基于时空共现模式的视觉行人再识别
2022-03-10钱锦浩宋展仁郭春超赖剑煌谢晓华
钱锦浩 宋展仁 郭春超 赖剑煌 , 谢晓华 ,
目前,随着 “智慧城市”和“平安城市”等项目建设,众多公共场所均部署了大量的监控摄像头,形成了庞大的监控摄像头网络.对这些摄像头的内容进行关联分析显得越来越重要,这也是计算机视觉领域当前研究热点之一.行人再识别(Person reidentification)技术旨在判断跨摄像头视域下的多个行人图像是否来自同一行人[1].行人再识别技术能够进一步应用于跨摄像头下的目标追踪、目标路径分析以及目标搜索等问题.该技术实现了监控视频的智能关联分析,其在智慧城市、公共安全、商业客流分析、城市安防和视频图像大数据处理等方面扮演极其重要的角色,具备非常广泛的应用场景.
目前基于视频图像的行人再识别领域的研究工作主要分为两个类别,分别是基于表征的方法以及基于度量学习的方法.这两类方法分别旨在寻找识别性强的特征表达与学习特征间相似度度量,使得相同身份的行人之间的相似度较大,相异身份的行人之间的相似度较小.随着深度学习技术的发展,以上两类方法逐渐达成紧密结合.然而,这两类方法的研究重点均聚焦于行人的表观视觉信息.由于现实场景中的目标行人姿态变化多端,加之环境遮挡物的影响、拍摄角度和距离的改变以及光照的变化,监控摄像头拍摄的行人视频图像会呈现较大变化,这无疑为单纯依靠视觉匹配的行人再识别带来巨大挑战.
针对单纯视觉识别的不足,研究人员开始应用各种上下文信息用于补充视觉匹配,比如视频图像采集的时空信息[2-4]、人群辅助[5-7]等.其中,人群辅助方法主要基于这种观察:在实际人流中经常存在相对稳定的小群体,这种群体也许是互相认识的同伴,也许是由于某些特殊原因形成相同时空轨迹的陌生人小群体(譬如在火车站相同班次到站的人群).这种相对稳定小群体对特定行人的再识别具有积极的辅助作用.
根据上面分析,本文将人群定义为一个时间窗口内从同一摄像头下经过的行人集合.基于此定义,本文提出了一种结合表观特征与行人时空共现模式的行人再识别方法.所提方法把现实中行人之间的时空联系看作是一种共同出现的模式状态作为上下文信息来辅助行人相似度的计算.本文在行人再识别两个权威的公开数据集Market-1501[8]和Duke-MTMC-ReID[9]上对该方法的有效性进行了实验验证.
1 相关工作
视觉行人再识别技术狭义上包括对行人的特征表达以及行人的跨摄像头匹配.因此行人再识别相关的绝大部分研究主要侧重于两个方面:行人视觉特征表达和度量学习.本节简要介绍这两类研究成果,同时介绍采用人群辅助行人再识别的相关方法.
1.1 行人特征表达
行人图像的特征表达方法逐渐从手工设计特征向深度学习特征过渡.手工设计特征主要有颜色特征、纹理特征、属性特征、形状和关键点特征等.其中颜色特征[10]是描述行人最为简单、直观的特征,主要包含颜色名称和基于统计特性的颜色直方图.颜色名称特征使用具体的颜色名称作为特征,物理意义明确,表达简洁高效.行人图像的纹理特征是描述行人表面性质的统计特征,具有较强的抗噪性质与旋转不变性.行人再识别中常用的纹理特征有Gabor 特征[11]、局部二值模式特征[12](Local binary pattern,LBP)和Schmid 特征[13]等.形状和关键点特征是通过图像的形状特征与关键点的信息来描述局部的特征,主要包含方向梯度直方图特征[14](Histogram of oriented gradient,HOG)、尺度不变特征变换特征[15](Scale invariant feature transform,SIFT)和加速鲁棒特征[16](Speeded up robust features,SURF).描述行人图像的属性特征[17-19]是更加接近人类的认知方式,其作为辅助信息提升了行人再识别算法模型的泛化能力.属性特征一般包括生物属性、附属物品属性和服装属性特征等,如行人图像的发型、性别、着装、是否携带背包等.
得益于深度卷积神经网络的发展,深度学习成为行人视觉特征学习的基准算法.深度学习特征是行人图像的多层抽象语义特征,对行人图像有着更加精确的表达.近年来行人再识别在新任务和新方法上都取得了不错的进展,例如Chen 等[20]提出使用分类子网络与验证子网络相结合进行训练网络;Jing 等[21]提出了一种半耦合低秩判别字典学习方法(Semi-coupled low-rank discriminant dictionary learning,SLD2L)用于超分辨率行人再识别;Ma 等[22]提出一种不对称的视频内投影半耦合字典对学习方法(Semi-coupled dictionary pair learning,SDPL)用以解决彩色到灰色视频行人再识别问题;Zhu 等[23]提出了一种基于视频行人再识别的视频内和视频间同步远程学习方法(Simultaneously learning intra-video and inter-video distance metrics,SI2DL);Zhang 等[24]提出多尺度时空注意力(Multi-scale spatial-temporal attention,MSTA)模型,着重于在空间和时间两方面挖掘每帧局部区域对整个视频表示的重要性;Wu 等[25]利用位姿对齐连接和特征亲和连接构造自适应结构感知邻接图,并通过图神经网络学习高判别性特征;Wang 等[26]利用时间差信息提出一种既挖掘视觉语义信息又挖掘时空信息的双流时空行人再识别框架.与已有大多数方法不同,本文不侧重于表观或者时序运动特征的提取,而关注利用目标行人的邻域行人分布信息来辅助行人相似度计算.
1.2 行人度量学习
度量学习即通过找到一种度量行人特征间相似度的准则,使得相同身份的行人之间的相似度较大,相异身份的行人之间的相似度较小.基于度量学习的方法在损失函数上体现为相同身份的行人图像对之间的距离小于不同身份行人图像对之间的距离.常用的度量学习损失函数主要有对比损失[27]、三元组损失[1,28-29]、困难样本三元组损失[30-31]、四元组损失[32]以及边界挖掘损失[33]等.
1.3 人群辅助方法
除了表征学习和度量学习,部分研究者尝试利用人群作为辅助信息来增强行人再识别的准确率.在文献[5]中,作者提出运用行人群体匹配来辅助个体匹配,着重研究了在同一图像上的人群的视觉描述子.然而在实际中,由于摄像头视域的限制,特定人群的行人未必会同时出现在同一视频帧上,可能随着时间依次出现于监控画面.因此,本文考虑的人群范围比文献[5]中的人群范围更广.除此之外,有研究者提出将人群作为一个弱标注信息并应用于弱监督学习行人再识别方法中[6-7].上述方法都将人群定义局限于共同出现在同一视频帧的行人组合,且重点关注目标行人与人群的从属关系.本文所提方法所定义人群允许跨视频帧出现,且重点关注目标行人与人群中其他个体成员的时空关系,具有更广泛的应用背景和更精确的时空特征刻画.
2 方法
2.1 方法动机
在一些特定的场景,比如车站、校道、街道等,行人在行走过程中的路线存在一致性.在这样情况之下,特定行人身边会形成相对稳定的人群,本文称之为行人邻域.通常情况下,同一行人的邻域具有相对稳定的时空分布结构,不同行人的邻域则存在着一定的差异性.自然而然地,相对稳定的行人邻域会对特定行人关联匹配起到一定的辅助作用.基于此,本文提出基于行人邻域的行人时空共现模式方法来辅助视觉行人再识别.给定两个待匹配行人的图像,其相似度取决于视觉表观特征与时空共现模式.若两者之间的行人邻域共现模式越相似,则两者越可能具有相同的身份.图1 是结合行人时空共现模式与视觉表观的行人匹配示意图.实际上,Zheng 等[5]已经意识到人群对行人识别的辅助作用,并最早提出了人群视觉描述子以及匹配方法.该方法把人群限制在同一视频帧内出现.此外,有研究人员提出将人群作为监督信息从而发展出弱监督学习的行人再识别方法[6-7].上述方法将人群定义为共同出现在同一视频帧内的行人.然而在实际中,人群是移动的,同人群的不同个体未必会同时出现在同一个视频帧,但是会出现在同一个时间窗口内的多帧照片,因此本文提出用特定时间窗口内的行人集合来定义人群更具合理性.下文介绍相关技术细节.
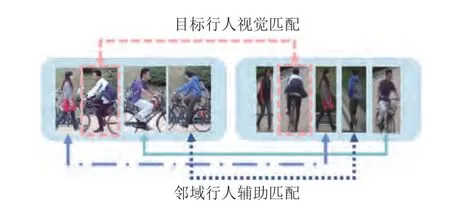
图1 行人时空共现模式辅助视觉匹配示意图(每个圆角矩形框代表一个摄像头视域,虚线框指定目标行人,其他行人表示目标行人在相应视域内的邻域)Fig.1 Illustration of spatiotemporal co-occurrence pattern aided pedestrian matching (Each rounded rectangle box represents a camera field.The dotted box specifies the target pedestrian,and other pedestrians indicate the target pedestrian's neighborhood in the corresponding view field)
2.2 行人视觉表观特征提取
行人视觉特征提取可由任何一种行人表征方法实现.本文采用一种基于行人全局特征的开源模型SphereReID[34]作为基准网络模型,这是目前被最广泛应用的行人特征提取基准网络模型之一,其中骨干网络使用残差网络(ResNet50)[35].在训练时采用三元组损失函数约束,并采用学习率启动策略[36]、随机擦除数据增强[37]、标签平滑[38]、移除最后一层下采样层[39]、对全局特征进行批归一化[40]等策略.相关实验细节将在第3.2 节实验设置中详细说明.
2.3 行人时空共现模式建模
行人时空共现模式是行人匹配中视觉表观特征的补充信息,其需要确定目标行人的行人邻域集合,并对该邻域进行匹配.本节主要介绍行人时空共现模式的建模过程.其中第2.3.1 节中介绍行人邻域的确定方式,第2.3.2 节中介绍基于邻域行人匹配的详细过程.


2.3.1 行人邻域的确定
本文考虑的目标行人的邻域为一个指定时间窗口内(以目标行人出现时间为时间窗口的中点),从同一摄像头下经过的行人集合,人群中的不同行人可以跨视频帧出现.本文把一个人群中行人之间的时空联系看作一种行人共同出现的模式状态.具体实验中,使用时间戳信息确定目标行人的行人邻域.通过预先设定时间差阈值,检索行人库中与目标行人图像的时间戳差值小于设定阈值的所有行人图像,并把返回的行人图像组成目标行人的邻域.显然,根据这种方式提取的行人邻域中很有可能包含目标行人的多帧图像.为了专注于对邻域行人的分析,需要删除邻域内与目标行人具有相同身份的行人图像,但保留其他身份行人的多帧图像.多帧图像可以提供同一个人的丰富视觉信息,更加有利于跨摄像头下的人群时空关联分析.具体地,首先计算目标行人与邻域内所有行人图像的相似度.其次,剔除邻域内与目标图像的相似度分数大于预定阈值的行人图像.
实际上,我们也可以考虑使用非极大值抑制方法对行人邻域中相同身份的行人进行图像去重,即对邻域内每个身份行人(包括目标行人)只选取有代表性的一张图像进行保留.本文后面提供的实验结果将表明使用非极大值抑制方法效果并不如前面介绍的处理方法.因此,本文在确定行人邻域上保留邻域行人中相同身份行人的多帧图像.
2.3.2 基于邻域的行人匹配
本节讨论如何基于邻域度量两个行人(如q和g) 之间的相似度.用Q={q1,···,qn}表示q的行人邻域;用G={g1,···,gm}表示g的行人邻域.首先我们讨论如何计算邻域Q和G间的相似度.一种自然的想法就是倘若两个行人邻域内拥有相同身份的行人越多,则这两个行人邻域越相似.
行人邻域图像匹配伪代码在算法1 中给出.对于Q中的每一个qi与G中的每一个gi,首先经过表观特征提取网络获取每张行人图像的表观特征表示,再利用相似度度量函数计算得到它们之间的表观特征相似度Sapp(qi,gi) .对于每一个qi,记录G中与qi的最相似行人的相似度si-max,若该相似度大于给定的相似度阈值θ,则加入匹配图像对的相似度集合S.
经过如上处理,可以从Q和G之间比较返回具备相同身份的图像对.值得注意的是,这种匹配结果可能出现Q中多个qi与G中相同的gi形成匹配,这主要是由于保留了邻域中同一个行人多帧图像所造成的.但是上述问题并不会对邻域间的匹配造成困扰,因为一对多的匹配本质上是相同身份行人的多次匹配.假设这种配对的图像有k对,记他们之间 的相似度为S={s1,···,sk},S的均值Senh=,则可以作为两个邻域G和Q之间的相似度度量.对相似度集合S求均值的主要目的是为了平衡相同身份行人的多次匹配问题.
另记q和g的表观相似度为Sapp(q,g),则q和g的最终 相似度Sfin(q,g) 由Sapp和Senh加权获得,即
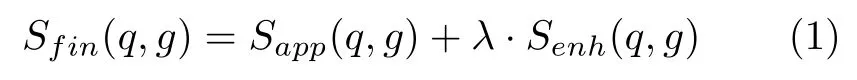
其中λ为加权系数.
3 实验结果与分析
我们在行人再识别的权威数据集Market-1501[8]和DukeMTMC-ReID[9]上对所提方法的性能进行评估,包括与其他主流方法的对比、消融实验以及模型参数敏感度分析.
3.1 实验数据集和评价指标
Market-1501[8]数据集包含1 501 个行人在6 个摄像机下拍摄的32 668 张行人图像.其中,训练集包含751 个不同身份行人的12 936 张图像;测试集由查询行人库和模板行人库两部分组成,包含750个不同行人共计19 732 张图像.对750 个行人,在每个摄像机下随机选择1 张图像组成查询行人库.一共有3 368 张行人图像,其余的则作为模板库.每张行人图像由可变形部件模型(Deformable parts model,DPM)[41]检测得到行人矩形框.
DukeMTMC-ReID[9]数据集由8 个摄像机记录而成,其包含出现在2 个以上摄像机的1 404 个不同行人,以及仅仅在1 个摄像机出现的408 个行人(干扰者)共计36 411 张图像.训练集包含702 个行人共计16 522 张图像,测试集由剩下702 个行人组成.查询行人库由在测试集中的每个行人在每个摄像机下选取1 张图像组成,共计2 228 张查询图像;测试集中余下的行人图像以及408 个干扰行人的图像共同组成测试的模板行人库,共17 661 张行人图像.Market-1 501和DukeMTMC-ReID 数据集中的每张图像都包含了自身的身份信息、摄像机的ID和视频序列编号时间戳信息.
本节实验使用累积匹配曲线(Cumulative match characteristic,CMC)和平均精度均值(mean average precision,mAP)对本文中涉及的行人再识别模型的性能进行量化评价.其中CMC反映检索精度,mAP 反映召回率.本文以rank-1的得分来代表CMC 曲线,其中rank-1 是检索结果中首位候选的准确率.mAP 是所有查询平均精度的平均值,其中每个查询的平均精度(Average precision,AP)是根据其精度召回曲线计算.
3.2 实验设置
本文实验基于被广泛使用的开放源码Open-ReID1下载地址:https://github.com/Cysu/open-reid,采用SphereReID[34]作为表观特征提取算法,使用在ImageNet[42]上预训练的ResNet50 模型作为基础网络,并将全连接层的维度改为数据集中的行人身份总数.在训练阶段,每个批训练样本包含64 张行人图像,其中每个行人4 张图像,共16个行人.每个行人图像统一裁剪为256×128 的分辨率,并以0.5 概率水平翻转进行样本增广.
基准网络训练过程如下:每张图像经过基准网络模型可得到分辨率为16×8 的全局特征图;在空间维度上,对全局特征图进行平均池化可得到行人图像的特征向量表示.根据特征向量计算三元组损失;而后对特征向量进行批归一化处理再计算身份损失.算法模型使用自适应矩估计(Adaptive moment estimation,ADAM)优化器进行优化,一共进行100 轮迭代优化.优化器的初始学习率设置为0.00035,在第40、70 轮迭代分别降低为原本学习率的0.1 倍.此外,为了验证本文方法在不同表征能力的基准网络的泛化性能,我们通过采用不同的训练策略来产生两种基准网络进行实验,即通过采用行人再识别领域先进的训练策略来增强基准网络的表征能力.这些训练策略包括随机擦除数据增强[37]、标签平滑[38]、移除最后一层下采样层[39]、对全局特征进行批归一化[40].
3.3 实验结果
3.3.1 与主流行人再识别算法的比较
本节将本文所提方法与当前主流的行人再识别方法进行性能实验比较.参与对比的方法涵盖了手工特征和学习特征,部分采用到行人姿态估计、行人掩模分割、注意力机制、生成对抗网络等最先进技术.其中基于手工特征的算法模型有词袋模型[8](Bags of words and keep-it-simple-and-straightforward metric,BoW+kissme)、核局部费希尔判别分类器[36](Kernel local Fisher discriminant classifier,KLFDA)、Null space[43]和加权近似秩分量分析[44](Weighted approximate rank component analysis,WARCA);基于姿态估计的算法包括全局局部对齐描述子[45](Global-local-alignment descriptor,GLAD)、姿势不变嵌入向量[46](Pose-invariant embedding,PIE)和姿势敏感嵌入向量[47](Pose-sensetive embedding,PSE);基于掩模的算法有语义解析行人再识别[48](Semantic parsing person re-identification,SPReID)和基于掩膜的行人再识别[49](MaskReID);基于局部特征学习的算法包括AlignedReID[50]、时空平行网络[51](Spatialchannel parallelism network,SCPNet)、基于分部卷积基线模型[40](Part-based convolutional baseline,PCB)、Pyramid[52]和Batch dropblock[53];基于注意力机制的算法有多任务注意力机制循环采样网络[54](Multi-task attentional network with curriculum sampling,MANCS)、双注意力机制匹配网络[55](Dual attention matching network,Du-ATM)和和谐注意力机制网络[56](Harmonious attention network,HA-CNN);基于生成对抗网络(Generative adversarial network,GAN)的模型有Camstyle[57]和姿态标准化生成对抗网络[58](Posenormalized generative adversarial network,PNGAN);基于全局学习特征的算法包括多目标多摄像机追踪与再识别[59](Multi-target multi-camera tracking and re-identification,MTMCReID),矩阵分解网络[60](SVDNet),视角不变行人再识别[61](Viewpoint invariant pedestrian recognition,IDE)和对比注意力机制网络[1](Comparative attention networks,CAN).
表1 展示了不同算法在Market-1501和Duke-MTMC-ReID 数据集上的实验结果.在数据集Market-1501 中,本文方法取得了96.2 %的rank-1准确率以及89.2 %的mAP;在数据集DukeMTMC-ReID 中,本文方法取得89.2 %的rank-1 准确率及80.1 %的mAP.本文提出的方法比现有主流的行人再识别算法具有较大的性能提升,表明行人时空共现模式的方法充分挖掘了行人的上下文特征,有效提高了行人再识别的准确性.此外,本文方法只使用了全局特征而没有利用局部特征,姿态估计和掩模等额外信息,但本文方法的准确率却能超越上述方法,表明行人时空共现模式方法是除了视觉表观特征以外强有力的辅助方法.
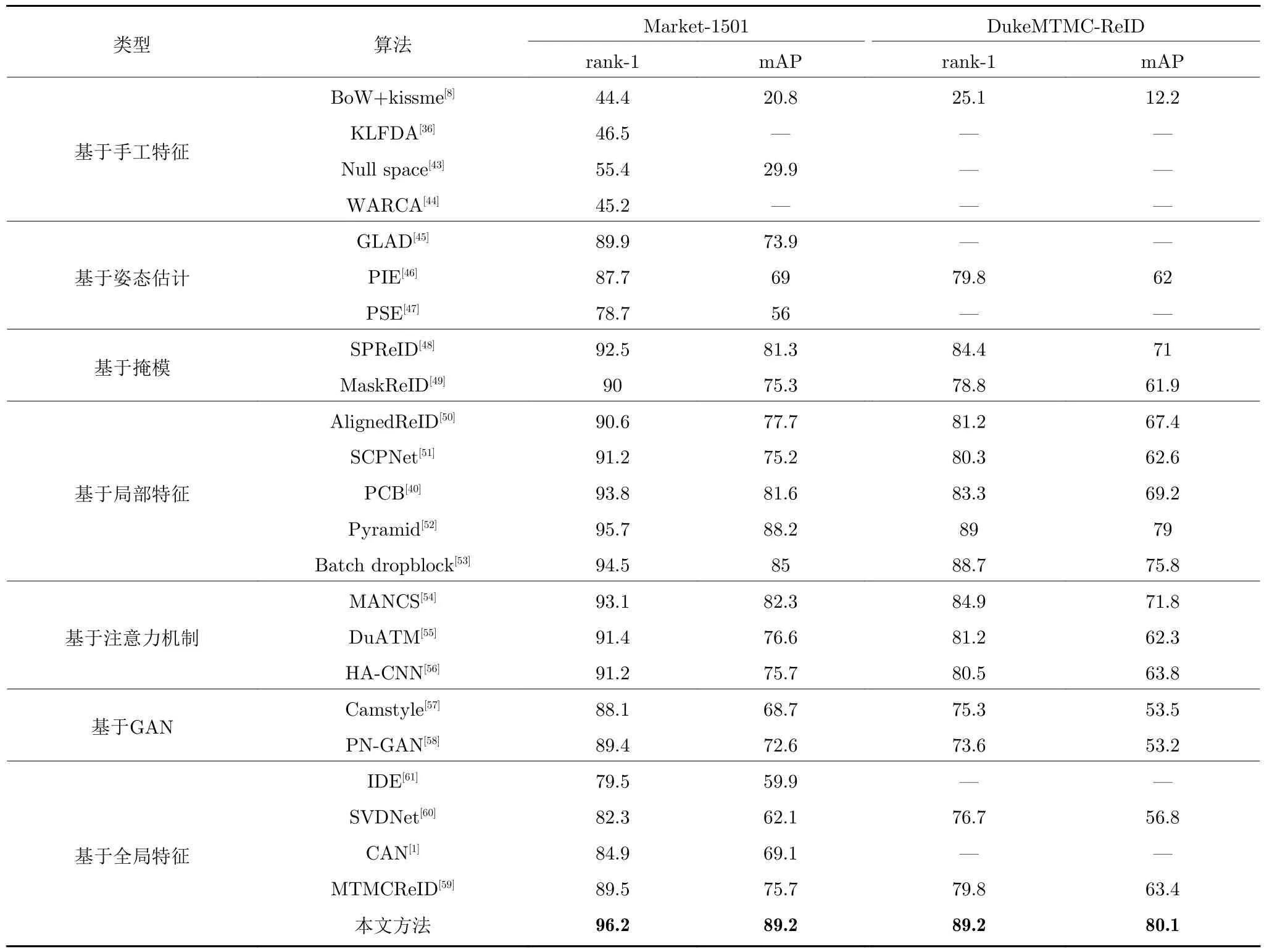
表1 本文方法与主流算法在Market-1501、DukeMTMC-ReID 数据集上实验结果比较 (%)Table 1 Comparison with state-of-the-arts on Market-1501 and DukeMTMC-ReID data sets (%)
3.3.2 行人时空共现模式消融实验
为验证行人时空共现模式对行人视觉特征在行人再识别上的辅助作用,我们采用两种基准网络进行了消融实验.两种基准网络采用的是相同的基干网络,但是采用的训练技巧不同.表2 给出了消融实验结果,其中 “基准网络模型(*)” 表示在训练网络的时候使用了近年来行人再识别中采用的先进训练策略,包括随机擦除数据增强[37]、标签平滑[38]、移除最后一层下采样层[39]、对全局特征进行批归一化[40].“基准网络模型” 则表示没有采用这些策略.

表2 用不同基准网络模型在数据集Market-1501和DukeMTMC-ReID 上的消融实验 (%)Table 2 Ablation experiment for proposed method on Market-1501 and DukeMTMC-ReID data set on different baseline network models (%)
表2 实验结果表明采用了行人时空共现模式进行行人匹配辅助之后,与基准视觉特征模型相比,所提方法在Market-1501 的rank-1 准确率上升了4.6 % (从86.7 %升至91.3 %),mAP 上升了4.4 %(从71.7 %升至76.1 %).在DukeMTMC-ReID 数据集上,rank-1 准确率上升了3.0 % (从76.4 %升至79.4 %),mAP 上升了3.3 % (从60.9 %升至64.2 %).由此可见,行人时空共现模式方法对增强行人再识别起到积极的作用.采用了先进的训练策略后,提升照样很明显,在Market-1501 的rank-1 准确率上升了1.8 % (从94.4 %升至96.2 %),mAP 上升了3.8 % (从85.4 %升至89.2 %).在DukeMTMCReID 数据集上,rank-1 准确率上升了2.6 % (从86.6 %升至89.2 %),mAP 上升了4.6 % (从75.5 %升至80.1 %).综合表2 的结果,行人时空共现模式方法在表征能力强弱不等的基准网络中均能带来稳定的提升,说明了本文方法具备良好的泛化性能.
3.3.3 模型参数敏感性分析
为了探究行人时空共现模式方法中重要参数的影响,本论文针对所提方法涉及的4 个重要参数在数据集DukeMTMC-ReID 上进行了敏感性分析实验.其中,行人邻域的时间差阈值参数δ的范围从1 400帧到2 700 帧;行人邻域后处理的相似度阈值θ1以及行人邻域匹配的相似度阈值θ2的变化范围从0.5到0.65;衡量加强相似度分数重要程度的比例系数λ参数范围从0.1 到0.16.实验结果由图2 可知,4个参数都对模型的性能产生影响,其中时间差阈值参数δ的影响最为显著.由于时间差阈值δ会直接影响行人邻域的范围,因此当时间差阈值δ取值过小,行人邻域没有足够的上下文信息辅助目标行人的匹配;随着时间差阈值δ增大至一定范围内,行人时空共现模式方法的优势得以体现.实验结果表明,当参数在合理的范围内,本文方法对于参数的选择不敏感.本文提出的行人再识别算法模型的参数配置为δ=2 500,θ1=0.55,θ2=0.6,λ=0.13 .
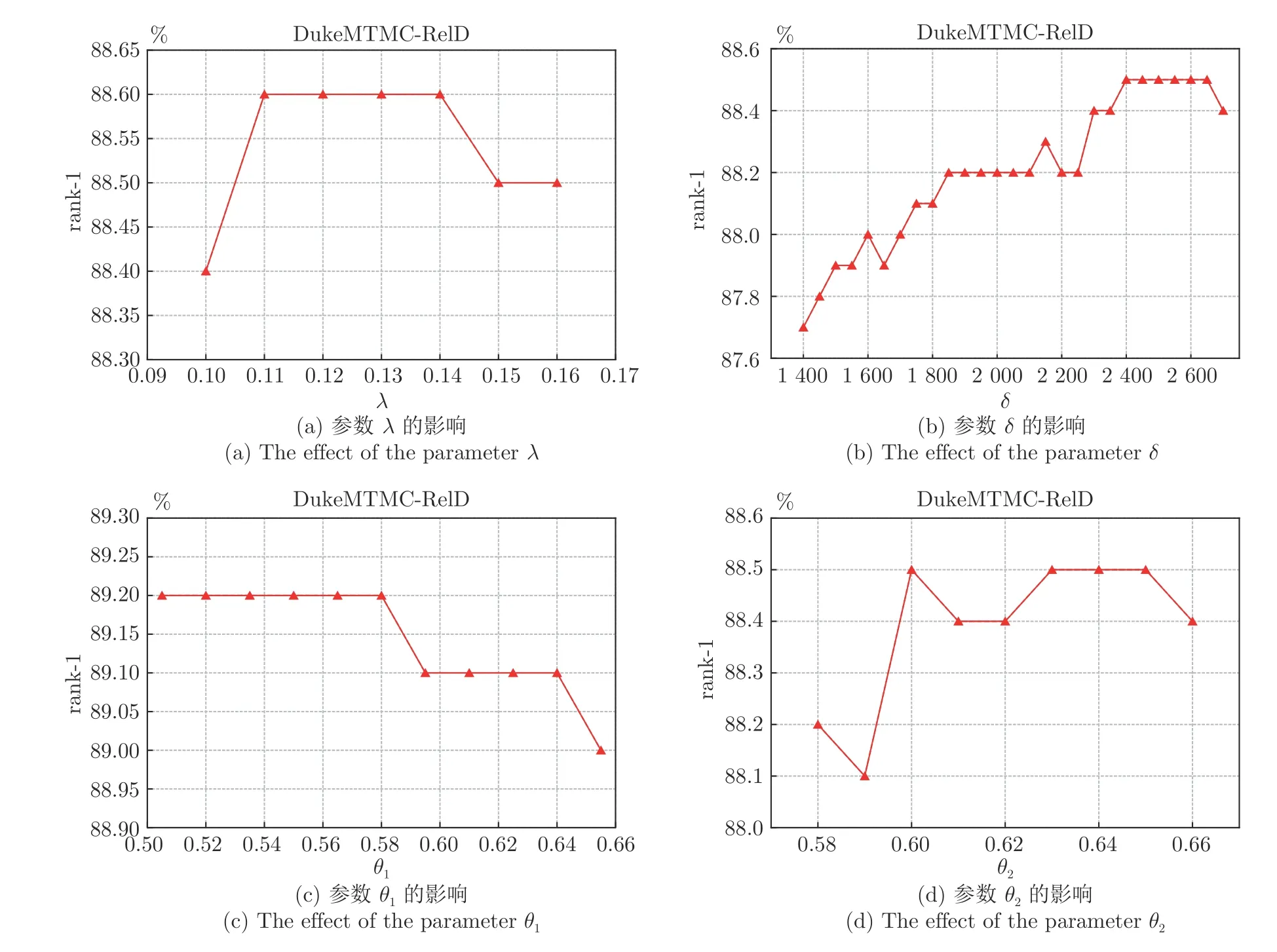
图2 超参数对模型性能的影响,纵坐标为rank-1 准确率Fig.2 Influence of hyper-parameters on model performance (rank-1 accuracy)
3.3.4 行人邻域图像去重策略探究
在第2.3.1 节,我们讨论了对行人邻域进行后处理的方法,其中主要有非极大值抑制方法以及仅仅剔除与目标行人具有相同身份的行人图像两种方法.本节通过实验比较两种策略的优劣性,实验结果如表3 所示.
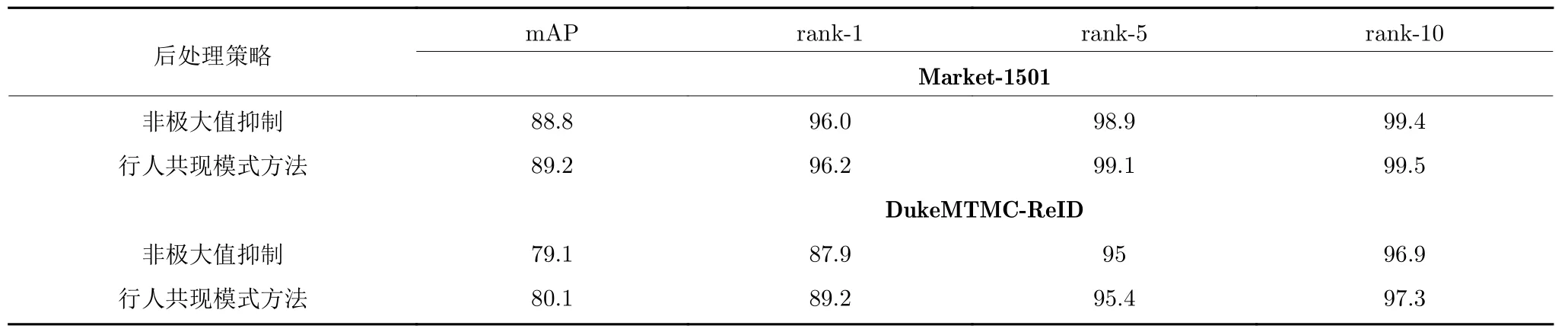
表3 不同行人邻域后处理策略在Market-1501和DukeMTMC-ReID 数据集性能比较Table 3 Comparison of different post-processing strategies for pedestrian neighborhood on Market-1501 and DukeMTMC-ReID datasets
在Market-1501和DukeMTMC-ReID 上的实验结果表明,本文使用的方法在rank-1 准确率、mAP 等各项指标上都超过非极大值抑制方法,其中DukeMTMC-ReID 上rank-1 准确率提升了1.3 %(从87.9 %到89.2 %),mAP 提升了1 % (从79.1 %到80.1 %).实验充分证明了,保留邻域中同一行人的多帧图像可以提供更丰富的视觉信息以用于行人匹配.因此,本文采用保留邻域中同一行人的多帧图像的处理方法.
4 结论
在某些公共场合,行人在行走过程中偶尔会在一段持续时间内处于某个特定小群体,这为行人匹配提供了一种特殊的上下文信息,可以用于加强行人再识别.基于此,本文提出一种结合行人表观特征跟行人时空共现模式的行人再识别算法.在行人再识别两个权威公开数据集Market-1501和DukeMTMC-ReID 上的实验验证了所提算法的有效性.未来可以继续将行人时空共现模式应用于行人再识别无监督或弱监督学习方法上.
