基于文本与图像的肺疾病研究与预测
2022-03-10曹吉龙魏景峰
吕 晴 赵 奎 曹吉龙 魏景峰
模态是指人接受信息的特定方式,由于多媒体数据往往是多种信息的传递媒介,多模态学习已逐渐发展为多媒体内容分析和理解的主要手段.在医学领域,也有研究者应用多模态学习.针对Alzheimer病,韩坤等[1]提出结合磁共振图像(Magnetic resonance imaging,MRI)和正电子发射型计算机断层显像(Positron emission computed tomography,PET)图像模态的特征信息相融合的方法,实验结果表明该方法在准确率上取得了较好的成绩.为了解决传统模态医学图像缺陷,张淑丽等[2]提出了自由变形法对多模态的医学图像进行融合.然而大多数研究人员主要融合多模态的医学图像,没有加入电子病历等文本模态的数据.调查发现,肺癌是世界发病率和死亡率最高的疾病之一[3].病人在进行肺疾病诊断时,需要CT 检查,影像科医生对CT影像进行检查描述,但在实际的诊断和治疗过程中,常常是由主治医生根据检查描述以及CT 影像进行进一步的判断.这一过场不仅增加了主治医生的工作量,也导致了医疗资源的不合理应用.
基于此,本文在影像CT 基础上,融入影像医生对CT 影像描述的文本信息,以及一些其他检验结果(比如癌胚抗原测定、鳞状上皮细胞癌抗原测定等),构建深度学习模型对肺疾病进行预测,将影像医生给出的CT 影像和检查描述以及其他检验结果输入到模型中,对疾病进行判别并给出得病概率,患病概率大的病人则交由主治医生更进一步地诊断和治疗,以减轻主治医生的工作量,提高工作效率.
1 数据预处理
本文收集的电子病历数据,主要分为三部分:检查描述、CT 影像和检验结果.
对检查描述研究发现,虽出自不同医生之手,但是对医学名词写法相同,只是在电子病历输入的时候,存在错别字、同音异字等问题.如 “双肺实质未见明显异常密度,双肺门不大,纵膈内未见明确肿大淋巴结 ··· 肺癌不除外纵隔淋巴结增大,肝脏内见斑片状高密度影,门静脉周围间隙增宽.” 数据中除了含有少见的医学专有名词 “纵隔淋巴结”、“斑片状高密度影”外,还有错别字 “隔”.本文使用预定义词库的方法,解决医学常见缩略语的分词问题,然后使用Multi-head attention 与Bi-LSTM 对文本进行编码,减少同音异字或者语法错误带来的文本理解上的问题.
CT 影像数据是通过成像设备进行采集的,但是由于成像设备参数、外界环境的干扰,会导致采集的CT 图像数据有差异,这些问题都会影响模型的准确率.本文使用去噪和归一化等图像处理技术对CT 图像进行处理.
其他检验结果主要是痰液细胞学、胸水检查、血常规检查和肿瘤标记物筛查等.痰液与胸水细胞学检查,主要是判断痰液与胸水中是否存在肿瘤细胞;血常规检查包括白细胞、红细胞和血小板以及细胞酸碱性等;肺癌筛选的肿瘤标记物主要有癌胚抗原(Carcinoembryonic antigen,CEA)、癌抗原CA125 (Cancer antigen 125,CA125)、细胞角蛋白19 片段(Cytokeratin fragment 19,CYFRA 21-1)等.
考虑到数据由文本数据和图像数据两部分组成,因此分别对两部分数据进行处理.
1.1 文本数据预处理
1.1.1 检查描述数据预处理
深度学习出现后,基于神经网络的词嵌入模型成为了主流,GloVe[4]使用词共现矩阵学习更广泛的共现概率.CoVe[5]通过神经翻译的编码器向词嵌入中添加含有上下文背景的表征向量,令模型学习上下文背景化的语义.BERT (Bidirectional encoder representation from transformers) 使用多层Transformer[6]编码器学习词汇前后的语义依赖关系,并通过遮罩语言模型(Masked language model,MLM)解决了模型的输入在多层Transformer 结构中可以看到自己的 “镜像问题”.ERNIE[7]提出了知识融合与对话语言模型的概念,针对中文通用领域的自然语言处理任务对BERT 进行了优化.
本文使用jieba 分词,考虑医学短文本中特有的专有名词、缩写语多的特点,在分词过程中加入了医学词库,医学词库的建立一方面是通过网络爬取医学专业词汇,另一方面通过影像科医生总结出常见的肺部CT 描述词汇.文本数据中有大量的词虽然出现频率很高,却对分类预测没有帮助,比如在 “检查描述”中常出现 “无”、“可”、“检查”这类词在实际训练中不能体现不同病历差异性的作用,更加重了学习器的负担,一般称其为 “停用词”.因此在分词的时候,需要将这些停用词去掉.分词之后的文本数据还需向量化,本论文使用(Word to vector,word2vec) 模型来训练词向量,并在模型中加入位置词向量与Multi-head attention 来更好地表征文本语义.
1.1.2 检验结果数据预处理
检验结果主要是痰液细胞学、胸水检查、血常规检查和肿瘤标记物筛查等,检验项目如表1 所示,电子病历中的检查结果会给出参考范围、检查名称、状态和结果值,由于不同检查项目的量纲不同,所以结果值有很大的差异,因此,本文使用状态值来作模型的输入,将正常的状态映射为0,非正常状态(高或低)映射为1,然后输入到模型里面.
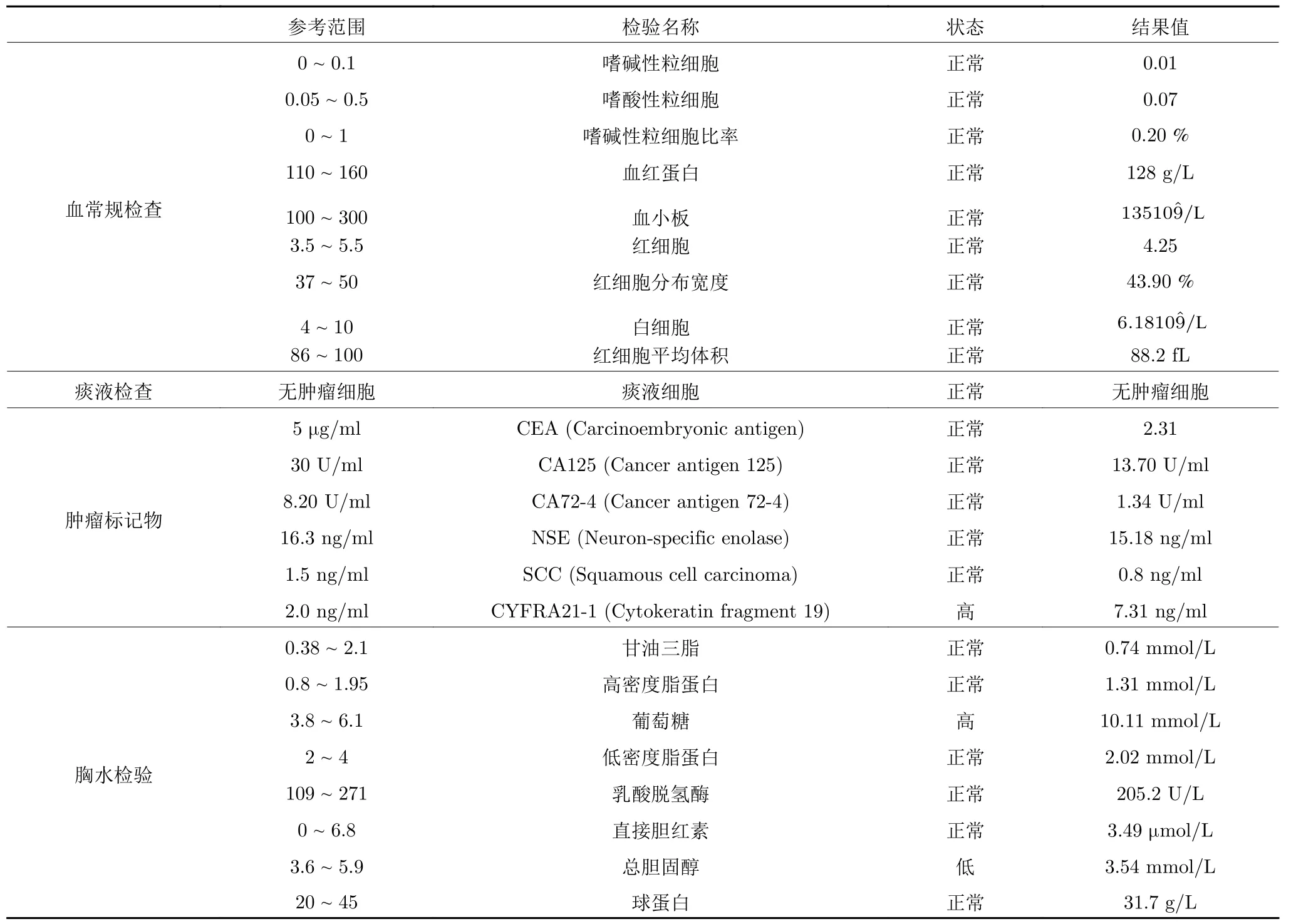
表1 检验项目Table 1 Examine items
1.2 图像数据预处理
在计算机辅助诊断领域中,主要针对肺部CT影像进行肺癌良恶性的诊断.Sun 等[8]使用了单层的CNN (Convolutional neural networks)和SDAE (Stacked denoised autoencoder) (3 个DAE(DialAnExchange))以及DBN (Deep belief nets)(4 层RBM (Restricted Boltzmann machine))解决了肺节点的良恶性分类问题.Xiao 等[9]增加了一个卷积层,使用CNN (2 个卷积层、2 个池化层、2 个全连接层)和DBN (2 层RBM)实现了肺节点的良恶性分类,其效果有明显的提高.Cheng 等[10]提出将肺节点兴趣区的多个参数与肺节点兴趣区一起输入到SDAE 模型,仅使用肺节点中间切片的Single模型与使用所有肺节点切片的All 模型进行对比,实验结果表明All 模型相比Single 模型,在准确率上大约有11 %的提升,而AUC 大约有5 %的提升.Nibali 等[11]将深度残差网络模型与迁移学习应用到肺癌分类中,由于深度残差模型,在加深网络深度的同时,减少了梯度消失的可能,因此,通过深度残差网络模型以ImageNet 图像集为源域进行迁移学习分类,使得分类准确率为89.9 %,AUC (Area under curve)为0.946.Shen 等[12]提出了一种具有多级裁剪结构的CNN 模型,该模型可以获取不同尺度的图像特征,从而加强模型的分类效果,该模型的准确率为87.1 %,AUC 为0.93.
通过对已有方法对比发现,分类准确率有明显的提高,但是分类效果还不是很高.一方面是由于模型过于简单,另一方面,没有根据目标数据进行有针对性的调整,所以模型仍有更大的改进空间.
由于CT 图像使用不同的扫描以及重建方法,会产生一些不需要的杂质和噪点,比如像结节一样的球状结构,这些干扰信息与感兴趣区域之间存在某种相似性.如果不去除噪声,后面对特征提取的质量将受到严重影响,从而影响模型的准确性.本文实验分析发现高斯滤波器的去噪效果比均值滤波等的效果更好,而且高斯滤波器对边缘信息的保留能力也更佳.除此之外,为了加快模型收敛,将图像像素归一化或标准化,在本文中,对去噪之后的图像,将像素的值归一化为0 到255 的整数.处理后的图像采用残差神经网络为基础构建模型,具体模型将在实验的图像模型部分给出.
2 实验
模型结构如图1 所示,整个模型的主要由三部分构成,分别是文本部分、图像部分和多层感知器(Multilayer perceptron,MLP),文本部分输入的是电子病历的文本信息(影像医生给出的CT 描述信息),图像部分输入的是影像检查的CT 图像,多层感知器输入的是其他检查结果.将文本部分的输出、图像部分的输出和多层感知器的输出拼接起来,然后经过全连接层,最后输出结果.模型的损失函数是交叉熵:
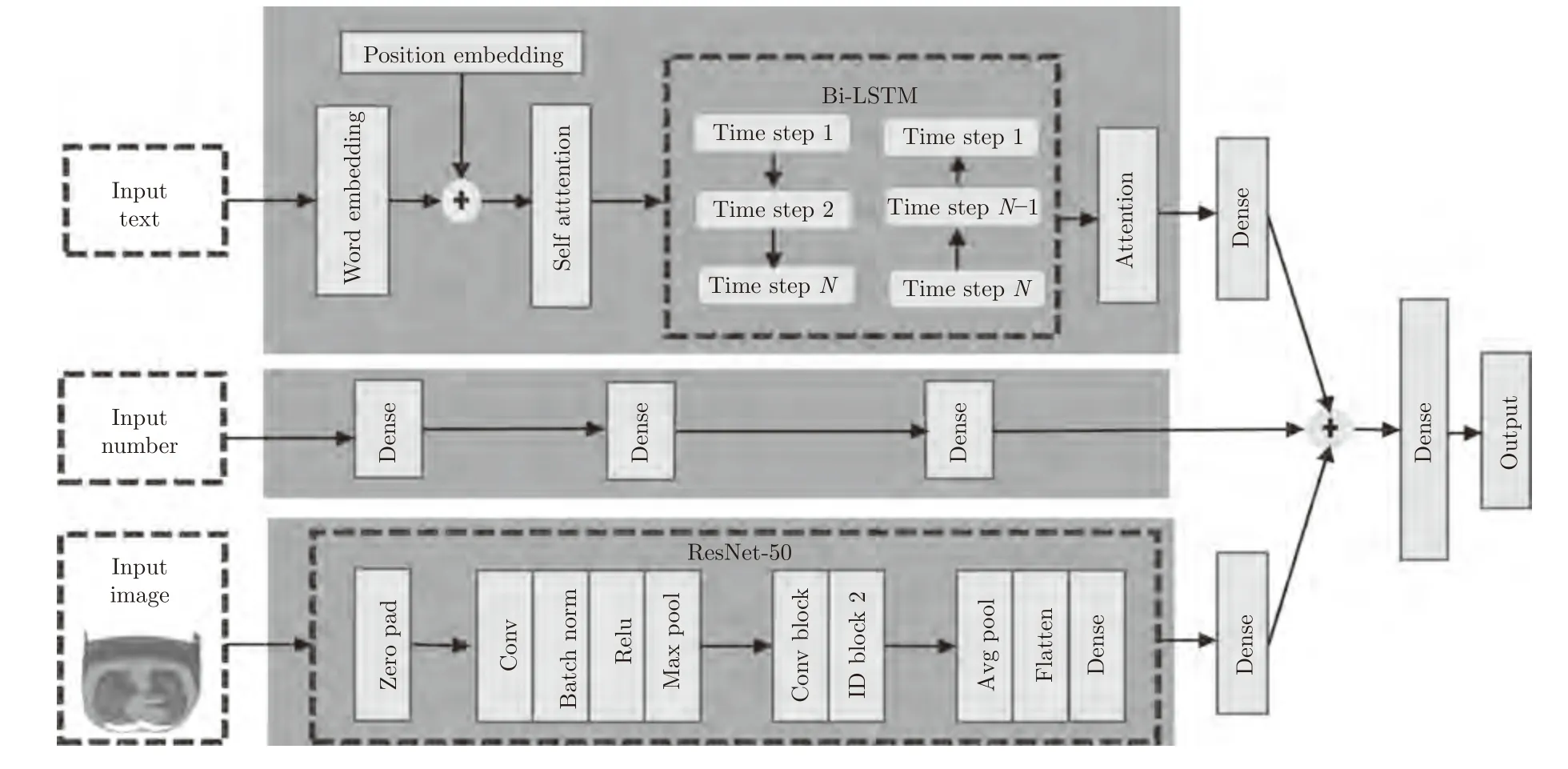
图1 模型结构图Fig.1 Model structure
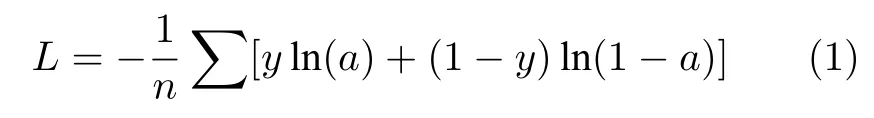
其中,a是真实值,y是预测值.
2.1 文本模型
在文本方面,以Bi-LSTM和Multi-head attention 为核心对文本建模,模型的输入层为词向量加位置向量,同时在模型的输入层后面引入Multihead attention.最后将多个特征进行拼接和融合,使模型进一步提高特征表达能力.
2.1.1 Word Embedding
本文使用词粒度的词向量.考虑到文本语料相对比较少,训练出来的词向量语义不够丰富,而腾讯预训练词向量大约超过800 万中文词汇数据,与其他公开的预训练词向量相比,具有比较好的覆盖性和新鲜度,因此本文使用腾讯预训练向量.
由于病例中的词语所在的位置不同而代表不同的语义,在词向量基础上,加入位置向量,能够使模型区别出不同位置的单词.因此,模型的输入也会将位置向量(Position embedding)作为辅助词向量输入.在语言序列中,相对位置至关重要,而Position embedding 本身是绝对值位置的信息,因此,本文将Position embedding 定义为如下:
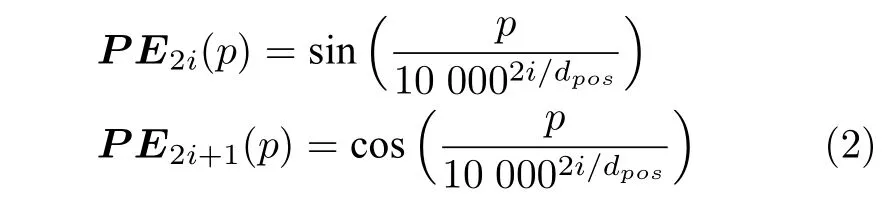
PE代表Position embedding,p代表词的位置,dpos代表维度,公式将词位置信息使用三角函数映射到dpos维度上.
2.1.2 Multi-head Attention
Multi-head attention 本质是进行多次Self-attention 计算,它可以使模型从不同表征子空间获取更多层面的特征,从而使模型能够捕获句子更多的上下文信息.
Self-attention 本质是一种信息编码方式,类似于CNN 中的卷积,Self-attention 的定义如下所示:
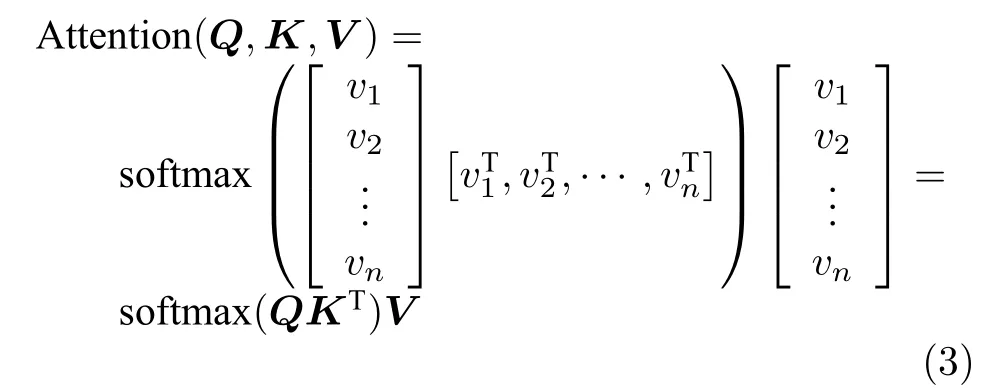
Q是Query,代表Query 向量,K是Key,代表Key 向量,V是Value,代表Value 向量.Wq矩阵,Wk矩阵和Wv矩阵将输入的词向量映射成Q,K,V,然后按照公式进行加权求和,对文本信息进行编码.
将Self-attention 执行k次,然后将结果拼接起来,就得到了Multi-head attention.
2.1.3 Bi-LSTM
词向量经过Multi-head attention 的时候,由于Self-attention 是对输入信息的上下文的向量进行计算编码信息,没有考虑到输入信息的词序,所以,在模型的输入层加入了Position embedding,除此之外,还在Multi-head attention 的后面加入了Bi-LSTM.LSTM (Long short-term memory)[13]是为了缓解RNN 的梯度消失而提出的,LSTM 单元有三个门,分别是遗忘门ft,输入门it和输出门ot[14].假设在t时刻,输入为xt,而t-1 (上一时刻)的隐藏层的输出为ht-1,其中Ct-1为t-1 (上一时刻)的细胞状态值,则在t时LSTM 的各个状态值:
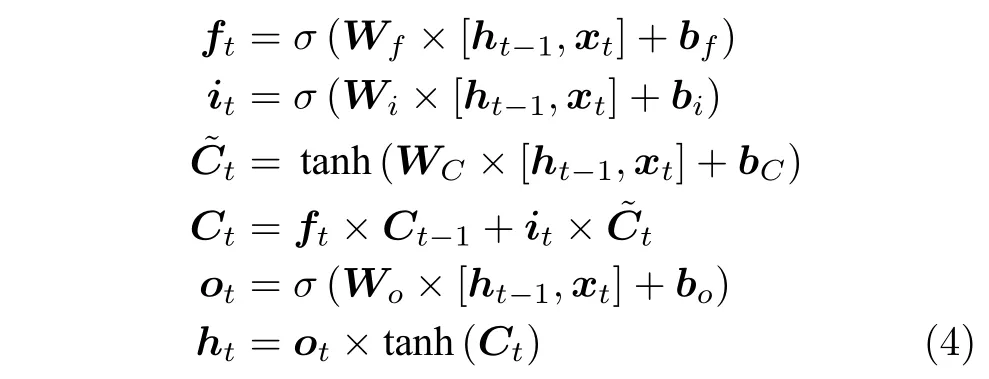
通过以上计算,最终得到t时刻LSTM 隐层状态的输出值.由于LSTM 对句子只是从前向后单向建模,无法进行从后向前的编码信息.因此,本文使用Bi-LSTM (双向LSTM),可以更好地捕捉双向的语义信息.
2.1.4 Soft Attention
Soft attention 即传统的Attention mechanism,通过保留Bi-LSTM 编码器对输入序列的中间输出结果,然后计算每个中间结果与其他结果的点积,最后加权求和.
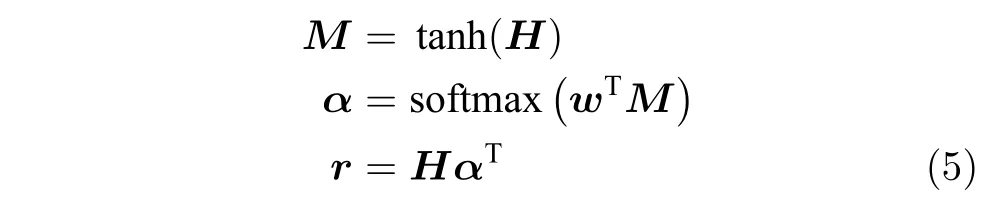
H是Bi-LSTM 隐藏层的输出结果,w是需要学习的参数.第二个Attention 机制的实现是通过计算每个中间结果与其他结果的点积,其中中间结果是通过保留Bi-LSTM 编码器对输入序列的中间输出的结果,最后再进行加权求和.这一层的Attention 能够观察到序列中的每个词与输入序列中一些词的对齐关系.本文使用的是乘法注意力机制,其中使用高度优化的矩阵乘法实现乘法注意力机制,那么整体计算成本和单次注意力机制的计算成本并不会相差很大,同时又提升了模型的特征表达能力.
2.2 多层感知机(Multilayer Perceptron,MLP)
模型的第三部分是多层感知器(MLP),MLP主要包含输入层、隐藏层和输出层.实验验证,隐藏层不能过多,一方面,层数越多,参数越多,容易过拟合,另一方面,到了一定的层数,增加更深的隐藏层,分类效果也不会提升太多,反而有时会下降.因此,MLP 部分设置三个隐藏层,具体参数如表2 所示.

表2 MLP 参数设置Table 2 The parameter of MLP
2.3 图像模型
本文的图像卷积部分在ResNet-50 结构基础上,基于ImageNet 数据集预训练,然后微调构建的模型.模型的结构如图2 所示,ResNet 中有2 个基本的block,一个是Identity block,输入和输出的dimension 是一样的,所以可以串联多个;另一个是ConvBlock,输入和输出的Dimension 是不一样的,所以不能连续串联,它的作用是为了改变特征向量的Dimension.
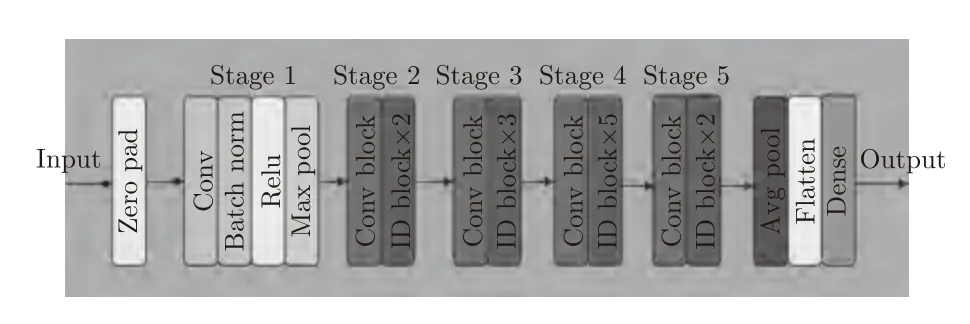
图2 图像模型结构图Fig.2 Image model structure
图像中包含足够的区分信息是卷积神经网络能够学习不同肺癌特征的重要条件[15].图像的大小会影响网络区分不同特征的能力,太小会使一些不明显的特征提取不到,太大会受计算机内存的限制,因此必须选择大小合适的图像尺寸,由于本文使用的是ResNet-50 (Residual neural network)网络,输入的图像尺寸需要调整为 2 24×224 .
2.4 实验设置
实验中所用的计算机硬件配置为Centos 系统,CPU 为Intel(R) Xeon(R) CPU E5-2630,GPU 为NVIDIA Tesla M4 显卡,深度学习框架为Keras 2.2.4,后端为Tensorflow 1.13.
在本论文中,主要有两个实验,第一个是分别测试Multi-head attention,Bi-LSTM和Soft attention 层在文本深度模型的效果,第二个是测试文本深度模型、图像深度模型、MLP和文本图像混合模型.
为了验证模型的优点和比较模型的表现能力,在第二个实验中,主要实现了以下几个模型:一个基线模型为ImageNet 预训练的VGG-19 (Visual geometry group),三个单模态模型为图像深度模型(Img-net)、多层感知器(MLP)和文本深度模型(Text-net),以及多模态模型Img+Text,Img+MLP和MLP+Text.Text-net 网络去掉下面的图像卷积部分,添加一个全连接层,损失函数为交叉熵的输出层.Img-net 网络去掉上面的文本深度模型,添加全连接层之后加上代价函数为交叉熵的输出层.MLP 是一个多层感知机网络,只使用检查结果进行预测.TI-net 网络是文本图像混合模型,输入为图像、文本和其他数值,数据经过各自的模型之后,拼接起来,经过一个全连接层之后输出.为了减少模型之间的扰动,对于单模型Text-net,Img-Net和MLP 三个网络分别用各自的输入进行预训练,而对于多模态模型,使用预训练的单模型的网络权重作为初始化,再对多模态模型进行微调.
实验数据共有3 785 个样本.本文主要研究的是一个二分类问题,即判断病人是否患有肺癌,与一般分类问题不同,疾病诊断分类问题的数据集往往存在不均衡问题,因此需要对不均衡的样本进行处理.由于本文的数据量比较大,因此,使用采样的方法来平衡数据集,以1:2 的比例对全量数据进行采样,数据的比例分布如表3 所示.

表3 正负样本比例Table 3 Positive and negative sample ratio
为了验证模型的效果,将原始数据按照8:2 的比例切分出训练集和验证集,并将训练集在3 个模型上进行训练,然后在验证集上评价模型.防止模型结果的偶然性,在训练模型的时候,采用k-fold交叉验证的形式来训练模型,实验结果显示k取值为7 的时候效果比较好一些.训练集和验证集中,文本的最大长度设置为80,词向量的维度为200,优化器为Adam,初始学习率为0.01,衰减因子为0.0001,训练轮次为2 000 次,为了防止过拟合,使用EarlyStopping 来提前停止训练,评价指标采用准确率,精确率和召回率.
2.5 实验结果
实验1 的结果如表4 所示,主要用来测试Multi-head attention,Bi-LSTM和Soft attention 层的效果,Text-net 网络使用了所有的层,Text-net1 去掉了Multi-head attention 层,Textnet2 去掉了Bi-LSTM 层,Text-net3 去掉了Soft attention 层,从表中结果可以看出,Text-net 模型比其他三个模型都要好.对比Text-net、Text-net1和Text-net2 可以看出,加入Multi-head attention 准确率提升了7 %,加入Bi-LSTM 准确率提升了3 %,所以加入Multi-head attention 层比Bi-LSTM 层效果更好.对比Text-net和Text-net3,加入Soft-attention 层后,模型准确率提升了4 %,这是因为Bi-LSTM 层只对文本进行序列建模,缺乏层次信息,后面加入Soft-attention,可以将Bi-LSTM 编码后的信息,进行层次信息建模.

表4 实验1 的结果Table 4 The result of experiment 1
实验2 的结果如表5 所示,从表5 可以看出,基线模型VGG-19 的准确率为92.53 %,而Img-Net (ResNet-50)的准确率为93.85 %,从图像深度卷积方面来看,显然ResNet-50 模型的效果更好.从单模态模型与多模态模型方面来说,对比Imgnet、Img+Text、Img+MLP和TI-net 模型,可以看出,增加CT 检验信息准确率提升了1 %,增加检验结果准确率提升了2 %,同时增加CT 检验信息和检验结果,准确率提升了3.2 %,精确率提升了4 %,召回率提升了4 %.从实验结果上可以看出,基于多模态数据的模型效果优于单模型的效果,并且对比单模型的结果可以看出,Img-net 效果远比Text-net和MLP 的效果好,这说明,CT 影像仍是肺癌诊断的主要信息,而检查描述和检验结果作为补充信息加入到模型中,可以很好地提升模型的精确度.
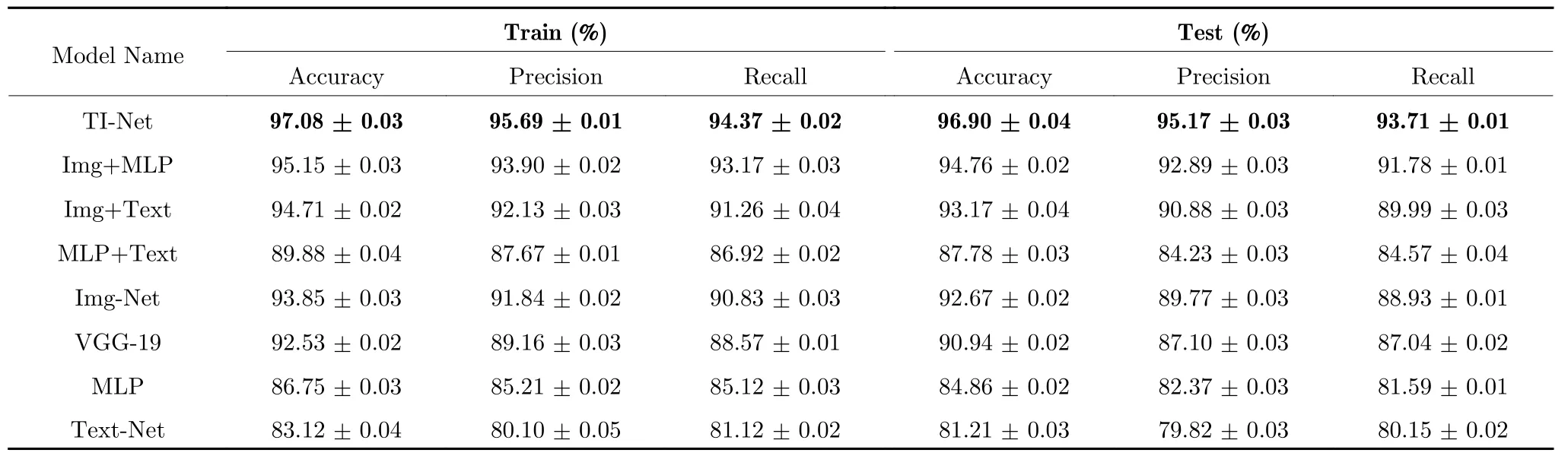
表5 实验2 的结果Table 5 The result of experiment 2
3 结论
本文提出了一种基于文本和图像的肺疾病分类算法,详细介绍了本文提出的文本图像混合深度模型,从基于深度学习的肺癌图像分类出发,引入了CT 影像描述信息和电子病历的检验项目,并使用Multi-head attention 以及Bi-LSTM 对文本建模,提取文本信息.实验结果证明,将文本信息和检验信息引入到模型后,与传统单纯的图像模型相比,本文提出的算法具有更好的识别效果和更强的泛化能力.
