基于可见光与红外热图像的行车环境复杂场景分割
2022-03-10陈武阳赵于前阳春华余伶俐陈白帆
陈武阳 赵于前 阳春华 张 帆 余伶俐 陈白帆
环境感知作为自动驾驶系统的重要环节,对于车辆与外界环境的理解、交互起关键作用.然而,真实情景中的行车环境感知,需要解决复杂场景下感知精度不高、实时性不强等关键技术问题.行车环境感知主要包括目标检测与语义分割[1].语义分割在像素级别上理解所捕获的场景,与目标检测相比,能够产生更加丰富的感知信息,并且分割结果可以进一步用来识别、检测场景中的视觉要素,辅助行车环境感知系统进行判断.目前,相关的公共图像分割数据集与语义分割网络大多数都是基于可见光图像.可见光图像能够记录物体丰富的颜色和纹理特征,但在光照条件不足或光照异常时(如:暗黑中迎面的大灯照射),可见光图像的质量会大幅降低,导致网络无法正确分割对象,进而影响行车环境感知系统在这些环境下的准确性.红外热成像相机与可见光相机不同,其通过探测物体热量获取红外辐射信息,因此对光线与天气的变化更加鲁棒,缺点在于红外热图像提供的信息量较少,视觉效果模糊.由此可见,若仅依靠单一传感器,难以精确分割不同环境下的场景.本文主要研究行车环境下基于可见光与红外热图像的复杂场景分割,尝试利用深度学习技术挖掘不同传感器之间的互补信息提升分割性能,使车辆能够充分感知其周围环境.
场景分割作为行车环境感知的基本技术需求,一直以来受到研究人员的关注.目前,绝大部分研究集中在可见光图像上,分割方法从初期的基于阈值、区域、边缘等由人工设计特征的传统算法,向基于深度学习的语义分割网络过渡;研究内容则根据可见光图像分割的难点大致从增加分割精细度、增强网络对多尺度的泛化能力和学习物体空间相关性三个方向提升网络性能.如文献[2]利用膨胀卷积模块用来保留特征图中的细节信息,预测更加准确的结果;文献[3]使用一个共享参数的卷积神经网络训练不同尺度的图像获得多尺度特征;文献[4]利用循环神经网络适用于序列数据编码的特性,捕捉物体的空间关系等.虽然上述研究提高了分割准确率并解决了某些技术难题,但大多数方法只注重提升精度而忽略了网络大小和分割速度,导致所提出的方法难以在行车环境感知系统中落地.此外,基于可见光图像的分割方法无论如何改进,其输入数据来源决定了这些方法无法避免因光线不足、分割对象与背景颜色纹理一致等导致的分割误差.
红外热成像相机由于其能够全天时、全天候有效工作的特性,在车辆驾驶领域中的应用越来越广泛[5-6].例如,对红外图像中的行人进行识别,能提供危险区域、安全距离等重要信息,从而辅助行车系统更好地进行路径规划,提高其可靠性与鲁棒性.一般来说,面向红外图像的分割算法都是通过人工设计特征来描述前景与背景的差异,如基于阈值、模糊集和最短路径等方法,但它们通常对场景变化和噪声很敏感,无法适应车辆所处的复杂环境.
近年来,有学者开始关注基于多种传感器的感知方法[7],尝试通过融合多模态数据充分挖掘信息,提高行车感知系统的性能[8].Ha 等[9]首次尝试结合可见光与红外热图像进行场景分割,提出了基于卷积神经网络的MFNet 分割模型,并创建了一个可见光与红外热图像的场景分割数据集.RTFNet[10]在MFNet 的基础上引入残差结构[11]进一步加强了信息的融合,提高了场景分割结果的准确性,由于该网络结构过于庞大且参数数量显著增加,与行车环境感知系统需要轻量级、实时性高的分割模型相违背,有待进一步改进.在此之前,针对多传感器感知的研究集中在应用点云与可见光融合进行目标检测[12-13],可见光与深度图像进行分割[14],以及针对多光谱图像进行目标检测[15-16]等.
本文提出一种基于可见光与红外热图像的复杂场景分割模型DMSNet (Dual modal segmentation network),该模型通过构建轻量级的双路特征空间自适应(Dual-path feature space adaptation,DPFSA)模块,将红外热特征与可见光特征变换到同一空间下进行融合,然后学习融合后的多模态特征,并提取这些特征中的低层细节与高层语义信息,从而实现对复杂场景的分割.实验结果表明,该模型可减少由于不同模态特征空间的差异带来的融合误差,即使在光线发生变化时也表现出较强的鲁棒性,分割结果相对其他方法也有明显改进.
1 方法
本文所构建的模型以复杂场景的可见光与红外热两种模态图像作为输入,输出该场景中不同类别物体的分割结果,我们因此将它命名为双模分割网络(Dual modal segmentation network,DMSNet),总体结构如图1 所示.
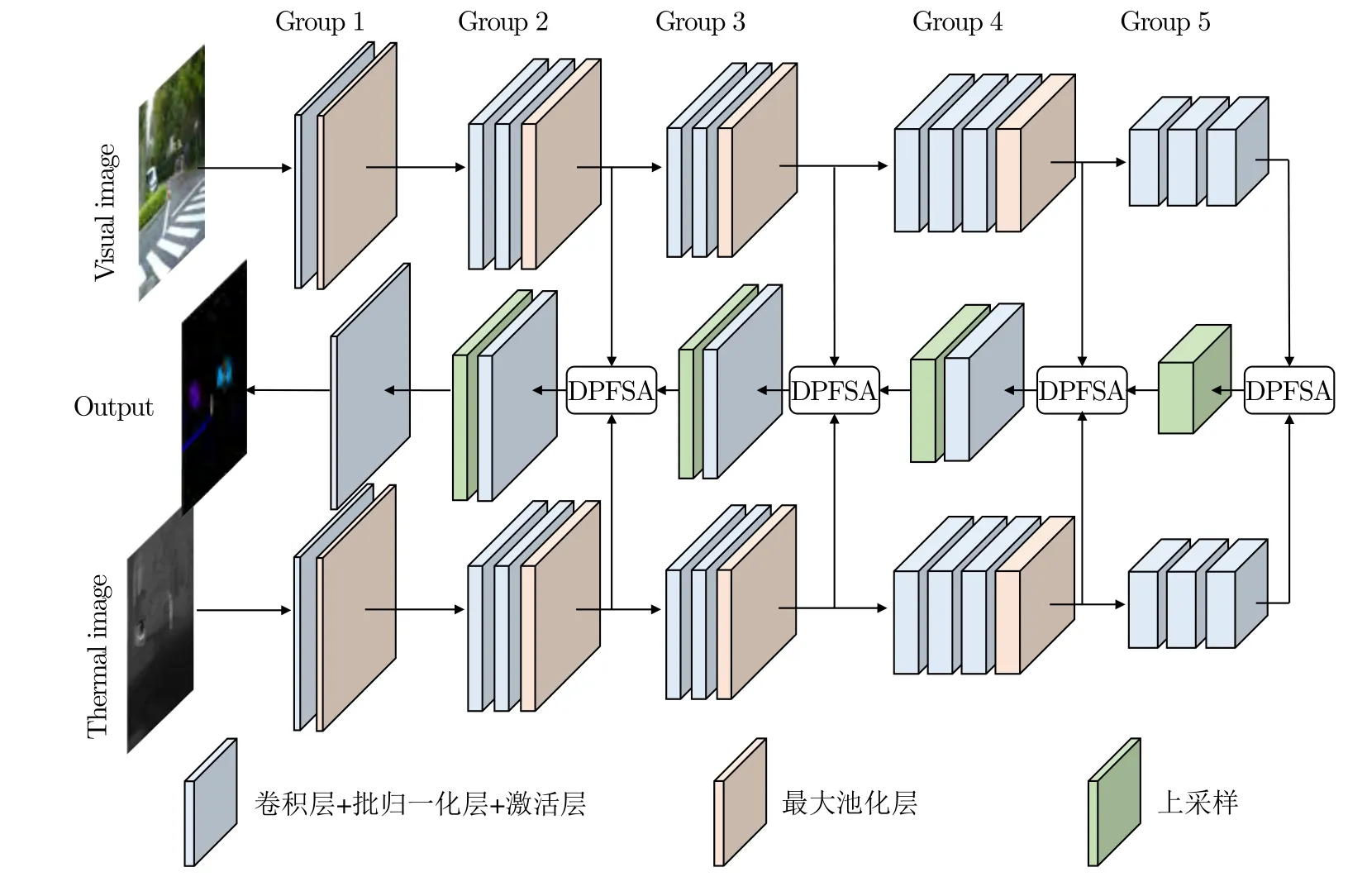
图1 DMSNet 模型结构图Fig.1 The architecture of DMSNet
1.1 场景分割模型
该网络主要包括编码器与解码器.编码器使用两条路径分别提取可见光与红外热图像特征.两条路径除了输入图像分别为彩色图像与灰度图像外,其余部分结构一致,均包含五组操作.每组内包含一到三个3×3 卷积层,卷积层后紧接着批归一化(Batch normalization)层[17],用来保持特征在网络内分布的相对稳定,然后是激活层.每组之间采用步长为2 的最大池化层缩小特征图空间尺寸,同时增加卷积核数目,由编码器的浅层至深层逐步学习到图像内更加丰富的语义信息.由于DMSNet 是面向行车环境感知的轻量级网络,特征通道数目在编码器最深层也未超过96,因此采用leaky-ReLU[18]作为网络所有的激活函数,这样做能够避免常用的ReLU[19]激活函数造成大量神经元失活的问题.
解码器负责融合两条编码路径学习到的特征,依次通过五组操作逐步增加特征图空间尺寸,并最终得到与输入图像尺寸一致的分割结果.解码器每组内的操作与编码阶段类似,包含卷积层、批归一化层与激活函数.每组之间以缩放因子为2 的最邻近插值法进行快速上采样,以逐步恢复特征图空间尺寸.进行上采样之前,需要融合来自可见光编码器与红外热编码器同一尺寸的特征图.为了缩小不同模态特征空间存在的差异,本文提出双路特征空间自适应(Dual-path feature space adaptation,DPFSA)模块,用来自动转换两种模态特征至同一空间,并对它们进行融合.该模块的详细设计将在第1.2 节中阐述.
1.2 特征融合方法
文献[13]指出,目前利用激光雷达数据与可见光图像融合进行道路检测的方法,相对于仅基于可见光图像的算法,正确率并没有明显提升.这种现象主要是由于两种信息在数据空间与特征空间存在差异,进而影响了二者的融合.数据空间的差异是指激光雷达数据位于三维真实空间,而可见光图像定义在二维平面上.特征空间的差异来源于两种数据模态不同,进而导致网络提取的特征也位于不同的空间,这些都会对特征融合造成不利影响.受该研究的启发,本文将文献[13] 中的特征空间转换(Feature space transformation,FST)模块进行改进并应用到DMSNet 中.
FST 模块将激光雷达特征全部以逐点相加的方式融进可见光特征,导致转换后的特征与未转换的特征发生混淆,一定程度给激光雷达信息增加了噪声,并有可能对可见光特征带来负面影响.针对这种不足,本文设计了DPFSA 模块,用来执行特征空间的转换.该模块结构如图2 所示,相比FST模块,最大的改进在于保留了不同模态数据的特征向量,且增加了预适应步骤(Pre-adaptation)与逆转换层(Reverse layer).其中,预适应步骤是为了增加模型的非线性能力;逆转换层的设计则借鉴了文献[17]中的思想,对转换完成的数据进一步执行卷积操作,从而避免数据分布严重改变,同时可增加模型的灵活性.这些改进使得最终的场景分割模型在几乎不增加网络参数的情况下,性能有了很大的提升.

图2 双路特征空间自适应模块(DPFSA)结构图Fig.2 The architecture of dual-path feature space adaptation module (DPFSA)
该模块主要包含两个功能:针对特征空间的转换,以及将携带不同信息的特征进行融合.对于特征空间转换,首先使用一个1×1 卷积层与leaky-ReLU 激活层对红外热特征进行预适应,然后将预适应后的红外热特征与可见光特征输入到转换网络(TransNet)学习转换参数,最后经过逆转换层完成对红外热特征空间的转换:
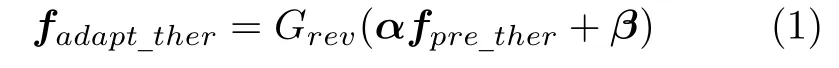
式中fadapt_ther为完成空间转换后的红外热特征,Grev代表逆转换层进行的操作,逆转换层与预适应的结构相同,仅包含单个1×1 卷积层与激活层,用来改变特征通道数,同时增加模型的非线性;fpre_ther是预适应后的红外热特征;α与β则代表Trans-Net 输出的转换参数,它们分别由TransNet 内的两个转换子网络计算得到:
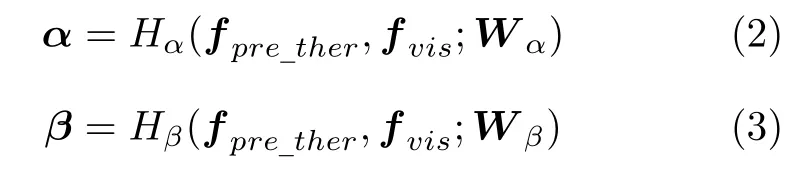
其中Hα和Hβ分别代表两个转换子网络计算α和β的全卷积运算,Wα和Wβ则是对应的参数,fvis表示可见光特征.
完成对特征空间的转换后,接着进行特征间的融合.经过转换后的红外热特征首先与可见光特征进行拼接,再与前一组已经融合的结果进行逐点相加达到融合效果,得到双路特征.DPFSA 模块处理过程可表示为:

其中,n代表场景分割模型的第n组,V、T分别为可见光与红外热图像,ffuse代表DPFSA 模块输出的双路特征经过解码器某一组卷积运算后的结果,W泛指该模块所有参数,Mfuse为逐点相加的融合过程.需要注意,在n=5 时,DPFSA 模块仅接收两个输入,处理过程变为结合图2 与式(4)可见,DPFSA 模块不仅保留了两种模态信息形成双路特征,而且该双路特征经过处理后能够继续作为下一个DPFSA 模块的输入,这种方式最大程度地减少了信息的杂糅与损失,增加了对红外热图像的利用率.
1.3 损失函数
考虑到交叉熵损失在反向传播中更易优化,而Dice[20]损失善于处理数据集中的类别不平衡问题,本文构建新的损失函数Lmix如下:
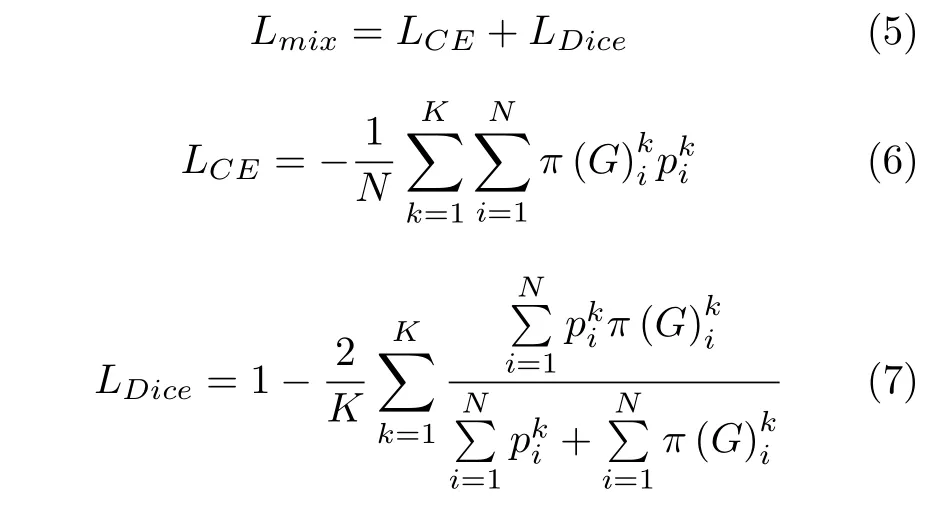
其中LCE表示交叉熵损失,LDice表示Dice 损失,K为分割类别总数,G代表图像对应的分割标签,N为图像像素总个数,将图像I中第k类像素点i的分割标签映射为独热(one-hot)编码形式,映射任意数值到 [0,1] 范围内,其计算公式如下:
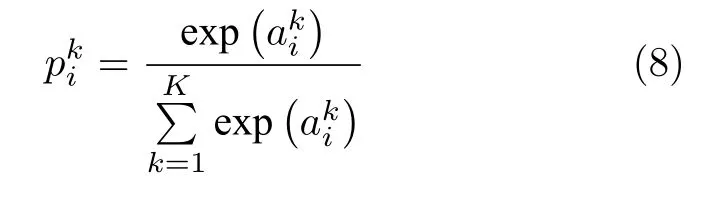
2 实验结果与分析
本文所有实验均通过基于CUDA10.0和cuDNN7.6.0 的PyTorch1.2.0 框架实现,使用搭载了Intel Xeon Bronze 3104 CPU (1.70 GHz)和NVIDIA GeForce RTX 2080 Ti (11 GB)硬件的Windows 10 电脑训练.模型初始学习速率设置为0.01,每经过一轮迭代学习速率减少1 %,模型通过SGD 随机梯度下降算法进行迭代优化,并使用动量为0.9、权重衰减系数为0.0005 的策略避免模型过拟合.本节首先介绍实验使用的数据集与评价指标,然后通过消融实验验证DMSNet 中DPFSA 模块与混合损失函数的有效性,并分析它们对模型产生的影响及可能原因,最后与其他分割模型进行对比.
2.1 数据集与评价指标
1)数据集
本文主要使用文献[9]中公开的数据集(后面统称为 “数据集A”),一共包含1 569 幅行车环境下的城市场景图像,其中820 张拍摄于白天,749 张拍摄于夜晚.该数据集使用InfRec R500 红外热成像相机拍摄,该设备能够同时获取可见光与红外热图像.数据集中一共有8 个类别被标注,分别是汽车(Car)、行人(Person)、自行车(Bike)、路缘石(Curve)、车辆停止标识(Car stop)、护栏(Guardrail)、路障(Color cone)和突出物(Bump),不属于上述类别的物体均以未标记(Unlabeled)处理.由于场景中只有少量类别被标记,未标记像素占据整体的93 %以上,而已被标记的像素中,不同类别像素占比相差达到43 倍以上.因此,该数据集有较严重的类别不平衡问题.在实际训练中,本文采用了与文献[9]相同的数据划分策略,50 %的图像用于训练,25 %用于验证,剩余的用作测试,所有图像均被缩放至480×640 固定尺寸.
由于面向行车环境的可见光与红外热多模态图像公开数据集稀缺,本文使用PST900 数据集[21](后面统称为 “数据集B”)作为实验补充.该数据集面向机器人自主环境感知,共包含894 对720×1 280 大小的可见光与红外热图像,具体有5 个类别:背景(Background)、灭火器(Fire-extinguisher)、背包(Backpack)、手钻(Hand-drill)和幸存者(Survivor).数据划分策略与数据集A 保持一致.
2)评价指标
本文采用两个指标衡量分割结果的性能,分别为正确率(Acc)和交并比(IoU).两个指标在所有类别上的平均结果分别以mAcc、mIoU 指代,计算公式如下:
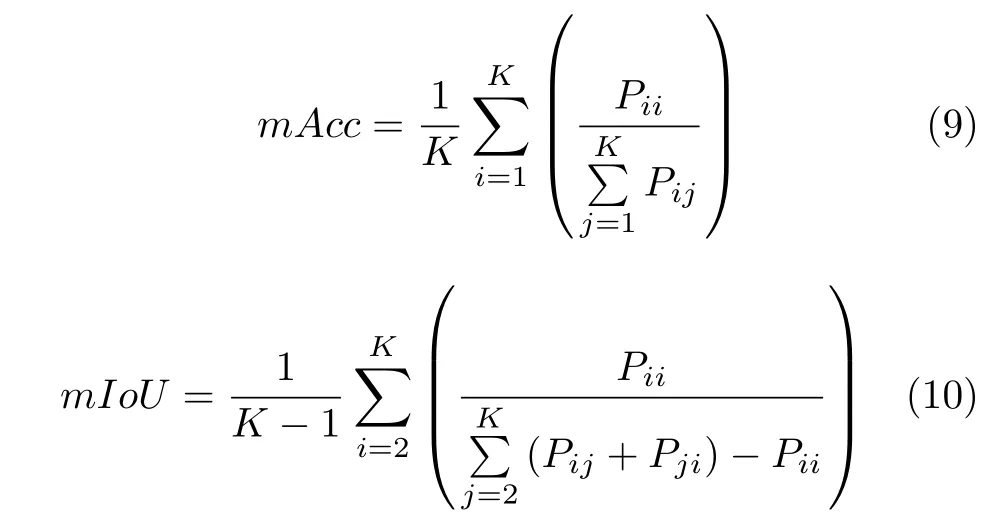
本文K在数据集A、B 上分别取为9和5,即包含了未被标注的类别.Pij代表类别为i的像素被预测为类别j的数目.在mIoU 的计算中,由于未被标注的像素占据绝大部分,不同分割模型计算得到的IoU 值非常接近,因此该类别未被纳入考虑.
2.2 消融实验
1) DPFSA 模块分析为了验证DPFSA 模块的有效性,现通过调整该模块内部结构得到另外两个模块,并将它们和MFNet、FuseNet[14]进行对比实验.两个调整后的模块如图3 所示,其中图3 (a)是在DPFSA 基础上去掉逆转换层与预适应步骤,为了表示方便,将之命名为DPFSA-1,该模块的提出是为了证明对特征空间进行转换的思路是可行的;图3 (b)是在DPFSA 基础上去除逆转换层(或者说在DPFSA-1的基础上增加了预适应步骤),将之命名为DPFSA-2,该模块的提出是为了证明单纯增加网络参数或层数不一定能提升分割精度.
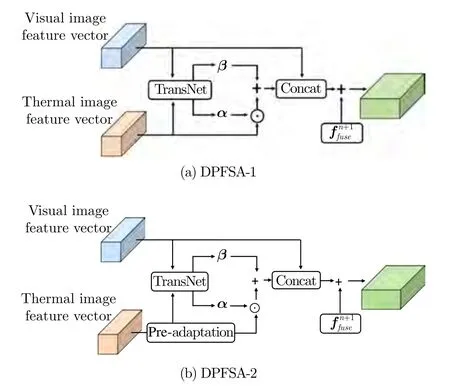
图3 调整DPFSA 内部结构得到的另外两个模块Fig.3 The other two modules obtained by adjusting the internal structure of DPFSA
为了保证比较的公平性,排除损失函数对模型性能的影响,将MFNet 使用的交叉熵损失函数作为表1 中DMSNet 及其变种模型的损失函数,并对白天与夜晚所有时间段内的图像进行测试.由表1可知,使用DPFSA-1 模块的分割结果优于MFNet与FuseNet,表明不同模态特征空间的差异能够通过这种方式缩小,对特征空间进行转换的思路可行;使用DPFSA-2 模块的实验结果虽然提升了mAcc指标,但mIoU 指标却有所下降,表明单纯通过增加网络参数或层数并不能保证模型正确率的提升,更深的模型往往需要更多的训练数据,且更难收敛.DPFSA 模块相比于DPFSA-2 模块,主要的不同在于将转换后的特征进一步输入到逆转换层,由表1可以看出这种方式显著提升了模型性能,且相比于未改进的DPFSA-1,参数量仅多出了0.18 MB,此外,模型参数量也只有FuseNet 的12.1 %.这也进一步证明,模型性能的提升并非由于训练参数大量增多引起,而是DPFSA 模块起了关键作用.

表1 不同模块在数据集A 上的mAcc、mIoU值与参数量比较Table 1 Comparison of mAcc and mIoU values and parameter values of different modules on dataset A
2)损失函数分析
本文基于交叉熵(CE)与Dice 构建损失函数,为了证明该损失函数的优越性,在DMSNet 上使用了四种不同的损失函数进行训练.表2 列出了不同损失函数在数据集A 上各类别的Acc 结果与mAcc、mIoU 指标值.其中,Focal 损失[22]的提出即为了解决样本不均衡导致模型准确率降低的问题,它通过调制系数(Modulating factor)减少易分类样本的权重,从而使得模型在训练时更专注难分类的样本.但从表2 可以发现,Focal 损失在本文所使用的数据集上效果并不好,很大程度是由于该数据集中不同类别的像素占比相差悬殊,可达十几个数量级.因此直接通过对难分类样本学习,微小的噪声都将导致损失偏差严重,影响模型收敛.
单独使用Dice 损失函数效果也较差,主要原因可能是Dice 损失的梯度形式类似于 2π(G)2/(p+π(G))2,在p与π(G) 均很小时,该梯度会变得异常大,导致整个训练过程不稳定.虽然交叉熵损失不关注类别不平衡问题,但其梯度更加简单、平稳,并且能够学习到数据中主要类别的分布,因此交叉熵损失相比Dice和Focal 损失更适用于本文数据集.
基于以上分析,为了让模型能学习到高频类别特征的同时也能兼顾低频类别,本文使用了交叉熵与Dice 相结合的混合损失函数.由表2 可知,本文提出的混合损失函数在mAcc和mIoU 指标上均表现最优,可有效提升模型性能.这在很大程度是由于交叉熵损失在网络训练前期起了主导作用,而Dice 损失作为辅助项,进一步优化了在低频类别上的分割准确率.

表2 不同损失函数在数据集A 上的Acc 结果与mAcc、mIoU 值Table 2 Acc results and mAcc and mIoU values of different loss functions on dataset A
2.3 对比实验
本节从准确性和鲁棒性角度将DMSNet 分别与SegNet、ENet、MFNet和FuseNet 的分割性能进行对比分析.其中SegNet 与ENet 是针对可见光图像的分割网络,之所以被选择为比较对象,是因为这两种网络参数量适中,并且ENet 是专门针对嵌入式端的高速度分割网络.其余大多数网络虽然在分割精度上表现更好,却具有庞大的网络结构与参数量(如RTFNet,模型参数量为980.88 MB),需要的硬件与计算条件也要求更高,对于行车环境感知系统甚至可能无法承受.为了确保对比实验的公平性,分别使用两种图像训练并测试SegNet 与ENet.第一种是可见光图像作为三通道输入,用3ch 表示;第二种为结合了可见光与红外热信息的图像,但由于SegNet 与ENet 本身不具备处理多模态数据的网络结构,因此第二种直接由可见光图像与红外热灰度图像在色彩维度上拼接作为四通道输入,用4ch 表示.
表3 展示了不同模型在数据集A 上各个类别的Acc 与IoU 评价结果,以及它们的平均值.可以看出,除了个别类在其他模型上的分割结果具有优势外,在绝大多数类别上DMSNet 都更胜一筹,且mAcc 与mIoU 指标相对于MFNet 分别高出了7.2 %与5.4 %,相对于FuseNet 则各高出了8.8 %与6.5 %.
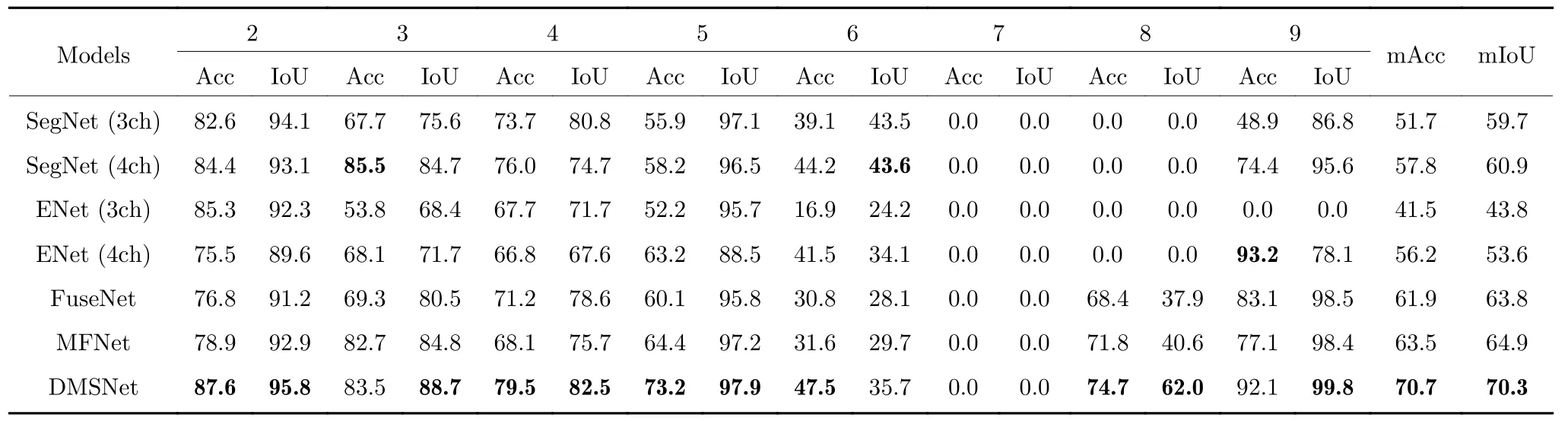
表3 不同模型在数据集A 上的Acc 与IoU 结果对比Table 3 Comparison of Acc and IoU results of different models on dataset A
此外,为了验证所提出模型在不同数据集上的适用性与鲁棒性,表4 展示了各模型在数据集B 上的测试结果.不难发现,文本提出的方法同样具有较强的分割性能.
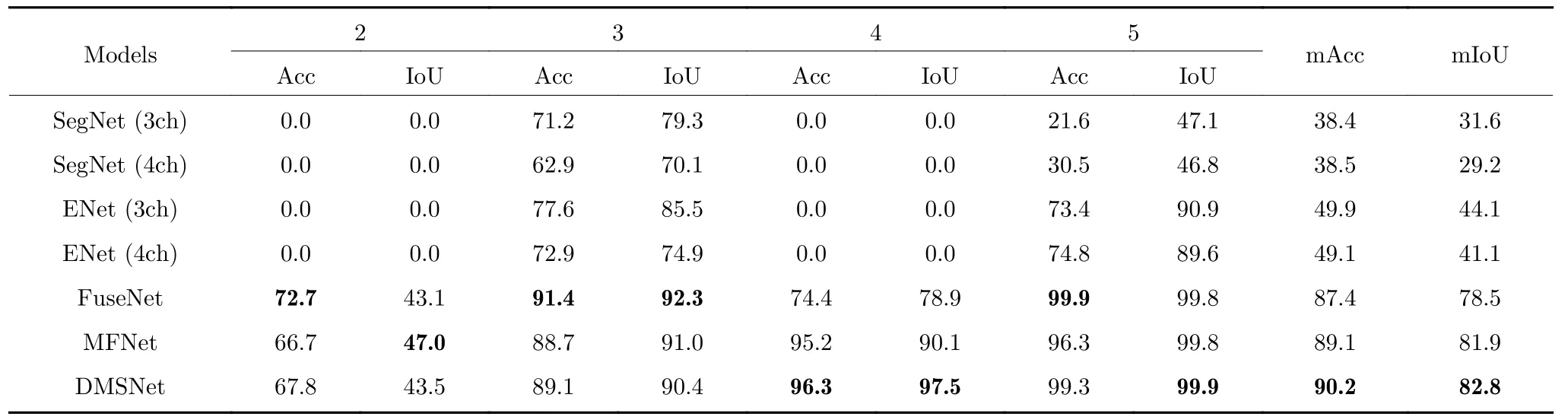
表4 不同模型在数据集B 上的Acc 与IoU 结果对比Table 4 Comparison of Acc and IoU results of different models on dataset B
为了深入探究模型是否合理利用了两种模态信息,本文进一步从时间角度比较不同模型对光照变化的鲁棒性.表5 列出了在白天与黑夜不同光线条件下不同模型在数据集A 上的分割结果对比.可以看出,不经过任何处理直接将可见光与红外热图像拼接输入网络,一定程度上影响了模型对于可见光数据的学习,特别对于SegNet 而言,四通道输入相比三通道输入,在白天的数据集上mAcc和mIoU 有明显下降.反观本文提出的DMSNet,在任意时间段的分割性能均有明显提高,这也进一步说明DMSNet 高效利用了两种模态数据的互补信息,对光照的变化表现出较强鲁棒性.
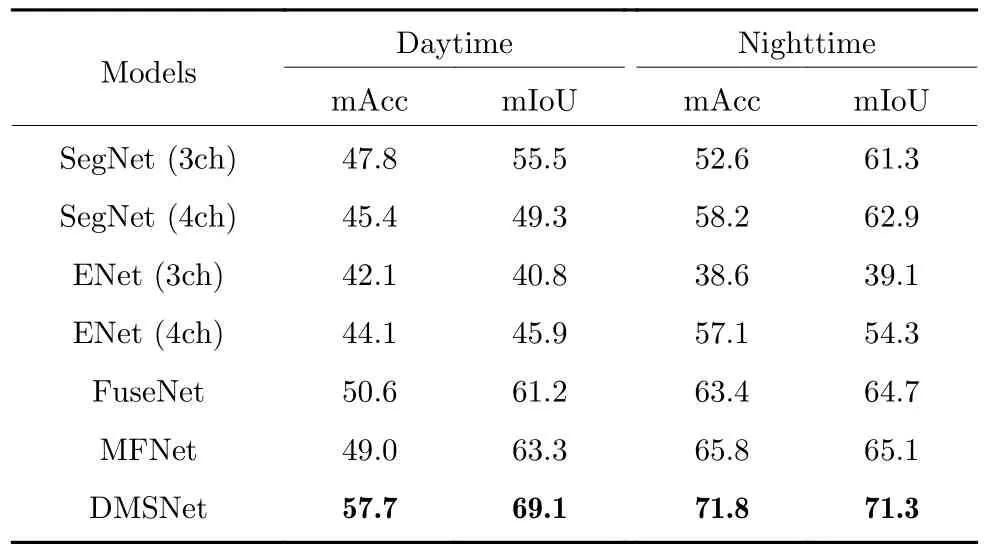
表5 不同模型在数据集A 白天与黑夜环境下的mAcc 与mIoU 结果对比Table 5 Comparison of mAcc and mIoU results of different models on dataset A in daytime and nighttime
图4 展示了DMSNet、FuseNet和MFNet 在数据集A 中5 组测试图像上的分割结果,其中第一行是可见光图像,第二行是红外热图像,第三行为分割标签,前3 幅拍摄于白天,后2 幅拍摄于夜晚.第四、五、六行分别为FuseNet、MFNet和DMSNet 的分割结果.可以看出,相比于MFNet和FuseNet,本文提出的DMSNet 对物体类别的判断更加准确,如第一列中的路障与第四列中的自行车分割结果;对边界细节的处理效果也更好,如图中的行人;另外分割结果的噪声也较少,如第三列和第五列中的汽车分割结果.

图4 DMSNet、FuseNet和MFNet 在数据集A 上的分割结果对比Fig.4 Comparison of segmentation results of DMSNet,FuseNet and MFNet on dataset A
3 结束语
针对现有场景分割模型大多基于可见光图像,无法适应复杂环境变化,且模型参数量庞大,难以部署在行车环境感知系统中的问题,本文构建了基于可见光与红外热图像的双模分割网络DMSNet.从可见光与红外热图像两种模态特征空间存在差异的角度入手,提出了DPFSA 模块.该模块以十分轻量的操作对红外热图像特征进行转换,缩小了两种模态特征空间的距离,从而能够在几乎不增加模型参数的情况下,有效改进模型性能.另外,使用本文提出的混合损失函数也可提升分割精度.不足之处在于,本文使用的数据集类别极其不平衡,甚至存在错误标记、对类别划分标准不一致等情况,导致场景中出现频率低的物体无法被准确分割,因此,下一步的工作需要从数据增强、模型优化等方面解决低频类别分割难的问题.
