一种基于深度学习的异常数据清洗算法
2022-03-09匡俊搴王海峰
匡俊搴 赵 畅 杨 柳 王海峰 钱 骅*
①(中国科学院上海高等研究院 上海 201210)
②(上海科技大学信息科学与技术学院 上海 201210)
③(中国科学院大学 北京 100049)
④(中国科学院大学微电子学院 北京 100049)
⑤(中国科学院上海微系统与信息技术研究所 上海 200050)
1 引言
随着物联网应用在实际生活与生产中的普及,其以数据为中心的特点日益凸显。密集部署的传感器节点会产生大量的传感器数据,由于节点能量受限、监测环境较为复杂、节点容易遭受外界攻击等,经常出现异常值[1]。由于物联网系统的运行主要依赖传感器数据,数据冗余和数据异常值会大大降低物联网应用的有效性。因此,必须采用数据清洗技术来去除异常值对物联网系统的影响。数据清洗的研究内容包括:重复数据检测、异常数据检测、缺失数据处理、不一致数据处理、逻辑错误检测等,是从事后诊断角度提升和保证数据质量的主要手段[2,3]。设计物联网异常数据清洗算法,是物联网数据分析中的关键问题。
目前,在基于无线传感器网络的物联网领域中,基于异常值的数据清洗技术与异常点检测技术类似,可分为以下几类:第1类是基于统计学的方法[4],假定数据集服从某种概率分布模型,把具有低概率的对象视为异常点,但实际情况不一定符合统计规律。第2类是基于聚类的方法[5],如果某些聚类簇的数据样本量比其他簇少得多,而且这个簇里的数据的特征也与其他簇差异很大,则该簇里的大部分样本点可视为异常点,但该方法需要事先确定阈值,这对于不同的数据集往往是比较困难的。第3类是基于专门的异常点检测算法,包括一类支持向量机(One-Class SVM)[6]、孤立森林(Isolation forest)[7]等。One-Class SVM通过建立分类模型得到一组精确的异常值,技术难点在于计算复杂度高和选择合适的核函数,更适用于中小型数据集的原型分析;Isolation Forest具有线性时间复杂度,可以部署在大规模分布式系统上来加速运算,但不适用于特别高维的数据,在某些局部的异常点较多的时候可能不准确。
此外,基于递归主成分分析(Recursive Principal Component Analysis, R-PCA)的异常数据清洗算法也得到了很多应用。Zhou等人[8]提出稳定的主成分追踪的方法来解决有噪情况下R-PCA算法数据恢复准确性的问题,采用低秩-稀疏矩阵分解(Low-Rank and Sparse Matrix Decomposition,LRaSMD)的技术,将2维的测量矩阵分解为低秩矩阵、稀疏矩阵和噪声矩阵,然后设计算法进一步处理。该方法旨在从有稀疏干扰的数据中恢复出低秩矩阵,但需要准确估计正常模式的相关矩阵,计算量特别大。Xu等人[9]提出一种基于LRaSMD的字典重建和异常提取方法,利用完备字典和稀疏编码构造低秩矩阵达到清洗异常值的目的,不过字典学习的计算量巨大,恢复精度较低。
本文针对传统异常数据清洗算法需要先验统计知识、计算量大、精度低的弊病,在LRaSMD模型的基础上,提出了一种基于深度神经网络的迭代阈值收缩算法框架,对物联网中时-空相关数据进行快速清洗。迭代阈值收缩算法(Iterative Shrinkage-Thresholding Algorithm, ISTA)是梯度下降法的延伸,求解的是1范数稀疏性正则化约束下的反问题[10]。其在图像处理[11]、压缩感知[12]以及信号处理[13]等领域有着广泛的应用。由于LRaSMD可以转换为上述反问题,所以可以引入ISTA来进行异常数据清洗问题的求解。虽然1范数约束问题是凸的,使得ISTA具有全局收敛性,但是其也存在不足,比如收敛速度慢、对初始参数敏感等。为了解决这些问题,本文进一步将ISTA展开为定长的深度神经网络,以神经网络层数来代替迭代次数,从而构造出ISTANet框架。在实际数据集上对该框架进行了评估,结果表明,该数据清洗方法能够得到高质量的有效数据,算法收敛速度快,精度更高。
本文的其余部分组织如下。第2节介绍了系统模型和优化问题。第3节描述了所提出的基于深度神经网络的快速异常数据清洗算法框架。第4节使用真实数据集进行实验仿真,验证了算法的性能。第5节对全文进行了总结。
2 系统建模
2.1 问题描述
在本文中,将针对特定的无线传感器网络(Wireless Sensor Networks,WSNs)应用场景,利用数据的时-空相关性,设计适合多传感器数据的离线异常数据清洗算法。本场景中数据清洗的对象为多传感器数据,算法需满足3个条件:只利用测量数据的时-空相关性;只考虑存在异常点的情况;算法的输出为逼近真实的数据,达到较高的精度。
如图1所示,椭圆形代表监测区域,椭圆形内的若干个小圆圈代表传感节点,无线传感器网络主要由部署在监测区域内的大量传感器节点组成。这些传感节点负责采集环境数据,汇聚节点将周围若干个传感节点的数据集中起来,再经由基站以无线通信的方式传输给后台数据中心。
图1 传感节点数据采集和传输示意图
由于传感器在某一时刻观测到的读数与在前一个时刻观测到的读数相似,并且相邻的多个传感节点的测量值相似,所以无线传感器的数据具有时-空相关性。当在某个域中表示时,信号有很多系数接近或等于零,因此假设时-空相关数据是低秩的[14]。

2.2 迭代收缩阈值算法(ISTA)

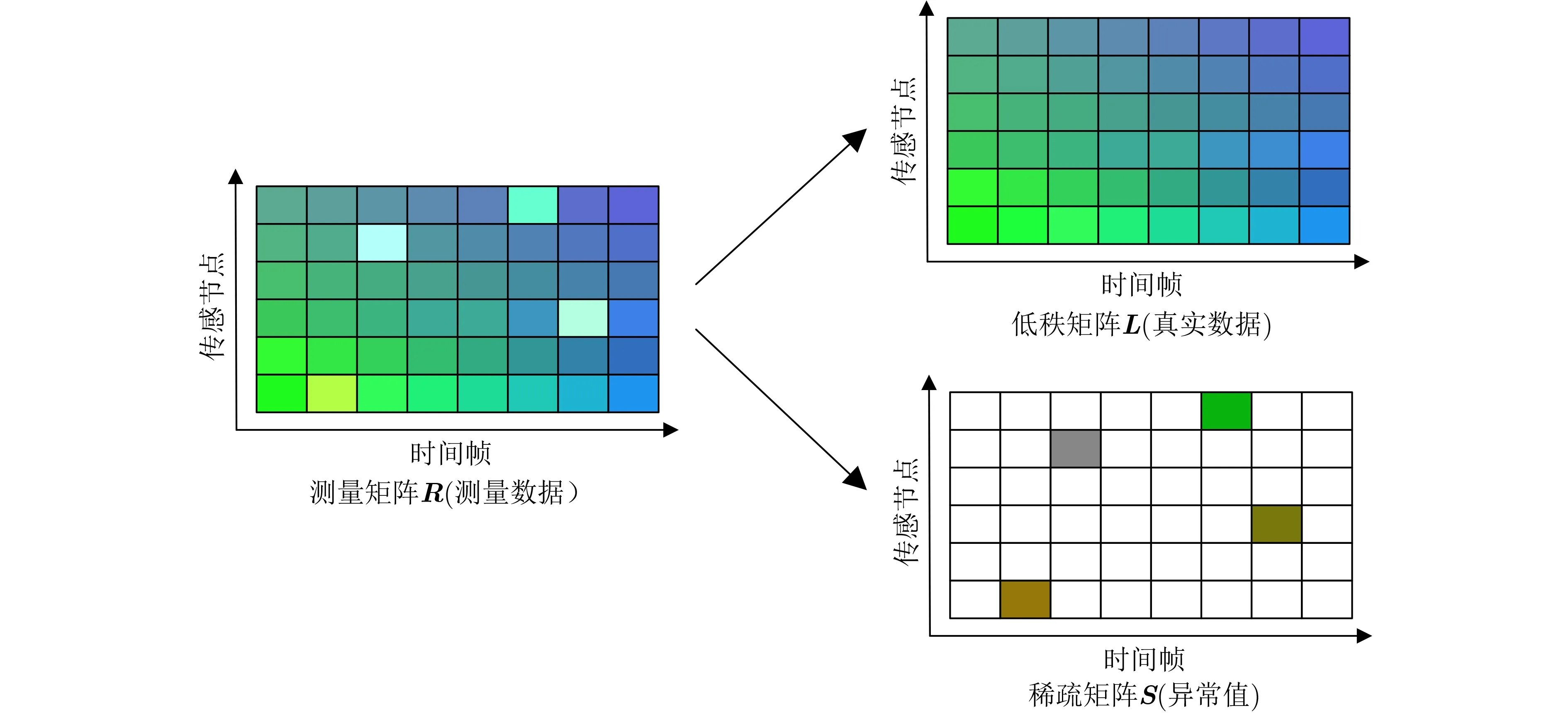
图2 无噪情况下的低秩-稀疏模型
对于大规模问题,很难快速计算出每次的迭代解。而式(8)中ISTA算法的迭代解依赖阈值参数λ1和λ2的选择。因此快速计算出合适的阈值参数是提高该算法收敛速度的关键。
3 算法描述
迭代展开(Unfolding)的概念于2012年被首次提出[18],显著地改进了收敛性。一个迭代算法可以看作一个神经网络,其中的第k次迭代被视作第k层。迭代展开的方法利用了深度学习和基于模型框架的强大功能,在一些应用领域[19]中提高了算法性能,已经有研究人员对交替方向乘子法[20]、近似梯度法[21]等方法进行了展开。
ISTA与深度神经网络在结构上具有相似之处。深度学习其实是有着超过3层隐藏层的神经网络。将ISTA中的每一次迭代看作一个时间层,软阈值函数等价于激活函数,那么ISTA可以用神经网络展开。图3展示了ISTA的迭代解的数据流图,其中K代表深度神经网络的层数。
选择归一化均方误差(Normalized Mean Square Error, NMSE)作为训练过程的损失函数。对于给定数据集中的第i个数据帧,使用迭代阈值收缩算法(ISTA)分解Ri,每次迭代过程中,需要学习的参数是λ1和λ2,最终得到该数据帧所对应的矩阵LK和SK,分别用Lˆi和Sˆi表示。网络输出值和真实值间的损失函数定义为

为了获得最优参数,使用后向传播策略计算梯度或者参数。首先初始化网络权值和神经元的阈值。在前向传播中,使用已经更新的参数,按照式(8)计算隐藏层神经元和输出神经元的输入和输出,并计算NMSE。在反向传播中,根据式(9)中NMSE的定义,再利用二次方自适应学习率优化算法,来更新每个阶段中的每个阈值参数。
具体的ISTA-Net异常数据恢复算法如表1所示,其中步骤(5)-步骤(8)的目的是参照式(8)计算出第k层神经网络的输出Lk和Sk,之后这两个值将作为第k+1层神经网络的输入来参与运算。需要说明的是,每层神经网络的阈值参数λ1和λ2的更新是独立的。同时为了取得更好的训练效果[22],实际中用于SVT和软阈值操作的阈值分别为σ(λk1)·bL·max(Lk)和σ(λk2)·bS ·mean(Sk),其中σ(x)是sigmoid函数,bL和bS是固定值,这里分别设置为0.1和1.5。
4 仿真结果
为了验证本文所采用的ISTA-Net算法在解决物联网异常数据清洗问题中的有效性,采用Intel Berkeley Research Lab[23]所测的温度数据进行仿真实验。该数据集包含54个传感器采集的14400条温度数据,每个传感器每隔30 s采集1次数据,每小时采集120次数据,温度范围在13.69~37.68°C。假定该数据集代表真实数据,采集过程中的噪声为高斯白噪声。选取其中49个传感器连续采集5天的温度数据,再加上随机异常值作为标注。将传感器1小时采集的数据看作1批数据,则5天总共有120批数据,选取的用于训练和测试的测量矩阵R的维度为49×120。仿真实验中,前80批数据为训练数据集,后40批数据为测试数据集。

表1 ISTA-Net异常数据恢复算法

图3 数据流图

其中,TP指的是确实包含异常值且被算法检测出的数据个数,FP指的是本身不包含异常值却被算法判定为异常的数据个数,FN指的是本身包含异常值但是算法却没有检测出的数据个数。从以上定义可以看出,F1分数越接近1,检测的正确率越高。
图4(b)描述了ISTA和ISTA-Net算法的F1分数随迭代次数(或神经网络层数)的变化关系。从图中可以看出两种算法的F1均是随着迭代次数的增加而逐渐增大,检测的准确率越来越高,收敛之后达到了0.9以上。不过,ISTA-Net的增加速度明显快于ISTA,并且收敛之后前者的F1还要大于后者。
在上述的对比中,ISTA-Net算法要优于ISTA的原因是ISTA算法本身是一个固定阈值的计算过程,算法的最终性能严重依赖分解软阈值时收缩阈值的初始值;而ISTA-Net算法受益于神经网络内部权重更新,对参数选择相对能够快速自动更新收缩阈值。因此ISTA-Net算法收敛更快,数据清洗的精度更高,性能得到了显著的提升。
需要指出的是,ISTA-Net前向传播的每一层的运算量和ISTA算法的1次迭代的运算量相同,通过网络训练得到最佳迭代参数后,ISTA-Net的计算过程与ISTA算法完全一致。此外,将ISTA算法展开为神经网络后,可以加快收敛速度,大大减少所需的迭代次数,这降低了整个算法的计算量。
在网络训练过程中,不同学习率下的ISTA-Net算法的损失随着训练数据批次数的变化如图5所示。其中,异常值、噪声以及初始阈值的设置均与上述相同,神经网络层数为25。由图5看出,不同学习率下的算法损失随着训练批次的增加而逐渐下降,同时学习率越大,损失函数收敛得越快,但是波动也越大。因此,在ISTA-Net算法的训练过程中,选择合适的学习率能够实现算法的收敛速度和恢复精度之间的平衡。
值得强调的是虽然对于Intel Berkeley Research Lab所测的温度数据集,ISTA-Net只需25层固定长度的深度神经网络就达到了优于传统ISTA算法的性能,但是对于不同的数据集,ISTA-Net需要的神经网络层数并不一定相同。不过尽管如此,ISTA-Net算法的收敛性仍远快于传统ISTA算法。这里选取由国家青藏高原科学数据中心提供的大纳伦河流域修正后的温度数据集[24],相关参数设置与前述相同。图6将ISTA和ISTA-Net算法在该数据集中测试阶段的损失函数随迭代次数(或神经网络层数)的变化情况进行了对比。可以看出在大纳伦河流域数据集中ISTA-Net达到收敛所需的神经网络层数为60,不同于前一数据集的25层,但是相对于传统ISTA算法的近600次迭代才能收敛而言,性能的提升是比较显著的。
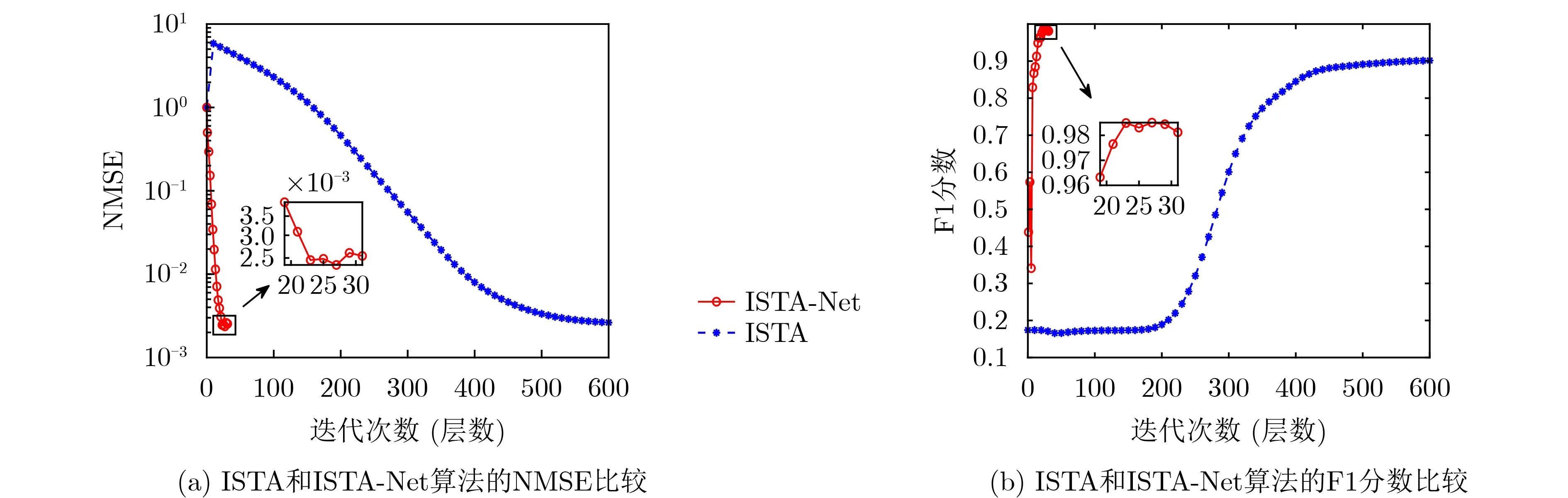
图4 ISTA和ISTA-Net算法的性能对比
为了证实所提算法方案的优越性,本文将ISTA, ISTA-Net算法和孤立森林算法进行了对比。这里用到的性能指标仍是上面提到的F1分数,数据集使用Intel Berkeley Research Lab所测的温度数据集,数据中异常值比例将逐渐增加,其他的设置(比如噪声以及初始阈值的设置)均与上述相同,ISTA-Net用到的神经网络层数为25。图7描述了随着数据中异常值比例的增加,3种算法的F1分数的变化情况。可以看出,在异常值比例比较小时,ISTA和孤立森林算法的F1分数比较低。这是因为此时实际上被叠加了异常值的数据占的比重小,因此TP比较小,而此时两种算法的FP和FN相较于TP而言较高,进而导致F1分数比较低。但随着异常值比例的逐渐增加,TP的比重提升,ISTA和孤立森林算法的F1分数逐渐升高。值得强调的是,虽然在异常值比例较低时,孤立森林算法的F1分数略高于ISTA,但是随着异常值比例的提升,前者性能逐渐弱于后者,并且差距逐渐拉大。对于ISTA-Net算法而言,其F1分数也是随着异常值比例的增加而逐渐升高,并且其起始点要远高于另外两种算法,性能差距比较明显。
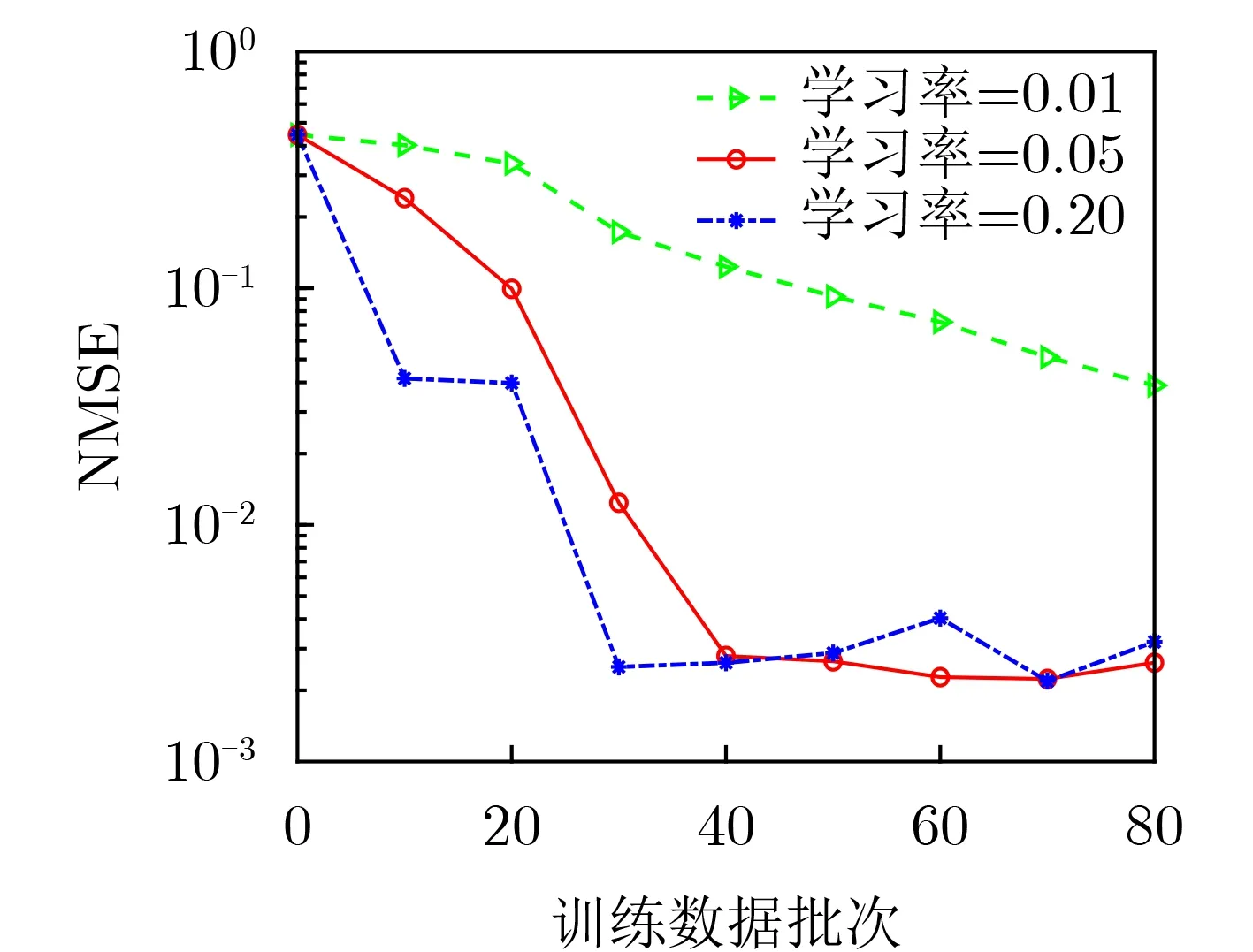
图5 ISTA-Net损失随训练数据批次数的变化情况
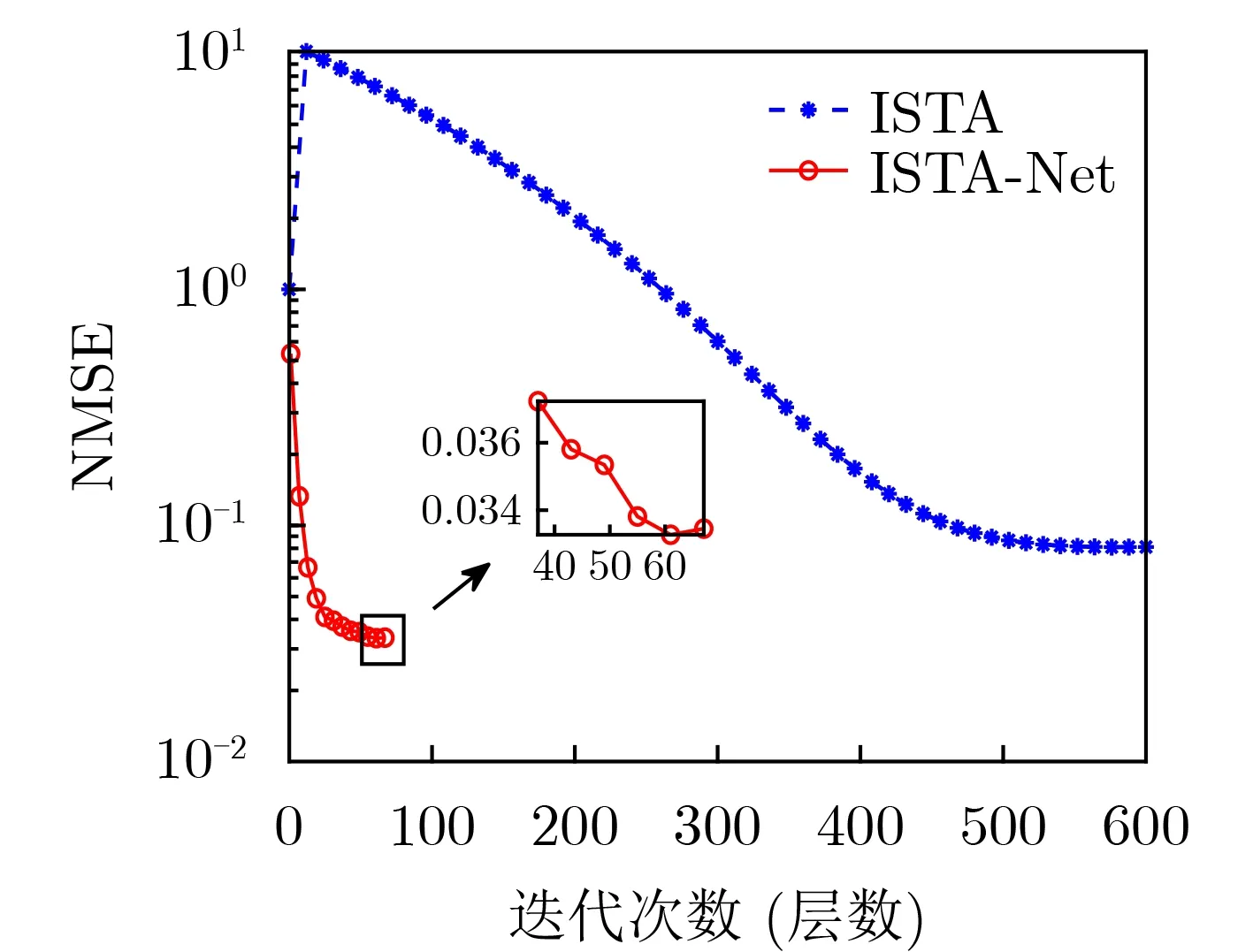
图6 ISTA和ISTA-Net算法的NMSE比较

图7 3种算法的F1分数随异常值比例的变化情况
由上述对比可以看出,ISTA-Net算法确实能够取得比ISTA以及孤立森林算法更好的性能,而且其对不同异常值比例的情况都表现得比较好,具有较好的鲁棒性。
5 结束语
本文针对传统异常数据清洗方法需要先验统计知识以及计算量大的问题,提出了一种基于神经网络的迭代阈值收缩算法,从而对物联网中时-空相关数据进行快速异常数据清洗。利用了感知数据的时-空相关性和异常值的稀疏性,根据低秩-稀疏矩阵分解模型,采用迭代收缩阈值算法(ISTA)求解优化问题,进一步将ISTA展开为定长的深度神经网络。在实际数据集上对算法进行了评估,仿真结果表明,该方法能够自动更新奇异值分解过程中的软阈值参数,克服了传统ISTA算法对初始参数敏感以及收敛速度慢的问题。在选择适当的阈值参数后,算法收敛速度更快,数据清洗的精度更高。
