基于主题词和LDA模型的知识结构识别研究
2022-03-11黄月张昕
黄月 张昕

关键词:知识结构;LDA模型;主题词;共词分析;数据挖掘
文献数据知识发现的研究对象一般是学术检索系统提供的科学文献题录,包含题目、作者、摘要、关键词、分类号、来源、参考文献等元素,这些元素分别作为检索系统的检索项提供检索入口,此外通用的学术检索系统还提供了包含题目、关键词、摘要3种元素构成的“主题词”。
知识结构(IntellectualStructure),指根据某一领域的科学文献进行分析,通过对基于某种关系构成的文献矩阵进行聚类而得到的组群及其关系。其中,每一组群对应该领域的一个研究子领域(或称研究主题)[1]。
针对科学文献题录信息进行知识结构识别是文献计量分析的一项重要任务,有助于帮助该领域的研究者了解研究主题及其关系。相比于关键词,学术检索系统中的主题词更能反映作者关于这篇文献主旨的概括。与传统的知识结构识别方法相比,LDA模型可以有效挖掘文献词语之间的语义关系,弥补传统文献计量在词语间处理能力的不足,对题目、摘要等长文本进行主题提取可以在更大程度上保留文献原始信息,能在一定程度上解决关键词无法很好概括文献信息的问题。本文探索基于主题词和LDA模型的知识结构识别,以数据挖掘领域顶尖期刊论文为例,并通过实验证明了其有效性。
1相关工作概述
1.1知识结构识别
传统学科知识结构识别方法是二步式的,即首先构建文献元素相似性矩阵,然后对该矩阵进行结构识别。常见文献元素相似性矩阵构建方法包括:文献共被引、作者共被引、文献耦合、作者文献耦合和共词分析等。这些思想已被广泛应用于知识结构识别,并获得了有效性验证。其中,通过共同词语联系到一起的文献可能表示一个共同的研究主题[2],共词分析常以高频关键词作为分析对象,在研究过程中没有涉及到文本中包含的语义信息,得到研究结果比较粗略。
越来越多的学者开始利用主题模型构建方法,对文本语义内容进行分析,对学科主题进行研究。隐含狄利克雷分配(LatentDirichletAllocation,LDA)模型,是一种比较成熟的主题模型[3],是一种无监督学习技术,可被用来识别大规模文档集中潜在主题信息,与针对某一领域进行知识结构识别的本质一致。LDA已被广泛用于科学文献情报分析,既包括主题识别[4]、主题演化[5]、新兴主题发现[6]、学科交叉主题识别[7]等将LDA应用于不同领域的研究,也包括不同语料下主题抽取效果分析[8]、最优主题个数确定[9]等利用LDA优化主题识别研究。
1.2LDA模型
LDA模型,在2003年由BleiDM等[10]提出认为一篇文档是由一组词组成的集合,词与词之间没有前后顺序关系,且语料库中的文档也没有顺序关系。它是一个关于文档、主题、词语的3层贝叶斯概率生成模型,其核心思想是把文档看成隐含主题的一个概率分布,主题看成词语的一个概率分布。文档到主题服从多项式分布,主题到词服从多项式分布,而该多项分布的参数服从Dirichlet分布。
LDA模型首先由Dirichlet分布得到主题分布的参数的分布,然后随机生成一个文档的主题分布,之后在该文档的每个位置,依据该文档的主题分布随机生成一个主题;然后由Dirichlet分布得到词语分布的参数的分布,再得到主题的词语分布,在该位置依据该主题的词语分布随机生成一个词语,直到文档的最后一个位置,生成整个文档;最后重复以上过程,生成所有的文档。
2研究设计
2.1研究思路
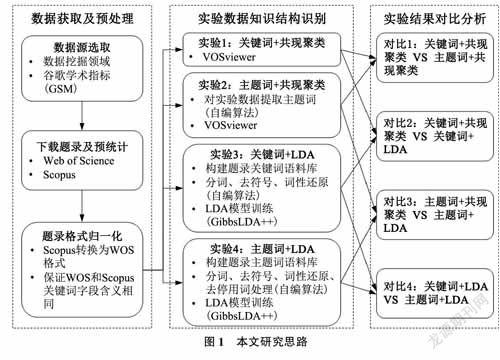
为探究考虑主题词和LDA模型进行知识结构识别的有效性,本文进行3步研究,如图1所示。首先,根据选定领域特点确定数据源、获取原始数据、进行数据预处理,以得到格式统一、主题词(题目、摘要和关键词)齐全的实验数据。然后,以关键词或主题词为实验对象,利用共现聚类或LDA模型分别进行知识结构识别,即进行4组知识结构识别实验。其中,利用文献计量网络可视化软件VOSviewer的共现聚类进行知识结构识别,利用自编的Python程序构建关键词或主题词语料库作为LDA模型输入,使用开源GibbsLDA++工具包进行LDA模型训练得到知识结构识别结果。最后,结合数据挖掘领域知识,对上述4组实验结果进行两两有共性分析元素的对比分析,获得基于关键词和主题词进行知识结构识别的差异、基于共现聚类和LDA模型进行知识结构识别的差异。
2.2基于LDA模型的知识结构识别方法
本文结合目前主流做法,提出如下基于LDA模型的知识结构识别方法。
步骤1:根据实验目的获取实验数据。本研究针对两种数据进行基于LDA模型的知识结构识别,一种是针对论文的关键词,另一种是针对由题目、摘要和关键詞得到的切分后的主题词。
步骤2:语料库的数据预处理。因为题目和摘要是短句和短篇形式,需要针对实验数据进行分词、去符号、词性还原和去停用词处理。
步骤3:参数估计和推断。利用LDA开源工具GibbsLDA++进行模型训练,得到两个超参数α、β的值。
步骤4:最优主题个数K的确定。观察不同主题个数下困惑度[11]的变化,利用拐点来确定K。
步骤5:计算在确定α、β、K下的研究主题情况。
3实验数据
3.1数据源选取
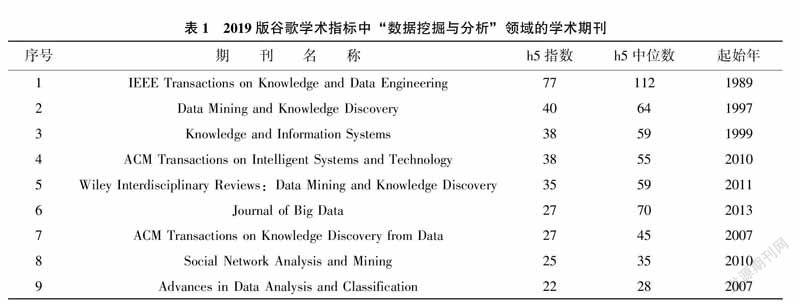
数据挖掘作为一个相对新的研究领域还不是一种现有学科的子类别,因而采用在“谷歌学术指标(GoogleScholarMetrics,GSM)”的“工程和计算机科学”类别的子类“数据挖掘与分析”中出现的出版物作为数据源。
GSM主要使用h5指数和h5中位数两种指数来帮助研究者去评估近期学术出版物中文章的可见度和影响力。2019版GSM涵盖2014—2018年发表的文章,指标基于2019年7月在谷歌学术搜索中索引的所有文章的引用,这也包括来自谷歌学术指标本身未涵盖的文章的引用[12]。在2019版GSM中列出了数据挖掘领域的9种学术期刊[13],进行统计,如表1所示,数据挖掘顶尖期刊的历史都不是很长。《IEEETransactionsonKnowledgeandDataEngineering》是这里的第一个专业期刊,创刊于1989年,也比计算机其他领域(如:人工智能)的顶尖期刊历史要短。此外,只有3种数据挖掘顶尖期刊创刊于21世纪之前,其余期刊创刊时间全部在2007年之后。
综上,本文以2019版GSM中“数据挖掘与分析”类别下的9种学术期刊在2014—2018年的题录作为数据源。
3.2原始数据获取及预统计
本文数据获取策略:首先从文摘数据库中WebofScience数据库(WOS)中进行检索,检索不到的以Scopus数据库作补充。在WOS核心合集,利用基本检索精确匹配出版物名称,时间跨度为2014—2018年,选择全记录与引用的参考文献进行题录下载保存为.txt文件。在Scopus中按ISSN进行精确检索,出版时间为2014—2018年,选择所有字段进行题录下载保存为.ris文件。最终,共计下载3341条题录。
通过对2014—2018年9种数据挖掘领域顶尖学术期刊的年度发文量(599篇、691篇、712篇、663篇、676篇)统计发现,总体呈现先上升后下降趋势。2014—2016年发文量增长率逐年降低,2016年发文量达到了最高点(712篇),这说明2016年是数据挖掘领域的一个重要转折点,2016年之前数据挖掘领域一直是研究的热点。之后在2017年发文量达到最低点,2018年略有回升,但仍低于2015年的发文量数据,说明数据挖掘领域研究已经逐渐成熟,发文量逐渐趋于平稳。
3.3原始数据预处理
由于本文获取的原始数据来源于不同科学文献数据库(WOS和Scopus)的题录格式不同,需要对此异构数据进行预处理。
1)把Scopus题录格式转换为更为普遍的WOS题录格式。利用CiteSpace对从Scopus获取的原始题录将.ris转换为.txt格式,获得3341条具有统一WOS格式的题录。
2)保证WOS和Scopus中的关键词字段含义相同。已知WOS包括作者关键词DE和扩展关键词ID,而Scopus中只提供作者关键词KW。经核实发现,经过格式转换过的题录将Scopus中作者关键词的缩写由KW变为ID,这与Scopus本意不一致,因此将格式转换过的题录文本中的作者关键词缩写由ID替换为DE。至此,获得本文实验数据共计3341篇文档。
4 实验结果与分析
4.1基于关键词和共现聚类的知识结构识别结果
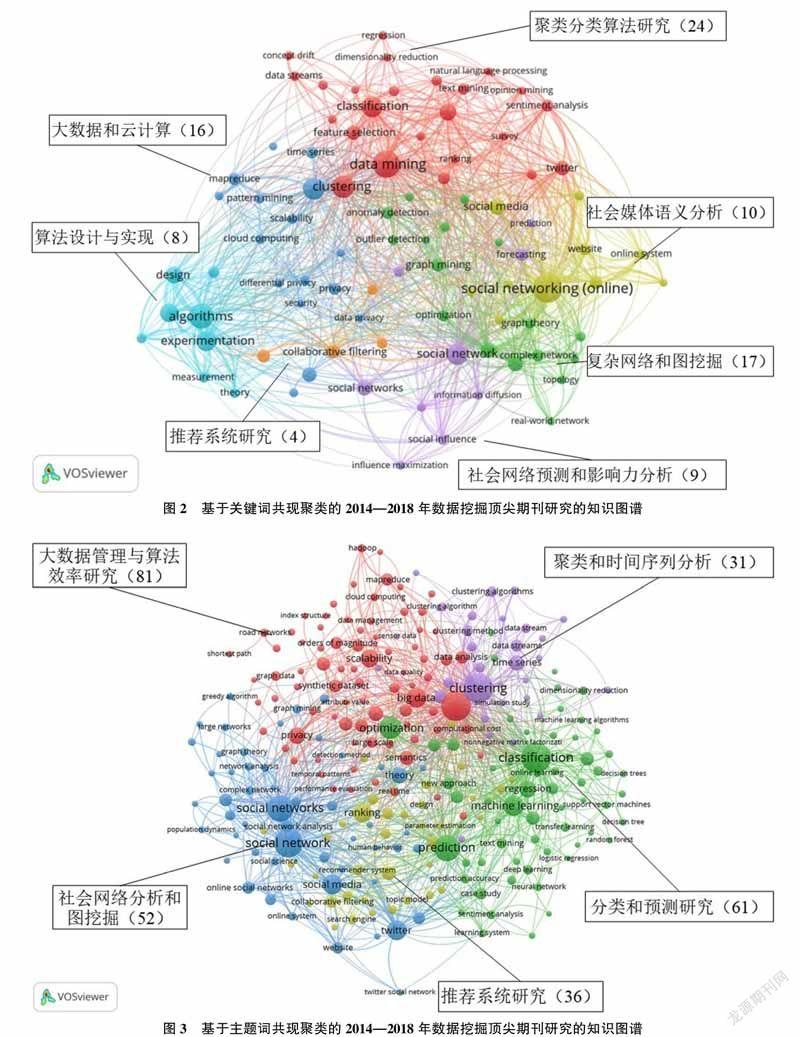
利用VOSviewer针对实验数据中的作者关键词进行关键词共现聚类分析,结果采用图谱显示。结合领域知识,得到2014—2018年数据挖掘领域顶尖期刊研究,可以归纳为7个研究主题(如图2所示,括号里数字为类规模)。
研究主题1为“聚类分类算法研究”,包括:clustering、classification、machinelearning、featureselection、informationretrieval、sentimentanalysis、datastreams、transferlearning等。研究主题2为“复杂网络和图挖掘”,包括:socialnetworkanaly⁃sis、communitydetection、graphmining、anomalydetection、complexnetwork、communitystructure等。研究主题3为“大数据和云计算”,包括:bigda⁃ta、queryprocessing、mapreduce、cloudcomputing、hadoop等。研究主题4为“社会媒体语义分析”,包括:socialnetworking(online)、socialmedia、onlinesocialnetwork、website、semantics等。研究主题5为“社会网络预测和影响力分析”,包括:so⁃cialnetwork、forecasting、linkprediction、socialin⁃fluence、informationdiffusion等。研究主题6为“算法设计与实现”,包括algorithms、experimentation、performance、design等。研究主题7为“推荐系统研究”,包括:collaborativefiltering、recommendersystems、matrixfactorization等。这7个研究主题之间,聚类分类算法与大数据和云计算、复杂网络和图挖掘、社会媒体语义分析联系较为紧密,复杂网络和图挖掘与社会媒体语义分析、社会网络预测和影响力分析联系较为紧密,推荐系统研究与社会网络预测和影响力分析联系较为紧密。
4.2基于主题词和共现聚类的知识结构识别结果
把实验数据中的作者关键词部分整理为分词词典,利用自编的正向最大匹配算法对题目和摘要进行分词,并对每一条题录内容中筛选出的关键词部分通过自编算法进行去重,用Notepad++对筛选出的关键词添加作者关键词DE及VOSviewer软件读取数据必须识别到的缩写内容。经多次共现次数实验,基于主题词共现聚类得到的网络结构均不是十分清晰,大致可以得到5個主题(如图3所示,括号里数字为类规模)。
研究主题1为“大数据管理与算法效率研究”,包括:datamining、bigdata、scalability、pri⁃vacy、effectivenessandefficiency、semantics、exper⁃imentalevaluation等。研究主题2为“分类和预测研究”,包括:classification、prediction、optimiza⁃tion、machinelearning、regression、featureselection等。研究主题3为“社会网络分析和图挖掘”,包括:socialnetwork、socialnetworks、twitter、socialmedia、theory、communitydetection、socialnetworkanalysis等。研究主题4为“推荐系统研究”,包括:ranking、recommendersystems、collaborativefil⁃tering、matrixfactorization、experimentation、baselinemethod、crowdsourcing、recommendersystem等。研究主题5为“聚类和时间序列分析”,包括:cluste⁃ring、timeseries、realdataset、datastreams、cluste⁃ringmethod、anomalydetection、knowledgediscovery、clusteringalgorithms、datastream等。在这5个研究主题中,社会网络分析和图挖掘与推荐系统研究这两个研究主题联系较为紧密。
4.3基于关键词和LDA模型的知识结构识别结果
1)利用自编Python程序抽取实验数据中的关键词作为语料库。
2)语料库的数据预处理。利用Python语言在JupyterNotebook软件环境下,自定义Clean函数,对实验语料库进行分词、去符号、词性还原处理,最终得到本实验语料库的词规模为37013。
3)参数估计和推断。在Linux环境下,基于开源工具包GibbsLDA++实现模型训练,设置迭代次数1000次,得到超参数α=1.430000、β=0.100000。
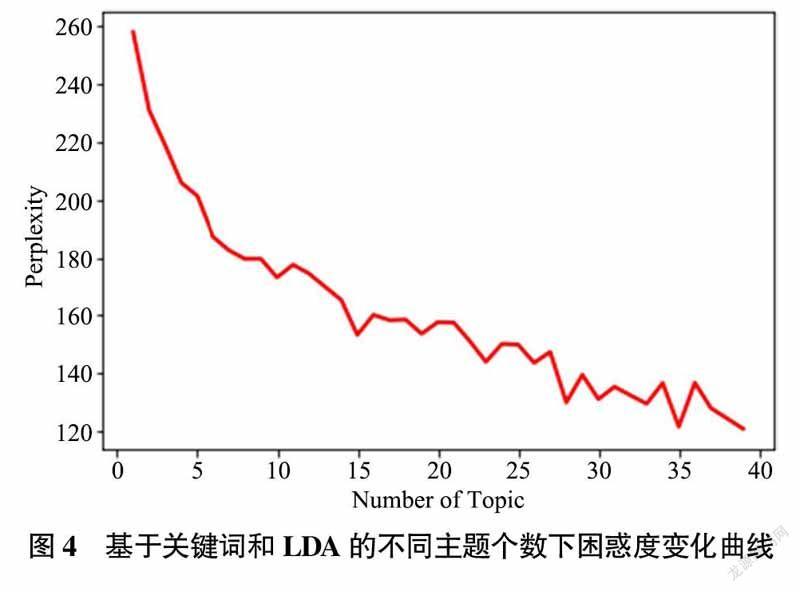
4)最優主题个数确定。困惑度计算结果如图4所示,在主题个数为35时困惑度最小,因此得到最优主题个数K=35。
根据模型输出文件获得每个主题下与该主题最相关的词语以及权重。主题1“轨迹数据挖掘”包括mining、image、trajectory、probabilistic等。主题2“复杂网络拓扑结构分析”包括network、com⁃plex、degree、topology、coefficient等。主题3“隐私安全保护”包括privacy、spatial、service、secur⁃ity、trust等。主题4“文本语义抽取”包括seman⁃tic、extraction、text、pattern等。主题5“动态图算法设计”包括design、dynamic、algorithm、graph、multiview等。主题6“矩阵分解”包括matrix、de⁃tection、factorization、nonnegative等。主题7“模糊分类算法”包括fuzzy、classification、statistic、rank等。主题8“自然语言处理概率语法模型”包括language、sentiment、natural、probabilistic、clas⁃sification等。主题9“时空数据挖掘”包括meth⁃od、location、network、performance、factor、spatio⁃temporal等。主题10“推荐系统研究”包括system、filtering、recommender、collaborative、design等。主题11“复杂网络节点中心性度量”包括model、centrality、feature、network、computational等。主题12“信息检索中的相似度分析”包括analysis、re⁃trieval、similarity、discovery、cluster等。主题13“在线社交媒体互动语义分析”包括social、medi⁃um、twitter、online、interaction、sentiment等。主题14“基于约束的距离聚类算法”包括clustering、learning、set、distance、algorithm、model、constraint等。主题15“最近邻算法研究”包括query、pro⁃cessing、bayesian、neighbor、nearest、summarization、network、skyline、object、parallel、approximate、da⁃tabase等。主题16“搜索流分析”包括search、temporal、space、stream、analytics等。主题17“基于众包的深度学习”包括algorithm、learning、ontology、crowdsourcing、deep等。主题18“机器学习及人工智能在文本上的应用”包括learning、machine、text、intelligence、artificial等。主题19“分布式计算模型及分布式数据库”包括compu⁃ting、database、distributed、model、machine等。主题20“马尔可夫随机场模型及最大似然算法研究”包括system、markov、random、likelihood、estima⁃tion等。主题21“主题模型及文本分类”包括modeling、topic、management、event、classification等。主题22“复杂网络社团结构发现”包括com⁃munity、network、detection、dynamic、structure等。主题23“基于分解的网络优化方法”包括optimi⁃zation、social、network、learning、decomposition、structural、unsupervised等。主题24“特征选择及用户行为研究”包括selection、feature、user、be⁃havior、reduction、learning、profile、social等。主题25“图聚类分析”包括graph、detection、sampling、latent、clustering、similarity等。主题26“社交网络中的异常检测”包括social、online、network、exper⁃imentation、rank、anomaly、spam、influence等。主题27“决策树算法”包括algorithm、tree、per⁃formance、decision、ensemble等。主题28“时间序列分类”包括classification、time、series、visualiza⁃tion、kernel等。主题29“网络度量和行为检测”包括network、detection、behavior、metric、meas⁃ure、linear、database等。主题30“图表征研究”包括graph、quality、representation、optimization、embedding等。主题31“数据不平衡及增量问题研究”包括analytics、concept、imbalanced、incre⁃mental、subgraph等。主题32“频繁模式挖掘”包括pattern、rule、frequent、experimentation、utility、sequential、association等。主题33“基于回归的链路预测”包括prediction、regression、link、stream、online等。主题34“扩散理论及演化模型”包括model、influence、theory、diffusion、analysis等。主题35“基于半监督的排序研究”包括ranking、local、semisupervised、selection、measurement等。
4.4基于主题词和LDA模型的知识结构识别结果
1)利用自编Python程序抽取实验数据中的主题词作为语料库。利用Python库re模块的正则表达式对字符串进行处理,根据文本格式选择multi⁃line模式,筛选出题目TI、关键词DE、摘要AB3部分内容。
2)语料库的数据预处理。利用Python语言在JupyterNotebook软件环境下,自定义Clean函数,对实验语料库进行分词、去符号、词性还原和去停用词处理,最终得到本实验语料库的词规模为377408。
3)参数估计和推断。在Linux环境下,基于開源工具包GibbsLDA++实现模型训练,设置迭代次数1000次,得到超参数α=1.470000、β=0.100000。
4)最优主题个数确定。困惑度计算结果如图5所示,在主题个数为34时困惑度最小,因此得到最优主题个数K=34。
根据模型输出文件获得每个主题下与该主题最相关的词语以及权重。主题1“复杂网络节点中心性度量”包括network、node、measure、complex、sampling、centrality、degree等。主题2“事件进程监测”包括event、process、temporal、technique、management、natural、source、news、monitoring等。主题3“时空数据挖掘”包括service、spatial、ap⁃proach、probabilistic、propose、effectiveness等。主题4“文本语义相似性研究”包括similarity、text、document、semantic、method、retrieval等。主题5“聚类算法研究”包括clustering、algorithm、meth⁃od、matrix、proposed、distance、subspace、vector等。主题6“优化算法研究”包括method、space、solution、concept、constraint、optimization等。主题7“信息扩散影响度研究”包括influence、metric、diffusion、based、propagation等。主题8“动态社交网络链接预测”包括network、social、interac⁃tion、link、relationship、dynamic等。主题9“分类算法研究”包括learning、classification、machine、label、domain等。主题10“知识系统应用研究”包括knowledge、system、technology、application、computing、study、cloud等。主题11“时间序列分析”包括time、series、study、product、method、dy⁃namic等。主题12“特征选择及分类研究”包括feature、classification、selection、classset等。主题13“社团结构发现算法研究”包括community、de⁃tection、structure、anomaly、algorithm等。主题14“分布式任务性能研究”包括task、performance、distribution、result、sample、mechanism等。主题15“在线社交媒体网络行为研究”包括social、us⁃er、online、medium、networking、behavior等。主题16“医疗数据挖掘”包括framework、predictive、patient、compared、video、record、accuracy、medi⁃cal、health、result、condition、disease等。主题17“图像表征研究”包括approach、technique、multi⁃ple、representation、image、visualization等。主题18“分布式计算研究”包括algorithm、framework、distributed、rule、datasets、processing、mapreduce等。主题19“轨迹数据挖掘”包括pattern、mining、discovery、trajectory、frequent、traffic、sequence等。主题20“异构数据挖掘”包括topic、type、paper、object、finding、heterogeneous、inference、relation⁃ship等。主题21“回归模型研究”包括method、model、regression、variable、paper、proposed、sta⁃tistical、linear等。主题22“搜索排序研究”包括search、ranking、framework、question等。主题23“数据库查询处理”包括query、database、stream、object、processing等。主题24“决策树算法”包括approach、method、set、tree、decision、strategy等。主题25“基于移动通讯数据的人类行为研究”包括mobile、human、activity、article、impact、pa⁃per、tag、identification、phone等。主题26“推荐系统研究”包括user、system、recommendation、i⁃tem、preference、approach、rating、filtering、recom⁃mender、collaborative等。主题27“定位预测”包括prediction、location、application、resource、paper等。主题28“隐私安全保护”包括privacy、utili⁃ty、technique、control、access、security等。主题29“情感分析”包括analysis、sentiment、tweet、language、mining等。主题30“图算法研究”包括graph、algorithm、edge、path、vertex等。主题31“数据集处理研究”包括approach、dataset、size、estimation等。主题32“大数据分析工具”包括data、paper、analytics、level、challenge、tradition⁃al、tool、massive等。主题33“算法性能研究”包括algorithm、efficient、application、result、perform⁃ance、scheme等。主题34“潜在混合模型研究”包括modeling、role、latent、factor、hierarchical、pa⁃rameter、mixture等。
4.5结果对比分析
在上述4组实验基础上,进行两两有共性分析元素的对比分析,包括以下4个方面。
1)分别基于关键词、主题词进行共现聚类的知识结构识别对比。4.1和4.2实验结果表明,在关键词基础上,加入了分词后的题目、摘要,得到的聚类个数变少,研究主题不够突出,因为针对一篇文献而言,其主题词涵盖的词组往往比其关键词范围广,故文献之间的共性会变大,基于主题词共现得到的聚类个数会变少。
2)基于关键词分别进行共现聚类、LDA模型的知识结构识别对比。4.1和4.3实验结果表明,前者得到的研究主题个数远远小于后者得到的研究主题个数,前者得到的研究主题更概括。例如,前者的研究主题2“复杂网络和图挖掘”与后者的研究主题2“复杂网络拓扑结构分析”、研究主题11“复杂网络节点中心性度量”、研究主题22“复杂网络社团结构发现”和研究主题29“网络度量和行为检测”紧密相关。
3)基于主题词分别进行共现聚类、LDA模型的知识结构识别对比。4.2和4.4实验结果表明,前者得到的研究主题个数远远小于后者得到的研究主题个数,后者得到的研究主题更为细分和具体。例如,前者的研究主题5“聚类和时间序列分析”对应后者的研究主题5“聚类算法研究”和研究主题11“时间序列分析”。再如,后者可以识别得到“文本语义相似性研究”“信息扩散影响度研究”“医疗数据挖掘”等细粒度研究主题。
4)分别基于关键词、主题词进行LDA模型的知识结构识别对比。4.3和4.4实验结果表明,二者得到的研究主题规模接近,均得到了细粒度的研究主题,二者存在大量共同或相关的研究主题和少量有差异的研究主题。例如,研究主题“轨迹数据挖掘”“隐私安全保护”“时空数据挖掘”“推荐系统研究”“复杂网络节点中心性度量”均被二者识别出来。又如,前者的研究主题34“扩散理论及演化模型”和后者的研究主题7“信息扩散影响度研究”很接近。此外,前者的研究主题6“矩阵分解”、后者的研究主题20“异构数据挖掘”是二者有差异的研究主题。
进一步根据数据挖掘背景知识,分析这4组实验,基于关键词(或主题词)和共现聚类的知识结构识别获得的研究主题粒度更大,得到的研究主题更具概括性,例如:聚类、分类、推荐系统研究,并且可以获得研究主题之间的关系,例如:社会网络分析和推荐系统研究联系较为紧密。而基于关键词(或主题词)和LDA模型的知识结构识别获得的研究主题粒度更小、更具体,提供的语义信息更多。具体而言:①研究主题结合具体应用领域,能够体现数据挖掘与其他领域的结合情况,例如“医疗数据挖掘”;②研究主题更细致,例如可以识别出“复杂网络节点中心性度量”和“异构数据挖掘”这样的具体研究主题;③研究主题涉及面更广,包括“轨迹数据挖掘”“情感分析”“时间序列分析”“基于众包的深度学习”等主题。这应该是由于主题词包括题目、关键词、摘要3部分,相较于关键词共现聚类只利用文献的关键词信息,前者产生的可解读信息更多。
综上,若针对同样的关键词(或主题词),基于关键词的共现聚类效果要好于基于主题的共现聚类效果,基于共现聚类获得的研究主题较为笼统,但可以获得研究主题之间的关系,而LDA模型获得的研究主题涉及具体应用更广、主题更加细分。
5结论
针对科学文献挖掘知识结构兼具研究价值和实际价值。已有进行知识结构识别的方法鲜有从主题词包括的题目、摘要和关键词3方面入手,而考虑词语间语义信息的知识结构识别十分重要。本文充分考虑作者定义的具有高度语义概括的题目、摘要和关键词,提出了基于主题词和采用LDA模型的知识结构识别方法,即首先要保证语料库包含文献的题目、摘要和关键词信息,然后对语料库进行分词、去符号、词性还原和去停用词预处理,再利用开源工具GibbsLDA++进行LDA模型的超参估计,最后利用困惑度来确定最优主题个数。以基于谷歌学术指标获得的2014—2018年数据挖掘顶尖学术期刊论文为数据源,进行基于关键词(或主题词)、采用共现聚类(或LDA模型)的4组交叉实证分析。结果表明,基于关键词共现聚类不仅可以获得聚类结果,还可以獲得类之间的关系,而基于主题词和LDA模型的知识结构识别有效且相对于传统的基于关键词共现聚类得到的研究主题更结合具体应用领域、更细致,可以提供更多的信息用于研究主题解读。在未来研究中,考虑对LDA模型进行改进以发现具体领域的新兴研究主题。
3576500338220
