基于概念关系对齐的中文抽象语义表示解析评测方法
2022-03-09肖力铭许智星霍凯蕊冯敏萱周俊生曲维光
肖力铭,李 斌,许智星,霍凯蕊,冯敏萱,周俊生,曲维光
(1. 南京师范大学 文学院,江苏 南京 210097;2.南京师范大学 计算机与电子信息学院,江苏 南京 210023)
0 引言
随着词法、句法分析技术的日益成熟,自然语言处理已经整体推进到了语义分析层面。句子语义作为重点和难点,更占据了语义分析的核心地位[1]。针对整句语义形式化表示的缺失,以及句子语义标注存在的领域相关性的问题,Banarescu等人[2]于2013年提出了一种与领域无关的整句语义表示方法——抽象语义表示(Abstract Meaning Representation,AMR)。AMR能将一个句子的语义抽象为一个单根有向无环图,其不仅可以描写一个名词由多个谓词支配所形成的论元共享现象,还允许补充隐含语义以完整地表示句义。强大的语义表示能力使得AMR一经问世便引起了广泛的关注,涌现出大量关于AMR自动解析技术、AMR转换应用等方面的文章。图1以“I have been having some trouble with money.”为例给出了AMR的两种展现形式:文本缩进法(上)和图示法(下)。
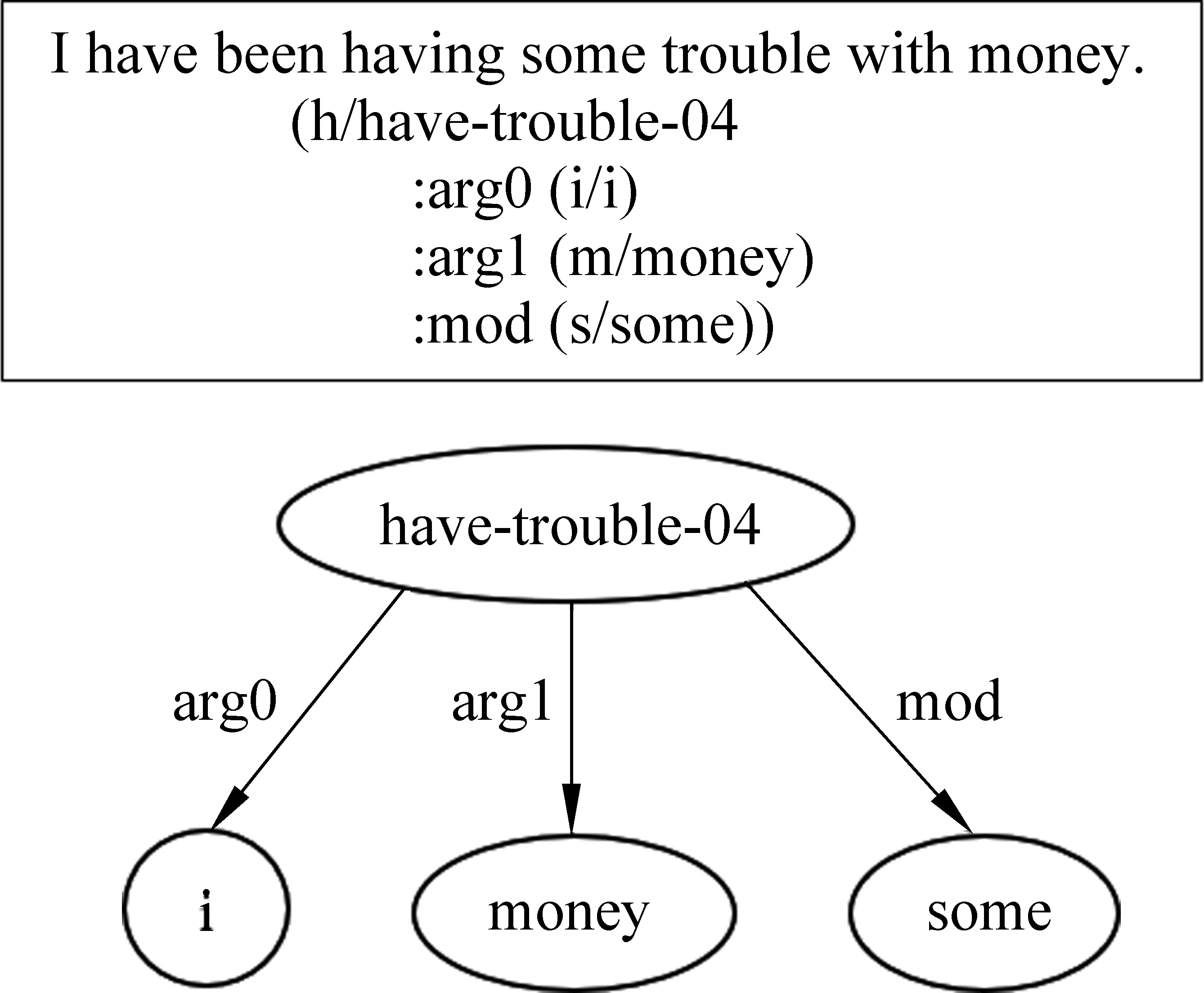
图1 AMR示例
不过,AMR在体系上仍存在两大问题。首先,AMR只关注实词,忽视虚词,对整句的语义表示仍不够完整[2-3],如图1句子中的“with”未得到表示。其次,AMR缺乏实词和概念的对齐(alignment),导致在相关模型的训练中需要使用对齐器(aligner)进行单独的对齐步骤。但对齐器自身存在误差,比如目前精度最高的JAMR-Aligner[4]在遇到同一个词根的不同形态同时出现时,容易做出错误的判断[5]。如图1句子中同时出现了have和having,对齐器可能错误地将have-trouble-04与have对齐。对齐器的误差将降低模型约5%~10%的分析精度[6-7]。
2016年,Li等人[8]将AMR引入到汉语中,进行了三大调整和改良。首先,在体系上增加了对于虚词的表示,如增加表示“体”“个体量词”等语义关系的标签。其次,在表示方法上提出了概念、关系与句子中的词语对齐,特别是把虚词标注在节点或有向弧上[3,9]。最后,根据汉语的语言特点规定了具体的标注细则,如规定了重叠式、离合词、连动结构等特殊结构的处理方法。最终,设计了一套中文AMR的标注规范,构建了一个规模约为两万句的中文AMR语料库[8-9]。
随着语料库规模的扩大,越来越多的学者参与到中文AMR的自动解析工作中[10-14]。他们研制的解析系统能在给定句子的情况下,预测并输出该句相应的AMR结构。在2020年国际自然语言学习会议CoNLL发布的跨语言语义表示方法解析评测任务MRP2020中,中文AMR的自动分析达到了0.81的F1值[15-16],是目前最好的结果。
尽管如此,这些成果仍不能体现中文AMR解析的真实水平。包括CoNLL在内,所有实验和评测所使用的评测指标都是基于英文AMR设计的,并不适合中文AMR。Smatch[17]、SemBleu[18]等整体性指标无法兼容中文AMR所做出的调整,评测语料只能删除对齐信息。中文AMR的概念和关系对齐信息,特别是标注在有向弧上的虚词并没有得到解析和评估。CoNLL使用的评测工具MTool[15]能够评测概念对齐信息,但也无法衡量关系对齐信息。其次,一些AMR分项评测指标[19-20]主要围绕概念识别和关系识别子任务设计,也不涉及对齐信息。
为了弥补中文AMR解析评测在对齐信息上的空缺,为未来中文AMR解析工作的发展提供新的标准和方向,本文基于Smatch指标进行改进,提出了Align-Smatch指标。同时,为了给评测提供细粒度的可读性报告,本文围绕对齐信息,提出了概念对齐指标、关系对齐指标、隐含概念指标共三个分项评测指标,以更好地服务于中文AMR解析评测。
1 概念对齐和关系对齐
AMR的本质是把句子中的词以及词之间的联系抽象为“概念”和“关系”,反映在AMR图中则分别是“节点”和“有向弧”。具体来说,词被抽象为概念节点,词之间的关系被抽象为带有语义角色标签的有向弧。
这种抽象的语义表示方式,一方面使得AMR拥有较强的语义表示能力,能够增加、删除、修改概念节点,对隐含概念进行补充标注。如图2中,AMR在标注专有名词“中国”时,将其中的隐含概念“country”抽象为节点补出。

图2 “中国金融对外开放稳步前行”中文AMR图示
但另一方面,也使得AMR难以反映概念和词的映射关系,因为它不进行概念对齐。AMR是基于英文设计的,考虑到英文词语有形态变化,而概念没有,所以在AMR标注过程中,难以使用词语编号来代表概念,只能取词语的首字母作为概念节点的编号,或按照节点的出现顺序分配编号[9],如表1左侧所示。这导致计算机不能直接对概念溯源,也无法从AMR中还原句子的语序,加大了AMR解析等应用技术的难度。
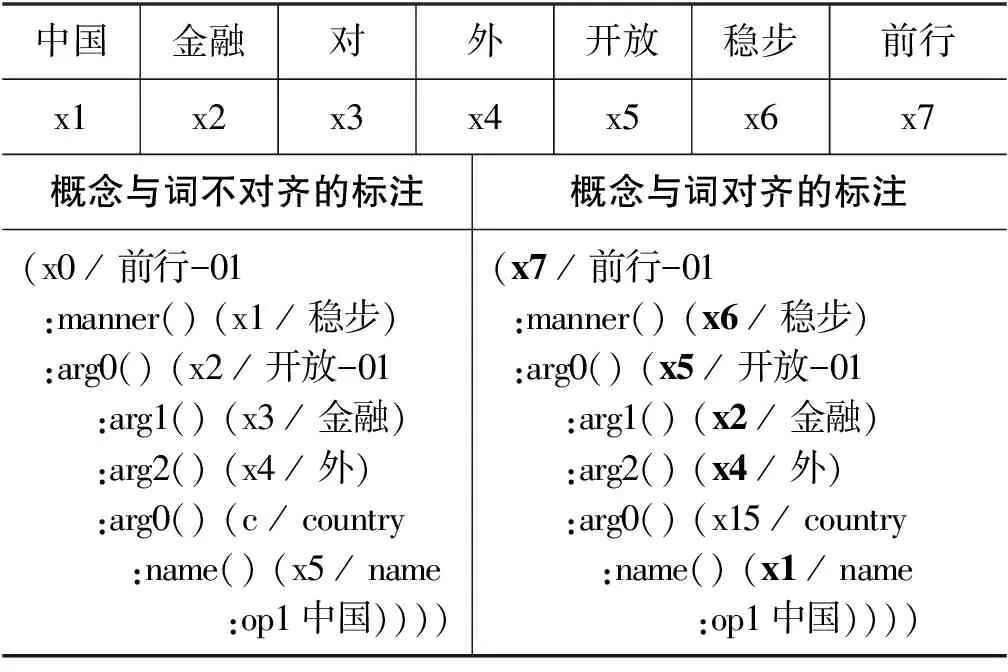
表1 概念对齐标注
为了解决这一问题,李斌等人提出了融合概念对齐的中文AMR标注方案,实现了中文AMR的概念对齐[9]。通过对分词后的原始句子按照线性有序的原则,给每个词分配编号,每个概念节点也被赋予了相应的编号。编号采用“x+数字”的形式表示,如果数字不大于句子的总词数,则代表与该节点对齐的词的编号。如表1所示,加粗部分即为对齐后的编号表示,保证了大部分概念节点与原始句子中的词对齐了。没有对齐的概念则是被补出的隐含概念,如“x15”节点的概念country,它被赋予了大于句子总词数的编号。
除了概念对齐,AMR还直接忽略了如介词、冠词等虚词,认为这些词对句子的语义没有贡献。但在解析中,一些研究尝试将虚词利用起来,提高模型关系预测的精度。如对齐器ISI[21]将介词与语义角色关系进行对齐,Brandt等[22]在解析模型中加入介词语义角色标注信息。虽然这些尝试尚未取得显著成果,但虚词在AMR解析中的作用仍有研究空间。其次,虚词对连接上下文有很大的作用,有利于更为精准地将AMR还原为句子、语篇。
因此,中文AMR选择保留虚词进行标注,将表示句子的体意义和语气意义的虚词处理为概念节点;将表示实词间关系意义的虚词视为语义关系的映射,与语义角色标签一同标注在有向弧上[3]。有向弧上的虚词同样带有编号,这完成了语义关系与词的对齐,实现了关系对齐。如表2所示,加粗部分即是把原始句子中表示实词“开放”和“外”之间关系的虚词“对”放进了AMR中,使用编号x3将表示对象的语义关系arg2与虚词“对”进行对齐。

表2 关系对齐标注
概念对齐和关系对齐的增加不仅改良了AMR表示体系,还为评价解析系统的优劣提供了新的维度,即对齐能力。该维度旨在衡量系统捕捉句子和AMR映射关系的程度,有利于对解析结果进行错误分析,而不仅仅是判断节点和有向弧是否正确。具体来说,概念对齐信息反映了概念和词的关系,而关系对齐信息反映了语义关系和词的关系,都是衡量对齐能力的重要因素。此外,概念对齐信息将隐含概念也区分了出来,而隐含概念大多来自复句关系和专有名词,对隐含概念进行评测有利于衡量AMR语义表示的完整度。这些都是缺乏对齐信息的AMR难以做到的。
2 基于概念关系对齐的中文抽象语义表示 解析评测方法
目前还没有解析器能够处理带有概念、关系对齐的中文AMR。为了推动中文AMR解析的进一步发展,首先应提供能够兼容概念、关系对齐的评测方法。为此,在整体性指标方面,我们在现有的评测方法Smatch的基础上,加入概念对齐和关系对齐的表示,提出了Align-Smatch指标,来总体评估中文AMR解析器的精度。在分项指标方面,设计了概念对齐指标、关系对齐指标及隐含概念指标来评测解析器在对齐能力上的表现。
2.1 Align Smatch
整体性指标直接返回一个0-1之间的数值来衡量两个AMR图的匹配程度。其中,Smatch是目前使用最广泛的AMR解析评测指标。对于两个需要进行匹配的AMR图,Smatch首先会重新命名AMR图的节点,并将每个AMR图转化为一个三元组的集合,然后利用爬山算法(Hill-climbing method)进行贪心式搜索以获取两个集合最大的三元组匹配个数,最终返回准确率(Precision)、召回率(Recall)和F1值。
Smatch生成的每个三元组集合一般包含三个三元组类别: 对于一个节点N1,有三元组instance(N1,C)表示该节点的概念(Concept),有三元组P(N1,V)表示该节点具有的属性(Property)和属性值(Value)。特别的,当P=“TOP”时,节点N1是顶点。节点N1和节点N2之间的有向弧用三元组R(N1,N2)表示,R代表语义角色(Role),节点N1是源节点,节点N2是目标节点。
以图2“中国金融对外开放稳步前行”的中文AMR为例,表3列举了由Smatch生成的三元组集合,共15个三元组。与中文AMR相比,节点被Smatch重新命名,缺失了用来表示概念对齐的节点编号、被标在有向弧上的虚词“对”,而且关系对齐也没有得到体现。可见,Smatch指标并不适合评测中文AMR。
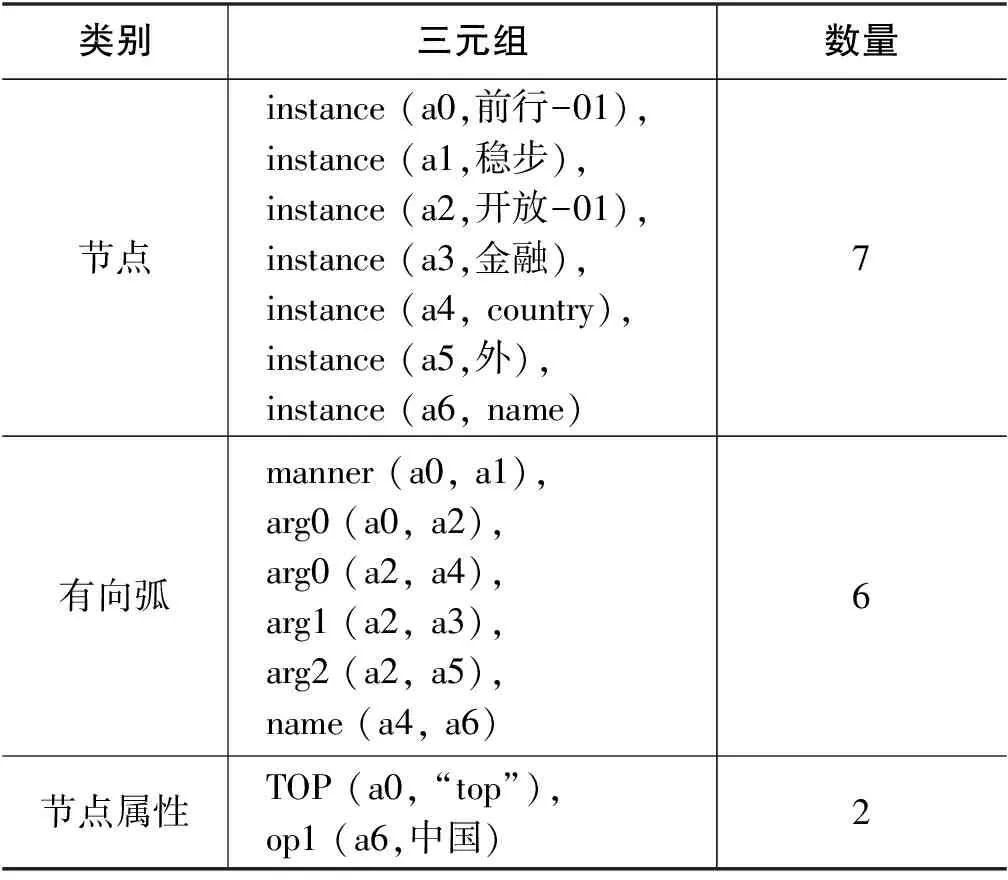
表3 Smatch三元组
除此之外,Smatch本身还存在两个不足:
(1) Smatch在比较有向弧的三元组时,只考虑语义角色标签是否相同,而没有考察节点的概念是否一致。这容易出现两个语义完全不同的AMR却有较高分数的情况[18]。
(2) Smatch会为每个AMR图的根节点加入TOP属性三元组,但比较时并不考虑两个根节点的概念是否相同,这使得两个根节点概念不一样的AMR也会有匹配上的TOP属性三元组。
以图3和图4为例,这两个语义完全不同的句子在Smatch中能达到约40%的F1值,共有两条边arg0, arg1与TOP属性得到匹配,这显然是不合理的。
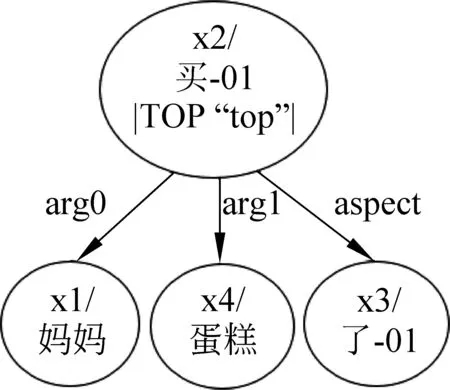
图3 “妈妈买了蛋糕”中文AMR图示
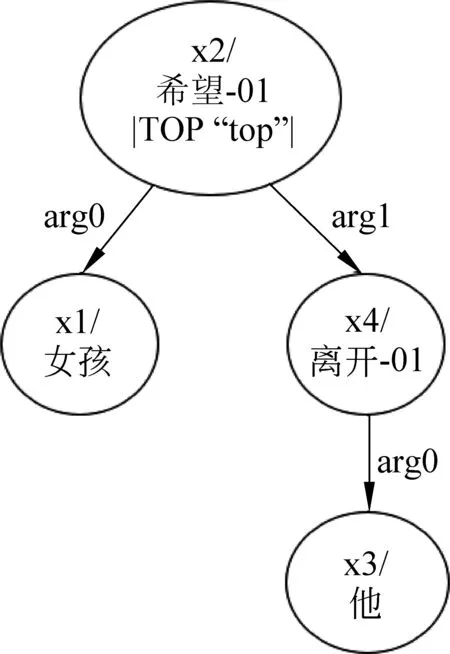
图4 “女孩希望他离开”中文AMR图示
为了解决上述问题,我们首先对Smatch进行了两处修正。一是在匹配有向弧三元组时,在语义角色相同的前提下,限制源节点和目标节点必须相同,否则不予匹配。二是将表示根节点的三元组由属性移到有向弧的类别中,表示为TOP (a0, a0),即视为一条指向自身的有向弧,如图5所示。这使得在匹配根节点时,会根据第一处修正,考察根节点的概念是否一致,从而避免了上述不同的根节点却能相互匹配的问题。图3和图4的Smatch值在第一处修正后降低为0.13,在第二处修正后变为0,更加符合人类的直觉。下文使用“FIX”代表修正版本。
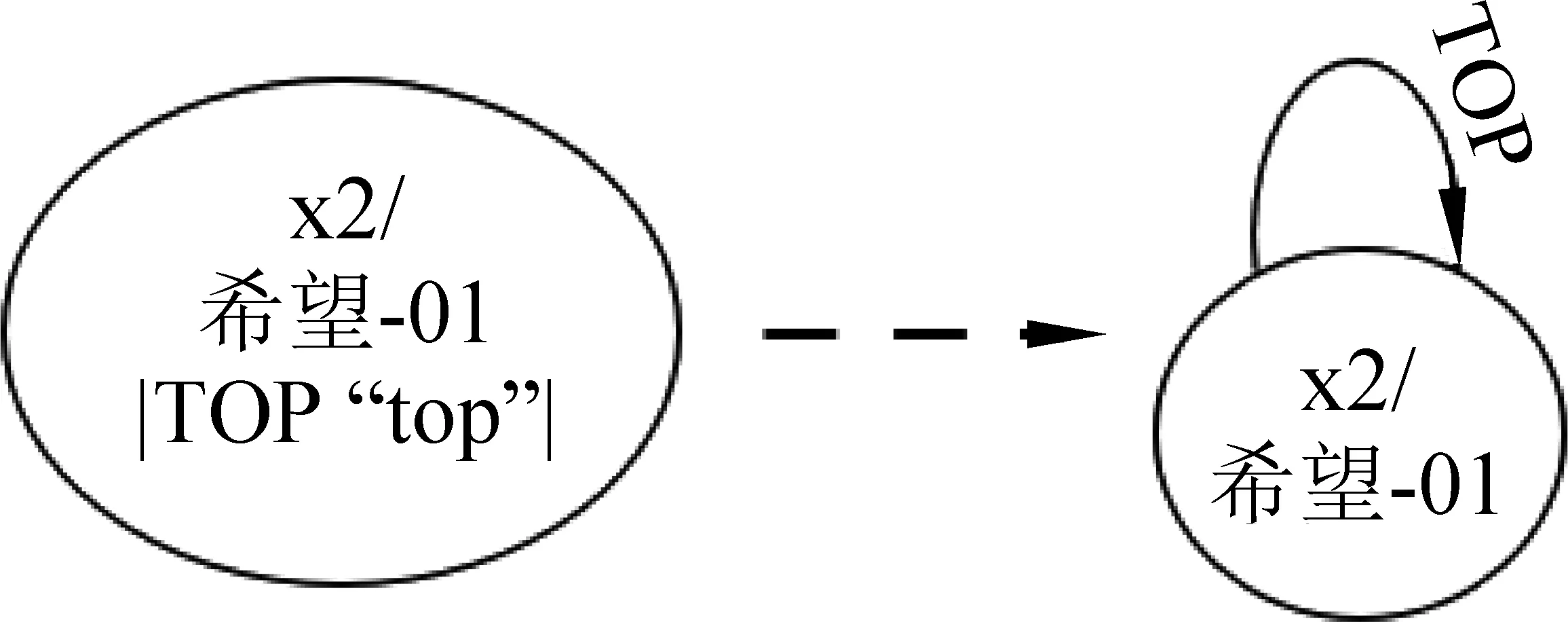
图5 Align-Smatch根节点图示
之后,我们在Smatch中融入了一个描写概念对齐的三元组和一个描写关系对齐的四元组。假如句子含有L个词,若节点N1的索引I≤L,则有一个P=“anchor”,V=I的节点属性三元组anchor(N1,I)表示节点N1的概念对齐信息。对于关系对齐,Smatch已有包含语义角色标签的三元组,只需再表示对应语义关系的词即可。我们将有向弧上的词WA(Word in Arc)和它的索引值I视为一个整体,用一个四元组((WA,I),N1,N2)来表示,N1、N2分别表示有向弧的源节点和目标节点。以图2中x5节点到x4节点的有向弧为例,它带有语义角色标签arg2和一个介词“对”,因此要表示成arg2(x5, x4)和(对, 3)(x5, x4)(1)为了与三元组表示一致,具体例子中将有向弧上的词和该词的索引值置于括号外。。这两个多元组表示arg2和“对”都在这条有向弧上,表示出了关系对齐信息。
表4展示了Align-Smatch形成的多元组。与表3相比,表4用有向弧类别表示根节点,而不是用节点属性类别表示;在节点属性类别中增加了表示概念对齐的三元组;在有向弧类别中增加了表示关系对齐的四元组。Align-Smatch多元组更加完整地表示了中文AMR。
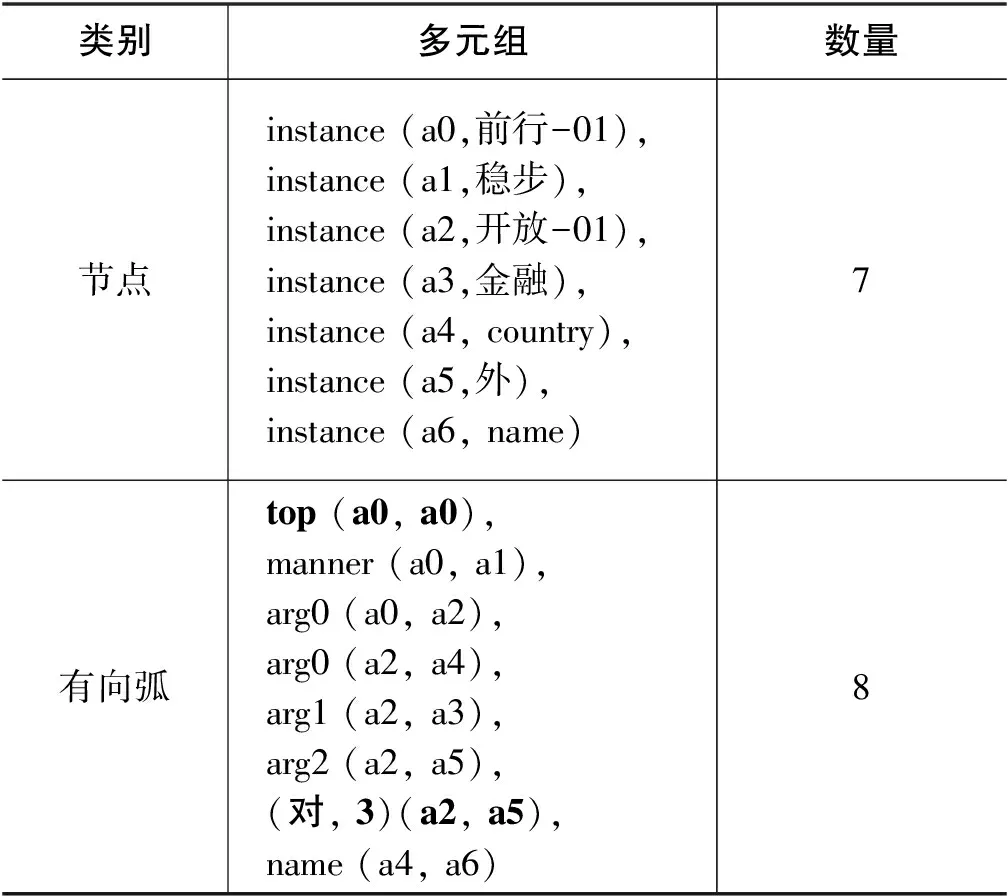
表4 Align-Smatch多元组
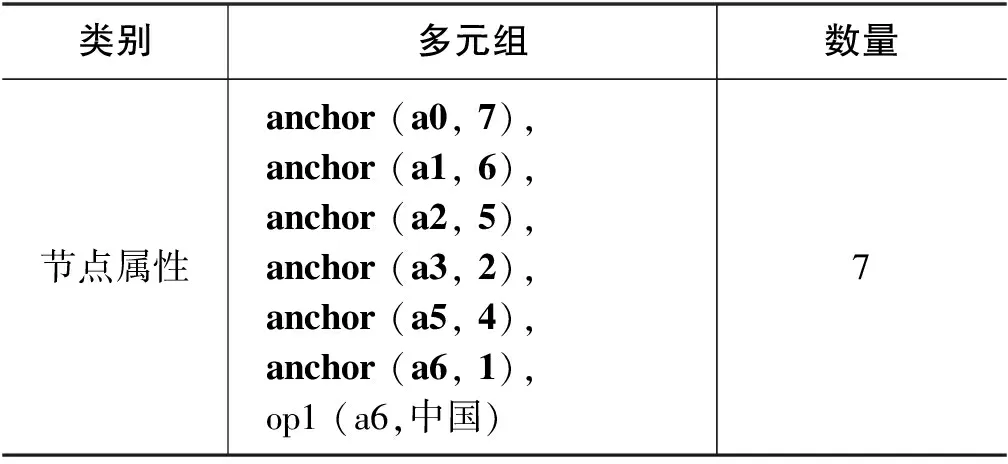
续表
为了生成表4中表示对齐信息的多元组,我们改进了Smatch生成三元组的算法,使其能够识别对齐信息。新算法采用Shift-Reduce方法依次处理中文AMR的字符wn,使用一个栈Node_Stack(NS)来储存节点,一个栈Arc_Stack(AS)来储存有向弧上的词,一个栈Relation_Stack(RS)来储存语义角色,一个缓存区(Buffer)来中转语义角色。最终,通过中文AMR的四个符号“)”“(”“: ”“/”生成相对应的状态码(State),从而对字符串s、栈和缓存区进行相应的操作(Action),将输入的中文AMR转变为多元组集合TW。表5为多元组生成算法的伪码。

表5 Align-Smatch多元组生成算法伪码
算法1与Smatch生成三元组的算法的不同主要在于对符号“(”的操作,以及新增的AS栈和缓存区。在英文AMR中,“(”后是节点,但在中文AMR中,“(”后还可能是有向弧上的词。以表2右侧的中文AMR“:arg2(x3/对) (x4/外)”为例,共有两个“(”,第一个“(”的后面是有向弧上的词“对”,第二个“(”的后面是概念节点“外”。为了对二者进行区分,在算法1中,第一个“(”之前的语义角色不再直接进入RS栈,而是先进入缓存区,直到操作符变为“)”才从缓存区弹到RS栈。这样,“(”和“)”之间的操作符“/”就能根据缓存区的状态,对前后字符串的归属做出判断: 如果缓存区不为空,则字符串为有向弧上的词,否则为节点。表6是以表2右侧的中文AMR为例的算法1部分运行流程。
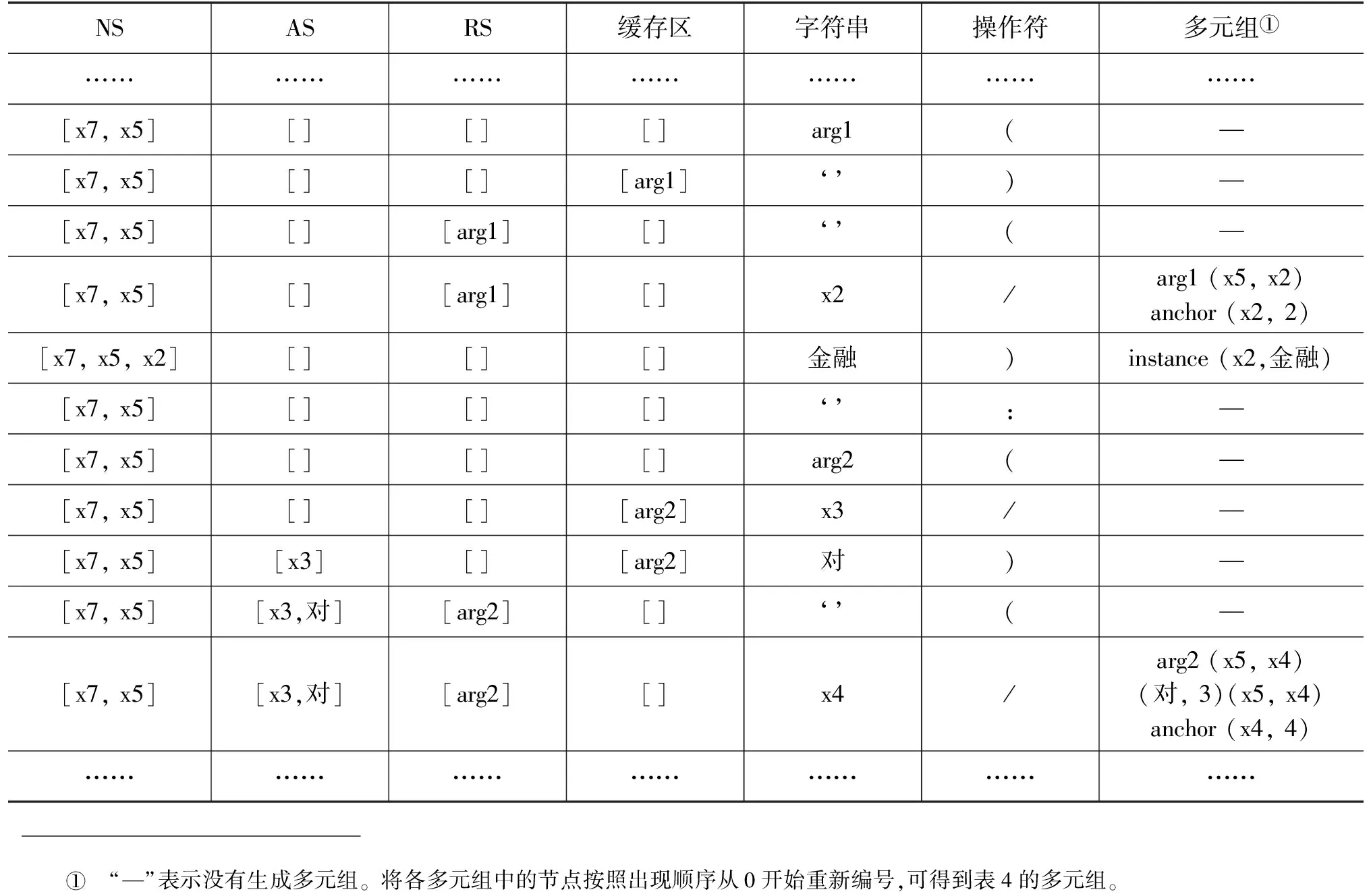
表6 以“中国金融对外开放稳步前行”中文AMR为例的算法1部分流程
通过算法1将中文AMR语料(Gold AMR)Gg和解析器输出结果(Parsed AMR)Gp转变为两个多元组集合Tg和Tp后,我们沿用Smatch的爬山算法来获得两个集合最佳的多元组匹配数。
爬山算法首先对Tg和Tp多元组中的节点进行初始化匹配,得到首次匹配的多元组数和节点映射集。例如,Tg有三元组instance (a0, 前行-01),Tp有三元组instance (b0, 前行-01),如果它们概念相同,则形成映射对(a0, b0)。接着,在初始的映射集中通过“交换(Swap)”和“移动(Move)”两个操作寻找更好的匹配结果。
“交换”发生在两个映射对之间,如有(a0, b0),(a2, b2)两个映射对,交换彼此的映射对象后,形成(a0, b2),(a2, b0)两个新的映射对。
“移动”发生在一个映射对和未被匹配的节点之间,如有(a0, b0)映射对和未匹配的节点b5,则会尝试构建映射对(a0, b5)。
最终,通过多次初始化以避免陷入局部最优的困境[15],搜索到两个多元组集合最优的匹配数。默认初始化次数为5次,具体如表7所示。

表7 Align-Smatch爬山算法伪码
根据匹配结果,将返回准确率P、召回率R、F1值来评估解析器的精度。
由此,概念关系对齐信息融入到了Smatch指标中,并能对中文AMR进行评测,我们将该指标称为Align-Smatch。
(1)
我们在CAMR 1.0语料库(2)https://catalog.ldc.upenn.edu/LDC2019T07中随机抽取了100句带有关系对齐的中文AMR作为标准语料(G)。由于目前没有能够处理关系对齐信息的中文AMR解析器,我们使用人工标注数据作为实验的对照语料,选择了两名标注人员对这100个句子进行重新标注,得到对照语料A和B。表8是三个语料的基本统计数据。
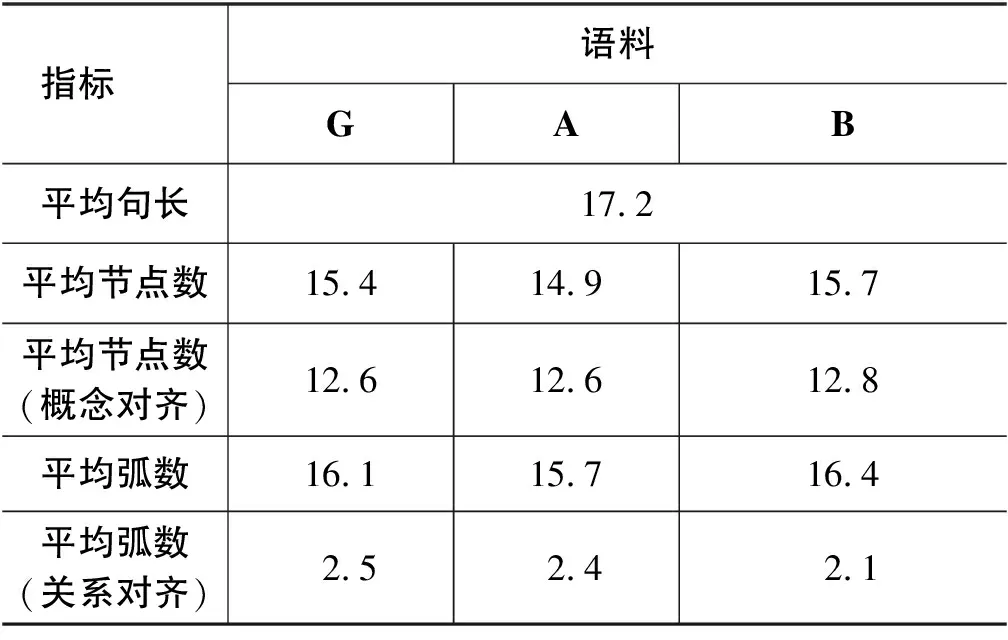
表8 实验语料基本统计数据
将对照语料和标准语料两两组合,得到三组实验对象: A-B、A-G、B-G,分别使用Smatch、加入概念对齐的Concept-Smatch、加入概念关系对齐的Align-Smatch共三个指标进行评测,其中,Concept-Smatch和Align-Smatch分别用修正版(FIX)再进行一次评测。表9为实验结果。
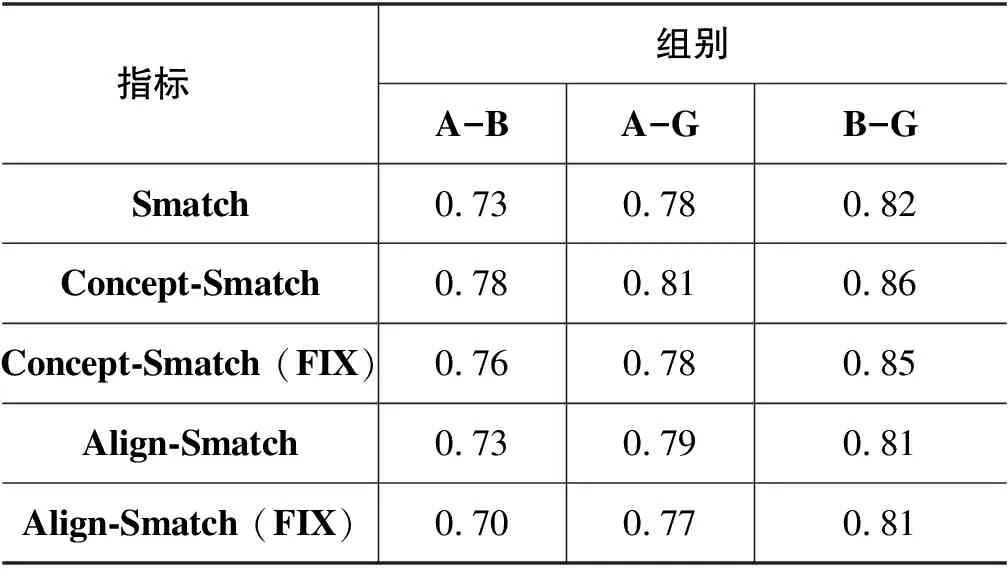
表9 整体性指标评测实验结果
从表9可以看出: 同一个指标下,B-G > A-G > A-B,说明语料B的标注更为标准。A-B的Smatch分数小于AMR要求的一致性准则0.83[2],说明A和B标注一致性较差。
同一组实验对象下,融入概念对齐信息的Concept-Smatch修正前后的分数均大于Smatch,提升了约3到5个百分点。这主要归因于中文AMR标注平台对于概念对齐标注的支持。标注人员只需输入词语编号就能实现概念对齐,还用词语高亮警示防止漏标词语[9],提高了概念对齐信息的标注准确率,进而提高了评测分数。
Align-Smatch的分数修正前后则普遍低于Smatch和Concept-Smatch,说明A、B在标注有向弧上的词时存在较多错误。错误主要集中在以下几点:
(1)虚词框架结构。如“所发出的信息”位于有向弧上的词是一个框架结构“所……的”,但漏标了“所”。
(2)有向弧的源节点或目标节点。如“只可惜这些人虽有一颗心”的连词“虽”应标在表示转折关系的节点contrast和概念节点“有”之间的有向弧上,但错误地标注在“可惜”和“有”之间的有向弧上。
(3)副词。中文AMR考虑到副词类别繁多、内部虚化程度不同的特点,将大多数副词与其他虚词区分开来,标注为节点概念。对于一些语义较虚的副词,标注可能会出现错误。如“昨晚未雨绸缪了一下”的“一下”是频率副词,用在动词后表略微之意,语义较虚。中文AMR将其处理为概念节点,与另一个概念节点“未雨绸缪”之间是表示频率的frequency关系。B标注则处理为与frequency关系对齐的词,因此无法得到匹配。
B标注在关系对齐信息上还存在较大的漏标问题,它标有关系对齐信息的平均弧数仅为2.1条,相比标准语料少了0.4条,因此B-G的Align-Smatch分数相较Concept-Smatch的下降幅度要大于A-G。
修正版的分数均不高于普通版本,这是因为修正版对于有向弧的匹配要更为严格,但也更为合理。以“人们越来越开始怀疑他们所发出的信息,是因为自己屡屡被骗。”一句为例,图6为人工标注A的中文AMR图示,图7为标准语料G的中文AMR图示。加粗部分为无法匹配的部分。
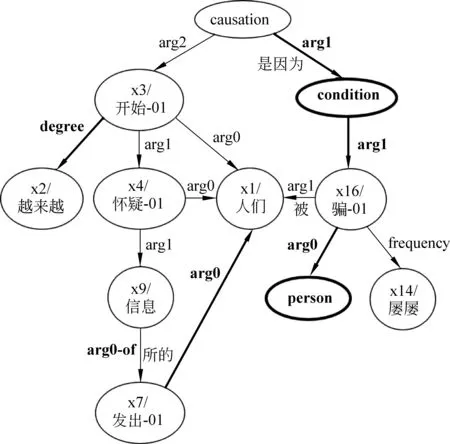
图6 中文AMR人工标注图示

图7 中文AMR标准图示
两图的Align-Smatch得分为0.76,修正后为0.73,正确匹配的三元组数减少了一个。这是因为修正前匹配有向弧的算法主要考虑语义角色是否相同,所以会将图6的arg0(x16, person(3)为方便区分对齐信息,图6、图7不为隐含概念节点添加编号。)有向弧与图7的arg0(x16, x5)有向弧相匹配,这显然是错误的,因为它们的目标节点并不相同。修正后的算法避免了这种情况的发生。
有趣的是,B-G的评测分数并没有在修正前后有所波动,而A-G则下调约两个百分点。这可能是因为B标注的有向弧更为贴合标准语料,而语料A标注的有向弧可能出现源节点或目标节点的错误。
2.2 三个分项指标
仅仅使用整体性指标还不足以评测解析系统的性能,因为整体性指标颗粒较粗,可读性差,无法体现解析系统在概念识别、关系识别等单维度子任务的表现情况,也无法反映解析系统的优势和劣势,不利于系统的进一步改进。因此,AMR解析评测还需要设立分项指标,多维度地评测解析系统,满足具体任务的考察需求。
Damonte等人[19]提出了九个维度的分项指标: 不考虑语义角色的Smatch指标、不考虑语义框架的Smatch指标、名词短语指标、边的重入性指标、概念指标、专有名词指标、含wiki属性的专有名词指标、极性属性指标、语义角色指标。我们在此基础上结合中文AMR的特点,增加了概念对齐指标、关系对齐指标,以及隐含概念指标。
概念对齐指标(Concept Alignment, CA)专注于衡量Gg和GP两个中文AMR概念对齐信息的匹配程度,可以考察解析器在概念对齐子任务中的表现情况。从中文AMR中提取节点N,获取概念映射到词的索引值I,以及概念C,转换为三元组C(N,I)用以计算概念对齐指标。概念相同时,若两个三元组的索引值也相同,则三元组正确个数加一。最终返回正确率PCA、召回率RCA和F1CA值。
(2)
概念对齐指标还可以用于英文AMR解析评测。近年来,随着深度学习的兴起,不少研究[6-7,20,23-24]借助基于注意力机制的编码器-解码器模型,让解析器自动获取对齐信息,从而舍弃了容易带来错误传播的外部对齐器。虽然不使用对齐器后,解析结果得到了提升,但这些解析器的对齐精度也不得而知。因此,需要一个概念对齐指标来评估解析器在对齐子任务中的表现情况。
关系对齐指标(Relation Alignment, RA)考察解析器将词对应到有向弧的能力。将有向弧上的词WA、词的索引值I,和有向弧的源节点N1、目标节点N2转换为四元组((WA,I),N1,N2),计算两个关系对齐四元组的匹配情况。有向弧上的词和索引相同时,若源节点和目标节点也相同,则四元组正确个数加一。最终得到正确率PRA、召回率RRA和F1RA值。
(3)
中文AMR里,还存在没有概念对齐的节点。这些节点是不出现在句子中的隐含概念,包括复句关系概念,如“causation”概念表示因果关系;专有名词概念,如“上海”中隐含的“city”概念。隐含概念与句子语义的完整度以及专名识别紧密相关,有必要对解析器生成隐含概念的能力进行考察。因此,我们提出隐含概念指标(Implicit Concept, IC),通过统计两个AMR图没有概念对齐的节点个数,计算正确率PIC、召回率RIC和F1IC值,得到该指标。
(4)
表10是A-G、B-G在这三个分项指标下的表现情况。二者在概念对齐指标上均有较高的分数,与整体性指标反映的趋势一致。从该分数也可以看出,即使有标注平台的帮助,标注概念对齐信息仍会出现错误。特别是遇到一个概念对齐多个词、一个概念对齐语素的情况,标注者容易错误地组合语义或拆分语义,导致错误的概念对齐信息产生。句中的同形词和长距离依存的词也容易被错标概念对齐信息。

表10 分项指标评测结果
A、B在关系对齐指标的分数则远低于概念对齐指标,说明关系对齐的标注难度更大。A的关系对齐指标分数比B高约6个百分点,说明A更善于标注关系对齐信息,这与整体性指标的对照实验结果相互印证。
B在隐含概念指标的分数上比A高约10个百分点,显然B更善于补出句子的隐含概念。A则存在漏标,根据表8可算出,G的平均隐含概念节点数约为3个,A仅有约2.3个。具体错误类别中,A有约70%的复句关系概念标注错误,B有约67%的专有名词概念标注错误。
分项指标的加入将在未来让我们可以更全面、更多样地评测一个中文AMR解析器,帮助发现每一个解析器的优势和劣势,从而推动中文AMR解析的发展。
3 结语
由于目前的AMR解析评测指标无法兼容中文AMR的概念对齐信息和关系对齐信息,使得评测结果无法真实反映中文AMR解析的水平,阻碍了中文AMR解析的进一步发展。为此,本文在Smatch指标的基础上,加入了描写概念、关系对齐的三元组,提出了面向中文AMR解析的整体性指标Align-Smatch,并设置了两份人工标注语料A、B与标准语料的对照实验。实验结果显示,两份人工标注语料一致性较低,语料B的标注更为标准,且修正后的评测指标更为合理。
本文还提出了概念对齐指标、关系对齐指标、隐含概念指标共三个分项评估方法,用以呈现中文AMR解析器在概念对齐、关系对齐、隐含概念生成等子任务中的表现情况。三个分项指标反映出A更善于标注关系对齐信息、语料B更善于标注隐含概念,突显了各自的优势和不足。
本文发现的人工标注错误对中文AMR解析系统的研发也有一定的借鉴意义,如在生成有向弧上的词时考虑是否为虚词框架、在概念对齐子任务中关注概念对齐的不同类别,以及同形词和长距离依存等问题。
下一步工作中,我们将把这四个评估方法,用于目前正在开发中的包含对齐信息的中文AMR解析器,以全面评测中文AMR的自动分析效果,实验情况也将推进评测方法的调整。通用语义表示方法(Uniform Meaning Representation,UMR)[25]的研究也正在如火如荼地展开,未来我们将尝试让Align-Smatch兼容其他语言的AMR,促进跨语言AMR解析评测工具的建设。
