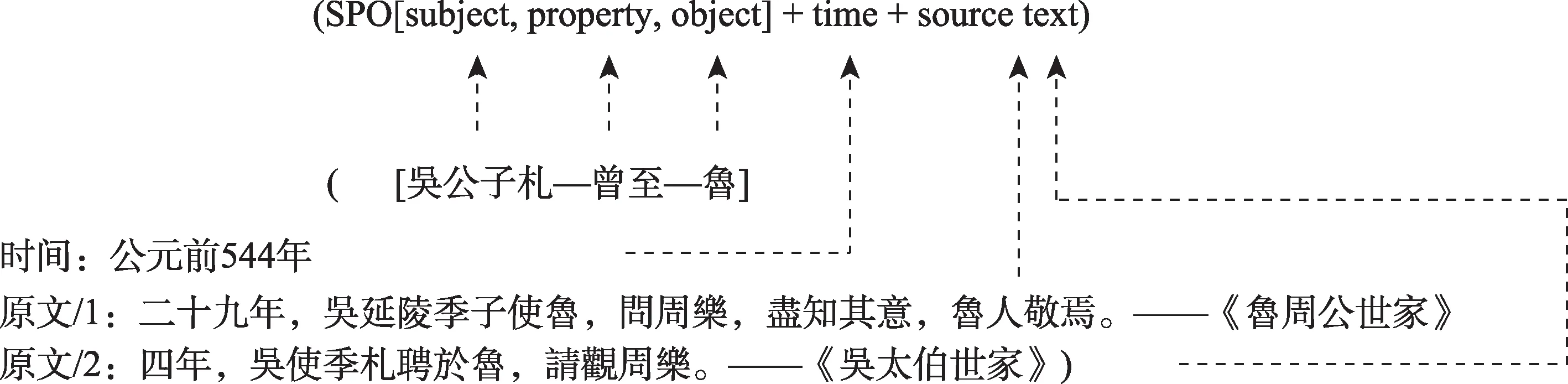
图2 采用SPO-TS表示史书知识示例
3.1.1 核心概念及其数据属性
本研究在第2.1节中已经列举了主要的史书体裁以及各种体裁所采用的叙事主线,本研究将编年体、纪传体、地方志(志书体)、国别体及官制史(典制体)五种史书体裁的主线作为重组史书知识的维度,并对其内涵进行一定的缩小或延伸。
(1)人物(people):纪传体史书以历史上的重要人物为中心展开,此处的人物包括《史记》中的所有人物,每个人物被分配以唯一的ID,避免知识库中的人名歧义,其属性包括主称谓与别名。
(2)时间(time):编年体史书以时间为主线展开,为使编年体、纪传体、纪事本末体等不同体裁的史书中的知识内容能够按时间顺序排列,须规范知识内容涉及的时间实体属性,既包含公元纪年,也包含中国古代纪年(包括王公即位纪年、帝王年号纪年)。
(3)地点(places):地方志将地点分门别类继而展开,地方志中的地点主要根据行政区域划分。本研究中的地点包括《史记》中出现的行政区域与自然地理,行政区域如“雍林”“葵丘”等,自然地理如“河”“山”等。
(4)社会集团/团体(groups):国别体按国家(诸侯国)组织史书内容,而国家(诸侯国)与家族、学术流派属于不同层面的社会集团,因此将社会集团作为核心实体以满足更多的信息获取需求。上古汉语标记语料库(http://lingcorpus.iis.sinica.edu.tw/ancient/)将其社会集团分为国家、家族和学术流派三种,各类别具体示例如表1所示。

表1 《史记》中三种主要的社会集团类型及实例
(5)职官(official/postings):官制史隶属典制体[19],记载并评述历史上的职官制度。《史记》中记载了大量的职官名,为历史学领域对职官制度的研究提供了丰富的材料。主要包括中央官制、郡县官制、诸侯国官制、爵禄制度、秩禄、选举制度等不同的职官制度及所涉及的职官。本研究的目的是从史书原文中提取职官实体及相关人物、社会集团,之后可引入官制史中对职官职能的描述,从而帮助读者进一步获取丰富的背景信息。
3.1.2 核心概念间的关系
在确定史书知识重组的五个维度,即五个核心概念的基础上,需要进一步确定五个核心概念之间的关系。
图3给出了产生关系的概念对,具体关系类型在http://www.shijigraph.com/help中给出。其中,人物与人物、人物与地点、人物与社会集团以及社会集团之间存在较多细分关系,下文将进一步展开说明。

图3 具有关系的概念对
(1)人物-人物:人物与人物之间的关系包括人物社会关系和人际态度倾向。其中,人物社会关系(social relationships)又分为亲属关系和非亲属关系,血缘亲属关系如父母、子女、兄弟姐妹、祖、孙等不具有时间属性,而婚恋等非血缘亲属关系则可能随时间发生变化,因此具有时间属性;非亲属关系包括上下级、师生、帝位更替等。
发生交互的历史人物之间往往呈现出某种态度倾向,认知心理学学者Heider[20]将人对人以及人对事的态度(attitude)分为积极(positive)与消极(negative)两种类型。本研究将史书中所描述的人物之间的态度称为人物态度倾向,正向关系主要包括推荐、欣赏、支持等,负向关系则体现为批评、弹劾、反对、攻击等。需要注意的是,人物态度倾向往往具有动态性,因此必须结合时间以及具体语境加以分析。本研究借助SPO-TS知识表示模型,赋予三元组时间属性呈现人物态度倾向的动态变化,并给出具体知识来源进一步对其进行解释说明,如图4所示。
(2)人物-地点:本研究所包含的人物与地点之间的关系类型主要有籍贯、居、辖、逃奔、卒于和其他六种。除籍贯外,人物地理位置的变化往往伴随着时间的变化。
(3)团体-团体:社会集团之间既存在从属关系,也往往具有一定态度倾向。在Heider[20]提出态度关系结构的基础上,Doreian等[21]将二战之后各国之间的结盟与敌对符号化,从而探究国际关系的变迁。本研究将其引入对先秦时期社会集团间关系的描述中,并将其命名为团体态度倾向。其中,积极倾向主要包括国家(诸侯国)间的结盟、联姻等,消极倾向则包括国家间战争、竞争、冲突等。团体态度倾向也具有动态性,因此同样受时间信息的约束并由知识来源提供具体情境。
3.1.3 事实属性
本研究采用上文中所定义的SPO-TS知识表示模型为所有三元组附加原文信息,为部分三元组附加时间信息,具有时间信息的所有三元组关系类型在链接http://www.shijigraph.com/help中给出。
图4给出了人物态度倾向随时间的变化的实例。由此可见,采用SPO-TS知识表示模型,可以结合时间和原文较为完整地呈现齐桓公小白对管仲的态度倾向由消极转向积极的过程。

图4 SPO-TS表示动态知识示例
3.2 基于古籍智能处理技术的史书多维知识库构建关键技术
3.2.1 多维知识获取
(1)历史事件时间轴自动生成:作为记载历史事件的重要维度,时间识别的准确性和全面性异常重要。首先,除编年体史书外,其余史书的时间信息均散落于文本之中,而中国古代时间表达存在歧义(如“桓公二十七年”)、共指(如“缪公任好元年”和“秦穆公元年”)、省略(“九年……”)、模糊(“昔者”)等特点,为后续处理带来了较大困难。其次,若仅从单个句子或段落等粒度抽取时间实体而不进行规范化处理及事件时间对齐,则将会导致大量具有隐式时间表达式及继承前文时间信息的句子被忽略。
为此,本研究构建了时间维度下的史籍自动重组系统,为史书中的事件句分配语义唯一、可计算的统一时间表达式。系统包含两个模块:第一个模块识别史书原文中所包含的时间描述,继而经过时间描述规范化、时间表达式链接实现时间描述的语义解析;第二个模块识别史书中的事件句,并将事件句关联至经过语义解析的时间描述。通过上述两层语义关联,使史书中的事件句获得无歧义的时间信息。
(2)三元组知识自动抽取:三元组知识抽取又被称为关系抽取(relation extration),目的在于从非结构化文本中获取实体对以及实体对之间的语义关系,获得的语义三元组根据中心节点整合后可获得多元组知识。三元组知识抽取是文本挖掘和信息抽取的核心任务[22],是知识图谱构建的关键技术[23],也是将史书知识以人物、地点为中心展开的关键技术。从语言的角度来讲,古代汉语具有言简意赅的特点,而记载几百乃至上千年历史的史书信息量则更为密集,统计显示白话文版的《史记》字数是大约是《史记》原文的1.617倍[24],这一特点也使得古汉语知识自动抽取难度更大。以《史记·吴太伯世家》的第一个句子“吳太伯,太伯弟仲雍,皆周太王之子,而王季歷之兄也”为例,短短25个字中存在6条人物关系,其中包含父子、兄弟等多种知识类型,且存在实体边界重叠、无触发词等现象。从技术角度来讲,以往基于SVM(support vec‐tor machines)、核函数等机器学习模型的方法依赖于句法特征,而目前古汉语领域暂时没有可用的句法分析器。
为此,本研究构建了基于深度学习模型BERT(bidirectional encoder representations from transform‐ers)的史书三元组抽取系统,以句子为单位获取史书中的三元组知识。首先,人工标注《史记》原文部分篇章以供前期为模型选定及模型训练提供基础,统计发现古汉语具有单个句子中所含知识类别多、数量多的特点,并且具有语义关系的实体对在句子中的距离更近,结合目前古汉语领域没有可用句法分析器的现状,本研究最终采用BERT作为基础模型,并添加分词与词性特征对其进行改进。然后将模型的输出层通过池化(pooling)转化为句子级特征输出,并将激活函数设置为sigmoid构建基于多标签分类的知识分类模型;将知识类别向量融入模型输入,并将激活函数设置为softmax构建基于序列标注的实体对抽取模型,通过分步的方法解决史书三元组知识抽取问题。最终,对系统效果的验证发现知识分类模型的F值达到84.80%,论元角色抽取模型的F值达到75.50%,这说明系统达到了较好的抽取效果。
3.2.2 知识融合
知识融合是指将不同来源、不同语言、不同结构的知识进行融合。对于本研究而言,主要包括实体融合(实体消歧和共指消解)和SPO-TS实例融合两部分。
实体层面的知识融合包含实体消歧与共指消解,本研究的解决方法如下:首先,构建了同名词典与别名词典,本研究从课题组前期已经实现电子化的《汉学引得丛刊》中获取了其中所包含的别名与同名信息,并结合自动构建的方法进行补充,从而构建了实体歧义词典与实体别名词典。例如,通过拆分“齐桓公小白”与“齐桓公午”可知,“桓公”“齐桓公”两种称谓均存在歧义;而齐桓公小白具有别名“桓公”“齐桓公”“小白”“桓公小白”。在此基础上,通过歧义词典确定抽取自原文的实体是否具有歧义。对于存在歧义的实体,结合上下文信息将其指向实体主称谓;若不存在歧义,则通过别名词典判断其是否具有别名,并映射至唯一主称谓。
SPO-TS知识实例层面的融合则主要涉及合并与去重,具体解决方法如下:若三元组部分与发生时间均相同,则三元组部分合并同时保留所有知识来源;若实体对及知识类型相同但发生时间不同,则视为不同的知识分别存储。
3.2.3 知识存储
知识存储主要有基于内存、文件、关系型数据库、原生RDF数据存储系统和图数据库等五种方式[25-27]。一方面,由于使用图数据库存储知识,不仅更加符合节点、节点属性、关系表达逻辑,还可以为边分配属性[28],与SPO-TS知识表示模型相契合;另一方面,从知识的计算与推理的角度来看,Neo4j[29]等图数据库支持社团检测(community de‐tection)、标签传播(label propagation)、中心节点计算(centrality algorithm)等图挖掘算法,便于史书知识的进一步挖掘与利用。综上考虑,本研究采用图数据库Neo4j完成史书多维知识的存储。
3.3 史书多维知识可视化
在史书多维知识库的基础上,本研究借助可视化技术实现史书知识的多维展示,不仅能够拉近普通读者与史书的距离,更允许从不同维度出发探索史书中包含的历史知识。如何展现知识背后的知识体系以及实现知识与原文的链接是可视化平台构建应考虑的重点问题。
本研究结合不同类型实体的知识特点,设计了三种呈现方案,即中心视图、时间轴视图和关联视图,实现以不同实体为中心的、与史书原文相关联的结构化知识呈现方案。由于对可视化的说明结合具体实例更加直观,因此,相关内容在第4.2节中展开说明。
4 《史记》多维知识重组与可视化
纪传体史书以历史上的重要人物为主线,大量未成传人物的信息散落于各卷之中,难以获取。因此,需要从人物、时间、地点等维度出发完成重组。《史记》是我国历史上第一部纪传体史书,记载了从上古时期至西汉汉武帝时期长达三千多年的历史事件,被称为中国古代二十四史之首。本节将上文提出的史书多维知识重组与可视化系统应用于《史记》,以证明系统的可行性。
本研究以上文提出的SPO-TS知识表示模型作为史书知识语义化和形式化描述的基础框架,基于上文所确定的史书中的核心概念以及概念之间的关系,完成史书多维知识建模。下文主要介绍《史记》多维知识库构建及可视化呈现的具体过程和结果。
4.1 基于古籍智能技术的《史记》多维知识库构建
4.1.1 语料采集与预处理
首先,本研究获取了包含年表及段落信息的《史记》全文、具有分词与词性标记的《史记》语料以及古代职官辞典,并基于《史记及注释综合引得》获得了人物同名词典与人物别名词典,具体信息如表2所示。

表2 《史记》多维知识处理基础语料
采用机器学习、字符串匹配等方法整合上述基础语料,获得具备段落、句子信息以及分词、词性、官职名标记的《史记》语料,共130卷,包含十二本纪、三十世家、七十列传、十表、八书,共45109个句子,680941个字(含标点符号)。
4.1.2 《史记》多维知识获取与融合
采用本课题组前期开发的史书时间轴自动生成系统,将史书中的事件句定位在时间轴上,实现以时间为主线的史书内容重组,结果示例如图5所示。

图5 《史记》历史事件时间轴自动生成示例
本纪、世家、列传、书所涉及的111卷《史记》语料共有31130个句子,共识别非模糊型时间表达式3564个,历史事件时间轴自动生成系统共为19868个事件句分配了时间信息,最终有16902个事件句定位于公元时间轴上。随机抽取本纪、世家、列传部分各一卷进行人工核验,显示其准确率均达到89%以上。
基于本课题组前期开发的三元组知识抽取模型以及触发词抽取模型获得了《史记》中的三元组知识及对应的触发词。共获得句内三元组实例17709个,具体示例如图6所示,其中70%的三元组实例包含触发词。此外,人工补充跨句子的三元组知识589个。在此基础上与事件句以及前序为事件句所分配的时间信息相结合,形成SPO-TS知识实例,继而完成实体与SPO-TS知识两个层面的知识融合。

图6 三元组知识抽取结果示例
采用上文所描述的知识融合方法将前序抽取得到的27341例人名进行消歧。通过歧义词典判定共6267例人名存在歧义,占所有人名的22.92%。通过上述方法将4421例歧义人名链接至其主称谓,例如,将《吕不韦列传》中的“夏姬”链接至夏太后,将《襄侯列传》中的“昭王”链接至秦昭襄王。此外,共8304例人名通过别名词典链接至其主称谓,占全部人名的30.37%。从而完成了SPO-TS实例层面的合并与去重。
4.1.3 知识存储
本研究结合前期开发的历史事件时间轴自动生成工具和三元组知识自动抽取工具获取了《史记》中的多维知识,继而通过知识融合将散落的知识相连接,最终将获取的所有知识存储于开源图数据库Neo4j中,呈现效果如图7所示。
4.2 《史记》多维知识可视化平台
本研究构建了《史记》多维知识可视化平台(http://www.shijigraph.com/),该平台支持以《史记》中出现的任意人物、时间、地点、社会集团、职官为检索对象,呈现相关联的历史知识和原文,以期缓解读者多维的信息获取需求与《史记》以人物为中心展开的矛盾,拉近普通读者与经典史籍之间的距离。
用户在前端输入字符串,后台经过简转繁、实体链接、相似度匹配、知识库数据获取与呈现等步骤以可交互图的方式返回检索结果。同时,本研究根据实体知识特点的共性与差异性,设计了不同的呈现方案。
4.2.1 以人物、地点、职官、社会集团等实体为中心的两种呈现方式
由于人物、地点、职官、社会集团等实体,一方面与其他实体产生多类型语义关联,另一方面,许多关联如态度倾向等具有随时间动态变化的特点。因此,本研究设计了中心视图和时间轴视图两种呈现方式。下文将以人物为例,展示并说明两种视图的机制和相关功能。
(1)中心视图:中心视图是以人物、地点、社会团体、职官等实体为中心呈现实体相关知识。图8以春秋时期吴国延陵季子为例,其事迹记载于《吴太公世家》《郑世家》《晋世家》《赵世家》等不同卷册之中。所涉及的知识类型包含人物关系、地理轨迹、官职变迁以及关联集团等。中心视图以某一具体实体为中心,从顶级关系类型开始层层细分,直至关系类型的最小单位,引导用户由粗至细地了解实体相关知识。
考虑到呈现结果的密集度,每种关系类型仅呈现1~2条知识,点击关系类型节点如“亲属”,将在弹框中呈现延陵季子的所有亲属。同时,将指针移向关系连接线,将显示该条知识的具体出处,从而与史书原文相关联。
(2)时间轴视图:时间轴视图呈现《史记》中任意人物、社会集团等实体随时间的动态变化。图9以时间轴的形式呈现了记载于《史记》多卷册当中的延陵季子(季札)的生平信息,时间轴最上侧是其父母兄弟等不具有时间属性的知识如亲属,之后则按年份依次呈现人物发生的事件,直观地展现实体随时间的动态变化。同时,两侧展现了知识来源,从而与《史记》原文相关联。

图9 时间轴视图示例(延陵季子检索结果部分截图)
4.2.2 时间知识的呈现
对于时间的检索,平台支持以公元时间为检索式,以关联视图的形式返回与该时间点相关联的所有历史以及对应的原文片段,便于读者概览该年份的重要人物与事件。例如,由延陵季子的时间轴视图(图9)可知,其于公元前548年封于延陵,图10是在系统中输入公元前548年,所展现出的记载于《齐太公世家》《晋世家》等各卷中的当年事件,可以帮助用户了解当年各个诸侯国的动态,从而更加全面地看待历史。同样地,鼠标移至实体间连线可以查看知识出处。
5 总结与展望
5.1 总结
本研究创新性地采用知识组织、古籍智能处理等理论、方法和技术解决中国古代史籍的信息获取问题,理论意义和现实意义主要体现在以下两方面:一方面,本研究从史书体裁维度出发构建史书知识模型,有助于实现不同史书知识以人物、时间、地点、国家、职官等维度为中心互联,有效弥补了史书体裁主线限制所带来的信息获取问题,打破史书体裁限制所导致的信息获取壁垒;另一方面,本研究将晦涩的古汉语句子转化为更容易被人和机器所理解的结构化知识,并针对不同类型的实体提出可视化方案,从而呈现史书中的历史知识,并特别注重于史书原文的关联,有助于拉近普通读者与经典史籍之间的距离,促进对中国古代经典史籍的利用。
针对当前相关研究的痛点和难点,本研究提出史书多维知识重组与可视化系统,并将其应用于我国第一部纪传体史书《史记》。该系统包含三个主要部分:①基于SPO-TS知识表示模型完成史书多维知识建模,从而更好地表示史书中的动态知识;②基于古籍智能处理技术完成史书多维知识库构建,提高了自动化程度;③考虑与史书原文的关联完成多维知识可视化,从而拉近用户与史书原文之间的距离。
5.2 展望
本研究提出了史书多维知识重组与可视化系统,并应用于《史记》。但仍有以下工作需要进一步探究:本研究以《史记》为例展开实践,多维知识建模主要考虑了纪传体、编年体等五种史书体裁的主线,未来将考虑纪事本末体以及典章体中军事、文化等多个维度的建模;数据获取主要考虑了《史记》单本史书,后续将扩大史书规模,并探究维基百科、百度百科等数据库中历史领域结构化数据与本研究所构建知识库的融合。
