融合属性特征的行人重识别方法
2022-03-10邵晓雯刘青山
邵晓雯 帅 惠 刘青山
行人重识别指跨监控设备下的行人检索问题,在公共安全、智能监控等领域具有广泛的应用.具体而言,给定一张行人图片,行人重识别用来在其他摄像头拍摄的大型图片库中找出该行人的图片.由于监控图片的分辨率低,且不同的图片之间存在光照、姿态、摄像头视角等方面的差异,行人重识别目前仍是一个很有挑战性的问题.
1 相关研究
早期行人重识别的研究思路通常是先对行人图片提取手工特征,如颜色直方图、方向梯度直方图(Histogram of oriented gradient,HOG)[1]等,然后使用相似性度量方法,如大边界最近邻算法(Large margin nearest neighbor,LMNN)[2]、交叉二次判别分析算法(Cross-view quadratic discriminant analysis,XQDA)[3]等来学习度量矩阵.为了克服光照、成像条件等因素影响,采用多特征分析是常用的一种方式[4-6].随着深度学习技术的兴起,深度学习广泛应用于行人重识别任务中.目前,基于深度学习的行人重识别方法在性能上大大超过了传统方法[7],主要有如下两个原因:1) 手工设计的特征描述能力有限,而深度学习使用深度卷积神经网络可以自动学习出更复杂的特征;2) 深度学习可以将特征提取和相似性度量联合在一起,实现端到端的学习,从而得到全局最优解.
目前基于深度学习的行人重识别方法主要分为度量学习和表征学习方法[8].度量学习通过设计不同的度量损失来约束特征空间,使得同一个行人的不同图片在特征空间上距离很近,而不同行人的距离很远,如三元组损失(Triplet loss)[9]、四元组损失(Quadruplet loss)[10]和群组相似性学习(Group similarity learning)[11]等方法.这类方法的关键在于样本对的选取,由于大量样本对简单易于区分,随机采样将会导致网络的泛化能力有限,因而需要挑选出一些难样本对进行训练.Zhu 等[12]对困难和简单的负样本设计不同的目标函数来学习距离度量方法,以充分利用负样本中的信息.相对于表征学习,度量学习的训练时间更长,收敛也更困难.因此,表征学习方法得到了更加广泛的研究.
表征学习方法在训练网络时将行人重识别当作身份分类任务来学习行人特征,关键问题是如何设计网络以学习到更具有判别力的特征.Sun 等[13]根据人体结构的先验知识,在垂直方向上对特征图均匀分块,然后提取每个区域的局部特征.还有一些方法利用额外的语义信息,例如骨骼关键点、分割结果等,定位行人的各个部位.Su 等[14]借助关键点检测模型对人体区域定位、裁剪、归一化后,拼接成新的图片作为网络的输入.Sarfraz 等[15]将行人14个关键点的位置响应图和原图片一起输入到网络中,让网络自动地学习对齐.Kalayeh 等[16]在LIP(Look into person)[17]数据集上训练人体解析模型来预测4 个人体部位和背景,然后在特征图上提取这些部位的特征.
由于不同的行人可能具有相似的外观,而同一个行人在不同的环境下存在很大差异,只从全局外观的角度无法进行正确匹配.行人的属性,例如性别、是否背包、头发长短等,包含丰富的语义信息,可以为行人重识别提供关键的判别线索.早期的研究中,Layne 等[18]手工标注了15 种语义属性来描述行人,包括性别、服装种类、是否携带物品等,并使用支持向量机(Support vector machine,SVM)训练属性分类器,最后与底层特征融合得到行人图像的最终特征描述.随着深度学习的广泛应用,Zhu 等[19]在一个卷积神经网络中同时预测多个属性,在PETA (Pedestrian attribute)[20]数据集上的属性识别性能明显优于基于SVM 的方法.Schumann 等[21]先在PETA 数据集上训练属性识别模型,然后在行人重识别模型中利用属性预测的结果,使得网络可以学习到与属性互补的特征.该方法分开训练两个网络,无法充分利用属性标签和身份标签,导致行人重识别的性能比较低.Lin 等[22]在行人重识别数据集DukeMTMC-reID[23]和Market1501[24]上标注了行人属性,并提出APR (Attribute-person recognition)模型实现行人重识别和属性识别的多任务学习,同时将属性预测的结果和全局特征一起用于行人重识别任务.该方法使用属性的预测结果,当属性识别错误时,会给行人重识别引入噪声.Tay 等[25]提出了AANet (Attribute attention network),将行人属性和属性的激活区域图集成到分类网络中来解决行人重识别问题,得到了比较好的检索结果.上述方法同等对待所有属性,忽略了每个属性对每张图片的重要性是不同的.
针对以上问题,本文提出了融合属性特征的行人重识别方法,主要工作如下:1) 将行人重识别和属性识别集成到分类网络中进行端到端的学习;2) 为了减小属性识别错误对行人重识别的影响,从特征的角度利用属性信息;3) 自适应地生成对应于每个属性的权重,并将所有属性特征以加权求和的方式结合起来,与全局特征一起用于行人重识别任务.在DukeMTMC-reID和Market-1501 数据集上的实验结果表明了本文方法的有效性.
2 融合属性特征的行人重识别模型
图1 为本文的网络结构图,前半部分为提取图片特征的主干网络,后半部分分为身份分类、属性识别和属性特征融合三个分支.身份分类分支对行人的全局特征进行身份的预测;属性识别分支用来预测行人的各个属性;属性特征融合分支首先以自适应的方式对属性特征加权求和,得到融合后的属性特征,然后对该特征进行身份预测.
2.1 主干网络结构
使用ResNet-50 作为主干网络提取图片的特征.ResNet-50 包含1 层卷积层(conv1)和4 个残差模块(conv2~ conv5),每个残差模块包含多层卷积层、批量规范化层和线性整流激活函数(Rectified linear units,ReLU).文献[26]提出多个相关性低甚至相反的任务一起学习时,在共享参数上会产生相互竞争甚至相反的梯度方向,从而影响所有任务的学习.为了减轻任务间的干扰,在ResNet-50 的第4 个模块conv4 后将网络分成两个分支,分别学习行人的全局特征和属性特征,即两个分支中conv5 模块的参数不共享.根据文献[13],本文去除了两个分支的conv5 模块中的下采样操作,以增加特征图的大小、丰富特征的粒度.将大小为 256×128 像素的图片输入网络时,可以从conv5 模块输出大小为 1 6×8 的特征图.
设S={(x1,y1,a1),···,(xn,yn,an)}为训练数据集,其中n是图片的张数,xi表示第i张图片,yi∈{1,2,···,N}表示该图片的身份标签,N是训练集中行人的个数,表示这张图片的属性标签,M是属性的个数,对于Duke-MTMC-reID和Market-1501 数据集,M分别是10和12,指这张图片的第j个属性的标签,Cj表示第j个属性的类别个数.如图1所示,对于 (x,y,a)∈S,将图片x输入到网络,可以分别得到对应于身份分类的特征图I ∈Rh×w×d和属性识别的特征图A∈Rh×w×d.
2.2 身份分类
对于身份特征图I∈Rh×w×d,先用全局平均池化(Global average pooling,GAP)对I处理得到特征z∈Rd,随后使用全连接(Fully connected,FC)层、批量规范化层和ReLU 激活函数对特征z进行降维,得到全局特征g∈Rv.训练时对特征g使用全连接层和Softmax 激活函数得到行人身份的分类结果,最后使用交叉熵损失函数作为目标函数.为了防止训练时出现过拟合的问题,对身份标签进行平滑操作(Label smoothing,LS)[27],LS 是分类任务中防止过拟合的常用方法.相应的过程如下:
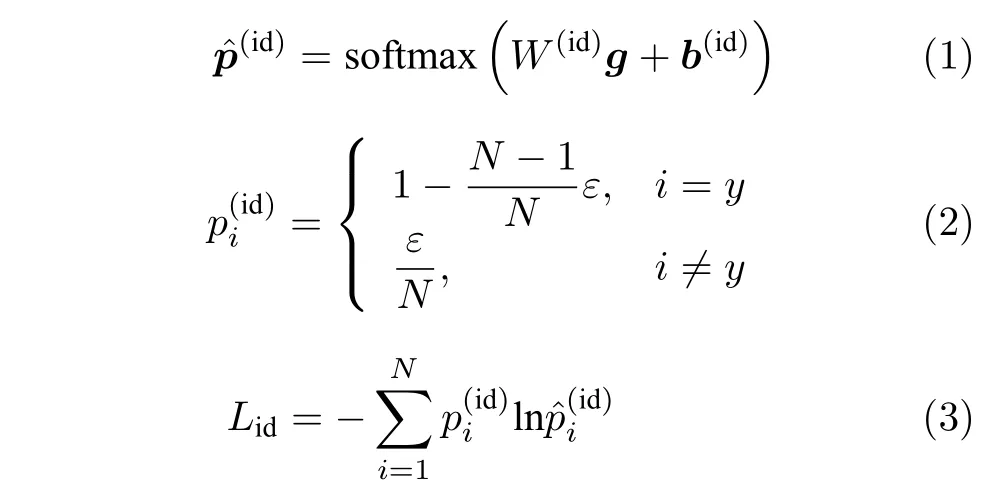
其中,N为训练集中行人的个数,W(id)∈RN×v和b(id)∈RN分别是全连接层的权重矩阵和偏差向量,为输出的行人身份的预测概率.式(2)表示对身份标签y进行LS 操作,ε是一个数值较小的超参数,文中ε=0.1 .Lid为网络的身份分类损失.
2.3 属性识别
在属性识别分支中,与身份分类类似,先用GAP 对属性特征图A∈Rh×w×d处理,得到特征f ∈Rd,然后使用M层全连接层对特征f进行提取,得到M个属性特征{h1,h2,···,hM}.对于每一个属性特征hk∈Rv,使用全连接层和Softmax激活函数得到对应的属性分类结果,最后使用交叉熵损失作为目标函数.相应的过程如下:

对于第k个属性,Ck表示它的类别个数,和分别是对应的全连接层的权重矩阵和偏差向量,为该属性的预测结果,Lk为第k个属性的分类损失.
由于属性各个类别的样本比例不平衡,并且为了降低大量简单样本在训练中所占的权重,对于每个属性使用加权的焦点损失(Focal loss)函数[28],更改后的属性损失函数如下:
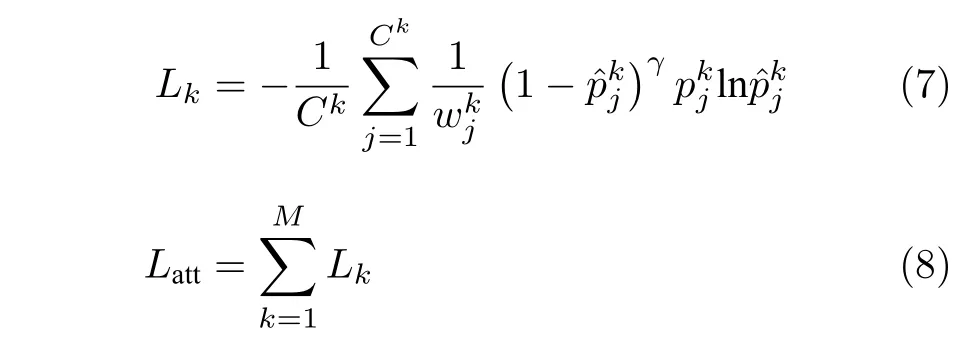
2.4 属性特征的融合
如果直接应用属性的预测结果,当属性预测错误时,很容易给行人重识别任务引入噪声,因此从特征的角度对属性加以利用.属性特征更关注于行人图片的某个区域,因而可以融合所有属性的特征和全局特征互相补充.直接想法是将提取到的M个属性特征{h1,h2,···,hM}以相加或相连等方式进行融合,但是对于每张图片,每个属性的重要性是不同的,如果简单地对每个属性分配相同的权重,最终可能会降低属性信息带来的益处.因此,对于每张图片,网络都会自适应地生成每个属性对应的权重,用来融合属性特征.具体方法如下:对于图片x得到的特征f∈Rd,首先使用一层全连接层和Sigmoid 激活函数得到对应于每个属性特征的权重,具体表示为
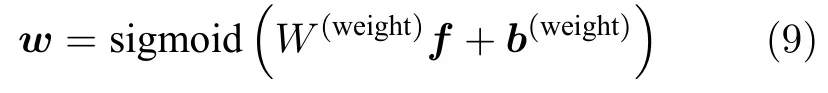
其中,W(weight)∈RM×d和b(weight)∈RM分别表示全连接层的权重矩阵和偏差向量,得到的属性权重向 量w=[w1,w2,···,wM],wi∈(0,1).然后 对每个属性特征以加权求和的方式,即得到融合后的属性特征hw∈Rv.随后以额外监督的方式对特征hw进行行人的身份分类,具体与上述的分类过程相同,使用全连接层和Softmax 激活函数得到分类结果,最后根据身份标签使用带有LS 的交叉熵损失函数作为优化目标,得到损失函数Llocal.训练时Llocal可以监督属性权重和属性特征的生成,Llocal表示为

总的损失函数包括全局特征、属性融合特征的身份分类损失和属性分类损失,具体表示为
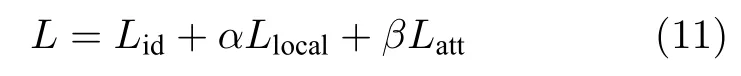
其中,α和β是平衡三个损失的权重因子.测试时,将全局特征g和融合后的属性特征hw相连得到行人总的特征e=[g;hw]∈R2v,并使用余弦距离计算特征间的距离,排序后得到检索结果.
3 实验结果与分析
本文的实验基于行人重识别的主流数据集DukeMTMC-reID和Market-1501 进行评测,并与PCB-RPP (Part-based convolutional baseline and refined part pooling)、PDC (Pose-driven deep convolutional)、ACRN (Attribute-complementary re-id net)等相关方法进行了对比.使用Pytorch 框架搭建整个网络,图片的大小缩放为 2 56×128 像素,仅使用水平随机翻转作为数据增强的方法.训练时使用Adam 优化器更新梯度,初始学习率设为0.0003,weight_decay 为0.0005.batch size 设为32,总共训练60 个epoch,每隔20 个epoch,所有参数的学习率降为之前的0.1 倍.使用ImageNet[29]上的预训练参数对网络初始化,在前10 个epoch中,使用ImageNet 初始化的参数保持不变,仅更新随机初始化的参数.降维之后的特征维度为512,即v=512 .
3.1 数据集和评估指标
DukeMTMC-reID 数据集共有1 404 个行人,分为训练集16 522 张图片包含702 个行人,测试集17 661 张图片包含另外的702 个行人和408 个干扰行人,另外有2 228 张图片作为待检索的行人图片.Lin 等[22]对数据集中的每个行人标注了23 个属性,本文使用了所有的属性,并把8 个上衣颜色的属性作为1 个类别数是8 的属性,同样将7 个下衣颜色的属性作为1 个类别数是7 的属性,最后得到10个属性.
Market-1501 数据集共有1 501 个行人,分为训练集12 936 张图片包含751 个行人,测试集19 732张图片包含750 个行人,另外还有3 368 张图片作为待检索的行人图片.Lin 等[22]对数据集中的每个行人标注了27 个属性,本文使用了所有的属性,对上衣颜色和下衣颜色采取上述的组合方式,最后得到12 个属性.
对于行人重识别任务,使用标准的评估指标:平均精度均值(Mean average precision,mAP)和累计匹配特性(Cumulative match characteristic,CMC)曲线.对于属性识别任务,本文对每个属性使用分类准确率进行评估,同时计算了所有属性的平均分类准确率.
3.2 与其他方法的比较
表1 是本文在DukeMTMC-reID和Market-1501 数据集上与当前相关方法的比较.PCB-RPP对特征图均匀分块,未考虑行人图片没有对齐的情形,而且没有去除背景的干扰.PDC和PSE (Posesensitive embedding)利用额外的姿态估计模型,SPReID (Semantic parsing for re-identification)利用额外的人体解析模型,来定位行人的各个部位,这种方法由于不能端到端地学习,训练好的部件定位模型在行人图片上定位错误时将会引入噪声,最终影响行人重识别的结果.表1 中的下面3 种方法利用属性标签辅助行人重识别,ACRN 在属性数据集PETA 上训练属性识别模型,APR和AANet-50 没有考虑行人重识别和属性识别之间的关系,直接使用同一个网络提取两个任务的特征.此外,它们对所有属性同等对待,忽略了各个属性对行人描述的重要性是不同的.在考虑了以上问题后,本文的方法在DukeMTMC-reID 上,mAP和Rank-1值分别达到了74.2%和87.1%,超过了AANet-50的结果1.6%和0.7%,在Market-1501 上,mAP 值超过AANet-50 1.0%,Rank-1 值降低0.3%,可见我们的方法对mAP 影响更大.而且相比于AANet-50 使用CAM (Class activation maps)[30]定位属性激活区域,本文的方法更加简单有效.
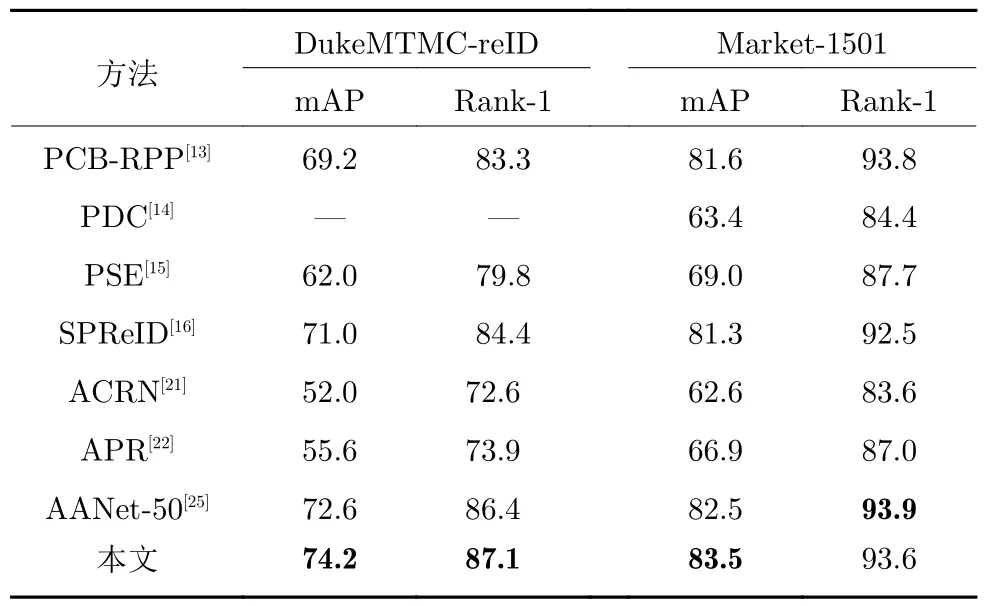
表1 与相关方法的性能比较(%)Table 1 Performance comparison with related methods (%)
3.3 本文方法分析
表2 是DukeMTMC-reID 上使用不同损失函数得到的检索结果,使用Lid相当于只训练身份分类的单支网络,可以作为基准模型,Lid+βLatt指身份分类和属性识别的多任务学习网络,Lid+αLlocal+βLatt指在多任务网络的基础上,加入了对属性特征进行身份监督的任务,即本文使用的网络.由表2 可以得出以下结论:基准模型得到了比较好的结果,mAP和Rank-1 值分别达到70.5%和84.1%;多任务网络比基准模型在mAP和Rank-1值上分别提高0.6%和1.7%,说明加入的属性识别对行人重识别起到了促进的作用,此时网络不光要正确预测行人的身份,还需要预测出各个属性,从而提高了网络的泛化性能;当利用属性特征时,mAP和Rank-1 值分别进一步提高3.1%和1.3%,说明融合的属性特征可以补充全局特征,最终形成了更具有判别力的特征.另外,指身份分类和属性识别双支网络中conv5 模块的参数共享时的结果,相比于不共享时,mAP和Rank-1 值分别降低1.2%和1.1%,说明这两个任务在提取特征的目标上并不完全相同,参数共享的模型使得两者在训练时相互影响,导致网络无法收敛至最优解.本文使用的网络结构减小了属性识别对行人重识别的干扰,并以自适应的方式利用属性特征,最终有效提高了行人的检索结果.Lid(no LS) 是在基准模型中没有对身份标签采用LS 平滑操作的结果,相比基准模型,mAP和Rank-1 值分别降低3.7%和0.8%,可见LS 操作有效提升了模型的性能.

表2 使用不同损失函数的性能比较(%)Table 2 Performance comparison using different loss functions (%)
表3 是对属性特征使用不同融合方式的性能比较.将所有属性的特征相加后,直接引入到第一支网络中与全局特征相连,对特征进行身份分类,而不进行额外的监督,该方法记为var1.在var1 的基础上,对所有属性特征以自适应加权求和的方式进行融合,而不是直接相加,即,该方法记为var2.第3 种方法与本文方法类似,区别是生成权重的方式不同,从全局的角度生成对应于每个属性的权重,记为var3,具体如下:将第一支网络中的全局特征z ∈Rd作为输入,使用全连接层和Sigmoid 激活函数输出权重w.由表3 可知,var2 相比var1,mAP和Rank-1 值分别提高0.9%和1.1%,可见自适应地对每个属性赋予不同的权重是有作用的,对于每张图片,网络可以自动调整各个属性的重要性.我们的结果相比于var2,mAP和Rank-1 值分别提高1.7%和1.4%,说明对融合后的属性特征进行额外的身份分类任务可以进一步提升性能,主要有两个原因:1)可以对属性特征和属性权重有更强的监督信息;2)由于没有加入到第一支网络中,从而不会干扰全局特征的学习.我们的方法相比于var3,mAP和Rank-1 值分别提高0.1%和0.8%,说明从属性的角度生成权重,这种类似于自注意力机制的方法可以得到更好的结果.另外从直觉上讲,将属性的特征作为输入,输出对应于每个属性的权重,这种方式也更加合理.
表3 的最后两行表示在训练完最终模型后,分别使用全局特征g和属性融合特征hw进行检索的结果.当只使用g测试时,mAP 值为72.4%,Rank-1 值为86.1%,只使用hw测试时,mAP和Rank-1值分别为71.8%和85.1%,两者均超过了基准模型的结果.而将g和hw相连后测试时,mAP和Rank-1 分别达到了74.2%和87.1%,可见全局特征和属性特征相互补充,可以对行人进行更全面的描述.
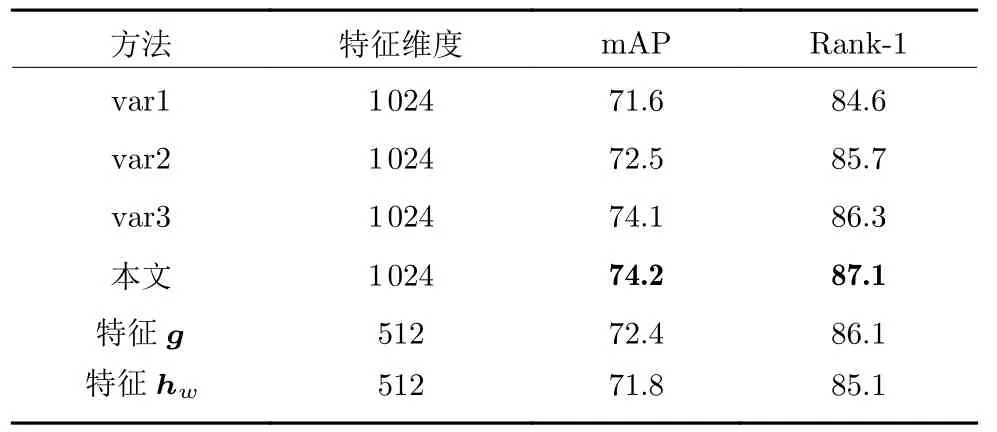
表3 使用不同特征融合方式的性能比较(%)Table 3 Performance comparison using different feature fusion methods (%)
3.4 网络参数设置
图2 是在DukeMTMC-reID 上分别设置不同的α和β得到的结果,图2(a) 中β=0.2,图2(b)中α=0.5 .由图2(a)可知,对属性融合特征进行过多或者过少的监督,效果都有所降低,当α为0.5时,可以得到最好的结果.由图2(b)可知,当β取值比较小时,结果有所提高,同时为了不影响属性识别的准确率,将β取为0.2.在所有实验中,对α和β均进行如上设置.
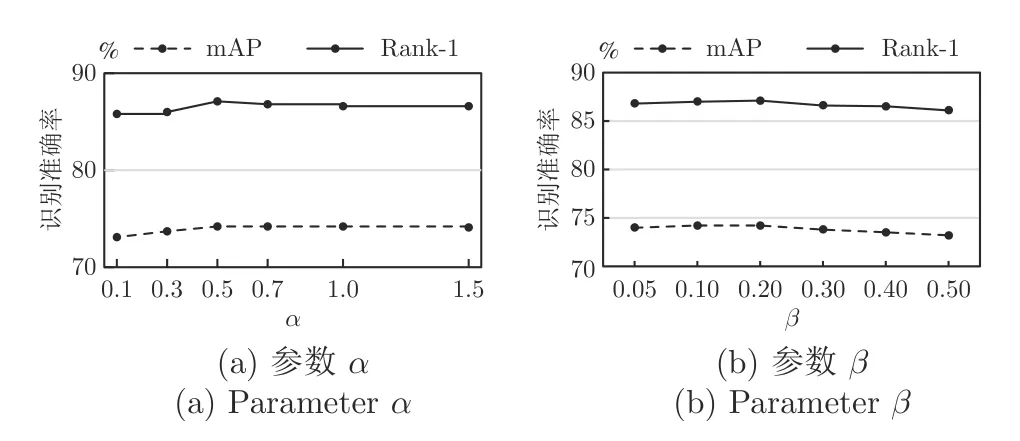
图2 设置不同的 α和β 的结果Fig.2 Results setting different α and β
3.5 可视化分析
图3 是模型训练完成之后,使用Grad-CAM(Gradient-weighted class activation mapping)[31]得到的各个属性的可视化结果,10 个属性依次为gender,hat,boots,length of upper-body clothing,backpack,handbag,bag,color of shoes,color of upper-body clothing,color of lower-body clothing.可视化结果下方的数字表示网络生成的对应于该属性的权重.上方是DukeMTMC-reID 检索库中的一张图片,下方的图片是由属性融合特征hw检索出的第1 张图片,匹配正确,即这两张图片属于同一个行人.

图3 各个属性的可视化结果及对应的权重值Fig.3 Visualization result and corresponding weight value of each attribute
由可视化结果可以看出,每个属性的激活区域基本都是落在行人区域内,可见利用属性的特征可以减少背景的干扰.此外,帽子、靴子、鞋子颜色、上衣颜色、下衣颜色等属性的激活范围基本符合对应的属性区域.由生成的权重值可知,对于这两张图片,帽子、靴子、背包等属性的重要性很大.这两张图片由于姿态、光线等差异,在外观上并不相似,但网络通过自适应地融合属性特征,关注头部、脚部、书包等区域,最终可以正确检索出来.
图4 是使用不同特征检索到的图片,其中匹配错误的样本用粗线条的框表示.对于每个行人,后面三行分别是使用全局特征g、属性融合特征hw和总的特征e得到的检索结果.由第1 个行人的结果可知,全局特征只关注上衣和裤子,找出的10 张图片中只有5 张匹配正确,而融合特征包含对于这个行人很重要的书包信息,检索出了10 张正确的图片.对于第2 个行人,融合特征通过帽子这个属性,正确找出了被遮挡的图片.相比于关注整体外观的全局特征,融合后的属性特征包含很多细节信息,这对于区分外观相似的行人是很重要的.对于第3 个行人,全局特征检索出的多为行人的背面图片,而融合特征检索出许多侧面图片,这两个结果中均有错误,但当这两个特征相连后,可以找出10张正确的包含各个视角的图片,说明全局特征和属性特征包含不相同的信息,可以互相补充促进最后的检索结果.

图4 使用不同特征检索到的图片Fig.4 Images retrieved by different features
3.6 属性识别准确率
表4和表5 分别表示DukeMTMC-reID和Market-1501 上各个属性的识别准确率,Avg 指所有属性的平均准确率,B2 表示只训练属性识别的单支网络.由表中结果可知,属性识别和行人重识别的多任务网络促进了属性识别的过程,本文方法相比于B2,平均准确率分别提高了0.32%和0.59%.此外,与APR、AANet-50 的结果比较也体现了本文方法的竞争力.

表5 Market-1501 上属性识别的准确率(%)Table 5 Accuracy of attribute recognition on Market-1501 (%)
4 结束语
针对行人外观存在类内差异大、类间差异小的问题,本文提出了一种融合属性特征的行人重识别的深度网络方法.实验结果表明,该方法能够通过加入的属性信息丰富行人的特征描述,提升识别性能.后续工作将考虑属性之间的依赖关系,进一步研究如何在行人重识别任务中更好地利用属性标签,实现行人共有属性的特征匹配.
